МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РЕСПУБЛИКИ КАЗАХСТАН
Некоммерческое акционерное общество
«Алматинский университет энергетики и связи»
К. Х. Туманбаева, К. С. Асанова.
СИСТЕМЫ ШИРОКОПЛОСНОЙ И ГИБКОЙ КОММУТАЦИИ
Учебное пособие
Алматы 2010
УДК 621.395.31
ББК 31.27-01я73
Т83 Системы широкополосной и гибкой коммутации:
Учебное пособие/ К.С.Асанова, К.Х. Туманбаева;
АУЭС. Алматы, 2010. – 80с.
ISBN 9965-850-40-2
В учебном пособии рассматриваются системы пакетной и гибкой коммутации. В первой части учебного пособия представлены принципы построения коммутационного оборудования технологии АТМ, коммутаторы нокаутного типа, двухступенчатые коммутаторы АТМ с выходным буфером и групповой доставкой, отказоустойчивость коммутатора АТМ, характеристики трафика и требования к качеству обслуживания.
Учебное пособие предназначено для студентов, обучающихся по специальности 5В071900 – Радиотехника, электроника и телекоммуникации.
Табл. 2, ил. 45, библиогр. –37 названий.
ББК 31.27-01я73
РЕЦЕНЗЕНТ: КазНТУ, д-р. техн. наук, проф. К.С.Шоланов
АУЭС, канд. техн. наук, проф. Г. С.Казиева
Печатается по плану издания Министерство образования и науки Республики Казахстан на 2010г.
ISBN 9965-850-40-2
1.1 Коммутационное оборудование АТМ
Для ныне существующих вторичных сетей связи, а также для локальных и глобальных вычислительных сетей разработано большое количество различного типа коммутационных устройств. На построение коммутационных устройств для широкополосных сетей интегрального обслуживания существенное влияние оказывают два основных фактора: высокая скорость работы коммутатора, стохастический характер потоков ячеек АТМ, обслуживаемых коммутационной системой.
Кроме того, концепция АТМ с ячейками фиксированной длины и с ограниченными функциональными возможностями заголовка также оказывает значительное влияние на принципы построения коммутационных устройств. Основное внимание уделено транспортной подсистеме коммутатора, под которой понимается совокупность средств, ответственных за правильную транспортировку пакетов (ячеек) АТМ от входа до выхода коммутатора с требуемым качеством обслуживания. Перенос пакета АТМ внутри коммутатора от входа к выходу (коммутация) может сочетаться с концентрацией (мультиплексированием) или деконцентрацией (демультиплексированием) трафика пакетов АТМ. Таким образом, основными функциями коммутационного оборудования в широкополосных сетях интегрального обслуживания являются: коммутация, концентрация (мультиплексирование), деконцентрация (демультиплексирование).
Под термином "коммутация" будем понимать передачу (транспортирование) пакетов АТМ от входящего логического канала коммутатора к исходящему логическому каналу, требующую выбора нужного логического канала из множества исходящих логических каналов. При этом логический канал характеризуется: физическим входом или выходом, определяемым номером физического порта, логическим каналом физического порта, определяемым идентификатором виртуального канала и идентификатором виртуального пути.
Для обеспечения коммутации физический вход и идентификаторы входящего виртуального канала и входящего виртуального пути должны соотноситься с физическим выходом и идентификаторами исходящего виртуального канала и исходящего пути[1-5,16,17]:
Таким образом, в коммутационной системе АТМ должны быть реализованы две функции, которые можно условно сравнить с функциями, выполняемыми классическими коммутационными системами. Первую функцию можно сравнить с пространственной коммутацией. Второй функцией современных коммутаторов в цифровых сетях является обмен временными интервалами, т.е. временная коммутация.
Так как в коммутационных системах АТМ концепция заранее установленного временного интервала отсутствует, то при одновременном соревновании ячеек двух и более логических каналов за один временной интервал, естественно, возникает ситуация состязания. Она может быть решена путем организации очередей из пакетов АТМ. Поэтому организация и ведение очередей является второй важнейшей функцией коммутаторов АТМ. Если количество входов превышает количество выходов, то информация мультиплексируется в меньшее количество выходов.
В технологии АТМ разница между мультиплексированием и концентрацией достаточно условна. При использовании термина "концентрация" подчеркивается, что число выходов коммутационного устройства меньше числа входов. При использовании термина "мультиплексирование" акцент ставится на статистическое слияние потоков ячеек от различных пользователей в единый поток пакетов АТМ в цифровом тракте.
Если при пространственной коммутации может возникать эффект блокировок, приводящий к потере пакетов, то основными характеристиками, которые определяются организацией и дисциплиной ведения очередей, является производительность коммутатора, т.е. пропускная способность, временные задержки и вариации задержки пакетов, а также потеря пакетов из-за конечной емкости буферных устройств. [5,6]
Статистическое мультиплексирование множества логических каналов, транспортирующих трафик различных пользователей в едином цифровом тракте, повышает эффективность использования цифровых трактов, а перенос всех видов информации в виде ячеек АТМ фиксированной длины делает коммутационное оборудование ATM однородным.
Для простоты изложения предположим, что все цифровые каналы (линии) имеют одинаковую пропускную способность и моменты поступления ячеек по разным каналам синхронизированы. Иными словами, мы принимаем, что вся временная ось разбита на интервалы, длительность которых равна времени передачи пакета по каналу связи так, что коммутатор работает в синхронном режиме. Примем также, что каждый поступающий пакет АТМ предназначен для единственного выходного порта. Однако, так как корреляция направления дальнейшего следования между поступающими ячейками отсутствует, то сразу несколько ячеек из числа поступающих на вход коммутатора в некотором временном интервале могут предназначаться для коммутации на один и тот же выходной порт. Такое событие будем называть конфликтом.
Из-за возможности возникновения выходных конфликтов в коммутаторе АТМ должна быть предусмотрена возможность буферизации пакетов АТМ.
И виртуальные каналы (VC) и виртуальные пути (VP) определены как виртуальные соединения между смежными объектами маршрутизации в ATM сети. Логическая связь между двумя конечными пользователями состоит из ряда виртуальных связей, если коммутируются n коммутационных узлов виртуальный путь является связкой виртуальных каналов. Так как виртуальное соединение маркируется посредством иерархического ключа VPI/VCI (идентификатор виртуального пути / идентификатор виртуального канала) в заголовке ATM ячейки, коммутационная схема может использовать или коммутацию полного VC или только VP коммутацию.
Первый случай соответствует полному ATM коммутатору, в то время как последний случай относится к упрощенному коммутационному узлу с уменьшенной обработкой, где минимальный объект коммутации – виртуальный путь. Поэтому коммутатор VP/VC повторно назначает новый VPI/VCI на каждую коммутируемую виртуальную ячейку, принимая во внимание, что только VPI повторно назначается в коммутаторе VP, как показано в примере на рисунке 1.1. [5,6]

Рисунок 1.1 – Коммутатор виртуальных пакетов и виртуальных каналов
Общая модель коммутатора показана на рисунке 1.2. Эталон коммутатора включает N контроллеров входных портов (IPC), N контроллеров выходных портов (OPC) и взаимосвязанную сеть (IN).
Очень важный блок, который не показан на рисунке, процессор запроса, задача которого состоит в том, чтобы получить от IPC запросы на установление соединение и использовать соответствующий алгоритм, чтобы решить, принимать или отказывать в установлении соединения.
Процессор запроса может быть соединен с IPC непосредственно или с решением, которое является независимым от размера коммутатора, через саму IN. Поэтому один выход IN может быть зарезервирован для доступа процессора вызовов и один вход IN может использоваться, чтобы получать ячейки, произведенные процессором запроса.[5,6,8]
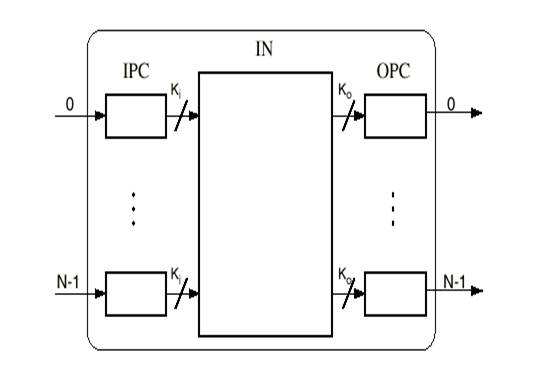
Рисунок 1.2 – Модель коммутатора АТМ
IN способна
коммутировать до ![]() ячеек к одному OPC в одном и
том же временном интервале,
ячеек к одному OPC в одном и
том же временном интервале, ![]() называется выходным
ускорением, так как внутренняя битовая скорость выше, чем внешняя. В некоторых
коммутационных системах может быть использовано ускорение по входу, это значит, что каждый
IPC может
передать больше ячеек к
IN. Если не имеется никакого
ускорения по входу, то ускорение по выходу определяется просто как ускорение и
обозначается как
K.
IN обычно представляет
собой многомерную матрицу простых коммутационных элементов (SWE
размерностью 2
называется выходным
ускорением, так как внутренняя битовая скорость выше, чем внешняя. В некоторых
коммутационных системах может быть использовано ускорение по входу, это значит, что каждый
IPC может
передать больше ячеек к
IN. Если не имеется никакого
ускорения по входу, то ускорение по выходу определяется просто как ускорение и
обозначается как
K.
IN обычно представляет
собой многомерную матрицу простых коммутационных элементов (SWE
размерностью 2![]() 2), которые обычно
обеспечиваются внутренней организацией очереди (SWE с
организацией очереди), которая может быть реализована как на входе, на выходе
или с разделенными буферами, или без буферов. В этом последнем случае
организация очереди на входе и выходе, как обычно, используется в
IPC и
OPC,
соответственно, принимая во внимание, что разделенная организация очереди
выполнена с помощью дополнительных аппаратных средств, соединенных с
IN. [5,6]
2), которые обычно
обеспечиваются внутренней организацией очереди (SWE с
организацией очереди), которая может быть реализована как на входе, на выходе
или с разделенными буферами, или без буферов. В этом последнем случае
организация очереди на входе и выходе, как обычно, используется в
IPC и
OPC,
соответственно, принимая во внимание, что разделенная организация очереди
выполнена с помощью дополнительных аппаратных средств, соединенных с
IN. [5,6]
В общем случае коммутационные операции в взаимосвязанной сети в каждом временном интервале могут охарактеризоваться двумя типами конфликтов: внутренние конфликты и внешние конфликты. Первые происходят, когда два соединения на входе и выходе конкурируют за один и тот же внутренний ресурс, который является тем же самым соединением между стадиями в многоступенчатой структуре (схеме), принимая во внимание, что последний имеет место, когда больше, чем K пакетов, переключены в тот же самый временной интервал к тому же самому OPC.
Взаимосвязанная сеть АТМ с ускорением K, как считают, является неблокируемой, если она гарантирует отсутствие внутренних конфликтов для любой произвольной коммутационной конфигурации, не имеющей внешних конфликтов для заданного значения сетевого ускорения K. Такая неблокируемая IN, способна передать OPC свыше N пачек в один временной интервал, в который большинство из K их адресуют в тот же самый выход коммутатора.
Обратите внимание, что использование выходных очередей и в SE, и в IN строго связано с полной эксплуатацией ускорения: фактически, структура не требует очередей на выходе, хотя выходной интерфейс способен передать один нисходящий пакет в слот. Всякий раз, когда очереди находятся в различных элементах коммутатора ATM (например, организация очереди в SE так же, как вход или разделенная очередь используются вместе с очередью по выходу в IN), два различных внутренних способа передачи могут быть приняты:
- обратное давление (BP), в котором посредством подходящей обратной сигнализации число пакетов фактически коммутируются к каждой нисходящей очереди, которая ограничена текущей способностью хранения очереди; в этом случае все другие «заголовки линии» (HOL) ячейки сохраняются в их соответствующих восходящих очередях;
- потеря очереди (QL), в котором имеют место потери ячеек нисходящих очередях для тех HOL пакетов, которые были переданы восходящей очередью, но не могут храниться в адресованной нисходящей очереди.[5]
Главные функции контроллера порта:
- скорость соответствия между входной/выходной скоростью канала и скоростью коммутации схемы;
- выравнивание ячеек для целей коммутации (IPC) и передачи (OPC) (это требует временный буфер для одной ячейки);
- обработка полученной ячейки(IPC) согласно функциональным возможностям поддерживающимся протоколом на уровне ATM;
- необходимая функция – функция маршрутизации (коммутации) , которая занимается распределением коммутационных выходов коммутатора и новых VPI/VCI каждой ячейке, основываясь на заголовке VCI/VPI, который несет полученная ячейка;
- само-маршрутизация, выполняет присваивание (IPC) и удаление (OPC) у каждой ячейки;
- организация очереди в IN, сохранение (IPC) пакетов, которые будут переданы, и исследование готовности пути ввода/вывода через IN к адресованному выходу, также проверяя способность хранения в очереди адресованного выхода в BP способе, если используется организация очереди по входам; организация очереди (OPC) пакетов на выходе коммутатора, если используется организация очереди по выходам. [4,5,6]
Пример коммутации в ATM представлен на рисунке 1.3.

Рисунок 1.3 – Пример коммутатора АТМ
Две ATM ячейки получены ATM узлом - номер один, и их идентификаторы VPI/VCI, А и C занесены в контроллер входных портов с новыми VPI/VCI, маркированными F и E; ячейки также адресованы выходным соединением c и f, соответственно.
Первый пакет поступает на нисходящий коммутатор J, где его ярлык исправляется на новый ярлык B и адресуется выходному соединению С. Последний пакет входит в нисходящий узел K, где он меняется на новый VPI/VCI, и выдается адрес выхода коммутатора g. Даже если это не показано на рисунке, использование техники самомаршрутизации для ячейки в пределах взаимосвязанной сети требует, чтобы IPC присвоила адрес выходного соединения, размещенный в виртуальном соединении каждой отдельной ячейки. Этот ярлык самомаршрутизации удаляется OPC перед тем, как ячейка покидает узел коммутации.[5]
Идеальным можно считать коммутатор, который в состоянии без потерь и с минимально возможной задержкой направлять все поступающие пакеты по требуемым выходным каналам, сохраняя при этом порядок, в котором пакеты поступили на вход. Помимо основных операций по коммутации и буферизации, от коммутатора может потребоваться выполнение еще двух функций. Первая из них - многоадресная передача, а вторая - возможность приоритетного обслуживания.
Все коммутаторы делятся на три типа[1-4,16]:
– с коллективной памятью;
– с общей средой;
– с пространственным разделением.
Далее будем рассматривать основные схемотехнические принципы, положенные в основу ранних моделей коммутаторов. Приведенные схемы прозрачны для понимания широкому кругу читателей, а принципиальные решения и методы используются в самых современных разработках.[4,5,6]
1.2 Коммутаторы с коллективной памятью
Высокоскоростные коммутаторы ячеек с коллективной памятью можно считать наиболее естественным типом коммутаторов АТМ из-за большего сходства их принципов построения с традиционными коммутаторами пакетов, используемыми в вычислительных сетях.
Все входные и выходные контроллеры непосредственно соединены с общим запоминающим устройством, доступным для записи со всех входных контроллеров и чтения для всех выходных контроллеров. В рассматриваемом варианте архитектуры коммутатора АТМ должны быть удовлетворены два основных конструктивных требования.[1,4,5,6]
Во-первых, время, необходимое процессору для того, чтобы определить, в какую очередь поставить поступивший пакет и выработать соответствующие управляющие сигналы, должно быть достаточно мало, чтобы процессор успевал справляться с потоком поступающих пакетов. Следовательно, в системе должен быть центральный контроллер, способный в течение каждого временного цикла обрабатывать последовательно N входных пакетов и выбирать N пакетов для дальнейшей передачи. Во-вторых, самое важное требование относится к коллективной памяти. Скорость записи/считывания должна быть достаточно велика, чтобы можно было обслужить одновременно весь входной и выходной трафик. Если число портов равно N, а скорость обмена через порт равна V, то скорость записи/считывания должна составлять 2NV. Так, для 32-х канального коммутатора с канальной скоростью 150 Мбит/с скорость запись/считывание должна составлять, по крайней мере, 9,6 Гбит/с.[1]
Следует отметить, что в коммутаторе с коллективной памятью требуемый объем памяти определяется не только количеством портов N, поступающей нагрузкой, моделью трафика, но и способом коллективного использования памяти различными выходными очередями. Так, в одном случае память может быть разбита на N различных секций, каждая из которых предназначена для отдельной очереди (полное разбиение памяти). А в другом крайнем случае может быть организовано полностью совместное использование памяти, при котором все очереди могут формироваться в любой области памяти, и пакет будет потерян лишь тогда, когда заполнена вся память. Естественно, совместное использование ведет к минимизации объема памяти. [1,3,4,17]
Примером коммутатора с общей памятью является коммутатор Prelude, разработанный во Франции в Национальном центре исследований в области связи (СМЕТ). Примечательно, что основные инженерно-конструкторские идеи, воплощенные в этом коммутаторе, актуальны и по сей день.
Другим примером разработки высокоскоростного коммутатора пакетов, в котором использован подход, основанный на идее коллективной памяти, служит коммутатор японской фирмы Hitachi. Помимо входных/выходных БИС, осуществляющих преобразование последовательного формата в параллельный и наоборот, а также БИС преобразования заголовка (ПЗ), которые обрабатывают номер виртуального канала в каждом заголовке, в коммутаторе используются три типа кристаллов:
– коммутационная БИС (БИС КМ);
– БИС, выполняющая контрольные функции (БИС КОНТР);
– БИС буферов адресов используемых областей памяти (БИС БА ИОП).
Микросхемы KM (БИС KM) содержат память, мультиплексор (М), демультиплексор (ДМ).
Микросхемы КОНТР содержат N регистров адресов записи (РАЗ) и N регистров адресов чтения (РАЧ), по одной паре на каждый связанный список.
При каждом поступлении пакета на вход коммутатора после преобразования заголовка (при котором определяется, в какой связанный список следует поместить пакет) опрашивается соответствующий регистр адресов записи для получения адреса свободной области памяти, в которую следует записать данный пакет. [1-6]
Одновременно идентифицируется база адресов используемых адресов памяти и выдается адрес нового свободного буфера памяти. В результате регистр адресов записи, как и соответствующие указатели, изменяет свое значение. Подобным же образом для каждого временного интервала в каждом связанном списке с помощью регистра адресов чтения идентифицируется один пакет, который извлекается из памяти и передается по выходному каналу. При этом одновременно корректируются указатели и содержимое буферов адресов используемых областей памяти. Чтобы обеспечить высокое быстродействие, используется разрядная организация памяти с большим числом идентичных микросхем коммутаторов, соединенных параллельно.[1-4]
Для реализации приоритетного обслуживания достаточно организовать хранение пакетов, предназначенных для передачи через некоторый выходной порт, в виде нескольких связанных списков, по одному для каждого уровня приоритета.
Также в коммутаторе типа Hitachi легко может быть реализована и функция многоадресной передачи. После установления виртуального соединения в коммутаторе хранится информация о многоадресной маршрутизации пакетов, передаваемых по данному виртуальному каналу, которая затем может использоваться для записи требуемого числа копий одного и того же пакета в соответствующие выходные очереди. Поскольку такая задача требует проведения нескольких операций записи в общую память, в зависимости от входного трафика по другим входным линиям ячейка может быть занесена в специальный буфер внутри коммутатора и будет храниться там до тех пор, пока не будут записаны в память все ее копии.
Таким образом, коммутатор может быть модифицирован за счет включения в его состав широковещательного буфера для хранения ячеек, подлежащих многоадресной передаче, таблицы широковещательных маршрутов, содержащих номера выходных каналов для каждого многоадресного пакета, и схемы управления, необходимой для решения соответствующей задачи.[1,4,5,6]
Принцип коммутатора с коллективной памятью показан на рисунке 1.4. Все входные и выходные контроллеры непосредственно соединены с общим запоминающим устройством, доступным для записи со всех входных контроллеров и чтения для всех выходных контроллеров.
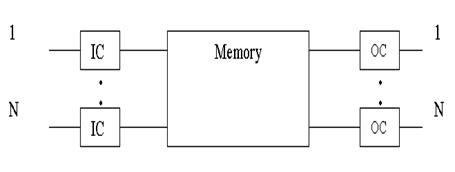
IC – входной контроллер;
OC – выходной контролер;
Memory –память.
Рисунок 1.4 – Коммутационный элемент с коллективной памятью
Первый пример подобного коммутатора был использован в эксперименты PRELUDE (Coudreuse and Servel, 1987).
Коллективная память может быть организована для обеспечения логических входных и выходных буферов. Проект Исследования и развития передовых коммуникационных технологий в Европе (RACE) под названием 1012 «Broadband Local Network Technology» использован коммутатор Sigma, базирующийся на структуре с коллективной памятью и логическими выходными буферами.
Поскольку все буферы коммутатора разделяют одну общую коллективную память, то значительное понижение требований коллективной памяти может быть достигнуто в сравнении с физически разделенными буферами. С другой стороны, высокая степень внутренних параллелизмов необходима для поддержки частоты доступа к памяти в осуществимой степени.
