МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РЕСПУБЛИКИ
КАЗАХСТАН
Некоммерческое акционерное общество
Алматинский институт энергетики и связи
|
А.Д.Джангозин |
К.С.Чежимбаева
Ю.М. Гармашова
ЦИФРОВАЯ МОДУЛЯЦИЯ
Учебное пособие
Алматы 2009
В учебном пособии излагаются вопросы модуляции в типичных цифровых коммуникационных системах, основные модуляционные методы и критерии отбора модуляционных схем.
Учебное пособие предназначено для бакалавров, обучающихся по специальности 050719 – Радиотехника, электроника и телекоммуникации
Содержание
|
Глава 1…………………………………………………………………………. |
4 |
|
Введение………………………………………………………………………... |
4 |
|
1.1 Цифровые коммуникационные системы…………………………………. |
4 |
|
1.2 Канал связи………………………………………………………………… |
7 |
|
1.3 Основные методы модуляции…………………………………………….. |
11 |
|
1.4 Критерии выбора схем модуляции……………………………………….. |
13 |
|
1.5 Краткий обзор цифровых схем модуляции………………………………. |
16 |
|
Глава 2………………………………………………………………………….. |
20 |
|
2 Модуляция основной полосы частот (Линейные коды)…………………... |
20 |
|
2.1 Дифференциальное кодирование…………………………………………. |
21 |
|
2.2 Описание линейного кодирования……………………………………….. |
25 |
|
2.3 Плотность спектральной мощности линейных кодов…………………... |
31 |
|
2.4 Норма ошибки бита линейных кодов…………………………………….. |
48 |
|
2.5 Линейные коды замены………………………………………………….... |
60 |
|
2.6 Блочные коды……………………………………………………………… |
64 |
|
2.7 Резюме…………………………………………………………………….... |
83 |
|
Список литературы……………………………………………………………. |
85 |
ГЛАВА 1
Введение
В этой главе мы кратко обсудим роль модуляций в типичных цифровых коммуникационных системах, основные модуляционные методы и критерии отбора модуляционных схем. Так же эта глава включает в себя краткое описание различных коммуникационных каналов, которые будут служить основой для дальнейших обсуждений модуляционных схем.
1.1 Цифровые коммуникационные системы
На рисунке 1.1 представлена обычная блок – схема типичной цифровой коммуникационной системы. Сообщение может быть передано из аналогового источника (т.е. голос) или из цифрового источника, (т.е. компьютерные данные). Аналогово-цифровой преобразователь квантует аналоговые сигналы и представляет их в цифровой форме (бит 1 и 0). Источник кодирующего устройства принимает цифровые сигналы и кодирует их в более короткие цифровые сигналы. Это кодирование источника вызывает уменьшение избыточности скорости передач.
Это, в свою очередь уменьшает полосу пропускания необходимой данной системе. Кодирующее устройство канала принимает выходной цифровой сигнал исходного кодирующего устройства и кодирует его в более длинный цифровой сигнал. Избыточность преднамеренно добавляется в закодированный цифровой сигнал так, чтобы некоторые из ошибок, вызванных шумом или интерференцией в течение передачи через канал могли быть исправлены в приемнике. Наиболее часто передача происходит в высокочастотной полосе пропускания, модулятор, таким образом, воздействует кодируемыми цифровыми символами на несущей. Иногда передача находится в основной полосе частот, в таких случаях модулятор называется модулятор основной полосы частот, также названный formator, который форматирует кодируемые цифровые символы в форме волн, удобные для передачи. Обычно после модулятора следует усилитель мощности. Для высокочастотной передачи, модуляция и демодуляция обычно выполняется в промежуточной частоте (IF). В этом случае верхний конвертер вставляется между модулятором и усилителем мощности. Если IF слишком низкая, по сравнению с несущей частотой, то необходимы несколько стадий преобразований несущей частоты. Для беспроводных систем антенна - заключительная часть передатчика
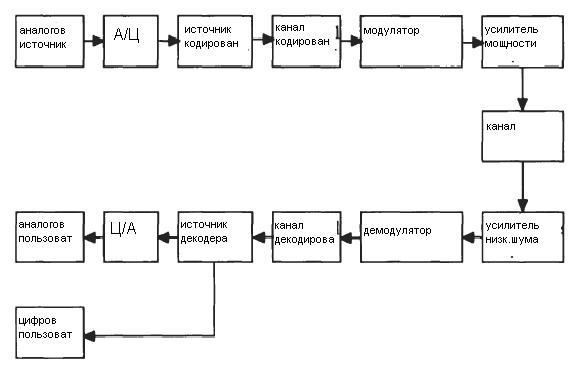
Рисунок 1.1 - Блок-схема типичной цифровой системы связи
Среду передачи обычно называют каналом, где шум добавляется к сигналу и затухание и эффекты ослабления воздействуют как сложный мультипликативные факторы на сигнал. Часть шума, в данном случае, широкое значение шума, который включает все виды из неопределенных электрических помех снаружи или изнутри системы. Канал также обычно имеет ограниченную полосу пропускания частоты так, что его можно представить в виде фильтра. В приемнике, фактически, происходит обратная обработка сигнала. Сначала полученный слабый сигнал усиливается (и down-converted если необходимо) и демодулируется. Затем добавленная избыточность убирается декодером канала и исходным декодером, возвращая сигнал к его первоначальной форме к такой, какая она была прежде, чем была послана пользователю. Цифро-аналоговый (D/A) конвертер необходим для аналоговых сигналов.
Блок-схема на рисунке 1.1 - только типичная конфигурация системы. Реальная конфигурация системы может быть более сложной. Для многопользовательской системы, этап мультиплексирования вставлен перед модулятором. Для многостанционной системы управляющий этап многочисленного доступа вставлен перед передатчиком. Другие особенности подобно частоте распространения и шифрования можно также добавить в систему. Реальная система также могла быть более простой. Кодирование источника и кодирование канала могут быть не нужны в простой системе. Фактически, только модулятор, канал, демодулятор и усилители существенны во всех системах связи (с антеннами для беспроводных систем).
Ради описания методов модуляции и демодуляции и анализа их работ, упрощенная модель системы, показана на рисунке 1.2.
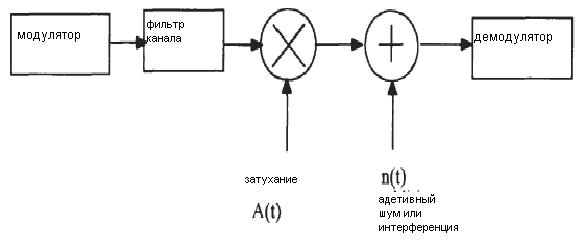
Рисунок 1.2 - Модель цифровой системы связи для модуляции
и демодуляции
Эта модель исключает не относящиеся к блокам модуляций так, чтобы необходимые блоки выделялись. Однако недавно разработанный модем позволил объединить методы модуляция и кодирование канала вместе. В этом случае, кодирующий канал - часть модулятора, а канал декодера - часть демодулятора. Из рисунка 1.2, полученный сигнал на входе демодулятора может быть выражен как
![]()
![]() (1.1)
(1.1)
![]()
где * обозначает скручивание.
На рисунке 1.2 канал описан тремя элементами.
Первый - фильтр канала. Из-за того, что сигнал s(t) должен передаваться от модулятора к передатчику, к каналу (среда передачи) и к приемнику, прежде, чем он достигнет демодулятора, его канальный фильтр становится более сложным, функция передачи которого
![]() (1.2)
(1.2)
где HT(f), Hc(f) и Hr(f) - функция передачи(перемещения) передатчика,
канала, и приемника, соответственно. Эквивалентно, реакция импульса
фильтра канала
![]() (1.3)
(1.3)
где hT(t), hC(t) и hR(t) - ответы импульса передатчика, канала и приемника, соответственно.
Второй элемент - фактор A(t), который более сложен. Этот фактор представляет затухание в некоторых типах каналов, в таких, как мобильный радио-канал. Третий элемент - совокупный шум и время интерференции n (t). Мы обсудим затухание и шум более подробно в следующих разделах. Модель канала на рисунке 1.2 - общая модель. Она может быть упрощена в некоторых случаях, мы будем рассматривать в следующих разделах.
1.2 Канал связи
Характеристика канала играет важную роль в изучении, выборе и проектировании схемы модуляции. Схемы модуляции изучены для различных каналов, чтобы знать их функции в этих каналах. Схемы модуляции выбраны или разработаны согласно характеристике канала, чтобы оптимизировать их работу. В этом разделе мы обсуждаем несколько важных моделей канала в коммуникациях.
1.2.1 Совокупный белый Гауссовский шумовой канал
Совокупный, белый Гауссовский шумовой (AWGN) канал - это универсальная модель канала для анализа схем модуляции. В этой модели канал только добавляет белый Гауссовский шум к сигналу, проходящему через него. Это подразумевает, что канал амплитудной частой является плоским (т.е. с неограниченной или бесконечной полосой пропускания), и ответ фазовой частоты линеен для всех частот так, чтобы с модулированные сигналы проходили через это без любой потери амплитуды и искажения фазы компонентов частоты. Затухание не существует. Единственное искажение появляется из-за AWGN. Полученный сигнал в (1.1) упрощен к
![]() (1.4)
(1.4)
где n (t) – совокупный, белый Гауссовский шум.
Белизна n (t) подразумевает, что это постоянный случайный процесс с flat.
Спектральная плотность мощности (PSD) для всех частот. Это - соглашение принято PSD как
![]()
![]() (1.5)
(1.5)
Это подразумевает, что «белый процесс» имеет бесконечную мощность. Это, конечно, математическая идеализация. Согласно теореме Wiener-Khinchine, автокорреляционная функция AWGN
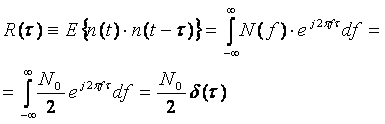 (1.6)
(1.6)
где и (T) - Dirac дельта функция.
Это показывает, что шумовые образцы являются некоррелированными независимо от того, как близко они во времени. Образцы также являются независимыми, начиная с Гауссовского процесса.
В любое время вероятность амплитуды n (t) зависит от функции Гауссовской плотности вероятности, которая равна
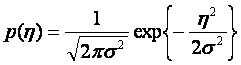 (1.7)
(1.7)
где, ŋ используется, чтобы представить значимость случайного процесса n (t), и σ2 изменение случайного процесса.
Следует обратить внимание на, что
σ2 = ![]() , для AWGN процесс σ2
- мощность шума, который является бесконечным из-за его "белизны".
, для AWGN процесс σ2
- мощность шума, который является бесконечным из-за его "белизны".
Однако, когда r (t) является коррелированным с функцией orthonormal (t), конечный шум имеет конечную разницу. Фактически
 (1.8)
(1.8)
Тогда функция плотности вероятности (PDF) n может быть написана как
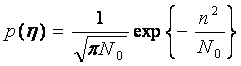 (1.9)
(1.9)
Этот результат будет часто использоваться в этой книге.
На самом деле, AWGN канал не существует, так как никакой канал не может иметь бесконечную полосу пропускания. Однако, когда полоса пропускания сигнала является меньшей, чем полоса пропускания канала, многие практические каналы приблизительны к AWGN каналу. Например, линия вида (ЛОС) радио-каналы, включая стационарную земную микроволновую связь и стационарные спутниковые связи, являются приблизительно AWGN каналами, когда погода является хорошей. Широкополосные коаксиальные кабели - также приблизительно являются AWGN каналами, при условии, если там нет других помех, кроме Гауссовского шума.
В этой книге все схемы модуляции изучены для AWGN канала.
По двум причинам. Во-первых, некоторые каналы приблизительно близки к AWGN каналу, но результаты могут использоваться непосредственно. Во - вторых, совокупный Гауссовский шум независим от других ухудшений канала таких, как ограниченная полоса пропускания, затухание и других существующих ухудшении. Таким образом, AWGN канал - лучший канал в данном случае. Когда существуют другие ухудшения канала, работа системы ухудшится. Степень деградации может измениться для различных схем модуляции. Действие в AWGN может служить стандартом в оценке деградации и также в оценке эффективности с ухудшением.
1.2.2 Канал с ограниченной полосой пропускания
Когда полоса пропускания канала является меньшей, чем полоса пропускания сигнала, то канал является ограниченным по полосе пропускания (band limited). Ограничение по полосе пропускания происходит из-за межсимвольной интерференции (ISI) (то есть цифровой импульс будет распространяться вне продолжительности передачи (периода Ts)) и из-за столкновения (interfere) со следующим символом или даже большим количеством символов. IS1 служит причиной увеличения вероятности ошибки бита или нормы ошибки бита (BER), как это обычно называется. Когда увеличение полосы пропускания канала невозможно или невыгодно, метод стабилизации канала используются для борьбы с межсимвольной интерференцией ISI. В течение многих лет, были изобретены и использовались многочисленные методы стабилизации. Новые методы стабилизации появляются непрерывно. Мы не будем раскрывать их в этой книге. Для предварительного изучения методов стабилизации, рекомендуем читателю (Главу 6) или любой другую книгу по системам связи.
1.2.3 Канал затухания
Затухание – явление, появляющееся при быстром изменении амплитуды и фазы радиосигнала за короткий период времени или расстояния. Затухание вызвано интерференцией между двумя или более версиями переданного сигнала, которые достигают приемника в различное время. Эти волны называются многопутевыми волнами, объединяются в антенне приемника, чтобы в результате получить сигнал, который может (широко) измениться по амплитуде и фазе. Если задержка многопутевых сигналов более длинны, чем период символа, эти многопутевые сигналы нужно рассматривать, как различные сигналы. В этом случае, мы имеем индивидуальные многопутевые сигналы.
В мобильных коммуникационных каналах, типа земного мобильного канала и спутникого мобильного канала, затухание и многопутевая интерференция вызвана отражениями от окружающих зданий и ландшафтов. Кроме того, относительное движение между передатчиком и приемником приводит к случайной модуляции частоты в данном сигнале, к различным Doppler shifts, перемещая на каждом из многопутевых компонентов. Движение окружение объектов, таких как транспортные средства, также вызывает изменение времени Doppler shift на многопутевой компонент. Однако, если окружающие объекты будут двигаться с меньшей скоростью, чем мобильная единица, эти эффект могут игнорироваться [2].
Затухание и многопутевая интерференция также существуют в установленных LOS микроволновых связях [3]. Ясными, спокойными летними вечерами нормальная атмосферная турбулентность минимальна. Тропосфера расслаивается с неоднородной температурой и распределениями влажности
Затухание является причиной амплитуды колебания и изменения фазы в полученных сигналах. Многопутевое затухание является причиной межсимвольной интерференции. Doppler shift является причиной перемещения несущей частоты и увеличения полоса пропускания сигнала. При этом приведут к ухудшению действий модуляции. Анализ действий модуляции в каналах затухания раскрыты в другой главе, где характеристики каналов затухания будут обсуждены более подробно.
1.3 Основные методы модуляции
Цифровая модуляция - процесс, который превращает цифровой символ на сигнал подходящий для передачи. Для передачи данных на короткие расстояния обычно используется модуляция основной полосы частот. Модуляцию основной полосы частот часто называют кодированием линии (line coding). Последовательность цифровых символов используются, чтобы создать квадратную форму волны пульса с некоторыми особенностями, которые представляют каждый тип символа без двусмысленности так, чтобы они могли быть восстановлены на приеме.
Эти особенности - изменения амплитуды импульса, ширины импульса и положения импульса. Рисунок 1.3 показывает несколько форм волны модуляции основной полосы частот.
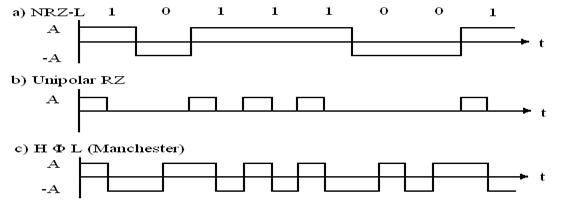
Рисунок 1.3 - Примеры основной полосы частот цифровой модуляции
Первый – невозвращение к нулевому уровню (NRZ-L) модуляции, которая представляет символ 1 положительным квадратный импульс с длиной T и символом 0 отрицательным квадратным импульсом с длиной T.
Второе - униполярное возвращение к нулевой модуляции с положительным импульсом T/2, для символа 1 и пробел для 0. Третье - двухфазный уровень или Манчестер, после его изобретения, модуляция, которая использует форму волны, состоящую из положительной первой половины T импульс и отрицательная вторая половина T импульс, для 1 и полностью измененная форма волны для 0. Эти и другие схемы основной полосы частот будут подробно разобраны в Главе 2.
Для дальнего расстояния и беспроводных передач обычно используется модуляция bandpass. Bandpass - модуляция также называется модуляцией несущей. Последовательность цифровых символов используются, чтобы изменить параметры высокочастотного синусоидального сигнала, так называемой - несущей. Известно, что синусоидальный сигнал имеет три параметра: амплитуда, частота и фаза. Таким образом, модуляция амплитуды, модуляция частоты и модуляция фазы - три основных метода модуляции в модуляции полосы пропускания. Рисунок 1.4 показывает три основные модуляции несущей.
Это - амплитуда shift keying (ASK), частота shift keying (FSK) и фазовая shift keying (PSK). В ASK, модулятор производит колебание для каждого символа 1, и никакого сигнала для каждого символа 0. Эту схему также называют релейным keying (OOK). В общей схеме ASK амплитуда для символа 0 не обязательно - 0. В FSK, для символа 1 колебание передается с более высокой частотой, для символа 0 - с более низкой частотой, или наоборот.
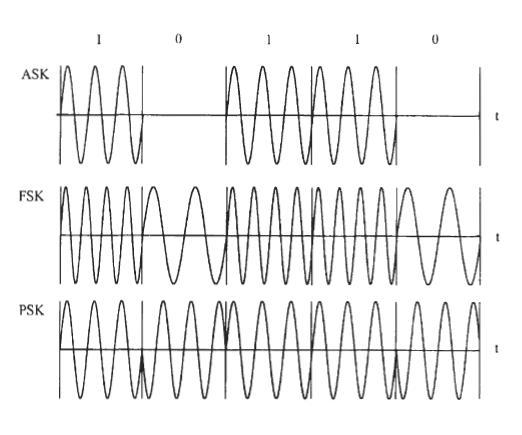
Рисунок 1.4 - Схемы трех основных bandpass модуляции.
В PSK, символ 1 передан как колебание, несущая с нулевой начальной фазой, в то время как символ 0 передается, как колебание несущей с начальной фазой 180.
Базируя на этих трех основных схемах, разнообразные схемы модуляции могут быть получены от их комбинаций. Например, объединяя два двоичных сигнала PSK (BPSK) с ортогональными несущими, можно получить новую схему, называемую фазовой квадратурной shift keying (QPSK). Модулируя одновременно амплитуду и фазу несущей, мы можем получить схему названную модуляцией амплитуды квадратуры (QAM), и т.д.
1.4 Критерии выбора схем модуляции
Сущность цифрового модема в том, чтобы эффективно передать цифровые биты и восстанавливать их после искажения и шума и других помех в канале. Есть три первичных критерия выбора схем модуляции: эффективность мощности, эффективность полосы пропускания и сложность системы.
1.4.1 Эффективность мощности
Норма битовой ошибки, или вероятность ошибки бита схемы модуляции, связано обратно пропорционально к Eb/No,отношением битовой энергии к интенсивности шумового спектра. Например, P b для ASK в АWGN канале
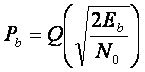 (1.10)
(1.10)
где Eb - средняя энергия бита (частицы);
No - интенсивность спектра шумовой мощности (PSD);
Q (s) - Гауссовский интеграл, иногда называемый Q-функцией. Она определяется как
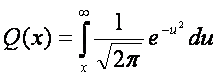 , (1.11)
, (1.11)
который является монотонно уменьшающейся функцией Х. Поэтому эффективность мощности из схемы модуляции определяется, как требуемый Eb/No для некоторой вероятности ошибки бита (Pb) по AWGN канал.
Pb=10-5 обычно используется, как рекомендуемая вероятность ошибки бита.
1.4.2 Эффективность полосы пропускания
Определение эффективности полосы пропускания немного более сложнее. Эффективность полосы пропускания определяется как число битов в секунду, которое может быть передано в один герц полосы пропускания системы. Очевидно, для некоторого модулируемого сигнала это зависит от требуемых условий полосы пропускания системы. Например, односторонняя плотность спектральной мощности ASK сигнала, нам дают модулируемую равновероятную независимую случайную двоичную последовательность, и показывается на рисунке 1.5,
 (1.11 а)
(1.11 а)
где T – продолжительность;
А - несущая амплитуда;
fс - является несущей частотой.
Из рисунка мы можем видеть, что спектр
сигнала растянут на отрезке от![]() до
до ![]() .
.
Таким образом, чтобы совершенно передать сигнал требуется система бесконечной полосы пропускания, которая является непрактичной. Полоса пропускания практической системы является конечной, она изменяется в зависимости от различных критериев. Например, на рисунке 1.5, большинство энергии сигнала концентрируется в отрезке между двумя нулями, таким образом, полосы пропускания от 0 до 0 кажется адекватной. Три вида эффективность полосы пропускания используются в литературе следующим образом:
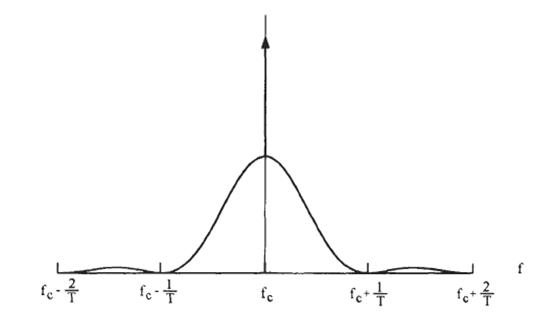
Рисунок 1.5 - Плотность спектральной мощности
Эффективность полосы пропускания Nyquist - система использует Nyquist (идеал прямоугольный) фильтрование в основной полосе частот, который требуется минимальной полосы пропускания для передачи без вмешательств цифровых сигналов. Тогда, основные полосы частот – 0.5Rs, где Rs - норма символа, и полоса пропускания в несущей частоты является W = R.
![]() (1.12)
(1.12)
где Rs=Rb/log2M, Rb - норма бита для модуляции М-мерной, эффективность полосы пропускания
Эффективность полосы пропускания от нуля к нулю. Для схем модуляции, которые имеют плотность спектральной мощности ноль, типа ASK рисунок 1.5, определяют полосу пропускания, поскольку ширина главного спектрального лепестка - удобный путь определения полосы пропускания.
Процентная эффективность полосы пропускания - если спектр модулируемого сигнала не имеет нулей, как в общей непрерывной модуляции фазы (CPM), полоса пропускания от нуля к нулю больше не существует. В этом случае может использоваться энергия полосы пропускания процента. Обычно используются 99 %, даже при том, что другие проценты (например, 90 %, 95 %) также используются.
1.4.3 Сложность системы
Сложность системы связана с суммой вовлеченных схем и технических трудностей в системе. Связано со сложностью системы, стоимостью производства, которая является, конечно, главным беспокойством в выборе метода модуляции.
Обычно демодулятор более сложнее, чем модулятор. Последовательный демодулятор намного более сложен, чем непоследовательный демодулятор, так как требуется восстановление несущей.
Для некоторых методов демодуляции, требуется сложные алгоритмы, подобно Viterbi алгоритму. Все они - основание для сравнения сложности.
Начиная с эффективности мощности, эффективность полосы пропускания и сложность системы - главные критерии выбора метода модуляции, мы будем всегда обращать внимание на них в анализе методов модуляции в остальной части книги.
1.5 Краткий обзор цифровых схем модуляции
Мы вносим в список сокращений и названия различных цифровых модуляций, и вводим их в таблицу 1.1 и в дерево цифровой модуляции изображены схематически на рисунке 1.6. Некоторые из схем могут быть получены больше чем одной "родительской" схемы. Схемы, где может использоваться дифференциальное кодирование отмеченной D, и те, которые могут некогерентное демодулирование отмеченной N. Все схемы могут когерентно демодулироваться.
Схемы модуляции, внесенные в список в таблицу, и в дереве классифицируются как две большие категории: постоянные огибающие и непостоянные огибающие. Под постоянными огибающими классифицируется - три подкласса: FSK, PSK, CPM. Под непостоянным классом огибающих три подкласса: АSK, QAM, и другие непостоянные огибающие модуляции.
Среди внесенных в список схем, АSK, PSK, и FSK - основные модуляции: MSK, GMSK, CPM, MHPM, и QAM, и т.д. - производные схемы. Производные схемы - разновидности и комбинации основных схем.
Постоянный класс огибающих является подходящим для систем связи, чьи усилители мощности должны работать в нелинейной области характеристик «ввода – вывода», чтобы достигать максимальной эффективности усилителя.
Пример.TWTA в спутниковых коммуникациях. Однако родовые FSK схемы в этом классе являются несоответствующими для спутникового применения, так как они имеют очень низкую эффективность полосы пропускания по сравнению с PSK схемами. Двоичные FSK используется в каналах управления низкой нормы первого порядка сотовой системы, AMPS (обслуживание службы мобильного телефона США.) и ETACS (европейская система полной связи доступа). Нормы данных - 10 Kbps для AMPS и 8 Kbps для ETACS. PSK схемы, включая BPSK, QPSK, OQPSK и MSK, использовались в спутниковой системе связи.
π/4-QPSK стоит специального внимания, из-за его способности избежать резкое изменение фазы на 180 и позволять дифференциальную демодуляцию. Это использовалось в цифровом мобильном телефоне сотовой системы, типа цифровой сотовой (USDC) системы Соединенных Штатов.
Таблица 1.1- Схемы цифровой модуляции
|
Abbreviation |
Alternate Abbr. |
Descriptive name |
|
Frequency Shift Keying (FSK) |
||
|
BFSK |
FSK |
Binary Frequency Shift Keying |
|
MFSK |
|
M-ary Frequency Shift Keying |
|
Phase Shift Keying |
||
|
BPSK |
PSK |
Binary Phase Shift Keying |
|
QPSK |
4PSK |
Quadrature Phase Shift Keying |
|
OQPSK |
SQPSK |
Offset QPSK, Staggered QPSK |
|
π/4-QPSK |
|
π/4, Quadrature Phase Shift Keying |
|
MPSK |
|
M-ary Phase Shift Keying |
|
Continuous Phase Modulations (CPM) |
||
|
SHPM |
|
Single-h (modulation index) Phase Modulation |
|
MHPM |
|
Multi-h Phase Modulation |
|
LREC |
|
Rectangular Pulse of Length L |
|
CPFSK |
|
Continuous Phase Frequency Shift Keying |
|
MSK |
FFSK |
Minimum Shift Keying |
|
SMSK |
|
Serial Minimum Shift Keying |
|
LRC |
|
Raised Cosine Pulse of Length L |
|
LSRC |
|
Spectrally Raised Cosine Pulse of Length L |
|
GMSK |
|
Gaussian Minimum Shift Keying |
|
TFM |
|
Tamed Frequency Modulation |
|
Amplitude and Amplitude/Phase modulations |
||
|
ASK |
|
Amplitude Shift Keying (generic name) |
|
OOK |
ASK |
Binary On-Off Keying |
|
MASK |
MAM |
M-ary ASK, M-ary Amplitude Modulation |
|
QAM |
|
Quadrature Amplitude Modulation |
|
Nonconstant Envelope Modulations |
||
|
QORC |
|
Quadrature Overlapped Raised Cosine Modulation |
|
SQORC |
|
Staggered QORC |
|
QOSRC |
|
Quadrature Overlapped Squared Raised Cosine Modulation |
|
Q2PSK |
|
Quadrature Quadrature Phase Shift Keying |
Продолжение таблицы 1.1
|
IJF-OQPSK |
|
Intersymbol-Interference/Jitter Free OQPSK |
|
TSI-OQPSK |
|
Two-Symbol-Interval OQPSK |
|
SQAM |
|
Superposed-QAM |
|
XPSK |
|
Cross correlated QPSK |
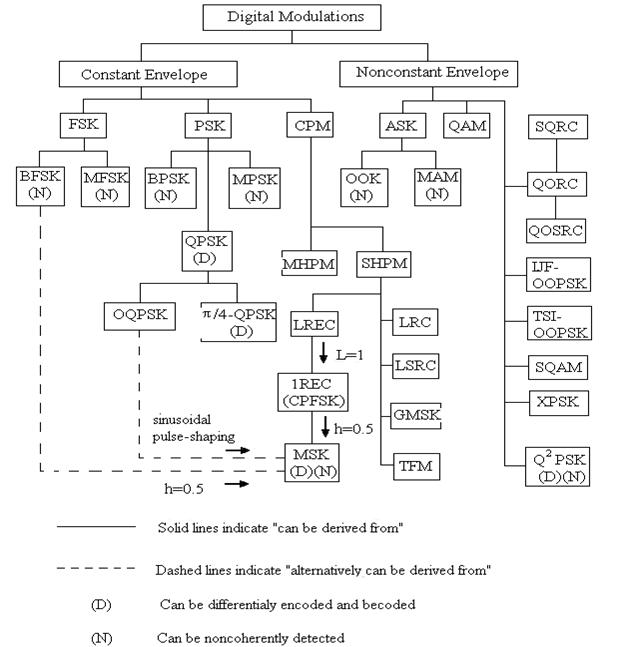
Рисунок 1.6 - Дерево цифровой модуляции
Схемы PSK имеют постоянную огибающую, но прерывистые переходы фазы от символа к символу. Схемы CMP имеют не только постоянную огибающую, но также и непрерывные переходы фазы. Таким образом, они имеют меньше side lope энергии в их спектрах по сравнению с PSK - схемами.
Класс CPM включает LREC, LRC, LSRC, GMSK, и TFM. Их различия лежат в их различных импульсах частоты , которые раскрываются в их названиях(именах). Например, LREC означает, что импульс частоты является прямоугольным импульс с длиной L периода символа. MSK и GMSK - две важные схемы в классе CPM.
MSK - особый случай CPFSK, но он также может быть получен от OQPSK с дополнительным синусоидальным формированием импульса. MSK имеет превосходную мощность и эффективность полосы пропускания. Его модулятор и демодулятор также не слишком сложны. MSK использовался в Передовых Технологиях Связи спутника(ACTS) НАСА. GMSK имеет Гауссовский импульс частоты.
Таким образом, он может достигнуть еще лучшей эффективности полосы пропускания, чем MSK. GMSK используется в американских системах сотовых цифровых пакетах данных (CDPD) и европейских системах GSM (глобальная система для мобильной коммуникации).
MHPM заслуживает особого внимания, так как оно имеет лучшее действие ошибки (error performance), чем одиночная – h CPM, индекс модуляции h, которой циклически изменен.
Общие схемы непостоянной огибающей , типа ASK и QAM, обычно не подходят для систем с нелинейными усилителями мощности. Однако QAM, с большим созвездием (constellation) сигнала, может достигнуть чрезвычайно высокой эффективности полосы пропускания. QAM широко использовался в модемах, используемых в телефонных сетях, типа компьютерных модемов. QAM можно даже использовать для спутниковых систем. В этом случае, однако, back-off в TWTA должна обеспечивать входную и выходную мощность, чтобы гарантировать линейность усилителя мощности.
Третий класс при непостоянной модуляции огибающей включает довольно многие схемы. Они прежде всего разработаны для спутниковых применений, так как они имеют очень хорошую эффективность полосы пропускания и минимальное изменение амплитуды. Все из них, кроме Q2, PSK базируются на формировании импульса амплитуды в 2Ts и их структуры модулятора являются подобными OQPSK. Схема Q2PSK базируется на четырех ортогональных несущих.
Глава 2
2 Модуляция основной полосы частот (Линейные коды)
Модуляция основной полосы частот определена как прямая передача без преобразования частоты. Эта - технология представляет собой цифровую последовательность импульса в форме волны удобной для передачи основной полосы частот. Разнообразие форм волны было предложено как попытка найти небольшое количество желательных свойств, типа хорошей полосы пропускания и эффективности мощности, и адекватной синхронизаций информации. Модуляция основной полосы частот этих форм волн иногда называют линейными кодами, основная полоса частот formаts (или формы волны), PCM формы волны (или formats, или кодами).
PCM (импульсная кодовая модуляция) относится к процессу, в котором двойная последовательность, представляющая цифро-аналоговый сигнал, закодированный в импульс в форме волны. Для сигнала данных PCM не обязателен. Поэтому часть линейного кода и формат основной полосы частот (или форма волны) является более подходящей, и модель наиболее часто используема. Линейные коды были, главным образом, развивались инженерами в годах 60-ых в AT&T, IBM или RCA для цифровой передачи по телефонным кабелям или цифровой записи на магнитную ленту [1-5]. Последнее время линейные коды, главным образом, концентрируются на волоконно - оптических системах передач [6-11].
В этой главе мы сначала вводим понятия метода дифференциального кодирования, которое используется в последующих разделах главы о построении линейных кодов. Затем мы опишем различные основные линейные кодирования в параграфе 2.2. Плотность спектральной мощности будет раскрыта в параграфе 2.3.
Демодуляция этих форм волны заключается в проблеме обнаружения сигналов в шуме. В параграфе 2.4 мы сначала описываем оптимальное обнаружение двойных сигналов в совокупном белом Гауссовском шуме (AWGN) и затем применяем общие формулы к полученным выражениям для вероятностей ошибки бита или норм ошибки бита (BER) различных линейных кодов. Общие результаты могут использоваться для любого двойного сигнала, включая bandpass сигналы, которые будут описаны в последующих главах.
Также должно быть подчеркнуто то, что практические датчики для линейных кодов часто не оптимальны для упрощения схем. Однако работа оптимального датчика всегда может быть рекомендуемой для сравнения. Коды замены и коды линейной схемы являются более сложными кодами с улучшенным действием основных линейных кодов. Они раскрыты в параграфе 2.5 и 2.6. Параграф 2.7 объединяет эту главу. Явление межсимвольной интерференций (Intersymbol interference) (ISI) и методы стабилизации, включая метод duo binary передачу сигналов, являются важными темами в основной полосе частот, где bandpass модуляция сопровождается или нет (is followed or not).
Более глубокое изучение этих тем требует большого количества времени, и поэтому некоторые особенности не включены в эту книгу, которая предназначена для схем модуляции. Для начального ознакомления с IS1 и стабилизацией читатель может обратиться к любому учебнику по цифровым коммуникациям.
2.1 Дифференциальное кодирование
Так как в некоторых полосах частот двоичной формы волны, используют метод, называемый дифференциальным кодированием, мы нуждаемся в более глубоком изучении этого метода основной полосы частот. Этот метод используется не только в модуляции основной полосы частот, но также и в band pass модуляция, где он используется для того, чтобы кодировать основную полосу частот данных перед тем, как модулировать их в несущую. Преимущество использования дифференциального кодирования станет ясным, когда мы рассмотрим схемы его использования. Изучаемым в данный момент метод, будет использоваться повсюду в остальной части книги.
Пусть {ak} будет первоначальной двоичной последовательностью данных, а дифференцированно кодируемая двоичная последовательность данных {dk} определяется согласно условию:
![]() (2.1)
(2.1)
где ![]() указывает сложение по модуль-2.
указывает сложение по модуль-2.
Сложение по модулю -2 также называют exclusive-OR (XOR) . 0+0=0, 0+1=1, 1+0=1 и 1+1=0 - это правила сложения по модулю-2. Из формулы (2.1) и из правил сложения по модулю-2 мы можем видеть, что текущий результат (output ) бита кодирования определен текущим исходным (input) кодом и предыдущим результатом кода. Если они отличны, то результирующий код будет -1 , если одинаковы, то – 0. Этот метод называется дифференциальным кодированием.
Для использования дифференциального кодирования необходим начальный код, и это называют (рекомендованным) reference кодом. Например, если {k} и {dk} оба начинаются с k = 1, то нам необходим d0 reference код. После этого d0 может быть выбирается как 0 или 1, тогда {ak} может кодироваться в две различные последовательности данных. Они дополнительны друг к другу.
Правило декодирования
![]() (2.2)
(2.2)
где шляпа указывает полученные данные в приемнике.
Полученный ![]() может быть тем же самым или отличаться от
{dk}.
Например, шумовой канал может при получении изменять некоторые из битов в
{dk}. Даже,
если шум незначительный, так что биты не изменяются шумом, то измененная
полярность на разных уровнях передатчика и приемника могут изменять полярность
всей последовательности.
может быть тем же самым или отличаться от
{dk}.
Например, шумовой канал может при получении изменять некоторые из битов в
{dk}. Даже,
если шум незначительный, так что биты не изменяются шумом, то измененная
полярность на разных уровнях передатчика и приемника могут изменять полярность
всей последовательности.
Таблица 2.1 - Пример дифференциального кодирования

