АЛМАТИНСКИЙ ИНСТИТУТ ЭНЕРГЕТИКИ И СВЯЗИ
КАФЕДРА ИНЖЕНЕРНОЙ КИБЕРНЕТИКИ
ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ
Методические указания к лабораторным работам
для студентов всех форм обучения
специальности 5B0702 – «Автоматизация и управление»
Алматы 2009
СОСТАВИТЕЛИ: Ешпанова М.Д., Ибраева Л.К., Сябина Н.В. Методические указания к лабораторным работам по дисциплине «Проектирование баз данных» для студентов всех форм обучения специальности 5B0702 - «Автоматизация и управление» – Алматы: АИЭС, 2009 – 51 с.
Рассматриваются вопросы разработки проекта базы данных и его реализации в среде MS SQL Server: от создания объектов базы данных до конструирования сложных запросов по поиску информации, а также средства профессионального пользователя – процедуры, триггеры, вопросы разработки приложений пользователей, вопросы шифрования данных в среде систем управления базами данных.
Методические указания предназначены для студентов специальности 5В0702 – «Автоматизация и управление».
Введение
Проектирование баз данных – одна из наиболее сложных и ответственных задач, связанных с созданием информационной системы. В результате её решения должны быть определены содержание базы данных, эффективный для всех её будущих пользователей способ организации данных и инструментальные средства управления данными. Процесс проектирования базы данных представляет собой последовательность переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели.
В реальном проектировании структуры базы данных применяется метод семантического моделирования, который представляет собой моделирование структуры данных, опираясь на смысл этих данных. В качестве инструмента семантического моделирования используются различные варианты диаграмм «сущность-связь» (Entity-Relationship - ER). Все варианты диаграмм «сущность-связь» используют графическое изображение сущностей (объектов) предметной области, их свойств и взаимосвязей между сущностями. Результатом проектирования базы данных является концептуальная схема (ER-диаграмма) моделируемой предметной области.
После разработки проекта базы данных можно приступать к его реализации в конкретной системе управления базами данных (СУБД). Современная волна информационных технологий управления данными основывается на использовании систем управления реляционными базами данных.
Все языки манипулирования данными, созданные до появления реляционных баз данных, были ориентированы на операции с данными, представленными в виде логических записей файлов. Это требовало от пользователей детального знания организации хранения данных и достаточных усилий для указания не только того, какие данные нужны, но и того, где они размещены и как шаг за шагом получить их. Рассматриваемый в методических указаниях непроцедурный язык SQL (Structured Query Language - структурированный язык запросов) ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц. Особенность предложений этого языка состоит в том, что они ориентированы в большей степени на конечный результат обработки данных, чем на процедуру этой обработки. SQL сам определяет, где находятся данные, какие индексы и даже наиболее эффективные последовательности операций следует использовать для их получения: не надо указывать эти детали в запросе к базе данных.
Спроектировать и создать базу данных еще недостаточно для успешной работы с данными: у нас должна быть возможность как-то обращаться к этим данным, дополнять и изменять их. В этом и состоит цель клиентского приложения - специальной программы, позволяющей работать с данными в удобной для пользователя форме. В общем случае с одной базой данных могут работать множество различных приложений. При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями.
В методических указаниях рассматриваются вопросы разработки проекта баз данных и его реализации в выбранной системе управления базами данных: от создания объектов базы данных, манипуляции данными - до конструирования сложных запросов по поиску информации, а также средства профессионального пользователя – процедуры, триггеры, вопросы разработки приложений пользователей. Для реализации проекта предлагается система управления базами данных Microsoft SQL Server 2005, которая ориентирована на создание и ведение базы данных на уровне предприятия. Стандартные средства для доступа к данным различных баз данных предоставляет язык запросов SQL. Большинство баз данных имеют свою собственную версию этого языка. Но, несмотря на это, понимание основ SQL поможет работать со многими базами данных на самых разных платформах.
Продукция на рынке информационных услуг обновляется каждые 4-6 месяцев. В связи с этим вполне вероятно, что версия Microsoft SQL Server, используемая на лабораторных занятиях в настоящий момент, может измениться. В помощь студентам для освоения основных возможностей языка SQL на кафедре «Инженерная кибернетика» была разработана виртуальная обучающая система SQL_Education по проектированию баз данных и изучению языка структурированных запросов. Эта программа имеет наглядный интерфейс, снабжена средствами видеоанимации, сопровождается множеством примеров. При подготовке к лабораторным занятиям студент должен изучить соответствующий раздел этой программы (согласно методическим указаниям) и использовать полученные навыки для выполнения заданий.
Ориентированный на работу с таблицами, SQL не имеет достаточных средств для создания сложных прикладных программ. Поэтому в большинстве СУБД он используется вместе с языками программирования высокого уровня. В лабораторной работе № 7 рассматриваются вопросы разработки приложения пользователя. Для иллюстрации того, как должен выглядеть конечный результат разработки, методические указания к этой работе снабжены exe-файлом, представляющим собой пример разработки.
Последняя лабораторная работа посвящена вопросам шифрования данных в MS SQL Server. Эта работа демонстрирует результат применения алгоритмов, рассмотренных в курсе «Защита информации» к защите данных в базе данных.
Кафедра выражает благодарность студентам специальности «Автоматизация и управление» Алтурмесову Е. и Цой М. (гр. БАУ-05) за помощь в реализации пользовательского интерфейса обучающей программы.
1 Лабораторная работа №1. Создание базы данных и определение ее структуры
Цель работы: освоение процедуры создания, удаления, резервирования и восстановления базы данных в среде MS SQL Server 2008; освоение языка определения данных.
1.1 Знакомство с MS SQL Server 2005
1.1.1 Логические компоненты базы данных
MS SQL Server является системой управления реляционными базами данных. Реляционная база данных – это база данных, разделенная на логически цельные сегменты, называемые таблицами, и внутри базы данных эти таблицы связаны между собой посредством ключевых полей. Таблицы являются основной формой хранения данных в базе данных. Реляционная база данных позволяет разделить данные на логически более мелкие и более управляемые сегменты, что обеспечивает оптимальное представление данных и возможность организации нескольких уровней доступа к данным. Вследствие наличия у таблиц общих ключей оказывается возможным объединить данные из нескольких таблиц в одно результирующее множество. Это является одним из основных достоинств реляционных баз данных. Набор действий, выполняемых по отношению к базе данных и рассматриваемый как единое целое, называется транзакцией. Транзакция представляет собой внесение в базу данных некоторых изменений. Каждая база данных имеет соответствующий ей журнал транзакций – место, куда SQL Server записывает все выполняемые транзакции перед тем, как записать их в базу данных.
Данные в SQL Server организованы в нескольких различных объектах, которые пользователь видит при создании базы данных. К ним относятся:
- пользователи базы данных Database Users);
- роли базы данных (Database Roles);
- таблицы (Tables);
- представления (SQL Server Views);
- хранимые процедуры (Stored Procedures);
- правила (Rules);
- значения по умолчанию (Defaults);
- типы данных, определенные пользователем (User Defined Datatypes);
- диаграммы базы данных (Database Diagrams).
Помимо этих видимых объектов в каждой базе данных имеются еще некоторые:
- условия на значения (Constraints);
- индексы (Indexes);
- ключи (Keys);
- триггеры (Triggers).
1.1.2 Типы команд SQL
Основные категории команд, реализующих в SQL выполнение различных функций:
- DDL (Data Definition Language — язык определения данных);
- DML (Data Manipulation Language — язык манипуляций данными);
- DQL (Data Query Language — язык запросов к данным);
- DCL (Data Control Language — язык управления данными);
- команды администрирования данных;
- команды управления транзакциями.
Среди таких функций — построение объектов базы данных, управление объектами, пополнение таблиц базы данных новыми данными, обновление данных, уже имеющихся в таблицах, выполнение запросов, управление доступом пользователей к базе данных, а также осуществление общего администрирования базы данных.
1.1.3 Основные типы данных
Типы данных позволяют хранить в базе данных различные по своей природе данные от любых символов до десятичных чисел, значений дат и времени. Подход к разделению данных на типы во всех языках одинаков - и при работе с переменными в языках третьего поколения типа С, и при работе с реляционными базами данных с помощью SQL. Хотя в каждой реализации SQL для стандартных типов данных используются разные имена, работают они практически одинаково. И при краткосрочном планировании, и с точки зрения перспективы нужно с особой тщательностью выбирать типы данных, их длину, масштаб и точность. При этом нужно принять во внимание и сложившиеся правила соответствующего бизнеса, и то, каким образом должны предоставляться данные конечному пользователю. Для этого вы должны понимать природу самих данных и то, как эти данные связаны внутри базы данных. Типы данных являются характеристиками самих данных, чьи атрибуты размещаются прямо в соответствующих полях таблицы. Например, можно указать, что некоторое поле должно содержать только числовые значения, и это не позволит вводить буквенно-числовые значения, когда, например, вы не хотите, чтобы последние появлялись в поле, предназначенном для хранения денежных значений.
Самыми общими типами в SQL, как и в большинстве других языков, являются: символьные строки; числовые строки; значения даты и времени.
Символьные (character) типы данных позволяют хранить буквенные, числовые и специальные (например, ? или >) символы. При загрузке в область хранения (такую, как столбец таблицы) символьные данные вводятся в одинарных или двойных кавычках.
Тип char(n). При хранении данных этого типа для каждого символа используется один байт. Число n определяет размер области хранения максимального количества символов данного столбца. Если вводится значение, меньшее n, SQL Server добавит пробелы после последнего символа, чтобы общая длина равнялась n.
Для экономии дискового пространства, когда хранящиеся в столбце значения имеют разную длину, можно использовать тип varchar(n). В отличие от предыдущего типа данных, размер области хранения для данных этого типа меняется в соответствии с фактическим количеством символов, хранящихся в каждом столбце таблицы, пробелы в конце введенного значения не добавляются.
Тип text. Используется для хранения больших объемов текстовой информации. Для вставки данных в столбец, определенный для данных этого типа, они должны быть заключены в одинарные кавычки.
Числовые (numeric) типы данных. Стандартными для SQL являются следующие типы: integer, smallint – для хранения целых чисел; real – для хранения положительных или отрицательных дробей с точностью до семи цифр; float(n) - для хранения положительных или отрицательных дробей с точностью до пятнадцати цифр.
Типы данных datetime и smalldatetime. Они используются для хранения даты и времени. Гораздо удобнее хранить дату и время в формате одного из предназначенных для этого типов данных, а не в виде строки символов. В этом случае дата и время выводятся на экран в привычном формате. Тип datetime позволяет определить дату и время, начиная с 1/1/1753 и заканчивая 12/31/9999; а тип smalldatetime – с 1/1/1900 по 6/6/2079.
Перечисленные типы данных позволяют хранить до 90% информации. Кроме этих типов, Transact SQL содержит набор специальных типов данных. Можно определить собственный тип данных - пользовательский, который затем будет использоваться для сохраняемых структур.
При назначении типа данных столбцу таблицы возможно использование ограничений NULL/NOT NULL, которые позволяют указать, какие из столбцов должны обязательно иметь значения во всех строках таблицы.
1.2 Работа с базой данных
1.2.1 Создание базы данных
Для создания любого объекта SQL Server и, в частности, базы данных существует несколько способов, базирующихся на выполнении определенной команды.
Работа начинается с создания базы данных. Команда создания базы данных Create Database имеет следующий синтаксис:
CREATE DATABASE имя_базы_данных
ON [PRIMARY]
(NAME = имя_базы_данных_data,
FILENAME='…\имя_базы_данных _data.mdf ', size = размер,
maxsize = максимальный размер, filegrowth = приращение)
LOG ON
(NAME = имя_базы_данных _log,
FILENAME=’…\имя_базы_данных _log.ldf ', size = размер,
maxsize = максимальный размер, filegrowth = приращение)
Здесь и далее при описании общего вида команды, размещение опции в квадратных скобках означает, что этот параметр не всегда обязателен. Например, в данном случае параметр PRIMARY определяет файл, содержащий логическое начало базы данных и системных таблиц. В базе данных может быть только один первичный (PRIMARY) файл. Если этот параметр пропущен, то первичным считается первый файл в списке. По умолчанию файлам типа primary присваивается расширение .mdf. Опции разделены вертикальной чертой – это означает возможность выбора из двух альтернативных вариантов. Многоточие означает путь.
1.2.2 Удаление базы данных
Удаление базы данных приводит к освобождению всего занимаемого ею пространства во всех файлах, где эта база данных находилась, а также к удалению всех содержащихся в ней объектов:
а) удаление базы данных в графическом режиме предполагает выполнение следующих действий:
- щелкните мышью имя базы данных, которую хотите удалить;
- выберите в контекстном меню команду Delete; в появившемся окне сообщений подтвердите необходимость удаления базы данных.