1.3 Коммутаторы с общей средой
В коммутаторах с общей средой все пакеты, поступающие по входным каналам, синхронно мультиплексируются в общую среду с высокой скоростью передачи, в качестве которой может выступать общая шина с разделением по времени или кольцо.[3,4]
Если в качестве общей среды выступает параллельная шина, то ее полоса пропускания должна быть в N раз больше, чем скорость передачи по одному входному каналу. Каждый выходной канал присоединен к шине через интерфейс, состоящий из адресного фильтра (АФ) и выходного буфера, организованного по принципу "первым пришел - первым вышел" (FIFO).[1-5]
Такой интерфейс в состоянии принять все пакеты, передаваемые по шине. В зависимости от значений идентификатора виртуального пути и виртуального канала, содержащихся в заголовке ячейки, адресный фильтр в каждом интерфейсе определяет, следует ли записывать ячейку в буфер данного выхода или нет. Таким образом, подобно коммутаторам с коллективной памятью коммутаторы с общей средой основаны на мультиплексировании всех поступающих пакетов в один поток и с последующим демультиплексированием общего потока на отдельные потоки по одному на каждый выход. Все пакеты проходят по единому пути - широковещательной шине с временным разделением, а демультиплексирование осуществляется адресными фильтрами в выходных интерфейсах.[4]
Отличие коммутатора с общей средой от коммутатора с коллективной памятью заключается в том, что в данном типе архитектуре осуществляется полностью раздельное использование памяти выходными очередями, так что последние могут быть организованы по принципу "первым пришел - первым обслужен". Примером реализации такой архитектуры служит коммутатор Atom, разработанный фирмой NEC. Как и в случае архитектуры с коллективной памятью, реализация архитектуры с общей шиной во многом определяется тем, каким образом обеспечить высокую скорость передачи данных в шине и буферных устройствах, которые должны работать со средней скоростью NV, где V - скорость обмена через порт.
При ограничениях на скорость доступа к памяти и размеры БИС реализация коммутационного модуля должна быть основана на параллельной организации, что позволяет уменьшить требуемую скорость доступа и размер микросхем. В коммутаторе Atom было принято решение об использовании разрядной организации памяти, что позволило решить обе проблемы.[1-6]
Поступающие последовательные потоки бит преобразуются в Р параллельных потоков, каждый из которых поступает в одну из параллельных БИС. В каждой микросхеме N битовых потоков, каждый из которых имеет скорость V/P, опять преобразуются в параллельный Q-разрядный код.
Поскольку распределение данных по выходным очередям должно осуществляться одинаковых образом во всех БИС, то более целесообразным оказывается разработка единого адресного контроллера, обрабатывающего заголовки всех поступающих пакетов и указывающего, в какой выходной буфер следует поместить данные. Для построения коммутатора с большим числом входов-выходов может использоваться многокаскадная архитектура.[4]
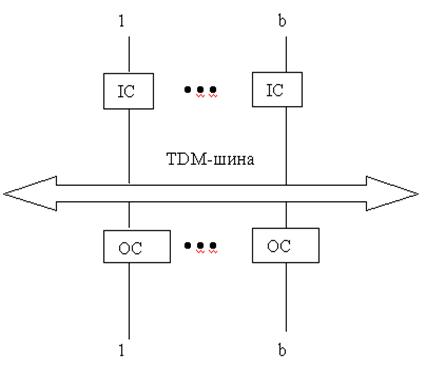
IC – входной контроллер;
ОС – выходной контроллер;
TDM – мультиплексирование с временным разделением.
Из приведенного описания можно сделать вывод, что архитектура с общей шиной приводит к независимым выходным очередям. Размер каждого буфера, организованного по принципу "первым пришел - первым обслужен", для заданных величин вероятности потери пакетов, соответствует результатам для архитектуры с полностью разделенным использованием памяти.
Взаимосвязнная сеть может быть реализована путем использования шины высокоскоростного мультиплексирования с временным разделением (IDM) . Безконфликтная передача может быть гарантирована в случае, если полная (общая) емкость шины составляет, по крайней мере, сумму емкостей всех входящих звеньев. Бит – параллельная передача данных (например, 16 или 32 бита) по шинной системе требует достижения такой большой мощности.[4]
Обычно алгоритм доступа шины применяется при размещении шины к индивидуальному входному контроллеру с постоянным интервалом. Каждый входящий контроллер способен передавать свою ячейку по направлению перед прибытием следующей полной ячейки. В данном случае нет необходимости размещать буферы на входных контроллерах. Однако несколько ячеек могут прибыть на один выходной контроллер, тогда как только одна из них может покинуть контроллер. Следовательно, существует необходимость расположения буферов на входных контроллерах. Такой коммутационный элемент имеет такие же характеристики, как и коммутатор матричного типа с выходной буферизацией.[1,4]
1.4 Коммутаторы АТМ с пространственным разделением
В противоположность вариантам архитектуры с коллективной памятью и общей средой, для которых характерно мультиплексирование входного трафика всех входных каналов в единый поток, в N раз превышающий полосу одного канала, в коммутаторе с пространственным разделением от входов к выходам устанавливается несколько соединений, скорость передачи по каждому из которых может быть равна скорости передачи по одному каналу.[4]
Другой особенностью является то, что управление коммутатором не обязательно должно быть централизованным, а может быть распределенным.
Однако данному типу архитектуры присущи собственные недостатки. В зависимости от конкретного вида используемой внутренней структуры и имеющихся коммутационных ресурсов может оказаться невозможным установить все требуемые соединения. Эта особенность, которая получила наименование внутренней блокировки, ограничивает пропускную способность коммутатора и при допустимой величине вероятности потери пакета представляет серьезную проблему при создании коммутаторов АТМ с пространственным разделением.[1-4]
В отличие от коммутаторов с коллективной памятью или с общей средой в структурах коммутаторов с пространственным разделением, для которых характерна возможность внутренних блокировок, выходная буферизация невозможна.
Коммутаторы с пространственным разделением могут быть разбиты на три большие группы:[2,4,15-17]
– баньяновидные (древовидные);
– с N2 раздельными соединениями.
На каждом входе коммутатора имеется разветвитель (т.е. демультиплексор), который направляет пакеты в N разных буферов (по одному буферу на каждый выходной порт). Аналогично каждая выходная линия подключена к концентратору (мультиплексору), который подключает все буферы N к выходной линии. Таким образом, данная модель коммутатора с пространственным разделением содержит N разветвителей, N концентраторов и N2 буферов.[1,4,5]
Данная категория коммутационных структур подразумевает наличие в коммутаторе физического ресурса, позволяющего установить N2 раздельных соединений между входами и выходами и тем самым достичь выходной буферизации.[4]
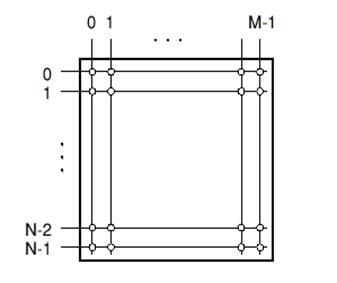
Самым очевидным примером является шинно-матричная коммутационная архитектура, которую мы уже рассматривали. В ней используется N широковещательных входных шин с множественным доступом, N выходных шин с множественным доступом и N2 матричных буферных запоминающих устройств, в каждом из которых содержится адресный фильтр, соответствующий выходной линии.
В данном случае разветвитель для входной линии содержит входную шину и N адресных фильтров, подсоединенных к ней, а выходной концентратор - это соответствующая шина с множественным доступом.
Предложены еще две структуры, которые очень похожи на шинно-матричную, но в которых достигается выходная буферизация: нокаутный коммутатор представлен на рисунке 1.7 и «интегрированная коммутационная структура»[1,15].
В нокаутном коммутаторе каждый входной порт передает свои пакеты на широковещательную шину, к которой подключены все выходные порты. Каждый выходной канал снабжён шинным интерфейсом, соединяющим его со всеми входными шинами. Каждый такой интерфейс содержит N адресных фильтров, которые обнаруживают пакеты, адресованные соответствующим выходным каналам. При N параллельно работающих фильтрах выходной интерфейс способен принимать N пакетов в одном временном интервале, так что входная полоса равна NV. Выходы фильтров присоединены к N x L - концентратору, который выбирает до L пакетов из числа принятых фильтрами.
Если одному и тому же выходному каналу в данном интервале (цикле) предназначено более L пакетов, то в буфер заносятся только L, а остальные пакеты теряются. Предлагаемая физическая реализация концентратора основана на аналогии с известной в спортивных соревнованиях олимпийской системой (из N в следующий круг выходит L, так называемый принцип «нокаута»).
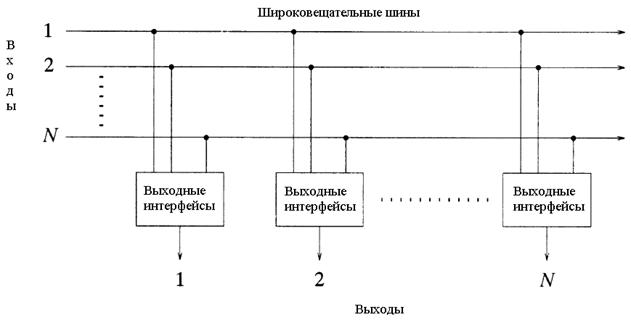
Рисунок 1.7 – Коммутационная система коммутатора нокаутного типа
В основе этого принципа лежит идея, что для обеспечения низкой вероятности потерь пакетов значение L необязательно должно быть большим. Так, при однородной модели трафика уже при L=8 достигается вероятность потерь пакетов не более 10-6 независимо от нагрузки и размера коммутатора.[15]
В структуре интегрированного коммутатора для направления пакета в соответствующий буфер для каждой входной линии используется двоичное дерево. Однако буферы представляют собой сдвиговые регистры размером в один пакет. За каждый цикл содержимое всех N регистров, содержащихся в микропроцессоре и соответствующих данной выходной линии, по очереди переписывается в буфер, организованный по принципу FIFO. Эта функция концентрации реализуется мультиплексором, работающим со скоростью, в N раз превышающей канальную.
С этой точки зрения данный вариант близок к архитектуре с коллективной шиной. Единственное отличие состоит в том, что в рассмотренном случае мультиплексируемая во времени шина и соответствующие фильтры заменяются на N разветвителей, реализованных в виде двоичного дерева с пространственным разделением.[1-6]
2.1 Одноступенчатый коммутатор нокаутного типа
Как показывает практика, коммутаторы с входным буфером (включая коммутаторы с разделенной памятью) обеспечивают лучшие показатели по критерию задержки. Проблема коммутаторов с выходным буфером заключается в том, что их емкость ограничена скоростью считывания из памяти. Рассмотрим случай с коммутатором АТМ на 100 портов. Нас интересует, какова вероятность того, что всем 100 ячейкам на входе, будет соответствовать один и тот же выходной порт в том же самом временном интервале. Если вероятность очень низка, зачем нам требуется выходной буфер, способный принять все 100 ячеек в один и тот же момент времени? Группа исследователей из Bell Labs в конце 1980-ых пробовала решить эту проблему с помощью ограничения числа ячеек, которые могут достигать выхода в определенный момент времени и таким образом определить требование к скорости считывания из памяти на выходах. Избыточные ячейки уничтожаются коммутационной системой. Концепция называется принципом нокаута. Вопрос заключается в следующем: сколько ячеек должны быть уничтожены на выходном порту в каждый интервал времени. Если их будет уничтожаться слишком много, тогда скорость памяти будет узким местом. Если слишком мало, коэффициент потери ячеек в коммутационной системе может быть слишком высоким и будет неприемлемым. Но для определенного коэффициента потери ячеек, это число может быть определено. Например, если оно равняется 12, то коэффициент потери ячеек равен 10-10 , независимо от размеров коммутатора. Этот результат кажется очень впечатляющим, так как скорость памяти больше не будет являться узким местом для коммутаторов с выходным буфером. [1-6]: Коммутатор нокаутного типа[18], проиллюстрирован на рисунке 2.1. Он состоит из полностью широковещательной взаимосвязанной коммутационной системы и из N шинных интерфейсов. Взаимосвязанная коммутационная система в коммутаторе нокаутного типа имеет две основных характеристики:
- каждый вход имеет отдельную широковещательную шину;
- каждый выход имеет доступ ко всем широковещательным шинам и соответственно ко всем входным ячейкам.
Для каждого входа, имеющего прямой доступ к каждому выходу, не будет существовать никакой коммутационной блокировки, которая может иметь место в пределах коммутационной взаимосвязанной системы. Единственная перегрузка в коммутаторе имеет место в выходном интерфейсе, куда ячейки могут прибывать одновременно от различных входов, предназначенные для одного и того же выхода. Модульность архитектуры коммутатора выражается в том, что N широковещательные шины могут находиться на объединенной плате со схемой для каждой пары N входов-выходов, и могут быть размещены на одной плате сменного модуля.[5]
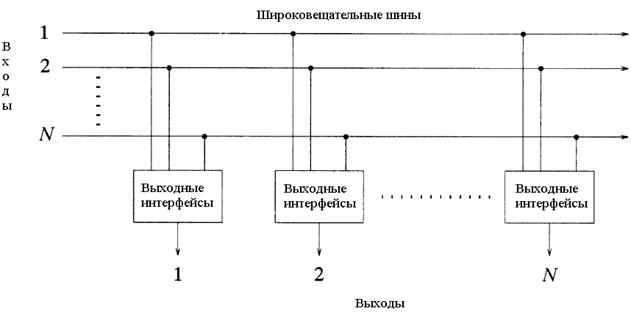
Рисунок 2.1 – Коммутационная система коммутатора нокаутного типа
Рисунок 2.2 иллюстрирует архитектуру интерфейса шины, связанного с каждым выходом коммутатора.
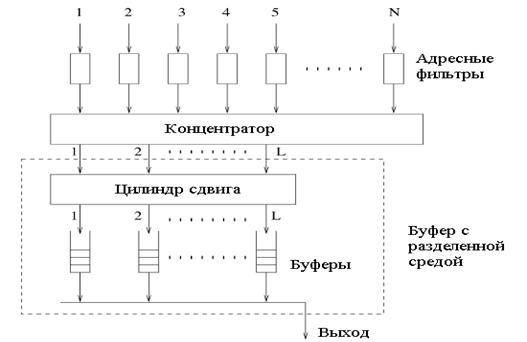
Рисунок 2.2 – Выходной интерфейс коммутатора нокаутного типа
Интерфейс шины имеет три
главных компонента. Сверху находится ряд из N адресных фильтров, где
рассматривается адрес каждой ячейки, с другими адресованными к этому выходу
ячейками, которым было разрешено перейти в концентратор, а все другие блокируются.
Концентратор N![]() L достигает
концентрации входных линий с помощью условия (L
L достигает
концентрации входных линий с помощью условия (L![]() N), и соответственно до L
ячеек в каждом временном интервале могут появиться на выходе концентратора. Эти
L выходов концентратора, затем соединяются с разделенным буфером,
который состоит из цилиндра сдвига, и L
выходов соединяются с буферами FIFO. Разделенный буфер позволяет полное разделение на L буферов FIFO и обеспечивает
эквивалент одной очереди с L входами и одним выходом, каждая из которых
использует дисциплину организации очереди – FIFO.[4,6]
N), и соответственно до L
ячеек в каждом временном интервале могут появиться на выходе концентратора. Эти
L выходов концентратора, затем соединяются с разделенным буфером,
который состоит из цилиндра сдвига, и L
выходов соединяются с буферами FIFO. Разделенный буфер позволяет полное разделение на L буферов FIFO и обеспечивает
эквивалент одной очереди с L входами и одним выходом, каждая из которых
использует дисциплину организации очереди – FIFO.[4,6]
Принцип действия цилиндра сдвига показывается на рисунке 2.3. В момент времени T, ячейки A, B, C прибывают и хранятся в начале очереди FIFO буфера. В момент времени T+1 ячейки от D до J прибывают и сохраняются в буферах FIFO, начиная с четвертого по циклическому принципу. Число позиций, которые сдвигает цилиндр сдвига, равно сумме прибывающих ячеек от L выходов.
2.1.2 Принцип концентрации в коммутаторах нокаутного типа
Все ячейки, проходящие через адресные фильтры, входят в концентратор с
параметрами концентрации
N![]() L. Если имеется
k
L. Если имеется
k![]() L ячеек, прибывающих в один временной интервал
для данного выхода, то эти
k ячейки появятся на выходах от 1 до
k после прохождения
концентратора. Если
k
L ячеек, прибывающих в один временной интервал
для данного выхода, то эти
k ячейки появятся на выходах от 1 до
k после прохождения
концентратора. Если
k![]() L, то все
L выходов концентратора
будут иметь ячейки, и
k-L ячеек будет удалено, то
есть потеряно в пределах концентратора.[5]
L, то все
L выходов концентратора
будут иметь ячейки, и
k-L ячеек будет удалено, то
есть потеряно в пределах концентратора.[5]
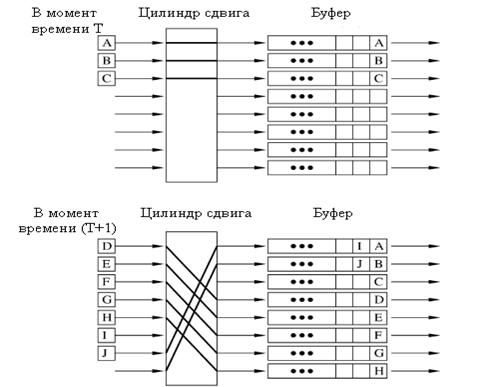
Рисунок 2.3 – Принцип действия цилиндра сдвига
Вероятность
потери ячейки оценивается следующим образом. Принимается следующее: в каждом временном
интервале существует определенная и независимая вероятность ![]() , вероятность того, что ячейка достигнет
входа. Каждая ячейка
с
одинаковой
вероятностью может предназначаться для любого выхода. Обозначим
, вероятность того, что ячейка достигнет
входа. Каждая ячейка
с
одинаковой
вероятностью может предназначаться для любого выхода. Обозначим ![]() вероятность того, что
k ячеек, прибывающих в
одном временном интервале, все предназначены для одного и того же выхода,
которая выражена биноминально следующим образом:
вероятность того, что
k ячеек, прибывающих в
одном временном интервале, все предназначены для одного и того же выхода,
которая выражена биноминально следующим образом:
![]() (2.1)
(2.1)
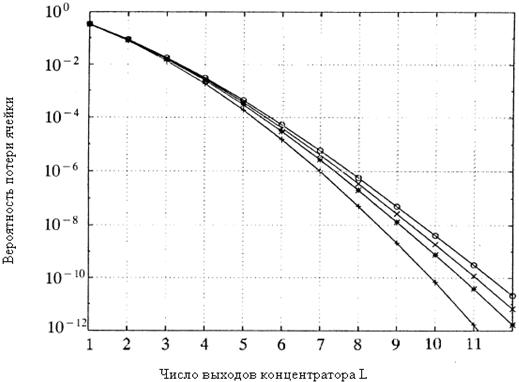
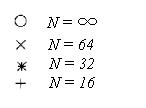
Рисунок 2.4 – Вероятность потерь ячейки в концентраторе при различных размерах коммутатора(при нагрузке в 90%)
Затем следует, что вероятность того, что ячейка будет уничтожена в концентраторе с N входами и L выходами равна:
 . (2.2)
. (2.2)
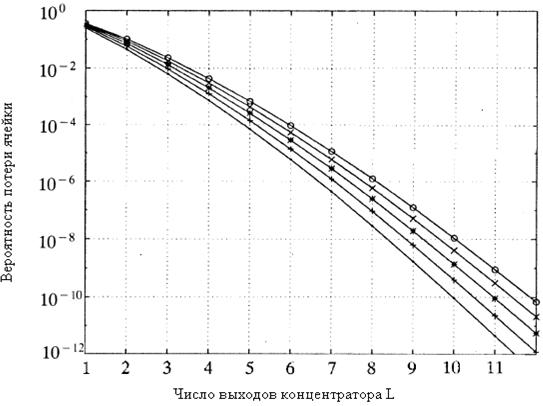

Рисунок
2.5 – Вероятность потерь ячейки в концентраторе при различных значениях
нагрузки(при ![]() )
)
Возьмем
предел при ![]() , и после некоторых преобразований
получим:
, и после некоторых преобразований
получим:
 . (2.3)
. (2.3)
Рисунок 2.4 показывает вероятность потери ячейки
в зависимости от L, числа выходов концентратора, при ![]() и N= =16,32,64,
и N= =16,32,64,![]() . Обратите внимание на то, что концентратор
только с восемью выходами может обеспечить вероятность потери ячеек меньше, чем 10-6 для
несоизмеримо большого N. Это сопоставимо с вероятностью потери ячеек в
500 бит при передаче ошибок с вероятностью 10-9. Также следует обратить
внимание на рисунке 2.4 на то, что на каждый дополнительный выход, добавленный
к концентратору свыше восьми выходов, приходится уменьшение величины
вероятности потери ячеек. Следовательно, независимый от числа входов
N, концентратор с 12
выходами будет иметь вероятность потери ячеек меньше, чем 10-10.
