Некоммерческое акционерное общество
АЛМАТИНСКИЙ УНИВЕРСИТЕТ ЭНЕРГЕТИКИ И СВЯЗИ
Кафедра компьютерных технологий
СИСТЕМЫ БАЗ ДАННЫХ
Конспекты лекций
для студентов
специальности 5В070300-«Информационные системы» и
5В070400 – «Вычислительная техника и программное обеспечение»
Алматы 2013
СОСТАВИТЕЛЬ: Е.Г. Сатимова,А.А.Аманбаев «Системы баз данных». Конспекты лекций для студентов специальности 5В070300-Информационные системы» и 5В070400 – «Вычислительная техника и программное обеспечение». – Алматы: АУЭС, 2013 - 59 с.
Конспекты лекций составлены согласно рабочей программе дисциплины «Системы баз данных» и в них рассмотрены технология баз данных, основные понятия и определения, архитектура базы данных. Дана классификация современных СУБД. Рассмотрены модели данных, способы проектирования и реализации реляционных баз данных с помощью модели "сущность-связь" и методом нормальных форм . Рассмотрены манипуляционная и целостная части реляционной модели данных, механизмы обеспечения целостности в БД, реляционная алгебра и реляционное исчисление. Даны основы языка SQL и Transact - SQL . Приведены основы администрирования серверных БД.
Основные теоретические материалы дисциплины разбиты на четырнадцать тем и каждая из этих тем представлена в виде конспекта отдельной лекции.
Конспекты лекций предназначены для студентов специальности 5В070300-«Информационные системы» и 5В070400 – «Вычислительная техника и программное обеспечение».
Библиогр. – 1 8 наимен.
Рецензент: к.т.н., доцент Ни А.Г.
Печатается по плану издания некоммерческого акционерного общества «Алматинский университет энергетики и связи» 2012 г.
© НАО «Алматинский университет энергетики и связи», 201 3 г.
Содержание
|
Лекция 1. Базы данных как часть информационной системы |
4 |
|
Лекция 2. Основные понятия и определения баз данных. СУБД |
7 |
|
Лекция 3. Архитектура базы данных. Физическая и логическая независимость |
11 |
|
Лекция 4. Модели данных |
16 |
|
Лекция 5. Проектирование реляционных баз данных |
20 |
|
Лекция 6. Проектирование реляционных баз данных методом нормальных форм |
24 |
|
Лекция 7. Целостность и надежность данных |
28 |
|
Лекция 8. Реляционная алгебра. Реляционное исчисление |
32 |
|
Лекция 9. Основы языка SQL |
35 |
|
Лекция 10. Программный (встроенный) T-SQL |
40 |
|
Лекция 11. Управление транзакциями в современных реляционных СУБД |
43 |
|
Лекция 12. Обеспечение безопасности СУБД |
47 |
|
Лекция 13. Планирование ёмкости базы данных |
52 |
|
Лекция 14. Настройка производительности системы |
54 |
|
Список литературы |
59 |
Лекция 1. Базы данных как часть информационной системы
Цель : рассмотрение основных понятий обработки данных, выявить основные структурные элементы баз данных и основные принципы, используемые при их разработке.
План:
1) Информационные отношения и взаимосвязи данных.
2) Задачи проектирования базы данных.
3) БД как информационная модель предметной области.
4) СУБД как средство создания и обработки БД.
Выборочные аналитические исследования ИТ-проектов, периодически проводимые международными компаниями Gartner Groups и IDC, показывают, что далеко не все они заканчиваются успешно. По оценкам этих компаний, 50% проектов с базами данных нельзя признать успешными. Существует множество причин, по которым это происходит: от плохо поставленной задачи до неудовлетворительного исполнения в установленные сроки. Одним из направлений работы, способствующих успешности ИТ-проектов, является формирование компетенции членов команды проекта в процессе целенаправленного обучения.
В настоящем пособии пойдет речь о решении комплекса задач, возникающих в процессе проектирования реляционных баз данных. Главная идея, рассматриваемая нами, состоит в том, что успешное проектирование хороших баз данных, без сомнения очень полезных, зависит от понимания их важнейших основополагающих концепций. Всегда очень нелегко разумно сочетать в учебном пособии теорию и практику, но полученный корректный масштабируемый проект базы данных оправдывает приложенные усилия.
Значительная часть ИТ-проектов направлена на разработку и создание информационных систем, в рамках которых осуществляется обработка данных различной сложности. Целью таких проектов является разработка и создание информационной системы с базами данных некоторого класса. Практически во всех таких проектах ставится и решается задача проектирования баз данных. Решение задачи проектирования повышает вероятность того, что разрабатываемая информационная система с базами данных будет удовлетворять заданным функциональным требованиям с учетом заданных ограничений.
Задача проектирования баз данных является сложной по ряду причин. Проектирование базы данных, по мнению многих ведущих специалистов, - это плохо структурированная задача по сравнению с анализом требований к базе данных или разработкой приложений. Проектирование базы данных является "самым размытым" этапом в разработке и создании базы данных. Проектирование базы данных не имеет явно выраженного начала и окончания в рамках принятого условного деления проекта на этапы: определение стратегии, анализ, проектирование, реализация, тестирование и внедрение. Оно начинается с момента принятия стратегических решений и продолжается на этапах тестирования и реализации.
Процесс проектирования базы данных охватывает несколько основных сфер:
1) проектирование объектов базы данных, т.е. проектирование конкретных объектов (таблицы, представления, индексы, триггеры, хранимые процедуры, функции, пакеты) для представления данных предметной области в базе данных;
2) проектирование интерфейса взаимодействия с базой данных (формы, отчеты и т.д.), т.е. проектирование приложений, которые будут сопровождать данные в базе данных, а также будут реализовывать вопрос-ответные отношения на этих данных;
3) проектирование баз данных под конкретную вычислительную среду или информационную технологию ("клиент-сервер", параллельные архитектуры, распределенная вычислительная среда);
4) проектирование баз данных под назначение (интеллектуальный анализ данных, OLAP , OLTP и т. д.) системы.
Отметим, что приложения работы с базой данных проектируются одновременно с базой данных, а не отдельно! Зачастую вычислительная среда задается в качестве входных условий проектирования, но иногда проектирование следует проводить с возможным переходом в будущем на другую аппаратную платформу или технологию.
Базы данных всегда проектируются под конкретное назначение системы. Техника проектирования баз данных может измениться, и не только в деталях, в зависимости от назначения системы. Например, следует различать проектирование систем складирования данных от так называемых OLTP -систем. В настоящем пособии пойдет речь о проектировании баз данных в основном для OLTP -систем. Именно на таких системах исторически сложилась техника проектирования реляционных баз данных. В чем состоит задача проектирования базы данных?
База данных:
- действует в рамках некоторой внешней среды;
- имеет свою внутреннюю архитектуру;
- имеет свое собственное лингвистическое содержание;
- имеет свои средства взаимодействия с окружающей средой;
- функционирует на конкретной программно-аппаратной платформе;
- поддерживается в рамках определенных организационно-технологических мероприятий.
Если представить проектирование баз данных как некий процесс и обозначить его на схеме прямоугольником, то на вход этого процесса будет подан набор исходных данных, а на выходе будет выведен результат, в первую очередь в виде физической базы данных, а также логическая и физическая структуры (реализованные в скрипте) базы данных.
Получение логической и физической структур базы данных и разработка скрипта для ее создания являются примерами профессиональных задач проектировщика базы данных.
В истории вычислительной техники можно проследить развитие двух основных областей ее использования. Первая область — применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Развитие этой области способствовало интенсификации методов численного решения сложных математических задач, появлению языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ. Характерной особенностью данной области применения вычислительной техники является наличие сложных алгоритмов обработки, которые применяются к простым по структуре данным, объем которых сравнительно невелик.
Вторая область, которая непосредственно относится к нашей теме, — это использование средств вычислительной техники в автоматических или автоматизированных информационных системах.
Информационная система представляет собой программно-аппаратный комплекс, обеспечивающий выполнение следующих функций:
1) надежное хранение информации в памяти компьютера;
2) выполнение специфических для данного приложения преобразований информации и вычислений;
3) предоставление пользователям удобного и легко осваиваемого интерфейса.
Обычно такие системы имеют дело с большими объемами информации, имеющей достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы, автоматизированные системы управления предприятиями, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т. д.
Вторая область использования вычислительной техники возникла несколько позже первой. Это связано с тем, что на заре вычислительной техники возможности компьютеров по хранению информации были очень ограниченными. В первых компьютерах использовались два вида устройств внешней памяти — магнитные ленты и барабаны. Емкость магнитных лент была достаточно велика, но по своей физической природе они обеспечивали последовательный доступ к данным. Магнитные же барабаны (они ближе всего к современным магнитным дискам с фиксированными головками) давали возможность произвольного доступа к данным, но имели ограниченный объем хранимой информации.