Дифференциальное кодирование используется также для эффекта обращенной полярности. Это показывает формула (2.2), в которой результат декодирования зависит от двух различных последовательностей, полученных битов, но не от их полярности. Когда полярность всей последовательности изменена, различие между двумя последовательными битами остается не -измененной.
Таблица 2.1 является примером, который показывает процесс кодирования и декодирования с изменением или без изменения полярности. Результаты те же самые. Отметьте, что в примере приняты ошибки, не вызванные шумом.
Первый бит {dk} – это reference бит, который 0 в примере.
Рисунок 2.1 показывает блок-схемы дифференциального кодирующего устройства и декодера выраженные формулами (2.1) и (2.2).
Рассмотрим распределение вероятности дифференцированно кодируемой последовательности. Это нам понадобится, когда мы будем рассчитывать позже в главе функцию автокорреляции кодирования последовательности. Предположим, что последовательность данных {ak} постоянна, ее биты независимы и распределены в (p0, p 1 ), где p0 =Pr(1) и
p1 =Pr(1)
, p0 + p1 =1. Предположим,
что ![]() - это
распределение k-ого бита кодируемой последовательности {dk} , где
- это
распределение k-ого бита кодируемой последовательности {dk} , где ![]() и
и ![]() .
Согласно формуле (2.1), мы имеем
.
Согласно формуле (2.1), мы имеем
![]() (2.3)
(2.3)
![]() (2.4)
(2.4)
Так как начальный бит определен при
кодировании, ![]() и
и ![]() .
.
Они принимают значение 0 или 1, в
зависимости от того, что выбрано. Например, если - reference 0, то ![]() . Это легко проверить, так как если
. Это легко проверить, так как если ![]() тогда
тогда ![]() , для всех k. То есть
дифференциальное кодирование не изменяет распределение данных для одинаково
вероятных данных. Однако, когда распределение первоначальных данных не
одинаково, дифференциальное кодирование действительно изменяет распределение
данных. Далее мы можем показать, что
, для всех k. То есть
дифференциальное кодирование не изменяет распределение данных для одинаково
вероятных данных. Однако, когда распределение первоначальных данных не
одинаково, дифференциальное кодирование действительно изменяет распределение
данных. Далее мы можем показать, что