Рисунок 2.5 иллюстрирует, при N
. Обратите внимание на то, что концентратор
только с восемью выходами может обеспечить вероятность потери ячеек меньше, чем 10-6 для
несоизмеримо большого N. Это сопоставимо с вероятностью потери ячеек в
500 бит при передаче ошибок с вероятностью 10-9. Также следует обратить
внимание на рисунке 2.4 на то, что на каждый дополнительный выход, добавленный
к концентратору свыше восьми выходов, приходится уменьшение величины
вероятности потери ячеек. Следовательно, независимый от числа входов
N, концентратор с 12
выходами будет иметь вероятность потери ячеек меньше, чем 10-10.
Рисунок 2.5 иллюстрирует, при N![]() , что требуемое
число выходов концентратора не особенно чувствительно к нагрузке на коммутатор,
менее и включая 100% загрузку. Также важно обратить внимание на то, что ячейки
прибывают на каждый вход независимо, простая, гомогенная модель, используемая в
анализе, соответствует самому
плохому случаю, делая результаты вероятности потери ячейки, показанные на
рисунке 2.4 и рисунке 2.5 верхних границ на любой тип гетерогенной
статистики прибытия ячеек.[1-5,18]
, что требуемое
число выходов концентратора не особенно чувствительно к нагрузке на коммутатор,
менее и включая 100% загрузку. Также важно обратить внимание на то, что ячейки
прибывают на каждый вход независимо, простая, гомогенная модель, используемая в
анализе, соответствует самому
плохому случаю, делая результаты вероятности потери ячейки, показанные на
рисунке 2.4 и рисунке 2.5 верхних границ на любой тип гетерогенной
статистики прибытия ячеек.[1-5,18]
2.1.3 Конструкция концентратора
Основным блоком построения концентратора
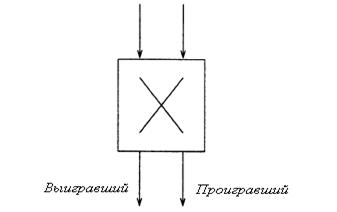
является простой коммутационный элемент 2![]() 2
соревновательного типа, показанный на рисунке 2.6. Два входа соревнуются за один
выход согласно их активным битам. Если только один вход имеет ячейку, пребывающую на его вход
(определенную активным единичным битом), то он коммутируется с левым выходом-
победителем. Если оба входа имеют прибывающие ячейки, один вход коммутируется с
выходом-победителем,
а другой вход с выходом-проигравшим. Если оба входа не имеют никаких
прибывающих ячеек, то бит активности для обоих входов должен остаться в
логическом 0 на выходе коммутатора.[1,4,5]
2
соревновательного типа, показанный на рисунке 2.6. Два входа соревнуются за один
выход согласно их активным битам. Если только один вход имеет ячейку, пребывающую на его вход
(определенную активным единичным битом), то он коммутируется с левым выходом-
победителем. Если оба входа имеют прибывающие ячейки, один вход коммутируется с
выходом-победителем,
а другой вход с выходом-проигравшим. Если оба входа не имеют никаких
прибывающих ячеек, то бит активности для обоих входов должен остаться в
логическом 0 на выходе коммутатора.[1,4,5]
Вышеупомянутые требования встречаются коммутатором в двух состояниях, показанными на рисунке 2.7. Коммутатор исследует бит активности только левого входа. Если бит активности равен 1, левый вход коммутируется с выходом победителем и правый вход коммутируется с выходом проигравшим. Если бит активности равен 0, правый вход коммутируется с выходом победителем, и никакой тракт не обеспечивается через коммутатор для левого входа. Такой коммутатор может быть реализован
Рисунок
2.6 – Пример соревновательного коммутационного элемента 2![]() 2
2
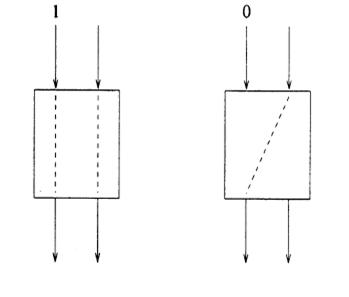
Рисунок
2.7 – Пример состояний соревновательного коммутационного элемента 2![]() 2
2
на 16 логических
элементов, и наличие времени ожидания самое большее один бит. Обратите
внимание, что приоритет дается ячейке на левый вход в коммутационном элементе 2![]() 2. Во избежание этого коммутационный
элемент может быть разработан таким образом, чтобы приоритет чередовался между
левым и правым входами, когда имеются ячейки, прибывающие на оба входа в тот же
самый временной интервал. Однако предположим, что приоритетная структура из
коммутационных элементов 2
2. Во избежание этого коммутационный
элемент может быть разработан таким образом, чтобы приоритет чередовался между
левым и правым входами, когда имеются ячейки, прибывающие на оба входа в тот же
самый временной интервал. Однако предположим, что приоритетная структура из
коммутационных элементов 2![]() 2 была создана, и как
описано выше концентратор был разработан таким образом, что один вход, например,
N-ый, всегда принимал бы
самый низкий приоритет из существующих выходов концентратора. Вероятность
потери ячейки для этого самого плохого случая по входу, при N
2 была создана, и как
описано выше концентратор был разработан таким образом, что один вход, например,
N-ый, всегда принимал бы
самый низкий приоритет из существующих выходов концентратора. Вероятность
потери ячейки для этого самого плохого случая по входу, при N![]() , равняется[5]
, равняется[5]
![]() . (2.4)
. (2.4)
Вышеупомянутое уравнение получено, с учетом того, что рассматривались k ячейки, предназначенные для одного итого же выхода от первых N-1 входов, где
![]() (2.5)
(2.5)
при N![]() ,
, ![]() .
.
Ячейки на N-ом входе будут переданы на выход, если число ячеек от первых N-1 входов, предназначенные для того же самого выхода, меньше чем или равны L-1. Полное суммирование в 2.4-это вероятность того, что ячейка от N-ого входа не будет потеряна. Сравнивая результаты 2.4 с вероятностью потери ячейки, усредненной по всем входам, как дано в 2.3 и показано на рисунке 2.5, учитывается, что это самый плохой случай, вероятность потери ячейки относительно среднего числа больше на 10%. Эту большую вероятность потери ячеек, однако, можно легко компенсировать с помощью добавления дополнительного выхода к концентратору.[4-6]
Рисунок 2.8 демонстрирует конструкцию
концентратора 8![]() 4, составленный на простых
коммутационных элементах 2
4, составленный на простых
коммутационных элементах 2![]() 2 и элементах задержки
1
2 и элементах задержки
1![]() 1 в 1 бит(показанных как
D). На входе
концентратора (верхний левый угол рисунка 2.8),
N выходов от адресных
фильтров соединены и входят в ряд из
N/2 коммутационных
элементов. Можно рассматривать эту первую стадию коммутации как первый круг
турнира с
N игроками, где
победитель каждого состязания появляется с левой стороны коммутационного
элемента 2
1 в 1 бит(показанных как
D). На входе
концентратора (верхний левый угол рисунка 2.8),
N выходов от адресных
фильтров соединены и входят в ряд из
N/2 коммутационных
элементов. Можно рассматривать эту первую стадию коммутации как первый круг
турнира с
N игроками, где
победитель каждого состязания появляется с левой стороны коммутационного
элемента 2![]() 2, а проигравший появляется с правой
стороны.
N/2 победителей из первого
круга переходят во второй круг, где они конкурируют в парах как прежде,
используя ряд из
N/4
коммутационных элементов.[5]
2, а проигравший появляется с правой
стороны.
N/2 победителей из первого
круга переходят во второй круг, где они конкурируют в парах как прежде,
используя ряд из
N/4
коммутационных элементов.[5]
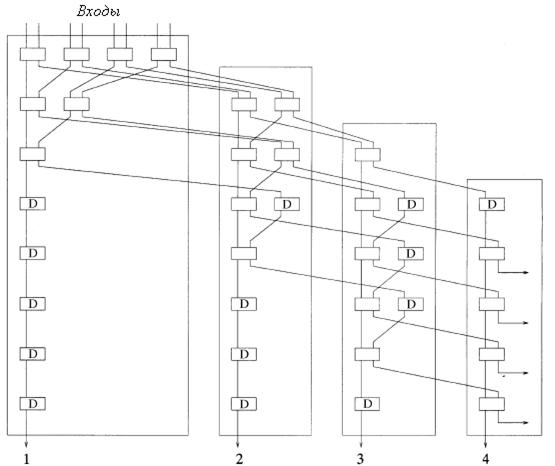
Рисунок
2.8 – Пример концентратора 8![]() 4
4
Победители второго круга переходят в третий круг, и это продолжается до тех пор, пока не останется два участника конкурирующих между собой за финал, который представляет собой право на выход первым из концентратора. Обратите внимание, что, если имеется по крайней мере одна ячейка, прибывающая на вход концентратора, она появится первой на выходе концентратора.
Турнир, включающий в себя только одно соревнование, имеющий древовидную структуру, ведет к единственному победителю, так называемое одно-нокаутное состязание, то есть при поражении в одном состязании вы выпадаете из турнира. В двух-нокаутном турнире N-1, проигравших первый круг соревнования, конкурируют во втором, который производит призера второго места(ту ячейку, поступающую на второй выход концентратора) и N-2 проигравших. Как иллюстрирует рисунок 2.8, проигравшие в первой секции могут начинать конкурировать во второй перед тем, как соревнование закончено в первой. Всякий раз, когда имеется нечетное число игроков в круге, один игрок должен ждать и конкурировать в следующем круге. В концентраторе эту функцию обеспечивает простой элемент задержки.[16]
Для концентратора с
N входами и
L выходами имеются
L секции по одной для
каждого выхода. Ячейке, входящей в концентратор, дают
L возможностей попасть на
выход концентратора. Другими словами, ячейка потерпевшая
L поражений, удаляется
концентратором. В других случаях, однако, некоторые ячейки удаляются при том
условии, что больше,
чем
L ячеек,
прибывают в один
временной интервал. Таким образом,
мы убедились, что случай с
L![]() 8 - это случай с низкой
вероятностью.[5,6,17]
8 - это случай с низкой
вероятностью.[5,6,17]
Для
NффL
каждая ступень концентратора содержит
приблизительно
N
коммутационных элементов, а для полной сложности концентратора
-
16NL логических элементов.
Для
N=32 и
L=8 это соответствует
относительно примерно 4000 логическим элементам. Таким образом, изготавливается
микросхема концентратора: рисунок 2.9 иллюстрирует, как несколько
идентичных микросхем могут быть соединены для формирования большого
концентратора. Коэффициент вероятности потерь двухступенчатого концентратора -
тот же самый, что и у
одноступенчатого. Вообще, концентратор с
KjL-входами и
L выходами может быть
сформирован путем соединения
J+1 рядов, состоящих из концентраторов, микросхем
размерностью
KL![]() L, в деревовидную
структуру с
i
рядами (считая снизу), содержащих
Ki-1
микросхем. Пример
проиллюстрирован на рисунке 2.9,при условии, что
L=8,
K=4 и
J=2.[5,18]
L, в деревовидную
структуру с
i
рядами (считая снизу), содержащих
Ki-1
микросхем. Пример
проиллюстрирован на рисунке 2.9,при условии, что
L=8,
K=4 и
J=2.[5,18]
2.2 Принцип группирования каналов
Конструкция двухступенчатой модульной сети главным образом основана на принципе группирования каналов, чтобы отделить вторую ступень от первой. Так же, как и на первой ступени, ячейка, предназначенная для выхода в этой группе, может быть соединена с любым выходом группы перед тем, как быть подключенной к выходу второй ступени. Для примера, как показано на рисунке 2.10, ячейка на входе, расположенном сверху, предназначенная для шестого выхода, появляется на втором входе второй группы, в то время как другая входящая ячейка, предназначенная для нулевого выхода, появляется на первом входе первой группы. Первая ступень сети маршрутизирует ячейки по требуемым выходным группам, а вторая ступень сети далее маршрутизирует ячейки к требуемым выходным портам. Это сглаживает проблему соревнования за выход, и таким образом достигается лучшее соотношение «эффективность-сложность» для первой ступени коммутатора. Более теоретические оценки рассматриваются далее.
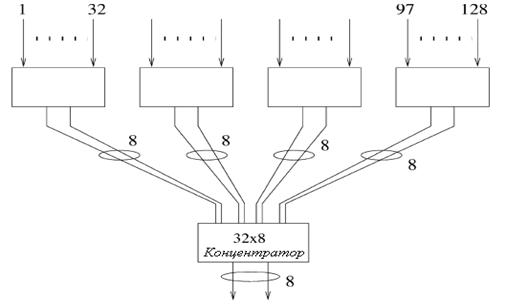
Рисунок
2.9 – Концентратор емкостью 128![]() 8, построенный
на микросхемах емкостью 32
8, построенный
на микросхемах емкостью 32![]() 8
8
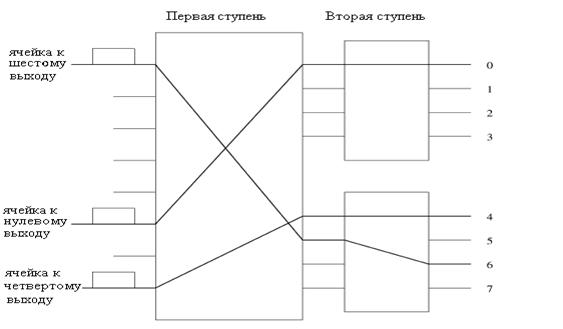
Рисунок 2.10 - Иллюстрация принципа группирования каналов
2.2.1 Максимальная производительность
Этот подраздел уделяет внимание структуре коммутатора, показанную на рисунке 2.11. Выходная группа состоит из М выходных портов и соответствует выходному адресу для первой ступени сети. Ячейка имеет доступ к любому из М выходных портов первой ступени сети. В любом данном временном интервале, большинство М ячеек могут пройти через одну выходную группу, одна ячейка на каждый выходной порт.

Рисунок 2.11 – Асимметричный коммутатор с коэффициентом расширения КМ/N
Максимальная производительность коммутатора с входным буфером ограничена внутренними блокировками. Симметрический случай оценен в [8], и максимальная производительность равна 0.586. Подобный подход мог быть использован для асимметричного случая, определяя решение с помощью числового анализа [20].
В таблице 2.1 приведена максимальная производительность по входу для различных значений М и K/N. Колонка, в которой K/N=1, соответствует специальному случаю. Для данных М, максимальная производительность
увеличивается с сростом соотношения K/N, потому что нагрузка на каждую выходную группу уменьшается с увеличением K/N. Для данных K/N, максимальная производительность увеличивается с ростом М, потому что каждая выходная группа имеет большее количество выходов.[5]
В таблице 2.2 приведена максимальная производительность как функция отношения расширения линий (отношение числа выходов к числу входов), КМ/N. Имеем следующее: для данного отношения расширения линий максимальная производительность увеличивается с M. Группировка каналов имеет более сильный эффект на производительность при меньших значениях КМ/N, чем для больших. Это потому, что для большого значения КМ/N, и при M=1, коэффициент расширения линий увеличил производительность за счет уменьшения внутренних блокировок.[1-5,17,18]
Таблица 2.1 –
Зависимость максимальной производительности от K/N (при K, N ![]() )
)
|
М/ К/N |
Максимальная пропускная способность |
||||||||
|
1/16 |
1/8 |
1/4 |
1/2 |
1 |
2 |
4 |
8 |
16 |
|
|
1 |
0,061 |
0,117 |
219 |
0,382 |
0,586 |
0,764 |
0,877 |
0,938 |
0,969 |
|
2 |
0,121 |
0,233 |
0,426 |
0,686 |
0,885 |
0,966 |
0,991 |
0,998 |
0,999 |
|
4 |
0,241 |
0,457 |
0,768 |
0,959 |
0,996 |
1 |
1 |
1 |
|
|
8 |
0,476 |
0,831 |
0,991 |
1 |
1 |
|
|
|
|
|
16 |
0,878 |
0,999 |
1 |
|
|
|
|
|
|
Таблица 2.2 –
Зависимость максимальной производительности от KM/N
(при
KM, N ![]() )
)
|
М |
Максимальная пропускная способность |
||||||
|
К/N= |
1 |
2 |
4 |
8 |
16 |
32 |
|
|
1 |
|
0,586 |
0,764 |
0,877 |
0,938 |
0,969 |
0,984 |
|
2 |
0,686 |
0,885 |
0,966 |
0,991 |
0,998 |
0,999 |
|
|
4 |
0,768 |
0,959 |
0,996 |
1 |
1 |
1 |
|
|
8 |
0,831 |
0,991 |
1 |
|
|
|
|
|
16 |
0,878 |
0,999 |
|
|
|
|
|
|
32 |
0,912 |
1 |
|
|
|
|
|
|
64 |
0,937 |
|
|
|
|
|
|
|
128 |
0,955 |
|
|
|
|
|
|
|
256 |
0,968 |
|
|
|
|
|
|
|
512 |
0,978 |
|
|
|
|
|
|
|
1024 |
0,984 |
|
|
|
|
|
|
2.2.2 Обобщенный принцип нокаута
Этот раздел обобщает вычисление потерь нокаутного
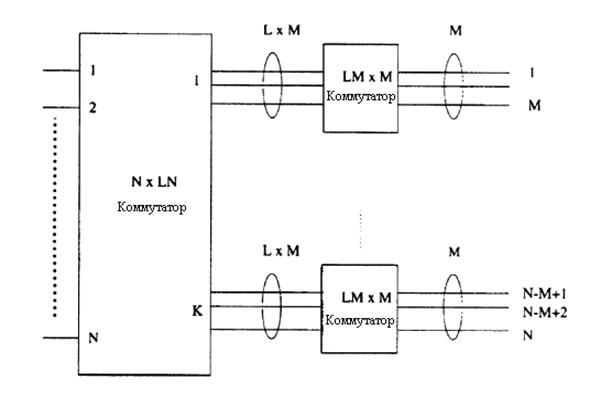
концентратора по отношению к выходным группам [7,3]. Учитывая, что коммутатор
емкостью
N![]() N имеет двухступенчатую маршрутизируемую сеть,
как показано на рисунке 2.12. Группа из М выходов на второй ступени
разделяет LM маршрутизируемые связи от первой ступени сети. Вероятность
того, что входная ячейка,
предназначенная для этой группы выходов, приблизительно равна М
N имеет двухступенчатую маршрутизируемую сеть,
как показано на рисунке 2.12. Группа из М выходов на второй ступени
разделяет LM маршрутизируемые связи от первой ступени сети. Вероятность
того, что входная ячейка,
предназначенная для этой группы выходов, приблизительно равна М![]() /N. Если же более чем LM
ячейкам разрешается пройти через группу выходов, где L называется коэффициентом
расширения группы, тогда
/N. Если же более чем LM
ячейкам разрешается пройти через группу выходов, где L называется коэффициентом
расширения группы, тогда
 (2.6)
(2.6)
Рисунок
2.12 – Коммутатор
N![]() N с коэффициентом
расширения группы (L)
N с коэффициентом
расширения группы (L)
При
N![]() ,
,
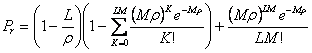 .
(2.7)
.
(2.7)
Для пример мы взяли следующие данные: М=16 - и построили график на рисунке 2.13, на котором вероятность потери ячейки (уравнение 2.7) отображена как функция LM при различных нагрузках. Следует обратить внимание на то, что значение функции LM, равное 33, достаточно большое для того, чтобы обеспечить вероятность потери ячеек ниже 10-6 при 90% нагрузки.[5]
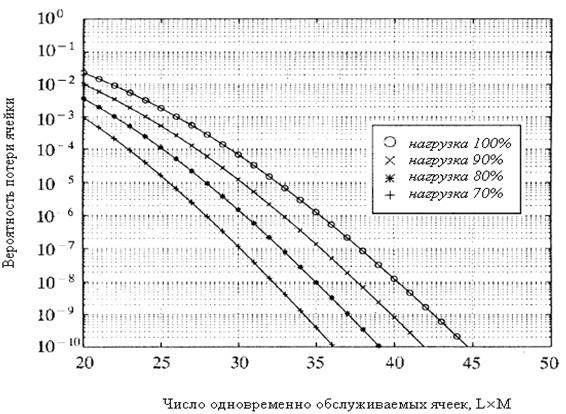
Рисунок 2.13 – Вероятность потери ячейки при использовании обобщенного принципа нокаута
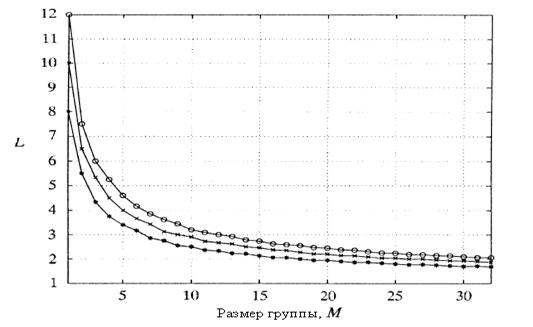
Рисунок 2.14 – Отношение числа одновременно обрабатываемых ячеек принятых к размеру группы при различных вероятностях потерь ячеек
Напротив, если выходные группы брались
индивидуально, тогда значение
LM
было бы 128(8![]() 16), для той же вероятности потери
ячейки. Преимущество группирования выходов показаны на рисунке 2.14, где
L коэффициент расширения
группы построен относительно практических данных М при различных критериях
потери ячейки.