б) для удаления базы данных с помощью Transact-SQL достаточно выполнить команду
DROP DATABASE имя_базы_данных
1.2.3 Создание резервной копии базы данных
Для сохранения копии базы данных, переноса ее на съемный носитель, вначале необходимо создать резервную копию базы данных посредством специальных возможностей MS SQL Server 2005:
- выберите свою базу данных из списка Databases и в контекстном меню строку Tasks-Back Up;
- в появившемся окне создания резервной копии вначале очистите список названий баз данных, готовых к копированию;
- кнопкой «Обзор» откройте следующее окно для выбора места на диске, введите имя резервной копии базы данных, подтвердите операцию копирования.
Система должна дать сообщение об успешном копировании.
Надо отметить, что под резервной копией понимается сохранение данных базы данных. Если же появилась необходимость переноса всей базы данных полностью, то это можно выполнить, скопировав .mdf и .ldf файлы, которые располагаются по адресу C:\Program Files\...\Ms SQL\Data\имя_файла.
1.2.4 Восстановление базы данных
Если появилась необходимость перенести сохраненную резервную копию на компьютер, это тоже выполняется посредством специальных возможностей MS SQL Server 2005:
- выберите базу данных для проведения операции восстановления;
- в контекстном меню выберите строку Tasks-Restore;
- появится страница с общими параметрами восстановления; укажите источник и местоположение резервной копии;
- выберите страницу «Параметры», отметьте флажок «Перезаписать существующую базу данных» и первый переключатель в разделе «Состояние восстановления»;
- подтвердите выбранные операции.
Система сообщит об успешном восстановлении. Если появится сообщение о невозможности восстановления базы данных и система предложит изменить скрипт, необходимо выполнить это требование (в отдельном окне со скриптом).
1.3 Определение структуры базы данных
1.3.1 Описание базы данных, используемой в лабораторной работе
В дальнейшем для освоения работы в среде SQL Server будет рассматриваться база данных компании, занимающейся продажами. Структура базы данных определяется на этапе проектирования. Вопросы проектирования базы данных подробно рассматриваются в расчетно-графической работе №1. Назовем эту базу TradeCompany.
База данных TradeCompany должна содержать данные о деятельности некоторой торговой фирмы. Фирма продает разнообразные виды товаров. На фирме имеется информация о клиентах фирмы (юридические лица). Для каждой сделки по продажам выписывается счет, в котором отражаются: номер счета, данные о клиенте, перечень и количество проданных товаров, дата продажи.
Предположим, что вся эта информация хранится в таблицах Товары, Клиенты и Счета. Любая таблица имеет структуру и хранимые в таблице данные. Структура таблицы определяется ее столбцами: их количеством, именем каждого столбца, типом данных, которые хранятся в столбце, и шириной столбца.
Структура таблиц базы данных TradeCompany приведена ниже.
Таблица 1.1 - Товары
|
Код товара |
Описание товара |
Цена товара |
Таблица 1.2 - Клиенты
|
Код клиента |
Название клиента |
Адрес клиента |
Телефон клиента |
Таблица 1.3 - Счета
|
Номер счета |
Код клиента |
Код товара |
Количество |
Дата счета |
Данные определяются содержимым строк таблицы. Столбцы в таблице называют полями, а строки - записями.
Ключевое поле (primary key) – это столбец, данные в котором однозначно идентифицируют каждую строку данных в таблице реляционной базы данных. Задачей ключевого поля является обеспечение уникальности каждой записи. Обычно ключ задается одним столбцом в таблице, но можно задать и сложный ключ на основе комбинации значений нескольких столбцов. Ключ таблице назначается при ее создании. Внешний ключ (foreign key) – это столбец в дочерней таблице, ссылающийся на ключ родительской таблицы. Столбец, назначенный внешним ключом, используется для ссылок на столбец, определенный как ключ в другой таблице.
В соответствии с требованиями используемого программного обеспечения для объектов рассматриваемой базы данных будем использовать названия полей на английском языке (сами данные можно вводить в кириллице). Что касается назначения имен таблицам, следует отметить следующее. В базе данных, кроме таблиц, может содержаться и множество других объектов. Поэтому за стандарт принято наличие суффикса _TBL в именах таблиц (а, например, суффикс _IDX используется для индексов таблиц). Желательно не только следовать правилам назначения имен, но и правилам, принятым внутри соответствующей области деятельности, чтобы имена носили описательный характер и соответствовали тем данным, на которые эти имена указывают. Также в именах столбцов, состоящих из нескольких слов, в качестве разделителя обычно используется символ подчеркивания. Использование суффиксов при назначении имен объектам базы данных не является обязательным. Выберем названия для таблиц создаваемой базы данных: CUSTOMER_TBL, PRODUCTS_TBL, ORDERS_TBL.
С учетом изложенного, схему связей между таблицами рассматриваемой базы данных можно представить в следующем виде (см. рисунок 1.1).

Рисунок 1.1 - Связи между таблицами базы данных TradeCompany
Линии, связывающие таблицы, указывают на связи таблиц посредством общего ключевого поля. В представленном варианте в таблице ORDERS_TBL не определен первичный ключ, так как в счете с одним номером может быть несколько товаров (номер счета используется в бухгалтерских документах).
1.3.2 Определение структур базы данных (DDL)
Язык определения данных (DDL) является частью SQL, дающей пользователю возможность создавать различные объекты базы данных и переопределять их структуру, например, создавать или удалять таблицы.
Рассмотрим следующие команды DDL: CREATE TABLE, ALTER TABLE, DROP TABLE.
Чтобы создавать таблицы, используется оператор CREATE TABLE.
Синтаксис оператора для создания таблиц:
CREATE TABLE имя_таблицы
( ПОЛЕ1 ТИП ДАННЫХ [NOT NULL],
ПОЛЕ2 ТИП ДАННЫХ [NOT NULL],
ПОЛЕЗ ТИП ДАННЫХ [NOT NULL],
ПОЛЕ4 ТИП ДАННЫХ [NOT NULL],
ПОЛЕ5 ТИП ДАННЫХ [NOT NULL] )
Ключ таблице назначается при ее создании с помощью опции PRIMARY KEY одному или нескольким полям и является по своей сути ограничивающим условием:
CREATE TABLE имя_таблицы PRIMARY KEY
(ПОЛЕ1 ТИП ДАННЫХ [NOT NULL], …)
Можно создать ключ и непосредственно как ограничивающее условие через запятую после определения всех столбцов таблицы, причем, если ключ является составным, перечисляются все его компоненты:
CREATE TABLE имя_таблицы
(ПОЛЕ1 ТИП ДАННЫХ [NOT NULL],
ПОЛЕ2 ТИП ДАННЫХ [NOT NULL], …
PRIMARY KEY (ПОЛЕ1, ПОЛЕ2) )
Внешний ключ создается с помощью опции FOREIGN KEY. Внешний ключ создается после определения всех столбцов таблицы следующим образом:
CREATE TABLE имя_таблицы_1
(ПОЛЕ1_1 ТИП ДАННЫХ [NOT NULL],
ПОЛЕ1_2 ТИП ДАННЫХ [NOT NULL],
…,
ПОЛЕ2_1 ТИП ДАННЫХ [NOT NULL],
CONSTRAINT ПОЛЕ2_1_FK FOREIGN KEY (ПОЛЕ2_1)
REFERENCES имя_таблицы_2 (ПОЛЕ2_1) )
Столбец ПОЛЕ2_1 здесь назначается внешним ключом таблицы имя_таблицы_1. Этот внешний ключ ссылается на столбец ПОЛЕ2_1 таблицы имя_таблицы_2.
1.4 Модификация таблицы
После создания таблицу можно модифицировать и с помощью команды ALTER TABLE. С помощью этой команды можно добавлять и удалять столбцы, менять определения столбцов, добавлять и удалять ограничения.
Стандартный синтаксис команды ALTER TABLE следующий:
ALTER TABLE имя_таблицы [MODIFY] [COLUMN имя_столбца]
[ТИП ДАННЫХ|NULL NOT NULL] [RESTRICT|CASCADE]
[DROP] [CONSTRAINT имя_ограничения]
[ADD] [COLUMN] определение столбца
а) модификация элементов таблицы. Атрибуты столбца задают правила представления данных в столбце. С помощью команды ALTER TABLE можно менять атрибуты столбца. Под атрибутами здесь понимается следующее: тип данных в столбце; длина, точность или масштаб данных в столбце; разрешение или запрет иметь в столбце значение NULL.
При добавлении столбца в уже существующую таблицу с имеющимися в ней данными новому столбцу нельзя назначить атрибут NOT NULL. NOT NULL означает, что столбец должен содержать значения для каждой строки в таблице, так что, если добавляемый столбец получит атрибут NOT NULL, вы сразу же получите противоречие с этим ограничением, поскольку имеющиеся в таблице столбцы не имеют значений для нового столбца. И все же имеется возможность добавить столбец, требующий обязательного ввода данных, следующим образом:
- добавьте столбец, задав ему атрибут NULL (это значит, что в столбце не обязательно должны присутствовать данные);
- введите данные в каждую строку нового столбца таблицы;
- убедившись, что столбец содержит значение в каждой из строк таблицы, можно изменить атрибут столбца на NOT NULL;
б) изменение столбцов. При изменении столбцов таблиц нужно учитывать целый ряд моментов. Общие правила следующие:
- ширина столбца может быть увеличена до максимальной длины, разрешенной для соответствующего типа данных;
- ширину столбца можно уменьшить только до наибольшей длины имеющихся в этом столбце значений;
- для столбцов с числовыми данными ширину всегда можно увеличить;
- для столбцов с числовыми данными ширину можно уменьшить только тогда, когда нового числа знаков будет достаточно для размещения любого из имеющихся в столбце значений;
- для числовых данных можно увеличивать или уменьшать число десятичных знаков;
- тип данных в столбце обычно можно изменить.
В некоторых реализациях использование определенных опций оператора ALTER TABLE может быть запрещено. Например, вам могут не позволить удалять столбцы из таблиц. Вместо этого вам нужно будет удалить таблицу и создать новую с нужным числом столбцов. Могут возникнуть проблемы с удалением столбцов из таблицы, зависящей от столбца из другой таблицы, или с удалением столбца, на который ссылается другая таблица. По этому поводу внимательно просмотрите документацию, предлагаемую той реализацией SQL, с которой вы работаете;
в) добавление ограничений. Эта ситуация может возникнуть, например, в случае, когда при создании таблицы не были определены ключевые поля:
ALTER TABLE имя_таблицы
ADD CONSTRAINT имя_таблицы_PK
PRIMARY KEY (имя_поля1, имя_поля2)
г) внешние ключи можно назначить таблице следующим образом:
ALTER TABLE имя_таблицы
ADD CONSTRAINT ID_FK FOREIGN REY (имя_поля)
REFERENCES имя_таблицы (имя_поля)
д) удаление таблиц является, пожалуй, самым простым делом. Синтаксис оператора, используемого для удаления таблиц, следующий:
DROP TABLE имя_таблицы [RESTRICT|CASCADE ]
Если используется опция RESTRICT, либо на таблицу ссылается представление или ограничение, используемый для удаления оператор DROP возвратит ошибку. При использовании опции CASCADE будет выполнено удаление не только самой таблицы, но и всех ссылающиеся на таблицу представлений и ограничений.
1.5 Задание на лабораторную работу
Прежде чем приступить к выполнению задания, следует ознакомиться с соответствующими разделами виртуальной обучающей системы SQL_Education.
1.5.1 Создание базы данных. TradeCompany:
а) создание базы данных в графическом режиме.
При этом способе выполняются следующие действия:
- запустите программу MS SQL Server 2005 посредством основного меню: Пуск-Все программы- MS SQL Server 2005-SQL Server Management Studio;
- в появившемся диалоговом окне предлагается ввести имя сервера, оно установлено по умолчанию, щелкните на Connect;
- в следующем окне Object Explorer на строке Databases из контекстного меню выберите New Database;
- появится окно, в котором надо ввести имя создаваемой базы данных и ОК; в нижней части этого окна в таблице располагается информация о файлах базы данных (разверните окно, чтобы видеть все колонки таблицы); здесь кнопка Add предназначена для случая, если база данных располагается не в одном файле;
- закройте окно; убедитесь, что ваша база появилась в списке Database;
- удалите базу данных (команда Delete из контекстного меню);
б) создание базы данных посредством команды Transact-SQL.
В окне Object Explorer щелкните на кнопку New Query. В правой части экрана появится окно редактора запросов. Введите в него команду на создание базы данных. Если команда выполнилась успешно, в нижней части окна должно появиться сообщение: Command (s) completed successfully.
В отличие от графического режима, чтобы увидеть в списке баз данных только что созданную базу, необходимо на строке Database из контекстного меню выбрать Refresh.
1.5.2 Создайте резервную копию базы данных. Запомните путь, где сохранилась резервная копия.
1.5.3 Выполните восстановление базы данных.
