МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РЕСПУБЛИКИ КАЗАХСТАН
Некоммерческое акционерное общество
«АЛМАТИНСКИЙ УНИВЕРСИТЕТ ЭНЕРГЕТИКИ И СВЯЗИ»
Кафедра компьютерных технологий
Куралбаев З.К.
ТЕХНОЛОГИИ ВЫСОКОСКОРОСТНЫХ ВЫЧИСЛЕНИЙ
Конспект лекций
для магистрантов, обучающихся по специальности
6М070400 – Вычислительная техника и программное обеспечение
Алматы, АУЭС, 2016
СОСТАВИТЕЛЬ: Куралбаев З.К., д.ф.-м.н., профессор. Технологии высокоскоростных вычислений. Конспект лекций для магистрантов, обучающихся по специальности 6М070400 – Вычислительная техника и программное обеспечение. – Алматы: АУЭС. - 87 с.
Конспект лекций содержит теоретические материалы по дисциплине «Технологии высокоскоростных вычислений», где рассматриваются основные понятия о высокоскоростных вычислениях, технологиях, применяемых для обеспечения высокой скорости решения практических задач и другие вопросы.
Рекомендуется магистрантам всех форм обучения по специальности 6М070400 – Вычислительная техника и программное обеспечение.
Ил., табл. , библиогр. - 11 назв.
Рецензент: канд. техн. наук, профессор Хисаров Б.Д.
Печатается по плану издания Некоммерческого акционерного общества «Алматинский университет энергетики и связи» на 2016 г.
© НАО «Алматинский университет энергетики и связи», 2016 г.
Лекция 1. Введение. Основные понятия о технологиях высокоскоростных вычислений
Цель лекции: дать магистрантам знания о необходимости разработки методов и технологий высокоскоростных вычислений, и о роли их в решении крупных практических задач.
Содержание лекции: Общие принципы организации высокопроизводительных ЭВМ и высокоскоростных вычислений. Уровни создания вычислительных систем.
Известно, что первопричиной создания компьютеров была настоятельная необходимость быстрого проведения вычислительных работ, связанных с решением больших научно-технических задач в различных отраслях и сферах деятельности человека. Решение таких задач и сейчас остается главным стимулом совершенствования компьютеров. В своем развитии компьютеры достигли высокого уровня совершенства. Современные компьютеры обладают большой скоростью выполнения заданий и достаточно просты в обращении. Однако увеличение возможностей компьютеров все же ограничено. И тогда приходится обращаться к суперкомпьютерам.
Появление суперЭВМ в качестве самостоятельного класса вычислительных машин произошло в начале 80-х гг. К середине 1985 г. в мире действовало более 150 таких ЭВМ стоимостью около 10 млн. долл. каждая. Важным фактором, послужившим причиной внезапного роста их популярности, является внезапное и очень резкое увеличение производительности ЭВМ за счет внедрения векторной обработки. В 70-х гг. ряд смелых идей был воплощен в целом классе машин, которые не имели коммерческого успеха, зато проложили путь к созданию нынешнего поколения суперЭВМ. Именно тогда впервые были реализованы принципы параллельной и векторной обработки. В 80-х гг. векторные машины практически стали обыденным явлением.
Согласно распространенному мнению, суперкомпьютер имеет огромную мощность: высокую скорость, большую память, высокую цену. Однако переход от персонального компьютера к суперкомпьютеру для пользователя связан также с большими трудностями. Главная трудность связана с тем, что для них отсутствует пользовательская среда. Кроме этого, разные суперкомпьютеры не совместимы друг с другом.
Общие принципы организации высокопроизводительных ЭВМ и высокоскоростных вычислений. Повышение производительности вычислительных систем предусматривает прежде всего достижение высокой скорости исполнения программ. Такая цель соответствует как требованиям пользователей, заинтересованных в наиболее быстром получении результатов счета, так и тому обстоятельству, что быстродействие определяет общее количество вычислительной работы, которую способна выполнить система за данный отрезок времени.
В ряде прикладных областей повышение скорости вычислений играет большую роль, так как время решения задач на стандартных ЭВМ обычно оказывается слишком большим с точки зрения практического использования результатов. Разумеется, стоимостные факторы и в этом случае имеют существенное значение, однако более важным становится обеспечение самой возможности получения результатов за приемлемое время при минимальной (насколько это удается) стоимости вычислений. Именно в таких прикладных областях и требуются суперЭВМ.
Основными
факторами, определяющими высокую стоимость суперЭВМ, являются:
1. Большие затраты на конструирование, обусловленные сложностью
оборудования и относительно малым серийным выпуском.
2. Высокая стоимость аппаратуры, для создания которой требуются новые
технологии, способные обеспечить предельные для нынешнего уровня развития
техники показатели. На стоимость аппаратуры влияют также увеличение числа
логических элементов, количества выделяемой теплоты в единице объема и другие
подобные факторы.
3. Дорогостоящее программное обеспечение, включающее специальные
средства, которые позволяют реализовать потенциально высокое быстродействие
систем.
Уровни создания вычислительных систем. Область применения методов достижения высокого быстродействия охватывает все уровни создания систем.
На самом нижнем уровне - это передовая технология конструирования и изготовления быстродействующих элементов и плат с высокой плотностью монтажа. В этой сфере лежит наиболее прямой путь к увеличению скорости, поскольку если бы, например, удалось все задержки в машине сократить в К раз, то это привело бы к увеличению быстродействия в такое же число раз. В последние годы были достигнуты огромные успехи в создании быстродействующей элементной базы и адекватных методов монтажа, и ожидается дальнейший прогресс, основанный на использовании новых технологий и снижения размеров устройств. Этот путь, однако, имеет ряд ограничений:
1. Для определенного уровня технологии обеспечивается определенный уровень быстродействия элементной базы: как только он оказался достигнутым, дальнейшее увеличение быстродействия сопровождается огромными расходами вплоть до достижения того порога, за которым уже нет технологий, обеспечивающих большее быстродействие.
2. Более быстродействующие элементы обычно имеют меньшую плотность монтажа, что, в свою очередь, требуют более длинных соединительных кабелей между платами и, следовательно, приводит к увеличению задержек (за счет соединений) и уменьшению выигрыша в производительности.
3. Более быстродействующие элементы обычно рассеивают больше тепла. Поэтому требуются специальные меры по теплоотводу, что еще больше снижает плотность монтажа и, следовательно, быстродействие. Для того чтобы избежать дополнительных расходов, задержек за счет соединений и увеличения рассеяния тепла, целесообразно, по-видимому, применять быстродействующие элементы не везде, а только в тех частях, которые соответствуют <узким местам>. Например, чтобы увеличить скорость сложения, можно применить высокоскоростные схемы только в цепи переноса. Однако путь увеличения быстродействия элементов имеет свои ограничения и может наступить момент, когда станет необходимым или более целесообразным использовать для реализации операции сложения другие способы.
Следующий шаг в направлении повышения быстродействия предполагает уменьшение числа логических уровней при реализации комбинационных схем. Хорошо известно, что любая функция может быть реализована с помощью схемы с двумя логическими уровнями. Однако в сложных системах это приводит к появлению громоздких устройств, содержащих очень большое число вентилей с чрезмерными коэффициентами соединений по входу и выходу. Следовательно, на данном этапе конструкторская задача состоит в создании схем с малым числом логических уровней, которое бы удовлетворяло ограничениям по количеству вентилей и их коэффициентам соединений по входу и выходу. В настоящее время разработаны принципы построения схем, требующих меньшее число вентилей и обладающих меньшими задержками, и предложены методы их создания. В силу присущих ограничений только один этот путь, как правило, не может дать требуемого увеличения производительности.
Следующий уровень охватывает способы реализации основных операций, таких как сложение, умножение и деление. Для того чтобы увеличить cкорость выполнения этих операций, необходимо использовать алгоритмы, которые приводили бы к быстродействующим комбинационным схемам и требовали небольшого числа циклов. В результате успешных исследований и разработок в области арифметических устройств создан ряд алгоритмов, которые могут быть использованы в условиях тех или иных ограничений. С точки зрения применения высокопроизводительных вычислительных машин для научных расчетов особый интерес представляет реализация принципа опережающего просмотра при операциях сложения, сложения с сохраняемым переносом и записи при матричном умножении. Сюда же относятся проблемы использования избыточности при делении и реализация деления в виде цепочки операций умножения.
Далее, быстродействие вычислительных систем может быть повышено за счет реализации аппаратными или программно-аппаратными средствами встроенных сложных команд соответствующих тем или иным функциям, встречающимся во многих практических вычислениях. К таким функциям относятся, например, корень квадратный, сложение векторов, умножение матриц и быстрое преобразование Фурье. Указанные средства позволяют сократить число команд в программах и создают предпосылки для более эффективного использования машинных ресурсов (например, конвейеризованных арифметических устройств). При решении некоторых задач получаемый выигрыш может быть весьма существенным, что особенно хорошо видно на примере рассматриваемых ниже векторных ЭВМ, в которых основную роль играют векторные команды. С другой стороны, непросто определить такие сложные команды, которые бы достаточно часто использовались в широком классе прикладных программ. В то же время исследования процессов выполнения большого числа программ из разных прикладных областей показывают, что существует явное смещение частот использования в направлении небольшого набора простых команд. Этот факт послужил основой для развития подхода, при котором из множества команд выделяется небольшое подмножество простых и часто используемых команд, подлежащих оптимизации. В настоящее время уже разработан ряд экспериментальных и промышленных образцов процессоров, использующих принцип оптимизации сокращенного набора команд. Влияние этого подхода на прогресс в области высокоскоростных вычислений нуждается в оценке.
Еще один резерв, используемый для повышения эффективности работы процессора,- это сокращение временных затрат при обращениях к памяти. Обычные подходы здесь состоят, во-первых, в расширении путей доступа за счет разбиения памяти на модули, обращение к которым может осуществляться одновременно; во-вторых, в применении дополнительной сверхбыстродействующей памяти (кэш-памяти) и, наконец, в увеличении числа внутренних регистров в процессоре. Как показано ниже, использование всех перечисленных способов тесно связано с организацией систем. Длительность исполнения одной команды может быть уменьшена за счет временного перекрытия различных ее фаз. К примеру, вычисление адреса, по которому нужно записать результат, может быть выполнено одновременно с самой операцией. Этот подход требует, разумеется, дополнительного оборудования, поскольку модули памяти не могут быть одновременно задействованы в совмещаемых фазах. Увеличение быстродействия, которое можно при этом достичь, зависит от формата (состава) команды, поскольку именно им определяется наличие независимых фаз.
Наконец, мы подходим к структуре алгоритма, по которому работает система. На этом уровне основной подход к повышению быстродействия состоит в том, чтобы выполнять одновременно несколько команд. Этот подход отличается от того, который реализован в обычной фон-неймановской машине, когда команды исполняются строго последовательно одна за другой. Параллельный подход приводит к различным вариантам архитектуры в зависимости от способа, по которому осуществляется задание очередности следования команд и управление их исполнением. Распараллеливание позволяет значительно увеличить производительность систем при решении широкого класса прикладных задач.
Перечисленные подходы касаются аппаратуры, логической организации и архитектуры систем. Усилия, затрачиваемые в этих областях, имеют своей целью обеспечение необходимого ускорения вычислений на программно-алгоритмическом уровне. На этом уровне должны использоваться либо специальные языки программирования, предоставляющие средства для явного описания параллелизма, либо методы выявления параллелизма в последовательных программах. Кроме того, алгоритм должен обладать внутренним параллелизмом, соответствующим особенностям данной архитектуры. Использование неадекватных алгоритмов и языков способно практически свести на нет возможности для реализации высокоскоростных вычислений, заложенные в архитектуре.
Лекция 2. Организация быстродействующих вычислительных систем
Цель лекции: Дать магистрантам знания и информацию о способах организации высокоскоростных вычислений, ознакомить с основными вычислительными системами.
Содержание лекции: Организация быстродействующих вычислительных систем. Матричная вычислительная система. Векторная вычислительная система. Принципы векторной обработки.
Как отмечалось в предыдущем параграфе, главный организационный принцип, ведущий к повышению быстродействия, подразумевает одновременное выполнение нескольких команд. В этом разделе мы рассмотрим возможные варианты организации систем и покажем, что эффективность их использования связана со структурами вычислительных алгоритмов.
Алгоритм - это описание вычислительного процесса в виде последовательности более простых вычислительных конструкций. Алгоритм включает спецификации этих вычислительных конструкций и отношений следования между ними. Алгоритмические структуры отличаются друг от друга содержанием простых вычислительных конструкций и типом отношения следования.
Вычислительные конструкции, образующие алгоритм, могут быть различными по степени сложности объектами: от простых арифметических операторов до функций. В действительности же концепция алгоритма подразумевает иерархию в том смысле, что вычислительная конструкция в свою очередь может быть описана в виде алгоритма, состоящего из еще более простых вычислительных конструкций. В контексте рассуждений о параллелизме это приводит к понятию детализации параллелизма. Детализацию называют мелкой, если вычислительные конструкции алгоритма являются примитивными (т. е. реализуемыми одной командой), и крупной, если эти конструкции являются сложными (т. е. реализуются с помощью другого алгоритма). Разумеется, спектр значений детализации параллелизма простирается от очень мелкой до очень крупной. Более того, в системах может использоваться комбинированная детализация.
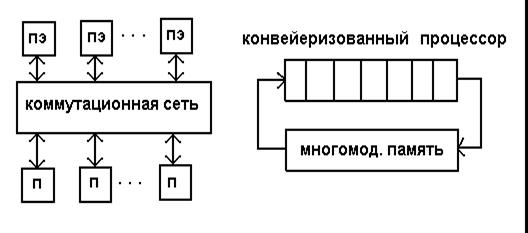
Рисунок 1 - Матричная вычислительная система (левый рисунок)
Рисунок 2 - Конвейерная вычислительная система (правый рисунок)
На этих рисунках ПЭ - процессорные элементы, П - модули памяти.
Основной тип организации векторной вычислительной системы изображен на рисунке 3. Он включает блок обработки команд, осуществляющий вызов и декодирование команд, векторный процессор, исполняющий векторные команды, скалярный процессор, исполняющий скалярные команды, а также память для хранения программ и данных. Последняя делится на главную память и память второго уровня, что обеспечивает ей необходимую емкость и пропускную способность при приемлемой стоимости. Компоненты векторного процессора, также изображенные на рисунке 3, рассмотрены ниже.
Чтобы показать, какой выигрыш в производительности дает векторная машина, рассмотрим операцию сложения двух векторов на рисунке 4,а изображены скалярная программа и временная диаграмма ее исполнения на обычной ЭВМ, в которой реализован опережающий просмотр в сочетании с конвейерным исполнением операций. На рисунке 4,б изображены соответствующая векторная программа и временная диаграмма.
Принципы векторной обработки. Принцип векторной обработки основан на существовании значительного класса задач использующих операции над векторами. Алгоритмы этих задач в соответствии с терминологией Флинна относятся к классу ОКМД (одиночный поток команд, множественный поток данных). Реализация операций обработки векторов на скалярных процессорах с помощью обычных циклов ограничивает скорость вычислений по следующим причинам.
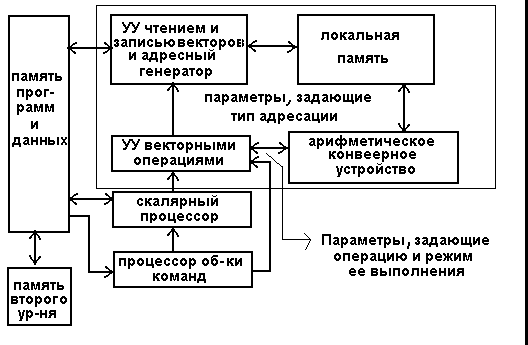
Рисунок 3 - Структура векторной вычислительной системы
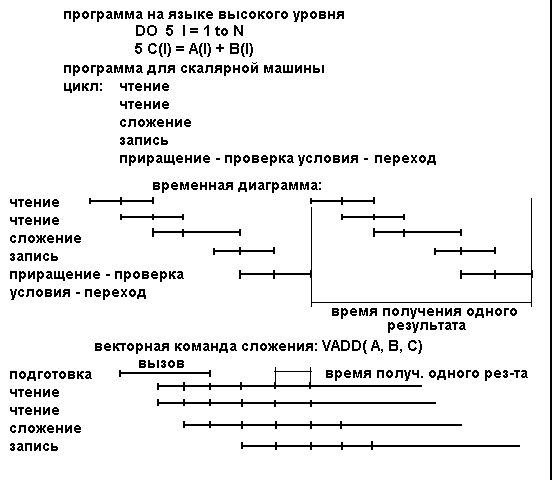
Рисунок 4 - Вычисление суммы двух векторов.
а - на скалярном процессоре; б - на векторном процессоре
1. Перед каждой скалярной операцией необходимо вызывать и декодировать скалярную команду.
2. Для каждой команды необходимо вычислять адреса элементов данных.
3. Данные должны вызываться из памяти, а результаты запоминаться в памяти. В больших ЭВМ память выполняется, как правило, в виде набора модулей, доступ к которым может осуществляться одновременно. В условиях когда каждая команда вырабатывает свой собственный запрос к памяти, такой раздробленный доступ может стать причиной возникновения конфликтов обращения к памяти, препятствующих эффективному использованию ее потенциальной пропускной способности. 4
4. Необходимо осуществлять упорядочение выполнения операций в функциональных устройствах. В целях увеличения производительности эти устройства строятся по конвейерному принципу. Эффективному использованию конвейерных устройств препятствует последовательная “природа” оператора цикла.
5. Реализация команд построения циклов (счетчик и переход) сопровождается накладными расходами. Кроме того, наличие в цикле команды перехода препятствует эффективному использованию принципа опережающего просмотра.
Влияние перечисленных отрицательных факторов уменьшается при введении векторных команд, с помощью которых задается одна и та же операция над элементами одного или нескольких векторов, и организации, системы, которая обеспечивает эффективное исполнение таких команд. Этот подход реализуется в системах двух типов: матричных и векторно-конвейерных.
Матричная система состоит из множества процессорных элементов (ПЭ), организованных таким образом, что они исполняют векторные, команды, задаваемые общим для всех устройством управления, причем каждый ПЭ работает с отдельным элементом вектора. ПЭ соединены через коммутационное устройство с многомодульной памятью. Исполнение векторной команды включает чтение из памяти элементов векторов, распределение их по процессорам, выполнение заданной операции и засылку результатов обратно в память.
В векторно-конвейерной системе, напротив, имеется один (или небольшое число) конвейерный процессор, выполняющий векторные команды путем засылки элементов векторов в конвейер с интервалом, равным длительности прохождения одной, стадии обработки. При этом скорость вычислений зависит только от длительности стадии и не зависит от задержек в процессоре в целом.
Оба подхода в принципе позволяют достичь значительного ускорения по сравнению со скалярными машинами. Более того, ускорение в системах матричного типа может быть больше, чем в конвейерных, поскольку увеличить число процессорных элементов проще, чем число ступеней в конвейерном устройстве. В настоящее время созданы и успешно применяются системы обоих типов. К наиболее значительным представителям семейства матричных систем относятся одна из первых крупных разработок – ILLIAC IV - системы DAP фирмы ICL, BSP фирмы Burrougs и МРР фирмы Goodyear. Класс конвейерных систем включает такие системы, как STAR100 и Суbег 205 фирмы СDС, Сгау-1 фирмы Сгау >Research, S-810 фирмы НIТАСНI, SХ NЕС и FАСОМ, VР-200 фирмы Fujitsu. Тот факт, что большинство суперЭВМ относится к классу конвейерных систем, свидетельствует, похоже, о том, что для современного уровня технологии такие системы являются более гибкими и эффективными с точки зрения стоимости.
Лекция 3. Факторы, снижающие пропускную способность
Цель лекции: Изучение способов скалярной и конвейерной обработки данных. Знакомство с зависимостями по данным и по управлению.
Содержание лекции: Скалярная обработка. Стартовое время конвейера. Зависимости по данным. Зависимости по управлению.
Существует ряд факторов, приводящих к тому, что при выполнении реальных программ производительность векторных ЭВМ оказывается значительно ниже максимально возможной. Мы обсудим наиболее важные из них и покажем, какие показатели могут служить мерой снижения производительности.
Скалярная обработка. Невозможно построить реальную прикладную программу, состоящую только из векторных операций. Значительная часть вычислений остается скалярной, причем некоторые скалярные команды служат для подготовки, векторных команд и управления их прохождением. Поскольку векторные устройства не обеспечивают эффективного исполнения этих команд, в состав оборудования входит скалярный процессор. Всякий раз, когда исполнение какой-либо скалярной операции не полностью перекрывается по времени векторными вычислениями, происходит снижение производительности.
Величина снижения может быть получена исходя из доли скалярных операций (f)и отношения максимальной пропускной способности в векторном режиме к пропускной способности в скалярном режиме (r). В итоге получим коэффициент снижения пропускной способности:
d=Rmax/R=f*r+(1-f) ,
где Rmax - максимальная пропускная
способность (полная загрузка всех конвейеров), R - реальная пропускная
способность, ![]() -
отношение максимальной пропускной способности в векторном режиме к пропускной
способности в скалярном режиме.
-
отношение максимальной пропускной способности в векторном режиме к пропускной
способности в скалярном режиме.
Как видно из рисунке 1, снижение производительности может быть весьма значительным.