Между собственно физической базой данных (т.е. данными, которые реально хра нятся на компьютере) и пользователями системы располагается уровень программного обеспечения, который можно называть по-разному: диспетчер базы данных ( database manager ), сервер базы данных ( database server ) или, что более привычно, система управ ления базами данных, СУБД ( DataBase Management System — DBMS ). Все запросы пользователей на получение доступа к базе данных обрабатываются СУБД. Все имеющиеся средства добавления файлов (или таблиц), выборки и обновления данных в этих файлах или таблицах также предоставляет СУБД. Основная задача СУБД — дать поль зователю базы данных возможность работать с ней, не вникая во все подробности рабо ты на уровне аппаратного обеспечения. (Пользователь СУБД более отстранен от этих подробностей, чем прикладной программист, применяющий языковую среду про граммирования.) Иными словами, СУБД позволяет конечному пользователю рассмат ривать базу данных как объект более высокого уровня по сравнению с аппаратным обеспечением, а также предоставляет в его распоряжение набор операций, выражае мых в терминах языка высокого уровня (например, набор операций, которые можно выполнять с помощью языка SQL ).
Рекомендуемая литература: 1 [31-137], 6[29-37], 3[57-80],4 [13-23], 12 [34-56].
Лекция 2. Основные понятия и определения баз данных. СУБД
Цель: изучить базовые понятия, выявить основные структурные элементы баз данных и основные принципы, используемые при их разработке.
План:
1) Основные определения.
2) Понятие СУБД. Классификация
3) Пользователи банков и баз данных.
Современные авторы часто употребляют термины "банк данных" и "база данных" как синонимы, однако в общеотраслевых руководящих материалах по созданию банков данных Государственного комитета по науке и технике (ГКНТ), изданных в 1982 г., эти понятия различаются. Там приводятся следующие определения банка данных, базы данных и СУБД:
Определения.
Банк данных (БнД) — это система специальным образом организованных данных — баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
Под банком данных понимают интегрированное хранилище данных (баз данных), предназначенное для одновременного (совместного) обслуживания множества пользователей, под управлением программной системы, называемой СУБД.
База данных (БД) — именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области.
Под базой данных (БД) понимают совокупность хранящихся вместе данных при наличии такой минимальной избыточности, которая допускает их использование оптимальным образом для одного или нескольких приложений. Целью создания баз данных, как разновидности информационной технологии и формы хранения данных, является построение системы данных, не зависящих от принятых алгоритмов (программного обеспечения), применяемых технических средств и физического расположения данных в ЭВМ; обеспечивающих непротиворечивую и целостную информацию при нерегламентируемых запросах.
Приложения — программы, с помощью которых пользователи работают с базой данных. В общем случае с одной базой данных могут работать множество различных приложений.
Системы управления базами данных. После признания концепции БД прошло почти четыре года, прежде чем в 1966 году была создана первая СУБД. На рисунке 2.1 представлены основные функции СУБД.

Рисунок 2.1 - Основные функции СУБД
Определение. Системой управления базами данных (Data-base Management System)- СУБД называется совокупность языковых и программных средств, необходимых для создания, ведения и совместного
использования базы данных многими пользователями, и предоставляющих разработчикам и пользователям множество различных представлений данных.
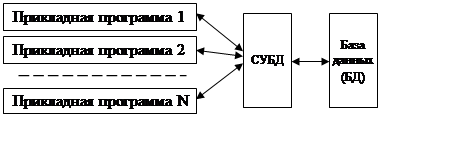
Рисунок 2.2 - Обеспечение независимости прикладных программ и базы данных
Использование базы данных предполагает работу с ней нескольких прикладных программ, решающих задачи разных пользователей. Работа с данными должна быть организована таким образом, чтобы данные и программы не зависели друг от друга. Роль интерфейса между прикладными программами и базой данных, обеспечивающей их независимость, играет программный комплекс – система управления базами данных (СУБД) (см. рисунок 2.2).
Общие принципы классификации СУБД.
СУБД - это программная оболочка, расширяющая функции операционной системы (OC), которая управляет доступом к базам данных и обеспечивает сервисные функции для пользователя.
В самом общем виде БД подразделяют на:
1) фактографические, которые хранят совокупность фактов интегрированных, возможно, из различных документов;
2) документальные, которые ориентированы на хранение документов;
3) документально-фактографические, которые обладают чертами и тех и других.
СУБД подразделяют:
1) по типу поддерживаемых моделей (по способу установления связей между данными) на: сетевые, иерархические, реляционные, объектно-ориентированные, объектно-реляционные;
2) по типу взаимодействия с обрабатывающей программой на: автоном-ные и с включающим языком программирования ( Access or FoxPro );
3) по уровню централизации обработки информации на: централизов-анные, децентрализованные, равноправные и смешанные;
4) по способу обработки данных и организации доступа к ним на: настольные СУБД и серверные СУБД;
5) по выполняемым функциям СУБД подразделяются на операционные и информационные;
6) по сфере применения СУБД подразделяются на универсальные и проблемно-ориентированные;
7) по используемому языку общения СУБД подразделяются на замкнутые, имеющие собственные самостоятельные языки общения пользователей с базами данных, и открытые, в которых для общения с базой данных используется язык программирования, расширенный операторами языка манипулирования данными;
8) по числу поддерживаемых уровней моделей данных СУБД подразделяются на одно-, двух-, трехуровневые системы;
9) по способу организации хранения данных и выполнения функций обработки базы данных подразделяются на централизованные и распределенные. Системы централизованных баз данных с сетевым доступом предполагают две основные архитектуры - файл-сервер или клиент-сервер.
Как правило, все или почти все данные СУБД:
1) реализованы для нескольких платформ;
2) обладают удобными административными утилитами;
3) поддерживают несколько сценариев репликаций;
4) поддерживают параллельную обработку данных в многопроцессорных системах;
5) поддерживают OLAP и создание хранилищ данных;
6) поддерживают выполнение распределенных запросов и транзакций;
7) позволяют использовать различные средства проектирования данных для создания своих объектов;
8) поддерживают средства разработки и генераторы отчетов как собственного производства, так и других производителей;
9) поддерживают как минимум публикацию данных в Internet.
Под транзакцией в самом общем случае понимают единицу работы, требуемой пользователем от БД, независимо от характера обработки. Чаще всего в результате обработки транзакции реализуется запрос пользователя либо на выборку данных из БД, либо на обновление БД, либо на выполнение каких-то иных действий над БД. При этом предполагается, что выполнение запроса сопровождается выполнением комплекса внутрисистемных действий СУБД, направленных на поддержание целостности данных, разграничение доступа и т.п.
Характеристиками СУБД
являются:
- производительность;
- обеспечение целостности данных на уровне баз данных;
- обеспечение безопасности данных;
- возможность работы в многопользовательских средах;
- возможность импорта и экспорта данных;
- обеспечение доступа к данным с помощью языка SQL;
- возможность составления запросов;
- наличие инструментальных средств разработки прикладных программ.
Производительность СУБД оценивается:
- временем выполнения запросов;
- скоростью поиска информации;
- временем импортирования баз данных из других форматов;
- скоростью выполнения операций (обновление, вставка, удаление);
- временем генерации отчета и другими показателями.
Безопасность данных достигается:
- шифрованием прикладных программ;
- шифрованием данных;
- защитой данных паролем;
- ограничением доступа к базе данных (к таблице, к словарю и т.д.).
Обеспечение целостности данных подразумевает наличие средств, позволяющих удостовериться, что информация в базе данных всегда остается корректной и полной. Целостность данных должна обеспечиваться независимо от того, каким образом данные заносятся в память (в интерактивном режиме, посредством импорта или с помощью специальной программы).
Этапами работы в СУБД являются:
- создание структуры базы данных, т.е. определение перечня полей, из которых состоит каждая запись таблицы, типов и размеров полей (числовой, текстовый, логический и т.д.), определение ключевых полей для обеспечения необходимых связей между данными и таблицами;
- ввод и редактирование данных в таблицах баз данных с помощью представляемой по умолчанию стандартной формы в виде таблицы и с помощью экранных форм, специально создаваемых пользователем;
- обработка данных, содержащихся в таблицах, на основе запросов и на основе программы;
- вывод информации из ЭВМ с использованием отчетов и без использования отчетов.
Пользователи банков и баз данных. Как любой программно-организационно-техничеcкий комплекс, банк данных существует во времени и в пространстве. Он имеет определенные стадии своего развития:
1) Проектирование.
2) Реализация.
3) Эксплуатация.
4) Модернизация и развитие.
5) Полная реорганизация.
Определим основные категории пользователей и их роль в функционировании банка данных:
1) Конечные пользователи. Это основная категория пользователей, в интересах которых и создается банк данных.
2) Администраторы банка данных. Это группа пользователей, которая на начальной стадии разработки банка данных отвечает за его оптимальную организацию с точки зрения одновременной работы множества конечных пользователей, на стадии эксплуатации отвечает за корректность работы данного банка информации в многопользовательском режиме.
3) Разработчики и администраторы приложений ( прикладные программисты), которые отвечают за написание при кладных программ, использующих базу данных.
Система БД поддерживает одновременно множество транзакций. Именно правильное выполнение всех таких транзакций и обеспечивает менеджер транзакций. Правильное выполнение транзакций обеспечивается ACID -свойствами ( atomicity , consistency , isolation , durability ).
Архитектура клиент/сервер. Во многих вариантах современного ПО реализуется архитектура клиент/сервер: один процесс (клиент) посылает запрос для выполнения другому процессу (серверу). Как правило, БД часто разделяется на процесс сервера и несколько процессов клиента.