1.5.4 Обоснованно выберите типы данных для полей таблиц рассматриваемой базы данных TradeCompany. Определите первичные и внешние ключи таблиц.
1.5.5 Активизируйте MS SQL Server 2005; сделайте текущей базу данных TradeCompany.
1.5.6 Создание и модификация таблиц базы данных TradeCompany.
Таблицы тоже можно создавать несколькими способами:
а) для создания таблицы в графическом режиме необходимо выполнить следующее (создайте таким способом таблицу CUSTOMER_TBL.):
- откройте папку своей базы данных; отметьте строку Tables и в контекстном меню выберите New Table;
- в появившемся окне введите наименования столбцов таблицы, выберите тип данных, установите (или уберите) флажок Allows Null; внизу окна установите свойства столбцов;
- закройте текущее окно, подтвердите сохранение изменений, введите имя таблицы;
б) нажмите в окне Object Explorer кнопку New Query, откроется окно редактора команд, вводя в это окно команды создания таблицы (создайте таким способом таблицы PRODUCTS_TBL, ORDERS_TBL), нажимая кнопку Execute (выполнение команды), создайте еще одну таблицу;
в) чтобы изменить структуру таблицы, выбираем из контекстного меню Modify Table;
г) для быстрого изучения команд SQL, выделите таблицу базы данных, выберите в контекстном меню Script Table As/ … /New Query Editor Window (вместо многоточия выберите требуемую команду), появится окно редактора команд, в котором можно просмотреть заготовки изучаемых скриптов на создание, удаление, обновление и т.д.
1.5.7 Просмотрите диаграмму связей созданной базы данных (раздел Diagrams).
1.6 Требования к отчету
Отчет по работе выполняется на бумажном носителе и должен содержать:
- описание вариантов создания базы данных;
- обоснование выбора типов данных для полей таблиц;
- определение первичных и внешних ключей таблиц;
- команды создания структур таблиц.
1.7 Контрольные вопросы
1.7.1 Что означает аббревиатура SQL?
1.7.2 Перечислите типы команд SQL.
1.7.3 Какие способы создания базы данных вы знаете, в чем их отличия?
1.7.4 Сколько файлов используется для базы данных?
1.7.5 Для чего предназначен журнал транзакций?
1.7.6 Объясните создание резервной копии и восстановление базы данных.
1.7.7 Объясните способы удаления базы данных.
1.7.8 Дайте определение реляционной базы данных.
1.7.9 В каких объектах хранится исходная информация базы данных?
1.7.10 Что называется полем таблицы, записью таблицы?
1.7.11 Какая команда определяет структуру таблицы?
1.7.12 Дайте определение первичного ключа таблицы.
1.7.13 Объясните назначение внешних ключей.
1.7.14 Какие основные типы данных вам известны?
1.7.15 С помощью какой команды можно модифицировать структуру таблицы?
1.7.16 Как можно удалить таблицу?
2 Лабораторная работа № 2. Язык манипуляции данными
Цель работы: изучение языка манипуляции данными.
Язык манипуляций данными (DML) является частью SQL, обеспечивающей пользователю базы данных возможность вносить реальные изменения в данные реляционной базы данных. С помощью DML пользователь может пополнять таблицы новыми данными, обновлять уже имеющиеся данные и удалять их из таблиц.
В SQL имеется три основных команды DML: INSERT, UPDATE, DELETE.
2.1 Заполнение таблиц данными
Заполнение таблицы данными — это процесс ввода новых данных в таблицу либо вручную с помощью отдельных команд, либо автоматически с помощью программ или каким-либо иным способом. То, какие данные и в каком количестве можно будет при этом вводить в таблицу, зависит от многих факторов, основными из которых являются ограничения, заданные при определении таблицы, физические размеры таблицы, типы данных ее столбцов, ширина столбцов, требования целостности в виде ключей и внешних ключей.
Возможны следующие ситуации:
а) ввод новых данных в таблицу. Для ввода новых данных в таблицу используется оператор INSERT. Он имеет вид:
INSERT INTO имя_таблицы
VALUES ('значение1', 'значение2', [ NULL ] )
Согласно представленному здесь синтаксису оператора INSERT, в список VALUES необходимо поместить значения для всех столбцов соответствующей таблицы. Значения в списке разделяются запятыми. Символьные значения и значения дат должны быть заключены в кавычки. Для числовых значений и пустых значений, задаваемых ключевым словом NULL, кавычки не нужны. Должны быть указаны значения для всех столбцов таблицы;
б) ввод данных в определенные столбцы таблицы. Имеется возможность ввести данные не во все, а только в определенные столбцы. В этом случае в операторе INSERT вместе со списком значений VALUES нужно указать и список соответствующих им столбцов:
INSERT INTO имя_таблицы ('СТОЛБЕЦ1', 'СТОЛБЕЦ2')
VALUES ('ЗНАЧЕНИЕ1', 'ЗНАЧЕНИЕ2');
Порядок в списке значений должен соответствовать порядку ввода значений в таблицу, задаваемому списком столбцов. Список столбцов в операторе INSERT не обязательно должен соответствовать списку столбцов в определении соответствующей таблицы, а вот список вводимых значений должен обязательно соответствовать списку избранных столбцов;
в) ввод значений NULL. Ввести значение NULL в таблицу просто. Это бывает нужно, в частности, когда значение соответствующего столбца не известно. Синтаксис оператора для ввода значения NULL следующий.
INSERT INTO имя_схемы.имя_таблицы
VALUES ('ЗНАЧЕНИЕ!', NULL, 'ЗНАЧЕНИЕЗ'}
2.2 Обновление уже имеющихся данных
Уже существующие в таблице данные можно изменить с помощью команды UPDATE. Команда UPDATE не добавляет новых записей в таблицу и не удаляет их, а только дает возможность изменить данные. С помощью одной такой команды можно изменить данные только одной таблицы, но одновременно можно менять данные нескольких столбцов. Одним таким оператором можно изменить и одну строку данных и целый набор строк:
а) обновление значений одного столбца. В своей простейшей форме оператор UPDATE изменяет один столбец таблицы. При изменении одного столбца можно изменить только одну запись или сразу несколько Синтаксис оператора для изменения данных в одном столбце следующий
UPDATE имя_таблицы
SET ИМЯ_СТОЛБЦА = 'ЗНАЧЕНИЕ'
[WHERE УСЛОВИЕ]
б) обновление с помощью оператора UPDATE нескольких столбцов сразу:
UPDATE имя_таблицы
SET СТОЛБЕЦ1 = 'ЗНАЧЕНИЕ'
[, СТОЛБЕЦ2 = 'ЗНАЧЕНИЕ']
[, СТОЛБЕЦ3 = 'ЗНАЧЕНИЕ']
[WHERE УСЛОВИЕ]
Обратите внимание на использование ключевого слова SET: оно одно, а описаний столбцов - несколько. Описания столбцов разделяются запятыми.
2.3 Удаление данных из таблиц
Для удаления данных из таблиц используется команда DELETE. Команда DELETE предназначена не для того, чтобы удалять значения отдельных столбцов, а для того, чтобы удалять целые записи. Оператор DELETE следует применять с осторожностью - слишком уж безотказно он работает. Чтобы удалить одну или несколько записей из таблицы, используйте следующий синтаксис оператора DELETE.
DELETE [FROM] имя_таблицы
[WHERE УСЛОВИЕ];
При удалении строк из таблицы ключевое слово WHERE представляет собой очень важную часть оператора DELETE. Если ключевое слово WHERE в операторе DELETE опущено, будут удалены все строки таблицы. Поэтому примите за правило всегда использовать ключевое слово WHERE в операторе DELETE.
2.4 Задание на лабораторную работу
Прежде чем приступить к выполнению задания, следует ознакомиться с соответствующими разделами виртуальной обучающей системы SQL_Education.
2.4.1 Измените структуру таблицы ORDERS_TBL – добавьте в нее ключевое поле ORDERS_ID (это идентификатор строки в таблице). Это связано с тем, что иногда необходимо однозначно определять каждую сделку по проданному товар).
2.4.2 Заполните данными все таблицы вашей базы данных. используйте все возможности ввода данных:
- графический режим: выделить таблицу, в контекстном меню выбрать Open Table;
- выделить таблицу и из контекстного меню выбрать Insert To-New Query Editor Window:
- выбрать меню New Query.
В таблицах CUSTOMER_TBL и PRODUCT_TBL должно быть не менее пяти записей, в таблице ORDERS_TBL – не менее 15-ти (покупка всевозможных товаров всеми клиентами в различные дни).
2.4.3 Добавьте в таблицу ORDERS_TBL столбец TOTAL_COST (в этом столбце будет храниться стоимость проданного товара). Заполните этот столбец значениями NULL.
2.4.4 Используя команду UPDATE, рассчитайте значения поля TOTAL_COST как произведение цены товара (PRODUCT_TBL.COST) на количество проданного товара (ORDERS_TBL.QTY).
2.4.5 Измените цену некоторых товаров в таблице PRODUCT_TBL. Измените количество проданного товара. Убедитесь, что данные столбца ORDERS_TBL.TOTAL_COST изменяются.
2.4.6 Создайте таблицу MANUFACTURER_TBL, в которой будут храниться данные о производителях товаров (поля таблицы выберите по своему усмотрению). В соответствии с этим изменится структура таблицы PRODUCT_TBL: первичный ключ таблицы MANUFACTURER_TBL будет внешним ключом таблицы PRODUCT_TBL. Внесите эти изменения.
2.4.7 Создайте таблицу SELLER_TBL, в которой будут храниться данные о торговых агентах (продавцах). В соответствии с этим изменится таблица ORDERS_TBL – в нее надо добавить первичный ключ таблицы SELLER_TBL (надо учитывать, кем совершена сделка по продаже).
2.4.8 Просмотрите диаграмму связей преобразованной реляционной схемы базы данных.
2.4.9 Заполните созданные таблицы и поля данными.
2.4.10 Удалите записи о продажах, совершенных в марте текущего года.
2.5 Требования к отчету
Отчет по работе выполняется на бумажном носителе и должен содержать:
- команды добавления данных в таблицы базы данных;
- все команды изменения реляционной схемы данных;
- команды обновления данных в таблицах базы данных;
- диаграмму связей базы данных;
- листинги таблиц с данными.
2.6 Контрольные вопросы
2.6.1 Что такое DML?
2.6.2 Какие команды манипуляции данными вы знаете?
2.6.3 Что означает определение поля NOT NULL?
2.6.4 Что указывается в списке VALUES команды INSERT?
2.6.5 Можно ли вводить данные только в определенные столбцы таблицы?
2.6.6 Можно ли командой UPDATE менять данные в нескольких таблицах?
2.6.7 Можно ли командой UPDATE менять данные в нескольких столбцах одной таблицы?
2.6.8 Всегда ли необходимо использовать условие в операторе удаления записей таблицы?
2.6.9 В чем отличие DDL от DML?
2.6.10 В чем отличие структуры таблицы и данных таблицы?
3 Лабораторная работа №3 Отбор данных (DQL)
Цель работы: освоение языка запросов к базе данных и способов формирования простых и сложных запросов.
3.1 Оператор SELECT
Этот раздел языка представлен только одной командой, однако для пользователя реляционной базы данных язык запросов к данным (DQL) является самой главной частью SQL. Этой командой является команда SELECT. Команда, имеющая множество опций и необязательных параметров, используется для построения запросов к реляционным базам данных. С ее помощью можно конструировать запросы любой сложности — от самых общих до специальных и от самых простых до невероятно сложных.
Запрос — это требование на получение информации из базы данных. Запросы используются для того, чтобы извлечь данные в том виде, который удобен пользователю.
Оператор SELECT используется для составления запросов к базе данных. Оператор SELECT не используется сам по себе, а требует указания некоторых параметров с помощью ключевых слов. Кроме обязательных, у этого оператора имеется несколько необязательных ключевых слов, расширяющих его возможности.
В операторе SELECT ключевое слово SELECT используется в совокупности с ключевым словом FROM для того, чтобы организовать извлечение данных из базы данных в удобном для чтения формате. Часть запроса, заданная ключевым словом SELECT, определяет источник отбора данных. Синтаксис простого оператора SELECT следующий:
SELECT * | ALL | DISTINCT [СТОЛБЕЦ1, СТОЛБЕЦ2 ]
FROM ТАБЛИЦА1 [, ТАБЛИЦА2 ]
За ключевым словом SELECT в запросе следует список столбцов, значения которых вы хотели бы видеть в результате запроса. За ключевым словом FROM следует список таблиц, из которых должны извлекаться данные. Звездочка (*) используется для указания того, что в результате запроса должны быть показаны значения всех столбцов таблицы. Опция ALL используется тогда, когда нужно показать все значения столбца, включая и повторяющиеся. Опция DISTINCT используется для того, чтобы повторения исключить. Из этих опций используемой по умолчанию опцией является ALL, которую поэтому указывать не обязательно. Обратите внимание на то, что имена столбцов в списке, следующем за ключевым словом SELECT, разделяются запятыми, точно так же, как имена таблиц, следующие за ключевым словом FROM.
