Некоммерческое акционерное общества
АЛМАТИНСКИЙ УНИВЕРСИТЕТ ЭНЕРГЕТИКИ И СВЯЗИ
Кафедра автоматической электросвязи
ТЕХНОЛОГИИ ПАКЕТНОЙ КОММУТАЦИИ
Конспект лекций, часть 2
для студентов специальности
5В071900 – Радиотехника, электроника и телекоммуникации
Алматы 2013
Составители: Чежимбаева К.С.,.Калиева С.А. Технологии пакетной коммутации. Конспект лекций для студентов специальности 5В071900 – Радиотехника, электроника и телекоммуникации. - Алматы: АУЭС, 2013.- 50 с.
Конспект лекций приведен краткий курс лекций по дисциплине «Технологии пакетной коммутации» для специальности «Радиотехника, электроника и телекоммуникации». Конспект лекций преследует цель краткого изложения теоретических основ дисциплины для освоения студентами современной технологии пакетной коммутации.
Ил. 22 , табл. 3 , библиогр.-11 назв.
Рецензент: Башкиров М.В.
Печатается по плану издания некоммерческого акционерного общества «Алматинский университет энергетики и связи» на 2013 г.
© НАО «Алматинский университет энергетики и связи», 2013 г.
Введение
Целью дисциплины «Технологии пакетной коммутаций» является изложение принципов и методов проектирования и анализа современных сетевых технологий с коммутацией пакетов и их научных основ; уяснить закономерности эволюции и конвергенции современных сетей телекоммуникации. Она углубляет и развивает подготовку инженеров, овладевающих современной технологией построения телекоммуникационных сетей с коммутацией пакетов, знакомит с концепцией построения сетей следующего поколения, принципами построения мультисервисных сетей. Основная задача курса «Технологии пакетной коммутаций»:
- обучить студентов теоретическим знаниям и принципам построения цифровых сетей с коммутацией пакетов, а также привить им практические навыки по методологии составления протоколов и их взаимодействия;
- обучить методам определения соответствия характеристик сети растущим требованиям информационных технологий и приложений;
- обучить методам технической эксплуатации коммутационных систем и цифровых сетей.
В процессе обучения студенты должны приобрести:
- знания принципов и методов сопряжения цифровых систем передачи и коммутации и их функционирование в реальных сетевых технологиях, технической реализации узлов коммутации и цифровых сетей;
- умение выполнить проектно-конструкторские и расчетные работы по созданию и внедрению в эксплуатацию сетей различного назначения;
- умение анализировать и составлять протоколы обмена различных уровней;
- навыки самостоятельного проведения исследований, изучения и проработки технического задания, технической литературы.
По данной дисциплине проводятся лекционные и практические занятия, проводятся лабораторные работы, кроме того, предполагается выполнение расчетно-графических работ с применением компьютера и проведение самостоятельных работ с целью углубления общих знаний теории.
1 Лекция. Качество передачи речевой информации по IP-сети
Цель лекции: изучение факторов, влияющие на качество IP-телефонии.
IP-телефония является одной из областей передачи данных, где все процессы передачи информации должны происходить в режиме реального времени и где особенно важна динамика передачи сигнала, которая обеспечивается современными методами кодирования и передачи информации; в результате увеличивается пропускная способность каналов по сравнению с традиционными телефонными сетями.
Хорошо изучены факторы, влияющие на качество IP-телефонии. Они могут быть разделены на две категории:
1) Качества IP-сети характеризуют:
- максимальная пропускная способность — максимальное количество данных, которая она передает;
- задержка — промежуток времени, требуемый для передачи пакета через сеть;
- джиттер — задержка между двумя последовательными пакетами;
- потеря пакета — пакеты или данные, потерянные при передаче через сеть.
2) Качества шлюза характеризуют:
- требуемая полоса частот пропускания;
- задержка — время, необходимое сигнальному процессору DSP для кодирования и декодирования речевого сигнала;
- объем буфера джиттера для сохранения пакетов данных до тех пор, пока все пакеты не будут получены; затем можно будет передать часть речевой информации в требуемой последовательности и таким образом минимизировать джиттер;
- возможность потери пакетов — потеря пакетов при сжатии и/или передаче в оборудовании IP-телефонии;
- наличие функции подавления эха, возникающего при передаче речи по сети.
В сетях IP протокол управления передачей (TCP) может решить проблему нарушения порядка следования пакетов данных из-за установления последовательности передачи и использования подтверждений, однако для передачи голоса используется протокол дейтаграмм пользователя (UDP), а не TCP. Применение протокола UDP в технологии VoIP обусловлено тем, что у посылающего устройства нет необходимости перед отправкой последующих пакетов дожидаться подтверждения от принимающего устройства. Данные VoIP отправляются тем же способом, который используется при отправке аудио- или видеоданных в сети Интернет. Потеря небольшого количества голосовых пакетов считается приемлемой и может быть компенсирована с помощью механизма кодирования/декодирования, а также различных методов интерполяции речи.
Задержка и меры по уменьшению ее влияния. Организация ITU-T серьезно занималась исследованием проблем, связанных с задержками при передаче голоса по сети. В результате был разработан стандарт ITU-T G.114, который рекомендует, чтобы задержка при передаче голоса в одном направлении не превышала 150 миллисекунд.
Также стандарт рекомендует рассматривать задержку от 150 до 400 миллисекунд как приемлемую, если говорящий и слушающий понимают наличие задержки и готовы с ней смириться. В том случае, когда задержка достигает 400 миллисекунд и более, она становится заметной. Для сравнения можно привести общение через спутник, задержка при передаче по спутниковой связи в одном направлении составляет примерно 170 миллисекунд. Стандарт также устанавливает, что при передаче голоса задержка более чем 400 миллисекунд является неприемлемой.
Возможны случаи, когда при передаче речи по IP-сети возникают намного большие, чем в СТОП, задержки, которые, к тому же, изменяются случайным образом. Задержка (или время запаздывания) определяется как промежуток времени, затрачиваемый на то, чтобы речевой сигнал прошел расстояние от говорящего до слушающего.
Покажем, что и как оказывает влияние на количественные характеристики этого промежутка времени.
Можно выделить следующие причины задержки при передаче речи от источника к приемнику:
a) Задержка накопления: эта задержка обусловлена необходимостью сбора кадра речевых отсчетов, выполняемая в речевом кодере. Величина задержки определяется типом речевого кодера и изменяется от небольших величин (0,125 мкс) до единиц миллисекунд.
b) Задержка обработки: процесс кодирования и сбора закодированных отсчетов в пакеты для передачи через пакетную сеть создает определенные задержки. Задержка кодирования или обработки зависит от скорости работы процессора и используемого типа алгоритма обработки.
Сетевая задержка: задержка обусловлена физической средой и протоколами, применяемыми для передачи речевых данных, а также буферами, используемыми для удаления джиттера пакетов на приемном конце.
Важно отметить тот факт, что задержки в сетях с коммутацией пакетов влияют не только на качество передачи речевого трафика в реальном времени. Не менее существенно, что данные задержки в определенных ситуациях могут нарушить правильность функционирования телефонной сигнализации в цифровых трактах типа E1/T1 на стыке голосовых шлюзов с оборудованием коммутируемых телефонных сетей.
Источники задержки при передаче речи по IP-сети представлены на рисунке 1.
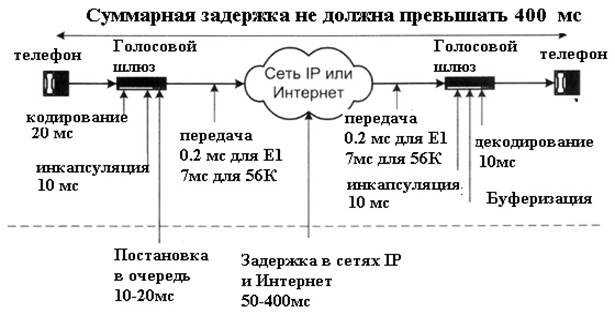
Рисунок 1 - Источники задержки при передаче речи по IP-сети
Кодеки IP-телефонии. Наибольшее распространение получили кодеки следующих типов. Основные характеристики кодеков представлены в таблице 1. Кодек G.711 — один из первых цифровых кодеков речевых сигналов, который является минимально необходимым. Это означает, что любое устройство VoIP должно поддерживать этот тип кодирования.
Т а б л и ц а 1- Основные характеристики кодеков
|
Кодек |
Метод компрессии |
Скорость кодирования |
Сложность реализации |
Качество |
Задержка |
|
G.726 |
ADPCM |
32/24/16 кбит/с |
низкая (8 MIPS) |
хорошее (32К), плохое (16 К) |
Очень низкая (0,125 мс) |
|
G.729 |
CS-ACELP |
8 кбит/с |
высокая (30 MIPS) |
хорошее |
Низкая (10 мс) |
|
G.729A |
CA-ACELP |
8 кбит/с |
Умеренная (20 MIPS) |
среднее |
Низкая (10 мс) |
|
G.723.1 |
MP-MLQ |
6.4/5.3 кбит/с |
умеренная (16 MIPS) |
хорошее (6,4), среднее (5,3) |
Высокая (37 мс) |
|
G.728 |
LD-CELP |
16 кбит/с |
очень высокая (40 MIPS) |
хорошее |
Очень низкая (3-5 мс) |
Кодек G.723.1 предусматривает две скорости передачи: 6.3 кбит/с и 5.3кбит/с. Режим работы может меняться динамически от кадра к кадру. Для этих кодеков оценка MOS (Mean Opinion Score) составляет 3,9 в режиме 6.3кбит/с и 3,7 - в режиме 5.3 кбит/с.
Кодек G.726 обеспечивает кодирование цифрового потока со скоростью 40, 32, 24 или 16 кбит/с, гарантируя оценки MOS на уровне 4,3 (32кбит/с), что принимается за эталон уровня качества телефонной связи (toll quality). Однако в приложениях IP-телефонии этот кодек практически не используется, так как он не обеспечивает достаточной устойчивости к потерям информации.
Кодек G.728 специально разрабатывался для оборудования уплотнения телефонных каналов, при этом было необходимо обеспечить, возможно, малую величину задержки (менее 5 мс), чтобы исключить необходимость применения эхокомпенсаторов.
Кодек G.729 очень популярен в приложениях передачи речи по сетям Frame Relay. Кодек использует кадр длительностью 10 мс и обеспечивает скорость передачи 8 кбит/с. Однако для кодера необходим предварительный анализ сигнала продолжительностью 5 мс.
Современная аппаратура IP-телефонии применяет разные кодеки, как стандартные, так и нестандартные. Конкурентами являются кодеки GSM (13,5 кбит/с) и кодеки МСЭ-Т серии G, использование которых предусматривается стандартом H.323 для связи по IP-сети. Оценка качества воспринимаемой информации и значения MOS для различных стандартов кодеров приведены в таблице 2.
Т а б л и ц а 2 - Средние субъективные оценки качества различных методов кодирования
|
Скорость передачи, кбит/с |
MOS |
Размер кадра, мс |
|
|
G.711 РСМ |
64 |
4,3 |
0,125 |
|
G.726 Multi-rate ADPCM |
16-40 |
2-4,3 |
0,125 |
|
G.723 MP-MLQ ACELP |
5.3; 6.3 |
3,7; 3,8 |
30 |
|
G.728 LD-CELP |
16 |
4,1 |
0,625 |
|
G.729 CS-ACELP |
8 |
4,0 |
10 |
|
G.729A CA-ACELP |
8 |
3,4 |
10 |
|
GSM RPE-LPC |
13 |
3,9 |
30 |
В каналах Интернета важными для IP-телефонии параметрами являются следующие:
- действительная пропускная способность, определяемая наиболее "узким местом" в виртуальном канале в данный момент времени;
- временная задержка пакетов, которая определяется трафиком, числом маршрутизаторов, реальными физическими свойствами каналов передачи, образующими в данный момент времени виртуальный канал, задержками на обработку сигналов, возникающими в речевых кодеках и других устройствах шлюзов;
- перестановка пакетов, пришедших разными путями.
Лекция 2. Обслуживание очередей
Цель лекции: изучить методы и алгоритмы обслуживание очередей.
Алгоритмы обслуживания очередей позволяют предоставлять разный уровень QoS трафику разных классов. Обычно используется несколько очередей, каждая из которых занимается пакетами с определенным приоритетом.
Требуется, чтобы высокоприоритетный трафик обрабатывался с минимальной задержкой, но при этом не занимал всю полосу пропускания, и чтобы трафик каждого из остальных типов обрабатывался в соответствии с его приоритетом.
Обслуживание очередей включает в себя алгоритмы:
- организации очереди;
- обработки очередей.
Алгоритмы организации очереди.
Существует два основных алгоритма организации очереди: Tail Drop и Random Early Detection.
Алгоритм Tail Drop — отсечения конца очереди. Задается максимальный размер очереди (в пакетах или в байтах). Когда очередь полна, ни один вновь поступивший пакет туда уже не помещается и потому отбрасывается. Такое управление очередью приводит к повторной синхронизации параметров соединения. После синхронизации TCP сразу посылает столько пакетов, сколько допускает размер окна подтверждения. Подобный всплеск нагрузки опять приводит к отсечению конца очереди, что опять порождает необходимость повторной синхронизации.
Чтобы избежать возникновения заторов, на маршрутизаторах зачастую организуются очереди большого размера. К сожалению, несмотря на то, что увеличение размеров очереди благоприятно сказывается на пропускной способности, большие очереди могут приводить к увеличению времени задержки, что становится причиной нестабильного поведения TCP-соединений.
Алгоритм Random Early Detection RED позволяет более «справедливо» разделить канал между TCP-соединениями. Он позволяет контролировать нагрузку с помощью выборочного случайного уничтожения некоторых пакетов до того, как очередь будет заполнена полностью и протоколы, подобные TCP, начнут снижать скорость передачи, а также предотвращает повторную синхронизацию.
Кроме того, выборочная «потеря» пакетов помогает TCP быстрее найти подходящую скорость передачи данных и удерживать размер очереди и время задержки на разумном уровне. Вероятность «потери» пакета конкретного соединения прямо пропорциональна пропускной способности, используемой этим соединением, а не числу пакетов, т. е. большие пакеты уничтожаются чаще маленьких, что дает достаточно справедливое распределение полосы пропускания.