Рисунок 2.1 - Дифференциальный кодер (a), и декодер (b).
![]() асимптотически независим от величин p0 и p1.
асимптотически независим от величин p0 и p1.
Начинаем с любого из вышеупомянутых двух уравнений, скажем (2.3), из которого мы имеем
![]()
Подставляя z- преобразование, в обе стороны вышеупомянутого уравнения, мы получаем
![]()
где Qo (z) - z-преобразование последовательности {qo}. Преобразовав выражение, мы имеем
![]()
Используя теорему конечной величины, мы
получаем предел ![]() как
как
![]()
![]()
![]()
Таким образом, мы можем сделать вывод, что распределения первоначальные данные независимо от распределения дифференциальные кодируемые данные, они всегда асимптотически равны.
Чтобы увидеть, как ![]() быстро сходится к 1/2, мы
определяем два отношения как
быстро сходится к 1/2, мы
определяем два отношения как
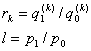
и заменяем (2.3) и (2.4) выражением r k, и мы имеем
![]() (2.5)
(2.5)
![]()
Затем мы определяем разность отношений как
![]()
Если ![]() и
и ![]() , то решение формулы (2.5) даст rk=1, т.е.
, то решение формулы (2.5) даст rk=1, т.е. ![]() для
для
![]()
Вычисления показывают, что для ![]() и
и![]() , фактически равняются
, фактически равняются ![]() при k=10 и 38,
соответственно. Для очень искаженного распределения (т.е. ро=0,01), чтобы
достичь
при k=10 и 38,
соответственно. Для очень искаженного распределения (т.е. ро=0,01), чтобы
достичь ![]() необходимо
411 повторений. Все эти значения k являются малыми по сравнению с числами
данных в практических системах. Таким образом, мы можем видеть, что распределение
дифференцированно кодируемых данных становится фактически равным очень быстро, независимо
от распределения первоначальных (оригинальных) данных.
необходимо
411 повторений. Все эти значения k являются малыми по сравнению с числами
данных в практических системах. Таким образом, мы можем видеть, что распределение
дифференцированно кодируемых данных становится фактически равным очень быстро, независимо
от распределения первоначальных (оригинальных) данных.
Дифференциальное кодирование может быть также получено, путем двойного дополнения сложения по модуль 2 как результат , который
![]() (2.6)
(2.6)
где ![]() обозначает двойное дополнение x.
Снова это второе правило может произвести две дополнительные последовательности
с двумя различными выборами опорного бита. Соответственно правило декодирования
обозначает двойное дополнение x.
Снова это второе правило может произвести две дополнительные последовательности
с двумя различными выборами опорного бита. Соответственно правило декодирования
![]() (2.7)
(2.7)
которая является также способным к исправлению переменной полярности. Блок-схемы кодера и декодера, определенные этими наборами правил, подобны тем, которые изображены на рисунке 2.1 , за исключением того, что на выходе и кодера и декодера необходим инвертер.
Вышеупомянутые аргументы о распределении также ссылаются к данным, кодированным этим путем, так как эта кодированная последовательность - только дополнение к предыдущей.
Другой тип дифференциального кодирования это
![]() ,
(2.8)
,
(2.8)
которая производит последовательность с тремя уровнями (-1,0, + 1). Произвольный начальный опорный бит a0 должен быть рассчитан. Очевидно, что распределение dk
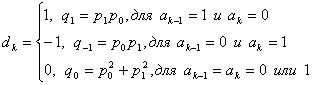 (2.9)
(2.9)
Расшифровка может быть произведена следующим
образом. Сначала ![]() преобразовывают
к униполярной
преобразовывают
к униполярной ![]() ,
c помощью исправление полной волны, тогда
,
c помощью исправление полной волны, тогда ![]() восстанавливается от
восстанавливается от ![]() путем XOR
действия:
путем XOR
действия:
![]() (2.10)
(2.10)
где известен начальный ![]() .
.
Эта схема кодирования – также является защитой от проблемы (inversion-ambiguity) двусмысленности инверсии полярности, после того, как исправления полной волны, форма волны могла быть такой же.
2.2 Описание линейного кодирования
Многодвойных линейных кодов были предложены в литературе, и некоторые из них используются в практических системах. Основные коды классифицируется в четыре класса: коды без возвращения к нулю (NRZ), с возвращением к нолю (RZ), псевдотроичное (PT), и двухфазный. NRZ и RZ классы могут быть далее разделены на униполярные и полярные подклассы. Коды включают коды замены и блочные коды. Есть некоторые другие коды, которые не принадлежат ни одному из классов. Некоторые кодексы могут принадлежать больше, чем одному классу. Рисунок 2.2 - весьма полное собрание форм волны различных основных линейных кодов. Каждый из них будет изучен подробно в короткое время. Рисунок 2.2 не включает коды замены и блокирующие коды. Они будут изучены отдельно, в последней части этой главы.
Причина такого широкого рассмотрения линейных кодов в различии их действия, которое будет вести к различным применениям. Особенности для выбора линейных кодов следующие. Для специфического применения некоторые из особенностей могут быть важны, в то время другие могут быть нет.
1) Адекватная синхронизация информации. Бит или символ синхронизации обычно восстанавливается от полученной последовательности данных. Это требует, чтобы формат линейных кодов обеспечивал адекватную плотность перехода в кодируемой последовательности. Форматы с более высокой плотностью перехода более предпочтительны, так как восстановление синхронизации этого вида волн будет проходить с меньшими проблемами. Ряд из двоичных 1 и 0 в данных не должны служить проблемой для восстановления синхронизации.
2) Спектр, подходящий для канала. Например, линейные коды с компонентами без dc и с маленькими near-dc компонентами плотности спектральной мощности (PSD) желательны для систем магнитных записей, соединенных каналов ac, или систем, использующих сцепление трансформатора, которые имеют очень низкую частотную характеристику. Кроме того, линейные коды PSD должны иметь достаточно маленькую полосу пропускания по сравнению с полосой пропускания канала IS1, так, чтобы не возникло проблем.
3) Узкая полоса пропускания. Полоса пропускания линейного кода должна быть столь узкой, насколько возможно.

Рисунок 2.2 - Линейные коды
Полоса пропускания передачи может быть уменьшена путем фильтрования и многоуровневой схемы передачи. Отрицательной стороной является увеличение Pb из-за увеличения в IS1 и уменьшения в отношении сигнала к шуму. Некоторые линейные коды могут перенести меньше изменений, чем другие.
Низкая вероятность ошибки. Линейные коды могут быть восстановлены с низкой вероятностью бита от шума and/or IS1 возвращенного полученного сигнала. Коды с более низкой Pb (вероятность ошибки) предпочтительны для средней энергии бита, но рассматривать нужно и другие характеристики также, как полоса пропускания и способности самосинхронизации.
Способность обнаружения ошибки. Некоторые схемы имеют способность обнаружения ошибки в полученной последовательности, не вводя дополнительные биты, как в схемах кодируемого канала. Эта способность обнаружения ошибки может использоваться как средство контроля процесса. Однако исправление ошибки невозможно, этого можно достичь с помощью методов кодирования канала или через автоматические схемы передачи (retransmission).
Независимые битовые последовательности. Линейные коды должны быть способны к кодированию любых последовательностей данных из любого источника, и декодер должен быть способен к декодированию этого назад к первоначальным данным. Другими словами, признаки кода независимы от исходных данных .
Дифференциальное кодирование. Эта особенность полезна так, как дифференцированно закодированные последовательности являются независимыми от инверсии полярности, как мы и изучали в предыдущем параграфе. Однако, если дифференциальное кодирование несвойственно, непосредственно для линейных кодов, то отдельные дифференциально - кодируемые схемы могут быть включены в систему.
В дальнейшем мы описываем различные линейные коды, в основном, в группах. Но некоторые из линейных кодов выбраны из-за их важности или уникальных особенностей. Когда мы изучаем эти коды, вышеупомянутые критерии должны быть учтены, и мы будем возвращаться к ним время от времени.
Мы акцентируем свое внимание на правилах кодирования и их характеристиках. Вообще, мы пренебрегаем действием кодера и декодера. Простые коды могут быть осуществлены простыми комбинациями и последовательными цифровыми повторениями, в то время как сложные коды могут быть переведены в цифровой сигнал обрабатывающим методом. Всестороннее изучение действия кодера и декодера не необходимо, и они также не входят в эту книгу. Заинтересованные читатели могут обратиться к рекомендованным спискам для схем. Однако многие схемы являются устаревшими, новые схемы должны быть разработаны на основе новых IС чипов.
2.2.1 Коды без возвращения к нулю
Группа без возвращения включает первые
три кода на рисунке 2.2. Два уровня (![]() A)
амплитуды импульса используются, чтобы отличить набор двоичных 1 и 0 в формате
NRZ-L. Эта форма волны не имеет никакого
dc компонента для равновероятной двоичной
последовательности данных. В NRZ-М формате изменение уровня
(от А к -A или от
-A к A) отмечается меткой (1) в двойной
последовательностью, если нет изменения, то (0). NRZ-S
форма волны подобны за исключением того, что изменение уровня используется,
чтобы указать место (0). И NRZ-М и NRZ-S являются
дифференцированно кодируемыми формами волны. Они могут быть произведены путем
модулирования дифференцированно кодируемых двойных последовательностей,
используя NRZ-L формат.
Форма волны NRZ-М производится путем кодирования по правилу (2.1) и форма
волны NRZ-S с помощью
кодирования по правилу (2.6). Опорный (references) бит
- 0. Соответственно последовательность кодов для NRZ-М была ранее
описана в таблице 2.1.
A)
амплитуды импульса используются, чтобы отличить набор двоичных 1 и 0 в формате
NRZ-L. Эта форма волны не имеет никакого
dc компонента для равновероятной двоичной
последовательности данных. В NRZ-М формате изменение уровня
(от А к -A или от
-A к A) отмечается меткой (1) в двойной
последовательностью, если нет изменения, то (0). NRZ-S
форма волны подобны за исключением того, что изменение уровня используется,
чтобы указать место (0). И NRZ-М и NRZ-S являются
дифференцированно кодируемыми формами волны. Они могут быть произведены путем
модулирования дифференцированно кодируемых двойных последовательностей,
используя NRZ-L формат.
Форма волны NRZ-М производится путем кодирования по правилу (2.1) и форма
волны NRZ-S с помощью
кодирования по правилу (2.6). Опорный (references) бит
- 0. Соответственно последовательность кодов для NRZ-М была ранее
описана в таблице 2.1.
Восстановление NRZ-L' от NRZ-М или NRZ-S достигнуто дифференциальным декодированием.
Главное преимущество NRZ-М и NRZ-S перед NRZ-L – этого устойчивость к переменной полярности, вследствие дифференциального кодирования.
Все три вышеуказанные форматы могут быть сделаны униполярными, за счет изменения нижнего уровня от – A до уровня 0. Для двойной последовательности с одинаково вероятными 1-ми и 0-ми, что является обычным предположение, униполярные формы волны имеют dc-компонент на уровне A/2, тогда как полярные не имеют.
Так как 1-ый ряд в NRZ-S и 0-ойряд в NRZ-М., и ряды из 1-ц или 0-ей в NRZ-L не содержат никаких переходов, этот класс форм волны не может обеспечить достаточную синхронизацию информации для данных с длинными рядами из 1 и 0. Решение этого недостатка включает предварительное кодирование последовательности данных, чтобы устранить длинные ряды из 1-ц и 0-ей или передачу отдельной последовательности синхронизации.
Как известно, NRZ-L обширно используется в цифровой логике. NRZ-М используется, прежде всего, в магнитных кассетных записях. В телекоммуникациях применение формата NRZ ограничено коротко приемными сетями из-за временной характеристики.
2.2.2 Коды с возвращением к нолю
Недостаток синхронизации информации форматов NRZ можно преодолеть, с помощью введения большого количества переходов в форму волны. Эти примеры RZ формата показаны на рисунке 2.2. Однако, полоса пропускания RZ формата шире, чем формата NRZ, как мы и увидим в дальнейшем.
В униполярном RZ формате двоичная 1 представлена положительным импульсом для полубититового периода, тогда возвращающего к нулевому уровню в течение следующей половины периода, заканчивающегося переходом в середине бита. Двоичный «0» представлен нулевым уровнем для полного битового периода. Так как у них нет никаких переходов в нулевом ряду, предварительно кодируя или scrambling, необходимо устранять длинные ряды из 0-ей. Этот формат также имеет dc-компонент, так как он является униполярным.
В полярном RZ формате 1 и 0 соответственно представляется положительным и отрицательным полупериодом импульса. Эта форма волны гарантирует два перехода в бит. Оно не имеет dc компонента.
2.2.3 Псевдотроичные Коды (включая АМI)
Эта группа линейных кодов использует три
уровня ![]() A
и 0. Коды AMI (alternative mark inversion) также находятся в этой группе. Их часто называют биполярными
кодами в телекоммуникационной индустрии. В AMI-RZ
(АМI возвращения к нолю) формате единица представлена RZ
импульсом с альтернативными полярностями, если единица последовательны. 0 представлен
нулевым уровнем. В АМI - NRZ
(АМI без возвращения к нулю), правило кодирования то же
самое, как AMI-RZ, за исключением того, что импульс символа имеет
полную длину T. Они не имеют dc компонента, но подобно униполярному RZ их
недостаток переходов заключается в проблеме синхронизации ряда 0. Поэтому AM1
коды с нулевым извлечением будут обсуждены позже в этой главе.
A
и 0. Коды AMI (alternative mark inversion) также находятся в этой группе. Их часто называют биполярными
кодами в телекоммуникационной индустрии. В AMI-RZ
(АМI возвращения к нолю) формате единица представлена RZ
импульсом с альтернативными полярностями, если единица последовательны. 0 представлен
нулевым уровнем. В АМI - NRZ
(АМI без возвращения к нулю), правило кодирования то же
самое, как AMI-RZ, за исключением того, что импульс символа имеет
полную длину T. Они не имеют dc компонента, но подобно униполярному RZ их
недостаток переходов заключается в проблеме синхронизации ряда 0. Поэтому AM1
коды с нулевым извлечением будут обсуждены позже в этой главе.
Восстановление NRZ-L от кода АМI-NRZ достигнуто простым исправлением полной волны. Подобно этому, AMI-RZ - коды из полной волны могут быть исправлены в RZ-L форму волны, которая может быть легко преобразована в форму волны NRZ-L.
Эти форматы используются в передаче данных основной полосы частот и при магнитной записи. Форматы AMI-RZ наиболее часто используется в системах телеметрии, например, AT&T для TI системы несущей.
Другие члены этой группы включают decode NRZ и decode RZ . Decode форматы также называют сдвоенными двоичными в литературе [1, 2]. В decode NRZ переход от 1 к 0 или от 0 до 1 изменяет полярность импульса, нулевой уровень не представляет никаких переходов данных. В decode RZ используется то же самое правило кодирования за исключением того, что ширина импульс – только полбита (то есть, возвращается к нолю для второй половины бита).
Decodes и коды AMI связаны дифференциальным кодированием [2]. Если
последовательность данных, это последовательность ![]() , используемая для непосредственного составления
decode, тогда последовательность
, используемая для непосредственного составления
decode, тогда последовательность ![]() , где
, где ![]() , может
использоваться для составления кода AMI, который является decode
к первоначальной последовательности
, может
использоваться для составления кода AMI, который является decode
к первоначальной последовательности ![]() . Предположим,
что а0 = 0, мы преобразовываем
. Предположим,
что а0 = 0, мы преобразовываем ![]() =(1,0,1,1,0,0,0,1,1,1,0,0) в
=(1,0,1,1,0,0,0,1,1,1,0,0) в ![]() =
(-1,1,-1,0,1,0,0-1,0,0,1,0). Используя
=
(-1,1,-1,0,1,0,0-1,0,0,1,0). Используя ![]() и правила AMI,
мы можем строить точные Decodes ,как на рисунке (с заменами А и -A на 1 и -1,
соответственно).
и правила AMI,
мы можем строить точные Decodes ,как на рисунке (с заменами А и -A на 1 и -1,
соответственно).
Decodes могут быть расшифрованы
следующим образом. Сначала ![]() преобразован к униполярному
преобразован к униполярному ![]() , с помощью
исправления полной волны, затем
, с помощью
исправления полной волны, затем ![]() восстановлен от
восстановлен от ![]() путем суммирования
по модулю- 2:
путем суммирования
по модулю- 2: ![]() Читатели
могут легко проверить вышеупомянутый пример.
Читатели
могут легко проверить вышеупомянутый пример.
2.2.4 Двухфазные Коды (включая Манчестер)
Эта группа линейных кодов использует полупериодные импульсы с различными фазами согласно правилам кодирования в форме волны. Четыре формы волны этой группы показаны на рисунке 2.2.
Формат Bi-Ф-L (двухфазный уровень) лучше известен как Манчестер, и его также называют diphase, или split-phase. В этом формате 1 представлен как импульс с первой половиной бита в более высоком уровне и второй половине бита на более низком уровне. 0 представлен как импульс с противоположной фазой (т.е. нижний уровень для первой половины бита и высший уровень для второй половины бита).
Конечно, формы импульса для 1 и 0 могут изменяться.
Bi-Ф-M (двухфазная марка) формат требует, чтобы переход всегда присутствовал в начале каждого бита. 1 кодируется, как второй переход в середине бита, и 0 кодируется, как второй переход в бите. Результат представляется так, что 1 является одной из 2-х фаз импульса. В Bi-Ф-S (двухфазное пространство) формате противоположные правила кодирования применены к 1 и 0. Вышеупомянутые три двухфазных формата гарантируют то, что есть, по крайней мере один переход с битовой продолжительности, таким образом, обеспечивая адекватную синхронизацию информации в демодуляторе.
Четвертый формат в этой группе – это conditioned(обусловленный) Bi-Ф -L. Фактически, это – дифференцированно - кодируемый Bi-Ф-L (то есть последовательность данных, используемые для модуляции произведена от первоначальной двойной последовательности с дифференциальным кодированием). Подробно NRZ-М и NRZ-S, этот формат является защитным от инверсий полярности в схеме.
Двухфазные форматы используются в магнитной записи, оптических коммуникациях и в некоторых спутниковых связях телеметрии. Манчестерский код был определен для IEEE 802.3 стандартным для основной полосы частот коаксиального кабеля, используя направляющую несущую многократного доступа и обнаружение столкновения (CSMА/СD) (то есть Ethernet [13,14]. Это также использовалось в MILSTD- 1553B, который является огражденной системой витой пары, разработанной для высоко-шумовых окружающих сред [14].
Дифференциальный Манчестер был определен для IEEE 802.5 стандартным для символического кольца, использующее любую основную полосу коаксиал кабеля или витую пару. Поскольку это дифференциальное кодирование используется, дифференциальный Манчестер предпочтено для канала с витой пары.
2.2.5 Задержка Модуляция (Код Мiller)
Задержка модуляции (DM) [3], или код Miller также может классифицироваться в двухфазные группы, так как у них есть две фазы в форме волны. Однако оно имеет некоторые уникальные особенности. 1 представлена переходом в середине бита. 0 представлен не переходом, если это не сопровождается другим 0. Тогда переход помещен в конец первых 0 битов. Этот формат имеет очень маленькую полосу пропускания, и он является наиболее важным и имеет очень маленький dc компонент. Это делает его подходящим для магнитной записи, так как магнитные записи не имеют никакого dc ответа [3].
2.3 Плотность спектральной мощности линейных кодов
В этом параграфе мы представляем общую формулу для спектральной плотности мощности (PSD) для вычисления в цифровой форме модулируемых форм волны основной полосы частот. Это может использовано, в основном, для двоичных линейных кодов. Поэтому во многих случаях мы будем использовать эту формулу для различных кодов в остальной части параграфа. Однако эта формула не применима для некоторых кодов, также для некоторых методов для вычисления PSD, их мы обсудим позже. Мы знаем, что большинство сигналов, подобно звуковым сигналам и видео сигналам, по существу случайные. Поэтому цифровые сигналы, полученные из этих сигналов, также случайны. Данные сигналы также случайные.
Предположите, что цифровой сигнал может быть представлен
![]() (2.11)
(2.11)
где ак - дискретные случайные биты данных;
g(t) - сигнал продолжительности T (то есть, отличный от нуля только в [O, TI).
Позвольте нам называть g(t) как symbol function. Это может быть любой сигнал с преобразованием Фурье.
Например, это может быть символ основной полосы частот, формирующий импульс или скачок модулируемой несущей в полосе пропускания. Случайная последовательность {ak} может быть двоичной или не двоичной.
Мы описываем, что спектральная плотность мощности s (t)
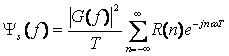 (2.12)
(2.12)
где ![]() G(f) - преобразование Фурье от g(t);
G(f) - преобразование Фурье от g(t);
R(n) – автокорреляция функции случайной последовательности {ak), определенная, как ![]() , где E
{x) является средней вероятностью числа x.
, где E
{x) является средней вероятностью числа x.
Уравнение (2.12) показывает, что PSD цифрового модулируемого сигнала решается не только путем символьной функции, но также с помощью автокорреляционной функции последовательности данных.
В последующем мы будем принимать, что
первоначальная двоичная последовательность данных имеет 1 и 0 одинаковой
вероятности, то есть, ![]() .
.
Однако, чтобы написать модулируемую форму волны в формуле (2.1l), последовательность {ak} в (2.11) является обычно не первоначальной последовательностью, скорее получено из оригинала. Поэтому распределение вероятности должно быть рассчитано.
Для некоррелированой последовательности {ak},
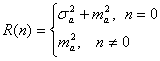 (2.13)
(2.13)
где ![]() - дисперсия;
- дисперсия;
ma – мода последовательности {ak).
Использование формулы суммы Пуассона
 (2.14)
(2.14)
где Rb = 1/T – интенсивность битовых данных.
Для линейных кодов с R (n) = 0 для
![]() более
подходящей является формула (2.12). Для линейных кодов с
более
подходящей является формула (2.12). Для линейных кодов с ![]() более подходящей
является (2.14).
более подходящей
является (2.14).
Среди основной полосы частот, модулированные сигналы, NRZ-L, NRZ-М., NRZ-S, RZ (полярный или униполярный), AMI-RZ, AMI- NRZ, Bi-Ф-L, и decode (RZ или NRZ), могут быть написаны в виде (2.11). Поэтому их PSD может быть найдено, весьма легко используя вышеупомянутые ряды систем уравнений. Однако есть некоторые цифровые сигналы, которые не могут просто представить через (2.1 1). Среди линейных кодов Bi-Ф-M, Bi-Ф-S, DM и заменяющих кодов и блока кодов, который будет описан позже, принадлежат этой группе.
Если сигнал - wide sense stationary (WSS),чтобы найти их PSD, надо
сначала найдите их автокорреляцию R (r), затем взять преобразование
Фурье, чтобы найти PSD (Wiener-Khintchine - теорема). Если сигнал - cyclostationary, то R (T)
–среднее время зависимости - времени ![]() в периоде. Wiener-Khintchine - теорема
является все еще применима, когда среднее время R (t,r), используется
для нестационарного, включая cyclostationary процесса.
в периоде. Wiener-Khintchine - теорема
является все еще применима, когда среднее время R (t,r), используется
для нестационарного, включая cyclostationary процесса.
Некоторая кодируемые последовательности, такие как Bi-Ф-М и модуляция задержки, могут быть описаны, как первое правило Марковского случайного процесса. Где R (T) может быть найден, используя метод рассмотренного в книге [3]. Мы будем использовать этот метод, когда мы сталкиваемся с вычислением PSDs Bi-Ф-M и задержка модуляция.
Для более сложных кодированных последовательностей можно использовать общую формулу, данную как [15,16]:
![]() (2.15)
(2.15)
где Gi(f) – преобразование Фурье состояние i импульса формы волны;
T - ширина импульса;
![]() - Kronecker дельта функция;
- Kronecker дельта функция;
pi - состояние установившееся данной вероятности;
Uij(f) - преобразование вероятности состояния j, установившееся после состояния i. вероятность pi найдено путем использования остатка Uij(f) в его полюсах, когда f=0. Uij(f) рассчитан с помощью графика потока сигнала и формулой Масона [17].
Мы не пытаемся использовать этот метод в этой главе, чтобы не делать наше обсуждение более математическими. Вместо этого результаты, полученные, используя этот метод, могут быть использованы, когда необходимо. Или мы можем использовать компьютерное моделирование Монте-Карло, чтобы найти и PSD.
Теперь мы готовы обсудить PSDs двоичных линейных кодов, описанных в предыдущем параграфе.
2.3.1 PSD Кодов без возврата к нулю
Вспомним, что NRZ-М. и NRZ-S произведены с помощью модуляции NRZ-L с дифференцированным кодированием последовательности данных. Предположим, что первоначальные двоичные данные одинаково вероятны. Тогда согласно параграфу 2.1, дифференцированно кодируемые последовательности с (2.1) или (2.6) являются также одинаково вероятными. Другими словами, статистические свойства последовательностей используются непосредственно для модуляции тех же NRZ-L, NRZ-М., и NRZ-S. И их символьные функции также одинаковы. В результате их PSDs те же самые.
Символьная функция NRZ форматов – это квадратный импульс с амплитудой в интервале [O. TI, который может быть выражен как
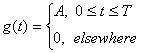 (2.16)
(2.16)
Это преобразование Фурье, может быть легко найдено как
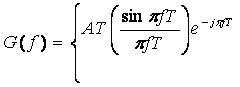 (2.17)
(2.17)
![]()
где ![]() -
это синусоидальная функция.
-
это синусоидальная функция.
Затем мы должны найти автокорреляцию функции R(n) для двоичной последовательности данных {ak}. Для этой формы волны
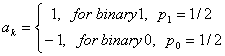 (2.18)
(2.18)
Таким образом
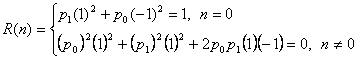 (2.19)
(2.19)
Заменяя выражения G(f) и R (n), в формуле (2.12) мы имеем,
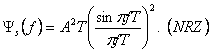 (2.20)
(2.20)
Рисунок 2.3 (a) показывает график ![]() и мощности Pob(B),
определенный как
и мощности Pob(B),
определенный как
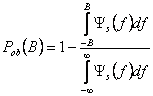 (2.21)
(2.21)
На рисунке Pob (B)
измеряется в децибеле, горизонтальная ось - нормализованная частота f
T =f/Rb. На рисунке
мы устанавливаем, что А=1 и T=1 для единой символьной энергии импульса.
Это PSD - функция преобразована с его первым нулем в f T=1.
Энергия сигнала концентрируется около 0 частоты и нулевой полосы
пропускания - ![]() ;
90%- энергия полоса пропускания -
;
90%- энергия полоса пропускания -
![]() , и 99%- полоса пропускания -
, и 99%- полоса пропускания - ![]() .
.
Мы упоминали, что все три NRZ
формы волны могут быть сделаны униполярными. Предположим, что амплитуда
импульса A, тогда dc компонент присутствует A/2 в сигналах, и он
представлен, как импульсная функция с интенсивностью ![]() до 0 частоты в спектральной
плотности мощности, как это будет показано в дальнейшем. В этом случае функция
импульса, такая же, как и в формуле (2.16), и данные представлены в виде
до 0 частоты в спектральной
плотности мощности, как это будет показано в дальнейшем. В этом случае функция
импульса, такая же, как и в формуле (2.16), и данные представлены в виде
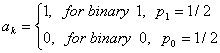 (22.2)
(22.2)
Из этого мы имеем
![]() (2.23)
(2.23)
и
![]() (2.24)
(2.24)
Заменяем выражение G (f), ma, и ![]() в
формуле (2.14), мы имеем,
в
формуле (2.14), мы имеем,
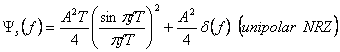 (2.25)
(2.25)
Для единой средней энергии символа мы
должны предположить, что А=![]() . Это PSD имеет ту же
самую форму, как и полярная NRZ. Единственное различие - импульс при 0 частотах.
. Это PSD имеет ту же
самую форму, как и полярная NRZ. Единственное различие - импульс при 0 частотах.
PSD и вне –полосе пропускания мощности представлены на
рисунке 2.3 (b). Полосы пропускания ![]() .
.
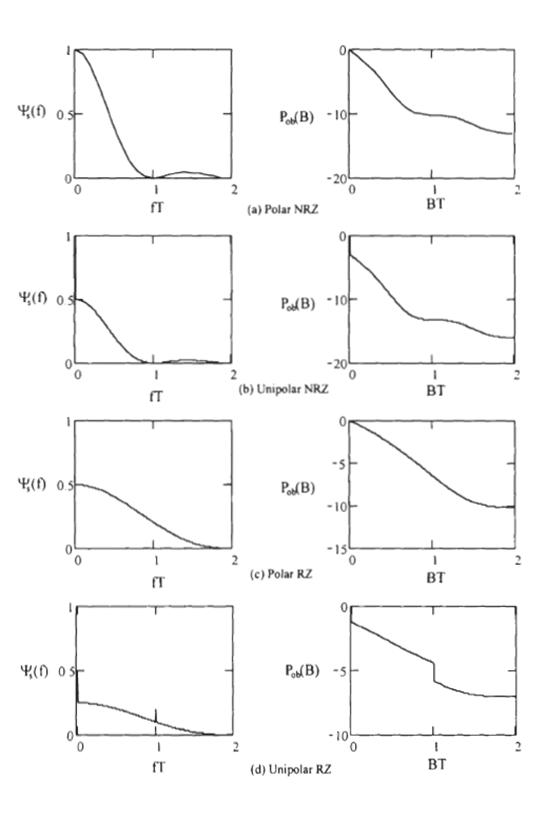
Рисунок 2.3 - PSD линейных кодов (Pob (B) измеряется в децибелах)