3.2 Операции в условиях для отбора данных
Для отбора данных используются условия. Условие - это часть запроса, содержащая информацию, на основе которой отбираются данные. Условие может принимать либо значение TRUE, либо значение FALSE, что и используется для отбора.
Синтаксис оператора SELECT, использующего выражение WHERE, следующий:
SELECT [ ALL | * | DISTINCT СТОЛБЕЦ1, СТОЛБЕЦ2 ]
FROM ТАБЛИЦА1 [ , ТАБЛИЦА2 ]
WHERE [УСЛОВИЕ1|ВЫРАЖЕНИЕ1]
[ AND УСЛОВИЕ2 | ВЫРАЖЕНИЕ2 ]
В выражении WHERE может содержаться несколько условий.
Условия задаются с помощью операций. Операция - это символ или ключевое слово SQL, использующееся для связывания элементов в операторе SQL.
В условиях для отбора данных используются следующие типы операций: операции сравнения, логические операции, арифметические операции, специальные операции.
Операции сравнения представляются знаками =, <>, <, >, <=, >=. Эти операции предназначены соответственно для проверки равенства и неравенства значений, проверки выполнения отношений "меньше", "больше", "меньше или равно", "больше или равно" между ними.
Логические операции в SQL задаются ключевыми словами, а не символами. Используются следующие логические операции:
- AND (логическое "И") сравнивает два логических значения и возвращает TRUE (истина), если оба значения истинны (т.е. равны TRUE), в остальных случаях - FALSE (ложь);
- OR (логическое "ИЛИ") сравнивает два логических значения и возвращает TRUE, если хотя бы один из аргументов равен TRUE;
- NOT (логическое отрицание ) возвращает TRUE, если его аргумент равен FALSE и наоборот.
Арифметические операции используются в SQL точно так же, как и в большинстве других языков. Таких операций четыре: + (сложение), * (умножение), - (вычитание), / (деление). Арифметические операции можно комбинировать. Пользователь может управлять порядком выполнения операций в выражении только с помощью скобок. Заключенное в скобки выражение означают необходимость рассматривать выражение как единый блок, порядок выполнения операций (приоритет операций) задает порядок, в котором обрабатываются выражения в математических выражениях или встроенных функциях SQL.
3.3 Отбор данных из нескольких таблиц
Одной из самых полезных возможностей SQL является возможность отбора данных из нескольких таблиц. Для связывания таблиц используются ключевые поля.
При связывании таблиц необходимым элементом оператора SQL является ключевое слово WHERE. Имена таблиц для связывания указываются в списке ключевого слова FROM. Связь определяется в выражении ключевого слова WHERE. Есть несколько типов связывания:
а) связвание по равенству. Это самый полезный тип связывания. Его также называют внутреним связыванием (INNER JOIN). При связывании по равенству таблицы связываются по общему столбцу, который в каждой из таблиц обычно является ключевым. Синтаксис оператора, задающего связывание по равенству, имеет вид:
SELECT таблица1.столбец1, таблица2.столбец2…
FROM таблица1, таблица 2 [, таблица3 ]
WHERE таблица1.имя_столбца = таблица2.имя_столбца
[ AND таблица1.имя_столбца = таблица3.имя_столбца]
Обратите внимание, что в списке оператора SELECT вместе с именами каждого из столбцов указываются имена соответствующих таблиц. Это назвается подробным определением столбца в запросе. Подробные определения требуются только для тех столбцов, которые присутствуют в нескольких из указанных в запросе таблиц. Но в операторе обычно указываются подробные определения для всех столбцов;
б) естественное связывание. Естественное связывание почти эквивалентно связыванию по равенству, но при естественном связывании таблиц повторения эквивалентных столбцов исключаются. Условие связывания оказывается таким же, но столбцы выбираются иначе. Синтаксис оператора:
SELECT таблица1.*, таблица2.имя_столбца
[ , таблица3.имя_столбца ]
FROM таблица1, таблица 2 [, таблица3 ]
WHERE таблица1.имя_столбца = таблица2.имя_столбца
[ AND таблица1.имя_столбца = таблица3.имя_столбца ]
в) связывание по неравенству. При связывании по неравенству две или несколько таблиц объединяются по условию неравенства значения столбца таблицы значению из столбца другой таблицы. Синтаксис соответствующей части оператора:
FROM таблица1, таблица 2 [, таблица3 ]
WHERE таблица1.имя_столбца != таблица2.имя_столбца
[ AND таблица1.имя_столбца != таблица3.имя_столбца ]
При связывании по неравенству обычно в выводе присутствует ряд строк, которые на самом деле оказываются ненужными, так что результаты запроса, в котором используется связывание по неравенству, всегда требуют дополнительной проверки;
г) рекурсивное связывание (использование псевдонимов). Отметим, что с целью сокращения объема печатания таблицам могут назначаться псевдонимы - временное переименование таблиц. Особенно часто псевдонимы используются при рекурсивном связывании.
Рекурсивное связывание (SELF JOIN) предполагает связывание таблицы с ней же самой, применяя временное переименование таблицы в операторе SQL. Синтаксис оператора:
SELECT А.имя_столбца, В.имя_столбца, [ , С.имя_столбца ]
FROM таблица1 А, таблица 2 В [, таблица3 С ]
WHERE А.имя_столбца = В.имя_столбца
[ AND А.имя_столбца = С.имя_столбца ]
Здесь А, В, С – псевдонимы таблиц.
д) связывание по нескольким ключам. В зависимости от структуры базы данных таблицы могут иметь не простые, а составные ключи, то есть состоящие из нескольких столбцов. Из нескольких столбцов может состоять и внешний ключ. В этом случае в предложении WHERE надо указать сравнение каждой составляющей ключа.
3.4 Задание на лабораторную работу
Прежде, чем приступить к выполнению задания, следует ознакомиться с соответствующими разделами виртуальной обучающей системы SQL_Education.
3.4.1 Выполните поиск информации в отдельных таблицах базы данных TradeCompany:
- список всех клиентов фирмы;
- список всех товаров, имеющихся на фирме;
- список товаров, цена которых не превышает указанную сумму;
- список счетов, выданных в текущем месяце;
- список товаров определенного наименования.
3.4.2 Выполните поиск информации в нескольких таблицах базы данных:
- список клиентов фирмы, приобретавших товар определенного вида;
- список всех клиентов и их счетов;
- список счетов, выставленных определенному клиенту;
- список клиентов и наименование товаров, приобретенных ими в определенную дату;
- список товаров и их количество, приобретенных определенным клиентом;
- найдите дату счета, выписанного определенному клиенту за приобретение определенного товара;
- список всех клиентов, которые не приобретали определенный товар.
3.5 Требования к отчету
Отчет по лабораторной работе содержит листинги команд и результаты выполнения запросов.
3.6 Контрольные вопросы
3.6.1 К какому разделу SQL относится оператор SELECT?
3.6.2 Назовите обязательные составляющие оператора SELECT.
3.6.3 Для всех ли данных в выражении ключевого слова WHERE обязательно нужно использовать кавычки?
3.6.4 Можно ли в выражении для ключевого слова WHERE задать несколько условий?
3.6.5 Допустимы ли кавычки для значений числовых полей?
3.6.6 Можно ли оператор SELECT использовать без ключевого слова FROM?
3.6.7 Что такое псевдоним таблицы?
3.6.8 При связывании таблиц должны ли они связываться в том же порядке, в каком они указаны в выражении ключевого слова FROM?
3.6.9 При использовании в операторе запроса таблицы-связки обязательно ли выбирать в запросе ее столбцы?
3.6.10 Можно ли связывать в запросе не один, а несколько столбцов таблиц? Какая часть оператора SQL задает условия связывания таблиц?
3.6.11 Что будет, если в запросе указать выборку из двух таблиц, но не связать их?
3.6.12 Что такое рекурсивное связывание?
4 Лабораторная работа № 4. Использование агрегатных функций и специальных операторов в условиях отбора
Цель работы: освоение операторов специального вида и возможностей подведения итогов по данным запроса.
4.1 Операторы специального вида
Под операторами специального вида мы будем понимать использование различных ключевых слов в операторах выборки:
- IN определяет список значений, в который должно входить значение поля. Набор значений для оператора IN заключается в круглые скобки, значения разделяются запятыми. Например, предложение WHERE ADDRESS IN (‘Samal’, ‘Tastak’) выберет из списка сотрудников, проживающих в микрорайонах Самал и Тастак;
- BETWEEN в отличие от списка допустимых значений BETWEEN, определяет диапазон значений. В запросе необходимо указать слово BETWEEN, затем начальное значение, ключевое слово AND и конечное значение;
- LIKE применим только к символьным полям, с которыми он используется, чтобы находить подстроки. В качестве условия он использует специальные символы: символ подчеркивания _ - замещает любой одиночный символ; знак процента % - замещает последовательность любого числа символов. LIKE удобен при поиске значений - можно использовать ту часть значения, которую помните;
- IS NULL – используется для проверки равенства данного значения значению NULL. Например, WHERE PHONE IS NULL – поиск сотрудников, не имеющих телефонов.
Для всех этих операций можно построить их отрицания (ключевое слово NOT), чтобы рассмотреть противоположные условия. Ключевое слово NOT используется с операциями следующим образом: NOT BETWEEN, IS NOT NULL, NOT IN, NOT LIKE.
4.2 Сортировка вывода
Обычно требуется, чтобы выводимые данные были как-то упорядочены. Выводимые данные можно упорядочить с помощью выражения, связанного с ключевым словом ORDER BY. Упорядочение, задаваемое с помощью ключевого слова ORDER BY, по умолчанию будет упорядочением по возрастанию, обозначается A-Z (А-Я) в случае сортировки имен. Алфавитное упорядочение по убыванию соответствует порядку Z-А (Я-А). Для числовых значений между 1 и 9 упорядочение по возрастанию обозначается 1-9, а по убыванию – 9-1. Синтаксис оператора SELECT, использующего выражение ORDER BY, следующий:
SELECT [ ALL | * | DISTINCT СТОЛБЕЦ1, СТОЛБЕЦ2 ]
FROM ТАБЛИЦА1 [ , ТАБЛИЦА2 ]
WHERE [ УСЛОВИЕ1 | ВЫРАЖЕНИЕ1 ]
[ AND УСЛОВИЕ2 | ВЫРАЖЕНИЕ2 ]
ORDER BY СТОЛБЕЦ1|ЦЕЛОЕ_ЗНАЧЕНИЕ [ ASC|DESC ];
Ввиду того, что порядок по возрастанию является порядком, принимаемым по умолчанию, нет необходимости указывать ASC вообще.
В SQL предлагаются и некоторые сокращения. Столбец, указанный в списке ключевого слова ORDER BY, можно заменить числом. ЦЕЛОЕ_ЗНАЧЕНИЕ является значением, замещающим действительное имя столбца и соответствующим порядку столбца в списке после ключевого слова SELECT.
4.3 Использование агрегатных функций
Агрегатные функции используются для обобщения данных. SQL Server предоставляет несколько агрегатных функций:
- COUNT производит подсчет строк, удовлетворяющих условию запроса. Синтаксис оператора:
COUNT [ (*) │(DISTINCT│ALL) ] (имя_столбца)
- SUM вычисляет арифметическую сумму всех значений колонки:
SUM ( [ DISTINCT ] имя_столбца)
- AVG вычисляет среднее арифметическое всех значений:
AVG ( [ DISTINCT ] имя_столбца)
- MAX определяет наибольшее из всех выбранных значений:
MAX( [ DISTINCT ] имя_столбца)
- MIN определяет наименьшее из всех выбранных значений:
MIN ( [ DISTINCT ] имя_столбца)
Функции SUM и AVG применимы только к числовым полям. С функциями COUNT, MAX, MIN могут использоваться числовые или символьные поля. При применении к символьным полям MAX, MIN сравнивают значения в алфавитном порядке. Агрегатные функции при своей работе игнорируют значения NULL. Функция COUNT несколько отличается от остальных. Она подсчитывает число значений в данной колонке или число строк в таблице.
Ключевое слово GROUP BY в условии WHERE позволяет задавать подмножество значений, для которых применяется агрегатная функция и упорядочить результат вывода запроса.
4.4 Задание на лабораторную работу
Прежде, чем приступить к выполнению задания, следует ознакомиться с соответствующими разделами виртуальной обучающей системы SQL_Education.
4.4.1. Выберите для работы базу данных TradeCompany.
4.4.2 Получите список клиентов, адреса которых начинаются на определенную букву.
4.4.3 Подсчитайте количество клиентов фирмы.
4.4.4 Подсчитайте количество наименований товаров.
4.4.5 Получите список счетов, выданных в течение последних трех месяцев.