Так, например, при f = 0,1 и r =50 реальная производительность меньше максимальной в 5,9 раза. Конкретные значения f и r варьируются в зависимости от системы и прикладной области
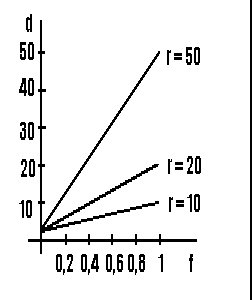
Рисунок 1 - Коэффициент снижения производительности
Стартовое время конвейера. Максимальная пропускная способность конвейерной машины достигается при обработке длинных векторов, поскольку только в этом случае доля времени, затрачиваемого на начальном этапе (загрузка параметров, реконфигурация, ожидание первого результата), оказывается максимальной. Следовательно, пропускная способность R как функция длины вектора l определяется выражением:
![]()
где ts - время прохождения одной стадии конвейера, tstart - стартовое время конвейера.
Типичными для современных суперЭВМ являются следующие цифры: tstart = 1000нс, ts = 15нс. Из графика этой функции, приведенного на рис.4.2, видно, что при малых длинах векторов пропускная способность может быть значительно ниже максимальной. Таким образом, необходимо стремиться к тому, чтобы длина векторов была возможно большей, а стартовое время меньшим.
Наличие стартового времени приводит к тому, что векторная обработка оказывается эффективней скалярной лишь начиная с некоторого порога длины векторов. Соответствующей количественной мерой может служить коэффициент ускорения вычислений как функция длины вектора, а именно:
![]()
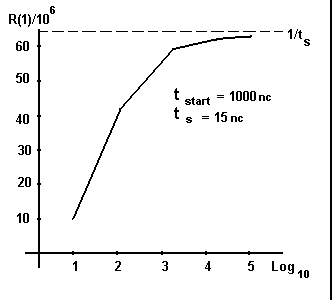
Рисунок 2 - Пропускная способность, как функция длины вектора
где r - введенное ранее отношение максимальных пропускных способностей при векторном и скалярных режимах соответственно. Отсюда найдем приближенную пороговую длину вектора:
![]()
где tscalar - время выполнения скалярных операций.
Зависимости по данным. Условием работы процессора в режиме пиковой производительности является одновременное исполнение нескольких команд, обеспечивающее постоянную занятость всех функциональных устройств. При наличии зависимостей по данным между командами, т.е. когда одна команда не может исполняться до завершения другой, это условие нарушается. Такого рода зависимость может существовать между любыми двумя командами. Примером двух зависимых векторных команд может служить следующий фрагмент:
![]()
![]()
В этом случае снижение производительности может быть предотвращено с помощью образования цепочек операций, когда исполнение данной векторной команды начинается сразу, как только образуются компоненты участвующих в ней векторных операндов (см. рисунок 2.3). Данный метод может применяться в большом числе практических случаев, однако не всегда.
Например, его нельзя использовать в следующем примере:
![]()
поскольку для начала исполнения второй команды необходимо вычислить скалярный результат первой.
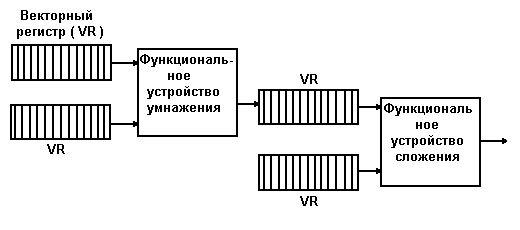
Рисунок 2.3 - Образование цепочки операций
Зависимости по управлению. Данный тип зависимости существует двумя командами в ситуациях до тех пор, пока не завершится исполнение предыдущей команды, и остается неизвестным, какая из двух окажется следующей. Такая зависимость обычно порождается условными переходами и является одним из наиболее существенных отрицательно влияющих на производительность факторов в скалярных процессорах с опережающим просмотром.
В векторных ЭВМ, где часть операторов цикла заменена векторными командами, влияние данного фактора несколько ослаблено, однако остается еще значительным.
При наличии зависимостей данного типа, когда команда, с которой начинается та или иная ветвь, остается неизвестной до тех пор, пока не завершится исполнение предыдущей команды и последовательность не прервется, в потери времени входит полный цикл обработки команды: вызов, декодирование и др.
Для уменьшения этих потерь различные конструктивные средства: предварительный вызов начальных команд обеих ветвей, являющихся возможными продолжениями данной; использование нескольких командных буферов для хранения разных участков программ; хранение, задержанных ветвей в виде, позволяющем загрузить процессор сразу после завершения выбора ветви.
Эти методы, разработаны для высокопроизводительных скалярных процессоров.
Лекция 4. Реализация условных операторов и ограничения, налагаемые на производительность
Цель лекции: Изучение способов использования условных операторов и знакомство с ограничениями при высокоскоростных вычислениях.
Содержание лекции: Реализация условных операторов. Нахождение команд вне буфера. Ограничения, связанные с локальной памятью. Ограничения, связанные с механизмом адресации и недостаточно эффективной пропускной способностью памяти. Ограничения, связанные с конфликтами доступа к памяти. Ограничения, связанные со специализированными арифметическими устройствами. Ограничения, связанные с объемом памяти. Оценка общей производительности.
Векторная команда как единое целое не может быть выполнена в ситуациях, когда вид операции над элементами вектора зависит от условия, как, например, в следующем фрагменте:
if
![]() then
then ![]() else
else
![]()
Один из возможных выходов состоит в том, чтобы выполнить все операции в скалярном режиме, однако, как мы видели раньше, это привело бы к резкому снижению производительности, Более перспективной альтернативой является использование для управления векторной операцией так называемого вектора режима. Это битовый вектор, содержащий такое же число элементов, как и каждый из векторов в управляемой операции. Управление в данном случае означает то, что операция выполняется только над теми элементами векторов, которым соответствует значение 1 в одноименных позициях вектора режима. Безусловно описанный способ лучше, чем скалярный, однако и при нем все еще остаются факторы, снижающие производительность.
Нахождение команд вне буфера. Как уже отмечалось при рассмотрении базовой структуры процессора, для обеспечения высокой производительности необходимо заранее вызывать команды из памяти и помещать в специальный буфер. Наличие такого буфера позволяет считывать из памяти целые блоки следующих друг за другом команд. Если эти команды находятся в памяти, организованной по принципу чередования адресов, то такая выборка может осуществляться параллельно со всеми преимуществами, которые представляет многомодульная организация памяти.
Ограничения, связанные с локальной памятью. Для поддержания высокой скорости конвейера арифметических операций операнды должны, интенсивно поступать из памяти. Это, в свою очередь, требует разделения памяти, на модули с возможностью одновременного доступа, а также включения буфером для операндов и результатов. Такой 6уфер сглаживает изменения пропускной способности тракта обмена данными между памятью и арифметическими устройствами, а также позволяет осуществлять выборку из памяти~ элементов векторов в порядке, отличающемся от того, который должен быть на входе обрабатывающих устройств. Это, как будет показано далее, существенно расширяет диапазон прикладных задач, которые могут эффективно решаться в векторном режиме. Буферная память служит также для хранения результатов, которые в последующих векторных командах выступают в качестве операндов.
По способу организации локальной памяти векторные процессоры делятся на два класса. К первому относятся те, в которых команды исполняются по принципу “регистр-регистр”, а ко второму - по принципу “память-память”. В первом случае локальная память представляет собой набор векторных регистров, адресуемых в командах, а во втором: локальную память, работающую как - буферное устройство и остающуюся невидимой для программиста. Основным преимуществом систем первого класса состоят в следующем: команды, в которых указаны короткие адреса регистров, имеют меньшую длину; промежуточные результаты естественным образом хранятся на регистрах; облегчается процесс контроля зависимостей между командами. Главный недостаток данного подхода связан с ограниченностью разрядности и числа регистров.
Ограничения, связанные с механизмом адресации и недостаточно эффективной пропускной способностью памяти. Поскольку время доступа к памяти существенно превышает длительность одной стадии обрабатывающего конвейера, а в процессе исполнения программ требуются одновременные обращения к памяти за различными операндами, обеспечение адекватной пропускной способности памяти в векторном режиме, когда элементы векторов-операндов занимают последовательный ряд адресов достигается за счет организации памяти в виде нескольких модулей и применения принципа чередования адресов (интерливинг/расслоение).
Это позволяет даже при максимальной пропускной способности осуществлять бесконфликтный доступ к блокам последовательно адресуемых элементов векторов.
Ограничения, связанные с конфликтами доступа к памяти. К ограничивающим факторам относятся конфликты доступа, возникающие при одновременном появлении нескольких разных - о6ращений к памяти. Необходимым условием работы системы с максимальной производительностью является своевременное считывание команд из памяти, вызов скалярных и векторных операндов и запись зарабатываемых результатов.
Указанные запросы реализуются через равные порты и “мешают” друг другу, что приводит к неполному использованию пропускной способности памяти. Для того чтобы отрицательное влияние этих конфликтов на общую производительность было минимальным, устройство управления доступом к памяти должно соответствующим образом планировать порядок обслуживания запросов.
Например, в системе Cray X-MP память разделена на четыре секции, каждая из которых имеет четыре порта: три обслуживают запросы процессоров и один обслуживает ввод/вывод. Порты А и В предназначены для чтения, а порт С для записи. Возникающие конфликты разрешаются с помощью системы приоритетов, причем последние зависят от вида обращения и времени поступления. Из сказанного ясно, что получить адекватную оценку производительности можно только путем прогонки программ на реальном оборудовании.
Ограничения, связанные со специализированными арифметическими устройствами. Максимальная пропускная способность системы достигается только в том случае, когда все арифметические устройства используются полностью. Как было отмечено выше, полной загрузке этих устройств препятствует наличие зависимостей по данным и по управлению. Другим ограничивающим фактором уменьшающим эффективную производительность, является специализированность арифметических устройств, состоящих из устройства сложения, устройства умножения и т.д. В этом случае полное использование арифметического оборудования возможно только на специально подобранной смеси векторных и скалярных операций. Следовательно, реальная производительность зависит от состава операций в конкретной программе.
Ограничения, связанные с объемом памяти. При решении многих прикладных задач массивы данных оказываются столь большими, что не могут уместиться в главной памяти. В этих случаях часть данных приходится хранить в памяти второго уровня и осуществлять подкачку и удаление информации в процессе счета. Размер главной памяти, скорость подкачки, способ сегментирования - все эти факторы оказывают значительное влияние на производительность.
Оценка общей производительности. Ввиду сложного характера взаимодействия между факторами, снижающими производительность, и зависимостью степени влияния этих факторов от конкретных программ оценка призводительности в целом должна осуществляться на специально подобранных прикладных задачах.
Приближенная оценка может быть получена с помощью контрольных задач, состоящих из набора типовых тестовых программ. Проблема, связанная с такой приближенной оценкой, заключается в трудности определения термина <типовой>. Искусственные контрольные задачи, содержащие в нужном соотношении скалярные операции и векторные команды различных типов, могут дать лишь самые грубые оценки.
Недостаток данного метода состоит в том, что он не учитывает взаимосвязи между командами, роль которых в формировании реального показателя производительности может быть значительной. Одними из наиболее широко используемых для оценки векторных машин контрольных задач являются так называемые Ливерморские циклы, разработанные в Национальной лаборатории им. Лоуренса в г. Ливерморе (США). Интересно отметить, что для всех типов машин оценки, полученные на разных циклах, сильно отличаются друг от друга.
Например, согласно этим оценкам производительность Сrау-1 колеблется от 3 до 90 млн. операций с плавающей запятой в секунду. Кроме того, хотя наилучшие и наихудшие с точки зрения производительности циклы практически одни и те же для всех машин, характер зависимости производительности от типа цикла на разных машинах существенно отличается один от другого.
Это подтверждает тезис о специфическом влиянии на производительность тех или иных особенностей организации систем. На производительность оказывает влияние также качество используемого компилятора.
Лекция 5. Архитектура высокопроизводительных ЭВМ
Цель лекции: Знакомство с основными видами архитектуры высокопроизводительных ЭВМ и их возможностями.
Содержание лекции: Рассматриваются различные виды архитектуры ЭВМ, их основные характеристики. Информация о классификации высокопроизводительных ЭВМ.
Прежде чем мы перейдем к изучению методов и средств параллельного программирования, полезно познакомиться с некоторыми особенностями устройства высокопроизводительных вычислительных систем. Преимуществом использования языков программирования высокого уровня является универсальность программ и их простая переносимость между различными компьютерами (разумеется, если на этих компьютерах имеется необходимое программное обеспечение, прежде всего, трансляторы).
Следует учитывать, что эффективность выполнения параллельных программ определяется не только аппаратной частью, но и способностью транслятора генерировать эффективный исполняемый код. Оба эти фактора взаимосвязаны и порой сложно определить, какой из них имеет решающее значение.
Обычно, программист полагается на эффективность транслятора, считая, что при грамотном программировании сгенерированный транслятором исполняемый код будет обладать хорошими показателями по быстродействию; в этом случае отпадает необходимость в применении языков низкого уровня (ассемблеров), требующих глубоких знаний архитектуры процессора.
Но, бывает и так, что программисту все же требуется знание устройства компьютера, принципов и даже некоторых деталей его работы. Можно привести следующий пример. При разработке программ для параллельных ЭВМ используются специализированные библиотеки, позволяющие организовать обмен данными между отдельными подзадачами и их синхронизацию. Для эффективной организации обмена данными необходимо знать, как происходит пересылка информации между процессорами, какова ее скорость и т. д.
В вычислительной технике используются три термина, связанные с устройством электронно-вычислительной машины:
Архитектура компьютера — это описание основных компонентов компьютера и их взаимодействия. Можно считать, что архитектура — это те атрибуты вычислительной системы, которые видны программисту: набор команд, разрядность машинного слова, механизмы ввода/вывода, методы адресации. Можно дать и другое определение: архитектура — это внутренняя структура системы или микропроцессора, которая определяет их функциональные возможности и быстродействие.
Организация компьютера — это описание конкретной реализации архитектуры, ее воплощения "в железе". Оно включает перечень используемых сигналов управления, интерфейсов, технологий памяти, реализацию арифметических, логических и других операций. Так, умножение может быть реализовано на аппаратном уровне или посредством многократного повторения операции суммирования.
Ряд суперкомпьютеров Cray, например, имеют сходную архитектуру. С точки зрения программиста у них одинаковое число внутренних регистров, используемых для временного хранения данных, одинаковый набор машинных команд, одинаковый формат представления данных. Организация же компьютеров Cray разных моделей может существенно различаться. У них может быть разное число процессоров, разный размер оперативной памяти, разное быстродействие и т. д.
Схема компьютера — детальное описание его электронных компонентов, их соединений, устройств питания, охлаждения и др. Программисту довольно часто требуется знание архитектуры компьютера, реже — его организации и никогда — схемы компьютера.
Действительно, зачем специалисту, который занимается, например, расчетом прочностных свойств новой модели автомобиля, знать, какая марка вентилятора охлаждает процессор компьютера во время выполнения его программы?
Классификация Флинна. Одной из наиболее известных схем классификации компьютерных архитектур является таксономия Флинна, предложенная Майклом Флинном в 1972 году. В ее основу положено описание работы компьютера с потоками команд и данных. В классификации Флинна имеется четыре класса архитектур:
1. SISD (Single Instruction Stream — Single Data Stream) — один поток команд и один поток данных.
2. SIMD (Single Instruction Stream — Multiple Data Stream) — один поток команд и несколько потоков данных.
3. MISD (Multiple Instruction Stream — Single Data Stream) — несколько потоков команд и один поток данных.
4. MIMD (Multiple Instruction Stream — Multiple Data Stream) — несколько потоков команд и несколько потоков данных.
Рассмотрим эту классификацию более подробно.
SISD-компьютеры. SISD-компьютеры (Рисунок 1) — это обычные последовательные компьютеры, выполняющие в каждый момент времени только одну операцию над одним элементом данных. Большинство современных персональных ЭВМ принадлежат именно этой категории.
Многие современные вычислительные системы включают в свой состав несколько процессоров, но каждый из них работает со своим независимым потоком данных, относящимся к независимой программе. Такой компьютер является, фактически, набором SISD-машин, работающих с независимыми множествами данных.
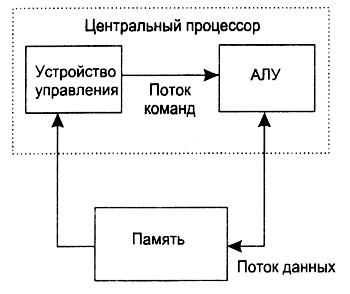
Рисунок 1 - Схема SISD-компьютера
SIМD-компьютеры. SIMD-компьютеры (Рисунки 2 и 3) состоят из одного командного процессора (управляющего модуля), называемого контроллером, и нескольких модулей обработки данных, называемых процессорными элементами (ПЭ). Количество модулей обработки данных таких машин может быть от 1024 до 16 384.
Управляющий модуль принимает, анализирует и выполняет команды. Если в команде встречаются данные, контроллер рассылает на все ПЭ команду, и эта команда выполняется либо на нескольких, либо на всех процессорных элементах.
Процессорные элементы в SIMD-компьютерах имеют относительно простое устройство, они содержат арифметико-логическое устройство (АЛУ), выполняющее команды, поступающие из устройства управления (УУ), несколько регистров и локальную оперативную память. Одним из преимуществ данной архитектуры считается эффективная реализация логики вычислений.
До половины логических команд обычного процессора связано с управлением процессом выполнения машинных команд, а остальная их часть относится к работе с внутренней памятью процессора и выполнению арифметических операций. В SIMD-компьютере управление выполняется контроллером, а "арифметика" отдана процессорным элементам.
Подклассом SIMD-компьютеров являются векторные компьютеры. Пример такой вычислительной системы — Hitachi S3600.
MISD-компьютеры. Вычислительных машин такого класса мало. Один из немногих примеров - систолический массив процессоров, в котором процессоры находятся в узлах регулярной решетки. Роль ребер в ней играют межпроцессорные соединения, все ПЭ управляются общим тактовым генератором. В каждом цикле работы любой ПЭ получает данные от своих соседей, выполняет одну команду и передает результат соседям. На рисунке 4 дана схема фрагмента систолического массива
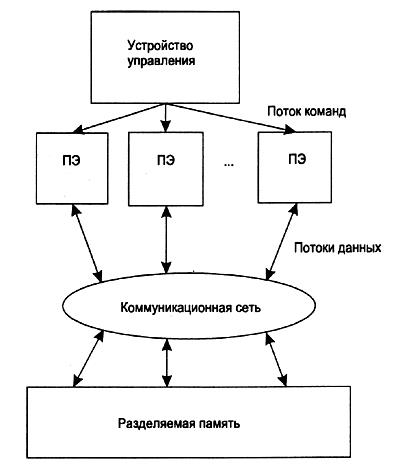
Рисунок 2 - Схема SIMD-компьютера с разделяемой памятью
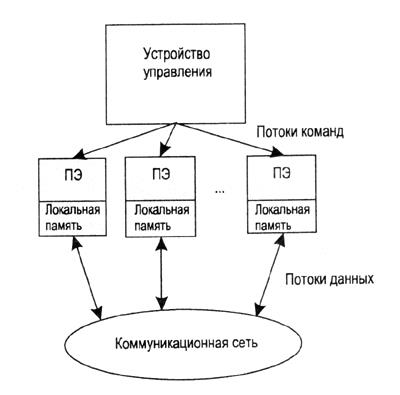
Рисунок 3 - Схема SIMD-компьютера с распределенной памятью
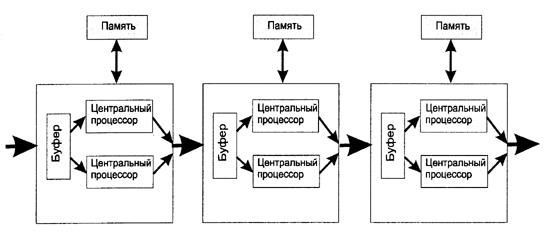
Рисунок 4 - Схема MISD-компьютера
Лекция 6. MIMD-компьютеры
Цель лекции: Знакомство с одним из популярных видов компьютеров, с возможностями и особенностями MIMD-компьютеров.
Содержание лекции: Основные характеристики и возможности MIMD-компьютеров, архитектура фон Неймана.
Этот класс архитектур (Рисунки 1.5 и 1.6) наиболее богат примерами успешных реализаций. В него попадают симметричные параллельные вычислительные системы, рабочие станции с несколькими процессорами, кластеры рабочих станций и т. д. Довольно давно появились компьютеры с несколькими независимыми процессорами, но вначале на них был реализован только принцип параллельного исполнения заданий, т. е. на разных процессорах одновременно выполнялись независимые программы. Разработке первых компьютеров для параллельных вычислений были посвящены проекты под условным названием СМ* и С.ММР в университете Карнеги (США). Технической базой для этих проектов были процессоры DEC PDP-11. В начале 90-х годов прошлого века именно MIMD-компьютеры вышли в лидеры на рынке высокопроизводительных вычислительных систем.
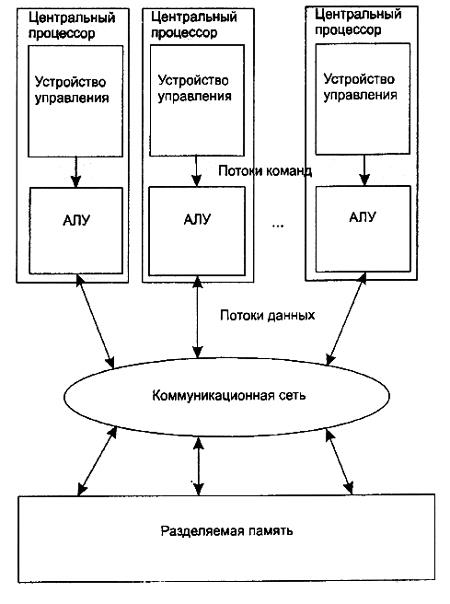
Рисунок 5 - Схема MIMD-компьютера с разделяемой памятью
Имеются и гибридные конфигурации, в которых, например, объединены несколько SIMD-компьютеров, в результате чего получается MSIMD-компьютер, позволяющий создавать виртуальные конфигурации, каждая из которых работает в SIMD-режиме.