Рекомендуемая литература: 1 [216-222], 3 [45-51], 5 [67-89].
Лекция 3. Архитектура базы данных. Физическая и логическая независимость
Цель: рассморение различных архитектурных решений в разрезе моделей.
План:
1) Модель с централизованной архитектурой.
2) Архитектура «файл-сервер».
3) Архитектура «клиент-сервер».
4) Концепция трех схем
СУБД носит централизованный характер, что предполагает необходимость существования некоторого лица (группы лиц), на которое возлагаются функции администрирования данными, хранимыми в базе.
По технологии обработки данных БД делятся на централизованные БД и распределённые БД.
Централизованная БД хранится в памяти одной вычислительной системы (применяется в локальных сетях ПК). Централизованные БД могут быть с сетевым доступом.
Централизованные базы данных с сетевым доступом могут иметь следующую архитектуру:
1) архитектура «файл-сервер» ;
2) централизованная архитектура - клиент-сервер базы данных;
3) распределенная модель вычислений:
- архитектура «клиент-сервер» ;
- трехуровневая архитектура.
3.1 Модель с централизованной архитектурой
При использовании этой технологии база данных, СУБД и прикладная программа (приложение) располагаются на одном компьютере (мэйнфрейме или персональном компьютере). Для такого способа организации не требуется поддержка сети, и все сводится к автономной работе. Работа построена следующим образом:
1) База данных в виде набора файлов находится на жестком диске компьютера.
2) На том же компьютере установлены СУБД и приложение.
3) Пользователь запускает приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к БД на выборку/обновление информации.
4) Все обращения к БД идут через СУБД, которая инкапсулирует внутри себя все сведения о физической структуре БД.
5) СУБД инициирует обращения к данным, обеспечивая выполнение запросов пользователя.
6) Результат СУБД возвращает в приложение.
3.2 Модель вычислений с сетью и файловым сервером (архитектура «файл-сервер»)
Увеличение сложности задач, появление персональных компьютеров и локальных вычислительных сетей явились предпосылками появления новой архитектуры «файл-сервер». Эта архитектура баз данных с сетевым доступом предполагает назначение одного из компьютеров сети в качестве выделенного сервера, на котором будут храниться файлы базы данных. В соответствии с запросами пользователей файлы с файл-сервера передаются на рабочие станции пользователей, где и осуществляется основная часть обработки данных. Центральный сервер выполняет в основном только роль хранилища файлов, не участвуя в обработке самих данных.
Работа построена следующим образом:
1) База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (файлового сервера).
2) Существует локальная сеть, состоящая из клиентских компьютеров, на каждом из которых установлены СУБД и приложение для работы с БД.
3) На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к БД на выборку/обновление информации.
4) Все обращения к БД идут через СУБД, которая инкапсулирует внутри себя все сведения о физической структуре БД, расположенной на файловом сервере.
5) СУБД инициирует обращения к данным, находящимся на файловом сервере, в результате которых часть файлов БД копируется на клиентский компьютер и обрабатывается, что обеспечивает выполнение запросов пользователя (осуществляются необходимые операции над данными).
6) При необходимости (в случае изменения данных) данные отправляются назад на файловый сервер с целью обновления БД.
7) Результат СУБД возвращает в приложение.
8) Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.
3.3 Распределенная модель вычислений (архитектура «клиент-сервер»)
Использование архитектуры «клиент-сервер» предполагает наличие некоторого количества компьютеров, объединенных в сеть, один из которых выполняет особые управляющие функции (является сервером сети).
Архитектура «клиент-сервер» разделяет функции приложения пользователя (называемого клиентом) и сервера. Приложение-клиент формирует запрос к серверу, на котором расположена БД, на структурном языке запросов SQL (Structured Query Languague), являющемся промышленным стандартом в мире реляционных БД. Удаленный сервер принимает запрос и переадресует его SQL-серверу БД.
В результате работа построена следующим образом:
1) База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (сервера сети).
2) СУБД располагается также на сервере сети.
3) Существует локальная сеть, состоящая из клиентских компьютеров, на каждом из которых установлено клиентское приложение для работы с БД.
4) СУБД инкапсулирует внутри себя все сведения о физической структуре БД, расположенной на сервере.
5) СУБД инициирует обращения к данным, находящимся на сервере, в результате которых на сервере осуществляется вся обработка данных и лишь результат выполнения запроса копируется на клиентский компьютер.
В архитектуре «клиент-сервер» используются так называемые «удаленные» (или «промышленные») СУБД. Промышленными они называются из-за того, что именно СУБД этого класса могут обеспечить работу информационных систем масштаба среднего и крупного предприятия, организации, банка.
К разряду промышленных СУБД принадлежат Oracle, Gupta, Informix , Sybase , MS SQL Server , DB 2, InterBase и ряд других.
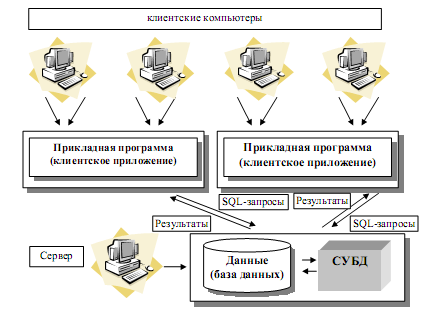
Рисунок 3.1- Архитектура «клиент-сервер»
3.4 Распределенная модель вычислений (Клиент-сервер. Трехзвенная (многозвенная) архитектура)
Конец 90-х годов был знаменован развитием сети Интернет. Сегодня мы смело можем сказать, что Интернет, как ранее вычислительная техника, проник или активно проникает во многие сферы человеческой жизни – экономику, науку, технику, образование.
Один из основных моментов – снижение затрат на организацию рабочих мест пользователей. Для полноценной работы требуется лишь возможность установки операционной системы и Web-браузера.
Второй момент – устранение бесконечных трудностей с обновлением клиентских приложений. Когда Интернет-магазин меняет свое программное
обеспечение, это никак не сказывается на Вас, как обычном пользователе.
Для разрешения описанных выше проблем появилось некоторое развитие архитектуры «клиент-сервер». Теперь при изменении бизнес-логики более нет необходимости изменять клиентские приложения и обновлять их у всех пользователей. Кроме того, максимально снижаются требования к аппаратуре пользователей.
По способу доступа к данным БД разделяются на БД с локальным и удаленным доступом.
БД с локальным доступом называется, если эта вычислительная система является компонентом сети ЭВМ, возможен распределённый доступ к такой базе. Такой способ использования БД часто применяют в локальных сетях ПК.
БД с удалённым (сетевым) доступом называется когда, части БД могут пересекаться или даже дублироваться, но хранятся в различных ЭВМ вычислительной сети.
3.5 Концепция трех схем
В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД.
Архитектура ANSI / SPARC включает три уровня: внутренний, внешний и концептуальный.
1. Внешний уровень (называемый также пользовательским логическим) наиболее бли зок к пользователям, т.е. связан со способами представления данных для отдель ных пользователей. Уровень внешних моделей — самый верхний уровень, где каждая модель имеет свое "видение" данных. Этот уровень определяет точку зрения на БД отдельных приложений.
2. Концептуальный уровень (называемый также общим логическим или просто логиче ским, без дополнительного определения) является "промежуточным" уровнем ме жду двумя первыми. Концептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных.
3. Внутренний уровень (называемый также физическим) наиболее близок к физич ескому хранилищу информации, т.е. связан со способами сохранения информации на физических устройствах. Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации.
Рекомендуемая литература: 6[34-44], 7 [45-67].
Лекция 4. Модели данных
Цели: рассмотреть различные представления о данных (различных моделей) у разных групп лиц, работающих с данными в разрезе различных моделей данных.
План:
1) Иерархическая и сетевая модель данных.
2) Реляционная модель данных.
3) Отношение, атрибут.
4) Реляционное исчисление.
5) Достоинства и недостатки реляционной модели.
1. Иерархический подход к организации баз данных. Иерархические базы данных имеют форму деревьев с дугами-связями и узлами-элементами данных. Иерархическая структура предполагала неравноправие между данными - одни жестко подчинены другим.
2. Сетевая модель данных. В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Однако унаследованы многие недостатки иерархической и главный из них- необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе.
3. Реляционная модель. Реляционная модель появилась вследствие стремления сделать базу данных как можно более гибкой. Данная модель предоставила простой и эффективный механизм поддержания связей данных. Все данные в модели представляются в виде таблиц. Реляционная модель - единственная из всех обеспечивает единообразие представления данных. И сущности, и связи этих самых сущностей представляются в модели совершенно одинаково - таблицами.
Полнота языка в приложении к реляционной модели означает, что он должен выполнять любую операцию реляционной алгебры или реляционного исчисления (полнота последних доказана математически Э.Ф. Коддом).
Реляционной модели требует от реляционной модели поддержания некоторых ограничений целостности . Одно из таких ограничений утверждает, что каждая строка в таблице должна иметь некий уникальный идентификатор, называемый первичным ключом.