4.4.6 Получите список клиентов, общая сумма счетов которых превышает указанную сумму.
4.4.7 Получите список клиентов и наименование товаров, приобретенных ими в течение двух последних месяцев.
4.4.8 Подсчитайте общую сумму товара, приобретенного определенными клиентами.
4.4.9 Подсчитайте количество всех счетов, выписанных определенному клиенту.
4.4.10 Предположим, что не все продавцы имеют телефоны (приведите данные в соответствие с этим предположением). Подсчитайте число продавцов, имеющих телефоны.
4.4.11 Подсчитайте сумму зарплат всех продавцов (пусть зарплата каждого продавца вычисляется как некоторый % от сделки).
4.4.12 Подсчитайте среднюю зарплату продавцов.
4.4.13 Найдите зачение максимальной и минимальной зарплаты.
4.5 Требования к отчету
Отчет по работе содержит листинги команд использования агрегатных функций и результаты запросов.
4.6 Контрольные вопросы
4.6.1 Какие операторы специального вида вы знаете? Назначение каждой операции?
4.6.2 Какие операции отношения используются в условиях отбора данных?
4.6.3 Какие логические операции используются в операциях отбора данных?
4.6.4 Что такое агрегатная функция?
4.6.5 Играет ли роль тип данных при использовании функции COUNT.
4.6.6 Чтобы группировать данные по столбцу, должен ли этот столбец быть указан в списке ключевого слова SELECT?
4.6.7 Для чего используются псевдонимы таблиц?
5 Лабораторная работа № 5. Создание и использование представлений и хранимых процедур
Цель работы: использование представлений для защиты данных; освоение хранимых процедур.
5.1 Использование представления для защиты данных
Представление – это виртуальная таблица, которая является комбинацией таблиц в форме заранее определенного запроса. Главное различие между представлением и таблицей состоит в том, что данные таблицы требуют физической памяти для своего хранения, а представление просто ссылается на данные реальных таблиц и поэтому места для своих данных не требует.
Представление можно для ограничения доступа пользователей к определенным столбцам и строкам таблиц, в зависимости от условий, задаваемых выражением ключевого слова WHERE в определении представления.
Представление создается с помощью команды CREATE VIEW:
а) создание представления для данных одной таблицы:
CREATE VIEW имя_представления
SELECT * | столбец1 [ , столбец2 ]
FROM имя_таблицы
[WHERE выражение1 [ , выражение2 ] ]
б) создание представления для данных нескольких таблиц:
CREATE VIEW имя_представления
SELECT * | столбец1 [ , столбец2 ]
FROM имя_таблицы1, имя_таблицы2 [ , имя_таблицы3]
[WHERE выражение1 [ , выражение2 ] ]
в) создание представления на основе другого представления:
CREATE VIEW представление2
SELECT *
FROM представление1
5.2 Использование хранимых процедур
Набор операторов SQL, созданный для удобства использования в программах, называется хранимой процедурой.
Некоторые из преимуществ использования сохраненных процедур: - операторы процедуры уже сохранены в базе данных; - операторы процедуры уже проверены и находятся в готовом для использования виде; - при использовании процедур результат получается быстрее; - возможность сохранения процедур позволяет использовать модульное программирование;
- сохраненные процедуры могут вызывать другие процедуры; - сохраненные процедуры могут вызываться другими программами.
В SQL Server процедуры создаются с помощью оператора следующего вида:
CREATE PROCEDURE имя_процедуры
[ [ ( ] @имя_параметра
ТИП_ДАННЫХ [(ДЛИНА) | (ТОЧНОСТЬ) [, МАСШТАБ ])
[=DEFAULT][OUTPUT] ]
[, @ИМЯ_ПАРАМЕТРА
ТИП_ДАННЫХ [(ДЛИНА) | (ТОЧНОСТЬ) [, МАСШТАБ ])
[=DEFAULT][OUTPUT] ]
[WITH RECOMPILE]
AS операторы SQL
Сохраненные процедуры используются следующим образом:
EXECUTE [ @ = ] имя_процедуры
[ [ @ имя_параметра =] значение |
[ @ имя_параметра = ] @ переменная [ OUTPUT ] ]
[WITH RECOMPILE]
5.3 Задание на лабораторную работу
Прежде, чем приступить к выполнению задания, следует ознакомиться с соответствующими разделами виртуальной обучающей системы SQL_Education.
5.3.1 Создайте для базы данных TradeCompany представления различного вида:
- представление, содержащее только описание товара и его цену;
- представление, содержащее название клиента и его адрес;
- представление, содержащее номер счета, название клиента, описание товара и дату счета.
5.3.2 Создайте хранимые процедуры:
- для добавления новых строк в таблицу PRODUCTS_TBL;
- для поиска товаров, цена которых превышает определенную сумму;
- для увеличения цены всех товаров на 12%;
- для поиска счетов клиентов с максимальной общей суммой;
- для формирования списка клиентов с их телефонами;
- для формирования списка товаров с их ценами;
- проверьте работу всех созданных процедур.
5.4 Требования к отчету
Отчет по работе содержит листинги команд создания и работы представления и процедур; результаты работы; результаты выполненных запросов к базе данных TradeCompany.
5.5 Контрольные вопросы
5.5.1 Что такое представление?
5.5.2 Что случится, если таблица, на основе которой строится представление, будет удалена?
5.5.3 Как представление можно использовать для защиты данных?
5.5.4 Как можно удалить представление?
5.5.5 Что такое хранимая процедура?
5.5.6 В чем преимущества использования процедур?
5.5.7 Может ли сохраненная процедура вызывать другую сохраненную процедуру?
5.5.8 Может ли сохраненная процедура выполнять вычисления?
5.5.9 Может ли сохраненная процедура выполнять сравнения вводимых пользователем значений с заранее установленными условиями?
5.5.10 Где хранится процедура?
6 Лабораторная работа № 6. Использование триггеров
Цель работы: освоение механизма триггеров, поддерживающего целостность данных в БД.
6.1 Определение триггера
Триггерами (Triggers) называется специальный класс хранимых процедур, автоматически запускаемых при добавлении, изменении и удалении данных из таблицы. Триггер срабатывает при модификации данных и запускает хранимую процедуру, выполняющую определенные действия. В зависимости от выполняемых пользователем действий, приводящих к запуску триггера, они делятся на три категории: триггеры изменения (UPDATE TRIGGER), триггеры вставки (INSERT TRIGGER) и триггеры удаления (DELETE TRIGGER). В одном триггере могут сочетаться все три типа. Очевидно, что невозможность срабатывания триггера по операции SELECT объясняется отсутствием модификации данных в этой операции.
Триггер присоединяется к определенной таблице и устанавливается на автоматический запуск в ответ на выполнение операции INSERT, DELETE или UPDATE. В отличие от хранимых процедур, триггер не может быть запущен вручную, иметь параметров и возвращать значений. Триггеры имеют множество применений, но чаще всего применяются для реализации делового регламента. Действие триггеров не ограничивается базами данных, в которых они устанавливаются. Их можно применять для модификации данных в таблицах других баз данных, даже на других серверах.
Синтаксис оператора на создание триггера:
/*Заголовок и название триггера*/
CREATE TRIGGER Trigger_name
/*Имя таблицы, для которой написан триггер*/
ON table_name
/*На какие события реагирует триггер*/
FOR INSERT, UPDATE, DELETE
/* Ключевое слово */
AS
/*Определение данных триггера*/
/*Начало тела триггера*/
BEGIN
DECLARE @var_name type
/*var_name – имя переменной,@ - обязательный символ, type - тип данных переменной*/
/*Присвоение переменной значения столбца таблицы*/
SELECT @var_name=Table_name.Column_name
/*Из какой таблицы будет выбираться столбец; T,Q – псевдонимы; inserted – условное обозначение вставляемых данных*/
FROM table_name T, inserted Q
/*Сравниваются ключевые поля исходной таблицы и вставляемых данных*/
WHERE T.key=Q.key
/*Условие выполнения триггера*/
IF условие
BEGIN
/*Отмена транзакции*/
ROLLBACK TRAN
/*Сообщение об ошибке*/
RAISERROR (‘Сообщение’)
END
END
/*Конец триггера*/
Пример создания триггера (создать триггер и проверить его работу рекомендуется после выполнения заданий 7.2.1 – 7.2.3).
Предположим необходимо отслеживать количество товара, которое мы можем продать. Это количество не должно превышать количество товара на складе; если менеджер по ошибке нарушает это условие, система должна выдать сообщение. Код триггера будет иметь вид:
CREATE TRIGGER CHECK_OSTATOK
ON ORDERS_TBL
for
INSERT
AS
declare @ost int, @ost1 int
select
/*OSTATOK =
= PRODUCTS_TBL.QTY_VSEGO - ORDERS_TBL.QTY*/
@ost= ORDERS_TBL.QTY,
@ost1= PRODUCTS_TBL. OSTATOK
from ORDERS_TBL, PRODUCTS_TBL
where PRODUCTS_TBL.PROD_ID= ORDERS_TBL. PROD_ID
if @ost>@ost1
BEGIN
rollback tran
raiserror ('недостаточно товара на складе',16,3)
END
6.2 Задание на лабораторную работу
Прежде, чем приступить к выполнению задания, следует ознакомиться с соответствующими разделами виртуальной обучающей системы SQL_Education.
Все задания выполняются командами Transact-SQL (не используйте графический интерфейс).
6.2.1 Внесите следующие изменения в структуру базы данных TradeCompany:
- добавьте в таблицу PRODUCTS_TBL поле QTY_VSEGO;
- добавьте в таблицу PRODUCTS_TBL поле OSTATOK;
- добавьте в таблицу ORDERS_TBL поле SUMMA_К_OPLATE;
- добавьте в таблицу CUSTOMER_TBL поле CITY;
- добавьте в таблицу ORDERS_TBL поле OPLATA (логическое поле, в котором отмечается, проведена ли клиентом оплата за покупку).
6.2.2 Используя команду UPDATE, заполните следующие поля:
PRODUCTS_TBL.QTY_VSEGO,
CUSTOMER_TBL.CITY,
ORDERS_TBL.OPLATA
данными (в последнем поле для некоторых клиентов установите значение NO).
В поле QTY_VSEGO таблицы PRODUCTS_TBL хранятся данные о количестве товара на складе, в поле QTY в таблице ORDERS_TBL – количество проданного товара, в поле OSTATOK – разница между значениями двух предыдущих полей.
6.2.3 Используя механизм сохраненных процедур, внесите следующие изменения в базу данных:
- в поле PRODUCTS_TBL.OSTATOK – количество товара, оставшегося на складе (PRODUCTS_TBL. QTY_VSEGO - ORDERS_TBL.QTY);
- в поле ORDERS_TBL.SUMMA_К_OPLATE - сумму, уплаченную за приобретенный товар; она рассчитывается как произведение цены товара (таблица PRODUCTS_TBL) на количество (таблица ORDERS_TBL).
6.2.4 Создайте триггер, приведенный в п.6.1, проверьте его работу, вводя в таблицу ORDERS_TBL записи о продажах, количество товара в которых заведомо превышает остаток этого товара на складе.
6.2.5 Создайте триггеры, позволяющие контролировать следующие ситуации:
- не обслуживать клиента из определенного города;
- обслуживать клиентов только из определенного города;
- не удалять запись о продажах, если товар не оплачен;
- не закупать товары, цена которых превышает определенную сумму.
6.3 Требования к отчету
Отчет по работе выполняется на бумажном носителе и должен содержать:
- листинги текстов триггеров;
- листинг результата работы созданных триггеров.
6.4 Контрольные вопросы
6.4.1 В чем преимущества использования процедур? 6.4.2 Когда выполняются триггеры – до или после выполнения команд INSERT, UPDATE и DELETE? 6.4.3 Можно ли изменить триггер?
6.4.4 Как можно ввести текст триггера в MS SQL 2005?
6.4.5 Как проверяется работа триггера?
Лабораторная работа № 7. Разработка интерфейса пользователя
Цель работы: освоение процедуры создания клиентского приложения к базе данных средствами Borland C++Builder.
7.1 Организация доступа к данным средствами технологии ADO
Цель клиентского приложения – дать возможность пользователю работать с данными в удобной для него форме. Существуют различные механизмы доступа к данным. Одной из технологий, разработанной корпорацией Microsoft, является технология ADO – (Active Data Objects). Данная технология ориентирована в первую очередь на создание клиент-серверных приложений, предполагающих постоянное взаимодействие клиента с сервером баз данных.
Технология ADO включает набор высокоуровневых интерфейсов OLE DB, которые входят в состав любой операционной системы Windows. Интерфейс OLE DB (Object Linking and Embedding Database – связывание и внедрение объектов баз данных) – это универсальная технология для доступа к источникам данных любого типа с использованием специализированных объектов COM (Component Object Model – модель компонентных объектов), в которых инкапсулированы стандартные функции обработки данных и передачи данных между объектами.