Классификация Флинна не дает исчерпывающего описания разнообразных архитектур MIMD-машин, порой существенно отличающихся друг от друга. Например, существуют такие подклассы MIMD-компьютеров, как системы с разделяемой памятью и системы с распределенной памятью. Системы с разделяемой памятью могут относиться по классификации Флинна как к MIMD, так и к SIMD-машинам. То же самое можно сказать и о системах с распределенной памятью.
Развитием концепции MIMD-архитектуры с распределенной памятью является распределенная обработка, когда вместо набора процессоров в одном корпусе используются компьютеры, связанные достаточно быстрой сетью. Концептуального отличия от MIMD-архитектуры с распределенной памятью нет, а особенностью является медленное сетевое соединение.
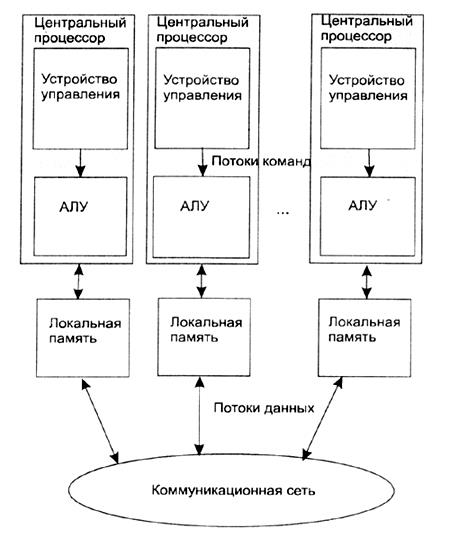
Рисунок 6 - Схема MIMD-компьютера с распределенной памятью
Традиционная архитектура фон Неймана. Традиционная фон-неймановская архитектура компьютера представлена на рис. 1.7. Она основана на следующих принципах:
- программа хранится в компьютере;
- программа во время выполнения и необходимые для ее работы данные находятся в оперативной (главной) памяти;
- имеется арифметико-логическое устройство, выполняющее арифметические и логические операции с данными;
- имеется устройство управления, которое интерпретирует команды, выбираемые из памяти, и выполняет их;
- устройства ввода и вывода (ВВ) используются для ввода программ и данных и для вывода результатов расчетов. Работают под управлением УУ.
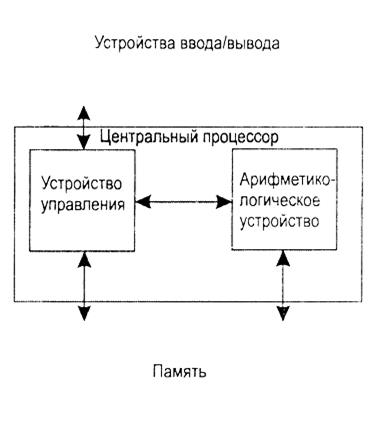
Рисунок 7 - Схема компьютера фон Неймана
Устройство управления и арифметико-логическое устройство (АЛУ) вместе составляют центральный процессор (ЦП). Можно считать, что все остальные функциональные блоки компьютера обслуживают АЛУ, а оно выполняет основную работу. Арифметические операции выполняются с целыми и вещественными числами, для представления которых используется двоичный формат. Для отрицательных значений применяется дополнительный код, что позволяет упростить реализацию арифметических и логических операций. Управляющее же устройство управляет работой остальных функциональных узлов компьютера.
В состав "традиционного" фон-неймановского компьютера входит один ЦП, основной задачей которого является выполнение машинных команд, выбираемых из оперативной памяти по очереди, одна за другой. Устройство управления интерпретирует очередную команду, которая входит в набор команд процессора, включающих арифметические и логические операции, операции пересылки данных и некоторые другие. Затем выполняется выборка данных, их обработка и запись результата выполнения в оперативную память. ЦП имеет набор регистров — устройств для временного хранения промежуточных результатов и данных, необходимых для выполнения команд (операндов).
Таким образом, основными компонентами компьютера являются:
- центральный процессор и оперативная память, образующие ядро системы;
- вторичная ("внешняя") память и устройства ввода/вывода, образующие "периферию";
- коммуникации между компонентами системы, осуществляемые посредством шин.
Лекция 7. О параллельной обработке данных
Цель лекции: Знакомство с проблемами повышения производительности компьютеров и методами параллельной обработки данных.
Содержание лекции: Проблема повышения производительности компьютеров. Параллельная обработка данных. Конвейерная обработка данных. Информационная зависимость и графы информационной зависимости.
Проблема повышения производительности компьютеров. В последние годы в повышении производительности компьютеров достигнуты колоссальные результаты. По закону Мура производительность обычного компьютера удваивается каждые полтора года. В качестве примера можно привести следующую информацию:
- на одном из первых компьютеров EDSAC (1949 год) можно было выполнять 2n арифметических операций за 18n миллисекунд, т.е. в среднем 100 арифметических операций в секунду (время такта 2 микросекунды);
- на одном узле современного суперкомпьютера HPSD (Hewlet-Packard Superdome) можно выполнять около 192 миллиардов арифметических операций в секунду (время такта приблизительно 1,3 нс, процессор PA-8700, 750 МГц).
Здесь возникает следующий вопрос: за счет чего достигнута такая производительность, которая составляет примерно два миллиарда раз, при увеличении тактового времени всего 1500 раз?
Ответ можно найти в использовании новых решений в архитектуре компьютеров, а также в использовании принципа параллельной обработки данных.
Для дальнейших изложений материалов данной лекции необходимо дать некоторые определения, которые часто будут использованы.
Команда, у которой все аргументы должны быть скалярными величинами, называется скалярной командой. Если хотя бы один аргумент команды может быть вектором, то такая команда называется векторной командой.
Любой программист начинает свою программистскую жизнь с создания последовательных программ. Последовательная модель программирования является традиционной. Но существуют и другие модели программирования. Одной из них является параллельная модель. Ее особенности, достоинства и связанные с ней проблемы обсуждаются в данной главе.
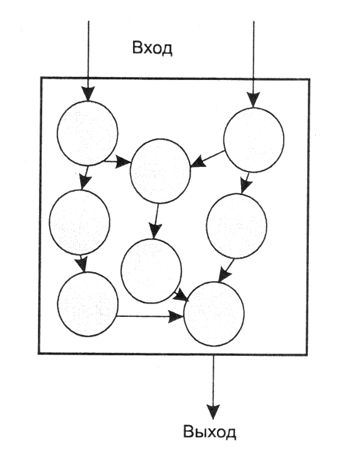
Рисунок 1 - Информационный граф алгоритма
Разработка параллельной программы для программиста, привыкшего к последовательной модели программирования, может оказаться на первых порах непростым делом. Ведь в этом случае придется задуматься не только о привычных вещах, таких как структуры данных, последовательность их обработки, интерфейсы, но и об обменах данными между подзадачами, входящими в состав параллельного приложения, об их согласованном выполнении и т. д. Однако, приобретя навык параллельного программирования, начинаешь понимать, что параллельное программирование — это... просто. Иногда написать параллельную программу для обработки массива данных оказывается проще, чем последовательную.
Последовательная и параллельная модели программирования. Совокупность приемов программирования, структур данных, отвечающих архитектуре гипотетического компьютера, предназначенного для выполнения определенного класса алгоритмов, называется моделью программирования. Напомним, что алгоритм — это конечный набор правил, расположенных в определенном логическом порядке и позволяющий исполнителю решать любую конкретную задачу из некоторого класса однотипных задач. Нижний уровень иерархии включает примитивные операции.
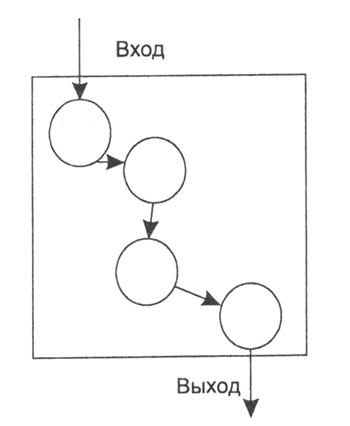
Рисунок 2 - Полностью последовательный алгоритм
Описание алгоритма является иерархическим, его сложность зависит от степени его детализации. На самом верхнем уровне иерархии находится задача в целом. Ее можно считать некоторой обобщенной операцией.
Алгоритм можно представить в виде диаграммы — информационного графа. Информационный граф описывает последовательность выполнения операций и взаимную зависимость между различными операциями или блоками операций. Узлами информационного графа являются операции, а однонаправленными дугами — каналы обмена данными (рисунок 1). Понятие операции может трактоваться расширенно. Это может быть оператор языка, но может быть и более крупный блок программы.
В информационном графе каждый узел задается парой (п, s), где п — имя узла, s — его размер. Размер узла определяется количеством простейших операций, входящих в его состав. Дуги характеризуются значениями (v, d), где v — пересылаемая переменная, a d — время, затрачиваемое на ее пересылку. Слияние нескольких узлов в один (упаковка узлов) уменьшает степень детализации алгоритма, но увеличивает количество дуг, выходящих из вершины графа. Упаковка позволяет скрыть несущественные на данном этапе разработки коммуникации и снизить затраты на их планирование.
На рисунках 2 и 3 представлены два предельных случая информационного графа. Первый из них соответствует последовательной, а второй — параллельной модели вычислений.
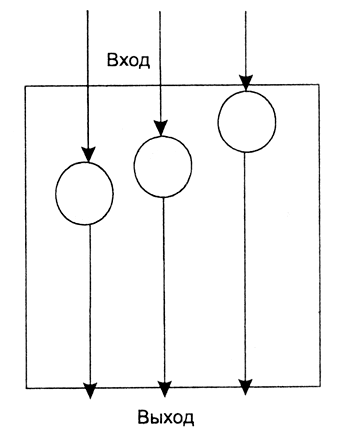
Рисунок 3 - Полностью параллельный алгоритм
Традиционной считается последовательная модель программирования. В этом случае в любой момент времени выполняется только одна операция и только над одним элементом данных. Последовательная модель универсальна. Ее основными чертами являются применение стандартных языков программирования (для решения вычислительных задач это, обычно, FORTRAN 90/95 и C/C++), хорошая переносимость программ и невысокая производительность.
Появление в середине шестидесятых годов прошлого столетия первого векторного компьютера, разработанного в фирме CDC знаменитым Сеймуром Креем, ознаменовало рождение новой архитектуры. Основная идея, положенная в ее основу, заключалась в распараллеливании процесса обработки данных, когда одна и та же операция применяется одновременно к массиву (вектору) значений. В этом случае можно надеяться на определенный выигрыш в скорости вычислений. Идея параллелизма оказалась плодотворной и нашла воплощение на разных уровнях функционирования компьютера . В настоящее время, строго говоря, уже нет исключительно последовательных архитектур; параллелизм применяется на разных уровнях, а с параллелизмом на уровне команд приходится сталкиваться любому пользователю современного персонального компьютера.
Основными особенностями модели параллельного программирования являются более высокая производительность программ, применение специальных приемов программирования и, как следствие, более высокая трудоемкость программирования, проблемы с переносимостью программ. Параллельная модель не обладает свойством универсальности.
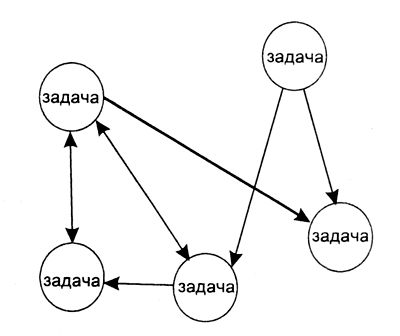
Рисунок 4 - Модель задача/канал
В параллельной модели программирования появляются проблемы, непривычные для программиста, привыкшего заниматься последовательным программированием. Среди них: управление работой множества процессоров, организация межпроцессорных пересылок данных и т. д. Можно сформулировать четыре фундаментальных требования к параллельным программам: параллелизм, масштабируемость, локальность и модульность.
В простейшей модели параллельного программирования, она называется моделью задача/канал (Рисунок 4), программа состоит из нескольких задач, связанных между собой каналами коммуникации и выполняющихся одновременно. Каждая задача состоит из последовательного кода и локальной памяти. Можно считать, что задача — это виртуальная фон-неймановская машина. Набор входных и выходных портов определяет ее интерфейс с окружением. Канал - это очередь сообщений-посылок с данными. Задача может поместить в очередь свое сообщение или, наоборот, удалить сообщение, приняв содержащиеся в нем данные.
Количество задач может меняться в процессе выполнения. Кроме считывания и записи данных в локальную память каждая задача может посылать и принимать сообщения, порождать новые задачи и завершать их выполнения.
Лекция 8. Понятие о параллельных вычислениях
Цель лекции: Знакомство с методами параллельной обработки данных и с возможностями параллельных вычислений.
Содержание лекции: Понятие о параллельной обработке данных и параллельных вычислениях. Конвейерная обработка данных. Понятие об информационной зависимости.
Параллельная обработка данных основана на идее одновременного выполнения нескольких действий. Она имеет две разновидности:
- конвейерная обработка данных;
- собственно параллельная обработка данных.
Параллельная обработка. Если некоторое устройство выполняет одну операцию за единицу времени, то тысячу операций оно выполняет за тысячу единиц времени. А если предположить, что имеется пять таких же независимо работающих устройств, то ту же тысячу операций система из пяти устройств может выполнить за двести единиц времени.
Примеров параллельной обработки можно найти в обычной жизни: множество кассовых аппаратов в супермаркете, несколько бензиновых колонок в автозаправочных станциях, многополосное движение по автотрассам, бригада зерноуборочных комбайнов и многих других.
Одним из первых, кто использовал параллельную обработку данных, был знаменитый ученый-математик Александр Андреевич Самарский. Для моделирования сложных процессов как ядерный взрыв он в 50-ые годы посадил несколько десятков человек с арифмометрами за столы. Каждый человек передавал данные друг другу просто на словах, и откладывали необходимые цифры на арифмометрах. С помощью такой вычислительной системы была рассчитана эволюция взрывной волны. Развитие процесса обработки во времени схематично изображено на следующем рисунке:
|
. . . a4 a3 a2 a1 → . . . b4 b3 b2 b1 → |
+ |
→ 0-й такт |
|
. . . a5 a4 a3 a2 → . . . b5 b4 b3 b2 → |
a1+b1 |
→ 1-й такт |
|
. . . a5 a4 a3 a2 → . . . b5 b4 b3 b2 → |
a1+b1 |
→ 2-й такт |
|
. . . a5 a4 a3 a2 → . . . b5 b4 b3 b2 → |
a1+b1 |
→ 3-й такт |
|
. . . a5 a4 a3 a2 → . . . b5 b4 b3 b2 → |
a1+b1 |
→ 4-й такт |
|
. . . a5 a4 a3 a2 → . . . b5 b4 b3 b2 → |
a1+b1 |
→ 5-й такт |
|
. . . a6 a5 a4 a3 → . . . b6 b5 b4 b3 → |
a2+b2 |
→ c1 6-й такт |
|
. . . a6 a5 a4 a3 → . . . b6 b5 b4 b3 → |
a2+b2 |
→ c1 7-й такт |
. . . . . . . . . . . . . . .
|
. . . a6 a5 a4 a3 → . . . b6 b5 b4 b3 → |
a2+b2 |
→ c1 10-й такт |
|
. . . a7 a6 a5 a4 → . . . b7 b6 b5 b4 → |
a3+b3 |
→ c2 c1 11-й такт |
. . . . . . . . . . . . . . .
Рисунок 4.1 – Суммирование векторов C=A+B с помощью последовательного устройства, выполняющего одну операцию за пять тактов
Конвейерная обработка. Пусть рассматривается сложение двух вещественных чисел. При этом выполняется множество операций:
- сравнение и выравнивание порядков;
- сложение мантисс;
- нормализация;
- сложение нормализованных чисел и т.д.
Обыкновенные компьютеры выполняют эти операции последовательно одна за другой до тех пор, пока не доходили до окончательного результата. Только после этого переходит к выполнению других операций.
Идея конвейерной обработки данных заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передает результат следующему, одновременно принимая новую порцию входных данных. Каждый этап называется ступенью конвейера, а общее количество ступеней называется длиной конвейера. Получается очевидный выигрыш в скорости обработки данных за счет совмещения прежде разнесенных во времени операций.
Пример. Допустим, что в операции можно выделить 5 микроопераций, каждая из которых выполняется за единицу времени. Если эти операции выполняется одним неделимым последовательным устройством, то 100 пар аргументов оно обрабатывает за 500 единиц времени. Если же каждую микрооперацию выделить в отдельный этап конвейерного устройства, то на пятой единице времени, на разной стадии обработки такого устройства будут находиться пять пар аргументов. Первый результат будет получен через 5 единиц времени, а каждый следующий результат через единицу времени после предыдущего. Тогда весь набор из 100 пар аргументов будет обработан за 5+99 =104 единицы времени. Отсюда видно, что время конвейерной обработки данных намного меньше, чем время обработки на последовательном устройстве. В данном примере почти 5 раз. Это зависит от количества ступеней, т.е. количества этапов конвейерного устройства.
Теперь пусть рассматривается общий случай. Пусть конвейерное устройство содержит m ступеней (этапов). Каждая ступень срабатывает за одну единицу времени. Тогда время обработки n независимых операций этим устройством составит n+m-1 единиц времени. Если это же устройство использовать в монопольном режиме, т.е. в последовательном режиме, то время обработки будет равно m x n. Сравнение этих величин показывает, что m x n больше n+m-1 почти m раз.
Теперь в качестве примера можно рассматривать процесс сложения двух одномерных массивов C=A+B, схематическое изображение которого показано в следующем рисунке:
|
. . . a4 a3 a2 a1 → . . . b4 b3 b2 b1 → |
|
|
|
|
|
→ 0-й такт |
|
. . . a5 a4 a3 a2 → . . . b5 b4 b3 b2 → |
a1b1 |
|
|
|
|
→ 1-й такт |
|
. . . a6 a5 a4 a3 → . . . b6 b5 b4 b3 → |
a2b2 |
a1b1 |
|
|
|
→ 2-й такт |
|
. . . a7 a6 a5 a4 → . . . b7 b6 b5 b4 → |
a3b3 |
a2b2 |
a1b1 |
|
|
→ 3-й такт |
|
. . . a8 a7 a6 a5 → . . . b8 b7 b6 b5 → |
a4b4 |
a3b3 |
a2b2 |
a1b1 |
|
→ 4-й такт |
|
. . . a9 a8 a7 a6 → . . . b9 b8 b7 b6 → |
a5b5 |
a4b4 |
a3b3 |
a2b2 |
a1b1 |
→ 5-й такт |
|
. . . a10 a9 a8 a7 → . . . b10 b9 b8 b7 → |
a6b6 |
a5b5 |
a4b4 |
a3b3 |
a2b2 |
→ c1 6-й такт |
|
. . . a11 a10 a9 a8 → . . . b11 b10 b9 b8 → |
a7b7 |
a6b6 |
a5b5 |
a4b4 |
a3b3 |
→ c2 c1 7-й такт |
|
. . . a12 a11 a10 a9 → . . . b12 b11 b10 b9 → |
a8b8 |
a7b7 |
a6b6 |
a5b5 |
a4b4 |
→ c3 c2 c1 8-й такт |
Рисунок 4.2 – Суммирование векторов C=A+B с помощью конвейерного устройства. Каждая из пяти ступеней конвейера срабатывает за один такт.
Сведения об информационной зависимости. Для того чтобы написать параллельную программу, необходимо выделить в ней группы операций, которые могут вычисляться одновременно и независимо разными процессорами, функциональными устройствами или же разными ступенями конвейера.
Возможность этого определяется наличием или отсутствием в программе истинных информационных зависимостей. Допустим, что под операцией считается либо отдельное срабатывание некоторого оператора, либо некоторые куски кода программы.
Две операции в программе называются информационно зависимыми, если результат выполнения одной операции используется в качестве аргумента другой операции. Это очевидно, что если какие-то результаты операции A используются в операции B, то операция B может выполнена только по завершении операции A. Если операции A и B не являются информационно независимыми, то алгоритмом не накладывается никаких ограничений на порядок их выполнения. Они могут быть выполнены одновременно. Таким образом, возникает возможность распараллеливания программы, для чего должны быть определены информационно независимые операции, распределение их между вычислительными устройствами, обеспечить синхронизацию и необходимых коммуникаций.
Как видно, что понятие информационной зависимости достаточно простое. Однако исследование всего набора информационных зависимостей, существующих в конкретной программе, является весьма сложной задачей. Например, программа состоит из десятка тысяч операторов. Здесь требуется учесть, что каждый цикл может состоять из большого количества итераций. Поэтому сложность данной задачи очевидна. Для того чтобы формализовать данную задачу и облегчить анализ, вводится понятие графов информационных зависимостей.
Некоторые сведения о графах. Среди дисциплин и методов дискретной математики теория графов и алгоритмы на графах находят наиболее широкое применение в программировании. Потому что теория графов представляет очень удобный язык для описания программных моделей. Стройная система специальных терминов и обозначений упрощает изложение теории и делает ее понятной, позволяет просто и доступно описывать сложные и тонкие понятия. Название «граф» подразумевает наличие графической интерпретации.
Основоположники теории графов ставили и решали следующие известные из школьной математики задачи, которые стали классическими. К ним относятся:
- задача о Кенигсбергских мостах;
- задача о трех домах и трех колодцах;
- задача о четырех красках.
Графом G(V,E) называется совокупность двух множеств: непустого множества V и множества E неупорядоченных пар различных элементов множества V. Множество V называется множеством вершин, множество E называется множеством ребер. Число вершин графа G обозначено p, а число ребер – q.
![]()
![]() 0; E
0; E![]() V x V, E = E-1; p:= p(G) := |V|; q:= q(G):= |E|.