При работе с RED пользователю необходимо определиться со значениями трех параметров: минимум (min), максимум (max) и превышение (burst).
Минимум — это минимальный размер очереди в байтах, выше которого начнется выборочная потеря пакетов.
Максимум — это «мягкий» максимум, алгоритм будет пытаться удержать размер очереди ниже этого предела.
Превышение — максимальное число пакетов, которые могут быть приняты в очередь сверх установленного максимального предела.
Минимальный размер очереди рассчитывается, исходя из максимально допустимого времени задержки в очереди и пропускной способности канала. Если установить минимальный предел слишком маленьким, это приведет к снижению пропускной способности, слишком большим — к увеличению времени задержки.
Максимальный размер очереди нужно задавать по меньшей мере в два раза больше минимального, чтобы снизить вероятность повторной синхронизации. На медленных линиях с небольшим минимальным пределом размера очереди, максимальный предел следует задавать в четыре, а иногда и более раз больше минимального.
Предел превышения отвечает за поведение RED на пиковых нагрузках. Кроме того, необходимо будет определиться с предельным размером очереди (limit) и средним размером пакета (avpkt). Когда очередь достигает предельного размера, RED переходит к алгоритму «отсечения конца».
При малых размерах очередей метод RED более эффективен, чем другие методы. Он также более устойчив к трафику, имеющему «взрывной» характер.
Алгоритмы обработки очередей. Стратегия FlFO.
Алгоритм обслуживания очередей Firstin-FirstOut (FIFO), также называемый First Come First Served, является самым простым. Пакеты обслуживаются в порядке поступления без какой-либо специальной обработки.
Такая схема приемлема, если исходящий канал имеет достаточно большую свободную полосу пропускания. Алгоритм FIFO относится к так называемым неравноправным схемам обслуживания очередей, так как при его использовании одни потоки могут доминировать над другими и захватывать несправедливо большую часть полосы пропускания. В связи с этим применяются равноправные схемы обслуживания, предусматривающие выделение каждому потоку отдельного буфера и равномерное разделение полосы пропускания между разными очередями.
Очередь с приоритетами (Priority Queuing) — это алгоритм, при котором несколько очередей FIFO (могут использоваться алгоритмы Tail Drop, RED и т. д.) образуют одну систему очередей.
При приоритетной организации очередей (PQ) важный трафик получает самую быструю обработку в каждом пункте, в котором она используется. Этот метод назначает строгий приоритет важного трафика и может обеспечить гибкое задание уровня приоритета в соответствии с сетевыми протоколами. При приоритетной организации очереди каждый пакет помещается в одну из четырех очередей — с высоким, средним и низким приоритетом ожидания — на основе присвоенного приоритета.
Назначение разным потокам нескольких разных приоритетов производится по ряду признаков таких, как источник и адресат пакета, транспортный протокол, номер порта.
Пакеты, которые не подверглись классификации этим механизмом занесения в список приоритетов, по умолчанию, направляются в нормальную очередь. Во время передачи этот алгоритм предоставляет очередям с более высоким уровнем приоритета преференциальный режим по сравнению с очередями с низким уровнем приоритета.
Class-Based Queuing (CBQ). Классовые дисциплины широко используются в случаях, когда различные виды трафика необходимо обрабатывать по-разному. Примером классовой дисциплины может служить CBQ.
Когда трафик передается на обработку классовой дисциплине, он должен быть отнесен к одному из классов (классифицирован). Определение принадлежности пакета к тому или иному классу выполняется фильтрами.
Фильтры, присоединенные к дисциплине, возвращают результат классификации (класс пакета), после чего пакет передается в очередь, соответствующую заданному классу.
Каждый из классов в свою очередь может состоять из подклассов и иметь свой набор фильтров для выполнения более точной классификации свой доли трафика. В противном случае пакет обслуживается дисциплиной очереди класса.
Кроме того, в большинстве случаев классовые дисциплины выполняют шейпинг (формирование) трафика, с целью переупорядочивания пакетов и управления скоростью их передачи. Это совершенно необходимо в случае перенаправления трафика с высокоскоростного интерфейса (например, Еthernet) на медленный (например, модем).
Это позволяет различным приложениям совместно использовать одну и ту же сеть, причем каждое из них предъявляет свои специфические минимальные требования к ширине полосы или к задержке.
Взвешенные очереди.
Для резервирования полосы пропускания в сети IP может использоваться метод WFQ (Weighted Fair Queuing). Метод WFQ позволяет для каждого вида трафика выделять определенную часть полосы пропускания. Оператор через систему административного управления может задать количество очередей. В случае, если одна очередь не использует полностью выделенную ей полосу пропускания, то свободный резерв полосы пропускания может задействоваться для передачи информации из следующей очереди.
Стратегия справедливых (взвешенных) очередей WFQ используется по умолчанию для интерфейсов низкого быстродействия. WFQ делит трафик на несколько потоков, используя в качестве параметров (для IP-протокола) IP-адреса и порты получателя и отправителя, а также поле IP-заголовка ToS (Type of Service). Значение ToS служит для квалификации части выделяемой полосы потока. Для каждого из потоков формируется своя очередь. Максимально возможное число очередей равно 256. Очереди обслуживаются в соответствии с карусельным принципом (roundrobin).
Более высокий приоритет имеют потоки с меньшей полосой, например, удаленный доступ (Telnet). По умолчанию каждая из очередей имеет емкость 64 пакета (но допускается значение и менее 4096 пакетов).
В сетях существует 8 уровней приоритета. Следует иметь в виду, что WFQ не поддерживается в случае туннелирования или шифрования. Поток с низким весом получает более высокий уровень обслуживания, чем поток с высоким уровнем. Когда задействованы биты ToS, WFQ реализует приоритетное обслуживание пакетов согласно значению этого кода.
Справедливые очереди, базирующиеся на классах (CBWFQ).
Дальнейшим развитием технологии WFQ является формирование классов потоков, задаваемых пользователем. Алгоритм CBWFQ предоставляет механизм управления перегрузкой.
Параметры, которые характеризуют класс, те же, что и в случае WFQ (только вместо ToS используется приоритет). В отличие от WFQ здесь можно в широких пределах перераспределять полосу пропускания между потоками.
Для выделения класса могут привлекаться ACL (Access Control List) или даже номер входного интерфейса. Каждому классу ставится в соответствие очередь. В отличие от RSVP данный алгоритм гарантирует полосу лишь в условиях перегрузки. Всего может быть определено 64 класса. Нераспределенная полоса может использоваться потоками согласно их приоритетам.
Очереди с малой задержкой (LLQ).
В некоторых случаях, например, в случае VoIP, важнее обеспечить малую задержку, а не широкую полосу пропускания.
Для таких задач разработан алгоритм LLQ (Low Latancy Queuing), который является модификацией CBWFQ. В этом алгоритме пакеты всех приоритетов, кроме наивысшего, вынуждены ждать, пока очередь более высокого приоритета будет опустошена.
Разброс задержки в высокоприоритетном потоке может быть связан только с ожиданием завершения передачи пакета низкогоприоритета, начавшейся до прихода приоритетного кадра. Такой разброс определяется диапазоном длин кадров.
Лекция 3. Сигнализация H.323
Цель лекции: изучить сигнализации IР сетей на базе Н.323.
Под IР-телефонией будем понимать технологию, позволяющую использовать любую сеть с пакетной коммутацией на базе протокола IР (например, сеть Интернет) в качестве средства организации и ведения международных, междугородных и местных телефонных разговоров и передачи факсов в режиме реального времени. Современные цифровые сигнальные процессоры и постоянно увеличивающиеся скорости передачи данных позволяют передавать речевую информацию в реальном времени по IP-сетям пакетной коммутации. Для реализации концепции VoIP необходимы такие операции, как, например, сжатие речи и изображения, эхо-компенсация, сигнализация, синхронизация тактового сигнала и др. Для интеграции всех перечисленных технологий, международная организация по стандартизации МСЭ-Т определила базовый стандарт H.323.
Рекомендация Н.323: специфицирует системы мультимедийной связи, предназначенные для сетей с коммутацией пакетов, не обеспечивающих гарантированное качество обслуживания, предусматривает применение различных алгоритмов сжатия информации, что позволяет использовать полосу пропускания гораздо более эффективно, чем в сетях с коммутацией каналов.
Архитектура H.323 подразумевает наличие терминалов, шлюзов, контроллеров зон (gatekeeper) и блоков многоточечной конференц-связи, MCU. Использование контролеров зон (GK) опционально, а шлюз (GW) необходим для соединения с внешними сетями (например, TDM).
Основные составляющие элементы архитектуры H.323. IP-терминал представляет собой устройство конечного пользователя, обеспечивающее двунаправленную передачу голоса, видео и данных другим IP-терминалам в реальном времени. Возможна также прямая связь IP-терминала с IP-шлюзом, IP контролером зоны или MCU.
IP-телефон рассматривается как вид IP-терминала. Минимальным требованием к сети VoIP является поддержка стандарта МСЭ-Т G.711, определяющего аналого-цифровое преобразование речевого сигнала с помощью логарифмической импульсно-кодовой модуляции и обеспечивающего высокое качество речевого сигнала в полосе частот 3.1 кГц при скорости передачи 56 или 64 кбит/с.
Сжатие речи необходимо из-за того, что 12-битные выборки должны быть представлены восемью битами. Остальные важные протоколы кодирования речи: МСЭ-Т G.723, G.726, G.729AB. Речевые кодеки выполняют пакетизацию трафика TDM в трафик IP. Размер полезной части пакета по продолжительности может составлять 10 мс, 20 мс, 30 мс и т.д. Для подавления эхо во время телефонных разговоров в речевые кодеки на вызываемой стороне включаются также эхо-компенсаторы (EC). Кроме речевых кодеков, основной стандарт H.323 включает в себя также кодеки изображения, поддерживаемые IP-терминалами.
IP-шлюз осуществляет коммуникацию с IP-терминалами или терминалами, не поддерживающими основного стандарта H.323. Основной задачей IP-шлюза является преобразование данных различных форматов, передаваемых между IP-терминалами. При этом имеется в виду преобразование различных речевых сигналов, которое осуществляется в соответствии с протоколами серии G МСЭ-Т (G.711, G.728, G.729 и т.д.). Возможна коммуникация различных IP-шлюзов между собой, а также соединение телефонной сети общего пользования с сетью ISDN через IP-шлюз. Контролер зоны IP служит для преобразования IP-адресов в телефонные номера, для аутентификации IP-терминалов и IP-шлюзов. Кроме того, он способен управлять полосой пропускания потока данных с помощью набора команд, которые позволяют IP-терминалам изменять выделенную ширину полосы пропускания на локальной сети.
MCU или блок многоточечной конференц-связи – это последний составной элемент в эталонной модели, определяемый основным стандартом H.323. Он обеспечивает конференц-связь между тремя или более терминалами или шлюзами. Зона H.323 представляет собой набором терминалов, шлюзов и MCU, управляемых одним контролером зоны IP (gatekeeper). Зона должна содержать, по крайней мере, один терминал и может содержать также шлюзы или блоков многоточечной конференц-связи.
Каждая зона может иметь только один контролер зоны IP. IP-зоны не зависят от сетевой топологии – они могут включать несколько сетевых сегментов, соединенных посредством маршрутизаторов или подобных устройств. В силу мультимедийного характера основного стандарта H.323 можно на более высоких уровнях найти подстандарты кодеков для сжатия речи и изображения из серии G и H международной организации МСЭ-T.
Группа подстандартов T.12x предназначена для передачи данных в среде мультимедийной конференц-связи. Их цель – распространение файлов данных в реальном времени во время многоточечной мультимедийной конференции. RTP – это протокол передачи потоков информации (аудио, видео) по пакетным сетям в реальном времени. Пакеты, в которых переносится аудио- или видеоинформация, должны быть упакованы в пакеты RTP и передаваться от передающей к принимающей стороне с использованием протокола UDP. Последний передает пакет UDP протоколу IP, который, к сожалению, не может гарантировать доставки пакета, поскольку в данном случае речь идет о не ориентированной на установление соединения услуге. Для контроля качества передачи потоков медиа (аудио, видео) в реальном времени на основе протокола RTP был разработан протокол RTCP. Подобно протоколу RTP пакеты RTCP передаются между передающей и принимающей стороной с помощью протокола UDP. Участники конференц-связи периодически обмениваются пакетами RTCP. Содержимое пакетов служит в качестве обратной информации самому приложению для контроля качества переданных данных и диагностики передачи.