4. Объектно-ориентированная модель. Новые области использования вычислительной техники, такие как научные исследования, автоматизированное проектирование и автоматизация учреждений, потребовали от баз данных способности хранить и обрабатывать новые объекты - текст, аудио- и видеоинформацию, а также документы. Основные трудности объектно-ориентированного моделирования данных проистекают из того, что такого развитого математического аппарата, на который могла бы опираться общая объектно-ориентированная модель данных , не существует. Поэтому до сих пор нет базовой объектно-ориентированной модели. С другой стороны, некоторые авторы утверждают, что общая объектно-ориентированная модель данных в классическом смысле не может быть определена именно по причине непригодности классического понятия модели данных к парадигме объектной ориентированности. Несмотря на преимущества объектно-ориентированных систем - реализация сложных типов данных , связь с языками программирования и т.п. - на ближайшее время превосходство реляционных СУБД гарантировано.
4.1 Иерархическая модель базы данных
Иерархические базы данных - самая ранняя модель представления сложной структуры данных. Информация в иерархической базе организована по принципу древовидной структуры, в виде отношений "предок-потомок". Каждая запись может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных - невозможность реализовать отношения "многие-ко-многим", а также ситуации, когда запись имеет несколько предков.
4.2 Сетевая модель базы данных
На разработку этого стандарта большое влияние оказал американский ученый Ч.Бахман. Основные принципы сетевой модели данных были разработаны в середине 60-х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных ( COnference on DAta SYstem Languages) CODASYL (1971 г.).
Сетевая модель данных определяется в тех же терминах, что и иерархическая . Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между записью-владельцем и записью-членом также имеет вид 1:N.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа.
4.3 Реляционные объекты данных
Отношение соответствует тому, что мы обычно называем таблицей. Кортеж соответствует экземпляру записи, атрибут – полю таблицы, степень – количеству атрибутов, кардинальное число – количеству кортежей.
Домен – это общее множество значений, из которых берутся конкретные значения определенного атрибута некоторого отношения.
 Скалярное
значение
(скаляр) – это наименьшая
семантическая единица данных, которая является отдельным значением данных. У
скаляров нет внутренней структуры, т.е. они не разложимы в данной реляционной
модели. На самом деле, в других контекстах скаляры могут иметь внутреннюю
структуру (например, фамилия состоит из букв), но для конкретной таблицы это
разложение не имеет смысла, т.к. теряется его значение. Каждый атрибут должен
быть определён на единственном домене. Например, атрибут
StudentID
определён на домене {1, 2, 3}, атрибут
GroupID
– на
домене {1, 2, 3}, но это будут разные домены, хотя и содержат одинаковые
элементы.
Скалярное
значение
(скаляр) – это наименьшая
семантическая единица данных, которая является отдельным значением данных. У
скаляров нет внутренней структуры, т.е. они не разложимы в данной реляционной
модели. На самом деле, в других контекстах скаляры могут иметь внутреннюю
структуру (например, фамилия состоит из букв), но для конкретной таблицы это
разложение не имеет смысла, т.к. теряется его значение. Каждый атрибут должен
быть определён на единственном домене. Например, атрибут
StudentID
определён на домене {1, 2, 3}, атрибут
GroupID
– на
домене {1, 2, 3}, но это будут разные домены, хотя и содержат одинаковые
элементы.
Рисунок 4.1- Основные элементы реляционной БД
Отношение можно рассматривать с двух сторон:
1) переменная отношения – это обычная переменная, т.е. именованный объект, значение которого может изменяться;
2) значение отношения – это значение этой переменной в конкретный момент времени.
Отношение
R,
заданное на множестве доменов
D
1
,
D
2
, …,
Dn
, которые не обязательно различны, содержит две части:
заголовок и тело. Заголовок содержит фиксированное множество пар
![]() , где
Ai
– имя атрибута. Тело содержит множество кортежей, каждый из которых в
свою очередь содержит множество значений
Zji
,
где
i
– номер атрибута,
j
– номер
кортежа.
, где
Ai
– имя атрибута. Тело содержит множество кортежей, каждый из которых в
свою очередь содержит множество значений
Zji
,
где
i
– номер атрибута,
j
– номер
кортежа.
Свойства отношений:
1) нет одинаковых кортежей, поскольку тело отношений представляет собой множество;
2) кортежи неупорядочены, т.е. нет таких понятий, как «первый» или «десятый» кортеж, нет понятий «предыдущий» и «следующий»;
3) атрибуты неупорядочены, т.к. заголовок отношения тоже определён как множество;
4) все значения атрибутов неделимы, т.к. домен содержит неделимые элементы.
Такие отношения, которые не содержат делимых атрибутов, называются нормализованными, или представленными в первой нормальной форме.
Пусть R – некоторое отношение. Тогда потенциальный ключ K для R – это подмножество атрибутов R, обладающих следующими свойствами:
1) уникальность, т.е. нет двух различных кортежей в текущем значении переменной отношения R с одинаковым значением K;
2) неизбыточность, т.е. никакое из подмножеств K не обладает свойством уникальности.
Это свойство применимо только для случая, если потенциальный ключ состоит более чем из одного атрибута. Например, нельзя назначить потенциальным ключом совокупность полей StudentID и Name , иначе этот ключ будет избыточным.
Могут существовать отношения, в которых единственным естественным потенциальным ключом будет комбинация всех атрибутов, но это может быть неудобно. Тогда вводят искусственный потенциальный ключ. Например, в таблице Students совокупность атрибутов { Name , GroupID , Birthdate } представляет собой ключ, но удобнее ввести искусственный ключ – StudentID.
|
StudentID |
Name |
GroupID |
BirthDate |
|
1 |
Казаков Петр |
2 |
23.04.1990 |
|
2 |
Васильев Иван |
1 |
11.05.1991 |
|
4 |
Шишкина Дарья |
2 |
23.09.1991 |
Потенциальные ключи предназначены для обеспечения основного механизма адресации на уровне кортежей, т.е. достаточно указать значение потенциального ключа, по которому можно найти любой кортеж.
Первичные и альтернативные ключи. Отношение может иметь более одного потенциального ключа, но один из них всегда выбирается в качестве первичного, остальные потенциальные ключи будут в этом случае называться альтернативными.
Внешние ключи . Пусть R2 – отношение. Тогда внешний ключ FK в отношении R2 – это подмножество множества атрибутов R 2 такое, что:
1) существует базовое отношение R1 с потенциальным ключом CK;
2) каждое значение FK в текущем значении R2 всегда совпадает со значением CK некоторого кортежа в текущем значении R 1 .
Из данного определения можно вывести такие следствия:
1) по определению каждое значение внешнего ключа должно являться значением соответствующего потенциального ключа, но обратное не требуется, т.е. потенциальный ключ может содержать значения, которые в данный момент не являются значением внешнего ключа;
2) данный внешний ключ будет составным тогда и только тогда, когда соответствующий потенциальный ключ тоже составной;
3) каждый атрибут, входящий в данный внешний ключ, должен быть опре--делён на том же домене, что и соответствующий атрибут потенциального ключа;
4) R1 и R2 не обязательно различны.
Рекомендуемая литература: 1, 2, 3.
Лекция 5. Проектирование реляционных баз данных
Цель: в лекции рассматриваются принципы проектирования в базах данных. Описываются основные этапы проектирования базы данных, рассматривается жизненный цикл их проектирования.
План:
1) Этапы проектирования БД.
2) Проектирование данных с помощью модели "сущность-связь".
3) Диаграммы сущность-связь.
При проектировании информационной системы необходимо провести анализ целей данной системы и выявить требования к ней отдельных пользователей. Сбор данных начинается с изучения сущностей предметной области, процессов, использующих эти сущности, и связей между ними [3, 5-7] и заканчивается построением ER-модели, являющейся базисом формализованной модели данных. Основная цель проектирования базы данных - это сокращение избыточности хранимых данных, а следовательно, экономия объема используемой памяти, уменьшение затрат на многократные операции обновления избыточных копий и устранение возможности возникновения противоречий из-за хранения в разных местах сведений об одном и том же объекте [1-6, 7-9].
В теории проектирования информационных систем предметную область (или, если угодно, весь реальный мир в целом) принято рассматривать в виде трех представлений:
1) представление предметной области в том виде, как она реально существует;
2) как ее воспринимает человек (имеется в виду проектировщик БД);
3) как она может быть описана с помощью символов.
На каждом уровне рассматривается ограниченное число элементов (обычно от 3 до 6-8), каждый из которых в свою очередь может быть декомпозирован на составляющие детали на следующем уровне. При этом соблюдаются строгие формальные правила записи информации. Такая технология получила название CASE (Computer Aided Software Engeneering - создание программного обеспечения с помощью компьютера). Рассмотрим более подробно этапы проектирования БД.
5.1 Системный анализ предметной области
С точки зрения проектирования БД в рамках системного анализа, необходимо осуществить первый этап, то есть провести подробное словесное описание объектов предметной области и реальных связей, которые присутствуют между описываемыми объектами. Желательно, чтобы данное описание позволяло корректно определить все взаимосвязи между объектами предметной области.
В общем случае существуют два подхода к выбору состава и структуры предметной области:
1) Функциональный подход — он реализует принцип движения "от задач" и применяется тогда, когда заранее известны функции некоторой группы лиц и комплексов задач, для обслуживания информационных потребностей которых создается рассматриваемая БД.
2) Предметный подход — когда информационные потребности будущих пользователей БД жестко не фиксируются. Они могут быть многоаспектными и весьма динамичными.