V x V, E = E-1; p:= p(G) := |V|; q:= q(G):= |E|.
Граф изображается диаграммой: вершины точками или кружком, а ребра - линиями.
Когда рассматриваются программы, то вершинами в графах обычно являются некоторые операции программы. Если между двумя операциями существует информационная зависимость, то соответствующие этим операциям вершины соединяются направленной дугой, началом которой является вершина-поставщик информации, а концом является вершина-потребитель информации.
Для упрощения исследования графа зависимостей в нем выделяется подграф, имеющий минимальное число дуг при выполнении следующего условия: если две вершины графа зависимостей связаны путем, то они должны быть связаны путем и в выделенном подграфе, который называется минимальным графом зависимостей. С помощью минимальных графов зависимостей можно решать все те же задачи, которые можно решать и с помощью обычных графов зависимостей. Однако они намного проще и в большинстве случаев позволяют производить эффективный анализ структуры зависимостей программы.
Если вершинам графа соответствуют отдельные срабатывания операторов программы, то такой граф называется информационной историей выполнения программы. Информационная история содержит максимально подробную информацию о структуре информационных зависимостей анализируемой программы. Поэтому она используется при анализе программ с целью распараллеливания. Однако сложность анализа такова, что если в простых случаях можно построить и проанализировать получающийся граф вручную, то для больших реальных программ необходимы инструментальные программные средства.
Эффективность конвейерной обработки данных. Как и прежде, пусть конвейерное устройство состоит из m ступеней, срабатывающих за один такт. Два вектора из n элементов можно сложить одной векторной командой. либо выполнить подряд n скалярных команд сложения элементов этих векторов.
Если n скалярных команд одна за другой исполняется на таком устройстве, то они будут обработаны за m+n-1 тактов. На практике выдержать ритм, определяемый этой формулой, довольно сложно:
- каждый такт нужно обеспечивать новые входные данные;
- сохранять результат;
- проверять необходимость повторной итерации;
- увеличивать значения индексов и т.д.
В итоге, необходимость выполнения множества вспомогательных операций приводит к тому, что становится невозможным каждый такт подавать входные данные на вход конвейерного устройства. Все это приводит к снижению эффективности работы устройства.
Если
используется векторные команды, то в формулу добавляется еще одно слагаемое: n+m+![]() -1. Здесь
-1. Здесь ![]() - время, необходимое
для инициализации векторной команды. Это означает, что для небольших значений
n
соответствующие векторные команды выгоднее исполнять в обычном
скалярном режиме, чем в векторном режиме.
- время, необходимое
для инициализации векторной команды. Это означает, что для небольших значений
n
соответствующие векторные команды выгоднее исполнять в обычном
скалярном режиме, чем в векторном режиме.
![]()
![]()

![]()
![]() E
E
Eпик=1/![]() пиковая
производительность
пиковая
производительность
0 n
Рисунок 3 – Зависимость производительности конвейерного устройства от длины входного набора данных
Так
как ![]() и m не зависят от n, то с
увеличением длины входных векторов эффективность конвейерной обработки
увеличивается. Здесь под эффективностью понимают реальную производительность E конвейерного
устройства. Она равна отношению числа выполненных операций n к времени их
выполнения. Тогда зависимость производительности от длины входных векторов
определяется следующей формулой:
и m не зависят от n, то с
увеличением длины входных векторов эффективность конвейерной обработки
увеличивается. Здесь под эффективностью понимают реальную производительность E конвейерного
устройства. Она равна отношению числа выполненных операций n к времени их
выполнения. Тогда зависимость производительности от длины входных векторов
определяется следующей формулой:
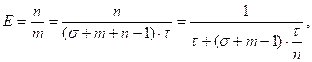
где
![]() время такта
работы компьютера.
время такта
работы компьютера.
Следует отметить, что пиковая производительность конвейерного устройства никогда недостижима на практике. Этот факт показан на рисунке 2.3, где значение производительности E растет из-за роста длины n входного набора данных, однако ее график асимптотически стремится к пиковой значения Eпик.
Лекция 9. Использование параллелизма
Цель лекции: Изучение разработки алгоритмов различных форм параллельных вычислений.
Содержание лекции: Ярусно-параллельная форма программы. Крупноблочное распараллеливание.
На прошлой лекции было введено понятие об информационной истории выполнения программы. Информационная история содержит максимально подробную информацию о структуре информационных зависимостей анализируемой программы.
Допустим, что каким-то образом удалось строить и исследовать информационную историю выполнения программы. Выделяют в ней множества информационно независимых операций, в результате возникает вопрос: каким же образом распределять эти множества между процессорами или другими обрабатывающими устройствами?
Ответ на этот вопрос будет следующим:
1. Выделяют в информационной истории те операции, которые зависят только от внешних данных программы. Будут считаться, что такие операции принадлежат первому ярусу информационной истории.
2. На второй ярус помещают операции, зависящие только от операций первого яруса и внешних данных.
Продолжая данное распределение операции информационной истории, таким образом, можно получить вид, который называется ярусно-параллельной формой программы. Количество ярусов данной формы называется длиной критического пути. Операции, попавшие на один ярус, не могут быть взаимно зависимыми, поэтому они выполняются одновременно.
Отсюда следует, что процесс получения параллельной программы может быть следующим:
1. Вначале операции первого яруса распределяются между процессорами.
2. После завершения их, операции второго яруса и т.д.
Поскольку любая операция n - го яруса зависит хотя бы от одной операции (n-1) – го яруса, то ее нельзя начать выполнять раньше, чем завершиться выполнение операций предыдущего яруса. Поэтому ярусно-параллельная форма представляет собой в определенном смысле максимально параллельную реализацию программы. При этом длина критического пути характеризует количество параллельных шагов, необходимых для ее выполнения.
Однако использование ярусно-параллельной формы связано с определенными трудностями. Причиной этого является то, что этот способ описания распараллеливания плохо согласован с конструкциями языков программирования и с архитектурными особенностями современных компьютеров. Поэтому на практике используются другие способы распараллеливания.
Крупноблочное распараллеливание. Самым простым вариантом распределения работ между процессорами является примерно следующая конструкция, называемая «крупноблочным распараллеливанием»:
if (MyProc ==0) {/*операции, выполняемые 0-ым процессором */}
. . .
if (MyProc ==k) {/*операции, выполняемые k-ым процессором */}
. . .
При этом предполагается, что каждый процессор должен иметь уникальный номер, который должен быть присвоен переменной MyProc и использовать в дальнейшем для получения участка кода для независимого исполнения. Таким образом, в приведенном примере операции в первых фигурных скобках будут выполнены только процессором с номером 0, операции во вторых фигурных скобках – процессором с номером k и т.д. При этом необходимо, чтобы одновременно разные процессоры могли выполнять только блоки информационно независимых операций, что может потребовать операций синхронизации процессоров. Кроме этого, при необходимости нужно обеспечивать обмен данными между процессорами.
Низкоуровневое распараллеливание. Однако не всегда удается выделить в программе достаточно большое число блоков независимых операций. Это означает, что при значительном числе процессоров в используемом компьютере, часть из них будет простаивать. Поэтому наряду с крупноблочным распараллеливанием используется способ низкоуровневого распараллеливания.
Из практики программирования известно, что наибольший ресурс параллелизма сосредоточен в циклах. Поэтому наиболее распространенным способом распараллеливания является то или иное распределение итераций циклов. Если между итерациями некоторого цикла нет информационных зависимостей, то их можно раздать разным процессорам для одновременного исполнения.
Условно это может быть выражено примерно следующей конструкцией:
for (i=0; i<N; i++) {
if (i – MyProc) {
/* операции i-ой итерации для выполнения процессором */
}
}
Здесь конструкция i-MyProc применена для того, чтобы номер итерации i каким-то образом соотносится с номером процессора MyProc. Конкретный способ задания этого соотношения определяет то, какие итерации цикла на какие процессоры будут распределяться. В принципе, можно раздать всем процессорам по одной итерации, а остальные итерации выполнить каким-то одним процессором. Тогда все процессоры после выполнения своих итераций будут простаивать, а один процессор будет работать. Это не эффективно. Поэтому одним из требований к распределению итераций является по возможности равномерная загрузка процессоров. Способы распределения итераций циклов в какой-то мере удовлетворяют этому требованию.
Блочно-циклическое распределение итераций. Распределение итераций цикла можно вести блоками последовательных итераций. Такое распределение называется блочным распределением. Пусть количество итераций равно N , а количество процессоров равно p. Количество итераций делится на число процессоров и число [N/p] будет количеством итераций в блоке. [N/p] – округление до ближайшего целого сверху. При этом все процессоры получают одинаковое количество итераций, однако некоторые процессоры будут простаивать.
Выбор меньшего размера блока может уменьшить этот дисбаланс. Однако при этом часть итераций останется нераспределенной. Если нераспределенные итерации снова распределять такими же блоками, начиная с первого процессора, то будет получено блочно-циклическое распределение итераций. Если уменьшать количество итераций дальше, то можно дойти до распределения по одной итерации. такое распределение называется циклическим распределением. Циклическое распределение уменьшает дисбаланс в загрузке процессоров, возникавший при блочных распределениях.
Пример. Пусть требуется распределить по процессорам итерации следующего цикла:
for (i=0; i<N; i++)
a[i] =a[i]+b[];
Пусть в компьютере имеется p процессоров с номерами 0 . . .p-1. Тогда блочное распределение итераций этого цикла можно записать следующим образом:
k = (n-1)/p +1; /* */
ibeg = MyProc * k; /* */
iend = (MyProc +1)*k-1; /* MyProc*/
if (ibeg>=N) iend = ibeg -1; /* */
else if (iend>=N) iend =N-1; /* */
for (i=ibeg; i<=iend; i++)
a[i] = a[i]+b[i];
Циклическое распределение итераций того же цикла можно записать так:
for (I = MyProc; i<N; i++)
a[i] = a[i] + b[i];
Следует заметить, что все соображения о распределении итераций циклов с целью достижения равномерности загрузки процессоров имеют смысл только в предположении, что распределяемые итерации приблизительно равноценны по времени исполнения. В некоторых случаях, например, при решении задач с треугольной матрицей, потребуется другие способы распределения.
Лекция 10. Проблема минимизации пересылок данных
Цель лекции: Изучение проблемы минимизации пересылок данных, распределение итераций в многомерных циклах.
Содержание лекции: Распределение итераций циклов. Анализ пространства итераций. Блочное распределение итераций. Блочно-циклическое распределение итераций.
Равномерная загрузка процессоров недостаточна для получения эффективной параллельной программы. Потому что бывает редко, когда в программе отсутствует информационная зависимость. Если же есть информационная зависимость между операциями, которые попадают на разные процессоры, то возникает проблема пересылки данных.
Пересылки данных требуют достаточное большое время для своего осуществления. Это связано созданием каналов связи между процессорами. Каналы связи могут увеличивать затрату времени на выполнения операций. Поэтому возникает задача о минимизации количества и объема необходимых пересылок данных. Например, при наличии информационных зависимостей между i - й и (i+1) -й итерациями некоторого цикла блочное распределение итераций может оказаться эффективнее циклического. Потому что при блочном распределении соседние итерации попадают на один процессор, а значит, потребуется меньшее количество пересылок, чем при циклическом распределении.
Анализ пространства итераций. В данной лекции до сих пор обсуждался вопрос о распределении итераций одномерных циклов. Однако в программах часто встречаются многомерные циклические гнезда. Каждый цикл такого гнезда может содержать некоторый ресурс параллелизма. Здесь вводится понятие пространство итераций. Пространством итераций гнезда тесновложенных циклов называют множество целочисленных векторов I, координаты которых задаются значениями параметров циклов данного гнезда. Задача распараллеливания при этом сводится к разбиению множества векторов на подмножества, которые выполняются последовательно друг за другом, но в рамках каждого такого подмножества итерации могут быть выполнены одномерно и независимо.
Среди методов анализа пространства итераций можно выделить несколько наиболее известных методов: методы гиперплоскостей, координат, параллелипипедов и пирамид.
Метод гиперплоскостей заключается в том, что пространство итераций размерности n разбивается на гиперплоскости размерности n-1 так, что все операции, соответствующие точкам одной гиперплоскости, могут выполняться одновременно и асинхронно.
Метод координат заключается в том, что пространство итераций фрагмента разбивается на гиперплоскости, ортогональные одной из координатных осей.
Метод параллелепипеда является логическим развитием двух предыдущих методов и заключается в разбиении пространства итераций на n -мерные параллелепипеды, объем которых определяет результирующее ускорение программы.
В методе пирамид выбираются итерации, вырабатывающие значения, которые далее в теле гнезда циклов не используются. Каждая такая итерация служит основанием отдельной параллельной ветви, в которую также входят все итерации, влияющие информационно на выбранную. При этом зачастую информация в разных вервях дублируется, что может привести к потере эффективности.
Пример. Пусть рассматривается следующий фрагмент программы:
for (i=1; i<N; i++)
for (j=1; j<M; j++)
a[i,j] = a[i-1,j]+a[i,j];
Пространство итераций данного фрагмента можно изобразить следующим образом:
![]() J
J
![]()
![]()
![]()
![]() M-1 * * * * . . .
*
M-1 * * * * . . .
*
. . . . . . . . . .
![]()
![]()
![]()
![]() 3 * * *
* . . . . . *
3 * * *
* . . . . . *
![]()
![]()
![]()
![]() 2 * * * * . . .
. *
2 * * * * . . .
. *
![]()
![]()
![]()
![]() 1 * * * *
. . . . *
1 * * * *
. . . . *
![]() I
I
0 1 2 3 4 N-1
Рисунок 5.1 – Пространство итераций фрагмента программы
На рисунке 6.1 звездочки соответствуют отдельным срабатываниям оператора присваивания, а стрелки показывают информационные зависимости. Отсюда видно, что разбиение пространства итераций по измерению I приведет к разрыву информационных зависимостей. Однако информационных зависимостей по измерению j нет. Поэтому возможно применение метода координат с разбиением пространства итераций гиперплоскостями, ортогональными оси j. Затем операции, попавшие в одну группу, распределяются для выполнения на один процессор целевого компьютера.
Пример. Пусть рассматривается немного усложненный вариант предыдущего примера:
for (i=1; i<N; i++)
for (j=1; j<M; j++)
a[i,j] = a[i-1,j]+a[i,j-1];
Пространство итераций данного фрагмента программы можно изобразить в следующем виде:
![]() J
J
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() M-1 * * *
* *
M-1 * * *
* *
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 3 * * * * *
3 * * * * *
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 2 * * * * *
2 * * * * *
![]()
![]()
![]()
![]() 1 * *
* * *
1 * *
* * *
![]()
0 1 2 3 4 N-1 I
Рисунок 2 – Пространство итераций фрагмента программы
Очевидно, что метод координат в этом случае неприменим, потому что любое разбиение как по измерению I , так и по измерению J приведет к разрыву информационных зависимостей. Если рассматривать гиперплоскости I+J = const, которые содержат вершины, между которыми нет информационных зависимостей. Это означает возможность применения метода гиперплоскостей, при котором осуществляется перебор плоскостей I+J = const. Для каждой из них соответствующие операции распределяются между процессорами целевого компьютера.
Пример. Теперь пусть рассматривается следующий пример:
for (i=1; i<N; i++) {
a[i] =a[i] + b[i];
c[i]= c[i-1] + b[i]; }
В данном цикле есть информационные зависимости между срабатыванием второго оператора из тела цикла на i -й и (i-1) -й итерациях. Поэтому нельзя просто раздать итерации исходного цикла для выполнения различным процессорам. Очевидно, что этот цикл можно разбить на два цикла, первый из которых станет параллельным:
for (i=1; i<N; i++)
a[i] = a[i] + b[i];
for (I =1; i<N; i++)
c[i] = c[i-1] +b[i];
}
Если переходить от распараллеливания отдельных циклических конструкций к распараллеливанию целой программы, то может оказаться невыгодным использовать весь найденный ресурс параллелизма, поскольку потребуется большое количество перераспределений данных между выполнением циклов.
В некоторых случаях можно добиться более эффективного распараллеливания программы при помощи эквивалентных преобразований – таких преобразований кода программы, при которых полностью сохраняется результат ее выполнения. Существует достаточно большое число подобных преобразований, полезных в различных случаях, например, перестановки циклов, охлопывание циклов, расщепление циклов и т.д.
Лекция 11. Технология параллельного программирования
Цель лекции: Изучение основных возможностей MPI – технологии.
Содержание лекции: Краткий обзор о технологиях параллельного программирования. Первоначальные сведения о технологии MPI.
Основное назначение параллельных компьютеров – это быстро решать задачи. Создание эффективных программ для таких компьютеров является особенно важной задачей. Здесь важную роль играет выбор технологии программирования. Технология может дать пользователю полный контроль над использованием ресурсов вычислительной системы и ходом выполнения его программы. Для этого ему предлагается набор из нескольких сот конструкций и функций, предназначенных на все случаи. Если правильно воспользоваться этими предложенными средствами, то можно создавать эффективную программу. Выбор технологии параллельного программирования достаточно серьезный вопрос. В настоящее время в мире существуют более 100 технологий.
Краткий обзор о технологиях параллельного программирования. Одновременно с совершенствованием архитектуры произошло развитие и программного обеспечения параллельных компьютеров. Практика показала, что развитие аппаратной и программной составляющих параллельных вычислительных систем нельзя рассматривать отдельно друг от друга. Изменение в одной из них влечет за собой изменение другой составляющей. В данной лекции будут рассматриваться вопросы, связанные с технологией параллельного программирования.
В настоящее время в арсенале программистов имеется достаточно большое количество систем программирования. Однако в настоящее время проблема разработки эффективного параллельного программного обеспечения оказалась центральной проблемой параллельных вычислений.
Перед пользователем возникает вопрос: как заставит несколько процессоров решать одну задачу? К настоящему времени появились различные технологии программирования. Пусть рассматриваются некоторые подходы, используемые в программном обеспечении параллельного программирования.
Одним из подходов является использование в традиционных языках программирования специальных комментариев. Эти комментарии добавляются в последовательные программы для выявления параллельную специфику. Допустим, что работа ведется на векторно-конвейерном компьютере. Пусть считается известным, что все итерации некоторого цикла программы независимы. Это значит, что его можно эффективно исполнить с помощью векторных команд на конвейерных функциональных устройствах. Обычно, если цикл простой, то компилятор сам может определить возможность преобразования последовательного кода в параллельный. Если нет уверенности, то перед заголовком цикла вставить явное указание на отсутствие зависимости и возможность векторизации.
На использование комментариев для получения параллельной программы, часто идут на расширение существующих языков программирования. Вводятся дополнительные операторы и новые элементы описания переменных, позволяющие пользователю явно задавать параллельную структуру программы и в некоторых случаях управлять исполнением параллельной программы. Примером может служить язык mpC, разработанный в Институте системного программирования РАН как расширение ANSI C. Основное назначение mpC – создание эффективных параллельных программ для неоднородных вычислительных систем.
С появлением массивно-параллельных компьютеров широкое распространение получили библиотеки и интерфейсы, поддерживающие взаимодействие параллельных процессов. Типичным представителем данного направления является интерфейс Message Passing Interface (MPI), реализация которого есть практически на каждой параллельной платформе, начиная от векторно-конвейерных супер-ЭВМ до кластеров и сетей персональных компьютеров. Программист сам явно определяет: какие параллельные процессы приложения в каком месте программы и с какими процессами должны либо обмениваться данными, либо синхронизировать свою работу. В частности, такой идеологии следуют MPI и PVM. В других технологиях допускается использование как локальных (private) переменных, так и общих (shared) переменных, доступных всем процессам приложения.
Несколько особняком стоит система LINDA, добавляющая в любой последовательный язык лишь четыре дополнительные функции: in, out, read, eval. Они позволяют создавать параллельные программы. Однако эта система не стала практическим инструментом.
Часто на практике программисты не используют никаких явных параллельных конструкций, обращаясь в критически по времени счета фрагментах к подпрограммам и функциям параллельных предметных библиотек. Весь параллелизм и вся оптимизация спрятаны в вызовах, а пользователю остается лишь написать внешнюю часть своей программы и воспользоваться стандартными блоками. В настоящее время существуют достаточно большое количество библиотек.
Последнее направление в использовании параллельного программирования – использование специализированных пакетов и программных комплексов. В этом случае пользователю не нужно заниматься программированием. Его основная задача – это правильно указать все необходимые входные данные и правильно воспользоваться функциональностью пакета. Например, химики для выполнения квантово-химических расчетов пользуются пакетом GAMESS. Они не думают о том, каким образом реализована параллельная обработка данных в самом пакете.
В заключение данного краткого обзора можно отметить, что большие изменения произошли в аппаратуре и программном обеспечении параллельных компьютеров за последние десятилетия. Эти изменения способствовали тому, что пользователи получили мощный вычислительный инструмент, способный решать совершенно неподъемные ранее вычислительные задачи.
Использование традиционных последовательных языков. Многие пользователи согласились бы следующим вариантом программирования, когда используются традиционные последовательные языки программирования. Потому что можно было бы сохранить уже созданные программные коды, программист продолжает мыслить в привычных для него терминах, а всю работу по адаптации к архитектуре параллельных компьютеров выполняет компилятор. Однако это не так просто.
Допустим, что ставится задача о получении эффективной программы для параллельного компьютера с распределенной памятью. Да, можно легко получить какой-нибудь исполняемый код, для чего скомпилировать программу для одного процессора. Тогда эта работа не имеет смысла, т.к. зачем использовать параллельный компьютер, если использовать только один процессор? Вопрос стоит об использовании потенциала параллельного компьютера. Чтобы полностью использовать потенциал данной архитектуры необходимо решать три основные задачи:
- найти в программе ветви, которые можно исполнять параллельно;
- распределить данные по модулям локальной памяти процессора;
- согласовать распределение данных с параллелизмом вычислений.