Рисунок 2 – Архитектура сети на базе H.323
Группа подстандартов контроля: подстандарт H.225 подразделяется на две части: H.225 - RAS и H.225 - Q.931.
В стандарте H.225 - RAS описывается та часть сигнализации, в задачи которой входит регистрация на сети передачи данных, предоставление прав на определенный режим работы, на изменения и занятие ширины полосы, а также состояния. Под состояниями имеется в виду доступность контроллеров зоны IP или выявление отказа определенного IP-терминала. С помощью сигнализации RAS осуществляется обмен сообщениями между IP-терминалом и управляющим сервером (контролером зоны IP и MCU). Он состоит из ряда сообщений, содержащих определенный запрос или ответ.
Стандарт H.225 - Q.931 – это модифицированный вариант H.225, базирующийся на концепции стандарта Q.931. Речь идет об основной сигнализации, которая служит для установления соединения между двумя конечными точками, контроля хода соединения и его разъединения.
Подстандарт H.245 комплементарен с подстандартом H.225 и служит для согласования между IP-терминалами вопросов о полосе пропускания, пропускных способностях, в режиме кодирования при приеме и передаче, а также об установлении и закрытии каналов для передачи видеоинформации, речи или данных. Обмен сообщениями может производиться в начале соединения между конечными точками или в ходе самого соединения по специальным контрольным каналам. Сигнальные каналы H.225 - Q.931 и контрольные каналы H.245 используют для передачи протокол TCP, а сигнальные каналы RAS – протокол UDP. Подстандарт используется при двухточечный и многоточечных соединениях и работает в соответствии со стандартом H.245. Компоненты H.323 и сигнализация. H.225 RAS (Registration, Admission and Status). Протокол между конечной точкой и привратником (привратник-шлюз или привратник-терминал) выполняет следующие функции:
- регистрация, проверка прав доступа, надзор полосы пропускания, статус, освобождение;
- сигнальный канал (RAS) устанавливается перед всеми другими каналами.
H.225 сигнализация установки/разрушения вызова:
- рекомендация ISDN Q.931 сигнализации;
- для управления соединениями между конечн. точками H.323.
H.245. В рекомендации ITU-Т Н.245 определен ряд независимых процедур (сигнализация управления каналом), которые должны выполняться для управления каналами переноса информации:
- определения ведущего и ведомого устройств;
- обмена данными о функциональных возможностях;
- открытия и закрытия однонаправленных логических каналов;
- открытия и закрытия двунаправленных логических каналов;
- определения задержки, возникающей при передаче информации от источника к приемнику и в обратном направлении.
Логические соединения между абонентами. Чтобы понять, как эти протоколы взаимодействуют друг с другом, рассмотрим случай ПК, являющегося терминалом локальной сети (с контролерам) и звонящего на удаленный телефон. Вначале компьютеру нужно найти контролера, поэтому он рассылает широковещательным образом специальный UDP-пакет через порт 1718. Из ответа контролера ПК узнает его IP-адрес. Теперь компьютер должен зарегистрироваться у контролера. Для этого он посылает ему сообщение RAS в пакете UDP. После регистрации компьютер обращается к контролеру с просьбой (сообщение доступа RAS) о резервировании пропускной способности. Только после выделения этого ресурса можно начинать установку соединения. Предварительное резервирование пропускной способности позволяет контролеру ограничить число соединений, устанавливаемых на исходящей линии, что, в свою очередь, служит для обеспечения необходимого качества обслуживания. Теперь ПК устанавливает TCP-соединение контролерам, чтобы осуществить телефонный звонок. При установлении телефонного соединения используются традиционные протоколы телефонной сети, ориентированные на соединение. Поэтому требуется протокол TCP. С другой стороны, в телефонной системе нет никаких RAS, которые позволяли бы телефонным аппаратам заявлять о своем присутствии, поэтому разработчики Н.323 могли применять как UDP, так и TCP.
Лекция 4. Общие принципы работы протокола SIP
Цель лекции: изучить принципы построение пакетных сетей на базе протокола SIP.
SIP (Session Initiation Protocol) - протокол установления сессии. Протокол оговаривает способ установки телефонных соединений через Интернет, технологию организации систем для видеоконференций и способы создания других мультимедийных приложений.
В отличие от Н.323, представляющего собой целый набор протоколов, SIP — это единый модуль, способный взаимодействовать с разнообразными интернет-приложениями. Основные задачи протокола SIP:
- определение местоположения пользователей;
- выяснение готовности пользователя включиться в соединение;
- выяснение параметров соединения (медиа-параметры);
- посылка вызова и установка параметров на сторонах всех пользователей;
- изменение параметров соединения, разрыв соединения, активизация услуг и т.д.
SIP не отвечает за всю коммуникацию, но является лишь одной из компонент архитектуры для мультимедиа-коммуникации. Для коммуникации между пользователями необходимо учитывать и использовать несколько различных протоколов:
Сигнальные протоколы – для установления, разрыва и изменения соединения SIP, SDP. Media Transport Protocols – передача аудио/видео/данных в виде пакетов (RTP, UDP, TCP, SCTP). Протокол SIP в IP-модели относится к прикладному уровню. Он спроектирован так, чтобы не зависеть от нижних уровней. Благодаря этому для передачи могут использоваться протоколы TCP, UDP или SCTP. Элементы сети, необходимые для SIP. Сервер - прикладная программа, которая позволяет системе принимать запросы, выполнять их и посылать ответы.
Виды серверов, рисунок 3:
а) SIP Proxy Server:
- передает сигнализацию – работает как клиент и как сервер;
- использует принцип транзакций;
- не хранит данных о соединении;
- выполняет маршрутизацию (routing) – определяет кому (UA/proxy/redirect) требуется передавать сообщения;
- обеспечивает программируемость маршрутизации;
- обеспечивает разделение (Forking) сообщений – может требоваться несколько пунктов назначения одновременно или последовательно.
б) SIP Redirect Server:
- перенаправляет вызовы на другие серверы или непосредственно вызываемому пользователю.
в) SIP Registrar:
- принимает запросы на регистрацию со стороны пользователей;
- хранит информацию о позиции пользователей;
- выполняет функцию контролера зоны (Gateway) в сторону телефонную сеть общего пользования.
Агент пользователя (UA) - прикладная программа, состоящая из двух частей:
- клиент агента пользователя (UAC) – прикладная программа, которая инициирует SIP-запрос (request);
- сервер агента пользователя (UAS) - прикладная программа общения с пользователем после принятия SIP-запроса, возвращает ответ (response) на запрос данного пользователя.
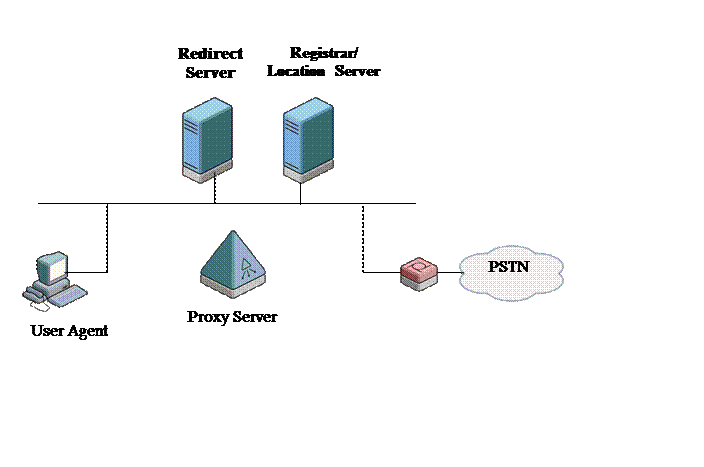
Рисунок 3 – Распределенная архитектура SIP
По модели SIP больше похож на протокол http, чем на классические телефонные сигнализации. Для реализации используется принцип обмена сообщениями ЗАПРОС – ОТВЕТ (Request – Response). На каждый запрос, кроме запроса ACK, возвращается ответ.
SIP Request – запрос клиента в сторону сервера после выполнения какой-либо операции (method).
SIP Response – ответ сервера об успешном выполнении запрошенной операции. Транзакция – последовательность SIP сообщений, состоящая из одного запроса и, по крайней мере, одного ответа.
Для соединения необходимы несколько последовательных транзакций.
а) Запросы (Request). Поддерживаемые запросы (параметр ‘Allow‘ сообщений SIP):
- INVITE и re-INVITE RFC3261;
- ACK RFC3261;
- CANCEL RFC3261;
- BYE RFC3261;
- REGISTER RFC3261.
Неподдерживаемые запросы:
- OPTIONS, RFC3261;
- NOTIFY, SUBSCRIBE, REFER.
Поддерживаемые ответы:
- предварительные ответы 1xx;
- положительные окончательные ответы 2xx;
- отрицательные окончательные ответы группы 4xx на INVITE;
- отрицательные окончательные ответы группы 5xx на INVITE;
- отрицательные окончательные ответы группы 6xx на INVITE.
Неподдерживаемые ответы:
- окончательные ответы группы 3xx (перенаправления, при SIP-T этот тип ответа не ожидается);
- внутри любой группы можно определить 100 различных ответов, хотя только некоторые значения определены заранее. Таким примером служит ответ 200, имеющий смысл "в порядке" (O.K.).
Адресация SIP. Для установления соединения вызывающий пользователь использует SIP-адрес вызываемого. Адреса являются глобальными. Используется формат URL. Адрес должен содержать имя "host", а кроме того может содержать еще имя пользователя (user name), порт и различные другие параметры:
- sip:nekdo@iskratel.si;
- sips:voicemail@iskratel.si?subject=callme;
- sip:recepcija@hotel.xy;geo.position:=48.54_-123.84_120.
Схема работы по протоколу SIP. Протокол SIP позволяет устанавливать и двухсторонние соединения (то есть обычные телефонные соединения), и многосторонние, и широковещательные (когда один из участников говорит, а остальные могут только слушать). Во время сеанса связи могут передаваться аудио-, видео- или другие данные. Эта возможность используется, например, при организации сетевых игр с большим количеством участников в реальном времени. SIP занимается только установкой, управлением и разрывом соединений. Для передачи данных используются другие протоколы, например, RTP/RTCP. Телефонные номера в SIP представляются в виде URL со схемой sip. Например, sip:ilse@cs.university.edu свяжет вас с пользователем по имени Use, хост которого определяется DNS -именем cs.university.edu. SIP URL могут содержать также адреса формата IPv4, IPv6 или реальные номера телефонов.
Компания Skype основана Никласом Ценнштрём и Янусом Фриисом в 2003 году. Программа Skype основана на P2P технологиях и обеспечивает:
- бесплатную голосовую связь через Интернет между компьютерами;
- платные услуги для связи с абонентами обычной телефонной сети;
- видео конференции, обмен сообщениями и файлами.
Skype — это бесплатное проприетарное программное обеспечение для VoIP, обеспечивающее бесплатную шифрованную голосовую связь через Интернет между компьютерами, а также платные услуги для связи с абонентами обычной телефонной сети. В отличие от многих других программ IP-телефонии, для передачи данных Skype использует P2P архитектуру. Каталог пользователей Skype распределён по компьютерам пользователей сети Skype, что позволяет сети легко масштабироваться до очень больших размеров (в данный момент более 100 миллионов пользователей, пять-десять миллионов онлайн) без дорогой инфраструктуры централизированных серверов. VoIP-протокол Skype закрыт и используется только оригинальным ПО Skype.