В лабораторной работе разрабатывается интерфейс к рассматриваемой базе данных TradeCompany.
Для облегчения задачи создайте упрощенный вариант структуры таблицы ORDERS_TBL: в этой таблице поле ORD_NUM будет являться первичным ключом (поле ORDERS_ID удаляется из таблицы). Заполните таблицу данными, поле TOTAL_COST не заполняйте.
С помощью этого интерфейса можно выполнять следующие задачи:
- просмотр данных в блицах базы данных;
- выполнение различных запросов к базе данных;
- формирование отчетов.
Примечание: описание работы не содержит иллюстраций, так как методические указания снабжены диском, на котором приведен exe-файл разрабатываемого в работе приложения. Результат разработки можно просматривать в процессе выполнения задания. Этот файл размещается на серверах компьютерных классов, где проводятся лабораторные занятия.
7.2 Настройка соединения ADO
Чтобы обеспечить сеанс связи приложения с базой данных, необходимо установить соединение между ними и настроить его параметры. Для этих целей предназначен компонент ADOConnection:
- в приложении Borland Builder C++ поместите на форму компонент ADO Connection со страницы ADO палитры компонентов. Параметры соединения указываются в свойстве ConnectionString;
- в окне инспектора объектов в свойствах ADO Connection выберите Connection String. В появившемся окне шелкните на кнопке Build; в окне «Свойства связи с данными» на вкладке «Поставщик данных» выбрать SQL Native Client;
- на вкладке «Подключение»: в пункте «Для входа в сервер» выбрать Учетные сведения Windows NT; в следующем пункте выбрать начальный каталог из раскрывающегося списка. Обязательно проверить подключение;
- в окне Инспектора объектов - значение свойства Login Promt установить false, чтобы при каждом обращении к базе не происходил вызов окна ввода пароля.
7.3 Доступ к данным базы данных
Каждое приложение, использующее базу данных, обычно имеет, по крайней мере, по одному компоненту следующих трех типов:
- наборы данных (DataSet), непосредственно связывающиеся с базой данных; в лабораторной работе это такие компоненты, как Table, Query, StoredProc;
- источник данных (DataSource), осуществляющий обмен информацией между компонентами Dataset и компонентами визуализации и управления данными;
- компоненты визуализации и управления данными, такие, как DBGrid, DBEdit, DBText (см. рисунок 7.1).
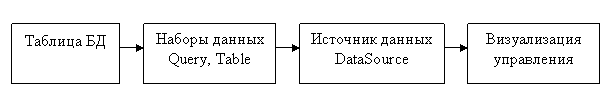 Рисунок 7.1 - Связь компонентов между собой и с
базой данных
Рисунок 7.1 - Связь компонентов между собой и с
базой данных
Свойство DataSet компонента DataSource идентифицирует имя компонента TDataSet. Значение свойству DataSet на этапе проектирования можно присвоить с помощью инспектора объектов, а на этапе выполнения – программно.
Для отображения данных базы данных можно использовать два варианта: АDO Table и ADOQuery.
Рассмотрим применение этих компонентов:
а) для локальных баз данных обычно используется компонент Table (ADOTable), представленный классом TTable. Он обеспечивает самый быстрый и простой доступ к таблице:
- на форму, описанную в п. 7.2, поместите компоненты ADOTable1, DataSource1;
- установите свойства компонентов (свойства устанавливаются в Инспекторе объектов):
|
Компонент |
Свойство |
Значение |
|
DataSource1 |
DataSet |
ADOTable1 |
|
ADOTable1 |
Connection |
ADOConnection1 |
|
ADOTable1 |
TableName |
Имя таблицы |
- поместите на форму компоненты DBGrid1 и DBNavigator1; установите свойства компонентов:
|
Компонент |
Свойство |
Значение |
|
DBGrid1 |
DataSource |
DataSource1 |
|
DBNavigator1 |
DataSource |
DataSource1 |
|
DBNavigator1 |
ShowHint |
True |
- для компонента ADOTable1 значение свойства Active установие true;
- предусмотрите возможность выхода из приложения;
- запустите приложение; просмотрите результат;
- измените внешний вид таблицы (например, надписи в заголовках столбцов) с помощью редактора свойств Columns Editor. Для вызова Columns Editor нужно либо выбрать соответствующую опцию в контекстном меню компонента DBGrid или щелкнуть мышью в колонке значений напротив свойства Columns в Инспекторе объектов. Щелкнув правой кнопкой мыши и выбрав строку Add All Fields, откроем свойство Title и для каждого поля в свойстве Caption можно записать русские названия полей.
С помощью навигатора можно передвигаться по записям набора данных. Если на некоторое время задержать указатель мыши на одной из кнопок навигатора, то появляется всплывающая подсказка к этой кнопке (значение свойства ShowHint – True);
б) в подавляющем большинстве случаев оправданно использование объектов TQuery (ADOQuery), чем применение наборов данных TTable. Связано это с большой гибкостью и эффективностью языка запросов SQL, полагаемых в основу TQuery. Преимущества использования компонента TQuery связаны с такими факторами, как:
- возможность объединить несколько таблиц связями, не предусмотрен-ными при проектировании базы данных;
- возможность в одном наборе данных сочетать информацию из разных таблиц одной базы данных;
- возможность легко задать фильтры любого уровня сложности, порядок сортировки записей, набор полей, которые должны попасть в итоговую выборку, и т.д.;
- возможность использовать параметры.
Использование ADOQuery: удалите компонент ADOTable1 с формы и поместите вместо него ADOQuery1; для этого компонента установить дополнительные свойства:
|
Компонент |
Свойство |
Значение |
|
ADOQuery1 |
Connection |
ADOConnection1 |
|
ADOQuery1 |
SQL |
select * from PRODUCTS_TBL |
|
ADOQuery1 |
Active |
true |
Основное свойство компонента Query — SQL, имеющее тип TStrings. Это список строк, содержащих запросы SQL. Здесь значение свойства SQL приведено в качестве примера.
Последнее свойство компонента можно установить программно:
//Подключение к базе данных
{ADOquery1->Open();
//К активной базе данных нельзя подключиться
ADOquery1->Enabled=False
}
Во время выполнения приложения свойство SQL может формироваться программно методами, обычными для класса TStrings: Clear() - очистка, Add ()- добавление строки, Open() - активизация запроса и т.д.
Здесь используется один и тот же компонент Query, который можно применить для разных запросов: текст запроса вписывается в текст кода (предварительно идет очистка от старого запроса, затем текущий запрос активируется). В результате выполнения запроса компонент DBGrid представил таблицу PRODUCTS_TBL в табличном виде.
Поместите кнопку Button1 на форму: при нажатии на эту кнопку выполняется запрос свойства SQL; код обработчика события будет иметь следующий вид:
void __fastcall TForm1::Button1Click(TObject *Sender)
{
//Очищаем от старого запроса
ADOQuery1->SQL->Clear();
//Запрос
ADOQuery1->SQL->Add("select * from PRODUCTS_TBL ");
//Активизирует компонент
ADOQuery1->Open(); }
7.4 Выполнение поиска по некоторому параметру
7.4.1 Использование фильтра
Под поиском понимается отображение данных, которые удовлетворяют некоторым условиям. Поиск можно реализовать с помощью компонентов TADOTable, TADOQuery.
Для выполнения поиска в компоненте TADOTable есть свойство Filter. В нем можно указывать условие, по которому будут отображаться данные.Чтобы фильтр заработал, нужно установить значения свойств TADOTable:
|
Компонент |
Свойство |
Значение |
|
ADOTable |
Filter |
текст условия в виде: Поле [оператор сравнения] ’значение’ |
|
ADOTable |
Filtered |
true |
Например, текст условия может быть следующим:
PROD_DECS =’ватман’;
Для возможности изменения фильтра можно использовать строку ввода TЕdit: поместите на форму дополнительно компонент – поле TЕdit1, в которое будет вводиться название товара, и кнопку - «Фильтрация по названию товара». В этом случае поиск задается программно и будет иметь вид:
void __fastcall TForm2::Button1Click(TObject *Sender)
{
ADOTable1->Filtered=False;
ADOTable1->Filter="PROD_DECS='"+Edit1->Text+"'";
ADOTable1->Active=True;
ADOTable1->Filtered=True;
}
Значение нужно указывать в одинарных кавычках (апострофы), а строка ввода заключается в кавычки, поэтому условие имеет вид '"+Edit1->Text+"'. Это конструкция будет использоваться и дальше.
7.4.2 Использование языка запросов SQL для поиска
Использование фильтра имеет недостаток – медленная скорость обработки фильтров. Для работы фильтра программе нужно получить все данные, а потом уже на стороне клиента произвести проверку. Таким образом, по сети идет слишком большое количество данных, и на клиента получается лишняя нагрузка. С большими базами желательно использовать SQL-запросы.
При использовании SQL-запроса клиент направит серверу текстовый запрос с условиями, сервер проверит его и вернет только необходимые данные. Если просто вписать запрос в свойство SQL компонента ADOQuery и его не изменять в течение всей программы, то такой запрос будет статическим. Если же в течение выполнения программы надо изменять текст запроса, то это динамический запрос. В этом случае удобнее в запрос ввести переменную и изменять ее, а запросы задавать на этапе программирования.
Пусть необходимо по названию товара получить всю информацию о нем.
Откройте новую форму. Поместите на нее компоненты: Label1 – с текстом подписи, Edit1 - для ввода названия товара; Label2, Label3 – для вывода количества записей со следующими свойствами:
|
Компонент |
Свойство |
Значение |
|
Label1 |
Caption |
Введите название товара |
|
Label2 |
Caption |
Видов данного товара |
Код для поиска указанного товара имеет вид:
void __fastcall TForm2::Button1Click(TObject *Sender)
{
ADOQuery1->SQL->Clear();
ADOQuery1->SQL->Add("select PROD_DECS, COST from PRODUCTS_TBL where PROD_DECS='"+Edit1->Text+"'");
ADOQuery1->Open();
Label3->Caption=IntToStr(ADOQuery1->RecordCount);
}
Примечание: в приведенном коде предполагается, что текст запроса записывается на одной строке; если текст запроса размещается на нескольких строках, то его вид будет следующим:
ADOQuery1->SQL->
Add ("select PROD_DECS, COST from PRODUCTS_TBL");
ADOQuery1->SQL->Add("where PROD_DECS='"+Edit1->Text+"'");
Компоненты TADOTable и TADOQuery имеют свойство RecordCount – количество строк в таблице
Усложним задачу поиска - необходимо вывести данные по указанному товару, проданному на указанную дату: название товара, цену товара, указанное в счете количество, дату.
Поместите на форму компоненты Edit1 – для ввода названия товара, по которому производится поиск, Edit2 – для ввода даты покупки. При использовании языка запросов SQL код обработчика будет иметь следующий вид:
void __fastcall TForm1::Button1Click(TObject *Sender)
{
ADOQuery1->SQL->Clear();
ADOQuery1->SQL->Add("Select PRODUCTS_TBL.PROD_DECS,");
ADOQuery1->SQL->
Add("PRODUCTS_TBL.COST, ORDERS_TBL.QTY,");
ADOQuery1->SQL->Add("ORDERS_TBL.ORD_DATE,");
ADOQuery1->SQL->Add(" from PRODUCTS_TBL,ORDERS_TBL");
ADOQuery1->SQL->Add("where PRODUCTS_TBL.PROD_DECS=");
ADOQuery1->SQL->Add("'"+Edit1->Text+"' and");
ADOQuery1->SQL->
Add("ORDERS_TBL.ORD_DATE='"+Edit2->Text+"' and");
ADOQuery1->SQL->
Add("ORDERS_TBL.PROD_ID=PRODUCTS_TBL.PROD_ID");
ADOQuery1->Open();
}
Если в запросе используется оператор select, то используется метод Open().
Если в запросе удаляются строки или изменяется структура столбца (в запросе есть такие операторы, как INSERT, UPDATE, DELETE или/и CREATE TABLE), необходимо вызвать метод ExecSQL компонента ADOQuery. То есть, если запрос возвращает данные, то достаточно активировать компонент - Open(), а если изменяет, то запрос нужно выполнить с помощью ExecSQL. Например, чтобы заменить данные, удалить строку в таблице, вставить новую запись, можно записать следующие коды обработчика:
void __fastcall TForm1::Button1Click(TObject *Sender)
{
ADOQuery1->SQL->Clear();
ADOQuery1->SQL->Add("Update PRODUCTS_TBL set PROD_DECS='ручка1' where PROD_DECS='ручка'");
ADOQuery1->ExecSQL();
}
//---------------------------------------------------------------------------
void __fastcall TForm1::Button2Click(TObject *Sender)
{
ADOQuery1->SQL->Clear();
ADOQuery1->SQL->Text="Delete PRODUCTS_TBL where PROD_ID='"+Edit1->Text+"'";
ADOQuery1->ExecSQL();
}
//---------------------------------------------------------------------------
void __fastcall TForm1::Button3Click(TObject *Sender)
{
ADOQuery1->SQL->Clear();
ADOQuery1->SQL->Text="Insert into PRODUCTS_TBL
values( 24,'коврик для мыши',3000)";
ADOQuery1->ExecSQL();
}
7.5.Заполнение таблиц
Рассмотрим задачу создания формы для ввода и редактирования записей таблицы. Вначале рассмотрим заполнение таблицы PRODUCTS_TBL. Откройте новую форму, поместите на нее компонент доступа к данным – TDBEdit1, TDBEdit2, TDBEdit, ADO Table1, DataSource1, DBNavigator1. Свойства компонентов приведены ниже в таблице 7.1.