16), для той же вероятности потери
ячейки. Преимущество группирования выходов показаны на рисунке 2.14, где
L коэффициент расширения
группы построен относительно практических данных М при различных критериях
потери ячейки.
Обратите внимание, что при вероятности потери ячейки 10-8 , L стремительно уменьшается от восьми до меньше чем 2.5, для большего размеров группы, чем M=16; подобная тенденция очевидна для других вероятностей потерь ячеек.[1,4,17]
3 Двухступенчатый коммутатор АТМ с выходным буфером и групповой доставкой
3.1 Двухступенчатая конфигурация.
На рисунке 3.1 показана структура двухступенчатого коммутатора АТМ с выходным буфером и групповой доставкой (MOBAS), который использует обобщенный принцип нокаута описанный выше. В результате сложность взаимосвязи соединений и построение элементов может быть уменьшено значительно, почти на один порядок [3].
Коммутатор состоит из входных контроллеров (IPC), сети с групповой доставкой (MGN1, MGN2), таблицы преобразования групповой доставки (MTT) и выходных контроллеров (OPC). Входные контроллеры (IPC) ограничивают поступающие ячейки, просматривают необходимую информацию в таблицах преобразования и прилагаю информацию (т.е. образцы групповой доставки и приоритетные биты) к началу ячеек таким образом, чтобы ячейки должным образом были направлены в сети с групповой доставкой (MGN). Сети с групповой доставкой (MGN) копируют ячейки с групповой доставкой и основанные на этих образцах копии посылают к каждой выходной группе.[3-6]
Таблицы преобразования групповой доставки (MTT) облегчают маршрутизацию ячейки с групповой доставкой в MGN2. Выходные контроллеры (OPC) временно хранят множество прибывающих ячеек, предназначенные для требуемого выхода в выходной буфер, производя многократные копии для ячеек с групповой доставкой с помощью дубликатора ячеек (CD), назначая новый виртуальный идентификатор канала VCI, полученный от таблицы преобразования к каждой копии, преобразовывая внутренний формат ячейки в стандартный формат ячейки АТМ, и, наконец посылает ячейки к следующему коммутационному узлу или к конечному пункту назначения.[5]
Позвольте нам сначала рассмотреть ситуацию
с индивидуальной доставкой. Как показано на рисунке 3.1, каждый из М
выходов связан в группу, и имеется общее количество
K групп (K=N/M) для
размера коммутатора
N![]() N. Из-за
соревнования ячейки
L1M
маршрутизируемых соединений подключаются к каждой группе из М выходных
портов.
N. Из-за
соревнования ячейки
L1M
маршрутизируемых соединений подключаются к каждой группе из М выходных
портов.
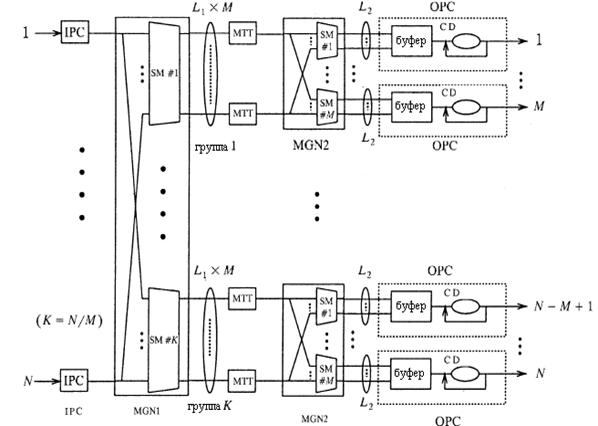
Рисунок 3.1 – Архитектура коммутатора АТМ с выходным буфером и групповой доставкой
Если имеется больше, чем L1M, ячеек в одном временном интервале, предназначенных для той же самой группы выходов, то эти избыточные ячейки будут удалены и потеряны. Однако мы можем создать L1 (т.н. коэффициент расширения группы) таким образом, что вероятность потери ячейки из-за соревнования за соединения LM будет более низкой, чем при буферном переполнении на выходе или ошибках бита, встречающихся в заголовке ячейки.[5]
Выше было доказано, что чем больше М, тем меньше может быть L1 , чтобы достичь того же самого значения вероятности потери ячейки. Например, для группы размером в один выход, который находится на второй ступени (МGN2), L2 должен иметь значение, по крайней мере, около 12, чтобы обеспечивать вероятность потери ячейки 10-10. Но для размера группы в 32 выхода, которая находится на первой ступени (MGN1), L1 должен быть равен двум, чтобы обеспечить ту же самую вероятность потери ячейки.
Ячейки от входов должным образом маршрутизируются в MGN1 в направлении одной из K групп, где они далее направляются к надлежащему выходу через MGN2, с учетом того, что до L2 ячеек может прибывать одновременно на каждый выход. Выходной буфер используется, чтобы хранить эти ячейки и отправлять одну ячейку в каждом временном интервале. Ячейки, которые создаются одним и тем же источником нагрузки, могут быть произвольно направлены на любую из L1M направленных связей, с учетом того, что последовательности ячеек все еще будет сохраняться.
Теперь давайте рассмотрим ситуацию групповой доставки, где ячейка размножается в множество копий в MGN1, MGN2, или в обеих сетях, и эти копии посылаются на множество выходов. На рисунке 3.2 показан пример для иллюстрации того, как ячейка копируется в MGN и дублируется в CD, предполагая, что ячейка поступает на вход i и должна быть доставлена к четырем выходным портам: 1, М, М+1 и N. Ячейка сперва передается ко всем K группам в MGN1, но только группы один, два и K принимают ячейку. Обратите внимание, что только одна копия ячейки будет появляться в каждой группе, и копируемая ячейка может появляться на любой из L1M связей. Копия ячейки на выходе группы один снова размножается в две копии в MGN2. Получается, что было создано всего четыре копируемых ячейки после MGN2. Когда каждая копируемая ячейка достигает OPC, она может быть далее дублирована в столько множество копии, сколько необходимо в CD. Каждая дублированная копия в OPC обновляется новым VCI, полученным из таблицы преобразования в OPC, прежде, чем она отсылается в сеть.
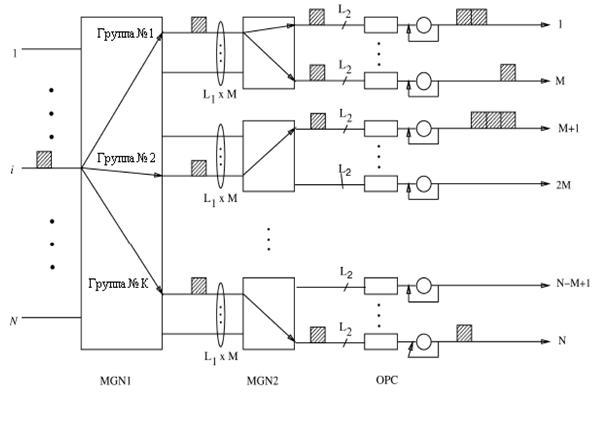
Рисунок 3.2 – Пример копирования ячеек для соединения с групповой доставкой в MOBAS
Например, две копии появились на выходе один, и три копии - на выходе М+1. Причина использования CD состоит в том, чтобы уменьшить размер выходного буфера, сохраняя только одну копию ячейки с групповой доставкой для каждого выхода, вместо хранения множества копий, которые произведены от одного и того же самого источника нагрузки и групповой доставки для множества виртуальных цепей на выходном порту. Также обратите внимание на то, что не имеется никаких буферов, как в MGN1, так и в MGN2.
Копируемые ячейки от любой MGN появляются одновременно. Однако заключительно дублированные ячейки на выходах могут появляться в разное время, так как они могут иметь различные задержки из-за очереди в выходных буферах.[5]
3.2 Группирующая сеть с групповой доставкой
На рисунке 3.3 показана модульная структура MGN на первой и второй ступени. MGN состоит из K коммутационных модулей для первой ступени и М для второй ступени. Каждый коммутационный модуль содержит набор коммутационных элементов (SWE) и определенное число копирующих моделей групповой доставки (MPM), и широковещательный адрес (AB). Широковещательный адрес (AB) производит фиктивные ячейки, которые имеют тот же самый адрес назначения, как и выход. [5,25-30] Это позволяет коммутировать ячейки по распределенному принципу и разрешает SWE не хранить номерную информацию выходной группы, что сильно упрощает схему SWE и тем самым увеличивает VLSI степень интеграции.
Так как структура и функции MGN1 и MGN2 являются идентичным, для примера рассмотрим только MGN1. Каждый коммутационный модуль в MGN1 имеет N горизонтальных входных линии и L1M вертикальных маршрутизирующих линий, где М=N/K. Эти маршрутизирующие линии разделяют ячейки, которые предназначены для той же самой группы выходов коммутационного модуля. Каждая входная линия связана со всеми коммутационными модулями, что позволяет ячейке на любой входной линии быть доставленной ко всем K коммутационным модулям.
Информация маршрутизации, которую несет перед каждой прибывающей ячейкой образец групповой доставки, которая является битом метки для всех выходов в MGN. Каждый бит, указывает должна ли быть ячейка послана связанной группе выходов. Рассмотрим для примера, коммутатор с групповой доставкой на 1024 входов и 1024 выходов и с числом групп в MGN1 и MGN2, K и М, соответственно равных 32.
Таким образом, модель групповой доставки и в MGN1 и MGN2 имеет 32 бита. Для ячейки с индивидуальной доставкой это частный случай модели групповой доставки с адресом выхода (т.е. с определенным выходным адресом), в котором только один бит установлен в единицу, а все другие 31 биты установлены в ноль.
Для ячейки с групповой доставкой в модели групповой доставки имеется больше, чем один бит, установленные в 1. Например, если ячейка X с групповой доставкой должна быть проключена между i-ым и j-ым коммутационными модулями, тогда в единицу будут установлены биты i-ый и j-ый, в модели групповой доставки. MPM выполняет логическую функцию «И» для модели групповой доставки с фиксированной длиной в 32 бита, из которых только i-ый бит, относящийся к i-ому коммутационному модулю, установлен в единицу, а все другие 31 бит установлены в ноль. Таким образом, после того, как ячейка X проходит через MPM в i-ом коммутационном модуле, её модель групповой доставки становится одноуровневой с выходным адресом, где только i-ый бит установлен в единицу.

Рисунок 3.3 – Группирующая сеть с групповой доставкой
Каждая пустая ячейка, которая передается от AB, присоединяется к началу одноуровневого адреса только с одним единичным битом. Например, пустые ячейки от AB для i-ого коммутационного модуля имеют только i-ый единичный бит в одноуровневом адресе. Ячейки от горизонтальных входов будут должным образом направлены к различным коммутационным модулям, основанным на результате соответствия их модели групповой доставки с пустыми ячейками одноуровневого адреса.
Для ячейки X единичные биты начинаются с i-ого и заканчиваются j-ым битом в образце групповой доставки, это и будет отличием пустых ячеек одноуровневых адресов пустых ячеек от широковещательного адреса (AB) в i-ом и j-ом коммутационных модулях. Таким образом, ячейка X будет направлена к выходу из этих двух коммутационных модулей.[5,6,13]
Коммутационный элемент (SWE) имеет два состояния: перекрестное состояние и сквозное - как показано на рисунке 3.4. Состояние коммутационного элемента SWE зависит от результата сравнения одноуровневого адреса и приоритетных областей в заголовке ячейки.
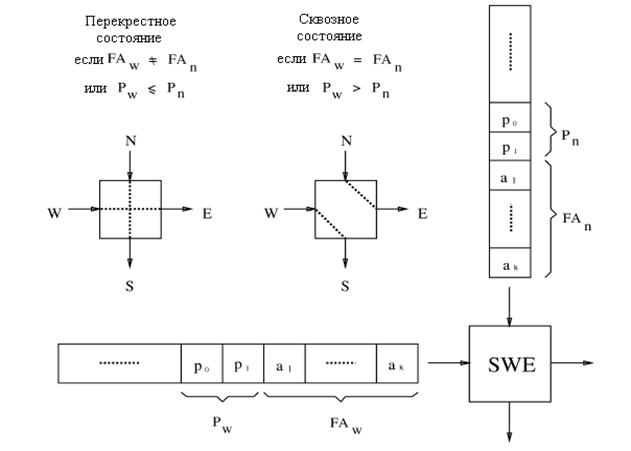
Рисунок 3.4 – Состояния переключения коммутационного элемента
Приоритет используется для вынесения окончательного решения при соревновании ячеек. Обычно, SWE находится в перекрестном состоянии, то есть ячейки с северной стороны коммутируется с южной стороной, и ячейки от западной стороны коммутируются с восточной стороной. Когда одноуровневый адрес ячейки с запада (FAw) соревнуется с одноуровневым адресом ячейки с севера (FAn) и когда приоритетный уровень западной (Pw ) выше, чем приоритет северной (Pn ), то состояние коммутационного элемента называется сквозным: ячейка с западной стороны направлена на юг, а ячейка с севера направлена на восток. Другими словами, любая не соревнующаяся или имеющая приоритет ниже (также учитывая одинаковые приоритеты) ячейка с запада всегда будет направляться к восточной стороне. Каждый коммутационный элемент SWE обеспечивает задержку в один бит не- зависимо от направления. Между ячейками от MPM и AB создается временной сдвиг в один бит прежде чем они будут посланы каждому коммутационному элементу SWE, из-за требования выравнивания по времени.[5,16]
На рисунке 3.5 пример того, как
ячейки коммутируются в коммутационном модуле. Ячейки
U,
V,
W,
X,
Y, и
Z прибывают
на входы от первого до шестого, соответственно, третьего коммутационного
модуля. В заголовке ячейки, имеется три бита образца групповой доставки (m3
m2 m1) и область приоритета длиной в два бита(p1
p0). Если например ячейка должна быть послана на выход этого
коммутационного модуля, то его ![]() бит будет установлен
в единицу. Среди этих шесть ячеек, ячейки U, V, и X - для одноуровневого
адреса, соответственно, где только один бит в модели групповой доставки
установлен в единицу. Другие три ячейки - для групповой доставки, где более чем
один бит в образце групповой доставки установлен в единицу. Принято следующее,
что, меньшее приоритетное значение имеет более высокий приоритетный уровень.
Например, ячейка Z имеет самый высокий приоритетный уровень (00), а пустые
ячейки, переданные от широковещательного адреса, имеют самый низкий
приоритетный уровень 11.
бит будет установлен
в единицу. Среди этих шесть ячеек, ячейки U, V, и X - для одноуровневого
адреса, соответственно, где только один бит в модели групповой доставки
установлен в единицу. Другие три ячейки - для групповой доставки, где более чем
один бит в образце групповой доставки установлен в единицу. Принято следующее,
что, меньшее приоритетное значение имеет более высокий приоритетный уровень.
Например, ячейка Z имеет самый высокий приоритетный уровень (00), а пустые
ячейки, переданные от широковещательного адреса, имеют самый низкий
приоритетный уровень 11.
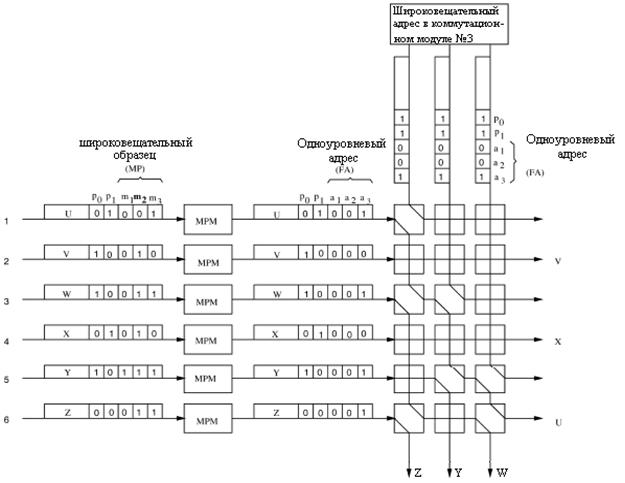
Рисунок 3.5 – Пример маршрутизации ячейки с групповой доставкой
MPM, выполняет логическую функцию
«И» для каждой модели с групповой доставкой с установленным образцом 100.
Например, после того, как ячейка W проходит через MPM, её модель групповой
доставки (110), становится 100 ![]() , который имеет только
один единичный бит и принимается как одноуровневый адрес. Когда ячейки
направляются к множеству коммутационных элементов SWE, их тракты маршрутизации
определяются состоянием SWE, которые управляются согласно правилам, указанным на рисунке
3.4. Так как ячейки V и X не предназначены для этой группы, коммутационные
элементы SWE они проходят в перекрестном состоянии. Следовательно, они направляются
на правую сторону модуля и будут удалены. Так как имеются только три связи
маршрутизации в этом примере, то могут существовать только четыре ячейки,
предназначенные этому коммутационному модулю, одна с самым низким приоритетом, то есть
ячейка U проигрывает состязание другим трем и удаляется.[3-6]
, который имеет только
один единичный бит и принимается как одноуровневый адрес. Когда ячейки
направляются к множеству коммутационных элементов SWE, их тракты маршрутизации
определяются состоянием SWE, которые управляются согласно правилам, указанным на рисунке
3.4. Так как ячейки V и X не предназначены для этой группы, коммутационные
элементы SWE они проходят в перекрестном состоянии. Следовательно, они направляются
на правую сторону модуля и будут удалены. Так как имеются только три связи
маршрутизации в этом примере, то могут существовать только четыре ячейки,
предназначенные этому коммутационному модулю, одна с самым низким приоритетом, то есть
ячейка U проигрывает состязание другим трем и удаляется.[3-6]
Так как перекрестная структура имеет характеристики идентичные и
короткие соединительные линии между коммутационными элементами, выравнивание времени для сигналов в каждом SWE намного более легко осуществимо, чем для других типов взаимосвязанных сетей, типа двоичной сети, сети Клоза и так далее.
Неравная длина проводов взаимосвязанной сети увеличивает сложности в синхронизации сигналов и, следовательно, ограничивает размер коммутационной системы, например, как на коммутаторе Батчер-баньян. Коммутационные элементы SWE в коммутационных модулях соединены только локально со своими соседями так же, как и микросхемы, которые содержат двумерный массив коммутационных элементов SWE. Коммутационные микросхемы не должны иметь длинные проводники к другим микросхемам в том же самом правлении печатной платы. Обратите внимание на то, что синхронизация сигналов данных требуется только для каждого коммутационного элемента SWE в каждом индивидуальном коммутационном модуле, а не для коммутационной системы в целом.
3.3 Таблицы преобразования
Таблицы, находящиеся в IPC, MTT, и OPC, представлены на рисунке 3.6, содержат информацию, необходимую для требуемой маршрутизации ячеек в коммутационных модулях MGN1 и MGN2, и преобразовывает старые значения VCI в новые VCI. Как было упомянуто выше, маршрутизация ячейки в MGN зависит от образца групповой доставки и значения приоритета, которые прилагаются ко фронту поступающей ячейки. Для того чтобы уменьшить сложность таблицы преобразования, содержание таблицы и информация, прилагаемая к фронту, ячеек различна для одноуровневого запроса и для запроса групповой доставки. В коммутаторе АТМ с двухточечным соединением, VCI поступающей ячейки на входной линии может быть идентичен VCI другим ячейкам на других входных линиях.[19-22]
Так как VCI в таблице преобразования связан с IPC, находящимся на каждой входной линии, то же самое значение VCI может быть неоднократно использовано для различных виртуальных соединений на различных входных линиях без какой - либо двусмысленности. Но ячейки, которые направляются от различных виртуальных соединений и предназначены для одного и того же выхода, требуют различных преобразованных VCI.
В коммутаторе с групповой доставкой ячейка копируется на множество копий, которые, вероятно, могут быть переданы по той же самой маршрутизациионной линии внутри коммутационной системы, и поэтому коммутатор должен использовать другой идентификатор, номер широковещательного канала BCN, для уникальной идентификации каждого соединения с групповой доставкой. Другими словами, номер широковещательного канала BCN соединения с групповой доставкой должен отличаться друг от друга, как и в случае с одноуровневыми адресами, где значение VCI может неоднократно использоваться для различных соединений на различных входных линиях. BCN может быть назначен в течение установления вызова или может быть определен, как комбинация номера входного порта и значения VPI/VCI.[5-9]
Для одноуровневой адресации, на момент прибытия ячейки, его значение VCI используется как индекс к доступу необходимой информация в таблице преобразования IPC, такой как адресация выхода в MGN1 и MGN2, установка значения приоритета, и нового VCI, как показано на рисунке 3.6, a. Адрес выхода MGN1, A1, сначала преобразуется в одноуровневый адрес, который состоит из K бит и помещен в область MP1 в заголовке ячейки, как показано на рисунке 3.7,a. Области MP1 и P используются для маршрутизации ячеек в MGN1, а A2 используется для маршрутизации ячеек MGN2. Бит I является битом признака групповой доставки, который установлен в 0 индивидуальной доставке и в 1 для групповой. Когда ячейка с индивидуальной доставкой поступает в MTT, поле A2 просто преобразуется в одноуровневый адрес и помещается в область MP2 как информация маршрутизации в MGN2.