Рисунок 4 - Архитектура сети Skype
Архитектура сети Skype, рисунок 4:
- сервер авторизации Skype;
- обычные узлы (пользователи);
- супер-узлы (имеют достаточно ресурсов и долго подключены к сети);
- супер-узлы Skype.
Одним из недостатков Skype считается использование проприетарного протокола, несовместимого с открытыми стандартами (такими, как SIP или H.323). Это приводит к тому, что сервис, основанный на этом протоколе, приносит доход только компании Skype.
Лекция 5. Протокол управления шлюзами MGCP
Цель лекции: изучить протоколы управления шлюзами.
В недавнем прошлом рабочая группа MEGACO комитета IETF разработала протокол управления шлюзами - Media Gateway Control Protocol (MGCP). Ранее подобный протокол под названием SGCP - Simple Gateway Control Protocol (простой протокол управления шлюзами) - был разработан компанией Telecordia (бывшая компания Bellcore). Фирма Level 3 предложила сходный протокол управления оборудованием, реализующим технологию маршрутизации пакетов IP, - IDCP (IP Device Control Protocol). Оба они впоследствии были объединены в протокол MGCP. При разработке протокола управления шлюзами рабочая группа MEGACO опиралась на принцип декомпозиции, согласно которому шлюз разбивается на отдельные функциональные блоки (рисунок 5):
- транспортный шлюз - Media Gateway, который выполняет функции преобразования речевой информации, поступающей со стороны СТОП с постоянной скоростью, в вид, пригодный для передачи по сетям с маршрутизацией пакетов IP: кодирование и упаковку речевой информации в пакеты RTP/UDP/IP, а также обратное преобразование;
- устройство управления - Call Agent, выполняющее функции управления шлюзом;
- шлюз сигнализации - Signaling Gateway, который обеспечивает доставку сигнальной информации, поступающей со стороны СТОП, к устройству управления шлюзом и перенос сигнальной информации в обратном направлении.