Рисунок 2.4 - PSD линейных кодов (Pob (B) измеряется в децибелах) (продолжение)
2.3.2 PSD Коды с возвратом к нолю
Для RZ форматов, функция импульса - это квадратный импульс с продолжительностью в полбита
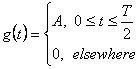 (2.26)
(2.26)
Соответственно преобразование Фурье
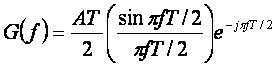 (2.27)
(2.27)
Для полярной формы волны RZ
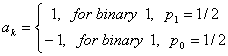 , (2.28)
, (2.28)
который является таким же для полярной NRZ. Таким образом,
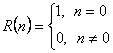 (2.29)
(2.29)
Заменяя (2.27) и (2.29) в (2.12), результат
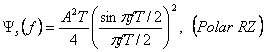 (2.30)
(2.30)
Для единой средней энергии символа мы
должны предположить, что А=![]() .PSD и вне – полосы пропускания
мощности показываются на рисунке 2.3 (с). По сравнению с PSD
формата NRZ, этот PSD – вытянутая версия с осью частоты, увеличенная в два
раза. Поэтому вся эта полоса пропускания увеличена в два по сравнению с NRZ.
Полосы пропускания
.PSD и вне – полосы пропускания
мощности показываются на рисунке 2.3 (с). По сравнению с PSD
формата NRZ, этот PSD – вытянутая версия с осью частоты, увеличенная в два
раза. Поэтому вся эта полоса пропускания увеличена в два по сравнению с NRZ.
Полосы пропускания ![]() .
.
Для униполярного RZ формата импульс символа такой же, как в (2.26).
Последовательность данных, ее мода и
дисперсия та же самая, как и у униполярного NRZ, заданного в
(2.22). (2.23) и (2.24). Заменяя G (f) в (2.27). ma
и ![]() в
(2.14), мы имеем
в
(2.14), мы имеем
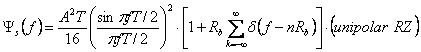 (2.31)
(2.31)
Для единой средней энергии символа мы должны предположить, что А=2. PSD и вне- полосы пропускания мощности представлены на рисунке 2.3 (d). Из рисунка мы можем видеть кроме непрерывного спектра, напоминающий PSD полярного RZ, оно является заостренным на всех нечетных числах частоты.
Их интенсивность определяется второй частью (2.31) и задано как
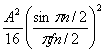
Для А = 2, интенсивность компонентов формируют f = 0. Rb. 3Rb. 5Rb. 7Rb. И 9Rb, которые: 0.25, 0.101, 0.01 1, 0.004, 0.002, и 0.001 в двухстороннем спектре. Все дискретные гармоники составляют в целом 0.5, и остальная часть энергии (0.5) находится в непрерывной части спектра.
Ширина полосы пропускания ![]() , которые являются
почти такими же, как у полярного RZ формата.
, которые являются
почти такими же, как у полярного RZ формата.
2.3.3 PSD - Псевдотроичных кодов
Для AM1 кодов последовательность данных {ak} выражается тремя значениями:
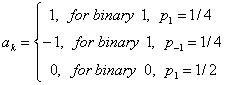 (2.32)
(2.32)
Мы можем найти R (0) следующим образом
![]()
Смежные биты в {аk},
коррелированные. Образец смежного бита в первоначальной двоичной
последовательности, должен быть один из: (1,1), (1,0), (0, I), и (0, O).
Возможно, ![]() преобразован в - 1, 0, 0, 0. Каждый из
них имеет вероятность, равную 1/4. Таким образом,
преобразован в - 1, 0, 0, 0. Каждый из
них имеет вероятность, равную 1/4. Таким образом,
![]()
Для n> 1,а k и а k +1 не
коррелируется. Возможные производные от ![]() - это
- это![]() 1,0,0,0. Каждый процесс
происходит с вероятностью 1/4.
1,0,0,0. Каждый процесс
происходит с вероятностью 1/4.
Таким образом,
![]()
Суммируя вышеперечисленные результаты, мы имеем

Заменяя R(n) и символьного импульса спектра (2.27) в (2.12), мы имеем PSD AMI-RZ кода:
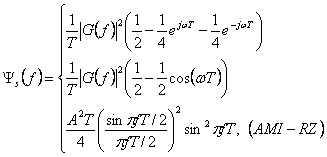 (2.33)
(2.33)
В PSD, показанной
на рисунке 2.4 (a), мы устанавливаем, что А= 2 , чтобы нормализовать PSD.
Ширина полосы пропускания -![]() , которая является более узкой, по
сравнению с RZ форматами, с особенно нулевой полосой пропускания,
которая является только половиной других.
, которая является более узкой, по
сравнению с RZ форматами, с особенно нулевой полосой пропускания,
которая является только половиной других.
PSD AMI-NRZ может быть получен, заменяя T/2 на T в G (f) AMI-RZ
(2.27), так как они оба имеют одинаковые правила кодирования, и единственное различие- это ширина импульса. Таким образом, PSD АМИ-NRZ получается как
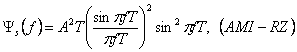 (2.34)
(2.34)
В PSD, показанной
на рисунке 2.4 (a), мы устанавливаем, что А= ![]() , чтобы нормализовать PSD.
Ширина полосы пропускания
, чтобы нормализовать PSD.
Ширина полосы пропускания ![]() , которые более узкие, чем AMI-RZ.
, которые более узкие, чем AMI-RZ.
PSDs других членов этой группы (то есть diodes NRZ и diodes RZ (или сдвоенные двоичные коды)) получены в последующем. Как мы описали ранее, decodes может быть построен, используя AM1 правила и дифференцированно кодированные последовательности, эти decodes могут быть выражены в форме (2.11) как
![]() (2.35)
(2.35)
где
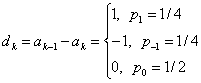
Последовательность {dk} - псевдотроичная последовательность, полученная из первоначальных двоичных данных последовательности {ak}. Его распределение вероятности, точно такое же, как и распределение AMI (2.32). Поэтому PSD decodes такие же, как и коды AMI и ширина полосы пропускания является также одинаковой соответственно AMI кодам.
2.3.4 PSD - Двухфазных кодов
Для Bi-Ф-L (Манчестера), символьной функции, импульс является полу положительным и полуотрицательным, определенный как
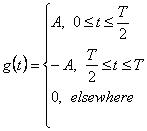 (2.36)
(2.36)
Преобразование Фурье из g (t) это
![]() (2.37)
(2.37)
Распределение вероятности данных

которая является одинаковой и для NRZ. Мы показали, что R (n) = 1 для n = 0 и
R (n) = 0 для n ![]() 0
(2.19). Использование (2.12) мы получаем
0
(2.19). Использование (2.12) мы получаем
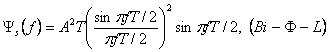 (2.38)
(2.38)
Этот PSD показан на рисунке 2.4 (c), где мы устанавливаем, что А= 1 для единой энергии символа.
PSD обусловленного Bi-Ф-L такой же , как и для Bi-Ф -L, так как это просто дифференцированно кодируемый Bi-Ф-L, и дифференциальное кодирование не изменяет распределение вероятности одинаково вероятных данных.
Очевидно, что Bi-Ф-М. и Bi-Ф –S имеют одинаковый PSD, начиная с марок и места, одинаково вероятны, равновероятную последовательность данных.
Поэтому мы можем предположить, что их PSD одинаковы, как и Bi-Ф-L. Фактически это предположение является правильным. Мы докажем это в следующем.
Мы будем использовать метод, используемый в получении PSD модуляции задержки или в Miller коде.
Мы будем базировать наше обсуждение на Bi-Ф-М, и этот результат применим к Bi-Ф-S, поскольку мы это уже упоминали.
Правило кодирования Bi-Ф-М. может
быть описано как Марковский случайный процесс первого порядка. Каждый интервал
бита может быть разделен на интервалы на два полубита, тогда каждый интервал
может быть описан уровнями, встречающимися в интервалах на два полубита.
Временно примем, что амплитуда А-1, тогда два уровня - +1 и - 1. Он
является четырьмя типами интервалов бита или, что это может произойти в
маленьком интервале: (-1+1) . (1-1). (-1-1) и (1 1) Они одинаково
вероятны (то есть pi=1/4, i=(1.2.3.4). Состояние маленького интервала зависит только от
состояния предыдущего интервала бита. Это Марковский процесс первого
порядка. Процесс тогда полностью описан, когда ![]() , матрица
вероятности-перехода, в который элемент Pil = p
(j / i) равняется условной вероятности состояния j встречающийся после
данного состояния, i произошел в предыдущем интервале бита. Для Bi-Ф -M с
помощью правил кодирования мы можем найти матрицу перехода как
, матрица
вероятности-перехода, в который элемент Pil = p
(j / i) равняется условной вероятности состояния j встречающийся после
данного состояния, i произошел в предыдущем интервале бита. Для Bi-Ф -M с
помощью правил кодирования мы можем найти матрицу перехода как

который представлен на рисунке 2.5 (a).
Функция автокорреляции R (r) , где T = nT (n = 0,1,2. ..)
 (2.39)
(2.39)
где г, (t) = форма волны состояния i.
p (j / i. n) = вероятность возникновения состояния j в t = nT.
Данное состояние i в t = 0, которые являются равными i, j-м элементам матрицы Pn.
W= матрица с элементами wij= , WT - это
транспонированная матрица W.
, WT - это
транспонированная матрица W.
Интеграл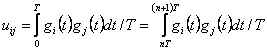 этого расчета "time averaging" переменного времени R (nT, t) через битовый интервал,
чтобы получить R (nT).
Базируемое на формах волны состояние, мы можем найти W как
этого расчета "time averaging" переменного времени R (nT, t) через битовый интервал,
чтобы получить R (nT).
Базируемое на формах волны состояние, мы можем найти W как

которое описано на рисунке 2.5 (b), где заштрихованные области - области интегрирования. Заменяя P и W в (2.39),в результате мы получаем