Проектирование с использованием метода "сущность-связь" - Метод "сущность–связь" (entity–relation, ER–method) является комбинацией двух предыдущих и обладает достоинствами обоих. Чаще всего на практике рекомендуется использовать некоторый компромиссный вариант, который, с одной стороны, ориентирован на конкретные задачи, а с другой стороны, учитывает возможность наращивания новых приложений.
При проектирование реляционной БД должны быть решены следующие проблемы:
1) С учетом семантики предметной области необходимо наилучшим способом представить объекты предметной области в виде абстрактной модели данных, т.е. определиться со схемой БД: из каких отношений должны состоять БД; какие атрибуты должны быть у этих отношений; каковы связи между отношениями.
2) Обеспечить эффективность выполнения запросов к базе данных (физическое проектирование БД).
Корректной называется схема БД, в которой отсутствуют нежелательные зависимости между атрибутами отношений. Процесс разработки корректной схемы БД называется логическим проектированием.
Проектирование схемы БД можно выполнить двумя методами:
1) Метод декомпозиции (разбиения) – исходное множество отношений, входящих в схему БД заменяется другим множеством отношений, являющих-ся проекциями исходных отношений! Число отношений возрастает.
2) Метод синтеза – компоновка схемы БД из заданных исходных элементарных зависимостей между объектами предметной области.
5.2 Инфологическое (семантическое) моделирование предметной области
Инфологическое (логическое) моделирование применяется на втором этапе проектирования БД, то есть после системного анализа предметной области. На этапе системного анализа были сформированы понятия о предметах, фактах и событиях, которыми будет оперировать БД. Наибольшее распространение получила модель "сущность-связь" (entity-relationship model, ER-модель), предложенная в 1976 г. Питером Пин-Шэн Ченом. Это модель является концептуальной моделью, т.е. не учитывает особенностей конкретной СУБД. Из модели "сущность-связь" могут быть получены все основные фактографические модели данных.
5.3 Выбор СУБД и других программных средств
Выбор СУБД является одним из важнейших моментов в разработке проекта БД, так как он принципиальным образом влияет на весь процесс проектирования БД и реализацию информационной системы. Теоретически при выборе СУБД нужно принимать во внимание десятки факторов.
5.4 Логическое проектирование БД
На этапе логического проектирования разрабатывается логическая структура БД, соответствующая логической модели ПО. Решение этой задачи существенно зависит от модели данных, поддерживаемой выбранной СУБД. Результатом выполнения этого этапа являются схемы БД концептуального и внешнего уровней архитектуры, составленные на языках определения данных (DDL, Data Definition Language), поддерживаемых данной СУБД.
5.5 Физическое проектирование БД
Этап физического проектирования заключается в увязке логической структуры БД и физической среды хранения с целью наиболее эффективного размещения данных, т.е. отображении логической структуры БД в структуру хранения. Решается вопрос размещения хранимых данных в пространстве памяти, выбора эффективных методов доступа к различным компонентам "физической" БД. Результаты этого этапа документируются в форме схемы хранения на языке определения данных (DDL).
5.6 Диаграммы сущность-связь
Наиболее распространенным средством моделирования данных являются диаграммы "сущность-связь" (ERD), нотация которых была впервые введена П. Ченом в 1976 г . и получила дальнейшее развитие в работах Ричарда Баркера. Различные CASE-средства используют несколько отличающиеся друг от друга нотации ERD. Одна из наиболее распространенных нотаций предложена Баркером (Oracle Designer). В CASE-средстве SilverRun используется один из вариантов нотации Чена. CASE-средства ERwin, ER/Studio, Design / IDEF используют методологию IDEF 1Х.
Модель Сущность-Связь (ER-модель) (entity-relationship model (ERM)) — модель данных , позволяющая описывать концептуальные схемы . Представляет собой графическую нотацию, основанную на блоках и соединяющих их линиях, с помощью которых можно описывать объекты и отношения между ними какой-либо другой модели данных.
ER-модель является одной из самых простых визуальных моделей данных (графических нотаций). Она позволяет обозначить структуру «крупными мазками», в общих чертах. Это общее описание структуры называется ER-диаграммой или онтологией выбранной предметной области. Диаграммы "сущность-связь" включают (сущность, атрибут и связи).
Сущность (Entity) - любой объект, событие или концепция, имеющие существенное значение для предметной области, и информация о которых должна сохраняться. Каждая сущность является множеством подобных объектов, называемых экземплярами.
Атрибут (Attribute) - любая характеристика сущности, значимая для рассматриваемой предметной области. Атрибут предназначен для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности.
Связь (Relationship) - поименованное логическое соотношение между двумя сущностями, значимое для рассматриваемой предметной области.
Сущность является независимой, если каждый экземпляр ее может быть однозначно идентифицирован без определения его отношений с другими сущностями. Независимая сущность изображается прямоугольником с четко выраженными углами. Сущность является зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности. Зависимая сущность изображается прямоугольником со скругленными углами.
Первичный ключ (Primary Key) - это атрибут или группа атрибутов, однозначно идентифицирующих экземпляр сущности. На диаграмме первичные ключи размещаются выше горизонтальной линии. Ключ может быть сложным, т.е. состоять из нескольких атрибутов.
Внешние ключи (Foreign Key) создаются автоматически, когда сущности соединяются связью (миграция ключа). Связи между таблицами реляционной БД представляются одинаковыми ключами в таблицах.
Связи (логические отношения между сущностями) именуются глаголами или глагольными фразами. Имена связей выражают некоторые ограничения или бизнес-правила и облегчают чтение диаграмм.
Нотация IDEF1X о бозначения сущностей:
|
Элемент диаграммы |
Обозначает |
||
|
|
независимая сущность |
||
|
|
зависимая сущность |
Список атрибутов приводится внутри прямоугольника, обозначающего сущность. Атрибуты, составляющие ключ сущности, группируются в верхней части прямоугольника и отделяются горизонтальной чертой.
Обозначения связей:
|
Элемент диаграммы |
Обозначает |
|
|
идентифицирующая связь |
|
|
неидентифицирующая связь> |
Рекомендуемая литература: 6 , 7 , 8.
Лекция 6. Проектирование БД методом нормальных форм
Цель: показать возможность эффективного использования формальных методов построения оптимальной (по определенным показателям) структуры реляционной базы данных путем нор-мализации схем отношений.
План:
1) Понятие нормализации отношений.
2) Нормальные формы.
Классическое проектирование БД связано с теорией нормализации, которая основана на анализе функциональных зависимостей между атрибутами отношений. Функциональные зависимости определяют устойчивые отношения между объектами и их свойствами в рассматриваемой предметной области.
Метод декомпозиции представляет собой процесс последовательной нормализации схем отношений: каждая новая итерация соответствует нормальной форме более высокого порядка и обладает лучшими свойствами по сравнению с предыдущей. Таким образом, изначально предполагается существование универсального отношения, содержащего все атрибуты БД, затем на основе анализа связей между атрибутами осуществляется декомпозиция универсального отношения, т.е. переход к нескольким отношениям меньшей размерности, причем исходное отношение должно восстанавливаться с помощью операции естественного соединения.
В теории реляционных БД обычно выделяют следующие нормальные формы:
1) первая нормальная форма (1 NF );
2) вторая нормальная форма (2 NF );
3) третья нормальная форма (3 NF );
4) нормальная форма Бойса-Кодда ( BCNF );
5) четвертая нормальная форма (4 NF );
6) пятая нормальная форма или форма проекции - соединения (5 NF или PYNF ).
Основные свойства нормальных форм:
1) каждая следующая нормальная форма в некотором смысле лучше предыдущей;
2) при переходе к следующей нормальной форме свойства предыдущих нормальных свойств сохраняются.
Схемы БД называются эквивалентными, если содержание исходной БД можно получить естественным соединением отношений, входящих в результирующую схему.
6.1 Понятие нормализации отношений
Одни и те же данные могут группироваться в таблицы (отношения) различными способами, т.е. возможна организация различных наборов отношений взаимосвязанных информационных объектов. Группировка атрибутов в отношениях должна быть рациональной, т.е. минимизирующей дублирование данных и упрощающей процедуры их обработки и обновления.
Нормализация отношений - формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных. [ 2 ]
Е. Коддом выделены три нормальные формы отношений и предложен механизм, позволяющий любое отношение преобразовать к третьей (самой совершенной) нормальной форме .
Зависимости между атрибутами. Рассмотрим основные виды зависимостей между атрибутами отношений: функциональные, многозначные и транзитивные.
Понятие функциональной зависимости является базовым, так как на его основе формулируются определения всех остальных видов зависимостей.
Частичной зависимостью называется зависимость не ключевого атрибута от части составного ключа. Атрибут С зависит от атрибута А транзитивно, если для атрибутов А, В, С выполняются условия А -> В и В -> С, но обратная зависимость отсутствует.
Определение многозначной зависимости . В отношении R атрибут В многозначно зависит от атрибута А, если каждому значению b соответствует множество значений В, не связанных с другими атрибутами из R. Многозначные зависимости могут быть «один ко многим» (1:М), «многие к одному» (М:1) или «многие ко многим» (М:М), обозначаемые соответственно: А->>В, А<<-В и А<<—>>В.