Таблица 7.1 - Свойства компонентов
|
Компонент |
Свойство |
Значение |
|
TDBEdit |
DataSource |
DataSource1 |
|
TDBEdit |
DataField |
Выбор соответствующего поля |
|
DataSource |
DataSet |
ADO Table1 |
|
ADO Table1 |
Connection |
ADO Connection1 |
|
ADO Table1 |
TableName |
Выбор из списка |
|
ADO Table1 |
Active |
True |
|
DBNavigator1 |
DataSource |
DataSource1 |
Эти компоненты автоматически редактируют указанные поля в базе данных.
Запустите приложение. На навигаторе щелкните на кнопке Insert record. Введите данные в DBEdit, щелкните на кнопке Post edit. Данные будут введены в таблицу PRODUCTS_TBL.
Рассмотрим более сложную задачу - ввод данных в таблицу ORDERS_TBL.
Создадим новую форму для заполнения полей: ORD_NUM, CUST_ID, PROD_ID, ORD_DATE, QTY (соответственно номер счета, код клиента, код товара, дата счета и количество товара) и вычисляемого поля TOTAL_COST. Для заполнения используются компоненты DBEdit (вкладка DataControl).
При работе с формой при нажатии на кнопках (которые будут размещены на форме) «Описание товара», «Цена товара», «Стоимость товара» на форме появляются значения соответствующих полей на компоненте DBText. Эти значения определяются в зависимости от введенного кода товара в таблицу ORDERS_TBL. В связи с этим необходимо формировать запрос (по введенному коду товара) для определения цены и описания товара.
Итак, поместим на форму необходимые компоненты, список которых с их свойствами приведен ниже в таблице 7.2.
Таблица 7.2 - Свойства компонентов
|
Компонент |
Свойство |
Значение |
|
TDBEdit |
DataSource |
DataSource1 |
|
TDBEdit |
DataField |
Выбор соответствующего поля |
|
DataSource1 |
DataSet |
ADO Table1 |
|
DataSource2 |
DataSet |
ADO Query1 |
|
DataSource3 |
DataSet |
ADO Query2 |
|
ADO Table1 |
Connection |
ADO Connection1 |
|
ADO Table1 |
TableName |
Выбор из списка |
|
ADO Table1 |
Active |
True |
|
DBNavigator1 |
DataSource |
DataSource1 |
|
ADO Query1 |
Connection |
ADO Connection1 |
|
ADO Query2 |
Connection |
ADO Connection1 |
|
DBText1 |
DataSource |
DataSource2 |
|
DBText2 |
DataSource |
DataSource3 |
Компоненты DBText1, DBText2 связываются с полем PROD_DECS и COST программно, например: DBText1->DataField="PROD_DECS";.
Ниже приводятся фрагменты кодов для различных ситуаций:
- определение названия товара
void __fastcall TForm1::Button1Click(TObject *Sender)
{
AnsiString t;
ADOQuery1->SQL->Clear();
t=DBEdit3->Text;
ADOQuery1->SQL->Add("select PROD_DECS from PRODUCTS_TBL where
PROD_ID='"+t+"'");
DBText1->DataField="PROD_DECS";
ADOQuery1->Open();
}
- определение цены товара
//---------------------------------------------------------------------------
void __fastcall TForm1::Button2Click(TObject *Sender)
{AnsiString t;
ADOQuery2->SQL->Clear();
t=DBEdit3->Text;
ADOQuery2->SQL->
Add("select COST from PRODUCTS_TBL where PROD_ID='"+t+"'");
DBText2->DataField="COST";
ADOQuery2->Open();
}
- вычисление стоимости товара и заполнение поля TOTAL_COST
//---------------------------------------------------------------------------
void __fastcall TForm1::Button3Click(TObject *Sender)
{
DBText3->Caption=
IntToStr(StrToInt(DBText2->Caption)*StrToInt(DBEdit5->Text));
DBEdit6->Text= DBText3->Caption;
//DBEdit6->Text=
IntToStr(StrToInt(DBText2->Caption)*StrToInt(DBEdit5->Text));
}
В некоторых случаях приложению требуется получить список имен полей таблицы, связанной с ADOQuery. Это может быть сделано методом GetFieldNames, который загружает список имен полей в любую переменную типа TStrings, передаваемую в него в качестве аргумента. Например, оператор
ADOQuery1->GetFieldNames(ComboBox1l->Items);
загружает в выпадающий список ComboBox1 имена полей таблицы, связанной с ADOQuery1.
7.6 Использование модуля данных
При разработке приложений с большим количеством таблиц или использующих большое количество запросов, интерфейс форм может быть переполнен невизуальными компонентами, соответствующими наборам и источникам данных. Borland С++ Builder (а также и Delphi) позволяют создать специальное окно Data Module (модуль данных), которое удобно для хранения компонентов доступа к базам данных.
Модуль данных – это специальный тип формы, который во время выполнения программы остается невидимым. Модуль данных позволяет централизованно управлять моделью взаимодействия компонентов, ориентированных на работу с базами данных.
Чтобы добавить модуль данных в проект, следует выполнить следующие команды: File| New| Data Module. Далее на форме расположить невизуальные компоненты, для работы с базой данных: ADOConnection, DataSource, ADOTable, ADOQuery.
Для того чтобы форма имела связь с модулем данных, необходимо в соответствующий заголовочный файл формы включить директиву
#include “Unit.h”.
Обратиться к объекту, расположенному в модуле данных, можно только по составному имени <название модуля данных>-><название объекта>. Например, следующим образом:
DataModule1->ADOTable1->Open();
DataModule1->ADOQuery->SQL-> Text="Delete tovar
where PROD_ID='"+Edit1->Text+"'";
DataModule1->ADOQuery1->ExecSQL();
7.7 Создание отчетности
При работе с базами данных всегда возникает потребность в формировании на их основе документов с целью последующей печати. В лабораторной работе рассматривается генератор отчетов Quick Reports, который входит в поставку Borland Builder C++.
В Borland Builder C++ отчеты QuickReport не устанавливаются, но это можно сделать самостоятельно. Для этого надо выбрать меню Project | Options и на вкладке Packages нажать кнопку Add. Найти файл dcltqr60. bpl, который должен находиться в папке Bin, где установлен Builder, и открыть его.
Все компоненты Quick Reports находятся на вкладке QReport палитры компонентов. Головной компонент TQuickRep. Этот компонент - основа любого отчета. Он представляет собой холст листа будущего отчета. Свойство Bands этого компонента (полосы) содержит несколько пунктов. В этих пунктах можно указать, что должен иметь будущий документ:
- HasTitle – в этом разделе задается заголовок отчета;
- HasColumnHeader – заголовки колонок. Если отчет содержит таблицу, то шапка, где будут определены названия колонок, создают в этой части документа. Если нужна будет таблица, то этому свойству присваивается значение true;
- HasDetail – если в отчете есть таблицы, то вид строк формируется в этом разделе.
- HasPageFooter – в этом разделе создается нижний колонтитул;
- DataSet – здесь указывается таблица, из которой отчет будет брать данные.
На вкладке QReport палитры компонентов доступен ряд компонентов, которые можно располагать в этих разделах: QRLabel - надпись (этот компонент просто отражает нужные данные); QRDBText – данные (предназначен только для отображения значения какого-либо поля из базы данных; QRSysData – системная информация (аналогичен TLabel, только отображает системную информацию: дату, время, номер страницы и т.д.); QRMemo – набор строк (аналогичен TMemo, отображает Memo-данные из базы данных).
Для предварительного просмотра созданного отчета используется метод QuickRep1->Preview().
Рассмотрим формирование отчетов:
а) выведем на печать список товаров. В отчете должны быть дата, время печати, название документа – «Список товаров».
Поместим на форму компоненты DataSource1, ADOTable1, QuickRep1. Настроим компоненты DataSource, ADOTable.
У компонента QuickRep1 для свойства DataSet установим значение ADOTable1. Откроем пункты свойства Bands. В свойстве HasTitle установить значение true. В появившуюся строку поместить компонент QRLabel со страницы QReport и в свойстве Caption ввести «Список товаров», также поместить компонент QRSysData1 для отображения текущей даты и времени. В свойстве HasColumnHeader установить значение true. Это означает, что в отчете будут отображаться названия полей таблицы. Вставить в появившуюся строку для полей три компонента QRLabel. В заголовках написать: Код товара, Описание товара, Цена товара.
В свойстве HasDetail установить значение true. Вставить в появившуюся строку три компонента QRDBText со следующими свойствами:
|
Компонент |
Свойство |
Значение |
|
QRDBText |
DataSet |
ADOTable1 |
|
QRDBText |
DataField |
указать соответствующие поля |
|
QRSysData1 |
Data |
qrsDateTime |
Поместить на форму кнопку. При щелчке на этой кнопке должно открыться окно предварительного просмотра. Все настройки проводятся в инспекторе объектов. Следующий обработчик события выводит список товаров из таблицы PRODUCTS_TBL:
/---------------------------------------------------------------------------
void __fastcall TForm1::Button1Click(TObject *Sender)
{
QuickRep1->Preview();
}
б) создадим отчет по запросу, рассмотренному ранее: вывести данные по указанному названию товара, проданного на указанную дату. В отчете должны быть выведены следующие данные: название товара, цена товара, количество товара, стоимость товара, дата счета. Заголовок отчета имеет следующий текст:
- данные по наименованию [название товара], купленному [дата счета].
Используем форму по поиску товара, купленного на определенную дату. Поместим компонент QuickRep, со значением ADOQuery1 свойства DateSet. Настроить пункты свойства Bands:
- поместите компоненты QRLabel в строку заголовка отчета; учесть, что название товара и дата – изменяемые параметры, которые определяются в Edit1 и Edit2;
- в строке HasColumnHeader отобразите названия полей;
- в строке HasDetail поместите компоненты QRDBText; свойство DateSet имеет значение ADOQuery1. .
В этом случае значение свойства DataField определяется программно:
QRDBText1->DataField="+имя поля+";
Обработчик события для создания отчета для указанного запроса имеет вид:
void __fastcall TForm1::Button1Click(TObject *Sender)
{
QRLabel2->Caption=Edit1->Text;
QRLabel4->Caption=Edit2->Text;
ADOQuery1->SQL->Clear();
ADOQuery1->SQL->Text="Select PRODUCTS_TBL.PROD_DECS,
PRODUCTS_TBL.COST, ORDERS_TBL.QTY,
ORDERS_TBL.ORD_DATE, ORDERS_TBL.TOTAL_COST
from PRODUCTS_TBL,ORDERS_TBL where
PRODUCTS_TBL.PROD_DECS='"+Edit1->Text+"' and
ORDERS_TBL.ORD_DATE='"+Edit2->Text+"' and
ORDERS_TBL.PROD_ID=PRODUCTS_TBL.PROD_ID";
ADOQuery1->Open();
QRDBText1->DataField="COST";
QRDBText2->DataField="QTY";
QRDBText3->DataField="TOTAL_COST";
QuickRep1->Preview();
}
7.8 Задание на лабораторную работу
Прежде, чем приступить к выполнению задания, следует ознакомиться с соответствующими разделами виртуальной обучающей системы SQL_Education.
Разработайте для своей базы данных клиентское приложение, используя один из механизмов доступа.
7.9 Требования к отчету
Отчет по работе должен содержать:
- разработанное приложение:
- листинги модулей с комментариями.
Выполнить демонстрацию работы разработанного приложения.
7.10 Контрольные вопросы
7.10.1 На что ориентирована технология ADO?
7.10.2 Назвать компонент для обеспечения связи между приложением и базой данных.
7.10.3 Назвать компоненты для отображения данных.
7.10.4 Объяснить предназначение свойства и методы компонентов Datasource, ADOTable, ADOQuery.
7.10.5 Указать свойства компонента ADOTable, которые используются при фильтрации данных.
7.10.6 На что указывает свойство RecordCount и свойством каких компонентов оно может быть?
7.10.7 В каких случаях используются методы ExecSQL(), Open()?
7.10.8 Указать, с помощью какого метода можно получить список имен полей таблицы, связанной с ADOQuery.
7.10.9 Объяснить использование модуля данных.