Подобно этому, мы можем найти автокорреляцию для T = (n + 1/2) T следующим образом
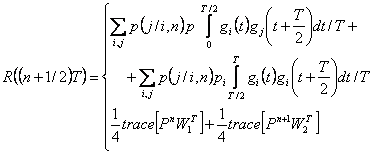 (2.40)
(2.40)
где

и
 ,
,
которые описаны на рисунке 2.5 (c, d). Результаты для n >0
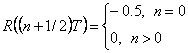
Из-за симметрии R (r), ясно, что R (-T/2) =-0.5 и R (nT/2) = 0
для всего n <-1. Автокорреляция по промежуточным значениям r получена, точно соединяя эти пункты. R (r) Bi-Ф-М показано на рисунке 2.5 (e). С помощью использования преобразования Фурье из R (r), легко найти PSD как
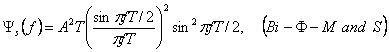 , (2.41)
, (2.41)
который является такой же, как эти для Bi-Ф -L или Манчестера.
Ширина полосы пропускания всех двухфазных кодов
![]()
2.3.5 PSD - Модуляции задержки
Спектральный анализ модуляции задержки также базируется на Марковском процессе первого порядка [3]. Автокорреляция R (nT) и R ((n + 1/2) T) также дается в (2.39) и (2.40).
Матрица вероятности-перехода
 ,
,
который показан на рисунке 2.6 (a). W матрица
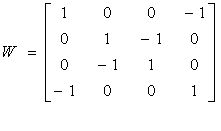
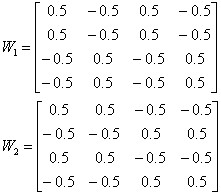
Все они представлены на рисунке 2.6.
Используя эти матрицы, мы можем определить R (T) для T = nT и
(n + 1/2) T.
Промежуточное звено R(T) получено, с помощью соединяя этих пунктов. Кроме того, это может быть легко проверено
![]()
Поэтому
![]()
Таким образом, первые восемь выражений R (T) от R (0) до R (3.5Т), данные в рисунке 2.6 (e), полностью определяют R (T).С помощью использования преобразования Фурье из R (r), используя (2.42), и отношение
![]()
где * указывает сопряженный PSD DM
![]()
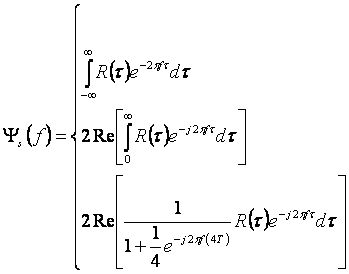
где Rе указывает реальную часть.
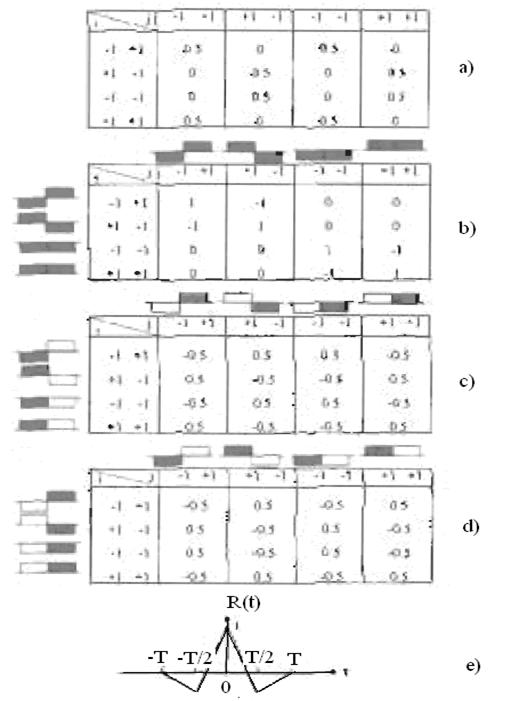
Рисунок 2.5
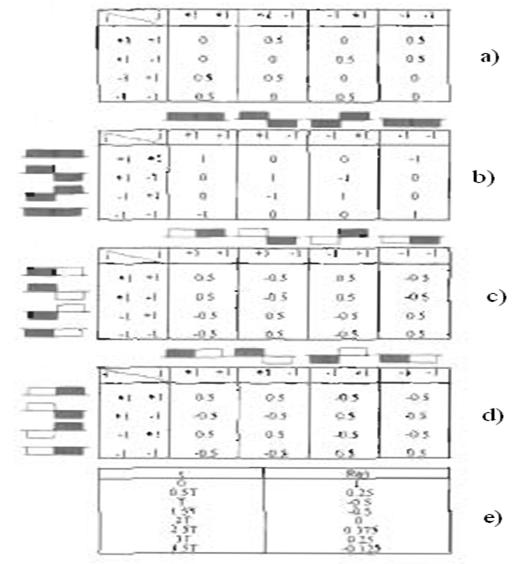
Рисунок 2.6
 (2.43)
(2.43)
где ![]() .
.
PSD показан на рисунке 2.4 (d), где А = 1 для единой энергии символа. PSD имеет пик в f = 0.4Rb, и он имеет очень узкую ширину полосы пропускания, приблизительно 0.5Rb. Однако он сходится к нулю очень медленно. В результате его энергия в пределах полосы пропускания 2Rb - только 76.4 %, и в пределах 250Rb – только 83.7 %.
2.4 Норма ошибки бита линейных кодов
В этом параграфе мы обсуждаем оптимальное обнаружение линейных кодов, переданных через AWGN канал, и их вероятностные ошибки. Мы должны иметь ввиду, что модель канала AWGN подразумевает, что ответ(response) частоты канала является плоским и имеет бесконечную полосу пропускания. Единственное искажение введено аддитивным белым Гауссовским шумом. Однако это достаточно точная модель полосы пропускания сигнала, которая является намного более узкой, чем этого канал. Также важно обратить внимание, что оптимальный приемник не может являться практическим решением. Другие неоптимальные приемники могут быть столь же хороши, как оптимальный в некоторых обстоятельствах (например, высокое сигнально- шумовое отношение) и их структуры более простые. Тем не менее, вероятность ошибки в AWGN канале служит для сравнения действия.
Мы начинаем с двоичных кодов и будем переходить к псевдотроичным кодам.
2.4.1 BER Двоичных кодов
Двоичные линейные коды состоят из двух видов сигналов, или форм с точки зрения теория обнаружения, мы имеем две гипотезы:
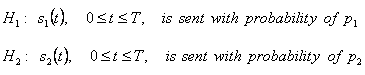
где p1 и p2 называются приорными (priori) вероятностями. Энергия этих двух сигналов
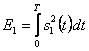
и
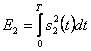
Эти два сигнала могут быть коррелированными. Мы определяем
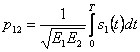
как коэффициент корреляции
s1 (t) и s2 (t). ![]() . Полученный сигнал
. Полученный сигнал
![]()
где шум n (t) - AWGN
с нулевой серединой и двухсторонней спектральной плотностью ![]() .
.
Оптимальный приемник состоит из коррелятора или согласованного фильтра, который, согласовывают к различным сигналам.
![]()
Эти две формы приемника показаны на
рисунке 2.7 (a, b), и они эквивалентны в частях с вероятностью ошибки. Области
решения двоичного обнаружения сигнала показана на рисунке 2.7 (c), где ![]() .
.
Пороговый детектор сравнивает интегратор
или результат образца z= z (T) с порогом ![]() , и решает, какая гипотеза является
правдоподобной, то есть правило решения это следующее
, и решает, какая гипотеза является
правдоподобной, то есть правило решения это следующее
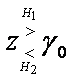
Для критерия минимальной вероятности ошибки и р1 = p2 порог рассчитывается по формуле
![]() (2.45)
(2.45)
Вероятностью ошибки бита
 (2.46)
(2.46)
где

является энергией различных сигналов, и Q (x) – это Q-функция, которую мы уже рассматривали в главе 1 (см. (1. 11)).
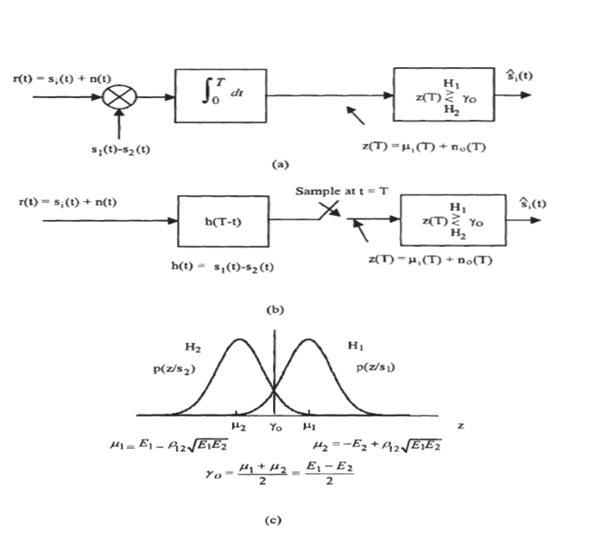
Рисунок 2.7 - Оптимальный приемник для двоичных сигналов:
(a) Коррелятор,
(b) согласовывающии фильтр,
(c) области решений.
Выражение (2.46) показывает, что
расстояние (![]() ) между двумя сигналами sl
(t) и s2 (t), меньше, чем Pb. Это
показывает, что чем большее расстояние, тем легче для декодера отличить их. В
части энергии каждого сигнала, вышеупомянутое выражение Pb становится
) между двумя сигналами sl
(t) и s2 (t), меньше, чем Pb. Это
показывает, что чем большее расстояние, тем легче для декодера отличить их. В
части энергии каждого сигнала, вышеупомянутое выражение Pb становится
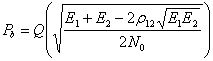 (2.47)
(2.47)
Это выражение указывает, что Pb зависит
не только от индивидуальных энергий сигнала, но также и от
корреляции между ними. Интересно обнаружить, что когда ![]() - минимальным. Двоичные сигналы
с
- минимальным. Двоичные сигналы
с ![]() называются
диаметрально противоположными (antipodal).
Когда,
называются
диаметрально противоположными (antipodal).
Когда, ![]() сигналы
ортогональны.
сигналы
ортогональны.
2.4.1.1. BER Кодов без возврата к нолю
NRZ-L. NRZ-L являются antipodal с
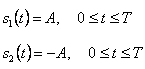
и
![]()
Тогда ![]() . Из (2.47)
. Из (2.47)
выражаем, что Pb
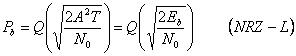 , (2.48)
, (2.48)
который изображен на рисунке 2.8. Оптимальный порог
![]()
Униполярная NRZ. Для униполярного NRZ,
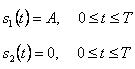
и
![]()
Таким образом, ![]() .
Его вероятность ошибки
.
Его вероятность ошибки
 , (2.49)
, (2.49)
который изображен на рисунке 2.8. Оптимальный порог
![]()
NRZ-М. или S. Они модулируются путем дифференциального
кодирования последовательности данных. Для кодированной последовательности
оптимальный приемник создает вероятность ошибки, данной в формуле (2.48) с ![]() =0.
=0.
После определения кодированной последовательности дифференцированное декодирование восстанавливает его в первоначальную последовательность данных закодированной последовательности используется, чтобы создать существующий бит первоначальной последовательности (см. (2.2)). Поэтому вероятность ошибки
![]() = Pr (существующий бит верный и предыдущий бит неверный )
= Pr (существующий бит верный и предыдущий бит неверный )
+ Pr (существующий бит неверный и предыдущий бит верный)
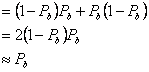
для маленьких значении Pb это:
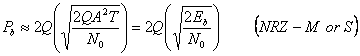 , (2.50)
, (2.50)
который изображен на рисунке 2.8.
2.4.1.2 BER Кодов с возвратом к нолю.
Полярный RZ. Сигналы являются антиподальными с
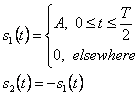
и
Тогда ![]()
Из (2.47) его Pb
 , (2.51)
, (2.51)
который является таким же и для NRZ-L в Eb/Nb, и оптимальный порог ![]() , также является 0. Pb и
изображен на рисунке 2.8.
, также является 0. Pb и
изображен на рисунке 2.8.
Униполярный RZ. Сигналы
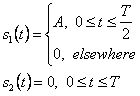
и
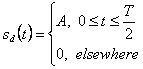
Тогда ![]() . Из (2.47) его Pb
. Из (2.47) его Pb
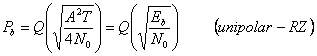 , (2.52)
, (2.52)
который изображен на рисунке 2.8. Оно
является таким же и для NRZ-L в Eb/No, и оптимальный порог ![]() равен
равен ![]() , Обратим внимание, что для того
, чтобы Eb униполярных RZ было такое же и для
униполярных NRZ, его амплитуда должно составлять
, Обратим внимание, что для того
, чтобы Eb униполярных RZ было такое же и для
униполярных NRZ, его амплитуда должно составлять ![]() времени униполярного NRZ. Это сделает их
пороги одинаковыми, когда их Ebs будут
так же одинаковы. Однако если амплитуда фиксирована, то импульс
униполярного NRZ будет иметь удвоенную энергию униполярного RZ
импульса, таким образом, вероятность ошибки будет ниже. В дальнейшем наше
сравнение всегда будет базироваться на Eb/No. Однако читатель
должен знать различные итоги заключения, если сравнение базируется на
одинаковой амплитуде.
времени униполярного NRZ. Это сделает их
пороги одинаковыми, когда их Ebs будут
так же одинаковы. Однако если амплитуда фиксирована, то импульс
униполярного NRZ будет иметь удвоенную энергию униполярного RZ
импульса, таким образом, вероятность ошибки будет ниже. В дальнейшем наше
сравнение всегда будет базироваться на Eb/No. Однако читатель
должен знать различные итоги заключения, если сравнение базируется на
одинаковой амплитуде.
2.4.2 BER Псевдотроичных кодов
Согласно результатам теории обнаружения в см. [18. Глава 4]), для сигналов М-ary, приемник вычисляет минимальную вероятность ошибки
![]() (2.53)
(2.53)
и выбирает наибольший, где

ri -
статистически независимые Гауссовские случайные переменные c
дисперсией No/2. Их средние
значения зависят от гипотез, то есть 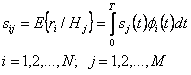
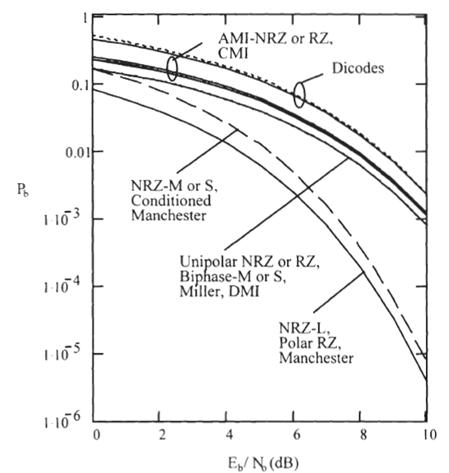
Рисунок 2.8 - Вероятность ошибки некоторого линейного
кода
![]() - orthonormal
координаты для проектирования на них r(t);
- orthonormal
координаты для проектирования на них r(t);
N – измерение векторного места, заполненного ![]() .
.
Коды АМI-NRZ состоят из трех типов сигналов, или мы имеем три гипотезы:

Мы выбираем, ![]() , и остальная часть сигналов линейно связанны с ними.
Поэтому N = 1 в этом случае и оптимальном приемнике состоит из
одного коррелятора и порогового детектора . Правило (2.53)
обнаружения уменьшается до
, и остальная часть сигналов линейно связанны с ними.
Поэтому N = 1 в этом случае и оптимальном приемнике состоит из
одного коррелятора и порогового детектора . Правило (2.53)
обнаружения уменьшается до