Рисунок 5 - Архитектура сети, базирующейся на протоколе MGCP
Таким образом, весь интеллект функционально распределенного шлюза размещается в устройстве управления, функции которого, в свою очередь, могут быть распределены между несколькими компьютерными платформами. Шлюз сигнализации выполняет функции STP - транзитного пункта системы сигнализации по общему каналу - ОКС7. Транспортные шлюзы выполняют только функции преобразования речевой информации. Одно устройство управления обслуживает одновременно несколько шлюзов. В сети может присутствовать несколько устройств управления. Предполагается, что эти устройства синхронизованы между собой и согласованно управляют шлюзами, участвующими в соединении. Рабочая группа MEGACO не определяет протокол синхронизации работы устройств управления, однако в ряде работ, посвященных исследованию возможностей протокола MGCP, для этой цели предлагается использовать протоколы Н.323, SIP или ISUP/IP (см.рисунок 6).

Рисунок 6 - Синхронизация работы устройств управления
Перенос сообщений протокола MGCP обеспечивает протокол не гарантированной доставки - UDP. Кроме того, рабочая группа SIGTRAN комитета IETF в настоящее время разрабатывает механизм взаимодействия устройства управления и шлюза сигнализации. Последний должен принимать поступающие из ТфОП сигнальные единицы подсистемы МТР системы сигнализации ОКС7 и передавать сигнальные сообщения верхнего, пользовательского уровня к устройству управления. Основное внимание рабочей группы SIGTRAN уделено вопросам разработки наиболее эффективного механизма передачи сигнальной информации по IP-сетям. Следует отметить, что существует несколько причин, уже упонинавшихся ранее, по которым пришлось отказаться от использования для этой цели протокола TCP. Вместо него рабочая группа SIGTRAN предлагает использовать протокол Stream Control Transport Protocol (SCTP), который имеет ряд преимуществ перед протоколом TCP. Основным из этих преимуществ является значительное снижение времени доставки сигнальной информации и, следовательно, времени установления соединения -одного из важнейших параметров качества обслуживания.
Если распределенный шлюз подключается к СТОП при помощи сигнализации по выделенным сигнальным каналам (ВСК), то сигнальная информация вместе с пользовательской информацией сначала поступает в транспортный шлюз, а затем передается в устройство управления без посредничества шлюза сигнализации.
Одно из основных требований, предъявляемых к протоколу MGCP, состоит в том, что устройства, реализующие этот протокол, должны работать в режиме без сохранения информации о последовательности транзакций между устройством управления и транспортным шлюзом, т.е. в устройствах не требуется реализации конечного автомата для описания этой последовательности. Однако не следует распространять подобный подход на последовательность состояний соединений, сведения о которых хранятся в устройстве управления.
Отметим, что протокол MGCP является внутренним протоколом, поддерживающим обмен информацией между функциональными блоками распределенного шлюза. Протокол MGCP использует принцип master/slave (ведущий/ведомый), причем устройство управления шлюзами является ведущим, а транспортный шлюз - ведомым устройством, выполняющим команды, поступающие от устройства управления.
Основной недостаток этого подхода - незаконченность стандартов. Функциональные блоки распределенных шлюзов, разработанные разными фирмами-производителями телекоммуникационного оборудования, практически несовместимы. Функции устройства управления шлюзами точно не определены. Не стандартизированы механизмы переноса сигнальной информации от шлюза сигнализации (Signalling Gateway) к устройству управления и в обратном направлении.
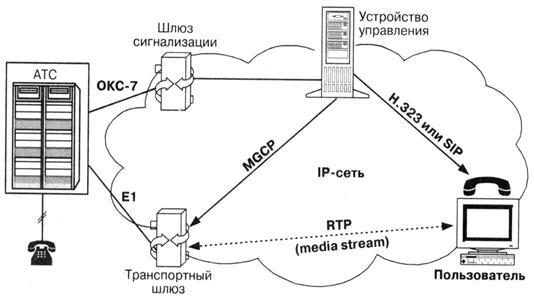
Рисунок 7 - Управление терминалами в сети, базирующейся на протоколе MGCP
К недостаткам можно отнести также отсутствие стандартизированного протокола взаимодействия между устройствами управления. Кроме того, протокол MGCP, являясь протоколом управления шлюзами, не предназначен для управления соединениями с участием терминального оборудования пользователей (IP-телефонами). Это означает, что в сети, построенной на базе протокола MGCP, для управления терминалами должен присутствовать привратник или сервер SIP (рисунок 7).
Классификация шлюзов. Рабочей группой MEGACO предложена следующая классификация транспортных шлюзов (Media Gateways):
- Trunking Gateway - шлюз между СТОП и сетью с маршрутизацией пакетов IP, ориентированный на подключение к телефонной сети посредством большого количества цифровых трактов (от 10 до нескольких тысяч) с использованием системы сигнализации ОКС 7;
- Voice over ATM Gateway - шлюз между СТОП и АТМ-сетью, который также подключается к телефонной сети посредством большого количества цифровых трактов (от 10 до нескольких тысяч);
- Residential Gateway - шлюз, подключающий к IP-сети аналоговые, кабельные модемы, линии xDSL и широкополосные устройства беспроводного доступа;
- Access Gateway - шлюз для подключения к сети IP-телефонии небольшой учрежденческой АТС через аналоговый или цифровой интерфейс;
- Business Gateway - шлюз с цифровым интерфейсом для подключения к сети с маршрутизацией IP-пакетов учрежденческой АТС при использовании, например, системы сигнализации DSS1;
- Network Access Server - сервер доступа к IP-сети для передачи данных;
- Circuit switch или packet switch - коммутационные устройства с интерфейсом для управления от внешнего устройства.
Для описания процесса обслуживания вызова с использованием протокола MGCP рабочей группой MEGACO разработана модель организации соединения - Connection model. Базой модели являются компоненты двух основных видов: порты (Endpoints) и подключения (Connections).
Endpoints - это порты оборудования, являющиеся источниками и приемниками информации. Существуют порты двух видов: физические и виртуальные. Физические порты - это аналоговые интерфейсы, поддерживающие каждое одно телефонное соединение, или цифровые каналы, также поддерживающие одно телефонное соединение и мультиплексированные по принципу временного разделения каналов в тракт Е1. Примером виртуального порта является источник речевой информации в интерактивном речевом сервере, т.е. некое программное средство.
Connection - означает подключение порта к одному из двух концов соединения, которое создается между ним и другим портом. Такое соединение будет установлено после подключения другого порта к его второму концу.
Лекция 6. Протоколы маршрутизации
Цель лекции: изучить протоколы внутренней маршрутизации.
Маршрутизация (англ. routing) — это процесс определения маршрута следования информации в сетях связи.
Зачастую в его таблицах маршрутизации есть несколько записей для заданной в пакете сети назначения. Тогда маршрутизатор смотрит на значение метрики. Он выбирает маршрут с наименьшей метрикой. Метрика назначается для каждого сетевого интерфейса.
В зависимости от того как вносятся изменения в таблицы маршрутов, маршрутизация называется статической илидинамической. Существуют специальные протоколы, которые описывают правила согласования таблиц маршрутизации множества маршрутизаторов в какой-нибудь сети. Они называются протоколами маршрутизации.
Протоколы обмена маршрутной информацией (протоколы маршрутизации) реализуют следующие типов алгоритмов:
- дистанционно-векторный алгоритм (Distance Vector Algorithms, DVA);
- алгоритм состояния связей (Link State Algorithms, LSA).
Алгоритмы дистанционно-векторного типа. В алгоритмах дистанционно-векторного типа каждый маршрутизатор периодически и широковещательно рассылает по сети вектор расстояний от себя до всех известных ему сетей. Под расстоянием обычно понимается число промежуточных маршрутизаторов через которые пакет должен пройти прежде, чем попадет в соответствующую сеть.
Дистанционно-векторные алгоритмы хорошо работают только в небольших сетях. Наиболее распространенным протоколом, основанным на дистанционно-векторном алгоритме, является протокол RIP (Routing information protocol).
Алгоритмы состояния связей обеспечивают каждый маршрутизатор информацией, достаточной для построения точного графа связей сети. Все маршрутизаторы работают на основании одинаковых графов, что делает процесс маршрутизации более устойчивым к изменениям конфигурации. Широковещательная рассылка используется здесь только при изменениях состояния связей.
Для того, чтобы понять, в каком состоянии находятся линии связи, подключенные к его портам, маршрутизатор периодически обменивается короткими пакетами со своими ближайшими соседями. Этот трафик также широковещательный, но он циркулирует только между соседями и поэтому не так засоряет сеть. Протоколом, основанным на алгоритме состояния связей, в стеке TCP/IP является протокол OSPF.
Иерархическая маршрутизация. Вся сеть разбивается на вложенные подсети. Внутри каждой автономной подсети используются протоколы внутренней маршрутизации. Автономные системы соединяются друг с другом с помощью шлюзов (gateway). Маршрутизация между этими шлюзами - внешняя маршрутизация. Все вместе это может быть также автономной подсетью.
Протоколы:
- внутренняя маршрутизация: RIP (Routing Internet Protocol) и OPSF (Open Shortest Path First);
- внешняя маршрутизация: BGP (Border Gateway Protocol).
Протокол маршрутной информации(Routing Information Protocol).
Характеристики:
- является дистанционно-векторным протоколом маршрутизации;
- в качестве метрики при выборе маршрута используется количество переходов (хопов);
- если количество переходов становится дольше 15 – пакет отбрасывается;
- по умолчанию обновления маршрутизации (routing updates) рассылаются широковещательно каждые 30 секунд.
На рисунке ниже показано как поступает протокол rip при выборе маршрута: вместо трех более скоростных участков магистрали он выбирает хоть и на много хуже по скорости, но лучше по количеству переходов маршрут.
Протокол RIP с течением времени перетерпел значительную эволюцию: от классового (classful) протокола маршрутизации (RIP-1) к бесклассовому протоколу RIP второй версии (RIP-2).Усовершенствования протокола RIP-2 включают в себя:
- способность переносить дополнительную информацию о маршрутизации пакетов;
- механизм аутентификации для обеспечения безопасного обновления таблиц маршрутизации;
- способность поддерживать маски подсетей;
Протокол RIP предотвращает появление петель в маршрутизации, по которым пакеты могли бы циркулировать неопределенно долго, устанавливая максимально допустимое количество переходов на маршруте от отправителя к получателю. Стандартное максимальное значение количества переходов равно 15. При получении маршрутизатором обновление маршрутов, содержащего новую или измененную запись, он увеличивает значение метрики на единицу.
Если при этом значение метрики превышает 15, то считается бесконечно большим, и сеть-получатель считается недостижимой. Протокол RIP обладает рядом функций, которые являются общими для него и других протоколов маршрутизации. Например, он позволяет использовать механизмы расщепления горизонта и таймеры удержания информации для предотвращения распространения некорректных сведений о маршрутах, но об этом я напишу в следующих статьях.
Недостатки RIP:
RIP не работает с адресами субсетей. Если нормальный 16-бит идентификатор ЭВМ класса B не равен 0, RIP не может определить является ли не нулевая часть cубсетевым ID, или полным IP-адресом.
RIP требует много времени для восстановления связи после сбоя в маршрутизаторе (минуты). В процессе установления режима возможны циклы.
Число шагов важный, но не единственный параметр маршрута, да и 15 шагов не предел для современных сетей.
Протокол OSPF (Открой кратчайший путь первым).
OSPF является относительно современной (принят в 1991) реализацией алгоритма состояния связей и обладает особенностями, ориентированными на реализацию в гетерогенных (смешанных) сетях.
По сравнению с RIP OSPF является "протоколом второго поколения" и имеет множество преимуществ:
- создает меньшую нагрузку на сеть;
- поддерживает сети значительно большего размера;
- существенно менее "болтлив";
- поддерживает множественные пути между узлом-отправителем и узлом-адресатом (load balancing);
- вычисляет оптимальные маршруты для различных типов сервиса;
- выполняет аутентификацию маршрутов.
Когда OSPF реализован в качестве единственного протокола маршрутизации в сети ("однородная маршрутизирующая система"), каждый маршрутизатор поддерживает свою собственную таблицу маршрутизации, но должен хранить информацию только о непосредственно подключенных к нему подсетях и лишь о тех маршрутизаторах, которые ему непосредственно доступны (так называемых смежных маршрутизаторах).
Процесс построения таблиц маршрутизации разбит на два этапа.
1-й этап. Каждый маршрутизатор строит граф связей сети. Для этого все маршрутизаторы обмениваются сообщениями со своими соседями - объявлениями о состоянии связей. При этом маршрутизаторы ее не модифицируют, а передают в неизменном виде. В результате все маршрутизаторы обладают идентичными сведениями о графе сети, которые хранятся в базе данных о топологии сети.
2-й этап. Нахождение оптимальных маршрутов на основе итерационного алгоритма Дейкстры. В каждом найденном маршруте запоминается один шаг – до следующего маршрутизатора, эта информация попадает в таблицу маршрутизации.
Если несколько маршрутов имеют одну и ту же метрику – запоминаются первые шаги для всех этих маршрутов. Для контроля состояния связей маршрутизаторы передают друг другу каждые 10 секунд короткие сообщения HELLO.
Таким образом тестируется состояние линий. Если в течение определенного периода сообщения от какого-то маршрутизатора-соседа перестают поступать – данный маршрутизатор делает вывод о неработоспособном состоянии связи, корректирует свои базы данных и шлет объявления об изменении состояния линий своим непосредственным соседям. Те тоже корректируют свои базы данных и пересылают информацию дальше.
Аналогичная процедура происходит, если появляется новый сосед и заявляет о себе сообщением HELLO.
Если состояние сети не меняется – объявления о связях не генерируются, что экономит пропускную способность сети и вычислительные ресурсы маршрутизаторов.
Каждые 30 минут все маршрутизаторы обмениваются всеми записями базы данных о топологии сети с целью синхронизации для более надежной работы.
Итак – основные особенности протокола.
Каждому каналу может быть присвоен свой вес (количество ретрансляций). Ограничение на количество ретрансляций ("хопов") -65535.
Каждый узел содержит базу сетевых путей в виде дерева, в вершине которого находится данный узел.
Если существуют пути с одинаковым весом, нагрузка распределяется между ними (режим баланса нагрузки).
Широковещательная рассылка таблиц маршрутизации производится только при появлении изменений. Маршрутизаторы соединены как с локальными сетями, так и непосредственно между собой.
Протокол распространяет информацию о связях двух типов – маршрутизатор-маршрутизатор и маршрутизатор-сеть. Каждая связь характеризуется метрикой. По умолчанию используется пропускная способность каналов связи.
Маршрутизаторы, принадлежащие некоторой области, строят граф связей только для этой области. Между областями информация не передается. Пограничные маршрутизаторы обмениваются только информацией об адресах сетей, имеющихся в каждой области и о расстоянии от пограничного маршрутизатора до каждой сети.
При передаче пакетов между областями среди пограничных маршрутизаторов выбирается тот, у которого расстояние до нужной сети меньше.
Лекция 7. Протоколы внешней маршрутизации
Цель лекции: изучить протоколы внешней маршрутизации.
Ни дистанционно-векторная маршрутизация, ни маршрутизация на основе состояния линий не годятся для внешней маршрутизации. Причины:
- в разных автономных системах могут быть разные метрики расстояний;
- в разных автономных системах могут быть разные приоритеты по отношению к другим автономным системам;
- лавинная рассылка информации о состоянии линий может оказаться невыполнимой.
Маршрутно-векторная маршрутизация – отказ от метрики маршрутизации. Внешние маршрутизаторы просто обмениваются информацией о том, какие сети им доступны и какие автономные системы им надо пересечь, чтобы попасть туда. Отличие от вектоно-дистанционного подхода не делается оценка расстояний или стоимости маршрута.
В каждом блоке информации о маршрутах перечисляются все АС, которые нужно пройти, чтобы достичь сети назначения.
Обладая полной информацией о последовательности пересекаемых АС, маршрутизатор может выбирать маршруты по какому-либо критерию (показателю):
- избегать пересечения определенных АС;
- учитывать пропускную способность, скорость, надежность, склонность к перегрузкам, общее качество работы;
- минимизация числа транзитных узлов;
- если внешнему маршрутизатору доступны два и более пограничных маршрутизаторов АС, где находится сеть назначения, то при выборе маршрута он может руководствоваться внутренними оценками расстояний от каждого из пограничных маршрутизаторов до сети назначения.
Машрутно-векторная маршрутизация реализована в протоколе BGP. EGP – Exterior Gateway Protocol.
Протокол внешних шлюзов (Exterior Gateway Protocol-EGP) является протоколом междоменной досягаемости (1984). Являясь первым протоколом внешних шлюзов, который получил широкое признание в Internet, EGP сыграл важную роль. К сожалению, недостатки EGP стали более очевидными после того, как Internet стала более крупной и совершенной сетью. Из-за этих недостатков EGP в настоящее время не отвечает всем требованиям Internet и заменяется другими протоколами.
Несмотря на то, что EGP является динамическим протоколом маршрутизации, он использует очень простую схему. Он не использует показатели, и следовательно, не может принимать по настоящему интеллектуальных решений о маршрутизации. Корректировки маршрутизации EGP содержат информацию о досягаемости сетей. Другими словами, они указывают, что в определенные сети попадают через определенные шлюзы.
Протокол EGP выполняет следующие функции:
- организует для себя определенный набор соседей (маршрутизаторы, с которыми он коллективно пользуется информацией о досягаемости сетей);
- опрашивает соседей, чтобы убедиться в их работоспособности;
- отправляет сообщения о корректировках, содержащих информацию о досягаемости сетей в пределах своих AS.
EGP – протокол досягаемости, а не маршрутизации.
Протокол BGP ( Border Gateway Protocol).
Пограничный шлюзовый протокол BGP является основным протоколом обмена маршрутной информацией между автономными системами Интернета. Он пришел на смену EGP, который использовался в период становления Интернета, когда Интернет имел единственную магистраль, так что не было необходимости предпринимать меры для исключения зацикливания маршрутов.
BGPv4 устойчиво работает при любой топологии связей между автономными системами, что соответствует современной структуре Интернета.
Сообщения о корректировках состоят из пар “сетевой номер - тракт AS”. Тракт AS содержит последовательность из AS, через которые достигается указанная сеть. Эти сообщения отправляются с помощью транспортного протокола TCP для обеспечения надежной доставки. BGP не требует обновления всей маршрутной таблицы, а только передает корректировки.
Показатель BGP представляет собой произвольное число единиц, характеризующее степень предпочтения какого-нибудь конкретного маршрута. Эти показатели обычно устанавливаются администратором сети с помощью конфигурационных файлов. Степень предпочтения может базироваться на любом числе критериев, включая число AS (тракты с меньшим числом AS как правило лучше), тип канала (стабильность, быстродействие и надежность канала) и другие факторы.
Маршрутизатор взаимодействует по протоколу BGP с другими маршрутизаторами только в том случае, если администратор явно указывает при конфигурировании, что они являются его соседями. Это важно, например, в ситуации, когда маршрутизаторы принадлежат разным ISP-провайдерам, которые могут накладывать ограничения на обмен трафиком с разными автономными системами.
Для установления сеанса с соседями BGP-маршрутизаторы используют протокол TCP. При установлении сеанса могут использоваться разные способы аутентификации для повышения безопасности.
Основное сообщение – UPDATE (обновление, корректировка). Сообщение о достижимости сетей, относящихся к его автономной системе. Это триггерное сообщение, посылается только тогда, когда в сети что-то резко меняется – появляются\исчезают новые сети\пути.
В одном таком сообщении можно объявить об одном новом маршруте или об исчезновении нескольких. Под маршрутом понимается последовательность автономных систем, которую нужно пройти на пути к указанной сети.
Маршрутизатор, получив сообщение о новой сети, запоминает информацию в своей таблице маршрутизации вместе с адресом следующего маршрутизатора. При обмене с внутренними маршрутизаторами по какому-либо внутреннему протоколу эта информация передается внутри автономной системы.
После того, как соединение протокола транспортного уровня организовано, посылается открывающее сообщение. Если оно приемлемо для получателя, то отправителю отсылается сообщение keepalive. После этого можно выполнять обмен корректировками, сообщениями keepalive и уведомлениями.
Определение маршрута сетевых пакетов - самая сложная функция маршрутизаторов, так как в таблице хранятся маршруты, представляющие собой совокупности адресов с общим началом. Соответственно, в таблице ищется самый длинный подходящий префикс. Методы поиска основаны на использовании бинарных деревьев.
Пропускная способность маршрутизаторов измеряется в переданных битах в секунду и в маршрутизированных пакетах в секунду. Средняя длина пакетов составляет 2000 бит, поэтому для обеспечения суммарной пропускной способности 10 Гбит/с необходимо маршрутизировать 5 миллионов пакетов в секунду при величине задержки пакета 10-100 мкс.
Методы групповой маршрутизации. Цель групповой маршрутизации заключается в том, чтобы построить дерево, связующее все маршрутизаторы, присоединенные хосты которых относятся к данной группе рассылки.
Построение дерева наименьшей стоимости называется задачей Штайнера. Существуют алгоритмы ее решения. Однако ни один из реализованных на практике алгоритмов маршрутизации не использует этот подход. Одна из причин – при малейшем изменении сети надо заново запускать алгоритм, требующий достаточно сложных вычислений. Кроме того, нет возможности использовать уже накопленные в рамках имеющихся протоколов данные и таблицы о маршрутах для одноадресной маршрутизации. Где используется групповая рассылка:
- мультимедиа. Несколько пользователей настраиваются на радио- или телепередачу мультимедийной станции;
- телеконференции. Группа рабочих станций образует группу рассылки, в которой передаваемый каждому члену группы пакет получает все члены группы;
- базы данных. Одновременное обновление всех копий;
- распределенные вычисления. Промежуточные результаты рассылаются всем процессам-участникам;
- рабочие группы, работающие в режиме реального времени. Обмен файлами, графикой, сообщениями в режиме реального времени.
Способы организации групповой рассылки.
Выборочная (целевая) рассылка. Источник явным образов посылает кратчайшим путем пакет каждому адресату из группы. Здесь можно действовать в рамках протоколов для одноадресной рассылки, но это неэкономично.
Групповая рассылка на прикладном уровне. Хост посылает сообщение только некоторым получателям, а они его дублируют и посылают другим членам группы. Необходимо поддерживать распределение групповой рассылки на прикладном уровне.
Явная групповая рассылка – хост направляет только одну дейтаграмму, она дублируетсясетевым маршрутизатором, копии посылаются по адресам группы. Здесь задействован сетевой уровень. Нужны специальные сетевые протоколы для преобразования групповых адресов в список сетей, содержащих членов группы (например, IGMP – Internet Group Management Protocol), и алгоритмы выбора маршрута.
Критерии оценки новых маршрутизаторов.
Эффективность. Маршрутизация пакетов с небольшой задержкой (10-100 микросекунд). Дополнительные функции (фильтрация, протоколирование и т.п.), не должны заметно снижать эффективность, а разброс в задержках пакетов должен быть минимальным.
Поддержка классов обслуживания. Взрывной трафик не должен нарушать передачу в реальном времени потоковых данных (аудио, видео). Маршрутизаторы должны обеспечивать требуемое качество обслуживания
Масштабируемость сети. Сетевая конфигурация, складывающаяся в результате использования маршрутизаторов, должна быть управляемой и масштабируемой по числу узлов и по трафику.
Область применения. Требования к маршрутизаторам, используемым в корпоративных и магистральных сетях различны. Различаются протоколы канального уровня, объем и характер трафика, функции протоколирования, меры безопасности и т.п.
Совместимость с существующей сетевой инфраструктурой. Маршрутизатор должен поддерживать употребительные протоколы, среду передачи, быть совместимым с существующими системами сетевого управления и диагностическими средствами.
Совместимость с продуктами других производителей. Ограничение на использование собственных сетевых протоколов.
Минимизация масштаба изменений, необходимых для эффективной работы нового оборудования. Установка нового маршрутизатора не должна вести перестройку значительной части сети.
Лекция 8. Бесклассовая адресация. Протоколы DHCP и NAT
Цель лекции: изучить принципы распределение бесклассовой адресаций и протоколов DHCP, NAT.
Проблема нехватки IP-адресов решилась предоставлением сети возможности разделения на несколько частей. Например, вместо одного адреса класса В с 14 битами для номера сети и 16 битами для номера хоста было предложено использовать несколько другой формат — формировать адрес подсети из нескольких битов. Например, если в университете существует 35 подразделений, то 6-битным номером можно кодировать подсети, а 10-битным — номера хостов. С помощью такой адресации можно организовать до 64 сетей по 1022 хоста в каждой (адреса 0 и 1 не используются, как уже говорилось, поэтому не 1024 , а именно 1022 хоста).
Иерархия IP-адресов