Таким образом, никакой таблицы
преобразования для ячеек с индивидуальной доставкой в MTT не требуется.
Обратите внимание, что A2 - не преобразуется в одноуровневый адрес, пока не
достигает MTT. Это занимает определенное количество бит в заголовке ячейки
(например, для вышеупомянутого примера коммутатора емкостью 1024![]() 1024 требуется 27 бит), и таким образом
уменьшает требуемую скорость операций в коммутационной системе. Формат
маршрутизации ячейки с индивидуальной доставкой в MGN2 показан на рисунке
3.7,б.
1024 требуется 27 бит), и таким образом
уменьшает требуемую скорость операций в коммутационной системе. Формат
маршрутизации ячейки с индивидуальной доставкой в MGN2 показан на рисунке
3.7,б.
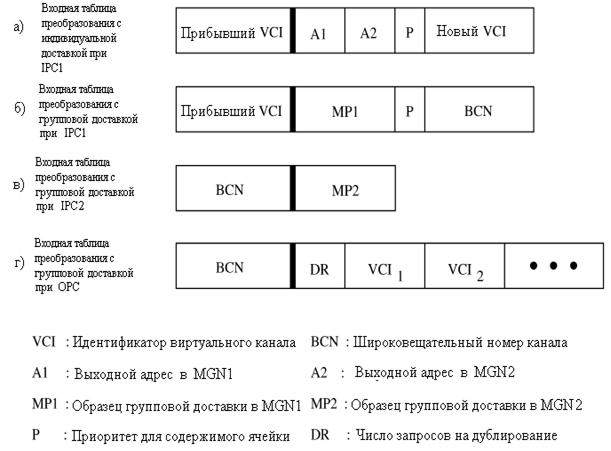
Рисунок 3.6 – Таблицы преобразования в IPC, MTT, и OPC
Для случая групповой доставки, перед информацией маршрутизации MP1, MP2, и P, используется BCN, для идентификации ячеек, которые направлены к той же самой группе выходов коммутационного модуля. Подобно случаю с индивидуальной доставкой, входящий VCI ячейки сначала используется, для просмотра информации об IPC в таблице преобразования, как показано на рисунке 3.6,б. После того, как ячейка прошла через MGN1, MP1 больше не используется. Вместо него используется BCN, для поиска следующей маршрутизационной информации MP2, в MTT, как показано на рисунке 3.6,в. Форматы ячеек с групповой доставкой в MGN1, и MGN2 показаны на рисунке 3.7,а и б. BCN далее используется в OPC, чтобы получить новый VCI для каждой дублированной копии, которая произведена дубликатором ячеек в OPC. Прохождение таблицы преобразования групповой доставки в OPC показано на рисунке 3.6,г.[4,5]
Обратите внимание MTT, которая связана с той же самой MGN2, содержит идентичную информацию, так как копия ячейки с групповой доставкой может появиться случайно на любом выходе L1M, соединенным с MGN2. По сравнению с [18,26] размер таблицы преобразования MTT намного меньше. Это связанно с тем, что копия ячейки с групповой доставкой может появиться только на одном из L1M выходов, связанных с MOBAS, против N связей в [18,26], что приводит к меньшему количеству входов таблицы в MTT. Так же, так как значения VCI копируемых копий не хранятся в MTT, содержание каждой входной таблицы в MTT также меньше.[5]
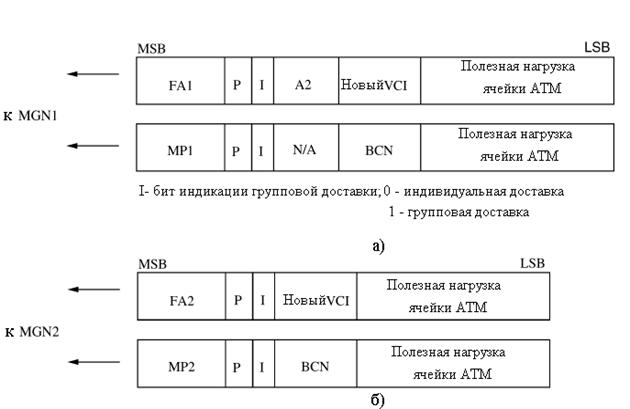
Рисунок 3.7 – Формат ячеек при индивидуальной и групповой доставке в MGN1(а), MGN2(б)
3.3 Принцип нокаута с групповой доставкой
Новый принцип нокаута с групповой
доставкой является расширенным принципом обобщенного нокаута, применяемый в
MOBAS с двумя ступенями, для обеспечения возможности стереофонического вещания.
Так как коммутационный модуль (SМ) в MGN
выполняет функции концентратора(например, N![]() L1M),
его иногда называют концентратором.
L1M),
его иногда называют концентратором.
3.4.1 Скорость потери ячейки в MGN1
При анализе делаются следующие
допущения: принимается, что нагрузка на каждом входе MOBAS независима от других
входов и копируемые ячейки однородно распределяются по всем группам выходов.
Средняя скорость прибытия ячейки (![]() )есть вероятность
того, что ячейка прибудет на входной порт в данном временном интервале.
Принимается, что среднее значение копирования ячейки в MGN1 – E[F1
], среднее значение копирования ячейки в MGN2 – E[F2 ], среднее
число дублирования ячейки в OPC – Е[D] и
случайные переменные F1, F2, и D независимы друг от
друга.[4]
)есть вероятность
того, что ячейка прибудет на входной порт в данном временном интервале.
Принимается, что среднее значение копирования ячейки в MGN1 – E[F1
], среднее значение копирования ячейки в MGN2 – E[F2 ], среднее
число дублирования ячейки в OPC – Е[D] и
случайные переменные F1, F2, и D независимы друг от
друга.[4]
Каждая поступающая ячейка передается ко всем концентраторам (SM) и должным образом фильтруется в каждом концентраторе согласно модели групповой доставки в заголовок ячейки. Средняя скорость прибытия ячейки, p на каждом входе концентратора равна:
 ,
,
где K =N/М-число концентраторов в MGN1.
Вероятность того, что k ячейки направлены в один и тот же концентратор MGN1, в данный временной интервал равна:
![]()
или
 , (3.1)
, (3.1)
где ![]() - вероятность того, что ячейки
прибудут на вход определенного концентратора в MGN1.[5]
- вероятность того, что ячейки
прибудут на вход определенного концентратора в MGN1.[5]
При ![]() 3.1 имеет следующий вид
3.1 имеет следующий вид
![]() (3.2)
(3.2)
где ![]() должна удовлетворить следующим
условиям для устойчивой системы:
должна удовлетворить следующим
условиям для устойчивой системы: ![]() .
.
Так как имеется только L1M маршрутизационных связей, доступных для каждой группы выходов, то, если для одной группы выходов в одном временном интервале будет предназначено больше, чем L1M ячеек, тогда избыточные ячейки будут отвергнуты и потеряны. Скорость потери ячейки в MGN1, P1 , является
 ,
(3.3)
,
(3.3)
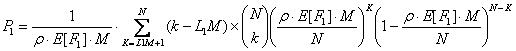 . (3.4)
. (3.4)
И
знаменатель, и числитель в формуле (3.3) имеют ![]() , для
того, чтобы учесть копирование ячейки в MGN2 и OPC. Другими словами, ячейка,
потерянная в MGN1, могла быть той ячейкой, которая должна была копироваться в MGN2
и OPC. Знаменатель в формуле (3.3),
, для
того, чтобы учесть копирование ячейки в MGN2 и OPC. Другими словами, ячейка,
потерянная в MGN1, могла быть той ячейкой, которая должна была копироваться в MGN2
и OPC. Знаменатель в формуле (3.3), ![]() является средним
числом ячеек, эффективно достигающих определенного концентратора в течение одного
временного интервала, а числитель в формуле (3.3),
является средним
числом ячеек, эффективно достигающих определенного концентратора в течение одного
временного интервала, а числитель в формуле (3.3), ![]() , является средним числом ячеек,
эффективно потерянных в определенном концентраторе.[15-20]
, является средним числом ячеек,
эффективно потерянных в определенном концентраторе.[15-20]
При ![]() 3.4 принимает вид:
3.4 принимает вид:
 . (3.5)
. (3.5)
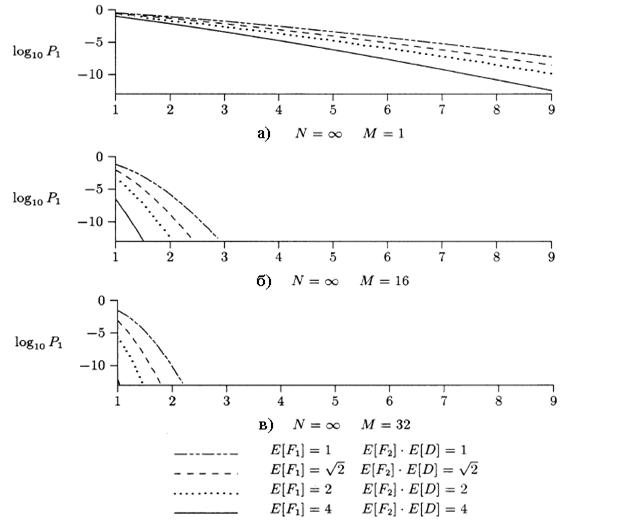
Рисунок 3.8 – Вероятность потери ячейки относительно коэффициента расширения группы L1 в MGN1
Обратите внимание, что выражение (3.5) подобно уравнению для обобщенного принципа нокаута, за исключением того, что параметры в этих двух уравнениях – слегка различны из-за копирования ячейки в MGN1 и MGN2 и дублирование ячейки в OPC.
Рисунок 3.8 показывает
графики вероятности потери ячейки в MGN1 от ![]() для
различных значений коэффициента разветвления по выходу и поступающей нагрузки
(равной
для
различных значений коэффициента разветвления по выходу и поступающей нагрузки
(равной ![]() ) 0.9 на каждый выходной порт. Можно
снова убедиться, что при увеличении М(то есть, большее количество
выходов распределяет свои маршрутизационные связи), требуемое значение L1
уменьшается для данной скорости потери ячейки. Требования к параметрам
проектируемого коммутатора М и L1 более строги для
ячеек с индивидуальной доставкой, чем для ячеек с групповой.
) 0.9 на каждый выходной порт. Можно
снова убедиться, что при увеличении М(то есть, большее количество
выходов распределяет свои маршрутизационные связи), требуемое значение L1
уменьшается для данной скорости потери ячейки. Требования к параметрам
проектируемого коммутатора М и L1 более строги для
ячеек с индивидуальной доставкой, чем для ячеек с групповой.
Таким образом, нагрузка на MGN1 уменьшается из-за среднего коэффициента разветвления по выходу в MGN2 и из-за увеличения OPC, скорость потери ячейки MGN1 в случае с групповой доставкой более низкая, чем в случае с индивидуальной.
Копируемые ячейки от запроса с групповой доставкой никогда больше не будут состязаться друг с другом за группу выходов того же самого концентратора, так как MOBAS копирует самое большее одну ячейку для каждой группы выходов. Другими словами,MGN1, которая разработана для того, чтобы удовлетворять требованию работы запроса с индивидуальной доставкой, также обслуживает запросы с групповой доставкой.[5]
3.4.2 Скорость потери ячейки в MGN2
Отдельного внимания требует анализ
скорости потери ячейки в MGN2, потому что прибытие копий ячейки на входы MGN2
определены числом ячеек, проходящих через соответствующий концентратор в MGN1.
Если имеется ![]() ячеек, прибывающих в MGN2, то эти ячейки
будут появляться в верхних
ячеек, прибывающих в MGN2, то эти ячейки
будут появляться в верхних ![]() последовательных
входах MGN2.[4,3]
последовательных
входах MGN2.[4,3]
Если больше, чем L1M, ячеек предназначены для MGN2, только L1M ячеек прибудет на входы MGN2 (одна ячейка на один вход), в то время как лишние ячейки будут отвергнуты ещё в MGN1.
Скорость потери ячейки концентратора в MGN2 принята Р2,
а вероятность того, что ![]() ячеек достигнет определенного
концентратора в MGN2 принята
ячеек достигнет определенного
концентратора в MGN2 принята ![]() .[5].
.[5].
Обе величины P2 и ![]() зависят от среднего числа ячеек,
достигающих входов MGN2 (то есть число ячеек, проходящих через определенный
концентратор в MGN1). Это подразумевает, что P2 - функция от
зависят от среднего числа ячеек,
достигающих входов MGN2 (то есть число ячеек, проходящих через определенный
концентратор в MGN1). Это подразумевает, что P2 - функция от ![]() в 3.1. В порядке вычисления P2,
вероятность того, что j ячеек достигнет MGN2, обозначена как
в 3.1. В порядке вычисления P2,
вероятность того, что j ячеек достигнет MGN2, обозначена как ![]() , и определяется как:
, и определяется как:
Если ![]() ячеек
достигнет MGN2, то они будут появляться на верхних j-ых последовательных входах
MGN2. Таким образом, как и где ячейки появляются на входах MGN2 не затрагивает
значение потери ячейки, и анализ может быть упрощен,
принимая, что ячейка может появиться на любом входе MGN2.
ячеек
достигнет MGN2, то они будут появляться на верхних j-ых последовательных входах
MGN2. Таким образом, как и где ячейки появляются на входах MGN2 не затрагивает
значение потери ячейки, и анализ может быть упрощен,
принимая, что ячейка может появиться на любом входе MGN2.
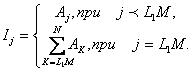
Если ![]() ячеек
достигнет MGN2, то они будут появляться на верхних j-ых последовательных входах
MGN2. Таким образом, как и где ячейки появляются на входах MGN2 не затрагивает
значение потери ячейки, и анализ может быть упрощен,
принимая, что ячейка может появиться на любом входе MGN2.
ячеек
достигнет MGN2, то они будут появляться на верхних j-ых последовательных входах
MGN2. Таким образом, как и где ячейки появляются на входах MGN2 не затрагивает
значение потери ячейки, и анализ может быть упрощен,
принимая, что ячейка может появиться на любом входе MGN2.
Обозначим ![]() вероятность
того, что
вероятность
того, что ![]() ячеек достигнет входов определенного
концентратора в MGN2 из
j ячеек, достигших MGN2.
Тогда:
ячеек достигнет входов определенного
концентратора в MGN2 из
j ячеек, достигших MGN2.
Тогда:
![]() ,
,
где q равно E[F2]/М согласно предположению, по которому копированные ячейки поступают равновероятно на М концентраторов в MGN2.[19]
Если не больше, чем L2
ячеек достигает MGN2 (![]() ), ни одна из
этих ячеек не будет снята в MGN2, потому что каждый концентратор может
принимать до L2 ячеек в течение одного временного интервала.
Если больше, чем L, ячеек достигают MGN2 (
), ни одна из
этих ячеек не будет снята в MGN2, потому что каждый концентратор может
принимать до L2 ячеек в течение одного временного интервала.
Если больше, чем L, ячеек достигают MGN2 (![]() ), потеря ячейки произойдет в каждом
концентраторе с некоторой вероятностью.
), потеря ячейки произойдет в каждом
концентраторе с некоторой вероятностью.
Так как принято, что копируемые
ячейки должны быть однородно распределены по всем М выходам в MGN2, то ![]() - вероятность того, что
l ячеек
предназначены для определенного выхода в MGN2 в одном временном интервале,
равна:
- вероятность того, что
l ячеек
предназначены для определенного выхода в MGN2 в одном временном интервале,
равна:
![]()
Скорость потери ячейки в MGN2 P2
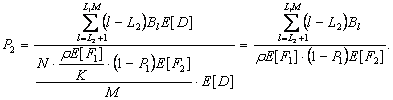 (3.6)
(3.6)
Здесь ![]() -
среднее число ячеек, предназначенных для концентратора в MGN1 от входов MOBAS;
-
среднее число ячеек, предназначенных для концентратора в MGN1 от входов MOBAS; ![]() - среднее число ячеек, которое прошли
этот концентратор и который в свою очередь становится средним числом ячеек,
достигших соответствующего концентратора в
MGN2.
- среднее число ячеек, которое прошли
этот концентратор и который в свою очередь становится средним числом ячеек,
достигших соответствующего концентратора в
MGN2.
Таким образом, знаменатель в формуле
(3.6) (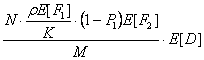 ) является средним числом ячеек,
эффективно достигающих определенного выхода. Числитель в формуле (3.6) (
) является средним числом ячеек,
эффективно достигающих определенного выхода. Числитель в формуле (3.6) (![]() ) является средним числом ячеек,
эффективных ячеек потерянных в определенном концентраторе в MGN2, так как
потерянная ячейка может быть дублированной OPC.[5,3]
) является средним числом ячеек,
эффективных ячеек потерянных в определенном концентраторе в MGN2, так как
потерянная ячейка может быть дублированной OPC.[5,3]
На рисунке 3.11 показаны графики
вероятности потери ячейки в MGN2 относительно L2 для
различных средних значений дублирования и обслуженной нагрузки равной 0.9 части
от ![]() . Средний коэффициент разветвления по
выходу на MGN1 принят равным 1,0(
. Средний коэффициент разветвления по
выходу на MGN1 принят равным 1,0(![]() ), размер группы 32 (М=32),
и коэффициент расширения 2,0 (L1=2,0 ).
), размер группы 32 (М=32),
и коэффициент расширения 2,0 (L1=2,0 ).
Так как нагрузка на MGN2 уменьшается
при увеличении дублирования ячеек(![]() ), то скорость потери
ячейки в MGN2 уменьшается при увеличении
), то скорость потери
ячейки в MGN2 уменьшается при увеличении ![]() .
Поэтому параметр проектируемого коммутатора L2 более
строго ограничивается при случае индивидуальной доставки, чем при
групповой. Соответственно, если MGN2 разработан, чтобы удовлетворять
требованиям запросов с индивидуальной доставкой, то он также будет
удовлетворять запросам с групповой доставкой.
.
Поэтому параметр проектируемого коммутатора L2 более
строго ограничивается при случае индивидуальной доставки, чем при
групповой. Соответственно, если MGN2 разработан, чтобы удовлетворять
требованиям запросов с индивидуальной доставкой, то он также будет
удовлетворять запросам с групповой доставкой.

Рисунок 3.9 – Вероятность потери ячейки относительно коэффициента расширения L2 в MGN2.
3.4.3 Общая скорость потери ячейки в MOBAS
Общая скорость потери ячейки в MOBAS равна:
![]() ,
,
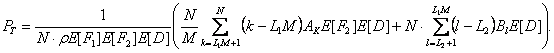 (3.7)
(3.7)
Первое слагаемое числителя ![]() выражения
(3.7) является средним числом эффективных ячеек, потерянных в MGN1.Второе
слагаемое числителя
выражения
(3.7) является средним числом эффективных ячеек, потерянных в MGN1.Второе
слагаемое числителя ![]() является общим средним числом
эффективных ячеек, потерянных в MGN2. Знаменатель в формуле (3.7),
является общим средним числом
эффективных ячеек, потерянных в MGN2. Знаменатель в формуле (3.7), ![]() представляет собой среднее число
эффективных ячеек, полученных из MOBAS. В 3.7 L1 и L2
должны быть выбраны в определенном диапазоне, чтобы гарантировать
требуемое значение потери ячейки в MOBAS. Например, чтобы получить скорость
потери ячейки 10-10 в MOBAS очень большого размера (
представляет собой среднее число
эффективных ячеек, полученных из MOBAS. В 3.7 L1 и L2
должны быть выбраны в определенном диапазоне, чтобы гарантировать
требуемое значение потери ячейки в MOBAS. Например, чтобы получить скорость
потери ячейки 10-10 в MOBAS очень большого размера (![]() ) и размерами групп М(= 32), L1
и L2 должны быть больше, чем два и
12, соответственно. Если любое из них - меньше чем требуемое число, общая
скорость потери ячейки в MOBAS не будет удовлетворять требованиям, начиная с
числителя формуле (3.7), который является функцией меньшего значения, тем самым
увеличивая общую скорость потери ячейки в MOBAS.[2-6]
) и размерами групп М(= 32), L1
и L2 должны быть больше, чем два и
12, соответственно. Если любое из них - меньше чем требуемое число, общая
скорость потери ячейки в MOBAS не будет удовлетворять требованиям, начиная с
числителя формуле (3.7), который является функцией меньшего значения, тем самым
увеличивая общую скорость потери ячейки в MOBAS.[2-6]
4 Отказоустойчивость коммутатора АТМ с выходным буфером и групповой доставкой
Отказоустойчивость является одним из главных аспектов при проектировании коммутаторов АТМ с высокой надежностью коммутации. В частности, так как скорость линии приближаются к 2,5 или 10 Гбит/с, отказ одного единственного элемента коммутатора в коммутационной системе прервет обслуживание всех связей, которые проходят через точку отказа. Несколько взаимоувязанных сетей, наряду с некоторыми методами, включая временную и пространственную избыточность, были предложены для достижения допуска отказа сети[1,11,27,12,15,29,17]. Метод временной избыточности использует стратегию много адресной маршрутизации, чтобы получить динамически полный доступ между входами и выходами. То есть осуществляется доступность любого выхода каждому входу при конечном числе рециркуляций через коммутационную сеть. Метод пространственной избыточности обеспечивает многократные тракты от каждого входа ко всем выходам, используя избыточное оборудование (коммутационные элементы, связи, или ступени)[16]. Это дополнительное оборудование увеличивает сложность системы и усложняет операции коммутатора.