Правило решения состоит в том, чтобы
выбрать наибольший порог. Для того, чтобы l1 был
наибольшим мы должны иметь ![]() , из этих
отношений мы можем вывести
, из этих
отношений мы можем вывести
![]()
Аналогично мы можем вывести
![]()
и
![]()
Поэтому есть два порога и три области решения, как показано на рисунке 2.9.
Оптимальный приемник состоит только из одного коррелятора и порогового датчика с двумя порогами, как показано на рисунке 2.9.
Используя Pr (e/si), чтобы обозначить вероятность ошибки, когда сигнал s (t) передан, средняя вероятность ошибки бита может быть рассчитана следующим образом:
![]()
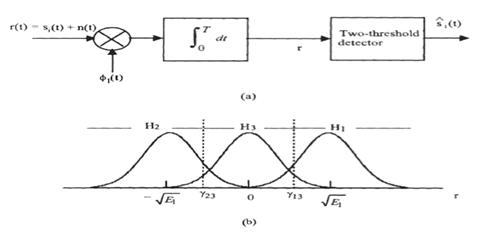
Рисунок 2.9 - оптимальный преемник (а), области решении(b)
AMI сигнала
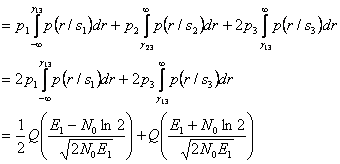 (2.54)
(2.54)
Дано ![]() , и мы имеем
, и мы имеем
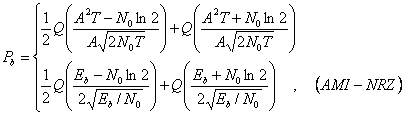 (2.55)
(2.55)
Это - вероятность ошибки бита оптимального приема.
Однако, когда отношение сигнала к шуму
высоко, пороги Noln2<<E1могут быть
установлены на полпути между сигналами, с очень маленькими потерями действия
ошибки, то есть,![]() .
Таким образом, выражение BER (2.55) уменьшается до
.
Таким образом, выражение BER (2.55) уменьшается до
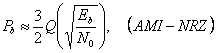 , (2.56)
, (2.56)
который составляет 3/2 времени униполярного NRZ. И точные, и приблизительные значения Pb для АМI-NRZ изображены на рисунке 2.8, где верхняя кривая - приблизительная. Может быть замечено, что они очень близки, даже при низких отношениях сигнала к шуму.
Для АМI-RZ, у
которого ![]() и
среднее число Eb = A2 T/4, BER может быть найден из (2.54)
и
среднее число Eb = A2 T/4, BER может быть найден из (2.54)
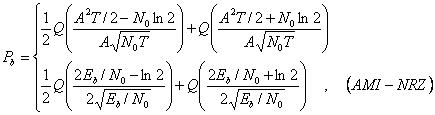 (2.57)
(2.57)
и
, (2.58)
который является одинаковым и для АМI-NRZ
в областях ![]() .
.
Так как восстановление NRZ-L из кодов АМI достигнуто путем исправления простой полной волной, вероятность ошибки конечного восстановления, последовательности данных остается неизменной.
Decodes и коды АМI связаны дифференциальным кодированием. Как описано в
параграфе 2.2.3, последовательность данных ![]() восстановлена от
восстановлена от ![]() ,
использованием сложения по модулю 2
,
использованием сложения по модулю 2 ![]() , где
, где ![]() - униполярная
последовательность, восстановленная от decode
- униполярная
последовательность, восстановленная от decode ![]() ,исправлением
полной волны.
,исправлением
полной волны.
Pb последовательности ![]() ,
такая же, как и у АМI, и – оно также одинаково и для
,
такая же, как и у АМI, и – оно также одинаково и для ![]() .
.![]() является неверным ,
когда любой
является неверным ,
когда любой ![]() или
или
![]() неверен.
Это похожая ситуация, которую мы рассматривали в параграфе 2.4.1
для NRZ-М. или NRZ-S . Используя (2.58), мы имеем
неверен.
Это похожая ситуация, которую мы рассматривали в параграфе 2.4.1
для NRZ-М. или NRZ-S . Используя (2.58), мы имеем
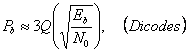 (2.59)
(2.59)
которая изображена на рисунке 2.8.
2.4.3 BER Двухфазных Кодов
Вi-Ф-L (Manchester) сигналы – антиподально двоичные с
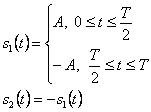 (2.60)
(2.60)
Bi-Ф-L сигналы могут быть обнаружены, используя оптимальный приемник, изображенный на рисунке 2.7. Коэффициент корреляции между ними - p 12=-1. Энергии сигнала
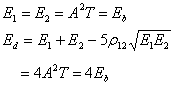
Таким образом, вероятность ошибки бита
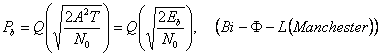 , (2.61)
, (2.61)
который является таким же, и для NRZ-L. Это неудивительно, так как они имеют одинаковую энергию бита, и оба являются антиподальными.
Обусловленный Вi-Ф-L имеет вероятность ошибки приблизительно в два раза больше, чем это Вi-Ф-L ,так как это только дифференциально-кодированный Вi-Ф-L.
Из этого можно сказать, что обусловленный Bi-Ф-L имеет такой же BER, как и NRZ-М или S.
Bi-Ф-M иBi-Ф-S имеет одинаковую вероятность ошибки. Так что это позволяет нам рассмотреть Bi-Ф-M. Есть четыре сигнала в Bi-Ф-M:
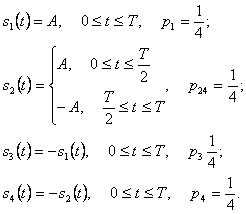
Каждый из них имеет энергию ![]() . Так что средняя
энергия бита остается такой же. Мы можем выбрать
. Так что средняя
энергия бита остается такой же. Мы можем выбрать ![]() как основную функцию. Таким
образом, из (2.53) мы имеем
как основную функцию. Таким
образом, из (2.53) мы имеем
![]()
где
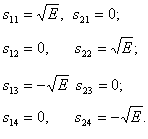
Правило решения состоит в том, чтобы
выбрать наибольший ![]() . До тех пор P,
является равными для всего j. Вышеупомянутым
правилом вычислением
. До тех пор P,
является равными для всего j. Вышеупомянутым
правилом вычислением
![]()
и выбираем минимум. Таким образом,
оптимальный приемник изображен, как показано на рисунке 2.10 (a), и область
решении будет двухмерной, как показано на рисунке 2.10 (b). Проблема
заключается в симметрии, этого достаточно для того, чтобы предположить, что S l (t) передан
и рассчитан результат ![]() , который равен среднему Pb. Мы также
можем видеть, что ответ был бы инвариантный с 45 градусным вращениям сигнала,
потому что шум является циркулярным симметрическим. Таким образом, мы можем
использовать простую диаграмму на рисунке 2.10 (c) для вычисления BER.
, который равен среднему Pb. Мы также
можем видеть, что ответ был бы инвариантный с 45 градусным вращениям сигнала,
потому что шум является циркулярным симметрическим. Таким образом, мы можем
использовать простую диаграмму на рисунке 2.10 (c) для вычисления BER.
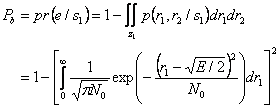
где двойной интеграл преобразован к упрощенному одномерному интегралу, потому что r 1 и r2- независимые идентичные Гауссовские переменные. Изменяя переменные, мы имеем
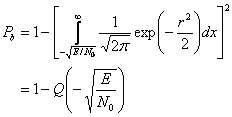
Рисунок 2.10 - Оптимальный приемник и области решении
сигналов Bi-Ф-M
 (2.62)
(2.62)
BER Bi-Ф-M идентичен этим униполярным кодам и на 3 децибела, хуже чем NRZ-L или полярный RZ. Этот BER изображен на рисунке 2.8.
2.4.4 BER модуляции задержки
Четыре сигнала символа в модуляции задержки такие же , как и Bi-Ф-М., и их распределение вероятности тоже одинаковы. Поэтому BER задержки модуляция – такое же ,как и у Bi-Ф-M
 (2.63)
(2.63)
Подобно Bi-Ф-M, BER модуляции задержки идентична этим униполярным кодам и на 3 децибела хуже, чем NRZ-L или полярный RZ.
2.5 Линейные коды замены
Код AM1 является наиболее подходящим для выбора из-за его многих преимуществ. Он имеет узкую полосу пропускания и не имеет dc компонента. Но имеет способность обнаруживать ошибки, из-за ее замены инверсии марки (alternate mark inversion). Возникновение последовательных положительных или отрицательных амплитуд указывает ошибки передачи и это называется биполярным нарушением. Синхронизация сделана более легкой, из-за переходов в каждом двоичном 1 бите.
Даже приоритетом том, что синхронизация кода AMI лучше, чем это правила у NRZ, это не является удовлетворяющим условием. Ряд 0-ей будет результатом длительного периода нулевого уровня, который будет причиной потери синхронизации. В системе Т1, устраняя все нулевые коды слово от 8 битного источника кодирования, максимальное число последовательных нулей ограничивается 14. Решением этому является то, что надо заменить блоком из N последовательных нолей со специальной последовательностью с намеренными биполярными нарушениями. Эти нарушения позволяют идентифицировать последовательность нулевой замены и заменить пространством (нулями) в конце получения линии. Плотность импульса - 1/N. Это улучшит восстановление синхронизации. Два распространенных кода замены нуля - это заменяющий двоичный N-ноль (BNZS) и коды высокой биполярной плотности n (HDBn).
2.5.1 Двоичные Коды Замены N-ноля
Коды BNZS были открыты Джонсоном в 1969 году. Это наиболее распространенные коды замены, которые заменяют ряд из N нулей в форме волны AMI со спектральной N бытовой формой волны с хотя бы одним биполярным нарушением. Все формы являются dc свободными и удерживают сбалансированную AMI, которая достигается выборкой замены последовательностей так, что условные последовательности несут равное количество положительного и отрицательного импульса.
Есть 2 вида кодов BNZS. Один называется немодальный код, в котором допускаются 2 заменяемые последовательности, и выбора между ними основание базируется исключительно на полярности расположенного перед нулевым, которые будут заменены.
Для баланса, последовательности замены для немодальных кодов должны содержать равное число положительного и отрицательного импульса. Они также могут содержать ноли, и общее количество нолей может быть нечетным. Последний импульс в последовательностях замены должен иметь ту же самую полярность, как импульс предыдущий последовательность. Если эта особенность не выполнена, униполярный образец, состоящий из одного N нулей, из одного N нули, и так далее, был бы преобразован в последовательности, состоящие из «+» для заменяемой последовательности, другой + (по закону чередующейся полярности), такой же заменяемой полярности и так далее. Так как заменяемая последовательность является сбалансированным сигналом, то будет, имеет компонент dc. Последовательность двух импульсов противоположной полярности удовлетворяет вышеупомянутым требованиям. Однако оно будет включать не биполярные нарушения, с помощью которых оно может быть опознано в конце получения, так что необходимо добавить другие два импульса. Таким образом, для немодальных кодов N должен быть, по крайней мере, 4. Таблица 2.2 показывает некоторые практические немодальные коды: B6ZS и B8ZS. Все они сбалансированные, и последний импульс тот же самый, как предыдущий пульс.
Другой заменяемый код называется модальным кодом, в котором определены больше, чем две заменяемые последовательности обеспечены, и выборка последовательности базируется на том, что полярности типично расположенного перед нулевым должна быть заменена так же, как предыдущая заменяющая использованную последовательность. Для модальных кодов, N может быть два или три. Модальный код заменяемых последовательностей необязательно должен быть сбалансированным, и баланс достигается чередованием последовательностей. Чтобы проиллюстрировать это, обращаем Ваше внимание на таблицу 2.2, где B3ZS является модальным кодом (также см. рисунок 2.11). Пусть B представляет нормальный биполярный код, который подчиняется закону AMI, V представляет биполярное нарушение, а 0 представляет отсутствие импульса. Тогда в B3ZS коде блок 000 заменен BOV или OOV. Выбор BOV или OOV сделан так, чтобы число B импульса между двумя последовательным V импульсами было нечетно. Таким образом, если мы рассматриваем вклад в компонент dc долей сигнала, начиная с последней замены, то будет два "дополнительных" импульса, которые вносят вклад в dc компонент из-за биполярного нарушения.
Однако полярность этих двух импульсов будет чередоваться, так как это зависит от полярности предыдущего импульса и от различных B импульсов, так как последняя замена нечетна. Все эти условия выполняются с одинаковой вероятностью в случайной последовательности. Поэтому долгое время их "дополнительный" импульсы будут отменят друг друга так, чтобы у них не было никакого компонента dc.
B3ZS и B6ZS определены для DS-3 и DS-2 Североамериканских стандартных норм, соответственно, и B8ZS определен, как альтернатива к AMI для норм DS-1 и DS-1С. На рисунке 2.11 показаны примеры некоторых кодов замены.
Вычисление спектра кодов BNZS основывается на текущем графике импульса. Спектр, очевидно, зависит от использования заменяемой последовательности и статистических свойств последовательности данных. Для детального изучения обратитесь к [4]. Рисунок 2.12 показывает спектр некоторых кодов замены [4], где F/Fbit – частота нормализованной к норме бита Fbit.
Так как они обусловлены кодами AMI, мы можем догадаться, что их нормы ошибки бита в датчике должны быть очень близки к AMI кодам. Однако могут возникнуть больше ошибок из-за отказов признавать заменяемые последовательности в декодере.
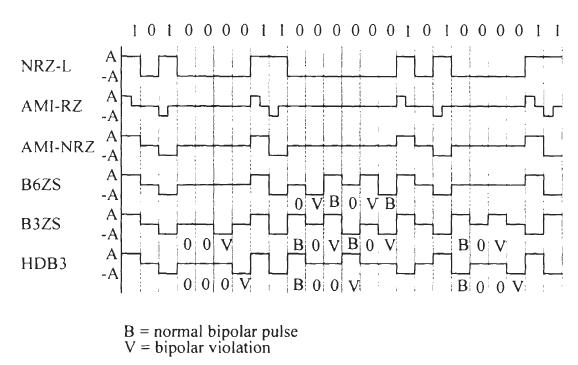
Рисунок 2.11 - Коды замены
2.5.2 Высокая Плотность Биполярных Кодов n
Кроизир предложил коды HDBn и код с совместимой высокой плотностью биполярного n (CHDBn) в 1970. CHDBn можно рассмотреть как улучшенная версия HDBn, с тех пор CHDBn кодирующие и декодирующие аппаратные средства ЭВМ несколько более просты.
Общая особенность этих двух кодов в том, что они ограничивают число последовательных 0-ей до n, заменяя (n+l)-ый 0 биполярным нарушением. Кроме того, чтобы избежать dc - компонент, они сделаны модальными, то есть, каждый из них имеет больше, чем одну возможную последовательность замены. Последовательности замены:

где опущенные биты - все ноли. Есть общее количество n нулей в каждой из последовательностей.
Выборы последовательностей должны быть таким, что число B импульсов между двумя последовательными V - импульсами всегда должно быть нечетным. Это может легко проверяется, как: полярность V импульс будет всегда чередоваться так, чтобы длинная последовательность не произвела фактически никакого dc - компонента.

Рисунок 2. I2 - PSDs некоторых кодексов замены
Два обычно используемых HDBn кодов - это HDB2 и HDB3. HDB2 идентичен B3ZS. HDB3 используется для того, чтобы кодировать мультиплексные 2.048 Mbps, 8.448 Mbps, и 34.368 Mbps в пределах европейской цифровой иерархии. Эти правила замены показаны в таблице 2,2(d). Пример HDB3 показывают на рисунке 2.11.
2.6 Блочные коды
Пока коды, которые мы обсуждали – бит за битом, в котором каждый входной бит был переведен постепенно в выходной бит. В блочных кодах входные биты, сгруппированы в блоки, и каждый блок переведен на другой блок символов. Цель использования блочных кодов - это введение избыточности, чтобы последовательно получать желанные свойства линейных кодов, как мы устанавливали в начале этой главы. Два основных метода, используемых в блочном кодировании - (I) вставка дополнительного двоичного импульса, чтобы создать блок TI двойных символов, который длиннее, чем количество информационных битов m., или (2) перевод блока входящих битов в блок выходных символов, которые используются больше, чем два уровня в символе. Первый метод главный, в основном используется в оптической передаче, где модуляция ограничена с двумя уровнями, но это относительно неприменимо к маленькому увеличению передаче, так как оптическое волокно имеет очень широкую полосу пропускания. Второй метод применим в случае, когда полоса пропускания ограничена, но возможна многоуровневая передача, типа металлических проводов, используемых для цифровых (subscriber loops) абонентских систем.
Все основные линейные коды, описанные в параграфе 2.2, могут быть рассмотрены как специальные случаи блочных кодов.
Есть некоторые технические разделы, которые должны быть рассмотрены прежде, чем мы опишем различные блочные коды. Некоторые из них также используются для не блочных кодов, но некоторые используется только для описания блочных кодов.
Цифровое суммирование (DC) цифровой последовательности определяется, как числовая сумма символов в последовательности. Цифровое суммирование также называют disparity (несоответствующим). Для подставления dc-компонент в кодирующую последовательность должна иметь нулевую цифровую сумму или неравенство. Поскольку во многих случаях DC уменьшается, так как последовательность становится более длинной, поэтому долгосрочный DC может являться нолем, даже при том, что краткосрочный DC, изменяется со временем. Важно знать, что максимальное изменение цифрового суммирования (DSV) ведет к dc wander. Когда последовательность имеет конечный DSV, говорят, что она сбалансирована, иначе несбалансированна.
Блочные коды, которые выбирают символы, больше чем один алфавит, называются алфавитными, иначе они являются не неалфавитными.
Эффективность кода определена как [21].
![]()
Например, NRZ коды кодируют 1 бит в 1 двоичной символ, эффективность, которой
![]()
AMI коды кодируют 1 бит в 1 троичный символ, эффективность, которой
![]()
Манчестерский код кодирует 1 бит в 2 двойных символа, эффективность
![]()
2.6.1 Coded Mark Inversion Codes (CMI)
Волокно - оптические системы связи используют модуляцию основной полосы частот, не полосу пропускания модуляция, так как передача символа представлена интенсивностью света из оптического источника, а именно: из лазерного диода. Даже притом, что AMI широко используется в цифровой системе или в паре кабельной системы, из-за его качества, описанного ранее, он не может быть использоваться в волоконно-оптических системах, так как оно использует три уровня, таким образом, из нелинейности лазерного диода. Многообещающим решением для, того чтобы избежать трудностью, является перемещение форм волны нулевого уровня AMI с двумя уровнями. Это ведет к двум уровням AMI кодам, включая схему закодированную инверсию марки (CMI) и включая в схему (DMI).
CMI был впервые предложен Takasaki в 1976
[6] для оптических систем волокна. CMI использует для
двоичных кодов А или –A, 1 для периода полного бита. Уровни А и -A чередуемый
для каждого возникновения 1. 0 представлен импульсом уровнем A
для первой половины бита и -A для второй половины бита, или наоборот. CMI может быть также рассматриваемый как 1 бит к кодированию 2
битов (1 B2B) с ![]() cчередованием
cчередованием ![]() только (или 0-, 10 только).
Пример CMI изображен на рисунке 2.13.
только (или 0-, 10 только).
Пример CMI изображен на рисунке 2.13.
CMI значительно улучшает плотность перехода. Это также имеет особенность обнаружения ошибки через контроль кодирования нарушения правила. Декодирование происходит сравниванием второй половины бита с первой половиной бита так, чтобы это было нечувствительно к аннулированиям полярности.
По сравнению с кодами AMI, скорость передачи в два раза больше скорости передачи двоичного выходного сигнала.
CMI выбран для мультиплексирования 139.246-Mbps в пределах европейской цифровой иерархии [20].
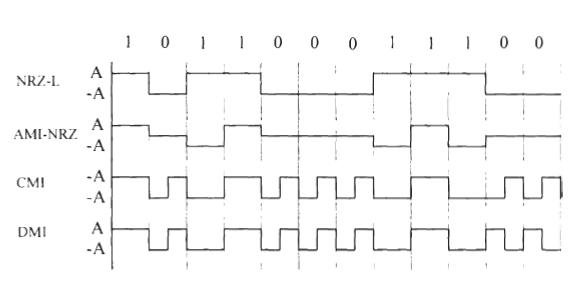
Рисунок 2.13 - CMI и DM1 формы волны
Формат сигнала CMI не может быть описан рисунком (2.11), так как он использует две формы волны (1, l) или (-1, l) для каждого бита. И при этом он не может быть описан Марковским процессом первого порядка, начиная с метки поочередно инвертирован, подразумевая, что текущее состояние бита может зависеть длительного состояния перед текущим. Поэтому его R (T) найден компьютерным моделированием Монте Карло, как показано на рисунке 2.14 (a). Также показан, что R (r) (рисунок 2.14 (b)) найден, приближая CMI к Марковскому процессу первого порядка, который является приблизительно равным к моделируемому сигналу. Моделируемый R (T) может быть разделен на две части, как показано на рисунке 2.14 (c, d), где (d) является периодическим. Используя преобразование Фурье из (c) и (d), аналитически PSD выражается как
 ,
(2.64)
,
(2.64)
который показан на рисунке 2.14 (e), где
А=1 для единой средней энергии бита. Периодическая часть
R (r) проявляется как ряд импульсов в нечетном множестве Нормы данных в
спектре. Внезапное снижение кривой Pob(B) происходит из-за импульса f=Rb в PSD.
Полосы пропускания ![]() и
и
![]() .
.
Обратите внимание, что вышеупомянутый
спектр CMI рассчитан двумя уровнями ![]() , это кодовая форма волны биполярна. Для
оптической передачи эти два уровня были бы А и 0, то есть кодовая форма волны униполярная. Это
изменение уровня не будет изменят R(T), рисунок (c) непериодическая
часть моделируемого R(T),(d) периодическая часть моделируемого R(T)
(e), PSD (f)
мощность за пределами полосы пропускания спектральной формы , но вынуждает спектр иметь dc
компонент, который может быть представлен
, это кодовая форма волны биполярна. Для
оптической передачи эти два уровня были бы А и 0, то есть кодовая форма волны униполярная. Это
изменение уровня не будет изменят R(T), рисунок (c) непериодическая
часть моделируемого R(T),(d) периодическая часть моделируемого R(T)
(e), PSD (f)
мощность за пределами полосы пропускания спектральной формы , но вынуждает спектр иметь dc
компонент, который может быть представлен ![]() , и непрерывная часть
должна быть умножена на 1/2.
, и непрерывная часть
должна быть умножена на 1/2.
Нулевая полоса пропускания ![]() . Энергия в
пределах полосы пропускания Rb – это 79.1%: и выше
сказанное Rb -
99.7 % из-за скачка, вызванного 0. l0l 6 (f) в f = Rb. Поэтому
. Энергия в
пределах полосы пропускания Rb – это 79.1%: и выше
сказанное Rb -
99.7 % из-за скачка, вызванного 0. l0l 6 (f) в f = Rb. Поэтому ![]() and
and ![]() не может быть найден.
не может быть найден.
Мы вычисляем BER CMI для биполярного случая, который может использоваться в металлических телеграфируемых (wired) системах. Мы обсудим униполярный случай для оптических систем, где первоначальное использование CMI. В биполярном случае, CMI - троичный сигнал с
 (2.65)
(2.65)
Все
три сигнала имеют одинаковую энергию: ![]() . s2(t) ортогонален к sl(t) И s3(t).
Так что мы можем выбрать
. s2(t) ортогонален к sl(t) И s3(t).
Так что мы можем выбрать ![]() как основанную функцию.
Третий сигнал
как основанную функцию.
Третий сигнал ![]() .
.
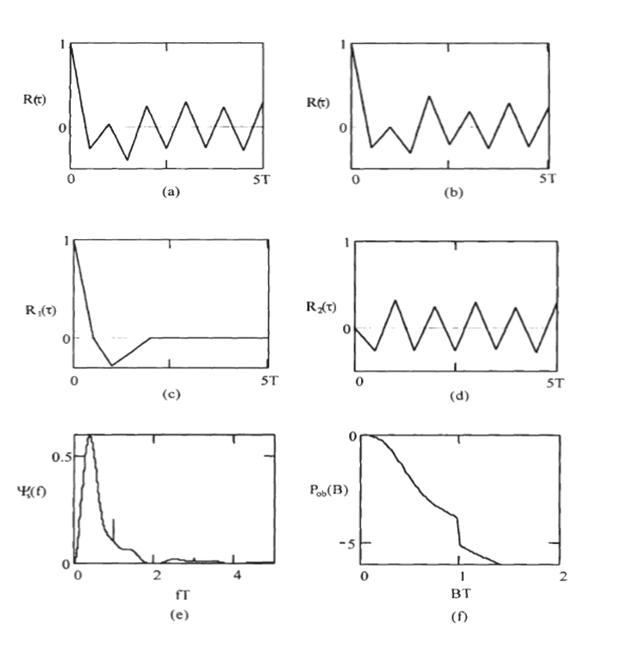
Рисунок 2.14 - Корреляция и спектр CMI: (a) моделированная R (T);
(b) – приблизительная
Таким образом, от (2.53) мы имеем
![]()
где
Таким образом, область решения является двухмерной, как показано на рисунке 2.15. Правило решения состоит в том, чтобы выбрать наибольший. Для того чтобы l1 был наибольшим мы должны иметь l1> l2 и l1> l от этих отношений, мы можем вывести ,что
![]()
где
![]()
подобно мы можем вывести
![]()
Рисунок 2.15 - Область решения CMI
![]()
Таким образом, есть три границы решений, как показано на рисунке 2.15. Оптимальный приемник состоит из двух корреляторов для вычисления r1 и r2 (см. рисунок 2.10 (a)).
Средняя вероятность ошибки бита
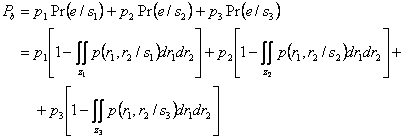
Из-за геометрической симметрии областей решения Z1 и Z3 и факта, что p1 = p2, мы имеем