Рисунок 9
Зарезервированные адреса
255.255.255.255 – широковещательный.
127.0.0.0/8 – петля обратной связи.
10.0.0.0/8 и 192.168.0.0/16 – частные сети, подсоединенные к Интернету через NAT.
Пример:

Рисунок 10
На рисунке NAT нет. Изображено всего 7 сетей: 3 (между маршрутизаторами) (192.168.2.0, 192.168.3.0 и 192.168.1.0) + 4 (172.17.0.0, 10.0.0.0, 172.16.0.0, 192.168.4.0).

Рисунок 11 - Таблица маршрутизации. Результат команды route print
Чтобы понять, как функционируют подсети, следует рассмотреть процесс обработки IP-пакетов маршрутизатором. У каждого маршрутизатора есть таблица, содержащая IP-адреса сетей (вида <сетъ, 0>) и IP-адреса хостов (вида <эта_сеть, хост>). Адреса сетей позволяют получать доступ к удаленным сетям, а адреса хостов — обращаться к локальным хостам. С каждой таблицей связан сетевой интерфейс, применяющийся для получения доступа к пункту назначения, а также другая информация. Когда IP-пакет прибывает на маршрутизатор, адрес получателя, указанный в пакете, ищется в таблице маршрутизации. Если пакет направляется в удаленную сеть, он пересылается следующему маршрутизатору по интерфейсу, указанному в таблице. Если пакет предназначен локальному хосту (например, в локальной сети маршрутизатора), он посылается напрямую адресату. Если номера сети, в которую посылается пакет, в таблице маршрутизатора нет, пакет пересылается маршрутизатору по умолчанию, с более подробными таблицами. Такой алгоритм означает, что каждый маршрутизатор должен учитывать только другие сети и локальные хосты, а не пары <сеть, хост>, что значительно уменьшает размер таблиц маршрутизатора.
DHCP (Dynamic Host Configuration Protocol — протокол динамического конфигурирования узлов) позволяет компьютерам автоматически получать IP-адрес и другие параметры.
DHCP — это сетевой протокол, позволяющий компьютерам автоматически получать IP-адрес и другие параметры, необходимые для работы в сети TCP/IP. Для этого компьютер обращается к специальному серверу, называемому сервером DHCP. Сетевой администратор может задать диапазон адресов, распределяемых среди компьютеров. Это позволяет избежать ручной настройки компьютеров сети и уменьшает количество ошибок. Протокол DHCP используется в большинстве крупных (и не очень) сетей TCP/IP.
Протокол DHCP предоставляет три способа распределения IP-адресов:
- ручное распределение. При этом способе сетевой администратор сопоставляет аппаратному адресу (обычно MAC-адресу) каждого клиентского компьютера определённый IP-адрес. Фактически, данный способ распределения адресов отличается от ручной настройки каждого компьютера лишь тем, что сведения об адресах хранятся централизованно (на сервере DHCP), и потому их проще изменять при необходимости;
- автоматическое распределение. При данном способе каждому компьютеру на постоянное использование выделяется произвольный свободный IP-адрес из определённого администратором диапазона;
- динамическое распределение. Этот способ аналогичен автоматическому распределению, за исключением того, что адрес выдаётся компьютеру не на постоянное пользование, а на определённый срок. Это называется арендой адреса. По истечении срока аренды IP-адрес вновь считается свободным, и клиент обязан запросить новый (он, впрочем, может оказаться тем же самым).
Некоторые реализации службы DHCP способны автоматически обновлять записи DNS, соответствующие клиентским компьютерам, при выделении им новых адресов.
Принципы работы DHCP:
- компьютер отправляет широковещательный UDP-пакет: «Кто может назначить мне IP-адрес?»;
- DHCP-серверы сети отправляют в ответ DHCP-предложения;
- Клиент получает список предложений, выбирает нужное и отправляет DHCP-запрос на конкретный сервер;
- от сервера приходит DHCP-подтверждение (в нем указывается IP-адрес, присвоенный клиенту).
Решение проблемы нехватки IP-адресов (NAT).
NAT (Network Address Translation — «преобразование сетевых адресов») — это механизм в сетях TCP/IP, позволяющий преобразовывать IP-адреса транзитных пакетов.
Транзитными пакеты могут быть для коммуникационного оборудования (если вы настроили ваш ПК как роутер, то он также может считаться коммуникационным оборудованием). Задача коммуникаторов — доставлять по адресу приходящие пакеты. Пакеты, которые не предназначены самому коммуникатору, а должны быть перенаправлены и доставлены другому адресату можно уже назвать транзитными. Хотя есть еще один контекст этого понятия. Обычно коммуникаторы ставят на границе локальной и внешней сети. Если пакет пришел в один из портов коммуникатора из внешней сети, и должен быть перенаправлен в другой порт внешней сети, то его называют транзитным.
Преобразование адресов методом NAT может производиться почти любым маршрутизирующим устройством — маршрутизатором, сервером доступа, межсетевым экраном. Суть механизма состоит в замене адреса источника (source) при прохождении пакета в одну сторону и обратной замене адреса назначения (destination) в ответном пакете. Наряду с адресами source/destination могут также заменяться номера портов source/destination. NAT выполняет две важных функции:
- позволяет сэкономить IP-адреса, транслируя несколько внутренних IP-адресов в один внешний публичный IP-адрес (или в несколько, но меньшим количеством, чем внутренних);
- позволяет предотвратить или ограничить обращение снаружи ко внутренним хостам, оставляя возможность обращения изнутри наружу.
При инициации соединения изнутри сети создаётся трансляция. Ответные пакеты, поступающие снаружи, соответствуют созданной трансляции и поэтому пропускаются. Если для пакетов, поступающих снаружи, соответствующей трансляции не существует, они не пропускаются.
Недостатки: не все протоколы могут «преодолеть» NAT. Некоторые не в состоянии работать, если на пути между взаимодействующими хостами есть трансляция адресов. Некоторые межсетевые экраны, осуществляющие трансляцию IP-адресов, могут исправить этот недостаток, соответствующим образом заменяя IP-адреса не только в заголовках IP, но и на более высоких уровнях. Из-за трансляции адресов «много в один» появляются дополнительные сложности с идентификацией пользователей и необходимость хранить полные логии трансляций, сложности в работе с пиринговыми сетями, в которых необходимо не только инициировать исходящие соединения, но также принимать входящие.
Лекция 9. Доменные имена компьютеров
Цель лекции: изучить иерархическую структуру имен DNS, компьютеров.
Каждый компьютер в Интернете имеет свой IP-адрес. Сейчас распространены IP-адреса версии 4. Они представляют собой 4 числа, каждое из которых от 0 до 255. Такой адрес удобен при маршрутизации, так как определяет месторасположение компьютера в сети Интернет, однако, такие числа совсем неудобны для восприятия человеком. Более того, если, например, ваш e-mail: sasha007@207.176.39.176 и ваша почтовая служба решила сменить сервер, то вместе с ним изменится и e-mail. Гораздо лучше, когда компьютер имеет мнемоническое имя, например, mail.ru, sasha007@mail.ru. Существует файл hosts (и в UNIX, и в Windows), в котором можно прописывать адреса серверов, с которыми вы регулярно работаете.
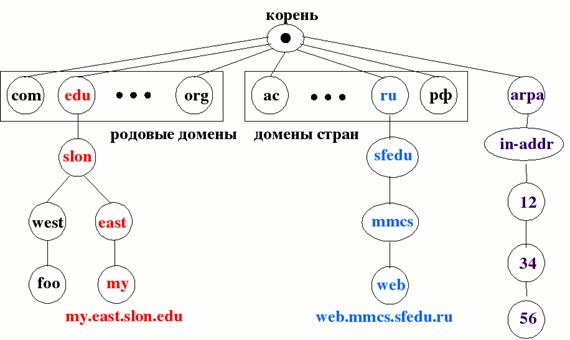
Рисунок 12 - Доменные имена компьютеров
DNS — иерархическая структура имен. Существует «корень дерева» с именем "." (точка). Так как корень един для всех доменов, то точка в конце имени обычно не ставится, но используется в описаниях DNS. Ниже корня лежат домены первого уровня.
Домены верхнего уровня разделяются на две группы: родовые домены и домены государств. К родовым относятся домены com (commercial — коммерческие организации), edu (educational — учебные заведения), gov (government — федеральное правительство США), int (international — определенные международные организации), net (network — сетевые операторы связи) и org (некоммерческие организации). За каждым государством в соответствии с международным стандартом ISO 3166 закреплен домен государства. Ниже находятся домены второго уровня, например, sfedu.ru. Еще ниже — третьего (math.sfedu.ru) и т.д.
В ноябре 2000 года ICANN было утверждено 4 новых родовых имени доменов верхнего уровня, а именно: biz (бизнес), info (информация), пате (имена людей) и pro (специалисты, такие как доктора и адвокаты). Кроме того, по просьбе соответствующих отраслевых организаций были введены еще три специализированных имени доменов верхнего уровня: aero (аэрокосмическая промышленность), coop (кооперативы) и museum (музеи). В будущем появятся и другие домены верхнего уровня. Можно регистрировать домены на кириллице, вот пример работающего сайта: http://цюрих.com/.
Имена доменов нечувствительны к изменению регистра символов. Так, например, edu и EDU означают одно и то же. Обычно разрешается регистрация доменов длиной до 63 символов, а длина полного пути не должна превосходить 255 символов. Размер доменного имени ограничивается по административным и техническим причинам.
Структура доменов отражает не физическое строение сети, а логическое разделение между организациями и их внутренними подразделениями. Так, если факультеты компьютерных наук и электротехники располагаются в одном здании и пользуются одной общей локальной сетью, они, тем не менее, могут иметь различные домены. И наоборот, если, скажем, факультет компьютерных наук располагается в двух различных корпусах университета с различными локальными сетями, логически все хосты обоих зданий обычно принадлежат к одному и тому же домену.
Служба трансляции имен DNS.
Клиенты DNS – специализированные библиотеки (или программы) для работы с DNS (в Windows – служба «DNS-клиент»).
Серверная сторона DNS – множество серверов имен, рассредоточенных по миру и осуществляющих поиск в распределенной базе данных доменных имен.
Порт сервера – 53. Серверное ПО: Berkeley Internet Name Domain (BIND) (демон named), NSD (name server daemon), Windows DNS Server
Суть системы DNS заключается в иерархической схеме имен, основанной на доменах, и распределенной базе данных, реализующей эту схему имен. В первую очередь эта система используется для преобразования имен хостов и пунктов назначения электронной почты в IР-адреса, но также может использоваться и в других целях.
Система DNS не только отыскивает IP-адрес по заданному имени хоста, но способна выполнять и обратную операцию, т.е. по IP-адресу определять имя хоста в сети. Многие веб- и FTP-серверы в сети Internet ограничивают доступ на основе домена, к которому принадлежит обратившийся к ним клиент. Получив от клиента запрос на установку соединения, сервер передает IP-адрес клиента DNS-серверу как обратный DNS-запрос. Если клиентская зона DNS настроена правильно, то на запрос будет возвращено имя клиентского хоста, на основе которого затем принимается решение о том, допустить данного клиента на сервер или нет.
Дополнительные функции DNS-сервера:
- поддержка псевдонимов серверов. Пример: mmcs.sfedu.ru, web.mmcs.sfedu.ru и web.mmcs.rsu.ru имеют один и тот же ip-адрес;
- поддержка почтового сервера домена;
- распределение нагрузки между серверами;
- кэширование (авторитетная и неавторитетная информация).
Поддержка почтового сервера домена. Можно узнать ip-адрес почтового сервера в домене (используется при пересылке почты).
Распределение загрузки между серверами. Одно доменное имя соответствует нескольким серверам, следовательно, по запросу служба может вернуть несколько IP–адресов. Наример, www.microsoft.com обслуживает несколько серверов. При этом первый по списку сервер меняется от запроса к запросу. Системы обычно берут первый IP-адрес. Загрузка происходит одновременно (то к одному серверу – то к другому), но мы, как пользователи, этого не замечаем.
Корневые серверы DNS — это серверы DNS, содержащие информацию о доменах верхнего уровня (edu, org, com, ru, …), конкретнее — указатели на серверы DNS, поддерживающие работу каждого из этих доменов.
Корневые серверы DNS обозначаются латинскими буквами от «A» до «М». Их всего 13 штук (+ куча зеркал). Они управляются различными организациями, действующими по согласованию с ICANN. Количество серверов ограничено в связи с максимальным объёмом UDP-пакета (большее количество серверов потребовало бы перехода на TCP-протокол для получения ответа, что существенно увеличит нагрузку).
У многих корневых серверов DNS существуют зеркала. В частности, российское зеркало сервера F расположено в РосНИИРОС. IP-адреса корневых DNS-серверов можно получить командой «dig. NS» (dig точка NS; точка – корневой домен).