6.2 Нормальные формы
Процесс проектирования БД с использованием метода нормальных форм является, итерационным и заключается в последовательном переводе отношений из первой нормальной формы в нормальные формы более высокого порядка по определенным правилам.
Каждая следующая нормальная форма ограничивает определенный тип функциональных зависимостей, устраняет соответствующие аномалии при выполнении операций над отношениями БД и сохраняет свойства предшествующих нормальных форм.
Первая нормальная форма . Отношение находится в 1НФ, если все его атрибуты атомарны (являются простыми, т.е.имеют единственное значение). Исходное отношение строится таким образом, чтобы оно было в 1НФ.
Вторая нормальная форма . Отношение находится в 2НФ, если оно находится в 1 НФ и каждый не ключевой атрибут функционально полно зависит от первичного ключа (составного).
Или другими словами: в 2NF нет неключевых атрибутов, зависящих от части составного ключа (+ выполняются условия 1NF ).
Для устранения частичной зависимости и перевода отношения в 2НФ необходимо, используя операцию проекции, разложить его на два отношения следующим образом:
1) построить проекцию без атрибутов, находящихся в частичной функциональной зависимости от первичного ключа;
2) построить проекции на части составного первичного ключа и атрибуты, зависящие от этих частей.
В результате получили два отношения R1 и R2 в 2НФ. В отношении R1 первичный ключ является составным и состоит из атрибутов ФИО. Предм, Группа. Напомним, что данный ключ в отношении R1 получен в предположении, что каждый преподаватель в одной группе по одному предмету может либо читать лекции, либо проводить практические занятия. В отношении R2 ключ ФИО.
Исследование отношений R1 и R2 показывает, что переход к 2НФ позволил исключить явную избыточность данных в таблице R2 — повторение строк со сведениями о преподавателях. В R2 по-прежнему имеет место неявное дублирование данных.
R 1:тав1( ФИО, Предм, Группа, ВидЗан)
R 2:тав2( ФИО, Должн, Оклад, Стаж, Д_Стаж, Каф)
Для дальнейшего совершенствования отношения необходимо преобразовать его в ЗНФ.
Третья нормальная форма. Отношение находится в ЗНФ, если оно находится в 2НФ и каждый не ключевой атрибут не транзитивно зависит от первичного ключа.
Только после приведения отношения к 3NF имеет смысл говорить о наличие первичного ключа.
Если в отношении R1 транзитивные зависимости отсутствуют, то в отношении R2 они есть:
ФИО->Должн->Оклад, ФИО->Оклад->Должн, ФИО->Стаж ->Д_Стаж
Транзитивные зависимости также порождают избыточное дублирование информации в отношении. Устраним их. Для этого используя операцию проекции на атрибуты, являющиеся причиной транзитивных зависимостей, преобразуем отношение R2, получив при этом отношения R3, R4 и R5, каждое из которых находится в ЗНФ.
R 3:тав3( ФИО, Должн, Стаж, Каф), R 4:тав4( Должн, Оклад), R 5:тав5( Стаж, Д_Стаж). Результатом проектирования является БД, состоящая из следующих таблиц: R2, R3, R4, R5. В полученной БД имеет место необходимое дублирование данных, но отсутствует избыточное.
Итак, процесс нормализации отношений методом нормальных форм предполагает последовательное удаление из исходного отношения следующих меж атрибутных зависимостей:
1) частичных зависимостей не ключевых атрибутов от ключа (2НФ);
2) транзитивных зависимостей не ключевых атрибутов от ключа (ЗНФ);
3) зависимости ключей (атрибутов составных ключей) от не ключевых атрибутов (БКНФ).
Определение нормальной формы Бойса-Кодда:
Отношение находится в BCNF, если оно находится во 3НФ и в ней отсутствуют зависимости атрибутов первичного ключа от неключевых атрибутов.
Ситуация, когда отношение будет находиться в 3NF, но не в BCNF, возникает при условии, что отношение имеет два (или более) возможных ключа , которые являются составными и имеют общий атрибут. На практике такая ситуация встречается достаточно редко, для всех прочих отношений 3NF и BCNF эквивалентны.
Многозначные зависимости и четвертая нормальная форма (4NF).
Четвертая нормальная форма касается отношений, в которых имеются повторяющиеся наборы данных. Декомпозиция, основанная на функциональных зависимостях, не приводит к исключению такой избыточности. В этом случае используют декомпозицию, основанную на многозначных зависимостях.
Многозначная зависимость является обобщением функциональной зависимости и рассматривает соответствия между множествами значений атрибутов.
Определение четвертой нормальной формы.
Отношение находится в 4NF если оно находится в BCNF и в нем отсутствуют многозначные зависимости, не являющиеся функциональными зависимостями. То есть, таблица находится в 4NF, если все ее многозначные зависимости являются функциональными.
Когда мы рассматривали функциональные зависимости, то каждому значению детерминанта соответствовало только одно значение зависимого от него атрибута. При рассмотрении многозначных зависимостей мы выделяем случаи, когда одному значению некоторого атрибута соответствует устойчиво постоянное множество значений другого атрибута.
Зависимости по соединению и пятая нормальная форма (5NF).
Определение пятой нормальной формы : Таблица находится в 5NF, если она находится в 4NF и любая многозначная зависимость соединения в ней является тривиальной.
Другими словами, каждая проекция такого отношения содержит не менее одного возможного ключа и не менее одного неключевого атрибута.
Пятая нормальная форма в большей степени является теоретическим исследованием и практически не применяется при реальном проектировании баз данных. Это связано со сложностью определения самого наличия зависимостей «проекции — соединения», поскольку утверждение о наличии такой зависимости должно быть сделано для всех возможных состояний БД.
Очень редко таблица, находящаяся в 4NF, не соответствует 5NF.
Рекомендуемая литература: 1, 2, 3, 4, 12.
Лекция 7. Целостность и надежность данных
Цель: рассмотреть вопросы обеспечения безопасности баз данных с точко зрения целостности данных в реляционных СУБД.
План:
1) Требования по безопасности данных, предъявляемые к БД.
2) Механизмы обеспечения целостности в БД.
3) Типы ограничений целостности, ссылочная целостность, умолчания, правила.
4) Транзакции.
О сновные требования по безопасности данных, предъявляемые к БД и СУБД, во многом совпадают с требованиями, предъявляемыми к безопасности данных в компьютерных системах – контроль доступа, криптозащита, проверка целостности, протоколирование и т.д.
П од управлением целостностью в БД понимается защита данных в БД от неверных (в отличие от несанкционированных) изменений и разрушений . Поддержание целостности БД состоит в том, чтобы обеспечить в каждый момент времени корректность (правильность) как самих значений всех элементов данных, так и взаимосвязей между элементами данных в БД . С поддержанием целостности связаны следующие основные требования.
1. Обеспечение достоверности. В каждый элемент данных информация заносится точно в соответствии с описанием этого элемента .Должны быть предусмотрены механизмы обеспечения устойчивости элементов данных и их логических взаимосвязей к ошибкам или неквалифицированным действиям пользователей.
2. Управление параллелизмом. Нарушение целостности БД может возникнуть при одновременном выполнении операций над данными, каждая из которых в отдельности не нарушает целостности БД . Поэтому должны быть предусмотрены механизмы управления данными, обеспечивающие поддержание целостности БД при одновременном выполнении нескольких операций.
3. Восстановление. Хранимые в БД данные должны быть устойчивы по отношению к неблагоприятным физическим воздействиям (аппаратные ошибки, сбои питания и т .п .) и ошибкам в программном обеспечении . Поэтому должны быть предусмотрены механизмы восстановления за предельно короткое время того состояния БД, которое было перед появлением неисправности.
В опросы управления доступом и поддержания целостности БД тесно соприкасаются между собой, и во многих случаях для их решения используются одни и те же механизмы.
Управление доступом в базах данных. Б ольшинство систем БД представляют собой средство единого централизованного хранения данных. Это значительно сокращает избыточность данных, упрощает доступ к данным и позволяет более эффективно защищать данные. Однако, в технологии БД возникает ряд проблем, связанных, например, с тем, что различные пользователи должны иметь доступ к одним данным и не иметь доступа к другим . Поэтому, не используя специальные средства и методы, обеспечить надежное разделение доступа в БД практически невозможно.
Б ольшинство современных СУБД имеют встроенные средства, позволяющие администратору системы определять права пользователей по доступу к различным частям БД, вплоть до конкретного элемента. При этом имеется возможность не только предоставить доступ тому или иному пользователю, но и указать разрешенный тип доступа: что именно может делать конкретный пользователь с конкретными данными (читать, модифицировать, удалять и т. п.), вплоть до реорганизации всей БД Таблицы (списки) управления доступом широко используются в компьютерных системах, например, в ОС для управления доступом к файлам. Особенность использования этого средства для защиты БД состоит в том, что в качестве объектов защиты выступают не только отдельные файлы (области в сетевых БД, отношения в реляционных БД), но и другие структурные элементы БД: элемент, поле, запись, набор данных.
Управление целостностью данных. Ограничители - это элементарные проверки или условия, которые выполняются для операций вставки и модификации значения столбца. Если данная проверка не проходит или условие не выполняется, то вставка или модификация отменяется, а в программу клиента передается ошибка.