Объединяя и опуская детали, Pb найдено как
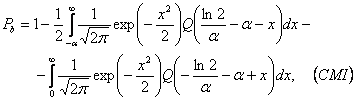 (2.66)
(2.66)
где
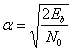
Если мы пренебрегаем граничными смещениями для высокой SNR, и устанавливаем границы, как средние линии между сигналами, тогда мы можем получить приблизительный Pb, заменяя ln2 на 0, в вышеупомянутом выражении:
 (2.67)
(2.67)
Кроме того, если мы пренебрегаем вероятностью ошибок между sl и s3, тогда рассчитывается только вероятность ошибки между s1 и s2 или s3 и s2.
Таким образом, Pb может быть приблизительно найден, как
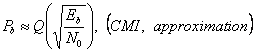 , (2.68)
, (2.68)
который является одинаковым и для униполярных кодов. Выражения (2.66) и (2.67) – оценивается в цифровой форме. Они изображены на рисунке 2.8 под тем же названием, что и коды AM1, так как они практически неразличимы.
Для оптической передачи уровень -A в CMI наборе сигнала будет 0. Не только импульс, униполярный, но также и много других факторов, которые нужно рассмотреть непосредственно для оптических систем и вычислить BER. Для того чтобы требуемая мощность p0 была желаемая, нужно изучить норму ошибки в [22] для прямых двойных форматов (униполярный NRZ-L). Оно может быть выражено как
![]() (2.69)
(2.69)
где

и где
E = постоянная, которая зависит от нормы ошибки и нормы бита;
Z = входящий тепловой шумовой;
Ii= shot noise contribution, который вызван оптическим импульсом в i-oм времени (i = 0 соответствует щели времени);
C = общее количество shot noise contribution;
x = дополнительный шумовой фактор для APD (фотодиод лавины).
Takasaki [6] показал, что небольшая модификация вышеупомянутых выражений обеспечивает требуемую оптическую мощность для других форматов импульса, включая CMI и DMI. Для CMI и DM1 следующие замены в (2.69) обеспечат требуемую оптическую мощность для прямой передачи
 (2.70)
(2.70)
BER, обнаруженный краем (edge-detected) CMI, передача данных по AWGN каналу [23] как
![]()
где B - эквивалентная шумовая полоса пропускания низкочастотного фильтра приемника.
2.6.2 Differential Mode Inversion Codes
DMI - это AMI
схема с двумя уровнями, предложенная Takasaki в 1976 [6] для
оптических волоконных систем. Его правило кодирования для двоичных единиц, такое
же, как и для CMI. Правило кодирования для двоичных нолей отличается: ![]() так, чтобы никакой
импульс в последовательности не имел ширину импульса шире, чем продолжительность
T. Пример DMI показан
на рисунке 2.13. Для оптических применений, код DMI униполярен. Если DMI используется для металлического применения, его можно
сделать биполярным.
так, чтобы никакой
импульс в последовательности не имел ширину импульса шире, чем продолжительность
T. Пример DMI показан
на рисунке 2.13. Для оптических применений, код DMI униполярен. Если DMI используется для металлического применения, его можно
сделать биполярным.
PSD униполярного DMI был найден, с помощью использования кодового метода графа потока Yoshikai в 1986 году как
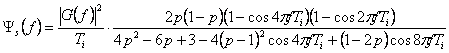
где Г(f) – преобразование Фурье из формы волны импульса линии, которое имеет ширину T = T/2 и p - вероятность возникновения метки. Для равновероятных данных последовательность p=0.5, вышеупомянутое выражение уменьшает до
![]()
Для прямоугольного импульса (NRZ пульс) с амплитудой A, оно выражается как
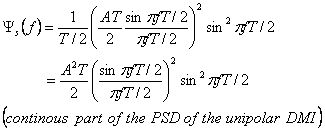 (2.71)
(2.71)
Энергия под кривой PSD - только половина энергии бита. Это говорит о том, что вышеупомянутое PSD выражение - непрерывная часть PSD униполярного DMI.
Другая половина энергии находится в
компоненте dc, который может быть представлен дельтой функции ![]() .
Он имеет первый ноль
.
Он имеет первый ноль ![]() . Полосы пропускания
. Полосы пропускания ![]() .
.
![]() and
and ![]() .
.
Когда DMI биполярен, тогда выражение (2.71) должно быть умножено
на фактор 2, чтобы представить полный PSD. В этом случае его PSD
имеет ту же самую форму PSD двухфазных
кодексов (2.41). Он имеет первый ноль в fT=2. Полосы
пропускания ![]() ,
,
![]() and
and ![]() .
.
Неудивительно, что PSD биполярного DMI является таким же, как у двухфазных кодов. Фактически биполярный DMI такой же, как и Bi-Ф-S код, даже притом, что их правила кодирования различны. Можно легко контролировать эти требования, просто кодируя простую последовательность, используя их правила. DMI также называется кодом изменения частоты (FSC) в бумаге Моррисом [24], где также представлены другие простые коды для оптической передачи.
Так как биполярный код DMI равен коду Bi-Ф-S, мы можем обнаружить его использование на рисунке 2.10 (a) и использование (2.62) его для BER вычисления. Для униполярного DMI, который используется, прежде всего, в оптических системах, мы можем использовать (2.69) и (2.70), чтобы вычислить требуемую оптическую мощность для данной BER и нормы бита.
2.6.3 mBnB коды
CMI и DM1 может интерпретироваться как два специальных случая большего семейства блочных кодов, названные mBnB кодами. Коды mBnB преобразовывают m двоичных цифр в n двоичных цифр с m <n. CMI и DM1 – это коды 1B2B. Двухфазные коды - также 1B2B коды.
Когда n=m+1, коды - mB(m+l)B коды, которые являются распространенными в высоко скоростной волокно оптической передаче. Помимо CMI, DM1 и двухфазных кодов, которые принадлежат к этому классу, есть другой mB(m+l)B код. CMI и DM1 имеют низкую эффективность. CMI и DM1 кодируют логику 1 в двоичный символ и логику 0 в два двоичных символа; эффективность выражена как

Чтобы увеличивать эффективность, должен быть выбран найбольший m.
2.6.3.1 Код Carter
Carter предложил в 1965 году для PCM системам [5]. Это - mB (m+l)B код. Далее следуют правила кодирования. Восьмеричная характеристика PCM канала передается с одним из двух изменении или с цифровой инверсией (то есть метка для пробела и пробел для метки), в зависимости от того, какое состояние уменьшит полное неравенство в начале передачи. Таким образом, не будет никого непрерывно увеличивающегося неравенства, и компонент dc будет нулевым в течение длительного периода, полярность которого дает эту информацию. Таким образом, код Картера является - 8B9B кодом. Его эффективность - 94.64%. Отсюда следует, что этот код может также применить для характеристики любой длины. Чтобы применять его к результату, не имеющему никакую структурную характеристику, надо определить "характеристику " или блоки.
С помощью кодов Картера полностью изменены неограниченных двоичных входных цифр. Это условие не всегда выполнимо для кодов AMI, так как синхронизация будет потеряна, если там будет присутствовать длинные ряды нолей или меток. Однако коды замены, предложенные позже (1969 г.) [4], описанные в параграфе 2.5, может также преодолеть проблему АМI.
Таблица 2.3 - Количество кодовых слов с различными значениями
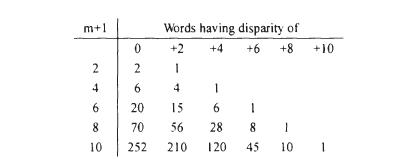
2.6.3.2 Grifiths код.
Этот код – один из разновидностей mB(m+l)B
кодов. Он был предложен Грифитом в (1969) [25] как усовершенствование кода Картера, в которой ряд
подобных цифр длины 2m+2 могут,
происходит из блока длинной m. Грифит проверил возможное число подобных слов с
различными длинами и различиями. Если m
нечетен, то количество слов с
нулевыми неровностями длинны 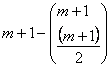 число слов, имеющих положительное
–неравенство – это
число слов, имеющих положительное
–неравенство – это  .
Они одинаковы и для отрицательного неравенства. Если слово с противоположным
неравенством соединено для передачи дополнительных слов, они будут общими
.
Они одинаковы и для отрицательного неравенства. Если слово с противоположным
неравенством соединено для передачи дополнительных слов, они будут общими  словами и достаточными
парами. Этого достаточно для того, чтобы первести блок из m
двоичных цифр, оставляя
словами и достаточными
парами. Этого достаточно для того, чтобы первести блок из m
двоичных цифр, оставляя 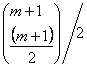 кодовых слов.
кодовых слов.
Число кодовых слов для первых нескольких выражений m приведены в таблице 2.3.
Для m+1 соответствуют два слова, это два слова нулевого (то есть, 0 и 1 могут быть переведены в 0 1 и 10). Это фактически Манчестерский код, норма бита, удвоена после кодирования.
Особое внимание отведено случаю, в котором m+1 равен четырем и шести словам. В обоих случаях перевод, может быть, достигнут с помощью использования слов с нулевым неравенством и слов с двоичным неравенством. Для m+1=6 (т.е. код 5B6B) мы можем использовать все слова с нулевым не равенством, и только те двойные неравенства, которые не имеют четыре одинаковых цифр. Правило кодирования показано на таблице 2.4. Для блока из пяти цифр содержит две передачи следующие друг за другом. Блок, содержащий три цифры, передача сопровождается нулем. Двадцать из возможных 32 блоков могут быть переданы этим путем, т.е. с нулевым неравенством. Остающиеся 12 блоков передаются, с помощью слов с двойным неравенством, в противном случае, слова с двойном неравенством посылаются инвертированными. Слова с противоположными признаками посылаются альтернативно. Таким образом, dc компонент линейного сигнала будет нулевым.
Таблица 2.4. - Таблица переводов для кода Грифета 5B6B
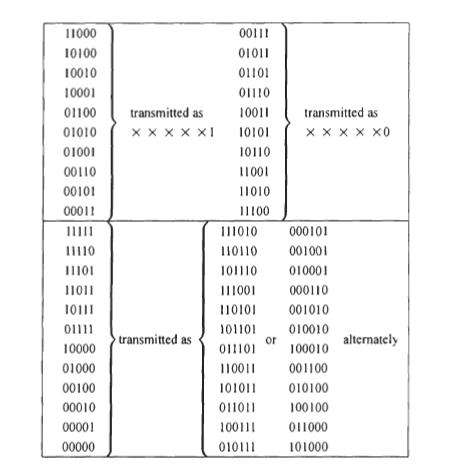
Этот код никогда не имеет больше, чем шесть последовательных цифр одинаковых типов. Норма увеличивается только на 20%.
Использования этого метода для кодирования блока из трех битов и набор подходящих правил перевода показаны в таблице 2.5. Увеличение нормы передачи 33%, это выше, чем код Грифета 5B6B. Аналогично семь битов могут кодироваться в восемь. Однако использование слов с квадратурным неравенством должно было бы обеспечить достаточные переводы. В общем, использование кодера высшего порядка будет излишним.
2.6.3.3 Код РАМ-PPM
Этот код был предложен Босотти и Пирани (1978)
[26]. Для оптических коммуникаций. Кодирование бита 00, 10 и 01 были
отображены в сигналах a, b и c аналогично положительным импульсом для
продолжительности ![]() и
ноль соответственно нулевому уровню для
и
ноль соответственно нулевому уровню для ![]() . Каждый из них, это так
называемые, импульсно-амплитудные и импульсно – position
модулированные сигналы.
. Каждый из них, это так
называемые, импульсно-амплитудные и импульсно – position
модулированные сигналы.
Таблица 2.5 - Таблица переводов для кода
Грифета 3U4B 
Правила кодирования показаны в таблице 2.6. Это фактически код 3B4B с 0 и 1 в кодовых словах, занимающих различные длины.
PSD этого кода с θ= ½ имеет первый ноль в f=2Rb и, который является одинаковым и для прямого РАМ сигнала, с шириной импульса T/2. Однако из PSD следует, что уменьшены компоненты низкой частоты. Исправленный импульс РАМ-PPM содержит обильный компонент синхронизации частоты. Самый длинный временной интервал без изменения уровня сигнала – это 3T.
2.6.3.4 2B3B dc-Constrained Code
Этот код был предложен Tакасаки (1976) [6]. Обычные коды пытаются подавить компонент dc. Об этом подробно рассказывается в [27], где коды не могут обеспечить способность контролировать ошибки, так как они израсходовали большинство избыточности в подавлении компонента dc. 2B3B dc-Constrained Code используют различные подходы. Это ограничивает компонент dc вместо того, чтобы подавлять его, и, таким образом, позволяет использовать избыточность для обнаружения ошибки. В таблице 2.7 показано правило перевода. Данные бита 1 и 0 преобразованы к + и- соответственно. Тогда третий символ + или - добавляется, чтобы сделать комбинации из одного + и двух - (способ I). Пара данных 11 может не соответствовать этим требованиям. Поэтому способы 1 и 2 используются поочередно для этой пары, чтобы произвести один + и два - в среднем. Этот код производит компонент dc из - l 3. Однако он не страдает от dc, так как компонент dc постоянен независимо от образца данных. В интервалах синхронизации информации, среднее число изменений уровней в блок располагается от 1 до 2. Самая длинная последовательность - уровни 7.
2.6.4 Коды m B1C
Этот код принадлежит классу кодов названных кодами вставки бита, которые являются популярными в быстродействующей оптической передаче.
Таблица 2.6 - код РАМ-PPM

Таблица 2.7 - 2B3B dc-Constrained Code

Код mB1C был предложен Yoshikai для волоконно-оптической передачи в 1984, чтобы поднять ограничение скорости, достигнутое на CMI, DMI, и коде mBnB. В процессе кодирования, скорость входного сигнала увеличена на (m+1)/m, тогда дополнительный бит вставляется в конце каждого блока m информационных битов. Вставленный бит, дополнителен к последнему биту m информационных битов. Правило кодирования очень простое, поэтому с помощью кодов mBnB можно избежать сложных электронных схем. Увеличение в кодовой норме является меньшим, только 1/m когда по сравнению с CMI и DMI, которые требуют кодовой нормы дважды быстрее скорости информационной нормы.
С mB1C кодируют максимальное число последовательных идентичных символов m + 1, которые происходят, когда вставленный бит и m последующих битов одинаковые. In-service ошибка может быть проверена, используя XOR, прикладной к последнему информационному биту и дополнительному биту. Этот код был принят в Японии 400 Mbps оптическими системами в форме 10В1С.
Спектр этого кода содержит непрерывную часть и дискретные компоненты. Если норма метки в информационной последовательности - 1/2, существует только компонент dc.
dc - компонент существует вследствие того, что код униполярен. Если норма метки отклоняется на 1/2, то РSD содержит гармонические спектры с оснсвным компонентом l/(m+1)T. Гармонические спектры вызваны фактом, что, когда норма метки - не 1/2, вероятность возникновения для метки в С бите - также не 1/2; вместо этого оно - обратно пропорционально информационному биту. Гармонические спектры вызывают колебание. Шифратор может использоваться, чтобы зашифровать передачу МБ IC, закодированная последовательность, следовательно, подавляет гармоники.
2.6.5 Коды DmB1М.
Drfferrntial m binary with I mark insertion (DmBIM), код предложен Kawanishi и Yoshikai (1988) для очень быстродействующей оптической передачи. Правило кодирования довольно простое. В процессе кодирования скорость входного сигнала (P) увеличена (m+l)/m, затем метка бита вставляется в конце каждого блока m информационных битов. Вставленный меткой сигнал (Q) преобразован в DmBlМ код (S), с помощью следующего дифференциального уравнения:
![]()
где Sk и Qk
обозначают k-ый бит сигнала S и Q, соответственно. Символ ![]() обозначает
XOR. Бит C (дополнительный бит) произведен автоматически
в процессе кодирования. Это может быть замечено следующим образом (вставленный
бит Q + всегда равен 1):
обозначает
XOR. Бит C (дополнительный бит) произведен автоматически
в процессе кодирования. Это может быть замечено следующим образом (вставленный
бит Q + всегда равен 1):
![]()
То есть (m+1)-ый бит всегда дополнителен к m-ному биту. Так S-последовательность является кодом mВ1С. Декодирование достигнуто уравнением
![]()
и первоначальный сигнал P тогда восстановлен через удаление метки и преобразовании скорости m/( m +1).
Подобно коду mВ1С, DmB1М ограничивает максимальную длину последовательных идентичных цифры до (m+1) и обеспечивает обнаружение ошибки через контроль каждого (m+1) восстановленного бита. В отличие от mBlC, вероятность метки кодированной последовательности всегда 1/2 независимо от вероятности метки информационной последовательности [9]. Таким образом, нет дискретной гармоники вызывающей колебание в спектр, кроме компонента dc.
Когда m является маленькой, непрерывная часть спектров кода mBlC и кода DmB1М подобна АМI коду, который обеспечивает подавление высокочастотных и низкочастотных компонентов. С увеличением длины блока m спектр сглаживается и принимает форму спектра случайного сигнала, имеющего компоненты, отличные от нуля, около нулевой частоты. Проблема контроля спектра в коде mВ(m+l), B может быть решена с помощью добавляя дальнейшего кодирования [10] или c использованием метода scrambling [11]. И код PFmB(m+l)B может преодолеть проблему спектра до некоторой степени.
2.6.6 Код PFmB(m+l)B
Это частично код flipped или PFmB (m+I)B код, который был предложен Krzymien (1989) [10]. Он сбалансировано, с минимальным увеличением нормы (1/m), и его легко кодировать и декодировать. Таким образом, он является подходящим для быстродействующих оптических систем.
Процесс кодирования PFmB(m+l)B кода состоит из двух стадий: предкодирование и сбалансированное кодирование. В предкодировании организуют входную двоичную последовательность {Bi} сгруппированиe. И блоки m битов (m нечетное число), к которому добавляется дополнительный бит Bm+1, согласно правилу
 (2.72)
(2.72)
Добавленный бит будет служить в качестве проверочного бита в декодировании.
Во второй стадии, предкодированные входные слова B=[ B1,B2 .., Bm+1] внесены в двоичные ключевые слова C = [С1,С2 ,…Сm+1 ] cогласно правилу
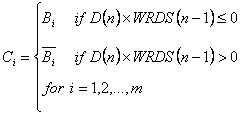 (2.73)
(2.73)
и
![]()
где
![]() является дополнением Bi.
является дополнением Bi.
D (n) - неравенство n-ного предкодированного слова Bn, которое определен значением - 0.5 двоичного ноля и 0.5 двоичной единицы, и затем суммируем их.
WRDS (n-1) - выражение running цифровой суммы (полное неравенство) в конце (n -1) – го предкодированного слово Bn-1
![]()
Из формулы (2.73) мы имеем следующие наблюдения. Если полное неравенство и неравенство потока предкодированного слова, имеют одинаковые признаки, то предкодированное слово B partially flipped, только оставляя последний бит неизменным, потому что оно будет служить проверочным битом в декодировании. Иначе предкодированное слово B скопировано в C без изменения. Это балансирует полное неравенство или running цифровой суммы.
Синхронизация блока в приемнике достигнута
с помощью проверки полученной кодированной последовательности ![]() , которая
удовлетворяет правилу кодирования (2.72) и (2.73). Высокая норма из кодовых
нарушений правила определяется тем, что система - вне синхронизма. После блока
синхронизм установлен, декодирование выполнено, с помощью проверки полученного
блок против кодового правила (2.72) (правления (2.72) с замененной Bi на
, которая
удовлетворяет правилу кодирования (2.72) и (2.73). Высокая норма из кодовых
нарушений правила определяется тем, что система - вне синхронизма. После блока
синхронизм установлен, декодирование выполнено, с помощью проверки полученного
блок против кодового правила (2.72) (правления (2.72) с замененной Bi на ![]() ). Если (2.72) удовлетворяется,
инверсия из битов
). Если (2.72) удовлетворяется,
инверсия из битов ![]() является
необходимой. Иначе биты
является
необходимой. Иначе биты ![]() должны
быть инвертированы, чтобы уступить B.
должны
быть инвертированы, чтобы уступить B.
Есть случаи расширения ошибки в декодировании кода PFmB(м+l)B. Однако это расширение является очень маленьким. Пример, данный в [10], ухудшается на 0.3 децибела SNR для m = 7, приблизительная вероятность 10-9 в AWGN канале. Изменение цифровой суммы (DSV) ограничено (3m-1)/2. Максимальное число последовательных битов также ограничено - 2 (m+1). Спектр кода имеет roll-off r нулю в нулевой частоте и f =Rb. Однако, когда входная вероятность данных эти неуравновешенные острые пики появляются на обеих границах полосы. Это неудобство могут быть устранены с помощью scrambling.
2.6.7 kBnT коды
Класс кодов, использующих три уровня, называется кодами kBnT, где k двоичных битов кодированы в n (n<k) троичных символов. AM1можно рассмотреть, как код 1B1T. Наиболее важные коды этого класса - 4B3T и 6B4T. Их эффективность составляет 84,12% и 94.64 %. Соответственно
Таблица 2.8 - Таблица переводов для 4B3T