Если не решить первую задачу, то бессмысленно использовать многопроцессорны конфигурации компьютера. Если решена первая задача, но не решены вторая и третья задачи, то время работы программы полностью может уйти на обмен данными между процессорами. Отсюда следует, что эти задачи достаточно сложные.
Пример. Пусть рассматриваются параллельные компьютеры с общей памятью. Дан следующий фрагмент программы:
DO 10 i=1,n
DO 10 j=1,n
10 U(i+j)= U(2*n-i-j+1)*q+p
Какие итерации данной циклической конструкции являются независимыми, и можно ли этот фрагмент исполнять в параллельном режиме? Вопрос не простой, несмотря на маленький размер текста фрагмента.
Первоначальные сведения о технологии MPI. Наиболее распространенной технологией программирования параллельных компьютеров с распределенной памятью в настоящее время является MPI. Основным способом взаимодействия параллельных процессов в таких системах является передача сообщений друг другу. Стандарт MPI фиксирует интерфейс, который соблюдается системой программирования на каждой вычислительной системе и пользователем при создании своей программы. Современные реализации соответствует стандарту MPI версии 1.1. Была создана версия 2.0, однако она не получила распространение.
MPI – Message Passing Interface. Этот термин переводится как «Интерфейс передачи сообщений». Данная модель передачи сообщений является разновидностью параллельной модели программирования. Она отличается от фон-неймановской модели.
Она была разработана в 1993-1994 годах группой MPI Forum, в состав которой входили представители академических и промышленных кругов. Она стала первым стандартом систем передачи сообщений. В этих процессах могут выполняться разные программы, поэтому модель программирования MPI иногда называют MPMD-моделью. MPMD -Multiple Program Multiple Data - множество программ множество данных.
Технология MPI поддерживает работу с языками Си и Фортран. Полная версия интерфейса содержит описание более 120 функций. Интерфейс поддерживает создание параллельных программ в стиле объединения процессов с различными исходными текстами (стиль MIMD). Однако на практике чаще используется SPMD-модель, в рамках которой для всех параллельных процессов используется один и тот же код. В настоящее время MPI поддерживают работу с нитями.
Все дополнительные объекты: имена функций, константы, предопределенные типы данных и т.п., используемые в MPI, имеют префикс MPI_. Если пользователь не будет использовать в программе имен с таким префиксом, то конфликтов с объектами MPI заведомо не будет. Все описания интерфейса MPI собраны в файле mpi.h, поэтому в начале MPI - программы должна стоять директива #include <mpi.h>.
MPI – программа - это множество параллельных взаимодействующих процессов. Все процессы порождаются один раз, образуя параллельную часть программы. В ходе выполнения MPI – программы порождение дополнительных процессов или уничтожение существующих не допускается. Каждый процесс работает в своем адресном пространстве, никаких общих переменных или данных в MPI нет. Основным способом взаимодействия между процессами является явная посылка сообщений.
Для локализации взаимодействия параллельных процессов программы можно создавать группы процессов, предоставляя им отдельную среду для общения – коммуникатор. Состав образуемых групп произволен. Группы могут полностью входить одна в другую, не пересекаться или пересекаться частично. При старте программы считается, что все порожденные процессы работают в рамках всеобъемлющего коммуникатора, имеющего предопределенное имя MPI_COMM_WORLD.
Каждый процесс MPI – программы имеет уникальный атрибут – номер процесса, который является целым неотрицательным числом. С помощью этого атрибута происходит значительная часть взаимодействия процессов между собой. В одном коммуникаторе каждый процесс имеет собственный номер. Так как процесс может одновременно входить в разные коммуникаторы, поэтому его номер в одном коммуникаторе может отличаться от его номера в другом.
Отсюда становится понятным два основных атрибута процесса: коммуникатор и его номер в коммуникаторе. Если группа содержит n процессов, то номер любого процесса в данной группе лежит в пределах от 0 до n-1.
Основным способом общения процессов между собой является посылка сообщений. Сообщение – это набор данных некоторого типа. Каждое сообщение имеет несколько атрибутов, в частности, номер процесса-отправителя, номер процесса-получателя, идентификатор сообщения и другие. Одним из важных атрибутов сообщения является его идентификатор или тэг. По идентификатору процесс, принимающий сообщение, может различить два сообщения, пришедшие к нему от одного и того же процесса. Сам идентификатор сообщения является целым неотрицательным числом, лежащим в диапазоне от 0 до 32767. Для работы с атрибутами сообщений введена структура MPI_Status, поля которой дают доступ к их значениям.
Лекция 12. Общая характеристика модели
Цель лекции: Изучение модели передачи сообщений и функций, используемых в данной модели.
Содержание лекции: Понятие о параллельной программе. Общие функции MPI. Структура MPI-программы. Обсуждение модельной задачи.
В данной модели считается, что компьютер состоит из нескольких процессоров, каждый из которых снабжен своей собственной памятью. Процессор и его собственная память, т.е. компьютер, включенный в коммуникационную сеть, называется хост - машиной (host) .
Параллельная программа в такой модели представляет собой набор обычных последовательных программ, которые отрабатываются одновременно. Каждая из этих последовательных программ выполняется на своем процессоре и имеет доступ к своей, локальной, памяти. Эти части параллельной программы в процессе их выполнения называются подзадачами.
Для согласованной работы подзадачи должны обмениваться между собой информацией. Информация может быть разной; например, обрабатываемые данные или управляющие сигналы. Пересылка данных и сигналов происходит с помощью сообщений. Обмен информацией происходит через коммуникационную сеть. Пересылка сообщений реализуется с помощью вызова соответствующих подпрограмм из библиотеки передачи сообщений. Схема модели передачи сообщений представлена на рисунке 1.
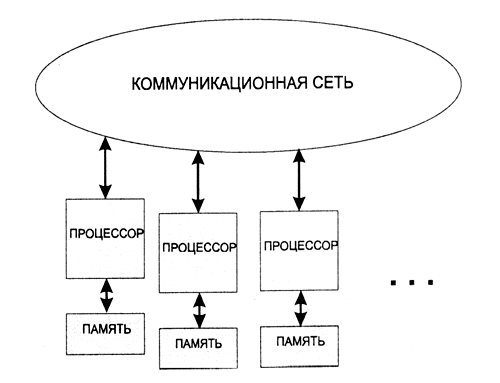
Рисунок 1 - Модель передачи сообщений
Модель передачи сообщений является универсальной. Она может быть реализована на параллельных вычислительных системах:
- с распределенной памятью;
- с разделяемой памятью;
на кластерах рабочих станций и на обычных однопроцессорных компьютерах. Такая универсальность этой модели является одной из основных причин ее популярности.
В случае, когда эта модель реализуется на обычном однопроцессорном компьютере, параллельная программа выполняется в режиме отладки.
Известно, что важнейшим из наиболее трудоемких этапов создания программы является разработка алгоритма. Процесс разработки алгоритма можно разбить на 4 этапа:
1. Декомпозиция
2. Проектирование коммуникаций между задачами
3.Укрупнение
4. Планирование вычислений.
На этапе декомпозиции исходная проблема разбивается на несколько частей (подзадач), каждая из которых может быть решена одним и тем же методом.
Общие функции MPI. Перед тем как переходить к описанию конкретных функций, необходимо сделать некоторые общие замечания. При описании функции используется слово out для обозначения входных параметров, через которые функция возвращает результат. Даже если результатом работы функции является одно число, оно будет возвращено через один из параметров. Связано это с тем, что практически все функции MPI возвращают в качестве своего значения информацию об успешности завершения. В случае успешного выполнения функция вернет значение MPI_SUCCESS, иначе – код ошибки. Вид ошибки, которая произошла при выполнении функции, можно будет понять из описания каждой функции.
Предопределенные возвращаемые значения, соответствующие различным ошибочным ситуациям, определены в файле mpi.h. В дальнейшем при описании конкретных функций, если ничего специально не сказано, то возвращаемое функцией значение будет подчиняться именно этому правилу.
В данной лекции будут рассмотрены общие функции MPI, необходимых практически в каждой программе.
Функция int MPI_Init(int *argc, char ***argv)
Инициализация параллельной части программы. Все другие функции MPI могут быть вызваны только после вызова MPI_Init. Необычный тип аргументов MPI_Init предусмотрен для того, чтобы иметь возможность передать всем процессам аргументы функции main. Инициализация параллельной части для каждого приложения выполняться один раз.
Функция MPI_Finalize(void)
Завершение параллельной части приложения. Все последующие обращения к любым MPI-функциям, в том числе к MPI_Init, завершены. К моменту вызова MPI_Finalize каждым процессом программы все действия, требующие его участия в обмене сообщениями, должны быть завершены.
Общая схема MPI – программы выглядит так:
Main(int argc, char **argv)
{
. . .
MPI_Init(&argc, &argv);
. . .
MPI_Finalize();
. . .
}
Функция int MPI_Comm_size(MPI_Comm сomm, int *size)
Здесь:
- comm – идентификатор коммуникатора;
- OUT size – число процессоров в коммуникаторе сomm.
Определение общего числа параллельных процессов в коммуникаторе сomm. Результат возвращается через параметр size, для чего функции передается адрес этой переменной. Поскольку коммуникатор является сложной структурой, перед ним стоит имя предопределенного типа MPI_Comm, определенного в файле mpi.h.
Функция int MPI_Comm_rank(MPI_Comm comm,int *rank)
Здесь:
comm – идентификатор коммуникатора;
OUT rank – номер процесса в коммуникаторе comm.
Определение номера процесса в коммуникаторе comm. Если функция MPI_Comm_size для того же коммуникатора comm вернула значение size, то значение, возвращаемое функцией MPI_Comm_rank через переменную rank, лежит в диапазоне от 0 до size-1.
Функция double MPI_Wtime(void)
Эта функция возвращает астрономическое время в секундах (вещественное число), прошедшее с некоторого момента в прошлом. Если некоторый участок программы окружить вызовами данной функции, то разность возвращаемых значений покажет время работы данного участка. Гарантируется, что момент времени, используемый в качестве точки отсчета, не будет изменен за время существования процесса. Заметим, что эта функция возвращает результат своей работы не через параметры, а явным образом.
Простейший пример программы, в которой использованы описанные выше функции:
Main(int argc, char **argv)
{
Int me,size;
. . .
MPI_Init(&argc, &argv);
Mpi_Comm_rank(MPI_COMM_WORLD, &me);
MPI_Comm_size(MPI_COMM_WORLD,&size);
Printf(“Process %d size %d\n”, me, size);
. . .
MPI_Finalize();
. . .
}
Строка, соответствующая функции Printf, будет выведена столько раз, сколько процессов было порождено при вызове MPI_Init. Порядок появления строк заранее не определен и может быть, вообще говоря, любым. Гарантируется только то, что содержимое отдельных строк не будет перемешано друг с другом.
Структура mpi-программы. Как устроена MPI-программа? В программе MPI должны быть соблюдены определенные правила, без которых она является неработоспособной. Прежде всего, в начале программы, сразу после ее заголовка, необходимо подключить соответствующий заголовочный файл. В программе на языке С это mpi.h:
#include “mpi.h”
В этом файле содержатся описания констант и переменных библиотеки MPI.
Первым вызовом библиотечной процедуры MPI в программе должен быть вызов подпрограммы инициализации MPI_Init, перед ним может располагаться только вызов MPI_Initialized, с помощью которого определяют, инициализирована ли система MPI. Вызов процедуры инициализации выполняется только один раз.
Параметры функции инициализации получают адреса аргументов главной программы, задаваемых при ее запуске:
MPI_Init(&argc, &argv);
Загрузчик mpirun в конец командной строки запуска MPI-программы добавляет служебные параметры, необходимые MPI_Init.
Процедура инициализации создает коммуникатор со стандартным именем MPI_COMM_WORLD. Это имя указывается во всех последующих вызовах процедур MPI.
После выполнения всех обменов сообщениями в программе должен располагаться вызов процедуры MPI_Finalize(ierr). В результате этого вызова удаляются структуры данных MPI и выполняются другие необходимые действия. Необходимо заботиться о том, чтобы к моменту вызова процедуры MPI_Finalize были завершены все пересылки данных. После выполнения данного вызова другие вызовы процедур MPI, включая MPI_Init, недопустимы. Исключение составляет подпрограмма MPI_Finalize, которая возвращает значение «истина», если процесс вызывал MPI_Init. Данный вызов может находиться в любом месте программы.
В тех частях программы, которые находятся до вызова MPI_Init и после вызова MPI_Finalize, не рекомендуется открывать файлы, выполнять считывание и запись в файлы стандартного ввода и вывода.
Выполнение всех процессов в коммуникаторе может быть прервано процедурой MPI_Abort. Если коммуникатор описывает область связи всех процессов программы, будет завершено выполнение программы. Данный вызов используется для аварийного останова программы при возникновении серьезных ошибок.
Пример простейшей MPI - программы на языке С:
#include “mpi.h”
#include <stdio.h>
int main(int argc,char *argv[])
{
int myid, numprocs;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
printf(stdout,”Process %d of %d\n”, myid, numprocs);
MPI_Finalize();
return 0;
}
Здесь использованы следующие подпрограммы MPI:
MPI_Init(&argc,&argv);
Аргументы процедуры задают количество аргументов командной строки запуска программы и вектор этих аргументов.
MPI_Finalize();
Завершение работы с MPI. После вызова данной подпрограммы нельзя вызывать подпрограммы MPI.
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
Определение размера области взаимодействия.
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
Определение номера процесса. Идентификатор процесса &myid.
Обсуждение модельной задачи. Теперь необходимо рассматривать порядок действий по написанию и оптимизации программы. Для этого рассматривается некоторая программа. Предлагается следующая последовательность действий:
- математическая постановка задачи, запись в виде формул;
- построение вычислительного алгоритма;
- создание и оптимизация последовательной программы;
- исследование ресурса параллелизма программы и выбор метода распараллеливания;
- написание «какой-то» параллельной программы с использованием любых технологий параллельного программирования;
- оптимизация параллельной структуры программы, выбор наиболее подходящих конструкций, возможно принятие другого решения по методу распараллеливания;
- дополнительная оптимизация программы, связанная, например, с экономией памяти или другими требованиями со стороны аппаратуры или программного обеспечения.
Лекция 13. Прием и передача сообщений между отдельными процессами
Цель лекции: Изучение способов приема-передачи сообщений между отдельными процессами при параллельном программировании.
Содержание лекции: Сообщения между отдельными процессами. Операции типа точка-точка. Прием/передача сообщений с блокировкой. Операции типа точка-точка.
Широкое распространение компьютеров с распределенной памятью определило и появление соответствующих систем программирования. Как правило, в таких системах отсутствует единое адресное пространство, и для обмена данными между параллельными процессами используется явная передача сообщений через коммуникационную среду. Отдельные процессы описываются с помощью традиционных языков программирования, а для организации их взаимодействия вводятся дополнительные функции. По этой причине практически все системы программирования, основанные на явной передаче сообщений, существуют не в виде новых языков, а в виде интерфейсов и библиотек.
К настоящему времени примеров известных систем программирования на основе передачи сообщений накопилось довольно много: Shmem, Linda, PVM, MPI и другие.
Наиболее распространенной технологией программирования параллельных компьютеров с распределенной памятью в настоящее время считается MPI. Выше было отмечено, что основным способом взаимодействия параллельных процессов в таких системах является передача сообщений друг другу. Это отражено в названии самой технологии – Message Passing Interface (Интерфейс передачи сообщений). Ранее мы отметили, что эта технология поддерживает работу с известными языками программирования Фортран и Си.
Интерфейс поддерживает создание параллельных программ в стиле MIMD, что подразумевает объединение процессов с различными исходными текстами. Однако на практике программисты чаще используют SPMD –модель, в рамках которой для всех параллельных процессов используется один и тот же код. В настоящее время все больше реализаций MPI поддерживают работу с нитями.
Все функции передачи сообщений в MPI делятся на две группы:
- индивидуальные операции или операции типа точка-точка;
- коллективные операции.
Операции типа точка-точка. На сегодняшней лекции будут рассматриваться вопросы, связанные с функциями передачи сообщений, относящие операциям точка-точка.
Функции, которые предназначены для взаимодействия двух процессов программы, называются операциями типа точка-точка или индивидуальными операциями. Все функции данной группы делятся на два класса:
- функции с блокировкой (с синхронизацией);
- функции без блокировки (асинхронные).
Прием/передача сообщений с блокировкой задаются конструкциями следующего вида:
int MPI_Send(void, *buf, int count, MPI_Datatype datataype, int dest, magtag, MPI_Comm comm)
Здесь:
buf – адрес начала буфера с посылаемым сообщением;
count - число передаваемых элементов в сообщении;
datatype – тип передаваемых элементов;
dest – номер процессора-получателя;
mаgtag – идентификатор сообщения;
comm – идентификатор коммуникатора;
Данная конструкция означает, что блокирующая посылка сообщения с идентификатором mаgtag, состоящего из count элементов типа datatypе, процессу dest. Все элементы посылаемого сообщения расположены подряд в буфере buf. Значение count может быть нулем. Разрешается передавать сообщение самому себе. Тип передаваемых элементов datatype должен указываться с помощью предопределенных констант типа. Например, MPI_INT, MPI_LONG, MPI_SHORT, MPI_LONG_DOUBLE, MPI_CHAR, MPI_UNSIGNED_CHAR, MPI_FLOAT и т.п. Для каждого типа данных языков Фортран и Си есть своя константа. Полный список предопределенных имен типов можно найти в файле mpi.h.
Блокировка гарантирует корректность повторного использования всех параметров после возврата из подпрограммы. Это означает, что после возврата из данной функции можно использовать любые присутствующие в вызове функции переменные без опасения испортить передаваемое сообщение. Выбор способа осуществления этой гарантии остается за разработчиками конкретной реализации MPI. Здесь возможны два варианта выбора:
- копирование в промежуточный буфер;
- непосредственная передача процессу dest.
Следует отметить, что возврат из функции MPI_Send не означает ни того, что сообщение получено процессом-получателем dest, ни того, что сообщение покинуло процессорный элемент, на котором выполняется процесс, выполнивший MPI_Send. Предоставляется только гарантия безопасного изменения переменных, использованных в вызове данной функции. Подобная неопределенность далеко не всегда устраивает пользователя. Чтобы расширить возможности передачи сообщений, в MPI введены дополнительные три функции: MPI_Bsend, MPI_Ssend, MPI_Rsend. Все параметры у этих функций такие же, как и у функции MPI_Send, однако у каждой из них есть своя особенность.
Функция MPI_Bsend – передача сообщения с буферизацией. Если прием посылаемого сообщения еще не был инициализирован процессом-получателем, то сообщение будет записано в буфер, и произойдет немедленный возврат из функции. Выполнение данной функции никак не зависит от соответствующего вызова функции приема сообщения. Тем не менее, функция может вернуть код ошибки, если места под буфер недостаточно.
Функция MPI_Ssend – передача сообщения с синхронизацией. Выход из данной функции произойдет только тогда, когда прием посылаемого сообщения будет инициализирован процессом-получателем. Таким образом, завершение передачи с синхронизацией говорит не только о возможности повторного использования буфера, но и о гарантированном достижении процессом-получателем точки приема сообщения в программе. Если прием сообщения так же выполняется с блокировкой, то функция MPI_Ssend сохраняет семантику блокирующих вызовов.
Функция MPI_Rsend – передача сообщения по готовности. Данной функцией можно пользоваться только в том случае, если процесс-получатель уже иницировал прием сообщения. В противном случае вызов функции, вообще говоря, является ошибочным и результат ее выполнения не определен. Во многих реализациях функция MPI_Rsend сокращает протокол взаимодействия между отправителем и получателем, уменьшая накладные расходы на организацию передачи.
Прием сообщения с идентификатором msgtag от процесса source с блокировкой задается следующей конструкцией:
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int magtag, MPI_Comm comm, MPI_Status *status)
Здесь:
- OUT buf - адрес начала буфера для приема сообщения;
- count – максимальное число элементов в принимаемом сообщении;
- datatype – тип элементов принимаемого сообщения;
- source – номер процесса-отправителя;
- msgtag – идентификатор принимаемого сообщения;
- comm – идентификатор коммуникатора;
- OUT status – параметры принятого сообщения.
Число элементов в принимаемом сообщении не должно превосходить значения count. Если число принятых элементов меньше значения count, то гарантируется, что в буфере buf изменяется только элементы, соответствующие элементам принятого сообщения. Если нужно узнать точное число элементов в принимаемом сообщении, то можно воспользоваться функциями MPI_Probe или MPI_Get_count. Блокировка гарантирует, что после возврата из функции все элементы сообщения уже будут приняты и расположены в буфере buf.
Пример программы. Пусть рассматривается пример, в котором нулевой процесс посылает сообщение процессу с номером один и ждет от него ответа. Если программа будет запущена с большим числом процессов, то реально выполнять пересылки все равно станут только нулевой и первый процессы. Остальные процессы после их порождения функцией MPI_Init сразу завершатся, выполнив функцию MPI_Finalize.
#include “mpi.h”
#include <stdio.h>
Int main (int argc, char **argv)
{
Int numtasks, rank, dest, src, rc,tag=1;
char inmsg, outmsg=’x’;
MPI_Status Stat;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
If(rank==0) {
dest = 1;
src = 1;
rc = MPI_Send(&outmsg, 1, MPI_CHAR, dest, tag, MPI_COMM_WORLD,&Stat);
}
else
if (rank = =1) {
dest = 0;
src = 0;
rc = MPI_Recv(&inmsg, 1, MPI_CHAR, src, tag,
MPI_COMM_WORLD, &Stat);
rc = MPI_Send(&outmsg, 1, MPI_CHAR, dest, tag,
MPI_COMM_WORLD);
}
MPI_Finalize();
}
Лекция 14. Прием/передача сообщений без блокировки
Цель лекции: Изучение способа приема- передачи сообщений без блокировки.