Рисунок 13 – Принципы работы DNS
Принципы работы DNS. Рассмотрим схему подачи запроса серверу. Студент Стэнфордского университета с университетского компьютера пытается зайти на сайт воскресной школы мехмата sunschool.math.sfedu.ru. Чтобы определить IP-адрес компьютера sunschool.math.sfedu.ru, браузер студента вызывает DNS-клиент (resolver) – функцию API операционной системы. Она, используя IP-адрес локального DNS-сервера из настроек сети на компьютере студента, посылает запрос в виде UDP-пакета DNS-серверу. Пусть сервер будет atalante.stanford.edu.
Предположим, что локальный сервер Стэнфордского университета имен не знает IP-адреса sunschool.math.sfedu.ru. Тогда он посылает запрос одному из корневых серверов, адреса которых содержатся в его базе данных, пусть это будет f.root-servers.net. Таким образом получается рекурсивный запрос: DNS-клиент студента обращается к локальному DNS-серверу, а тот к корневому. Маловероятно, что корневой сервер знает адрес хоста sunschool.math.sfedu.ru. Скорее всего он даже не знает адреса сервера sfedu.ru, однако он должен знать все свои дочерние домены – домены верхнего уровня. Но продолжать рекурсию он не будет. Дело в том, что корневые домены сильно загружены запросами, поэтому сконфигирированы так, что возвращают список DNS-серверов, которые должны больше знать о sunschool.math.sfedu.ru – это DNS-серверы домена ru. Получив список DNS-серверов, локальный сервер Стэнфордского университета направляет запрос одному из серверов списка (обычно первому), например, ns.ripn.net. Тот тоже загружен и возвращает адреса DNS-серверов дочерней зоны sfedu.ru. Последние два запроса называютсяитеративными. Затем локальный сервер Станфордского университета обращается к первому в списке серверу домена sfedu.ru. Пусть это будет ns.sfedu.ru. В данном примере оказалось, что он тоже не знает IP-адреса sunschool.math.sfedu.ru. DNS-сервер нашего университета не так загружен, как корневые серверы или серверы доменов верхнего уровня, поэтому его сконфигурировали выполнять рекурсивные запросы. Он обращается к серверу домена math.sfedu.ru – это ns.math.sfedu.ru, получает искомый IP-адрес и возвращает его в ответе локальному серверу Стэнфордского университета, который, в свою очередь, сообщает его компьютеру студента. Когда записи ресурсов попадают на сервер имен Стэнфордского университета, они помещаются в кэш на случай, если они понадобятся еще раз. Однако, информация в КЭШе не является авторитетной, так как изменения в домене sfedu.ru не будут автоматически распространяться на все КЭШе, в которых может храниться копия этой информации. По этой причине записи ЭШе обычно долго не живут. В каждой записи ресурса присутствует поле Time_to_live. Оно и сообщает удаленным серверам, насколько долго следует хранить эту запись в КЭШе. Набор DNS-серверов в ответе на запрос все время один и тот же, однако, их последовательность в списке меняется от запроса к запросу, так как программы обычно берут первое имя из списка, то они обращаются к разным серверам. Таким образом нагрузка равномерно распределяется между DNS-серверами списка.
Лекция 10. IP версия 6 архитектуры адресации
Цель лекции: изучить архитектуру сетевую адресацию IPV6.
Ipv6 представляет собой новую версию протокола Интернет (RFC-1883), являющуюся преемницей версии 4 (IPV4; RFC-791). Изменения Ipv6 по отношению к IPV4 можно поделить на следующие группы:
Расширение адресации.
В IPV6 длина адреса расширена до 128 бит (против 32 в IPV4), что позволяет обеспечить больше уровней иерархии адресации, увеличить число адресуемых узлов, упростить авто-конфигурацию. Для расширения возможности мультикастинг-маршрутизации в адресное поле введено субполе «scope» (группа адресов). Определен новый тип адреса «anycast address», который используется для посылки запросов клиента любой группе серверов. Аnycast адресация предназначена для использования с набором взаимодействующих серверов, чьи адреса не известны клиенту заранее.
Спецификация формата заголовков.
Некоторые поля заголовка IPV4 отбрасываются или делаются опционными, уменьшая издержки, связанные с обработкой заголовков пакетов с тем, чтобы уменьшить влияние расширения длины адресов в Ipv6.
Улучшенная поддержка расширений и опций
Изменение кодирования опций IP-заголовков позволяет облегчить переадресацию пакетов, ослабляет ограничения на длину опций, и делает более доступным введение дополнительных опций в будущем.
Возможность пометки потоков данных.
Введена возможность помечать пакеты, принадлежащие определенным транспортным потокам, для которых отправитель запросил определенную процедуру обработки, например, нестандартный тип TOS (вид услуг) или обработка данных в реальном масштабе времени.
Идентификация и защита частных обменов.
В IPV6 введена спецификация идентификации сетевых объектов или субъектов, для обеспечения целостности данных и при желании защиты частной информации.
Существует три типа адресов:
1) unicast - Идентификатор одиночного интерфейса. Пакет, посланный по unicast адресу, доставляется интерфейсу, указанному в адресе;
2) anycast - Идентификатор набора интерфейсов (принадлежащих разным узлам). Пакет, посланный по anycast адресу, доставляется одному из интерфейсов, указанному в адресе (ближайший, в соответствии с мерой, определенной протоколом маршрутизации);
3) multicast - Идентификатор набора интерфейсов (обычно принадлежащих разным узлам). Пакет, посланный по multicast адресу, доставляется всем интерфейсам, заданным этим адресом.
В IPV6 не существует широковещательных адресов, их функции переданы multicast адресам.
Представление записи адресов (текстовое представление адресов).
Существует три стандартные формы для представления ipv6 адресов в виде текстовых строк:
Основная форма имеет вид x:x:x:x:x:x:x:x, где 'x' шестнадцатеричные 16-битовые числа.
Примеры:
fedc:ba98:7654:3210:FEDC:BA98:7654:3210
1080:0:0:0:8:800:200C:417A
Из-за метода записи некоторых типов Ipv6 адресов, они часто содержат длинные последовательности нулевых бит. Для того чтобы сделать запись адресов, содержащих нулевые биты, более удобной, имеется специальный синтаксис для удаления лишних нулей. Использование записи «::» указывает на наличие групп из 16 нулевых бит. Комбинация «::» может появляться только при записи адреса. Последовательность «::» может также использоваться для удаления из записи начальных или завершающих нулей в адресе. Например:
|
1080:0:0:0:8:800:200c:417a |
- unicast- -адрес; |
|
ff01:0:0:0:0:0:0:43 |
- multicast адрес; |
|
0:0:0:0:0:0:0:1 |
- адрес обратной связи; |
|
0:0:0:0:0:0:0:0 |
- неспецифицированный адрес. |
может быть представлено в виде:
|
1080::8:800:200c:417a |
- unicast –адрес; |
|
ff01::43 |
- multicast адрес; |
|
::1 |
- адрес обратной связи; |
|
:: |
- не специфицированный адрес. |
Альтернативной формой записи, которая более удобна при работе с ipv4 и Ipv6, является x:x:x:x:x:x:d.d.d.d, где 'x' шестнадцатеричные 16-битовые коды адреса, а 'd' десятичные 8-битовые, составляющие младшую часть адреса (стандартное Ipv4 представление). Например:
0:0:0:0:0:0:13.1.68.3
0:0:0:0:0:FFFF:129.144.52.38
или в сжатом виде:
::13.1.68.3
::FFFF:129.144.52.38
Представление типа адреса.
Специфический тип IPV6 адресов идентифицируется лидирующими битами адреса. Поле переменной длины, содержащее эти лидирующие биты, называется префиксом формата (Format Prefix – FP).
Т а б л и ц а 3 - Префиксы формата
|
Тип адреса |
Префикс (двоичный) |
Нотация IPV6 |
|
Вложенный Ipv4-адрес |
00…1111 1111 1111 1111 (96 бит) |
::FFFF/96 |
|
Обратная связь |
00…1 (128 бит) |
::1/128 |
|
Глобальный unicast |
01 – 1111 1100 0 |
4000::/2 – FC00::/9 |
|
Teredo |
0010 0000 0000 0001 0000 0000 0000 0000 |
2001:0000::/32 |
|
Немаршрути-зируемый |
0010 0000 0000 0001 0000 1101 1011 1000 |
2001:DB8::/32 |
|
6to4 |
0010 0000 0000 0010 |
2002::/16 |
|
6Bone |
0011 1111 1111 1110 |
3FFE::/16 |
|
unicast локального канала |
1111 1110 10 |
FE80::/10 |
|
Зарезервировано |
1111 1110 11 |
FEC0::/10 |
|
Локальный Ipv6-адрес |
1111 110 |
FC00::/7 |
|
multicast |
1111 1111 |
FF00::/8 |
В Ipv6 определены локальные связи (Link-local). Это относится к локальным сетям или сетевым каналам. Каждый интерфейс IPV6 в LAN должен иметь адрес этого типа. Такие адреса начинаются с FE80::/10. Пакеты с адресом места назначения этого вида не могут маршрутизироваться и не могут переадресовываться за пределы локальной области.
Существует несколько форм присвоения unicast адресов в Ipv6, включая глобальный unicast адрес провайдера, географический unicast адрес, NSAP адрес, IPX иерархический адрес, Site-local-use адрес, Link-local-use адрес и IPV4-compatible host address. В будущем могут быть определены дополнительные типы адресов.
Узлы IPV6 могут иметь существенную или малую информацию о внутренней структуре Ipv6 адресов, в зависимости от выполняемой узлом роли, (например, ЭВМ или маршрутизатор). Как минимум, узел может считать, что unicast адрес (включая его собственный адрес) не имеет никакой внутренней структуры. То есть представляет собой 128 битовый неструктурированный образ. ЭВМ может дополнительно знать о префиксе субсети для каналов, c которыми она соединена, где различные адреса могут иметь разные значения N:

Рисунок 14
Более сложные ЭВМ могут использовать и другие иерархические границы в уникастном адресе. Хотя простейшие маршрутизаторы могут не знать о внутренней структуре IPv6 уникастных адресов, маршрутизаторы должны знать об одной или более иерархических границах для обеспечения работы протоколов маршрутизации. Известные границы для разных маршрутизаторов могут отличаться и зависят от того, какое положение занимает данный прибор в иерархии маршрутизации.
Не специфицированный адрес. Адрес 0:0:0:0:0:0:0:0 называется не специфицированным адресом. Он не должен присваиваться какому-либо узлу. Этот адрес указывает на отсутствие адреса. Примером использования такого адреса может служить поле адреса отправителя любой IPv6 дейтограммы, посланной инициализируемой ЭВМ до того, как она узнала свой адрес.
Не специфицированный адрес не должен использоваться в качестве указателя места назначения IPv6 дейтограмм или в IPv6 заголовках маршрутизации.
Адрес обратной связи. Уникастный адрес 0:0:0:0:0:0:0:1 называется адресом обратной связи. Он может использоваться для посылки машиной IPv6 дейтограмм самой себе. Его нельзя использовать в качестве идентификатора интерфейса.
Адрес обратной связи не должен применяться в качестве адреса отправителя в IPv6 дейтограммах, которые посылаются за пределы узла. IPv6 дейтограмма с адресом обратной связи в качестве адреса места назначения не может быть послана за пределы узла.
Лекция 11. IPv6 адреса с вложенными IPv4 адресами
Цель лекции: изучить механизм организации туннелей для IPv6 пакетов через маршрутную инфраструктуру IPv4.
Алгоритмы IPv6 включают в себя механизм организации туннелей для IPv6 пакетов через маршрутную инфраструктуру IPv4. Узлам IPv6, которые используют этот метод, присваиваются специальные IPv6 уникастные адреса, которые в младших 32 битах содержат адрес IPv4. Этот тип адреса называется "IPv4-compatible IPv6 address" и имеет формат, изображенный на рисунке 15:

Рисунок 15
Определен и второй тип IPv6 адреса, который содержит внутри IPv4 адрес. Этот адрес используется для представления IPv6 адресов узлам IPv4 (тем, что не поддерживают IPv6). Этот тип адреса называется "IPv4-mapped IPv6 address" и имеет формат, показанный на рисунке 16:

Рисунок 16
NSAP адреса. Соответствие NSAP адреса IPv6 адресам выглядит следующим образом (рисунок 17):

Рисунок 17
IPX Адреса. Соответствие IPX и IPv6 адресов показано ниже на рисунке 18:

Рисунок 18

Рисунок 19
Старшая часть адреса предназначена для определения того, кто определяет часть адреса провайдера, подписчика и т.д.
Идентификатор регистрации определяет регистратора, который задает провайдерскую часть адреса. Термин "префикс регистрации" относится к старшей части адреса, включая поле идентификатор регистрации (ID).
Идентификатор провайдера задает специфического провайдера, который определяет часть адреса подписчика. Термин "префикс провайдера" относится к старшей части адреса включая идентификатора провайдера.
Идентификатор подписчика позволяет разделить подписчиков, подключенных к одному и тому же провайдеру. Термин "префикс подписчика" относится к старшей части адреса, включая идентификатор подписчика.
Часть адреса интра-подписчик определяется подписчиком и организована согласно местной топологии Интернет подписчика. Возможно, что несколько подписчиков пожелают использовать область адреса интраподписчик для одной и той же субсети и интерфейса. В этом случае идентификатор субсети определяет специфический физический канал, а идентификатор интерфейса - определенный интерфейс субсети.

Рисунок 20 - Локальный адрес канала
Локальные адреса канала предназначены для обращения через определенный канал, например, для целей авто-конфигурации адресов, поиска соседей или в случае отсутствия маршрутизатора. Маршрутизаторы не должны переадресовывать пакеты с локальными адресами отправителя. Локальный адрес сети имеет формат, показанный на рисунок 21:

Рисунок 21 - Локальный адрес сети
Локальные адреса сети могут использоваться для локальных сетей или организаций, которые (пока еще) не подключены к глобальному Интернет. Им не нужно запрашивать или “красть” префикс адреса из глобального адресного пространства Интернет. Вместо этого можно использовать локальный адрес сети IPv6. Когда организация соединяется с глобальным Интернет, она может сформировать глобальные адреса путем замещения локального префикса сети префиксом подписчика.
Маршрутизаторы не должны переадресовывать пакеты с локальными адресами сети отправителя.
Аnycast адреса выделяются из уникастного адресного пространства, и используют один из известных уникастных форматов. Таким образом anycast адреса синтаксически неотличимы от уникастных адресов. Когда уникастный адрес приписан более чем одному интерфейсу, он превращается в anycast адрес и узлы, которым он приписан, должны быть сконфигурированы так, чтобы распознавать этот адрес.
Для любого anycast адреса существует адресный префикс P, который определяет топологическую область, где находятся все соответствующие ему интерфейсы. В пределах области, заданной P, каждый член anycast группы должен быть объявлен, как отдельный вход в маршрутной системе; вне области, заданной P, anycast адрес может быть занесен в маршрутную запись для префикса p.
Заметим, что в худшем случае префикс P anycаst группы (anycast set) может быть нулевым, т.e., члены группы могут не иметь никакой топологической локальности. В этом случае anycst адрес должен объявляться как отдельная маршрутная единица (separate routing entry) по всему Интернет, что представляет собой серьезное ограничение, так как число таких "глобальных" anycаst адресов не может быть большим.
Одним ожидаемым приложением anycast адресов является идентификация набора маршрутизаторов, принадлежащих Интернет сервис провайдеру. Такие адреса в маршрутном заголовке IPv6 могут использоваться в качестве промежуточных, чтобы обеспечить доставку пакета через определенного провайдера или последовательность провайдеров. Другим возможным приложением может стать идентификация набора маршрутизаторов, связанных с определенной субсетью, или набора маршрутизаторов, обеспечивающих доступ в определенный домен.
Существует ограниченный опыт широкого применения anycаst Интернет адресов, некоторые возможные осложнения и трудности рассмотрены в [anycаst]. Имеются следующие ограничения при использовании anycst IPv6 адресов:
- anycаst адрес не может использоваться в качестве адреса отправителя в ipv6 пакете;
- anycаst адрес не может быть приписан ЭВМ IPv6, таким образом, он может принадлежать только маршрутизатору.
Необходимые anycаst адрес маршрутизатора субсети предопределен и имеет формат, отображенный на рисунок 22:

Рисунок 22
Префикс субсети в anycаst адресе является префиксом, который идентифицирует определенный канал. Этот anycаst адрес является синтаксически идентичным уникастному адресу для интерфейса канала с идентификатором интерфейса равным нулю.
Пакеты, посланные группе маршрутизаторов с anycаst адресом, будут доставлены всем маршрутизатам субсети. При этом все маршрутизаторы субсети должны поддерживать работу с anycаst адресами. Реальный обмен будет осуществлен лишь с тем маршрутизатором, который ответит первым.
Аnycаst адрес маршрутизатора субсети предполагается использовать в приложениях, где необходимо взаимодействовать с одним из совокупности маршрутизаторов удаленной субсети.
Список литературы
1. Жданов А.Г., Рассказов Д.А., Смирнов Д.А., Шипилов М.М./под ред. Бабкова В.Ю. и Вознюка М.А. Передача речи по сетям с коммутацией пакетов (IP-телефония). – СПб.: ГУТ, 2001. – 165 с.
2. Шелухин О.И., Лукьянцев Р.Ф. Цифровая обработка и передача речи. – М.: Радио и связь, 2000. – 454 с.
3. Гольдштейн Б.С., Пинчук А.В., Суховицкий А.Л. IP-телефония. – М.: Радио и связь, 2001. – 336 с.
4. Рабинер Л.Р., Шафер Р.В. Цифровая обработка речевых сигналов. – М.: Радио и связь, 1981. – 200 с.
5. Олифер В., Олифер Н., Компьютерные сети. Принципы, технологии, протоколы. - СПб.:Питер, 2006 – 958 с.
6. Чежимбаева К.С., Калиева С.А. Учебное пособие. Применение сетевого оборудования для локальных сетей. АИЭС. - Алматы, 2010. – 82 с.
7. Чежимбаева К.С., Калиева С.А. Конспект лекций. Технологии пакетной коммутации. - Алматы, АИЭС. 2010. – 58 с.
Содержание
Введение
Лекция 1. Качество передачи речевой информации по IP-сети
Лекция 2. Обслуживание очередей
Лекция 3. Сигнализация H.323
Лекция 4. Общие принципы работы протокола SIP
Лекция 5. Протокол управления шлюзами MGCP
Лекция 6 Протоколы маршрутизации
Лекция 7 Протоколы внешней маршрутизации
Лекция 8. Бесклассовая адресация. Протоколы DHCP и NAT
Лекция 9. Доменные имена компьютеров
Лекция 10. IP версия 6 архитектуры адресации
Лекция 11. IPv6 адреса с вложенными IPv4 адресами
Список литературы
Сводный план 2013 г., поз.272