Из-за наличия единственного тракта маршрутизации между любым входом и парой выходов в двоичных сетях с самомаршрутизацией, трудно достичь отказоустойчивости без добавления дополнительных плоскостей коммутации, ступеней, или коммутационных элементов. Как показано на рисунке 3.1, имеются многократные тракты между каждым входом и парой выходов. А они сильно зависят от отсутствия дефектных коммутационных элементов и внутренних отказов соединений. В этой главе мы рассмотрим различные методы диагностики ошибки, включая обнаружение повреждения и его местоположение, а также изменение конфигурации системы, изолируя дефектные коммутирующие элементы в MOBAS [5]. Регулярная структура MOBAS также упрощает диагностирование ошибки и изменение конфигурации системы при происхождении ошибки.
Ошибка в SWE может случаться в логической схеме управления или на линии передачи, данных к SWE. В последнем случае SWE останется в любом из двух состояний: перекрестном или сквозном; эти ошибки называются остановками в перекрестном или сквозном состоянии, соответственно. Если линия передачи данных замыкается или размыкается, выход SWE находится или в высоком, или низком состоянии; тогда это называется «застывшим в одном состоянии» (s-a-1) или «застывшим в нуле» (s-a-0). Ячейки, проходящие через дефектные связи, будут всегда искаженными. Отказ связи может происходить или в вертикальной, или в горизонтальной связи, и они соответственно называются вертикальными или горизонтальными. Примем SWE (i,j) за элемент, который находится в i-ой строке и j-ом столбце в коммутационной матрице SWE. Обозначим соответственно CS(i,j), TS(i,j) VS(i,j), и HS(i,j) как состояние перекрестной, сквозной, вертикальной и горизонтальной ошибки в SWE(i,j).[5,9]
Далее мы будем рассматривать отказы с единственной ошибкой, так как они встречаются с большей вероятностью в интегральных схемах, чем отказы с многократной ошибкой [2].
4.1.1 Состояние перекрестного отказа (CS)
Рисунок 4.1 показывает маршрутизацию ячейки в коммутационной матрице с перекрестной ошибкой в SWE (4,3) [заштрихованный и обозначенный CS(4,3)], где ячейка с севера всегда будет направляться на юг, а ячейка с запада - на восток. Если ошибка CS просквозит в последней колонке коммутационной матрицы SWE, как показано на рисунке 4.1, коэффициент потери ячейки уменьшается. Например, ячейка Х4 будет отвергнута из-за перекрестной ошибки в SWE(4,3) . Если имеется только три ячейки с первого по четвертый вход, принадлежащих одной группе выходов, одна из трех ячеек будет отвергнута в SWE(4,3), который соответственно влияет на уменьшение значения рабочих характеристик.
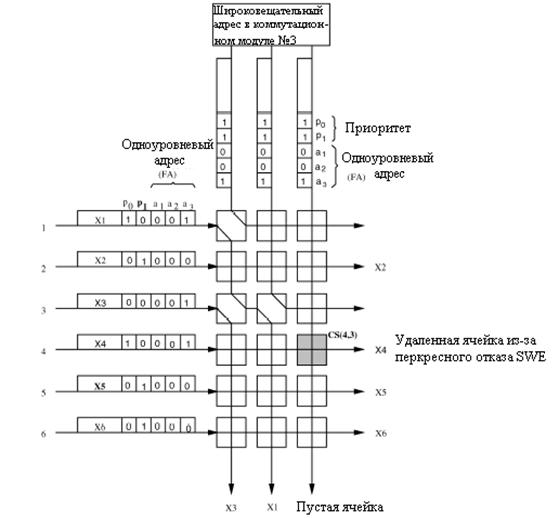
Рисунок 4.1 – Пример потери ячейки из-за перекрестной ошибки в SWE(4,3), обозначенной как CS(4,3)
Однако, если X4 – не третья ячейка, предназначенная для этой группы, или имеется больше чем три (число выходных связей) ячейки, предназначенных для этой группы, CS в последней колонке не будет влиять на коэффициент потери ячейки.[1]
4.1.2 Состояние сквозной ошибки (TS)
Рисунок 4.2 показывает, как SWE 4,2 в состоянии исходной ошибки воздействует на маршрутизацию ячейки в коммутационной матрице SWE. В отличие от перекрестной ошибки, исходная ошибка может привести к неправильной маршрутизации.
Если ячейка на западном входе SWE с исходной ошибкой на рисунке 4.2 не предназначена для этого выхода, выходная связь будет потрачена впустую, потому что связь по ошибке занята этим входом. Поэтому каждый вход, кроме этого входа, может повлиять на ухудшение рабочих характеристик. Например, на рисунке 4.2, ячейка X1 отвергнут из-за ошибки TS(4,2).[5,3]

Рисунок 4.2 – Пример потери ячейки из-за состояния перекрестной ошибки в SWE (4,2), обозначенная как TS(4,2)
4.1.3 Вертикально/горизонтальные ошибки (VS/HS)
Рисунок 4.3 показывает маршрутизацию ячейки в коммутационной матрице SWE, когда ошибка (s-a-1) или (s-a-0) находится в вертикальной связи SWE(4,2). Рисунок 4.4 показывает ошибку в горизонтальной связи. Ячейки, проходящие через этот дефектный SWE, всегда искажаются в любой вертикальной или горизонтальной связи. Это может причинить ретрансляцию данных и увеличение нагрузки и вероятность перегрузки сети.[5]
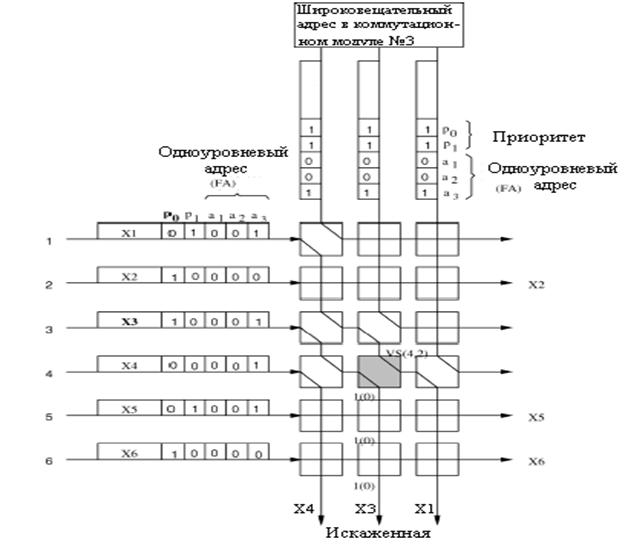
Рисунок 4.3 – Пример потери ячейки из-за вертикальной (s-a-1) или (s-a-0) ошибки в SWE(4,2), обозначенной как VS(4,2)
4.2 Обнаружение повреждения
Чтобы обнаружить ошибку, примем, что MTT, OPC, и горизонтальные выходы коммутационной матрицы SWE, где ячейки отвергнуты, имеют простую логическую схему, называемую указателями повреждений FD, которые способны обнаружить любую неправильную маршрутизацию ячейки в коммутационных модулях, и таким образом обеспечивается возможность обнаружения ошибки во время работы. Кроме того, MPMS и ABS используются для того, чтобы создавать испытательные ячейки, обнаруживающие дефектный SWE, как только ошибка обнаружена FD.
Диагностика ошибок и изменение конфигурации системы могут быть выполнены в любое время, когда необходимо, сохраняя ячейки пользователей в IPCS и прогоняя испытательные ячейки через коммутационную систему. Поскольку испытание может быть закончено в пределах двух временных интервалов, заголовок не будет влиять на обычные операции коммутатора.
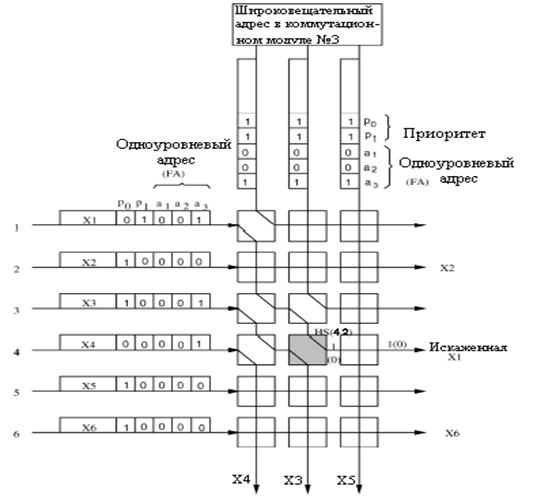
Рисунок 4.4 – Пример потери ячейки из-за горизонтальной (s-a-1) или (s-a-0) ошибки в SWE(4,2), обозначенный как HS(4,2)
FD в MTT или OPC, состоящих из k SМ, исследуют k бит одноуровневого адреса (ноль или единица) для определения неправильно направленной ячейки. Они также исследуют исходный адрес с помощью тестирующих ячеек, чтобы обнаружить дефектный SWE.[5]
4.2.1 Обнаружение перекрестного и исходного отказа
Отказ TS может быть обнаружен контролирующими ячейками, направленных к MTT или OPC. Если ячейка, направленная к MTT или OPC, имеет в FA все нули, то она рассматривается как неправильно направленная ячейкой. Так как любая ячейка со всеми нолями в FA не должна быть направлена на юг. Как показано на рисунке 4.2, когда ячейка X4 – неправильно направлена ко второму выходу, соответствующий FD обнаруживает эту ячейку, потому что ее весь FA равен 0.[16]
В то время как TS отказ может быть легко обнаружен во время работы, CS отказ не может быть обнаруженным во время работы. Этот отказ не будет вносить вклад в уменьшении качественных характеристик, если он не расположен в последней колонке.
4.2.2 Обнаружение вертикальных и горизонтальных отказов
VS и HS отказы может быть легко обнаружены, проверяя выходящий сигнал от коммутационной матрицы SWE единица (или ноль). Например, как показано на рисунке 4.3, сигнал от второй выходящей связи всегда единица (или ноль), который указывает, что один из SWE во второй колонке должен иметь отказ VS. Например, VS отказ произошел в SWE 4,2, все SWE ниже дефектного остаются в перекрестном состоянии, таким образом, будут определены отказы s-2-0 и s-2-1 на южном выходе из дефектной колонки. Ячейки, которые будут достигать южных выходов или будут ячейками от пользователя, или пустыми ячейками от AB. Они имеют образцы, состоящие или из всех нулей или из всех единиц в их заголовках (состоящих из FA и приоритетных полей). Таким образом, если ячейка появляется на южном выходе и имеет образец из всех нулей или всех единиц, то это не что иное, как VS отказ.[20]
Рисунок 4.4 показывает, что сигнал от четвертого вышедшего из строя выхода всегда единица (или ноль) и что должен иметь место HS отказ в четвертом ряду. Как только происходит HS отказ, например, SWE (4,2), все SWE справа от дефектного остаются в перекрестном состоянии таким образом, что отказы s-a-0 и s-a-1 могут быть обнаружены на восточном выходе дефектного ряда. Ячейки, которые достигают восточных выходов могут быть ячейками от пользователя, пустыми ячейками от AB или незанятых ячеек от IPC. Если даже принять, что адресная область незанятых ячеек установлена во все нули, в то время как приоритетная область установлена во все единицы, соответствующие самому низкому приоритету. Тогда ячейка, появившаяся на восточном выходе и имеющая образец, состоящий из всех нолей или из всех единиц, должен иметь место HS отказ.[5]
4.3 Местоположение ошибки и изменение конфигурации
Как только ошибка обнаружена, нам
требуется большое количество информации, чтобы локализовать ошибку и изменить
конфигурацию коммутационной сети. Само обнаружение повреждения обеспечивает частичной
информацией местоположение дефектного SWE (например, мы можем
идентифицировать или ряд или колонку). Для того, чтобы изменить конфигурацию
сети должным образом, мы должны знать точное место расположения HS SWE и TS
SWE. Для
VS отказа нам требуется только информация о колонке. Тестирующая
ячейка, состоящая из FA области, с новой приоритетной областью, и с новым
входным источником адресного поля, производится MPM или AB для того, чтобы
обнаружить ошибку. Её FA область имеет ту же самую длину, как и стандартная
ячейка, формирующаяся в MOBAS. Новая приоритетная область длиною в ![]() бит в MGN1 и
бит в MGN1 и ![]() бит в
MGN2. Адресное поле входного источника имеет
бит в
MGN2. Адресное поле входного источника имеет ![]() бит в
MGN1 и
бит в
MGN1 и ![]() бит в MGN2.[1-3,5]
бит в MGN2.[1-3,5]
4.3.1 Случаи сквозного и перекрестного отказов
Выполняя операцию по локализации ошибки при TS отказе, параллельно определяется дефектная колонка. Для того чтобы определить дефектный ряд, нам надо определить местоположение теста(называемого TS тестом) для TS отказа. Рисунок 4.5 показывает пример TS теста.
Ячейки, идущие от MPM, вынуждены иметь отличный FA от тех, которые идут от AB; таким образом, все SWE в коммутационной матрице установлены в перекрестное состояние. В результате чего все ячейки от MPM в безотказном состоянии появляются в восточной стороне коммутационной матрицы, в то время как от AB появляются в южной стороне. Если имеется TS отказ в SWE(i,j), ячейки от MPM будут доставлены в j-ую выходную связь, в то время как ячейки от j-ой колонки AB направляются к i-тому неисправному выходу.[19]
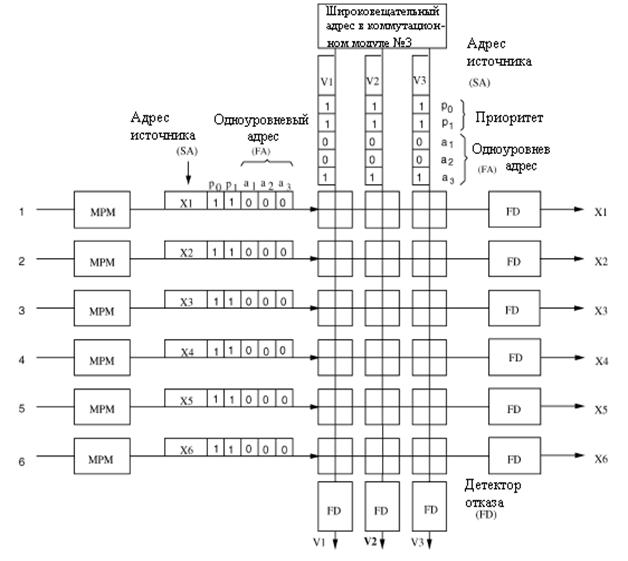
Рисунок 4.5 – Тест местоположения исходного отказа SWE с принужденным изменением состояния всех SWE в сквозное
Как только мы точно локализовали TS отказ, зная (i,j), мы можем изменить конфигурацию коммутационной матрицы, устанавливая SWE(i,j) в перекрестное состояние, как показано на рисунке 4.6.
Эта измененная конфигурация коммутационной матрицы имеет тот же самый коэффициент потери ячеек как и коммутационная матрица с CS отказом в (i,j) элементе.[15]
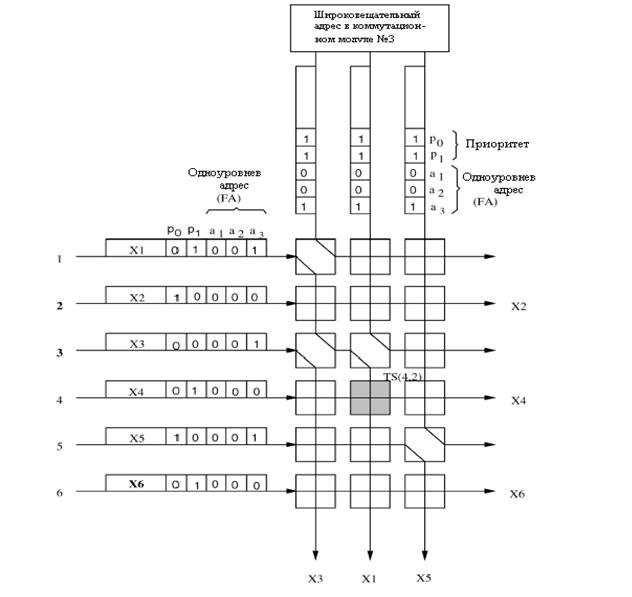
Рисунок 4.6 – Изменение конфигурации сети при переводе SWE (4,2) в сквозное состояние
Как было упомянуто выше, CS отказ не может быть обнаружен в режиме работы. Однако, так как CS ситуация может рассматриваться как изменение конфигурации при TS отказе, нам не требуется определять местоположение CS отказа (хотя он может быть определен и обнаружен с помощью нескольких шагов автономных испытаний, как описано далее).
Если мы добавляем еще один бит к приоритетной области и изменяем установку приоритетных областей тестовых ячеек, мы можем автономно обнаружить и определить CS отказ в коммутационной матрице. Метод определения CS отказа состоит в том, чтобы вынудить все SWE в заштрихованном квадратном блоке на рисунке 4.7 переключиться в сквозное состояние, в то время как остальная часть SWE установлена в перекрестное состояние. Если в этом квадратном блоке существует элемент с CS отказом, то мы будем способны идентифицировать его местоположение, контролируя выходы. Перемещая квадратный блок по коммутационной матрице и повторяя тестовую процедуру, мы можем определить, имеется ли CS отказ и определить его местоположение (если таковой имеется).
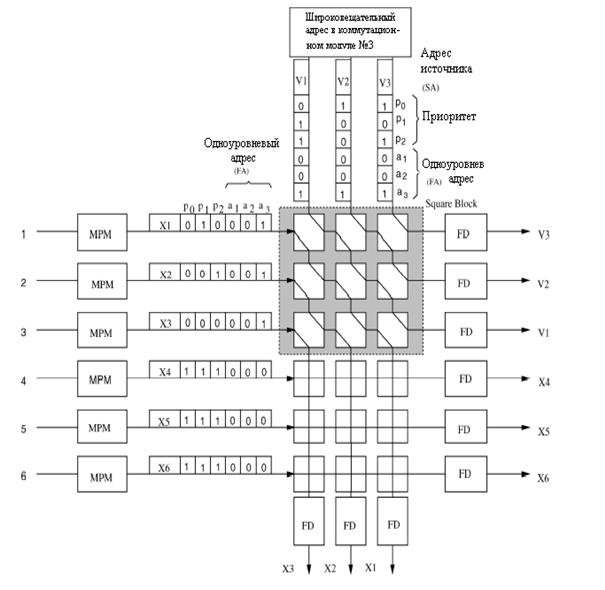
Рисунок 4.7 – Тест определяющий перекрестный отказ в SWE, использующий перемещение квадратного блока в коммутационной матрице.
Рисунок 4.7 показывает пример
определения местоположения ошибки при CS отказе. Этот тест может также
использоваться, чтобы определить место положение коммутационного элемента с HS
отказом. Для диагностирования SWE в трех высших рядах, приоритеты тестовых
ячеек X3, X2, X1, V1, V2 и V3 установлены в уменьшающемся порядке. Все эти ячейки FA создает
идентичными, в отличие от тестовых ячеек X4, X5 и X6 которые отличны друг от
друга. Тест CS отказа вынуждает все SWE в квадратном блоке (3![]() 3 в этом примере) перейти в сквозное
состояние, а все остальные SWE в перекрестное состояние. Если существует CS
отказ в этом квадратном блоке, образец выхода будет отличаться от ожидаемого.
Для автономного испытания коммутационного модуля требуется, минимум
3 в этом примере) перейти в сквозное
состояние, а все остальные SWE в перекрестное состояние. Если существует CS
отказ в этом квадратном блоке, образец выхода будет отличаться от ожидаемого.
Для автономного испытания коммутационного модуля требуется, минимум ![]() тестов в MGN1 и
тестов в MGN1 и ![]() тестов
в MGN2.[5]4.3.2. В случае вертикальных и горизонтальных отказов.[1,4,5,17]
тестов
в MGN2.[5]4.3.2. В случае вертикальных и горизонтальных отказов.[1,4,5,17]
Итак, при наличии VS или HS отказов в коммутационной матрице, ячейки, которые проходят через дефектный SWE, будут искажены, как показано на рисунке 4.3 и рисунке 4.4 . Если VS отказ обнаружен FD в MTT или OPC, информация относительно дефектной колонки немедленно становиться известна. Эта информация достаточна для изменения конфигурации коммутационной сети.[3]
Например, если j-ая колонка содержит VS, j=2 на рисунке 4.3, все коммутационные элементы в j-ой колонке вынуждаются к перекрестному состоянию, таким образом, получается j-ая колонка становится изолированной. Например, рисунок 4.8 показывает изменение конфигурации со второй изолированной колонкой. Конечно, коэффициент потери ячейки увеличивается из-за сокращения доступных маршрутизационных связей.