Содержание лекции: Способы приема-передачи сообщений между процессами без блокировки. Получение информации о структуре ожидаемого сообщения с блокировкой.
Пусть рассматривается пример программы; анализ данной программы с целью изучения способа приема-передачи сообщений между различными процессами.
Пример программы. В данном примере каждый процесс с четным номером посылает сообщение своему соседу с номером на единицу большим. Дополнительно поставлена проверка для процесса с максимальным номером, чтобы он не послал сообщение несуществующему процессу. Здесь показана только схема программы.
#include “mpi.h”
#include <stdio.h>
main(int argc, char **argv)
{
int me, size;
int SOME_TAG=0;
MPI_Status status;
. . .
MPI_Init (&argc, &argv);
MPI_Comm_rank (MPI_WORLD, &me);
MPI_C0mm_size (MPI_COMM_WORLD, &size);
if ((me % 2)==0) {
if ((me+1)<size) /* посылают все процессы, кроме последнего */
MPI_Send (. . ., m+1, SOME_TAG, MPI_COMM_WORLD);
}
else
MPI_Recn (…, me-1, SOME_TAG, MPI_COMM_WORLD, &status);
. . .
MPI_Finalize();
}
В качестве номера процесса-отправителя можно указать предопределенную константу MPI_ANY_SOURCE - признак того, что подходит сообщение от любого процесса. В качестве идентификатора принимаемого сообщения можно указать константу MPI_ANY_TAG - это признак того, что подходит сообщение с любым идентификатором. При определенном использовании этих двух констант будет принято любое сообщение от любого процесса.
Параметры принятого сообщения всегда можно определить по соответствующим полям структуры status. Предопределенный тип MPI_Status описан в файле mpi.h. В языке Си параметр status является структурой, содержащей поля с именами MPI_SOURCE, MPI_TAG, MPI_ERROR. Реальные значения номера процесса-отправителя, идентификатора сообщения и кода ошибки доступны через status. MPI_SOURCE, status. MPI_TAG и status. MPU_ERROR. В фортране параметр status является целочисленным массивом размера MPI_STATUS_SIZE. Константы MPI_SOURCE, MPI_TAG, MPI_ERROR являются индексами по данному массиву для доступа к значениям соответствующих полей, например, status(MPI_SOURCE).
Следует обратить внимание на некоторую несимметричность операций посылки и приема сообщений. С помощью константы MPI_ANY_SOURCE можно принять сообщение от любого процесса. Однако в случае посылки данных требуется явно указать номер принимающего процесса.
В стандарте оговорено, что если один процесс последовательно посылает два сообщения другому процессу, и оба эти сообщения соответствуют одному и тому же вызову MPI_Recv, то первым будет принято сообщение, которое было отправлено раньше. Вместе с тем, если два сообщения были одновременно отправлены разными процессами, и оба сообщения соответствуют одному и тому же вызову MPI_Recv, то порядок их получения принимающим процессом заранее не определен.
Последнее замечание относительно использования блокирующих функций приема и посылки связано с возможным возникновением тупиковой ситуации. Предположим, что работают два параллельных процесса и они хотят обменяться данными. Было бы вполне естественно в каждом процессе сначала воспользоваться функцией MPI_Send, а затем MPI_Recv. Но именно этого и не стоит делать. Дело в том, что мы заранее не знаем, как реализована функция MPI_Send. Если разработчики для гарантии корректного повторного использования буфера посылки заложили схему, при которой посылающий процесс ждет начала приема, то возникнет классический тупик, первый процесс не может вернуться из функции посылки, поскольку второй не начинает прием сообщения.
А второй процесс не может начать прием сообщения, поскольку сам по похожей причине застрял на посылке. Выход из этой ситуации прост. Нужно использовать либо неблокирующие функции приема/передачи, либо функцию совмещенной передачи и приема. Оба варианта будут обсуждены.
int MPI_Get_count(MPI_Status *status, MPI_Dattype datatype, int *count)
Здесь:
- status –параметры принятого сообщения;
- datatype – тип элементов принятого сообщения;
- OUT count – число элементов сообщения.
По значению параметра status данная функция определяет число уже принятых (после обращения к MPI_Recv) или принимаемых (после обращения к MPI_Probe или MPI_Iprobe) элементов сообщения типа datatype. Данная функция, в частности, необходима для определения размера области памяти, выделяемой для хранения принимаемого сообщения.
Получение информации о структуре ожидаемого сообщения с блокировкой
int MPI_PROBE (int source, int msgtag, MPI_Comm comm, MPI_Status *status)
Здесь:
- source – номер процесса-отправителя или MPI_ANY_SOURCE;
- msgtag - идентификатор ожидаемого сообщения или MPI_ANY_TAG;
- comm – идентификатор коммуникатора;
- OUT status – параметр найденного подходящего сообщения.
Возврата из функции не произойдет до тех пор, пока сообщение с подходящим идентификатором и номером процесса-отправителя не будет доступно для получения. Атрибуты доступного сообщения можно определить обычным образом с помощью параметра status. Следует особо обратить внимание на то, что функция определяет только факт прихода сообщения, но реально его не принимает.
Прием/передача сообщений без блокировки. В отличие от функций с блокировкой, возврат из функций данной группы происходит сразу без какой-либо блокировки процессов. На фоне дальнейшего выполнения программы одновременно происходит и обработка асинхронно запущенной операции. В принципе, данная возможность исключительно полезна для создания эффективных программ. В самом деле, программист знает, что в некоторый момент ему потребуется массив, который вычисляет другой процесс. Он заранее выставляет в программе асинхронный запрос на получение данного массива, а до того момента, когда массив реально потребуется, он может выполнять любую другую полезную работу. Опять же, во многих случаях совершенно не обязательно дожидаться окончания посылки сообщения для выполнения последующих вычислений.
Если есть возможность операции приема/передача сообщений скрыть на фоне вычислений, то этим, вроде бы, надо безоговорочно пользоваться. Однако на практике не все согласуется теорией. Многое зависит от конкретной реализации. К сожалению, далеко не всегда асинхронные операции эффективно поддерживаются аппаратурой и системным окружением.
Поэтому не стоит удивляться, если эффект от выполнения вычислений на фоне пересылок окажется нулевым. Сделанные замечания касаются только вопросов эффективности. В отношении предоставляемой функциональности асинхронные операции исключительно полезно, поэтому они присутствуют практически в каждой реальной программе.
int MPI_Isend(void *buf, int count, MPI_Datatype datatype, int dest, int msgtag, MPI_Comm comm., MPI_Request *request)
- buf – адрес начала буфера с посылаемым сообщением;
- count – число передаваемых элементов;
- datatype - тип передаваемых элементов;
- dest - номер процесса-получателя;
- msgtag – идентификатор сообщения;
- comm - идентификатор коммуникатора;
- OUT request – идентификатор асинхронной операции.
Передача сообщения аналогична вызову MPI_send, однако возврат из функции MPI_Isend происходит сразу после инициализации процесса передачи без ожидания обработки всего сообщения, находящегося в буфере buf. Это означает, что нельзя повторно использовать данный буфер для других целей без получения дополнительной информации, подтверждающей завершение данной посылки. определить тот момент времени, когда можно повторно использовать буфер buf без опасения испортить передаваемое сообщение, можно с помощью параметра request и функций MPI_Wait и MPI_Test.
Аналогично трем модификациям функции MPI_send, предусмотрены три дополнительных варианта функций MPI_Ibsend, MPI_Issend, MPI_Irsend. К изложенной выше семантике работы этих функций добавляется асинхронность.
Лекция 15. Программы, используемые для приема/передачи сообщений
Цель лекции: Обсуждение и анализ программ, которые используются для приема/передачи сообщений.
Содержание лекции: Примеры программ, используемых для приема/передачи сообщений.
Пример программы 1. Пусть рассматривается пример, в котором нулевой процесс посылает сообщение процессу с номером один и ждет от него ответа. Если программа будет запущена с большим числом процессов, то реально выполнять пересылки все равно станут только нулевой и первый процессы. Остальные процессы после их порождения функцией MPI_Init сразу завершатся, выполнив функцию MPI_Finalize.
#include “mpi.h”
#include <stdio.h>
Int main (int argc, char **argv)
{
Int numtasks, rank, dest, src, rc,tag=1;
char inmsg, outmsg=’x’;
MPI_Status Stat;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
If(rank==0) {
dest = 1;
src = 1;
rc = MPI_Send(&outmsg, 1, MPI_CHAR, dest, tag, MPI_COMM_WORLD,&Stat);
}
else
if (rank = =1) {
dest = 0;
src = 0;
rc = MPI_Recv(&inmsg, 1, MPI_CHAR, src, tag,
MPI_COMM_WORLD, &Stat);
rc = MPI_Send(&outmsg, 1, MPI_CHAR, dest, tag,
MPI_COMM_WORLD);
}
MPI_Finalize();
}
Пример программы 2. В данном примере каждый процесс с четным номером посылает сообщение своему соседу с номером на единицу большим. Дополнительно поставлена проверка для процесса с максимальным номером, чтобы он не послал сообщение несуществующему процессу. Здесь показана только схема программы.
#include “mpi.h”
#include <stdio.h>
main(int argc, char **argv)
{
int me, size;
int SOME_TAG=0;
MPI_Status status;
. . .
MPI_Init (&argc, &argv);
MPI_Comm_rank (MPI_WORLD, &me);
MPI_C0mm_size (MPI_COMM_WORLD, &size);
if ((me % 2)==0) {
if ((me+1)<size) /* посылают все процессы, кроме последнего */
MPI_Send (. . ., m+1, SOME_TAG, MPI_COMM_WORLD);
}
else
MPI_Recn (…, me-1, SOME_TAG, MPI_COMM_WORLD, &status);
. . .
MPI_Finalize();
}
В качестве номера процесса-отправителя можно указать предопределенную константу MPI_ANY_SOURCE - признак того, что подходит сообщение от любого процесса. В качестве идентификатора принимаемого сообщения можно указать константу MPI_ANY_TAG - это признак того, что подходит сообщение с любым идентификатором. При определенном использовании этих двух констант будет принято любое сообщение от любого процесса.
Пример программы 3. В программе все процессы обмениваются сообщениями с ближайшими соседями в соответствии с топологией кольца.
#include “mpi.h”
#include <stdio.h>
int main (int argc, char **argv)
{
int numtasks, rank, next, prev, buf[2[, tag1=1, tag2=2;
MPI_Request reqs [4];
MPI_Status [4];
MPI_Init (&argc, &argv);
MPI_Comm_size (MPI_COMM_WORLD, &numtasks);
MPI_Comm_rank (MPI_COMM_WORLD, &rank);
prev = rank – 1;
next = rank + 1;
if (rank == 0) prev = numtasks – 1;
if (rank == (numtasks – 1)) next = 0;
MPI_Irecv (&buf[0], 1, MPI_INT, prev, tag1, MPI_COMM_WORLD, &reqs);
MPI_Irecv(&buf[1], 1, MPI_INT, next? tag2, MPI_COMM_WORLD, &reqs [1]);
MPI_Isend (&rank, 1, MPI_INT, prev, tag2, MPI_COMM_WORLD, &reqs[2]);
MPI_Isend(&rank,1 MPI_INT, next, tag1, MPI_COMM_WORLD, &reqs[3]);
MPI_Waitall (4, reqs, stats );
MPI_Finalize();
}
Лекция 16. Внутренний параллелизм в алгоритме произведения двух квадратных матриц
Цель лекции: Анализ внутреннего параллелизма в конкретном примере для изучения процесса организации параллельных вычислений.
Содержание лекции: Понятие о внутреннем параллелизме. Достоинство и недостатки. Графы алгоритма. Входные и выходные графы.
Первый вопрос, который касается применению компьютеров, имеющих возможности параллельных вычислений, является следующий: как обстоит дела на вычислительных системах параллельной архитектуры?
Понятие о внутреннем параллелизме. В процессе длительного использования последовательных компьютеров был накоплен и тщательно отработан огромный багаж численных методов и программ. Появление параллельных компьютеров вроде бы должно было привести к созданию новых методов. Однако этого не произошло. Попытка разработать новые специальные параллельные методы, в частности, методы малой высоты, оказалась на практике не состоятельной.
Очевидно, возникает вопрос: как же тогда решать задачи на параллельных компьютерах и можно ли на этих компьютерах использовать старый алгоритмический и программный багаж?
Ответ был найден простым по форме, но не совсем простым по реализации. Мы с вами рассматривали примеры подхода к решению этой проблемы, который заключается в следующем: возьмем любой алгоритм, записанный в виде математических соотношений, последовательных программ или еще каким-либо способом. Допустим, что для него удалось построить граф алгоритма и предположим, что для этого графа обнаружена параллельная форма с достаточной шириной ярусов. Тогда этот алгоритм в принципе можно реализовать на параллельном компьютере.
Здесь должно быть выполнено следующее утверждение: пусть при выполнении операции ошибки округления определяются только значениями аргументов. Тогда при одних и тех же входных данных все реализации алгоритма, соответствующие одномк и тому же частичному порядку на операциях, дают один и тот же результат, включая всю совокупность ошибок округления.
Поэтому очень важно, согласно этому утверждению параллельная реализация алгоритма будет иметь такие же вычислительные свойства, как и любая другая. Если исходный алгоритм был численно устойчив, то он останется таким же и в параллельной форме. Подобный параллелизм называется внутренним.
Оказалось, что в старых, давно используемых и хорошо отработанных алгоритмах довольно часто удается хороший запас внутреннего параллелизма.
Использовать внутреннего параллелизма имеет очевидное достоинство, т.к. не нужно тратить дополнительные усилия на изучение вычислительных свойств вновь создаваемых алгоритмов. Недостатки также очевидны из-за необходимости определять и исследовать графы алгоритмов.
В тех случаях, когда внутреннего параллелизма какого-либо алгоритма недостаточно для эффективного использования конкретного параллельного компьютера, приходится заменять его другим алгоритмом, имеющим лучшие свойства параллелизма. Известно, что для многих задач уже разработано большое количество различных алгоритмов. Поэтому подобрать подходящий алгоритм в принципе возможно. Однако осуществить этот выбор не так просто, т.к. нужно знать параллельную структуру алгоритма. Она как раз не известна. Поэтому является актуальными сведения о параллельных свойствах алгоритмов, а также знания, позволяющие эти сведения получать.
Приведем некоторые понятия, связанные с построением графа алгоритма. В отличие от обыкновенного компьютера, в параллельных компьютерах в каждый момент времени может выполняться целый ансамбль операций, не зависящих друг от друга.
Пусть при фиксированных входных данных программа описывает некоторый алгоритм. Построим ориентированный граф. В качестве вершин графа возьмем любое множество точек арифметического пространства, на которое взаимно-однозначно отображается множество всех операций алгоритма.
Возьмем любую пару вершин u, v. Допустим, что
вершине u должна
поставлять аргумент операции, соответствующей вершине v. Тогда проведем
дугу из вершины u в вершину v. Если они
выполняются независимо друг от друга, то дугу проводить не будем. Построенный
таким образом граф называется графом алгоритма. Независимо от способа
построения ориентированного графа, те его вершины, которые не имеют ни одной
входящей или выходящей дуги, будем называть соответственно входными или выходными
вершинами графа. Для обозначения графа используется стандартная символика ![]() где
где ![]() множество вершин,
множество вершин, ![]() множеств дуг
графа G.
множеств дуг
графа G.
Пусть задан ориентированный
ациклический граф, имеющий вершин. Существует число для которого все
вершины графа можно так пометить одним из индексов, что если дуга из вершины с
индексом i идет в вершину
с индексом j, то![]() Граф, размеченный в соответствии с этим
утверждением, называется строгой параллельной формой графа. Если в
параллельной форме некоторая вершина помечена индексом k, то это
означает, что длина всех путей, оканчивающихся в данной вершине, меньше k.
Граф, размеченный в соответствии с этим
утверждением, называется строгой параллельной формой графа. Если в
параллельной форме некоторая вершина помечена индексом k, то это
означает, что длина всех путей, оканчивающихся в данной вершине, меньше k.
Существует строгая параллельная форма, при которой максимальная из длин путей оканчивающихся в данной вершине с индексом k, равна k-1. Для этой параллельной формы число используемых индексов на 1 больше длины критического пути графа.
Среди подобных параллельных форм существует такая форма, в которой все входные вершины находятся в группе с одним индексом, равным 1. Эта строгая параллельная форма называется канонической. Для заданного графа его каноническая параллельная форма является единственной.
Группа вершин, имеющие одинаковые индексы, называется ярусом параллельной формы. Число вершин в группе называется шириной яруса. Число ярусов в параллельной форме называется высотой параллельной формы. Максимальная ширина ярусов называется шириной параллельной формы.
Если алгоритм реализуется на обыкновенном (последовательном) компьютере, то этому соответствует параллельная форма, в которой все ярусы имеют ширину, равную 1. В таком случае параллельная форма называется линейной и говорят, что граф упорядочен линейно.
Ярусы параллельной формы можно строить следующим образом. В первый ярус объединяют максимальное число вершин, не имеющих входящих дуг и соответствующих операциям с непустым пересечением временных интервалов их выполнения. Эти вершины заведомо не связаны друг с другом какими-либо дугами.
Зная граф алгоритма и его параллельные формы, можно понять, каков запас параллелизма в алгоритме и как его лучше реализовать на компьютере параллельной архитектуры.
Приведем следующее утверждение. Для канонической параллельной формы алгоритма операции любого яруса не зависят друг от друга. Аргументами первого яруса являются только входные данные. Они не зависят от времени выполнения операций. Аргументами операций 2-го яруса являются либо входные данные, либо результаты выполнения операций 1-го яруса.
Пусть рассматривается пример. В качестве примера рассматривается произведение двух квадратных матриц
![]() ,
,
где
![]()
Формула для определения операции умножения матриц будет иметь следующий вид:
![]() (1)
(1)
Эти
формулы часто используются для вычисления элементов матрицы А. Сами по себе
они (1) не определяют алгоритм однозначно, потому что не определен порядок
суммирования. Следует заметить, что явно виден параллелизм вычислений. Это выражается
отсутствием указания о соблюдении какого-либо порядка перебора индексов ![]()
Если операции сложения и умножения чисел выполняются точно, то все порядки суммирования в формуле (1) эквивалентны и приводят к одному и тому же результату.
Пусть выбран следующий алгоритм:
![]() (2)
(2)
Здесь
явно указан параллелизм перебора индексов ![]() Однако по индексу
Однако по индексу ![]() параллелизма нет, т.к. индекс
должен перебираться последовательно от 1 до
параллелизма нет, т.к. индекс
должен перебираться последовательно от 1 до ![]() Это следует из второй формулы (2).
Это следует из второй формулы (2).
Теперь
нужно построить граф алгоритма (2). Будем считать, что вершины графа
соответствуют операциям ![]() где
где ![]() элементы того же кольца, которому
принадлежат элементы матриц
элементы того же кольца, которому
принадлежат элементы матриц ![]() . Для наглядности их можно рассматривать
ка числа, хотя ничто не мешает им быть, например, квадратными матрицами
одного порядка. При построении графа природу элементов
. Для наглядности их можно рассматривать
ка числа, хотя ничто не мешает им быть, например, квадратными матрицами
одного порядка. При построении графа природу элементов ![]() не будем учитывать.
не будем учитывать.
Не
будем также сначала показывать в графе вершины и инцидентные им дуги,
связанные с вводом элементов матриц ![]() и с присвоением элементам матрицы А
вычисленных значений
и с присвоением элементам матрицы А
вычисленных значений ![]() .
Чтобы не вносить в исследование графа алгоритм неоправданные дополнительные
трудности, вершины графа нельзя располагать произвольно. Приемлемый способ их
расположения подсказывает сама форма записи (2).
.
Чтобы не вносить в исследование графа алгоритм неоправданные дополнительные
трудности, вершины графа нельзя располагать произвольно. Приемлемый способ их
расположения подсказывает сама форма записи (2).
Рассмотрим
прямоугольную решетку в трехмерном пространстве с координатами ![]() Во все целочисленные
узлы решетки для
Во все целочисленные
узлы решетки для ![]() поместим
вершины графа. Из (2) следует, что в вершину с координатами
поместим
вершины графа. Из (2) следует, что в вершину с координатами ![]() для
для ![]() будет передаваться результат
выполнения операции, соответствующей вершине с координатами
будет передаваться результат
выполнения операции, соответствующей вершине с координатами ![]()
Граф
алгоритма устроен достаточно просто. Он распадается на ![]() не связанных между собой
подграфов. Каждый подграф содержит
не связанных между собой
подграфов. Каждый подграф содержит ![]() вершин и представляет один путь,
расположенный параллельно оси
вершин и представляет один путь,
расположенный параллельно оси ![]() . Как и следовало ожидать, в графе
отражен тот же параллелизм, который был указан явно в записях (1) и (2).
. Как и следовало ожидать, в графе
отражен тот же параллелизм, который был указан явно в записях (1) и (2).
Для
частного случая, когда ![]() , граф алгоритма имеет следующий вид:
, граф алгоритма имеет следующий вид:
![]()
![]() ● ●
● ●
![]()
![]()
![]() i
● ●
i
● ●
![]()
![]()
![]() j
j
k ● ●
● ●
Рисунок
1 – Граф алгоритма для ![]()
В
полном графе имеется множественная рассылка данных. Элемент ![]() рассылается по всем
вершинам, имеющим те же самые значения координат
рассылается по всем
вершинам, имеющим те же самые значения координат ![]() .
.