SQL-серверы, как правило, поддерживают следующие ограничители.
NOT NULL - проверка на непустое значение. NULL - специальное понятие в СУБД, которое означает "пусто". "Пусто" и "0(ноль)" не равны друг другу!
UNIQUE - проверка на уникальность. Вставляемое значение должно быть уникально для данного столбца по всей таблице. Может содержать пустые значения.
PRIMARY KEY - первичный ключ. Значение в столбце считается первичным ключом, если оно непустое и уникально в пределах столбца данной таблицы. Первичный ключ может быть составным и представлять собой комбинацию столбцов. Тогда чтобы считаться первичным ключом, каждое из группы значений не должно быть пустыми и формируемые строки значений первичного ключа должны быть уникальны в пределах таблицы. Первичный ключ - основа для построения индексов по таблице.
Ограничение ссылочной целостности не позволяет значениям из столбца одной таблицы принимать значения, кроме как из присутствующих в столбце другой таблицы. Это делается при помощи ограничителей FOREIGN KEY (внешний ключ) и REFERENCES (указатель ссылки). Таблица, содержащая FOREIGN KEY, считается родительской таблицей. Таблица, содержащая REFERENCES, считается дочерней таблицей. Внешний ключ и указатель ссылки могут находиться в одной таблице, т.е. родительская таблица одновременно является дочерней.
Н арушение целостности данных может быть вызвано рядом причин:
1) сбои оборудования, физические воздействия или стихийные бедствия;
2) ошибки санкционированных пользователей или умышленные действия несанкционированных пользователей;
3) программные ошибки СУБД или ОС;
4) ошибки в прикладных программах;
5) совместное выполнение конфликтных запросов пользователей и др.
Н арушение целостности данных возможно и в хорошо отлаженных системах. Поэтому важно не только не допустить нарушения целостности, но и своевременно обнаружить факт нарушения целостности и оперативно восстановить целостность после нарушения.
Управление параллелизмом. П оддержание целостности на основе приведенных выше ограничений целостности представляет собой достаточно сложную проблему в системе БД даже с одним пользователем . В системах, ориентированных на многопользовательский режим работы, возникает целый ряд новых проблем, связанных с параллельным выполнением конфликтующих запросов пользователей . Прежде , чем рассмотреть механизмы защиты БД от ошибок, возникающих в случае конфликта пользовательских запросов, раскроем ряд понятий, связанных с управлением параллелизмом.
В ажнейшим средством механизма защиты целостности БД выступает объединение совокупности операций, в результате которых БД из одного целостного состояния переходит в другое целостное состояние, в один логический элемент работы, называемый транзакцией. Суть механизма транзакций состоит в том, что до завершения транзакции все манипуляции с данными проводятся вне БД, а занесение реальных изменений в БД производится лишь после нормального завершения транзакции.
Восстановление данных. К ак уже отмечалось, возникновение сбоев в аппаратном или программном обеспечении может вызвать необходимость восстановления и быстрого возвращения в состояние, по возможности близкое к тому, которое было перед возникновением сбоя (ошибки) . К числу причин, вызывающих необходимость восстановления, зачастую относится и возникновение тупиковой ситуации.
М ожно выделить три основных уровня восстановления:
1) Оперативное восстановление, которое характеризуется возможностью восстановления на уровне отдельных транзакций при ненормальном окончании ситуации манипулирования данными (например, при ошибке в программе).
2) Промежуточное восстановление .Если возникают аномалии в работе системы (системно-программные ошибки, сбои программного обеспечения, не связанные с разрушением БД), то требуется восстановить состояние всех выполняемых на момент возникновения сбоя транзакций.
3) Длительное восстановление. При разрушении БД в результате дефекта на диске восстановление осуществляется с помощью копии БД. Затем воспроизводят результаты выполненных с момента снятия копии транзакций и возвращают систему в состояние на момент разрушения.
Транзакция и восстановление. П рекращение выполнения транзакции вследствие появления сбоя нарушает целостность БД . Если результаты такого выполнения транзакции потеряны, то имеется возможность их воспроизведения на момент возникновения сбоя . Таким образом, понятие транзакции играет важную роль при восстановлении. Для восстановления целостности БД транзакции должны удовлетворять следующим требованиям:
1) необходимо, чтобы транзакция или выполнялась полностью, или не выполнялась совсем;
2) необходимо, чтобы транзакция допускала возможность возврата в первоначальное состояние, причем, для обеспечения независимого возврата транзакции в начальное состояние монопольную блокировку необходимо осуществлять до момента завершения изменения всех объектов;
3) необходимо иметь возможность воспроизведения процесса выполнения транзакции, причем, для обеспечения этого требования, совместную блокировку необходимо осуществлять до момента завершения просмотра данных всеми транзакциями.
В процессе выполнения любой транзакции наступает момент ее завершения . При этом все вычисления, сделанные транзакцией в ее рабочей области, должны быть закончены, копия результатов ее выполнения должна быть записана в системный журнал. Подобные действия называют операцией фиксации . При появлении сбоя целесообразнее осуществлять возврат не в начало транзакции, а в некоторое промежуточное положение.
Откат и раскрутка транзакции. О сновным средством, используемым при восстановлении, является системный журнал, в котором регистрируются все изменения, вносимые в БД каждой транзакцией. Возврат транзакции в начальное состояние состоит в аннулировании всех изменений, которые осуществлены в процессе выполнения транзакции.
Рекомендуемая литература: 1, 2, 3, 4, 12.
Лекция 8. Реляционная алгебра. Реляционное исчисление
Цель: рассмотреть математическое механизм манипулирования данными, познакомить с основными операторами реляционной алгебры, приводятся примеры их реализации на языке SQL.
План :
1) Виды формализованного описания отношений.
2) Понятие реляционной алгебры.
3) Типы операций реляционной алгебры.
Для манипулирования данными в реляционной модели используются два формальных аппарата:
- реляционная алгебра, основанная на теории множеств;
- реляционное исчисление, базирующееся на исчислении предикатов первого порядка.
Механизмы реляционной алгебры и реляционного исчисления эквивалентны, т.е. для любого допустимого выражения реляционной алгебры можно построить эквивалентную формулу реляционного исчисления и наоборот
Отличаются два этих формальных аппарата уровнем процедурности. Выражения реляционной алгебры строятся на основе алгебраических операций (высокого уровня), и подобно тому, как интерпретируются арифметические и логические выражения, выражение реляционной алгебры также имеет процедурную интерпретацию. Другими словами, запрос, представленный на языке реляционной алгебры, может быть реализован как последовательность элементарных алгебраических операций с учетом их старшинства и возможного наличия скобок.
Понятие реляционной алгебры. Реляционная алгебра – это набор операций, которые принимают отношения в качестве операндов и возвращают отношение в качестве результата. Первая версия этой алгебры была определена Э. Коддом.
В основе всех реляционных БД лежит использование реляционной алгебры, которая обеспечивает запись выражений для реализации на некотором языке, например, SQL. Если возможности языка как минимум соответствуют возможностям, обеспеченным алгебраическими операциями, то его называют реляционно полным.
Обычно выделяют 8 основных операторов реляционной алгебры и несколько дополнительных (их количество меняется со временем). Мы рассмотрим два дополнительных оператора: расширения и подведения итогов.
Основные операторы реляционной алгебры. Реляционная алгебра включает восемь основных операций, которые подразделяются на две группы, в каждую из которых входит четыре операции. Традиционные операции с множествами, модифицированные для таблиц (отношений).
Объединение: A UNION B . Результатом операции объединения является отношение, содержащее все кортежи, принадлежащие одному из двух или обоим отношениям.
В отличие от объединения множеств, результатом объединения отношений должно стать отношение, а не набор разнородных кортежей.
При объединении должны соблюдаться два условия:
1) отношения должны быть совместимы по типу, т.е. иметь одно и то же множество атрибутов, определённых на одних и тех же доменах;
2) результатом каждой операции должно быть также отношение (свойство замкнутости).
SELECT Name, BirthDate FROM Students
UNION SELECT Name, BirthDate FROM Teachers
Пересечение: A INTERSECT B . Результатом операции пересечения является отношение, содержащее кортежи, которые принадлежат обоим отношениям.
Для операции пересечения необходимы те же два условия, что и для объединения: совместимость по типу и замкнутость.
SELECT Name FROM Teachers
INTERSECT SELECT Name FROM Supervisors
Вычитание: A MINUS B . Результатом операции вычитания является отношение, которое содержит все кортежи, принадлежащие первому отношению и не принадлежащие второму отношению.
Условия необходимы те же: совместимость по типу и замкнутость.
SELECT Name FROM Teachers
EXCEPT SELECT Name FROM Supervisors
П роизведение: A TIMES B . Результатом является отношение, содержащее все возможные кортежи, которые являются сочетанием двух кортежей, принадлежащих двум отношениям.
Для произведения необходимо свойство замкнутости, т.е. результатом является не просто множество пар кортежей, а множество целых кортежей. В реляционной алгебре каждая пара кортежей заменяется одним благодаря сцеплению (сцепление – это объединение в смысле теории множеств, а не реляционной алгебры).
При произведении может возникнуть проблема одинаковых имён атрибутов. В этом случае одно из конфликтующих полей необходимо переименовать.