Отдельное внимание необходимо уделить HS отказу, потому что мы должны точно определить место положения дефектного SWE до требуемого изменения конфигурации. Как только HS отказ обнаружен, мы получаем информацию относительно дефектного ряда автоматически. А нам требуется информация о колонке. Чтобы определить место положение отказа, нам требуется запустить тест локализации отказа (HS тест).[5,17-22]
HS тест в тестовых ячейках в FA устанавливает приоритет и адрес источника в значениях, при которых все SWE дефектного ряда вынуждаются к переключению в сквозное состояние. Рассмотрим HS тест для i-ого ряда коммутационной матрицы. Одноуровневый адрес тестовых ячеек от всех MPM, кроме i-ого MPM, установлены в нули (для рассогласования целей), в то время как FA тестовых ячеек от i-ого MPM установлены идентично с тестовыми ячейками от AB. Все адреса источников тестовых ячеек установлены в свои номера ряда или номера колонки, в зависимости от расположения в коммутационной матрице горизонтально или вертикально.
Приоритеты тестовых ячеек от i-ого MPM и широковещательные тестовые ячейки от AB установлены в порядке уменьшения. Обычно приоритет тестовых ячеек от i-ого MPM самый высокий, следующий приоритет имеет широковещательная тестовая ячейка первой колонки, следующий приоритет имеет широковещательная тестовая ячейка от второй колонки и так далее.
Таким образом, ячейка от i-ого MPM будет появляться на первой выходной связи, в то время как широковещательная ячейка от r-ого AB будет появляться на (r+1)-ой выходной связи или на i-ом вышедшем из строя выходе. FD на выходных связях исследуют исходный адрес поля SA, чтобы определить дефектную колонку, которая содержит коммутационный элемент с HS отказом.
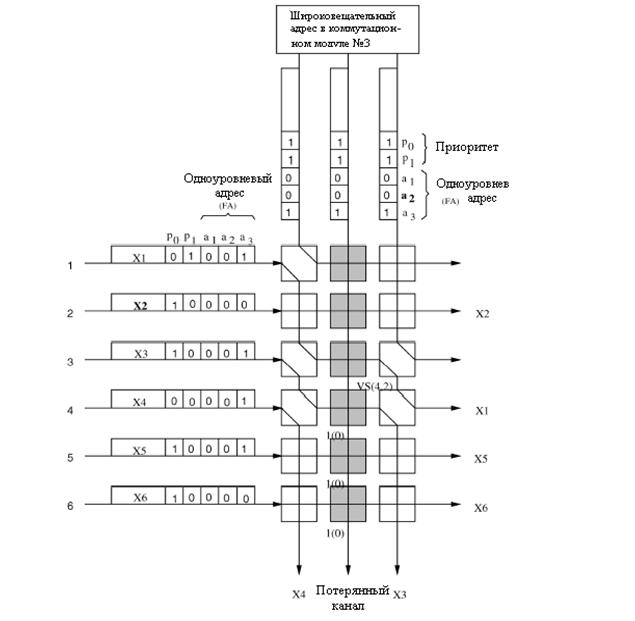
Рисунок 4.8 – Изменение конфигурации, по средствам изолирования дефектной колонки, в которой находиться элемент
SWE 4,2 с вертикальным отказом
Если таковой будет иметь j-ая
колонка, то тестовая ячейка от
i-ого MPM
будет появляться на первой выходной связи, и широковещательная тестовая ячейка
Vr от r-ого AB
![]() будет появляться на (r+1)-ой выходной связи.
Широковещательная тестовая ячейка Vj от j-ого
AB будет искажена и появится на
i-ом вышедшем из строя выходе.
Широковещательная тестовая ячейка, Vj+sот (j+s)-ого
AB
будет появляться на (r+1)-ой выходной связи.
Широковещательная тестовая ячейка Vj от j-ого
AB будет искажена и появится на
i-ом вышедшем из строя выходе.
Широковещательная тестовая ячейка, Vj+sот (j+s)-ого
AB ![]() будет появляться на (j+s)-ой выходной
связи.
будет появляться на (j+s)-ой выходной
связи.
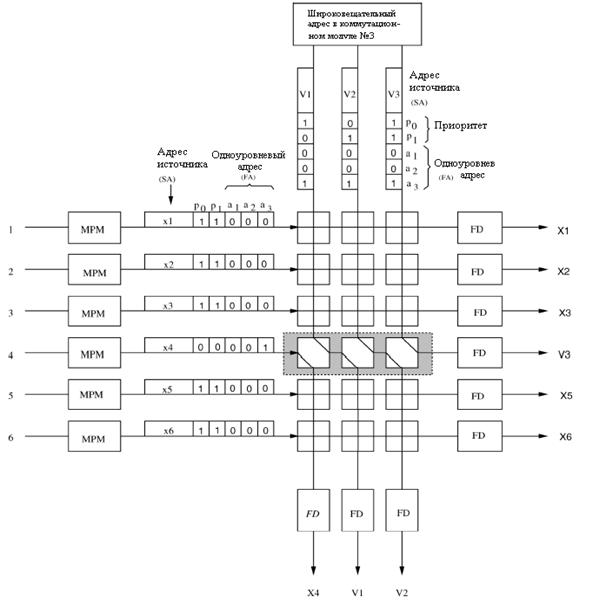
Рисунок 4.9 – Тест локализации отказа для горизонтального отказа, который вынуждает SWE в дефектном ряду к переключению в сквозное состояние
Если коммутационный элемент с HS отказом находится в последней колонке, тестовая ячейка от r-ого AB будет появляться на (r+1)-ой выходной связи, и широковещательная тестовая ячейка от самого правого AB будет появляться на i‑ом выходе от вышедшего из строя коммутационного элемента и будет искажена.
Рисунок 4.9 показывает пример теста, где коммутационный элемент с HS отказом находится в четвертом ряде и все элементы в четвертом ряду вынуждены переключиться в сквозное состояние для определения HS отказа.[3,5,27-30]
Например, если HS отказ будет в SWE (4,2), то ячейка V3 вместо ячейки V2 должна будет появиться на 3 выходе; ячейка V2, которая будет искажена, должна будет появиться на 4-ом выходе коммутационного элемента, вышедшего из строя.
После обнаружения HS отказа, в SWE(i,j), мы сможем
изменить конфигурацию сети, вынуждая SWE(i,j) к
переключению в сквозное состояние, а другие коммутационные элементы, в той же
самой колонке и выше дефектного SWE ![]() , к переключению в
перекрестное состояние так, чтобы на ячейки не воздействовал HS отказ в SWE(i,j). На рисунке
4.10 показан пример изменения конфигурации сети при HS отказе в
, к переключению в
перекрестное состояние так, чтобы на ячейки не воздействовал HS отказ в SWE(i,j). На рисунке
4.10 показан пример изменения конфигурации сети при HS отказе в
SWE(4,2).
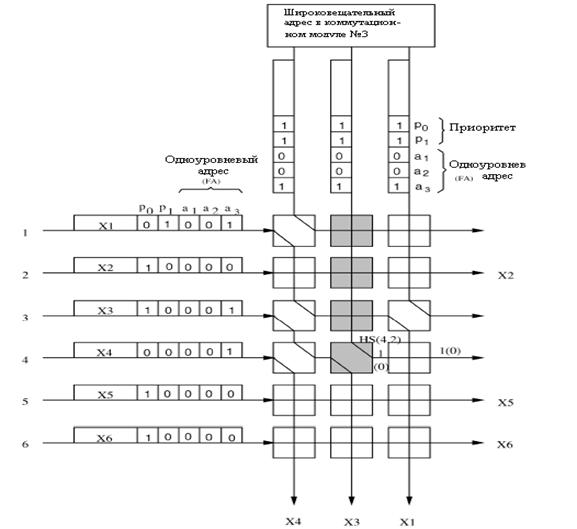
Рисунок 4.10 – Изменение конфигурации по средствам изолирования верхней колонки с горизонтальным отказом в SWE(4,2)
4.4 Анализ работы модуля с измененной конфигурацией
В этом подразделе, мы рассмотрим
ухудшение рабочих характеристик коммутационного модуля при условиях отказа.
Будут произведены расчеты скорости потери ячейки отдельного входа при различных
отказах. Для простоты примем, что коммутационный модуль имеет коммутационную
матрицу размерностью ![]() , и все поступающие ячейки в
которую имеют одинаковый приоритет или выше относительно широковещательных
ячеек от AB и что нагрузка, поступающая на каждый входной порт MOBAS, не зависит от
нагрузки на других входах. Средняя скорость поступления ячеек:
, и все поступающие ячейки в
которую имеют одинаковый приоритет или выше относительно широковещательных
ячеек от AB и что нагрузка, поступающая на каждый входной порт MOBAS, не зависит от
нагрузки на других входах. Средняя скорость поступления ячеек:![]() - это
вероятность того, что ячейка прибудет на вход в данный временной интервал.
Также принимается, что ячейки однородно адресуются ко всем выходам и что
имеется только связь «точка-точка», которая определяет самый плохой случай
анализа. В результате нагрузка на каждом входе коммутационном модуле имеет
распределение, идентичное распределению Бернули, со средней
скоростью поступления ячеек, равной
- это
вероятность того, что ячейка прибудет на вход в данный временной интервал.
Также принимается, что ячейки однородно адресуются ко всем выходам и что
имеется только связь «точка-точка», которая определяет самый плохой случай
анализа. В результате нагрузка на каждом входе коммутационном модуле имеет
распределение, идентичное распределению Бернули, со средней
скоростью поступления ячеек, равной ![]() .[1-6,12,13]
.[1-6,12,13]
![]() - это скорость потери ячейки
k входов с коэффициентом расширения L при безотказном состоянии.
Скорость потери ячейки входов, число которых не более L, равна нулю, что
означает, что ячейки от этих входов всегда доставляются успешно, это можно обозначить
как:
- это скорость потери ячейки
k входов с коэффициентом расширения L при безотказном состоянии.
Скорость потери ячейки входов, число которых не более L, равна нулю, что
означает, что ячейки от этих входов всегда доставляются успешно, это можно обозначить
как:
![]()
Скорость потери ячейки остальных входов, от входа L+1 до N:


![]() определена
как скорость потери ячейки k входов с коэффициентом расширения L
с дефектным SWE коммутационным элементом. Заметьте, что скорость потери ячейки,
обсуждаемая здесь,
не для всего MOBAS, а только для коммутационного элемента,
который имеет дефектный SWE.
определена
как скорость потери ячейки k входов с коэффициентом расширения L
с дефектным SWE коммутационным элементом. Заметьте, что скорость потери ячейки,
обсуждаемая здесь,
не для всего MOBAS, а только для коммутационного элемента,
который имеет дефектный SWE.
4.4.1 Случай перекрестного и сквозного отказов
Как было сказано выше, TS отказ может быть изолирован посредством переключения коммутационного элемента с TS отказом в перекрестное состояние, которое походит на возникновение CS отказа в этом SWE, рисунок 4.6. Таким образом, оказываемый эффект на потерю ячейки при CS и TS при отказах одинаков. Мы будем анализировать только потери ячейки в коммутационном модуле при CS отказе.
Если CS отказ произошел в SWE(i,j) не в
последней колонке ![]() , то ухудшение рабочих
характеристик мы наблюдать не будем. Когда он происходит в последней колонке
, то ухудшение рабочих
характеристик мы наблюдать не будем. Когда он происходит в последней колонке ![]() , CS отказ не влияет на потерю ячейки на
входах, исключая те, которые находятся в том же самом
ряду.[5]
, CS отказ не влияет на потерю ячейки на
входах, исключая те, которые находятся в том же самом
ряду.[5]
Для CS![]() отказа
только один входной образец прибытия вносит вклад в ухудшение рабочих характеристик.
Это происходит тогда, когда имеется точно L ячеек, предназначенных для
этого выхода. Среди этих L-1 ячейки от 1 до
отказа
только один входной образец прибытия вносит вклад в ухудшение рабочих характеристик.
Это происходит тогда, когда имеется точно L ячеек, предназначенных для
этого выхода. Среди этих L-1 ячейки от 1 до ![]() входов;
одна ячейка от входа
i, и никаких ячеек от i+1 до N
входов
входов;
одна ячейка от входа
i, и никаких ячеек от i+1 до N
входов ![]() . Среднее
число дополнительно
потерянных ячеек, AL(i), из-за дефектного SWE (i,j) зависит от
расположения ряда
i, в котором произошел отказ:
. Среднее
число дополнительно
потерянных ячеек, AL(i), из-за дефектного SWE (i,j) зависит от
расположения ряда
i, в котором произошел отказ:
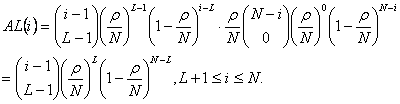
Обратите
внимание, что дефектный SWE(i,L)(i![]() L-1) никак не
влияет на ухудшение параметра потери ячейки. Из перекрестного состояния
измененной конфигурации для дефектного SWE (i,L) скорость
потери ячейки каждого входа следующая:
L-1) никак не
влияет на ухудшение параметра потери ячейки. Из перекрестного состояния
измененной конфигурации для дефектного SWE (i,L) скорость
потери ячейки каждого входа следующая:

где P(A) - вероятность события A,


Вероятность P(A) рассматривается как улучшение скорости потери ячейки для k входов.
На
рисунке 4.11 показана скорость потери ячейки каждого входа после того, как
коммутационная матрица изменила конфигурацию. Здесь использован MOBAS с одной
ступенью размером 64![]() 64 и коэффициентом расширения L=12.
64 и коэффициентом расширения L=12.
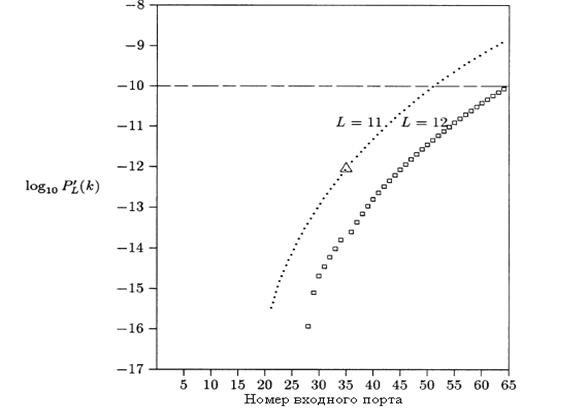
Рисунок 4.11 – Скорость потери ячейки каждого входа после перекрестного изменения конфигурации
Дефектный SWE принят SWE(35,12). Для тех входов, которые находятся выше дефектного входа 35, скорость потери ячейки является той же самой, как в безотказном случае, в то время как у дефектного входа скорость потери ячейки равняется такому же безотказному случаю, но с L=11. Входы ниже дефектного от 36 до 64 имеют почти те же самые скорости потери ячейки как в безотказном случае, так как усовершенствование P(A) очень маленькое.
4.4.2 Случай вертикального отказа
Когда имеется коммутационный элемент с VS отказом в j-ой колонке, все SWE в этой колонке будут вынуждены переключиться в перекрестное состояние для изолирования j-ой колонки, как показано на рисунке 4.8 (j=2). Это изолирование колонки предотвращает ячейки от искажения, но уменьшает доступные маршрутизационные связи с L до L-1.
Поэтому, после изменения конфигурации, скорость потери ячейки каждого входа – слегка увеличивается к следующему значению:
![]()
Обратите внимание, что эффект на ухудшение рабочих характеристик потери ячейки независим от расположения дефектной связи. Скорость потери ячейки после изменения конфигурации равняется безотказному случаю при L=11, независимо от положения ряда с дефектной связью.
5 Характеристики трафика в ШЦСИО. Требования к качеству обслуживания в транспортной среде ATM
5.1 Характеристики трафика в ШЦСИО
Широкий диапазон скоростей передачи, от нескольких сот бит/с до сотен Мбит/с, существенный статистический характер информационных потоков, большое разнообразие сетевых конфигураций – все эти факторы значительно усложняют описание трафика в современных информационных системах по сравнению с классическими сетями связи [1, 7].
Важным требованием, возникшим из-за необходимости экономически эффективного построения ШЦСИО, является требование гибкого изменения ширины полосы пропускания канала между пунктами передачи и приема информации. Пакетная коммутация ATM технологии с предварительным выбором виртуальных путей и каналов обеспечивает плавное изменение ширины полосы пропускания канала практически на любую величину [8], вплоть до использования всей сети для передачи информации между двумя заданными пунктами. По мере необходимости увеличения ширины полосы пропускания канала между определенными пунктами передачи информации в сети виртуальные пути, передачи захватывают все большую и большую часть сети аналогично тому, как во время наводнения потоки воды захватывают все больше и больше площади.[5]
Физическая природа значительных диапазонов
изменения характеристик случайных процессов передачи битового графика в
значительной мере обусловлена нерегулярностью генерации информации источником.
Периоды «раздумий» чередуются с периодами «активности». Обработка больших
объемов информации в современных территориально распределенных информационных
системах и различный темп (замедление или ускорение) ее направления от верхних
уровней к передающей транспортной среде позволяют проводить аналогии с
физическими кинематическими системами. Данное обстоятельство позволяет ввести в
рассмотрение для каждой
k-й службы случайный процесс ![]() передачи объема (количества) битовой
информации и его двух первых производных – битовых скорости
передачи объема (количества) битовой
информации и его двух первых производных – битовых скорости ![]() и ускорения
и ускорения ![]() ,
которые тоже являются случайными процессами.
,
которые тоже являются случайными процессами.
Будем характеризовать каждую службу скоростью, с которой источник формирует (генерирует) битовую информацию. При этом необходимо отметить, что скорость поступления во многом определяется способом кодирования и сжатия данных и, следовательно, зависит от умения осуществлять обработку сигналов, достигнутого уровня технологии и стоимости обработки.
Генерирование информации источником в самом
общем виде может быть представлено с помощью стохастического процесса ![]() , изображенного на рисунке 5.1.
Процесс передачи информации продолжается в течение отрезка времени Т.
Это может быть длительность ведения телефонного разговора, сеанс взаимодействия
с ЭВТ для передачи данных, сессия видеоконференции и т.д. Стохастический
процесс можно характеризовать [1]:
, изображенного на рисунке 5.1.
Процесс передачи информации продолжается в течение отрезка времени Т.
Это может быть длительность ведения телефонного разговора, сеанс взаимодействия
с ЭВТ для передачи данных, сессия видеоконференции и т.д. Стохастический
процесс можно характеризовать [1]:
- максимальной (пиковой)
скоростью передачи источника k-й службы ![]() ;
;
- средней скоростью
передачи источника k-й службы  ;
;
- соотношением между
пиковой и средней скоростью источника k-й службы, т. е. коэффициентом
пачечности или пачечностью ![]() ;
;
- средней длительностью
пика ![]() .
.

Рисунок 5.1 – Процесс генерирования информации источником с изменяющейся скоростью передачи
Очевидно, что даже для одной службы стохастический процесс от сеанса к сеансу может протекать по- разному, но пиковая и средняя скорость передачи, а также коэффициент пачечности или пачечность достаточно полно характеризуют службу. Пачечность речевых служб, в основном, связана с периодом активности абонента и паузами в разговоре, каждый из которых, как правило, продолжается около 50% времени.
Одним из ключевых понятий в описании широкополосных сетей является скорость передачи службы, определяемая в рекомендациях ITU-T по ШЦСИО как скорость передачи информации, доступная пользователю данной службы. В соответствии с этой характеристикой все службы ШЦСИО можно разделить на две категории: с постоянной скоростью передачи (ПСП) и с изменяющейся скоростью передачи (ИСП).
Службы с ИСП могут быть разделены на службы
стартстопного и непрерывного типов. Для стартстопных служб с ИСП характерно
наличие в информационном потоке периодов активности и пауз
(информационно-поисковые системы): скорость передачи в таких системах меняется
скачком от нуля до ![]() .
.
В службах с ИСП непрерывного типа скорость передачи в течение сеанса связи меняется плавно (цифровая видеотелефония со статистическим кодированием).
При решении задачи распределения сетевых ресурсов между различными службами, абонент каждой службы характеризуется, с одной стороны, традиционными параметрами трафика:
- интенсивностью
входящего потока заявок на предоставление услуг
k-й службы ![]() , выз/час;
, выз/час;
- средней длительностью
сеанса связи ![]() , с ;
, с ;
-
удельной интенсивностью
нагрузки ![]() ,
,
а, с другой стороны, параметрами, упомянутого выше случайного процесса, но характеризующими конкретного абонента k-й службы ШЦСИО (определены Рек. ITU-T I.311):
- пиковой (максимальной)
битовой скоростью передачи ![]() ;
;
- средней битовой
скоростью передачи ![]() ;
;
- пачечностью ![]() , определяемую отношением
, определяемую отношением ![]() ;
;
- средним временем пика ![]() .
.
Службы с ПСП характеризуются тем, что на всей
длительности сеанса связи скорость передачи информации ![]() пиковая
скорость) остается постоянной (например, цифровая телефония без обнаружения
пауз и использования статистического уплотнения).
пиковая
скорость) остается постоянной (например, цифровая телефония без обнаружения
пауз и использования статистического уплотнения).
Исследования служб распределения информации
могут привести к необходимости введения новых разновидностей классов трафика.