Элемент
![]() рассылается
по всем вершинам, имеющим те же самые координаты
рассылается
по всем вершинам, имеющим те же самые координаты ![]() . Для частного
случая, когда
. Для частного
случая, когда ![]() ,
рассылки имеют следующий вид:
,
рассылки имеют следующий вид:
![]() i
i
![]()
![]() j
j
![]()
![]() ●
●
![]()
![]()
![]()
 ●
●
●
●
![]()
![]() ●
●
![]()
![]()
![]()
![]() ● ●
● ●
● ●
![]()
![]() ●
●
![]()
![]() ● ●
● ●
![]()
![]() ●
●
![]()
![]() ● ●
● ●
● ●
Рисунок
2 – Рассылки данных для случая ![]()
Все
вершины соответствуют операциям вида ![]() . Однако при
. Однако при ![]() они выполняются несколько иначе, чем при
они выполняются несколько иначе, чем при ![]()
Именно,
в этих случаях аргумент а не является результатом какой-либо операции,
а всегда полагается равным 0. Ничто не мешает 0 считать входным данным
алгоритма и рассылать его по всем вершинам при ![]()
Здесь
многое зависит от правильного выбора способа расположения вершин графа
алгоритма. Если расположить вершины на прямой линии, без какой-либо связи с
индексами ![]() из (2), то
вряд ли в таком графе удалось бы разглядеть параллелизм. При выбранном
расположении вершин параллелизм очевиден. Более того, легко описать любой ярус
любой параллельной формы. Это есть множество вершин, не содержащее при
фиксированном
из (2), то
вряд ли в таком графе удалось бы разглядеть параллелизм. При выбранном
расположении вершин параллелизм очевиден. Более того, легко описать любой ярус
любой параллельной формы. Это есть множество вершин, не содержащее при
фиксированном ![]() более
одной вершины.
более
одной вершины.
Ярусы
канонической параллельной формы представляют множество вершин, лежащих на
гиперплоскости ![]() Поэтому
вполне естественно ожидать, что нам придется связывать способ расположения
вершин с системой индексов, используемых в записи алгоритма.
Поэтому
вполне естественно ожидать, что нам придется связывать способ расположения
вершин с системой индексов, используемых в записи алгоритма.
Но этот труднее разместить в трехмерном пространстве. Записать суммирование по принципу сдваивания, используя один индекс, значительно сложнее. Следует заметить, что если суммирование (1) выполнять по схеме сдваивания, то граф алгоритма станет совсем другим. Именно, каждый путь в графе должен быть заменой на следующего графа:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() ●
● ● ● ● ●
● ●
●
● ● ● ● ●
● ●
![]()
![]()
![]()
![]() ● ● ●
●
● ● ●
●
![]()
![]() ● ●
● ●
●
Рисунок 3 – Схема сдваивания
Лекция 17. Внутренний параллелизм в алгоритме решения системы линейных алгебраических уравнений
Цель лекции: Изучение внутреннего параллелизма на примере алгоритма решения системы линейных алгебраических уравнений.
Содержание лекции: Алгоритм системы линейных алгебраических уравнений. Параллелизм в алгоритме. Граф алгоритма.
Пусть
рассматривается система линейных алгебраических уравнений ![]() с невырожденной треугольной
матрицей А порядке n методом обратной
подстановки. Обозначим через
с невырожденной треугольной
матрицей А порядке n методом обратной
подстановки. Обозначим через ![]() элементы матрицы, правой части и
вектор-решение. Предположим для определенности, что матрица А левая
треугольная с диагональными элементами, равными 1. Тогда имеем
элементы матрицы, правой части и
вектор-решение. Предположим для определенности, что матрица А левая
треугольная с диагональными элементами, равными 1. Тогда имеем
![]() (1)
(1)
Эта запись также не определяет алгоритм однозначно, т.к. не определен порядок суммирования. Рассмотрим, например, последовательное суммирование по возрастанию индекса j. Соответствующий алгоритм можно записать следующим образом
![]()
![]() (2)
(2)
![]()
Основная
операция алгоритма имеет вид ![]() Выполняется она для всех допустимых
значений индексов
Выполняется она для всех допустимых
значений индексов ![]() Все
остальные операции осуществляют присваивание. Опять неэффективна простая
перенумерация операций при построении графа алгоритма. В декартовой системе
координат с осями
Все
остальные операции осуществляют присваивание. Опять неэффективна простая
перенумерация операций при построении графа алгоритма. В декартовой системе
координат с осями ![]() построим
прямоугольную координатную сетку с шагом 1 и поместим в узлы сетки при
построим
прямоугольную координатную сетку с шагом 1 и поместим в узлы сетки при ![]() вершины графа,
соответствующие операциям
вершины графа,
соответствующие операциям ![]() Анализируя связи между операциями, построим
граф алгоритма, включив в него также вершины, символизирующие ввод входных
данных
Анализируя связи между операциями, построим
граф алгоритма, включив в него также вершины, символизирующие ввод входных
данных ![]() и
и ![]() . Этот граф для случая
. Этот граф для случая ![]() представлен на рисунке
1. Верхняя угловая вершина находится в точке с координатами
представлен на рисунке
1. Верхняя угловая вершина находится в точке с координатами ![]()
![]()
![]() j
j
1 2 3 4



![]()
![]()
![]()
![]()
![]()
![]() i b1
●
i b1
●

![]()
![]()
![]() b2● ●
b2● ●
a21●
![]()

![]()
![]()
![]()
![]() b3●
● ●
b3●
● ●
a31● a32 ●
![]()
![]()
![]()
![]()
![]()
![]()
![]() b4● ● ● ●
b4● ● ● ●
a41 ● a42● a43●
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() b5●
● ● ● ●
b5●
● ● ● ●
a51● a52● a53● a54●
Рисунок 1 – Граф для прямоугольной системы для (2)
На
этом рисунке показана одна из максимальных параллельных форм. Ее ярусы
отмечены пунктирными (тонкими) линиями. Параллельная форма становится
канонической, если вершины, соответствующие вводу элементов ![]() , поместить в первый
ярус. Общее число ярусов, содержащих операции типа
, поместить в первый
ярус. Общее число ярусов, содержащих операции типа ![]() равно
равно ![]() Операции ввода элементов
вектора В расположены в первом ярусе.
Операции ввода элементов
вектора В расположены в первом ярусе.
Если при вычислении суммы (1) мы останавливаемся по каким-то соображениям на последовательном способе суммирования, то выбор суммирования именно по возрастанию индекса j был сделан, вообще говоря, случайно. Так как в этом выборе пока не видно каких-либо преимуществ, то можно построить алгоритм обратной подстановки с суммированием по убыванию индекса j. Соответствующий алгоритм следующий:
![]()
![]() (3)
(3)
![]()
Его
граф для случая ![]() представлен
на рисунке. Теперь верхняя угловая вершина находится в точке с координатами
представлен
на рисунке. Теперь верхняя угловая вершина находится в точке с координатами ![]()
Пытаясь
размещать вершины, соответствующие операциям типа ![]() по ярусам хотя бы какой-нибудь
параллельной формы, мы обнаруживаем, что теперь в каждом ярусе всегда может
находиться только одна вершина. Объясняется это тем, что все вершины графа на
рисунке 2 лежат на одном пути. Этот путь показан пунктирными стрелками.
Поэтому общее число ярусов в графе алгоритма (3), содержащих операции вида
по ярусам хотя бы какой-нибудь
параллельной формы, мы обнаруживаем, что теперь в каждом ярусе всегда может
находиться только одна вершина. Объясняется это тем, что все вершины графа на
рисунке 2 лежат на одном пути. Этот путь показан пунктирными стрелками.
Поэтому общее число ярусов в графе алгоритма (3), содержащих операции вида ![]() всегда равно
всегда равно ![]() что намного больше,
чем
что намного больше,
чем ![]() ярус в
графе алгоритма (2).
ярус в
графе алгоритма (2).
Полученный результат трудно было ожидать. Действительно, оба алгоритма (2) и (3), предназначены для решения одной и той же задачи. Они построены на одних и тех же формулах (1) и в отношении точных вычислений эквивалентны. Оба алгоритма совершенно одинаковы с точки зрения их реализации на однопроцессорных компьютерах, т.к. требуют выполнения одинакового числа операций умножения и вычитания и одинакового объема памяти. На классе треугольных систем оба алгоритма даже эквивалентны с точки зрения ошибок округления.
Тем не менее, графы обоих алгоритмов принципиально отличаются друг от друга. Если эти алгоритмы реализовывать на параллельной вычислительной системе, имеющей n универсальных процессоров, то алгоритм (2) можно реализовать за время, пропорциональное n, а алгоритм (3) – только за время, пропорциональное n2 . В первом случае средняя загруженность процессоров близка к 0,5, во втором случае она близка к 0.
Таким образом, алгоритмы, совершенно одинаковые с точки зрения реализации на обыкновенных компьютерах, могут быть принципиально различными с точки зрения реализации на параллельных компьютерах.
Воспользовавшись данным примером, подчеркнем, что в этом факте, собственно говоря, и заключается основная трудность математического освоения параллельных компьютеров. Специалисты различного профиля, работающие на обыкновенных компьютерах в течение многих лет, привыкли оценивать алгоритмы, главным образом, через три характеристики: число операций, объем требуемой памяти и точность. На этих характеристиках было построено практически все основные параметры вычислительной техники, процесс обучения вычислительному делу, создание численных методов и алгоритмов, оценка эффективности, разработка языков и трансляторов и многое другое.
Создание параллельных вычислительных систем дополнительно потребовало от алгоритмов принципиально других свойств и характеристик, знание которых для последовательных компьютеров было просто не нужно. Нет никаких оснований предполагать, что складывавшиеся годами и десятилетиями стереотипы отношения к вычислительной технике и конструктивную методологию для выявления и изучения параллельных свойств алгоритмов.
Лекция 18. Внутренний параллелизм в алгоритме решения систем линейных алгебраических уравнений с блочно-двухдиагональными матрицами
Цель лекции: Изучение внутреннего параллелизма в алгоритме решения СЛАУ с блочно-двухдиагональными матрицами.
Содержание лекции: СЛАУ с блочно-двухдиагональной матрицей. Макрооперации.
Среди многих задач линейной алгебры, возникающих при решении уравнений математической физики сеточными методами, часто встречается задача решения систем линейных алгебраических уравнений с блочно-диагональными матрицами. При этом внедиагональные блоки представляют собой диагональные матрицы, диагональные блоки – двухдиагональные матрицы. Будем считать для определенности, что матрица системы является левой треугольной.
Пусть
она имеет блочный порядок m и порядок блоков, равный n. Итак,
рассмотрим систему линейных алгебраических уравнений ![]() следующего вида:
следующего вида:
где
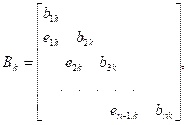
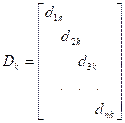 ,
(1)
,
(1)
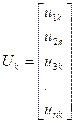 ,
, 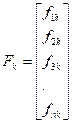 .
.
Решение
блочно-двухдиагональной системы (1) определяется рекуррентно: ![]()
Если
положить ![]() Макрооперация
Макрооперация
![]() вычисляет
вектор Х по векторам
вычисляет
вектор Х по векторам ![]() и матрицам
и матрицам ![]() Построим граф алгоритма (1), считая, что
каждая из его вершин соответствует данной макрооперации. Очевидно, он будет
таким, как показано на рисунке 1. Большие размеры вершин и дуг на рисунке
подчеркивают, что операции являются сложными и передается сложная информация.
Построим граф алгоритма (1), считая, что
каждая из его вершин соответствует данной макрооперации. Очевидно, он будет
таким, как показано на рисунке 1. Большие размеры вершин и дуг на рисунке
подчеркивают, что операции являются сложными и передается сложная информация.
Из строения графа сразу видно, что если алгоритм (2) рассматривать как последовательность матрично-векторных операций, то он является строго последовательным и не распараллеливается. Практически не распараллеливается и каждая макрооперация в отдельности. Она также представвляет решение двухдиагональной системы. Поэтому распараллеливание может только процесс вычисления правой части системы, если, конечно, данную систему снова решать аналогично (2).
B1 D0=0 B2 D1 Bm Dm-1
![]()
![]()
![]()
![]()
![]()
![]() U0=0
U0=0
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() ∙ ∙ ∙
∙ ∙ ∙
![]()
![]()
![]()
![]()
![]()
![]()
F1 U1 F2 U2 Fm Um
Рисунок 1 – Макрограф для блочно-двухдиагональной системы
Из строения графа сразу видно, что если алгоритм (2) рассматривать как последовательность матрично-векторных операций, то он является строго последовательным и не распараллеливается. Практически не распараллеливается и каждая макрооперация в отдельности. Она также представвляет решение двухдиагональной системы. Поэтому распараллеливание может только процесс вычисления правой части системы, если, конечно, данную систему снова решать аналогично (2).
Из этих фактов можно было бы сделать вывод о невозможности хорошего распараллеливания алгоритма решения рассматриваемой системы (1). Однако такой вывод был бы преждевременным.
Исследуем поэлементную запись алгоритма решения блочно-двухдиагональной системы. С учетом введенных ранее обозначений элементов матриц и векторов имеем:
![]() (3)
(3)
При
этом предполагается, что ![]() для всех
для всех ![]()
В записи (3) основной и единственной является скалярная операция
![]() (4)
(4)
которая вычисляет величину ![]() по величинам
по величинам ![]() Опять неэффективна
простая перенумерация операций. Для построения графа алгоритма рассмотрим
прямоугольную решетку, узлы которой имеют целочисленные координаты
Опять неэффективна
простая перенумерация операций. Для построения графа алгоритма рассмотрим
прямоугольную решетку, узлы которой имеют целочисленные координаты ![]() Во все узлы решетки
для
Во все узлы решетки
для ![]() поместим
вершины графа и будем считать, что они соответствуют операции (4). Не будем
указывать вершины, поставляющие входные данные и нулевые значения некоторых
аргументов. Анализируя запись (3), нетрудно убедиться в том, что в вершину с
координатами
поместим
вершины графа и будем считать, что они соответствуют операции (4). Не будем
указывать вершины, поставляющие входные данные и нулевые значения некоторых
аргументов. Анализируя запись (3), нетрудно убедиться в том, что в вершину с
координатами ![]() будут
передаваться результаты выполнения операций, соответствующих вершинам с
координатами
будут
передаваться результаты выполнения операций, соответствующих вершинам с
координатами ![]() и
и
![]() Вся остальная
информация, необходимая для реализации операции с координатами
Вся остальная
информация, необходимая для реализации операции с координатами ![]() является входной и
нужна для реализации только этой операции. В графе данного алгоритма нет
множественной рассылки входных данных типа той, которая имела место в алгоритме
(2) из лекции 17.
является входной и
нужна для реализации только этой операции. В графе данного алгоритма нет
множественной рассылки входных данных типа той, которая имела место в алгоритме
(2) из лекции 17.
Для
случая ![]() граф
алгоритма может быть представлен. Из него следует, что вопреки возможным
ожиданиям граф алгоритма прекрасно распараллеливается. Пунктирными линиями
отмечены ярусы максимальной параллельной формы. Понятно, что высота алгоритма
без учета ввода входных данных равна
граф
алгоритма может быть представлен. Из него следует, что вопреки возможным
ожиданиям граф алгоритма прекрасно распараллеливается. Пунктирными линиями
отмечены ярусы максимальной параллельной формы. Понятно, что высота алгоритма
без учета ввода входных данных равна ![]() ширина алгоритма равна
ширина алгоритма равна ![]() На рисунке 3 в этом же графе
пунктирными линиями обведены группы вершин. Каждая из таких групп
соответствует одной вершине графа, представленного на рисунке 1. Они же
являются ярусами обобщенной параллельной формы. Из этих рисунков видно, каким
образом хорошо распараллеливаемый алгоритм может превратиться в
нераспараллеливаемый при неудачном укрупнении операций.
На рисунке 3 в этом же графе
пунктирными линиями обведены группы вершин. Каждая из таких групп
соответствует одной вершине графа, представленного на рисунке 1. Они же
являются ярусами обобщенной параллельной формы. Из этих рисунков видно, каким
образом хорошо распараллеливаемый алгоритм может превратиться в
нераспараллеливаемый при неудачном укрупнении операций.
Лекция 19. Исследование алгоритма решения одномерного уравнения теплопроводности
Цель лекции: Исследование алгоритма решения одномерного уравнения теплопроводности на предмет параллелизма.
Содержание лекции: Алгоритм решения задачи теплопроводности, анализ алгоритма на предмет параллелизма.
Пусть
рассматривается решение краевой задачи для одномерного уравнения
теплопроводности. Здесь требуется найти функцию ![]() удовлетворяющее уравнению теплопроводности
удовлетворяющее уравнению теплопроводности
![]()
![]()
Построим равномерную сетку с шагом h по z и шагом τ по y. Предположим, что по тем или иным причинам выбрана явная схема
![]() .
.
Пусть алгоритм реализуется в соответствии с формулой
![]() (1)
(1)
Для
построения графа алгоритма введем прямоугольную систему координат с осями ![]() Переменные y,z связаны с
переменными
Переменные y,z связаны с
переменными ![]() соотношениями
соотношениями
![]()
Поместим в каждый узел целочисленной решетки вершину графа и будем считать ее соответствующей скалярной операции
![]() (2)
(2)
Выполняемой для разных значений аргументов a,b,c. Для случая h=1/8, τ=T/6 граф алгоритма представлен на обоих рисунках 1 и 2. На границе области расположены вершины, символизирующие ввод начальных данных и граничных значений.
На данном примере мы хотим затронуть очень важный вопрос, касающийся реализации алгоритмов на любых компьютерах. До сих пор мы связывали ее с выполнением операций по ярусам параллельных форм. Конечно, операции одного яруса не зависят друг от друга и их действительно можно реализовывать на разных устройствах одновременно. Но эффективность такой организации параллельных вычислений может оказаться очень низкой. На рисунке 1 пунктирными линиями показаны все ярусы максимальной параллельной формы алгоритма (1). Предположим, что операции реализуются по этим ярусам. Каждая операция вида (2) одного яруса требует трех аргументов. Если данные, полученные на одном ярусе, могут быстро извлекаться из памяти, то никаких серьезных проблем с реализацией алгоритма по ярусам параллельной формы не возникает. Однако для больших многомерных задач ярусы оказываются столь масштабными, что информация о них может не поместиться в быстрой памяти. Тогда для ее размещения приходится использовать медленную память. Для этой памяти время выборки одного числа существенно превышает время выполнения базовой операции (2). Это означает, что при переходе к очередному ярусу время, затраченное на выполнение операций, окажется отношение времени выполнения операций ко времени доступа к памяти, тем меньше эффективность реализации алгоритма (1) по ярусам параллельной формы. В этом случае большая часть времени работы параллельного компьютера будет тратиться на осуществление обменов с медленной памятью, а не на собственно счет.
Можно
ли каким-либо способом повысить эффективность использования медленной памяти в
алгоритме (1) и, если можно, то как? Ответ на данный вопрос дает более
детальное изучение графа алгоритма. Заметим, что в графе алгоритма (1), кроме
строгой параллельной формы с горизонтальными ярусами на рисунке 1, существуют
параллельные формы, строгие и обобщенные, с наклонными ярусами. Например,
обобщенные параллельные формы можно получить, сгруппировав в ярусы вершины на
прямых ![]() и
и ![]()
Лекция 20. Технология MPI. коллективные взаимодействия процессов
Цель лекции: Изучение технологии MPI. на предмет коллективного взаимодействия процессов.
Содержание лекции: Коммуникатор. Использование коммуникатора для взаимодействия процессов MPI- программы. Рассылка сообщений.
Для локализации взаимодействия параллельных процессов программы можно создавать группы процессов, предоставляя им отдельную среду для общения. Эта среда общения называется коммуникатором. Коммуникатор существует всегда и служит для взаимодействия всех процессов MPI- программы.
В операциях коллективного взаимодействия процессов участвуют все процессы коммуникатора. Соответствующая процедура должна быть вызвана каждым процессом, быть может, со своим набором параметров. Возврат из процедуры коллективного взаимодействия может произойти в тот момент, когда участие процесса в данной операции уже закончено. Как и для блокирующих процедур, возврат означает то, что разрешен свободный доступ к буферу приема или посылки. Асинхронных коллективных операций в MPI нет.
В коллективных операциях можно использовать те же коммуникаторы, что и были использованы для операций типа точка-точка. Технология MPI гарантирует, что сообщения, вызванные коллективными операциями, никак не повлияют на выполнение других операций и не пересекутся с сообщениями, появившимися в результате индивидуального взаимодействия процессов.
Вообще говоря, нельзя рассчитывать на синхронизацию процессов с помощью коллективных операций. Если какой-то процесс уже завершил свое участие в коллективной операции, то это не означает ни того, что данная операция завершена другими процессами коммуникатора, ни даже того, что она ими начата.
Рассылка сообщений. В коллективных операциях не используются идентификаторы сообщений. В следующем фрагменте показана рассылка от процесса source всем процессам данного коммуникатора, включая рассылающий процесс:
Int MPI_Bcast(void *buf, int count, MPI_Datatype datatype, int source, MPI_Comm comm)
- OUT buf – адрес начала буфера посылки сообщения;
- count – число передаваемых элементов в сообщении;
- datatype – тип передаваемых элементов;
- source – номер рассылающего процесса;
- comm – идентификатор коммуникатора.
При возврате из процедуры содержимое буфера buf процесса source будет скопировано в локальный буфер каждого процесса коммуникатора comm. Значения параметров count, datatype, source, comm должны быть одинаковыми у всех процессов. В результате выполнения следующего оператора всеми процессами коммуникатора comm:
MPI_Bcast (array, 100, MPI_INT, 0, comm);
Первые сто целых чисел из массива array нулевого процесса будут скопированы в локальные буфера array каждого процесса коммуникатора comm.