2.6.7.1 Код 4B3T
Код, предложенный Waters [21], наиболее простой из класса 4B3T. Таблица переводов, показанная в таблице 2.8, где рассчитаны различия путем назначения веса из 1 к положительной метке и вес-1 к отрицательной метке. Это алфавитный код, который используют, начиная с двух алфавитов.
Есть 27(33) возможных комбинации трех троичных цифр. Чтобы поддерживать независимость последовательности бита, 000 не используется. Все другие комбинации используются. Мы может разместить шесть двоичных блоков на четыре бита к шести нулевым словам неравенства. Оставшиеся десять размещены и положительное слово неравенства и его отрицательная инверсия неравенства. В течение перевода счет сохранен из полного неравенства. Когда оно отрицательно, для передачи отобрано положительное слова неравенства и наоборот. Это обеспечивает то, что переданный код имеет нулевое содержание dc. Неравенство ограничено, и в конце слово возможно только шесть выражений полного неравенства (-3,-2,-2, 0, 1 и 2, где «0» рассчитан, как положительный). Полное неравенство +3 невозможно, несмотря на это неравенство, слова может быть +3, так как слово +3 неравенства, посылают только, когда полное неравенство отрицательное.
Таблица 2.9 - Таблица переводов для MS43
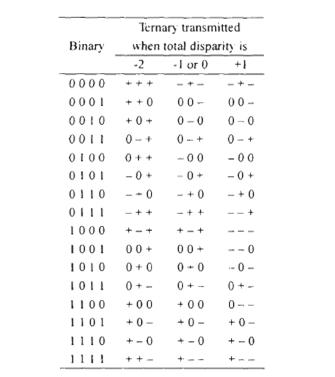
2.6.7.2 Код MS43
MS43 код, предложенный Franaszek (1968) [28], – также является кодом 4B3T. Он имеет более сложную таблицу перевода с тремя алфавитами, как показано в таблице 2.9.
Disparity слов располагаются от -3 до +3. Есть только четыре возможных общих состояния disparity в конце слова: -2, -1, 0 или 1. В состоянии -2 посылаются только ноль или положительные disparity слова; в состоянии +1, только нулевое или отрицательное disparity слово; и в состояних 0 или -1, только ноль и слова disparity единицы. Это распределение уменьшает содержание низкой частоты по сравнению с 4B3T, делая его более терпимым к ac coupling[29].
2.6.7.3 Код 6B4T
Этот код был предложен Catchpole в 1975 [30]. Таблица перевода показана в таблице 2.10. Она подобно
коду 4B3T, используется два алфавита с обоими нулями и слова disparity единицы, уникально размещенные 50 из 64 на возможных двоичных
шести - битных блоках. Disparity контроль достигнут, с помощью соединена ![]() и
и ![]() disparity
слов, размещенных на других 14 двоичных комбинациях.
disparity
слов, размещенных на других 14 двоичных комбинациях.
Таблица 2.10 - Таблицы Переводов для 6B4T

Этот код более эффективен, чем 4B3T код, но он имеет неограниченное полное disparity. Однако может показаться, что с практической величиной низкой частоты сокращаются в ретрансляторах, это незначительно затрагивает выполнение передачи, если шифратор scrambler используется.
2.7 Резюме
В этой главе мы сначала описали
методы дифференциального кодирования,
часто используемых в линейных кодах.
Тогда перед обсуждением различной линейных кодов, мы представили список
критерий линейного кодирования. Они включают синхронизацию информации,
спектральную характеристику, полосу пропускания, вероятность ошибки,
способность обнаружения ошибки, независимость последовательности и использование
дифференциального кодирования. В соответствии с этими критериями, мы
рассмотрим классически традиционные коды линии, включая NRZ, RZ, PT,
бифазную модуляцию задержки. Коды NRZ включая NRZ-L, NRZ-M и NRZ-S, NRZ-M и NRZ-S по
кодированные формы NRZ-L. Они являются самыми простыми условиями правил
кодирования, имеют узкую ширину полосы пропускания ![]() , но в них отсутствует
большинство желаемых характеристик. Все коды NRZ имеют
подобное BER с наименьший NRZ-L и NRZ-M и
сигналы высокой NRZ-S.
, но в них отсутствует
большинство желаемых характеристик. Все коды NRZ имеют
подобное BER с наименьший NRZ-L и NRZ-M и
сигналы высокой NRZ-S.
Коды RZ увеличивают плотность переходов, что хорошо влияет
хорошо для синхронизации, по их полосе пропускания удвоенная ![]() полярный RZ
имеет такой же BER, как в обе униполярный NRZ и униполярный
RZ имеют одинаковые BER, которые не
3дб ниже, чем NRZ-L. Спектр кодов NRZ и RZ
имеет большую энергию, близкую dc, которая не подходит для соединения.
полярный RZ
имеет такой же BER, как в обе униполярный NRZ и униполярный
RZ имеют одинаковые BER, которые не
3дб ниже, чем NRZ-L. Спектр кодов NRZ и RZ
имеет большую энергию, близкую dc, которая не подходит для соединения.
Коды РТ, включая AMI (NRZ и
RZ) и 2е коды (NRZ и RZ). Коды AMI
имеют узкую ширину полосы пропускания ![]() , и наиболее важным является то, что они
не имеют частотного компонентное dc и компоненты, близкие dc, тоже малы.
Это делает коды AMI удобными для сцепленных целей. Однако 3-х уровневая
передача сигнала кода AMI делает характеристику BER на 3дб ниже,
чем полярные коды NRZ. Двойные коды относятся к AMI
дифференциальным кодированием. Таким образом, они имеют одинаковый спектр, как
коды AMI и их, представляя BER также
близко, но чуть выше, чем у кодов AMI. Недостаток перехода в ряде о
кодах AMI и двойных кодов может вызвать проблемы в
синхронизации т.о., коды AMI нулевым были предложены для предотвращения этого
недостатка.
, и наиболее важным является то, что они
не имеют частотного компонентное dc и компоненты, близкие dc, тоже малы.
Это делает коды AMI удобными для сцепленных целей. Однако 3-х уровневая
передача сигнала кода AMI делает характеристику BER на 3дб ниже,
чем полярные коды NRZ. Двойные коды относятся к AMI
дифференциальным кодированием. Таким образом, они имеют одинаковый спектр, как
коды AMI и их, представляя BER также
близко, но чуть выше, чем у кодов AMI. Недостаток перехода в ряде о
кодах AMI и двойных кодов может вызвать проблемы в
синхронизации т.о., коды AMI нулевым были предложены для предотвращения этого
недостатка.
Бифазные коды включают Bi-Ф-L или
MANCHESTER Bi-Ф-М, Bi-Ф-S и обусловленный Манчестер. Все они имеют одинаковый
спектр, который имеет ![]() . Однако, спектральная форма лучше, чем RZ, тем,
что компоненты dc и близки устранены. В условиях BER, Manchester и обусловленный Manchester, подобные BER Манчестера идентичны BER и
NRZ-L. BER обусловленного Манчестера немного выше. Представления
BER Bi-Ф-М и Bi-Ф-S одинаковое,
которое на 3дб ниже, чем BER Манчестера. Бифазные коды всегда имеют, как правило,
один переход в символе, т.е. синхронизующая информация адекватна из-за его
достоинств. Манчестерский код, широко исполняя в особенности дифференциальной форме.
Из выше сказанного, мы видим, что кода AMI и Манчестер
установлены как 2 наиболее использующихся кода. Оба кода имеют маленькие
компоненты ближе dc. Код Манчестер лучше, чем код AMI в
условиях BER. Но коду AMI необходимо только половина
ширины полосы пропускания, требуемая кодом. Манчестер также дает лучшую
синхронную информацию, чем код AMI.
. Однако, спектральная форма лучше, чем RZ, тем,
что компоненты dc и близки устранены. В условиях BER, Manchester и обусловленный Manchester, подобные BER Манчестера идентичны BER и
NRZ-L. BER обусловленного Манчестера немного выше. Представления
BER Bi-Ф-М и Bi-Ф-S одинаковое,
которое на 3дб ниже, чем BER Манчестера. Бифазные коды всегда имеют, как правило,
один переход в символе, т.е. синхронизующая информация адекватна из-за его
достоинств. Манчестерский код, широко исполняя в особенности дифференциальной форме.
Из выше сказанного, мы видим, что кода AMI и Манчестер
установлены как 2 наиболее использующихся кода. Оба кода имеют маленькие
компоненты ближе dc. Код Манчестер лучше, чем код AMI в
условиях BER. Но коду AMI необходимо только половина
ширины полосы пропускания, требуемая кодом. Манчестер также дает лучшую
синхронную информацию, чем код AMI.
Модуляция задержки имеет очень узкую ширину полосы пропускания
с основанием ![]() .
Однако ее представление BER на 3дб хуже, чем представление NRZ-L. Ее
синхронизирующая информация не больше, чем в бифазных кодах, но больше, чем
другие коды могут обеспечить. Она является потенциальной конкурентом кода AMI и
кода Манчестер, несмотря на это, его практическое применение не описано в
литературе.
.
Однако ее представление BER на 3дб хуже, чем представление NRZ-L. Ее
синхронизирующая информация не больше, чем в бифазных кодах, но больше, чем
другие коды могут обеспечить. Она является потенциальной конкурентом кода AMI и
кода Манчестер, несмотря на это, его практическое применение не описано в
литературе.
В конце этого раздела мы рассмотрели более сложные коды, включая заменяемые коды и коды блокировании. Коды замены сформировали для подавления длинных рядов всех нулей. Два важных кода замены BNZS и HDB включая CHDB, были рассмотрены. Все они основаны на кодах AMI. Подавляя последовательные нули, были охвачены недостаток синхронизации первоначальной информации. Коды AMI, т.е. эти коды конкурентно - способные к коду Манчестер, особенно в полосе ограничительных системах.
Коды блокирования сформированы для
представления ввода желаемых характеристик их drawback, является увеличение в
скорости передачи. Они, широко используя в оптоволоконных системах передачи,
где доступна широкая полосы пропускания. Там есть огромное количество кодов
блокирования. Важные коды, которые используются в практических системах,
включают следующие коды: CMI и DMI, которые являются 2-х уровневыми кодами AMI,
сформированными для замены AMI в оптикофиберной системе. Основанным классом двойных
кодов блокировки, которые могут заменить AMI, является
коды. Для быстро скоростной оптической передачи, и увеличение должно быть
сохранено на минимуме, т.о., в классе предложены простые коды, как ![]() и DmB1M.
Все они добавляют только один лишний бит к исходному блоку бита, т.е. сохраняя
возрастание скорости на минимуме. Все они имеют простые правила кодирования и
декодирования, т.е. могут быть достигнуты высокие скорости передачи. Коды
блокирования неограниченны, сдвоенные многоуровневые коды блокирования могут
увеличить эффективность линейных кодов. Известные многоуровневые коды является кодами,
такими как 4B3T, Ms43, и 6B4T. Они сформированы для того, чтобы имеет нуль или
постоянный dc - компонент и ограниченное неравенство. Они не могут
быть использованы для оптической системы из-за многоуровневой передачи
сигнала.
и DmB1M.
Все они добавляют только один лишний бит к исходному блоку бита, т.е. сохраняя
возрастание скорости на минимуме. Все они имеют простые правила кодирования и
декодирования, т.е. могут быть достигнуты высокие скорости передачи. Коды
блокирования неограниченны, сдвоенные многоуровневые коды блокирования могут
увеличить эффективность линейных кодов. Известные многоуровневые коды является кодами,
такими как 4B3T, Ms43, и 6B4T. Они сформированы для того, чтобы имеет нуль или
постоянный dc - компонент и ограниченное неравенство. Они не могут
быть использованы для оптической системы из-за многоуровневой передачи
сигнала.
Список литературы
1. Aoron M.R., ”PCM transmission in the exchange plant.” Bell System Technical Journal. vol. 41. no. 99, January 1962.
2. Croisier A., “ Introduction to pseudotcrnary transmission codes.” IBM J. Res. Develop., July 1970, pp. 354-367.
3. Hecht M., and A. Duida, “Delay modulation.” Proc. IEEE. vol. 57. no 7. July 1969. pp. 1314-1316.
4. Johannes V.I., A.G. Kaim and T. Walzman, “Bipolar pulse transmission with zero extraction.”IEEE. Trans Comm. Tech. vol.17, 1969, p.303.
5. Carter R.O., “Low disparity binary coding system., ”Electron Lett. vol. 1 no 3. 1965. p. 67.
6. Takasaki Y. et al., “Optical pulse formats for fiber optic digital communications.” IEEE Trans Comm. vol.24, April 1976.pp.404-413.
7. Takasaki Y. et al., ”Two-level AMI line coding family for optic fiber systems. ”Int J. Electron.vol.55, July 1983.pp.121-131.
8. Yoshikai N., K. Katagiry and T. Ito. ”mBIC code and its performance in an optical communication system.” IEEE Trans Comm. vol.32.no 2. 1984. pp.163-168.
9. Kawanish. S et al.- Dm BIM code and its performance in a very high- speed optical transmission system.- IEEE Trans Comm. vol. 36. no 8, August 1988. pp 951- 956.
10. Krzymien. W. “Transmission performance analysis of a new class of line codes for optical fiber systems.” IEEE. Trans Comm. vol. 37 no 4. April 1989.pp 402- 404.
11. Fair. I.J. et al. ”Guided scrambler: a new line coding technique for high bit rate fiber optic transmission system.” IEEE Trans Comm. vol. 39. no 2, Feb1991, pp. 289-297.
12. Sklar B. Digital Communications. Fundamentals and Applications Englewood Cliffs. New Jersey. Prentice Hall,1988.
13. Killen H., Fiber optic digital communications. Fundamentals and Applications Englewood Cliffs. New Jersey. Prentice Hall, 1991.
14. Stallings W., “Digital signaling techniques,” IEEE Communications Magazine vol.22 no 12 Dec.1984, pp. 21-25.
15. Tsujii S., and H. Kasai.” An algebraic method of computing the power spectrum of coded pulse trains.” Electron Commune. Japan vol.51-A. no 7, 1968.
16. Yoshikai N.,” The effects of digital random errors on the DMI code power spectrum.” IEEE Trans Comm. vol. 34. July 1986, pp. 713-715.
17. Huggins W.H., “ Signal – flow graphs and random signals.” Proc IRE, vol. 45, January 1957, pp. 74-86.
18. Van Trees H.I., Deflection. Estimation and Modulation Theory Part I. New York. John Wiley&Sons.Inc.,1968.
19. Smith D.R., Digital - transmission system and ed. New York. Van No strand Reinhold.1993.
20. CCITI yellow book, vol. III 3 Digital Networks- Transmission systems and multiplexing equipment. Geneva. IT.1981.
21. Walers D.B. ”Line codes for metallic systems.” Int J. Electron vol. 55, July 1983, pp. 159-169.
22. Personick S.D., “Receiver design for digital fiber optic communication systems. I-II.” Bell Syst. Tech. J., vol.52, July-August 1973, pp. 843-886.
23. Chew Y.H. and T.T. Tjhing,” Bit error rate performance for edge-detected CMI data transmission.” IEEE. Trans Comm. vol. 41, June 1993, pp. 813-816.
24. Morris D.J., “Code your fiber-optic data for speed without losing circuit simplicity. ”Electronic Design, vol. 22, October 1978, pp.84-91.
25. Griffiths J.M., “Binary code suitable for line transmission.” Electronics Letters, vol.5. Feb. 1969, p. 79.
26. Bosotti L. and G. Pirani.,” A new signaling format for optic communications.” Electronics Letters, vol.14, no 3, 1978, pp. 71-73.
27. Takasaki Y. et al., ”Line coding plans for fiber optic communication systems.” Prod. Int. Conf. Commun. 1975, paper 32E.
28. Franszec P.A., “ Sequence state coding for digital data transmission.” Bell Syst. Tech. J. vol. 47, 1968, pp. 143-157.
29. Buchner J.B., “Ternary line codes. ”Philips Telecomm.Rev. vol.34, 1976, pp.72-86.
30. Catchpole R.J., “Efficient ternary transmission codes.” Electronics Letters, vol. 11, 1975, pp. 482-484.