Здесь также не рассматриваются системы передачи неподвижных изображений, в
которых используются системы кодирования с переменной скоростью. Есть основания
полагать, что в таких системах отношение ![]() будет
меняться во время вызова
в достаточно широких пределах так же, как и длительность пачек со скоростью
будет
меняться во время вызова
в достаточно широких пределах так же, как и длительность пачек со скоростью ![]() . Вместе с тем даже представленные
характеристики трафика свидетельствуют о том, что проектирование систем
распределения ресурсов и динамического управления для ШЦСИО является сложной
задачей [1, 6, 9, 10]. Ясно, что ресурс для каждого нового соединения может
предоставляться до тех пор, пока выполняются требования к качеству связи. Сети
связи
ATM для удовлетворения
требований к качеству связи со стороны пользователей должны иметь такие
свойства, как семантическая и временная прозрачность.
. Вместе с тем даже представленные
характеристики трафика свидетельствуют о том, что проектирование систем
распределения ресурсов и динамического управления для ШЦСИО является сложной
задачей [1, 6, 9, 10]. Ясно, что ресурс для каждого нового соединения может
предоставляться до тех пор, пока выполняются требования к качеству связи. Сети
связи
ATM для удовлетворения
требований к качеству связи со стороны пользователей должны иметь такие
свойства, как семантическая и временная прозрачность.
По оценкам экспертов [1, 6] для различных видов широкополосных служб требуются следующие скорости передачи информации: цветное ТВ - 4...6 Мбит/с, ТВВЧ - 16...24 Мбит/с, черно-белое факсимиле - 1...4 Мбит/с, полутоновое факсимиле - 30...60 Мбит/с, цветное факсимиле - 30...60 Мбит/с, машинная графика с высокой разрешающей способностью - 20...100 Мбит/с, пересылка файлов-до сотен мегабит в секунду [1].
На начальной стадии оборудование ATM будет служить основой сетей, предназначенных, главным образом, для передачи данных. Поэтому сеть ATM должна обеспечивать поддержку как существующих, так и появляющихся служб передачи данных Х.25, Frame Relay и службы коммутируемой передачи данных (SMDS -Switched Multimegabit Data Service).
SMDS введена как высокоскоростная служба передачи данных пакетного типа без установления соединения со скоростью до 45 Мбит/с, а в будущем - до 155 Мбит/с. Она использует схему адресации, определенную СС МСЭ в Рек. Е.164. Европейская версия SMDS называется широкополосной службой передачи данных, не ориентированной на соединение (CBDC - Connectionless Broadband Data Service).
Сеть ATM с первых дней своего существования служит основой для объединения различного типа локальных вычислительных сетей. Поэтому на начальном этапе, когда локальные сети ATM только начинают внедряться, ШЦСИО на технологии ATM должна поддерживать объединения ныне существующих локальных и городских вычислительных сетей типа Ethernet, Fast Ethernet, Token Ring, FDDI (Fiber Distributed Data Interface), DQDB (Distributed Queue Dual Bus) в национальные и глобальные сети.
Другой услугой, которая должна предоставляться сетями ATM на самом начальном этапе их внедрения, является эмуляция каналов, т.е. возможность предоставления пользователям аренды каналов с постоянной скоростью Е1 на 2048 кбит/с, ЕЗ на 34,368 Мбит/с, DS1 на 1544 кбит/с, DS2 на 6,312 Мбит/с и DS3 на 44,736 Мбит/с.
Большим преимуществом сетей на технологии ATM для сетевых операторов является ее гибкость, позволяющая поддерживать как все существующие, так и будущие службы. Хотя технология ATM и ориентирована на соединения, она обладает достаточно гибкими возможностями переноса информации всех служб, включая и службы, не ориентированные на соединения (службы CL).
5.2 Основные положения проблемы управления графиком в сетях ATM
Концепция широкого внедрения сетевых технологий получила наиболее полное отражение при создании цифровых сетей интегрального обслуживания, обеспечивающих объединение большого числа различных служб в рамках единой сети. Разработка принципов построения и создания ведомственных (корпоративных), а также национальных и глобальных широкополосных цифровых сетей интегрального обслуживания общего пользования является главным направлением развития электросвязи в большинстве стран мира.
Применение новой технологии переноса информации - метода ATM, основанного на статистическом способе разделения пропускных способностей цифровых трактов связи и производительности коммутационного оборудования в совокупности с интеграцией служб в рамках единой сети и единого метода переноса информации различных служб с существенно отличающимися требованиями к параметрам семантической и временной прозрачности сети, ставят ряд новых задач, связанных с динамическим управлением сетевыми ресурсами, контролем и управлением потоками и защитой от перегрузок.
Настоящий раздел посвящен рассмотрению принципов функционирования основных механизмов управления сетевыми ресурсами, контроля и управления потоками и защиты от перегрузок ШЦСИО, построенных на технологии ATM.
Под сетевыми ресурсами здесь и далее будем понимать [1, 6,10]:
- полосу пропускания цифровых трактов связи;
- производительность узлов коммутации;
- емкость буферных накопителей, обеспечивающих промежуточное хранение пакетов ATM (ячеек) при их транспортировании через сеть.
Управление ресурсами в ШЦСИО должно обеспечивать выполнение следующих основных функций:
- борьбу с перегрузками;
- выбор оптимальных путей передачи информации (маршрутизацию).
В данном разделе основное внимание уделено первым трем механизмам управления ресурсами.
Опыт создания и эксплуатации сетей связи различного назначения показал, что система динамического управления потоками является обязательным условием системы управления сетью. Под управлением потоками понимается совокупность механизмов, управляющих порядком доступа пользователей к сетевым ресурсам и обеспечивающих согласование возможностей сети с потребностями пользователей.
Основной целью системы управления потоками является предотвращение и устранение перегрузок и разрешение тупиковых ситуаций, возникающих в результате перегрузок. При этом система управления потоками должна функционировать так, чтобы были обеспечены условия оптимального распределения ресурсов [1, 6, 11] и гарантированы требуемые показатели качества обслуживания пользователей.
Под перегрузкой принято понимать такое состояние сети, при котором основные показатели качества обслуживания начинают быстро ухудшаться.
Перегрузки могут возникать как на отдельных участках сети (так называемые локальные перегрузки), так могут охватывать и всю сеть (глобальные перегрузки).
В сетях с промежуточным накоплением при перегрузках наблюдается резкий рост очередей в отдельных узлах сетей. Если при этом отсутствует механизм контроля, то это может привести к невозможности доступа пользователей к ресурсам отдельных участков или зон, а в отдельных случаях- и к ресурсам всей сети в целом. Такое состояние может быть определено как блокировка сети. При явлении блокировки число обслуженных пакетов стремится к нулю, а задержки - к бесконечности.
Причинами перегрузок могут быть:
- резкое увеличение входного трафика;
- блокировка терминалов на приемной стороне;
- ограниченные объемы памяти коммутационного оборудования;
- недостаточные значения производительности коммутационного оборудования и пропускной способности трактов связи;
- выходы из строя по различным причинам линейного и станционного оборудования и т. п.
Основной задачей системы управления потоками является предотвращение явления блокировки и увеличение доли обслуженного потока путем уменьшения вероятности блокировки при наступлении перегрузки. Введение механизмов контроля потоков позволяет существенно улучшить поведение сети в области больших нагрузок и повысить реальную производительность сети.
5.3 Защита от перегрузок в сетях ATM
Разработка механизмов управления ресурсами и защиты от перегрузок в сетях ATM представляет собой сложную и многоплановую задачу.
Новые подходы и методы ее решения обусловлены следующими особенностями сетей ATM:
- необходимостью удовлетворения требований пользователей к полосе пропускания и качеству обслуживания для очень широкого диапазона применений;
- в отличие от традиционных пакетных сетей, узким местом в высокоскоростных сетях ATM является не время передачи по каналу, а скорость обработки пакетов в узлах коммутации и время распространения сигналов.
Функционирование механизмов динамического управления ресурсами и защиты от перегрузок в ШЦСИО на технологии ATM должно отвечать следующим основным целям:
- гарантировать всем принятым соединениям удовлетворения требований к полосе пропускания (скорости обслуживания) и качеству обслуживания;
- обеспечивать простоту функционирования и реализации;
- обеспечивать устойчивость функционирования сети и ее элементов в неординарных условиях, локализацию отказов оборудования и перегрузок;
- обеспечивать высокую эффективность использования сетевых ресурсов.
5.4 Соглашение по трафику между пользователем и сетью
5.4.1. Классы качества обслуживания
Для каждого соединения виртуальных путей (англ. Virtual Path Connection - VPC) и соединения виртуальных каналов (англ. Virtual Channel Connection - VCC) должно заключаться отдельное соглашение по графику, которое, в сущности, является соглашением между пользователем и сетью на интерфейсе пользователь-сеть (англ. User-Network Interface - UNI) no следующим пунктам [1, 11]:
- параметры трафика, определяющие характеристики потока ячеек источника;
- качество обслуживания, предоставляемое сетью;
- правила проверки соответствия реальных параметров трафика источника заявленным;
- определение сетью соединения, представляемого для транспортирования трафика.
Качество обслуживания существенно зависит от выполнения сетью своих обязательств по доставке ячеек, которые приняты при установлении соглашения по трафику. Качество обслуживания должно оцениваться на приемном конце, т. е. с точки зрения пользователя, как отношение числа ячеек, являющихся конформными, к общему числу отправленных источником ячеек. При этом под конформными ячейками принято понимать ячейки ATM, которые удовлетворяют принятым соглашениям по трафику. Для упрощения процесса запроса со стороны абонентов качества обслуживания установлены классы качества обслуживания.
Классы качества обслуживания принято определять для каждого соединения виртуальных путей или соединения виртуальных каналов согласно Рек. 1.350 СС МСЭ с помощью следующих параметров [1]:
- вероятности (коэффициента) потери ячеек при нулевом значении поля приоритета потери ячеек (CLP=0);
- вероятности (коэффициента) потери ячеек при значении поля приоритета потери ячеек равном единице (CLP=1);
- среднего времени задержки ячеек для общего потока ячеек (CLP =0+1);
- разброса времени задержки для общего потока ячеек (CLP=0+1).
Термин "Общий поток (CLP=0+1)" относится ко всем ячейкам в виртуальном соединении.
Форумом ATM в настоящее время определены следующие классы качества обслуживания:
- первый класс качества обслуживания, обеспечивающий выполнение требований служб класса А. Этот класс качества обслуживания должен обеспечивать характеристики, сравнимые с характеристиками, которые обеспечиваются в настоящее время при аренде цифровых каналов и трактов;
- второй класс качества обслуживания, обеспечивающий выполнение служб класса В. Этот класс качества обслуживания предназначен для мультимедийных приложений при транспортировании видео и аудио информации с изменяющейся скоростью передачи;
- третий класс качества обслуживания, обеспечивающий выполнение требований к качеству обслуживания служб класса С. Этот класс качества обслуживания предназначен для службы передачи данных, ориентированных на соединение (например, Frame Relay);
- четвертый класс качества обслуживания, обеспечивающий выполнение требований к качеству обслуживания служб класса D. Этот класс предназначен для служб передачи данных без установления соединения (например, IP или SMDS).
Необходимо отметить, что сетевой оператор имеет право обеспечивать одинаковое качество обслуживания для всех или какой-нибудь группы классов качества обслуживания, так как выполнение сетью требования 1-го класса качества обслуживания означает выполнение требования для всех других классов.
Для соединений, в которых не требуется высокое качество обслуживания, класс качества обслуживания может не задаваться. Для таких соединений, которые можно назвать "на грани риска" (At Risk), сеть предоставляет оставшиеся сетевые ресурсы от тех соединений, которые задавали параметры трафика. Следует отметить, что это позволяет операторам сети повысить эффективность использования сетевых ресурсов, а потребителям, которым в силу ряда причин не нужно очень высокое качество обслуживания, сеть как бы предоставляет возможность сделать "лучшую попытку" (Best Effort), т. е. рискнуть.
Важной особенностью услуги «лучшая попытка» является то, что пользователь должен быть готов к тому, что выделяемые ему сетевые ресурсы могут изменяться в очень больших пределах как от сеанса к сеансу, так и во время сеанса.
Услугу этого типа принято называть незаданной или не специфицированной скоростью передачи (UBR - Unspeccified Bit Rate), хотя с полным основанием ее можно называть, встав на точку зрения пользователя, и как неопределенная или негарантированная скорость передачи.
Услуга, предоставляемая сетью с контролем потока ячеек пользователя и с адаптацией к складывающейся обстановке, Форумом ATM названа как доступная скорость передачи (ABR -Available Bit Rate), предоставляемая сетью пользователю.
5.4.2 Описание трафика
Под описанием или дескриптором трафика принято понимать перечень параметров, охватывающих основные его характеристики. Параметры трафика должны иметь физическую сущность и быть измеряемыми.
К основным параметрам трафика ячеек отнесены:
- пиковая скорость (PCR - Peak Cell Rate), измеряемая количеством ячеек, генерируемых источником, за единицу времени (секунду);
- поддерживаемая скорость (SCR - SustainabI Cell Rate), которая всегда меньше или равна пиковой скорости;
- допустимый разброс значений времени задержки в секундах;
- максимальный размер (длина) пачки в ячейках (MBS -Maximum Burst Size).
При этом Форумом ATM пиковая скорость, как параметр графика, рассматривается совместно с допустимым разбросом времени задержки ячеек, а поддерживаемая скорость - с максимальным размером пачки.
Допустимое значение разброса времени задержки ![]() . Этот параметр трафика обычно не может
быть определен пользователем, но может быть измерен в сети, в том числе и как
количество ячеек, которое может быть направлено получателем источнику за
время
. Этот параметр трафика обычно не может
быть определен пользователем, но может быть измерен в сети, в том числе и как
количество ячеек, которое может быть направлено получателем источнику за
время ![]() на скорости линии доступа (источника)
на скорости линии доступа (источника) ![]() .
.
Максимальный размер пачки, который принято измерять количеством ячеек, генерируемых источником на пиковой скорости MBS.
Максимальная длительность пачки может быть определена следующим образом
![]() .
.
Поддерживаемая скорость (SCR), которая является, по существу, скоростью передачи
пачки максимального размера, которую генерирует источник трафика типа
"вкл.-выкл." за время интервала ![]() между
пачками
между
пачками
![]() ,
где
,
где ![]() , - минимальный
интервал между пачками;
, - минимальный
интервал между пачками;
Необходимо отметить, что данные определения и соотношения очень полезны в понимании трафика, но далеко не все они принимают участие в соглашении по трафику.
Так СС МСЭ в Рек. 1.371 определена только пиковая скорость источника. Форум ATM добавил также к определению поддерживаемую скорость и максимальный размер пачки, что позволяет более точно производить расчет числа мультиплексируемых источников при заданном уровне потери ячеек.
5.5 Основные требования к качеству обслуживания и особенности измерения транспортной среды ATM
5.5.1 Семантическая прозрачность
Под семантической прозрачностью принято понимать способность сети обеспечивать доставку информации от источника до адресата с приемлемым для данной службы уровнем ошибок [1].
Типы ошибок и их количество во многом определяются способом передачи информации и физической природой канала.
Ни одна система передачи не является идеальной. В реальных каналах действуют искажения сигналов, замирания, шумы, различные помехи, которые в дискретном канале проявляются в виде ошибок, определяющих верность приема информации.
Одним из наиболее часто используемых показателей, которым принято характеризовать качество цифровых систем передачи, является коэффициент двоичных ошибок (BER - Bit Error Rate), который представляет собой отношение между ошибочно принятыми битами к общему количеству переданных бит. При передаче за достаточно большой (репрезентативный) интервал времени коэффициент двоичных ошибок сходится к вероятности ошибочного приема двоичного символа (вероятности ошибки на бит)

где ![]() – число ошибочно принятых двоичных
символов;
– число ошибочно принятых двоичных
символов;
![]() – общее число переданных бит.
– общее число переданных бит.
В сетях, ориентированных на пакетную передачу, биты формируются в пакеты. Поэтому в качестве показателя, характеризующего качество передачи пакетов, принято использовать вероятность приема пакета с ошибками или вероятность искажения пакета (PER - Packet Error Rate)
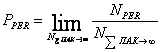
где ![]() – число пакетов, принятых с ошибками;
– число пакетов, принятых с ошибками;
![]() – общее число переданных пакетов.
– общее число переданных пакетов.
Ошибки в общем случае могут привести к разным последствиям. В некоторых случаях пакеты могут потеряться, а в других случаях поступать не по назначению.
Потеря пакетов может происходить из-за ошибок при маршрутизации или вследствие перегрузок. Вероятность потери пакета (PLR - Packet Loss Rate) есть отношение количества утраченных пакетов к общему количеству переданных за достаточно большой промежуток времени

где ![]() – число потерянных пакетов;
– число потерянных пакетов;
![]() – общее число
переданных пакетов.
– общее число
переданных пакетов.
Иногда пакеты могут поступать адресату, которому они не предназначены. Будем называть такие случаи доставкой пакета не по адресу (вставкой пакета). Вероятность доставки пакета не по адресу (PIR - Packet Insertion Rate) есть количество пакетов, доставленных не по адресу, за достаточно большой интервал времени наблюдения

где ![]() – число пакетов, доставленных не по адресу;
– число пакетов, доставленных не по адресу;
![]() – число пакетов, принятых за интервал
t.
– число пакетов, принятых за интервал
t.
Природа этих ошибок во многом определяется техническими устройствами, в которых они возникают.
Ошибки, зависящие от систем передачи, определяются, в основном, физической средой (коаксиальная линия, волоконно-оптическая линия и взаимосвязанные с ними системы передачи) и рядом других факторов (видом кодирования, скремблирования и т.д.).
5.5.2 Временная прозрачность сети
Под временной прозрачностью сети принято понимать ее свойство обеспечивать значение времени задержки и джиттера задержки, при которых обеспечивается требуемое качество обслуживания.
Временную прозрачность принято оценивать двумя показателями: временем задержки и джиттером задержки.
В сети ATM задержка может быть различной для каждого пакета ATM и представляет собой случайную величину (cл.в.). Случайная величина задержки в виртуальном соединении может быть выражена следующим образом:
![]()
где М – число звеньев в виртуальном соединении;
N – число узлов коммутации;
![]() –
cл.в. времени
пакетизации;
–
cл.в. времени
пакетизации;
![]() –
cл. в. времени
распространения сигнала в i-м звене;
–
cл. в. времени
распространения сигнала в i-м звене;
![]() –
cл.в. времени обслуживания пакета
ATM в
j -м
коммутационном устройстве при условии отсутствия очереди;
–
cл.в. времени обслуживания пакета
ATM в
j -м
коммутационном устройстве при условии отсутствия очереди;
![]() –
cл.в. времени ожидания в очереди пакета
ATM в j –м
коммутационном устройстве.
–
cл.в. времени ожидания в очереди пакета
ATM в j –м
коммутационном устройстве.
В сетях ATM процессы доставки пакетов в отдельных звеньях сети и обработки в различных коммутационных устройствах можно считать независимыми, что позволяет среднее значение и дисперсию времени задержки пакета ATM между отправителем и получателем на основании теорем о числовых характеристиках независимых случайных величин выразить следующим образом [1,12,13]:
![]()
![]() , (5.1)
, (5.1)
где ![]()
![]()
Задержки при пакетизации, на распространение сигнала и при обслуживании пакета ATM в коммутационных устройствах могут считаться для данного виртуального соединения практически постоянными, что дает нам право записать
![]() (5.2)
(5.2)
С учетом (5.2) выражение (5) для дисперсии времени задержки может быть сведено к виду
![]() ,
,
а для среднего квадратического отклонения времени задержки
![]()
т. е. джиттер задержки определяется только очередями в коммутационных устройствах ATM.
Для устранения джиттера задержки для интерактивных служб в оконечном оборудовании предполагается осуществлять дополнительную задержку пакетов ATM. Однако, если джиттер задержки некоторых пакетов ATM будет превосходить установленную величину дополнительной задержки, то такие пакеты не успеют включиться в процесс депакетизации и будут потеряны.
Выбор значения времени дополнительной задержки пакетов интерактивных служб определяется двумя противоречивыми факторами:
- с одной стороны при большом значении времени задержки при депакетизации представляется возможным реализовать малую вероятность потери пакетов ATM по времени в процессе депакетизации;
- с другой стороны при большом времени задержки при депакетизации тяжело реализовать в сети ATM нормативные значения задержек пакетов ATM.
Исследования, проведенные в [30], показывают, что вероятность потери пакетов по времени в процессе депакетизации не должна превышать
![]()
Время задержки
на депакетизацию при заданном значении вероятности потери пакета может быть
найдено как квантиль ![]() порядка
порядка ![]() [15,31,32,33] при котором
[15,31,32,33] при котором
![]()
где W(t) - функция распределения суммарного времени ожидания в М коммутационных устройствах.
В этом случае временную прозрачность сети ATM для интерактивных служб можно характеризовать временем задержки, при котором вероятность потери пакета ATM по времени не превосходит допустимого (нормативного) значения
![]()
где ![]() порядка
порядка ![]() .
.
При этом должно выполняться еще одно условие
![]()
т. е. задержка в сети не должна превышать нормативное значение.