Сборка данных со всех процессов в буфере rbuf процесса dest. Она выполняется с помощью следующего фрагмента:
Int MPI_Gather (void *sbuf, int scount,MPI_Datatype stype, void *rbuf, int rcount, MPI_Datatype rtype, int dest, MPI_Comm comm)
- sbuf – адрес начала буфера посылки;
- scount – число элементов в посылаемом сообщении;
- stype – тип элементов отсылаемого сообщения;
– OUT rbuf – адрес начала буфера сборки данных;
- rcount – число элементов в принимаемом сообщении;
- rtype – тип элементов принимаемого сообщения;
- dest – номер процесса, на котором происходит сборка данных;
- comm – идентификатор коммуникатора.
Каждый процесс, включая dest, посылает содержимое своего буфера sbuf процессу dest. Собирающий процесс сохраняет данные в буфере rbuf, располагая их в порядке возрастания номеров процессов. На процессе dest существенными являются значения всех параметров, а на всех остальных процессах – только значения параметров sbuf, scount, stype, dest, comm. Значения параметров dest и comm должны быть одинаковыми у всех процессов. Параметр rcount у процесса dest обозначает число элементов типа rtype, принимаемых не от всех процессов в сумме, а от каждого процесса. С помощью похожей функции MPI_Gatherv можно принимать от процессов массивы данных различной длины.
Лекция 21. Эффективность распараллеливания
Цель лекции: Изучение эффективности параллельного вычисления.
Содержание лекции: Параллельная система. Закон Амдала. Пути повышения производительности компьютеров.
Пользователь, используя параллельную систему с p вычислительными устройствами, ожидает получить ускоренное выполнение своей программы в p раз по сравнению с последовательным вариантом. Однако на практике оказывается, что такое ускорение не всегда происходит. В данной лекции рассматриваются вопросы, связанные с попытками и решениями проблем увеличения производительности компьютеров.
Закон Амдала. Допустим, что структура информационных зависимостей программы определена. В общем случае такая задача является непростой задачей. Также определена доля операций, которые нужно выполнять последовательно. Эта доля понимается не по числу строк кода, а по времени выполнения последовательной программы. Пусть доля последовательной программы равна f. Она может принимать значения, ограниченные в промежутке [0,1]. Если f=0, то программа полностью параллельная, а если f=1, то программа полностью последовательная.
Тогда для того, чтобы оценить, какое ускорение S может быть получено на компьютере из p процессоров при данном значении f, можно воспользоваться законом Амдала:
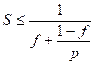 .
.
Например, если 90% программы исполняется параллельно, а 10% последовательно, то ускорение получить в 10 раз невозможно. Причем, это не зависит от качества реализации параллельной части кода и числа используемых процессоров.
Отсюда можно сделать следующий вывод: не любая программа может быть эффективно распараллелена. Для того чтобы это было возможно, необходимо, чтобы доля информационно независимых операций была очень большой. В самом деле, большинство вычислительных алгоритмов устроено в этом смысле достаточно хорошо.
Допустим теперь, что в программе относительно немного последовательных операций. Вроде проблема распараллеливания может быть решена легко. Однако доступные нам процессоры разнородны и их производительности разные. В этом случае часть процессоров свои задания выполняют быстрее, а другая часть медленнее. Тогда некоторые процессоры простаивают в ожидании, когда другие еще работают. Если разброс производительностей процессоров большой, то и эффективность будет низкой.
Теперь предположим, что все процессоры одинаковы. Процессоры выполняют свои задания, результатами они должны обмениваться. На передачу данных тратится время и в это время процессоры опять простаивают.
Кроме названных выше, имеются еще большое количество факторов, влияющих на эффективность выполнения параллельных программ. Причем, эти факторы могут действовать одновременно. Поэтому при распараллеливании программ должны быть учтены.
Таким образом, добиться максимальную эффективность работы параллельной вычислительной системы или суперкомпьютера является достаточно сложной проблемой. Для достижения такую эффективность необходимо тщательное согласование структуры программы и алгоритма с особенностями архитектуры параллельных вычислительных систем.
Пути повышения производительности компьютеров. Попытка людей повысить производительность компьютеров была начата давно, со времен появления первых компьютеров. Идея параллельной обработки данных не новая, она появилась давно. Вначале эти идеи внедрялись в самых передовых, а потому в единичных компьютерах.
Впоследствии, с развитием новых технологий и удешевлением производства, эти идеи внедрялись в обычных компьютерах, в рабочих станциях и персональных компьютерах. Это в то время, когда еще не использовались микропроцессоры, не было понятия о суперкомпьютерах.
В конце 40 –х годов и в начале 50-х годов прошлого столетия в компьютерах использовались разрядно-последовательная память и разрядно-последовательная арифметика. В таком способе организации памяти разряды слова поступали для последующей обработки последовательно один за другим. Также поразрядно выполнялись и арифметические операции. Например, для сложения двух 32-разрядных числе требовалось 32 машинных такта.
С изобретением запоминающих устройств с произвольной выборкой данных стали использовать разрядно-параллельную память и разрядно-параллельную арифметику. Все разряды слова одновременно считываются из памяти и участвуют в выполнении операции арифметико-логическим устройством (АЛУ).
Однако для дальнейшего увеличения производительности компьютеров было преградой следующее положение дел. Операции ввода и вывода выполнялись арифметико-логическим устройством. Такая организация вела к снижению производительности. Для решения этой проблемы была введена специализированная ЭВМ, называемая каналом ввода и вывода (УВВ). Это позволило работать параллельно АЛУ и УВВ.
Стало понятно, что наряду с увеличением скорости арифметического устройства, появилась необходимость уменьшение времени обращения к запоминающему устройству (ЗУ). Это привело к созданию дополнительной «сверхбыстродействующей памяти» небольшой емкости.
Такая память дает возможность сократить время для выполнения стандартных вычислений. При этом заполнение «сверхбыстродействующей памяти» из общей памяти компьютера осуществляется одновременно с выполнением вычислений. Для осуществления этой идеи архитектура системы должна иметь две принципиально важных особенности:
- опережающий просмотр для считывания, декодирования, вычисления адресов, а также предварительная выборка операндов нескольких команд;
- расслоение памяти, т.е. разбиение памяти на два независимых банка, способных передавать данные в АЛУ независимо друг от друга.
В 1962 году была создан компьютер ATLAS. В этом компьютере впервые начали использовать конвейерный принцип обработки данных. Цикл обработки команды разбили на четыре ступени:
- выборка команды;
- вычисление адреса операнда;
- выборка операнда;
- выполнение операции.
Это позволило сократить время выполнения команды 6 до 1,6 мкс и увеличить производительность компьютера до 200 тысяч вещественных операций в секунду.
В 1964 году компания CDC (Control Data Corporation) выпускает компьютер CDC-6600. Центральный процессор этого компьютера содержал 10 независимых функциональных устройств. Все они работали одновременно независимо друг от друга. Характеристики данной машины: время такта 100 нс, память разбита на 32 банка по 4096 60-разрядных слов, средняя производительность 2-3 млн. операций в секунду.
Одним из важных этапов развития идей параллельной обработки данных стало создание компьютеров, основанных на идее – матрица синхронно работающих процессоров. Здесь основу составляет матрица из 256 процессорных элементов (ПЭ), которые сгруппированы в 4 квадранта по 64 ПЭ. В каждом квадранте находилось собственное устройство управления (УУ), которое выдает команды для синхронно работающих ПЭ своего квадранта. Время такта компьютера равнялось 40 нс, а запланированная пиковая производительность 1 миллиард вещественных операций в секунду.
Данный проект оказал огромное влияние на архитектуру последующих поколений компьютеров. Отработанные в рамках проекта технологии были использованы при создании компьютеров последующих поколений и программного обеспечения параллельных вычислительных систем.
Идея включения векторных операций в систему команд компьютеров дала определенные успехи в повышении производительности компьютеров. Причинами такого успеха являются:
- использование векторных операций позволяет намного проще записать многие вычислительные фрагменты в терминах машинных команд;
- многие алгоритмы можно выразить в терминах векторных операций;
- подобные операции позволяют добиться максимального эффекта от использования конвейерных устройств.
В 1976 году компания Gray Research (руководитель - знаменитый конструктор многих компьютеров С. Крэй) выпускает первый векторно-конвейерный компьютер Gray-1. Отличительными особенностями данного компьютера:
- векторные команды, которые упростили путь к высокой производительности на практике за счет эффективной загрузки конвейера;
- независимые конвейерные функциональные устройства;
- развитая регистровая структура.
Работа функциональных устройств с регистрами сделала высокую производительность в выполнении операций. Можно привести некоторые характеристики GRAY-1:
- время такта 12,5 нс;
- 12 конвейерных устройств;
- оперативная память до 1 Мслова;
- пиковая производительность 160 млн операций в секунду.
Анализ архитектурных особенностей компьютеров затрагивает важную проблему согласования работы процессора и времени выборки данных из памяти. В различных компьютерах используются различные структуры памяти. Здесь целесообразно привести известную аналогию с организацией работы мастера:
- все самое необходимое мастер держит под рукой, на рабочем столе (регистры);
- часто используемые предметы хранятся здесь же в ящиках стола (кэш-память);
- основной набор инструментов лежит в шкафу недалеко от стола (основная память);
- за чем-то приходится идти на склад (дисковая память);
- а некоторые вещи приходится заказывать в другой мастерской (архив на магнитной ленте).
Регистровая память, имеющаяся в составе процессора или других устройств ЭВМ, предназначена для кратковременного хранения небольшого объема информации, непосредственно участвующей в вычислениях или операциях обмена (ввода-вывода).
Кэш-память служит для хранения копий информации, используемой в текущих операциях обмена. Это очень быстрое ЗУ небольшого объема, являющееся буфером между устройствами с различным быстродействием. Обычно используется при обмене данными между микропроцессором и оперативной памятью для компенсации разницы в скорости обработки информации процессором и несколько менее быстродействующей оперативной памятью.
Кэш-памятью управляет специальное устройство – контроллер, который, анализируя выполняемую программу , пытается предвидеть, какие данные и команды вероятнее всего понадобятся в ближайшее время процессору, подкачивает их в кэш-память.
Основная память предназначена для оперативного хранения и обмена данными, непосредственно участвующими в процессе обработки. Конструктивно она исполняется в виде интегральных схем и подразделяется на два вида:
- постоянное запоминающее устройство (ПЗУ);
- оперативное запоминающее устройство (ОЗУ).
Внешняя память используется для долговременного хранения больших объемов информации. В современных компьютерных системах в качестве устройств внешней памяти наиболее часто применяются:
- накопители на жестких магнитных дисках;
- накопители на шибких магнитных дисках;
- Накопители на оптических дисках; Магнитооптические носители информации;
- ленточные накопители (стримеры).
В элементах оперативной памяти время доступа к информации измеряется в пределах наносекунд (нс), т.е. 10-9 секунд. Время доступа к информации для внешних запоминающих устройств находится в пределах миллисекунд, т.е. 10-3секунд.
Микропроцессор не имеет непосредственного доступа к данным, находящимся во внешней памяти. Для обработки этих данных процессором они должны быть загружены в оперативную память.
Лекция 22. Повышение качества управления компьютером. Заключение
Цель лекции: Изучение проблемы повышения качества управления компьютером.
Содержание лекции: Проблема повышения качества управления компьютером. Компьютеры с общей памятью. Задачи производительности компьютеров.
Итак, из предыдущих материалов лекции следует, что параллелизм в архитектуре компьютеров является необходимым для повышения производительности вычислительных систем. Современные технологии позволяют решать задачу объединения тысячи процессоров в рамках одной вычислительной системы. Эти системы позволяют добиться производительность, измеряемая в терафлопах, т.е. 1012 (триллион) операций в секунду.
Вместе с тем, опыт использования параллельных компьютеров показывает, что здесь не все гладко. Естественно, повышение параллелизма в архитектуре компьютера ведет к росту его пиковой производительности. Однако, с другой стороны, это ведет к увеличению разрыва между реальной производительности и пиковой производительности. Очевидно, что не все программы одинаково эффективно могут использовать все возможности процессорных элементов такого компьютера. В связи с этим возникает проблема поднятия реальной производительности вычислительной системы.
Поднятие реальной производительности программы связано с определенными трудностями. Производительность программы зависит от того, насколько развита поддержка параллелизма в аппаратно-программной среде вычислительной системы. Здесь важно следующие факторы:
- операционные системы и компиляторы;
- технологии параллельного программирования;
- системы времени исполнения программы;
- поддержка параллелизма в процессоре;
- поддержка работы с памятью.
Архитектура параллельных компьютеров развивалась большими темпами и в самых разных направлениях. Однако, если отбросить детали и выделить общую идею построения большинства современных параллельных вычислительных систем, то останется лишь два класса:
- компьютеры с общей памятью;
-компьютеры с распределенной памятью.
Компьютеры с общей памятью. Системы, построенные по такому принципу, иногда называют мультипроцессорными системами или мультипроцессорами. В данной системе присутствуют несколько равноправных процессоров, имеющих одинаковый доступ к единой памяти. Все процессоры «разделяют» между собой общую память (Рисунок 5.1). Поэтому компьютеры этого класса называются компьютерами с разделяемой памятью. Все процессоры работают с единым адресным пространством. Например, если один процессор записал некоторое значение по определенному адресу, другой процессор из этого адреса получит то же значение.
Процессор Процессор Процессор
. . .
 |
Рисунок 1 – Параллельные компьютеры с общей памятью
|
|
|
Память Память Память
. . .

Рисунок 2 – Параллельные компьютеры с распределенной памятью
Компьютеры с распределенной памятью. Компьютеры этого класса иногда называются мультикомпьютерными системами (Рисунок 5.2). Здесь каждый вычислительный узел является полноценным компьютером со своим процессором, памятью, подсистемой ввода и вывода, операционной системой. Каждый узел системы работает в своем адресном пространстве.
Эти два класса компьютеров появились не случайно. Они отражают две основные задачи параллельных вычислений.
Первая задача заключается в построении вычислительных систем с максимальной производительностью. Это легко позволяет сделать компьютеры с распределенной памятью. В настоящее время существуют установки, объединяющие тысячи вычислительных узлов в рамках единой коммуникационной среды. В качестве примера можно рассматривать Интернет, который объединяет миллионы компьютеров. Здесь имеются следующие проблемы:
- эффективное использование таких систем;
- уменьшение накладных расходов, идущих на взаимодействие параллельно работающих процессоров;
- упрощение разработку параллельных программ.
Здесь практически существует единственный способ программирования подобных систем. Это использование систем обмена сообщениями. Этот способ не всегда прост.
Вторая задача возникает также из желания повысить качества управления компьютером. Она заключается в следующем – поиск методов разработки эффективного программного обеспечения для параллельных вычислительных систем. В этой задаче некоторые вопросы проще решается для компьютеров с общей памятью. Накладные расходы на обмен данными между процессорами через общую память минимальны, а технологии программирования таких систем, как правило, проще. Однако есть другая проблема. По технологическим причинам не удается объединить большое количество процессоров с единой оперативной памятью. Следовательно, большую производительность на таких системах получить нельзя.
Система коммуникации. В рассмотренных задачах основной проблемой является система обмена данными, т.е. система коммуникации. Система коммуникации предназначена для организации связи между самими процессорами, между процессорами и модулями памяти. Здесь будут рассматриваться некоторые способы организации коммуникационных систем в компьютерах.
Использование общей шины. Одним из простых способов организации мультипроцессорных систем опирается на использование общей шины. К ней подключаются как процессоры, так и память. Шина состоит из некоторого количества линий, необходимых для передачи адресов, данных и управляющих сигналов между процессорами и памятью (Рисунок 3). Чтобы не было одновременных обращений нескольких процессоров к памяти, используется некоторая схема арбитража. Основной проблемой таких систем заключается в том, что даже небольшое увеличение числа устройств на шине приводит к значительным задержкам при обмене данными. Это приводит падению производительности всей системы.
Использование матричного коммутатора. Одним из мощных систем является разделение памяти на независимые модули и обеспечение возможности доступа разных процессоров к различным модулям одновременно. Одним возможных решений является использование матричного коммутатора. Процессоры и модули памяти связываются так, как показано на рисунке 4.
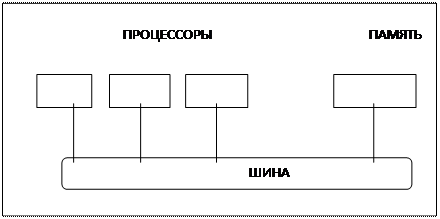 |
Рисунок 3 – Мультипроцессорная система с общей шиной
Модули памяти Процессоры
Точечные переключатели С С С С М М М М
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Рисунок 4 – Мультипроцессорная система с матричным коммутатором
В пересечении линии располагаются элементарные точечные переключатели, разрешающие и запрещающие передачу информации между процессорами и модулями памяти. Преимуществом такой организации является возможность одновременной работы процессоров с различными модулями памяти. Недостатком является большой объем необходимого оборудования. Например, для связи n процессоров с n модулями памяти требуется n2 элементарных переключателей. Во многих случаях это является дорогим решением.
|
М М М М С С С С ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Рисунок 5 – Мультипроцессорная система с омега-сетью
Использование каскадных переключателей. Еще одним альтернативным решением является использование каскадных переключателей (Рисунок 5). На рисунке показана сеть из четырех коммутаторов 2х2 организованная в два каскада. Каждый использованный коммутатор может соединить любой из двух своих входов с любым из двух своих выходов.
Это свойство и использованная схема коммутации позволяют любому процессору вычислительной системы, показанной на этом рисунке, обращаться к любому модулю памяти. В общем случае для соединения n процессоров с n модулями памяти потребуется (n log2n)/2 коммутаторов. Для больших значений n эта величина намного лучше, чем n2. Однако появляется другая проблема – происходят задержки. Каждый коммутатор не срабатывает мгновенно, потому что на коммутацию входа с выходом на каждом каскаде требуется некоторое время.
Заключение. Существуют и другие варианты соединений процессоров с модулями памяти. Рассмотренные нами особенностей компьютеров с общей и распределенной памятью показали, что оба класса компьютеров имеют свои преимущества и недостатки. Возник вопрос: можно ли объединить достоинства этих двух классов? Одним из возможных направлений является проектирование компьютеров с архитектурой NUMA (Non Uniform Memory Access) - компьютеры с неоднородным доступом.
Литература:
1. Корнеев В.Д. Параллельное программирование в МР1. Издательство «Регулярная и хаотическая динамика» 2003.- 303 с.
2.Воеводин В.В., Воеводин Вл. В. Параллельные вычисления. - СПб: BHV, 2002.
З.Грегори Р. Эндрюс. Основы многопоточного, параллельного и распределенного программирования. Издательство «Вильяме», 2003. - 512 с.
4. Дейкстра Э. Взаимодействие последовательных процессов. - В кн.: Языки программирования. М.: Мир, 1972.
5. С. Седухин. Параллельно-поточная интерпретация метода Гаусса. Вычислительные системы с программируемой структурой (Вычислительные системы, 94). ИМ СОАН СССР. Новосибирск.1982.
6. Супер ЭВМ. Аппаратная и программная реализация/ Под. Ред. С. Фернбаха: Пер. с. Англ. - М.: Радио и связь, 1991. - 320 с: ил .
7. В. Воеводин. Математические модели и методы в параллельных процессах. М.: Наука, 1986.
8. Д. Росляков, И. Терехов. Новые технологические решения в построении отказоустойчивых систем. Информационные технологии.№1. 1998.
9. http://www.intuit.ru. Параллельное программирование. Автор: А.Б. Барский.
10. http://www.exelenz.ru. Высокопроизводительные
вычисления:
курс лекции.
11. Давыдов В.Г. Технологии программирования С++. Санкт- Петербург, 2005.
Содержание
|
Лекция 1 |
Введение. Основные понятия о технологиях высокоскоростных вычислений |
3 |
|
Лекция 2 |
Организация быстродействующих вычислительных систем |
7 |
|
Лекция 3 |
Факторы, снижающие пропускную способность |
11 |
|
Лекция 4 |
Реализация условных операторов и ограничения, налагаемые на производительность |
15 |
|
Лекция 5 |
Архитектура высокопроизводительных ЭВМ |
18 |
|
Лекция 6 |
MIMD-компьютеры |
22 |
|
Лекция 7 |
О параллельной обработке данных |
31 |
|
Лекция 8 |
Понятие о параллельных вычислениях |
36 |
|
Лекция 9 |
Использование параллелизма |
40 |
|
Лекция 10 |
Проблема минимизации пересылок данных |
43 |
|
Лекция 11 |
Технология параллельного программирования |
47 |
|
Лекция 12 |
Общая характеристика модели |
52 |
|
Лекция 13 |
Прием и передача сообщений между отдельными процессами |
56 |
|
Лекция 14 |
Прием/передача сообщений без блокировки |
60 |
|
Лекция 15 |
Программы, используемые для приема/передачи сообщений |
62 |
|
Лекция 16 |
Внутренний параллелизм в алгоритме произведения двух квадратных матриц |
67 |
|
Лекция 17 |
Внутренний параллелизм в алгоритме решения системы линейных алгебраических уравнений |
70 |
|
Лекция 18 |
Внутренний параллелизм в алгоритме решения систем линейных алгебраических уравнений с блочно-двухдиагональными матрицами |
72 |
|
Лекция 19 |
Исследование алгоритма решения одномерного уравнения теплопроводности |
74 |
|
Лекция 20 |
Технология MPI. коллективные взаимодействия процессов |
74 |
|
Лекция 21 |
Эффективность распараллеливания |
75 |
|
Лекция 22 |
Повышение качества управления компьютером. Заключение |
80 |
|
|
Список литературы |
85 |