7.10.10 Как обратиться к объекту, расположенному в модуле данных?
7.10.11 Перечислить основные пункты и объяснить назначение компонента Bands.
7.10.12 На что указывает компонент QRSysData?
7.10.13 Указать метод, используемый для предварительного просмотра созданного отчета.
8 Лабораторная работа № 8. Шифрование данных в SQL Server 2005
Цель: получить практические навыки по обеспечению безопасности информации в реляционной базе данных.
8.1 Общие сведения
При разработке баз данных обеспечение безопасности хранимой информации является обязательным этапом. Комплексные средства защиты заключаются в объединении средств скриптов безопасности (триггеры и представления) со средствами разделения пользователей. Благодаря гибкой настройке разделения прав пользователей, создаются разнородные пользователи с разными уровнями доступа к данным. Создание ролей очень облегчает процедуру разделения полномочий. Роли позволяют создавать некое условное хранилище объектов и разрешений к ним. Каждый пользователь в базе данных – это определенный уровень в системе защиты сервера базы данных. Благодаря широким возможностям настройки объектов пользователей и ролей для них, временные затраты на создание системы безопасности являются весьма небольшими.
В сравнении с предыдущими версиями, MS SQL Server 2005 обеспечивает защиту данных не только внутри своих серверов, но и во вне. Это достигается системой шифрования, которая позволяет защищать данные, передаваемые по незащищенному каналу. Алгоритмы шифрования разнятся от самых простых, с применением простого шифрования паролем, до многоступенчатых и комплексных, где даже сами ключи для шифрования на каждом шаге генерируются отдельно (алгоритмы DES, TRIPPLE DES, RSA). В случае физического проникновения злоумышленника, то есть в случае такой ситуации, когда рубежи защиты разделением пользователей пали, в сервере MS SQL Server вся зашифрованная информация будет для него нечитаемой.
Для шифрования данных в SQL Server 2005 предусмотрено четыре способа:
- шифрование при помощи сертификатов. Сертификат при этом должен присутствовать в виде объекта в базе данных (в SQL Server Management Studio можно просмотреть имеющиеся сертификаты в контейнере Databases/ Имя_базы_данных/Security/Certificates);
- шифрование при помощи асимметричных ключей. Алгоритм здесь такой же, как и при использовании сертификатов. От сертификата асимметричный ключ отличается тем, что в нем не предусмотрено дополнительных полей с информацией о том, кому он выдан, для каких целей, до какого времени действителен и т. п. Имеющиеся асимметричные ключи можно просмотреть в контейнере Asymmetric Keys, который находится там же, где и контейнер Certificates;
- шифрование при помощи симметричных ключей. Используются намного более быстрые алгоритмы, по сравнению с асимметричными ключами. Сами симметричные ключи также создаются в виде объектов базы данных и могут быть защищены сертификатом, другим симметричным ключом, ассиметричным ключом или просто паролем. Просмотреть их можно при помощи контейнера Symmetric Keys;
- простое шифрование при помощи паролей.
Возможности шифрования продемонстрируем на примере шифрования данных таблицы Num_cards базы данных Education (рассмотренной в обучающей программе к методическим указаниям), в которой будут храниться ID студента и номер его платежной карточки (для выдачи стипендии). Шифрование будет произведено для номера карточки.
8.2 Процедуры шифрования данных в MS SQL Server 2005
8.2.1 Шифрование с помощью сертификатов для защиты ключей
Создание сертификата выполняется при помощи команды CREATE CERTIFICATE. Самый простой вариант этой команды выглядит так:
CREATE CERTIFICATE Cert1
ENCRYPTION BY PASSWORD = '11'
WITH SUBJECT = 'Проверка шифрования',
START_DATE = '02/06/2009'
Обратим внимание, что для создания сертификата нам не требуется никакой центр сертификации — все необходимые средства уже встроены в SQL Server.
Параметр ENCRYPTION BY PASSWORD определяет пароль, который потребуется для расшифровки данных, защищенных сертификатом (для шифрования данных он не нужен). Если этот параметр пропустить, то создаваемый сертификат будет автоматически защищен главным ключом базы данных (Database Master Key). Автоматически этот ключ не создается. Чтобы получить возможность работать с ним, нужно предварительно его создать:
CREATE MASTER KEY ENCRYPTION BY
PASSWORD = 'P@ssw0rd';
Кроме пароля, главный ключ базы данных автоматически защищается также главным ключом службы (Service Master Key). Этот ключ автоматически генерируется SQL Server 2005 в процессе установки. Надо быть очень внимательным при использовании главного ключа базы данных: если мы переустановим сервер (а, следовательно, изменится главный ключ службы), зашифрованные данные могут быть потеряны. Чтобы этого не случилось, нужно производить регулярное копирование базы данных master или экспортировать главный ключ службы в файл при помощи команды BACKUP SERVICE MASTER KEY.
Обязательный параметр SUBJECT команды CREATE CERTIFICATE определяет цель выдачи сертификата.
После того, как сертификат создан, его можно использовать для шифрования данных. Для этой цели применяется специальная функция EncryptByCert:
insert into Num_cards
values(1, EncryptByCert(Cert_ID('Cert1'), N'111001') )
insert into Num_cards
values(2, EncryptByCert(Cert_ID('Cert1'), N'111002') )
insert into Num_cards
values(3, EncryptByCert(Cert_ID('Cert1'), N'111003') )
Для расшифрования используется команда DecryptByCert. Чтобы расшифровать данные, нужно использовать обыкновенный запрос SELECT:
select convert(nvarchar(50),
DecryptByCert(Cert_ID('Cert1'),Cred_ID, N'11') )
from Num_cards
8.2.2 Шифрование ассиметричным ключом
Вначале нужно создать ассиметричный ключ.
CREATE ASYMMETRIC KEY ASymKey1
WITH ALGORITHM = RSA_512
ENCRYPTION BY PASSWORD = '11'
Обратите внимание, что, кроме пароля, здесь требуется указать длину создаваемого ключа. В нашем распоряжении три варианта: 512, 1024 и 2048 бит.
После этого при помощи созданного ключа можно производить шифрование данных:
insert into Num_cards
values
(1, EncryptByAsymKey(AsymKey_ID('ASymKey1'), N'111001'))
insert into Num_cards
values
(2, EncryptByAsymKey(AsymKey_ID('ASymKey1'), N'111002'))
insert into Num_cards
values
(3, EncryptByAsymKey(AsymKey_ID('ASymKey1'), N'111003'))
Мы вносим в таблицу 3 записи с одним и тем же ассиметричным ключом ASymKey1. В результате данные в таблице будут представлены в виде нечитаемого набора символов.
Для расшифрования воспользуемся функцией DecryptByAsymKey
SELECT Convert(nvarchar(50), DecryptByAsymKey(AsymKey_ID('ASymKey1'),Cred_ID, N'11'))
FROM Num_cards
8.2.3 Шифрование симметричным ключом
При использовании симметричных ключей шифрование производится быстрее, чем при применении асимметричных алгоритмов, поэтому при работе с большими объемами данных рекомендуется использовать именно их. Применение симметричных ключей выглядит очень похоже. Правда, есть и небольшие отличия. Во-первых, при создании симметричного ключа его можно защищать не только паролем, но и другим симметричным ключом, асимметричным ключом или сертификатом. Во-вторых, при создании симметричного ключа вы можете указать один из восьми алгоритмов шифрования, поддерживаемых SQL Server 2005 (DES, TRIPLE_DES, RC2, RC4, DESX, AES_128, AES_192, AES_256). Само создание симметричного ключа может выглядеть так:
CREATE SYMMETRIC KEY SymKey1
WITH ALGORITHM = DES
ENCRYPTION BY PASSWORD = '11'
Перед использованием ключа (для шифрования или расшифровки данных) его нужно обязательно открыть. Это достаточно сделать только один раз в течение сеанса работы пользователя:
OPEN SYMMETRIC KEY SymKey1 DECRYPTION BY
PASSWORD = '11'
Используем созданный ключ для шифрования данных:
insert into Num_cards
values(1, EncryptByKey(Key_GUID('SymKey1'), convert(nvarchar(50),'111001') ))
insert into Num_cards
values(2, EncryptByKey(Key_GUID('SymKey1'), convert(nvarchar(50),'111002') ))
insert into Num_cards
values(3, EncryptByKey(Key_GUID('SymKey1'),
convert(nvarchar(50),'111003') ))
Обратите внимание, что при расшифровке данных нет необходимости передавать функции DecryptByKey имя симметричного ключа и пароль. Будут автоматически подставляться данные открытого ключа при помощи команды open. Для расшифровки сообщения нужно запустить следующий скрипт:
select convert(nvarchar(50), DecryptByKey(Cred_ID))
from Num_cards
Потому как зашифрованные данные нельзя хранить в столбцах типа int, char, применяетcя команда convert.
8.2.4 Шифрование паролем
SQL Server 2005 позволяет производить шифрование данных также просто при помощи пароля. Для этого используется функция EncryptByPassPhrase.
В самом простом варианте она принимает только пароль и данные, которые необходимо зашифровать:
insert into Num_cards
values(4, EncryptByPassPhrase('Password', N'111004'))
Расшифровка производится при помощи функции DecryptByPassphrase:
select
convert(nvarchar(50), DecryptByPassPhrase('Password', Cred_Id))
from Num_cards
8.3 Задание на выполнение лабораторной работы
8.3.1 Используйте базу данных, разработанную в расчетно-графических работах. Выберите из этой базы таблицу с полями разных типов (символьные, числовые, дата/время и др.).
8.3.2 Выполните процедуры шифрования всеми четырьмя способами для различных типов полей.
8.3.3 Выясните недостатки и достоинства каждого вида шифрования для определенного типа поля.
8.4 Требования к отчету
Отчет по лабораторной работе должен содержать:
- структуру таблицы используемой базы данных;
- тексты команд шифрования различными способами и листинги
результатов доступа к зашифрованной информации;
- сравнительный анализ способов шифрования полей различного типа.
8.5 Варианты заданий
Студент использует собственную базу данных и таблицу выбранной структуры в этой базе; выполняет задание применительно к данным этой таблицы.
8.6 Контрольные вопросы
8.6.1 Для чего нужна процедура шифрования в базе данных?
8.6.2 Какие способы шифрования данных базы данных вы знаете?
8.6.3 Что такое сертификат?
8.6.4 Как отображаются данные таблицы, к которой применено
шифрование?
8.6.5 Различается ли применение шифрования от типа поля таблицы?
Список литературы
1 Джоунс Э., Стивенз Р., Плю Р., Гарретт Р., Кригель А. Функции SQL. Справочник программиста. – М.: Диалектика, 2006.
2 Дейт К.Дж. Введение в системы баз данных. — М.: Издательский дом «Вильямс», 2008.
3 Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика. — М.: Издательский дом «Вильямс», 2003.
4 Кузнецов С.Д. Основы баз данных. — 1-е изд. — М.: «Интернет-университет информационных технологий - ИНТУИТ.ру», 2005.
5 Харрингтон Дж. Разработка баз данных. – М.: ДМК Пресс, 2005.
6 Хомоненко А.Д., Цыганков В.М., Мальцев М.Г. - Базы данных. Учебник для вузов. – М.: Корона-Принт, 2004.
7 SQL Server 2005. Реализация и обслуживание. //Серия: Учебный курс Microsoft SQL. – СПб.: Питер, Русская редакция, 2007.
8 Хансен Г., Хансен Д. Базы данных: разработка и управление. – М.: ЗАО «Издательство БИНОМ», 1999.
9 Плю Р., Стефенс Р., Райан К. Освой самостоятельно SQL за 24 часа. – М.: Издательский дом «Вильямс», 2000.
10 Кандзюба С.П., Громов В.Н. Delphi 6/7. Базы данных и приложения. – СПб: ООО «ДиаСофтЮП», 2002.
11 Григорьев Ю. А., Ревунов Г. И. Банки данных. – М.: Изд. МГТУ им. Н. Э. Баумана, 2002.
12 Харрингтон Д. Проектирование реляционных баз данных просто и доступно. – М.: Изд. «Лори», 2000.
Содержание
Введение.......................................................................................................... 3
1 Лабораторная работа № 1. Создание базы данных и определение
ее структуры..................................................................................................... 5
2 Лабораторная работа № 2. Язык манипуляции данными................... 15
3 Лабораторная работа № 3. Отбор данных (DQL) .............................. 19
4 Лабораторная работа № 4. Использование агрегатных функций и
специальных операторов в условиях отбора.................................................. 24
5 Лабораторная работа № 5. Создание и использование
представлений и хранимых процедур............................................................. 27
6 Лабораторная работа № 6. Использование триггеров........................ 29
7 Лабораторная работа № 7. Разработка интерфейса пользователя..... 32
8 Лабораторная работа № 8. Шифрование данных в
MS SQL Server 2005......................................................................................... 45
Список литературы................................................................................ 51