SELECT Students . Name AS ‘ Student ’, Courses . Name AS ‘ CourseName ’
FROM Students CROSS JOIN Courses
В ыборка ( или ограничение ). Результатом выборки является отношение, содержащее все кортежи из исходного отношения, которые удовлетворяют определённому условию.
SELECT * FROM Students WHERE GroupID = 2
Проекция. Результатом проекции является отношение, содержащее все кортежи после удаления из них некоторых атрибутов. В этом случае результирующие кортежи называются подкортежами.
Обратим внимание на два момента:
1) возможно указание всех атрибутов исходного отношения для проекции – получится тождественная проекция;
2) возможно указать пустой список атрибутов – получится нулевая проекция.
Осуществить проекцию можно указанием после SELECT списка необходимых атрибутов.
SELECT Name, BirthDate FROM Students
Соединение . Результат соединения – это отношение, кортежи которого являются сочетанием двух кортежей, принадлежащих двум начальным отношениям и имеющих общие значения для одного или нескольких атрибутов (общее значение в результирующем отношении появляется только один раз).
SELECT Name, GroupName FROM Students
INNER JOIN Groups ON Students.GroupID = Groups.GroupID
Операции расширения и подведения итогов . После того , как Э. Кодд предложил восемь основных операций, многочисленные авторы предложили новые алгебраические операции. Мы рассмотрим лишь две из них – расширение и подведение итогов. Эти операции удачно дополняют основной набор и являются наиболее востребованными.
Расширение. С помощью операции расширения из отношения создаётся новое отношение, содержащее новый атрибут, значения которого получены посредством скалярных вычислений.
Добавим новый атрибут Age , который будет показывать, сколько полных лет исполнилось преподавателю:
SELECT TeacherID, Name, BirthDate, DATEDIFF(YEAR, BirthDate, GetDate()) AS ‘Age’ FROM Teachers
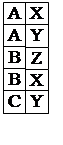
Деление: A DIVIDEBY B . Результатом деления двух отношений (бинарного и унарного) является отношение, содержащее все значения атрибута первого бинарного отношения, которые соответствуют всем значениям унарного отношения.
Эта операция не имеет аналога в MS SQL Server 2008, поэтому рассмотрим на примере деления отношения R1 на R2:
|
Подведение итогов. Операция подведения итогов даёт возможность "вертикальных" вычислений. Для этого используются агрегатные функции, которые для набора значений возвращают одно единственное. Наиболее распространенные функции: Sum , Count , Avg , Min , Max .
Требуется подсчитать, сколько студентов в каждой группе:
SELECT GroupID, Count(StudentID) as ‘StudentCount' FROM StudentsGROUP BY GroupID
Операторы обновления . Предназначены для управления данными в таблицах. Существует три операции обновления.
Вставка записи. Позволяет добавлять одну или несколько новых записей в отношение.
INSERT INTO Students (Name, GroupID) VALUES (‘ Драгомиров Евгений ’, 1)
INSERT INTO Students (Name, GroupID) VALUES (‘ Васнецова Евгения ’, 2)
Удаление записи. Удаляет все записи из отношения, или только записи, удовлетворяющие заданному критерию.
DELETE Students WHERE GroupID = 1
Обновление записи . Позволяет обновлять значения указанных полей всех или только определенных записей.
UPDATE Students SET GroupID = 2 WHERE GroupID = 1
Краткие итоги . Рассмотрены основные операции над таблицами, а также были приведены примеры использования этих операций на языке SQL.
Рекомендуемая литература: 1, 3, 12.
Лекция 9. Основы языка SQL
Цель: дать общую характеристику операторов языка SQL и показать, как записываются основные запросы к базе данных на языке SQL (в интерактивном режиме).
План:
1) Стандарты ЫЙД.
2) Основные операторы языка SQL.
3) Формы языка SQL.
4) Группы операторов SQL.
5) Применение языка SQL.
6) Формирование запросов средствами языка SQL.
Текущая версия стандарта языка SQL принята в 1992 г. (Официальное название стандарта - Международный стандарт языка баз данных SQL (1992) ( International Standart Database Language SQL ), неофи-циальное название - SQL/92, SQL-92, или SQL2). Документ, описывающий стандарт, содержит более 600 страниц. Мы дадим только некоторые понятия языка. Использованные источники приведены в концетекста.
Язык SQL стал фактически стандартным языком доступа к базам данных. Все СУБД, претендующие на название "реляционные", реализуют тот или иной диалект SQL. Многие нереляционные системы также имеют в настоящее время средства доступа к реляционным данным. Целью стандар-тизации является переносимость приложений между различными СУБД.
Язык SQL оперирует терминами, несколько отличающимися от терминов реляционной теории, например, вместо "отношений" используются "таблицы", вместо "кортежей" - "строки", вместо "атрибутов" -
Стандарт языка SQL, хотя и основан на реляционной теории, но во многих местах отходит он нее. Например, отношение в реляционной модели данных не допускает наличия одинаковых кортежей, а таблицы в термин-ологии SQL могут иметь одинаковые строки. Имеются и другие отличия.
Язык SQL является реляционно полным. Это означает, что любой оператор реляционной алгебры может быть выражен подходящим оператором SQL.
9.1 Операторы SQL
Основу языка SQL составляют операторы, условно разбитые не несколько групп по выполняемым функциям. Можно выделить следующие группы операторов (перечислены не все операторы SQL):
Операторы DDL (Data Definition Language) - операторы определения объектов базы данных. CREATE SCHEMA - создать схему базы данных, CREATE TABLE - создать таблицу, CREATE DOMAIN - создать домен, CREATE COLLATION - создать последовательность, CREATE VIEW - создать представление, DROP SHEMA - удалить схему базы данных, DROP TABLE - удалить таблицу, DROP DOMAIN - удалить домен, DROP COLLATION - удалить последовательность, DROP VIEW - удалить представление, ALTER TABLE - изменить таблицу и ALTER DOMAIN - изменить домен.
Операторы DML ( Data Manipulation Language ) - операторы манипулирования данными. SELECT - отобрать, INSERT - добавить, UPDATE - изменить и DELETE - удалить строки в таблице. COMMIT - зафиксировать внесенные изменения и ROLLBACK - откатить внесенные изменения.
Операторы защиты и управления данными:
1) CREATE ASSERTION - создать ограничение;
2) DROP ASSERTION - удалить ограничение;
3) GRANT - предоставить привилегии пользователю или приложению на манипулирование объектами;
4) REVOKE - отменить привилегии пользователя или приложения.
9.2 Формы языка SQL
Структурированный язык запросов SQL реализуется в интерактивный, статический, динамический и встроенный.
Интерактивный SQL позволяет конечному пользователю в интерактивном режиме выполнять SQL-операторы. Все СУБД предостав-ляют инструментальные средства для работы с базой данных в интерактив-ном режиме. Например, СУБД Oracle включает утилиту SQL*Plus, позволяющую в строчном режиме выполнять большинство SQL-операторов.
Статический SQL может реализовываться как встроенный SQL или модульный SQL. Операторы статического SQL определены уже в момент компиляции программы.
Динамический SQL позволяет формировать операторы SQL во время выполнения программы.
Встроенный SQL позволяет включать операторы SQL в код программы на другом языке программирования (например, С++).
9.3 Группы операторов SQL
Язык SQL определяет:
1) операторы языка, называемые иногда командами языка SQL;
2) типы данных;
3) набор встроенных функций.
По своему логическому назначению операторы языка SQL часто разбиваются на следующие группы:
1) язык определения данных DDL (Data Definition Language);
2) язык манипулирования данными DML ( Data Manipulation Language ).
Язык определения данных включают операторы, управляющие объектами базы данных. К последним относятся таблицы, индексы, представления. Для каждой конкретной базы данных существует свой набор объектов базы данных, который может значительно расширять набор объектов, предусмотренный стандартом
Язык манипулирования данными включают операторы, управляющие содержанием таблиц БД и извлекающие информацию из этих таблиц.
9.4 Применение языка SQL
Подключение к СУБД. Первым шагом в любом случае следует выполнить подключение к СУБД. Например, CONNECT TO MyDB1 USER User1/Password1.
Фраза TO специфицирует источник данных, с которым устанавливается соединение. Фраза USER определяет имя и пароль пользователя, который будет работать с базой данных.
Операторы и функции языка SQL не чувствительны к регистру, в отличие от строковых значений. Однако, как и в стандарте языка, SQL-операторы всегда будут обозначаться в лекциях заглавными буквами, а названия полей, таблиц и псевдонимов (алиасов) - строчными.
Перед началом работы с данными должны быть выполнены следующие действия:
1) разработана модель базы данных и на ее основании создана схема базы данных - все взаимосвязанные таблицы;
2) в каждую созданную таблицу должны быть введены данные.
Создание таблицы. Для создания таблицы используется оператор CREATE TABLE, имеющий в стандарте SQL92 следующее формальное описание:
CREATE [ { GLOBAL | LOCAL } ] TEMPORARY]
TABLE имя _ таблицы ( { column | [table_constraint] } . , ..
[ ON COMMIT { DELETE | PRESERVE} ROWS ] );
column определяется как имя _ поля {domain | datatype [size]}
[column_constraint:] [ DEFAULT default_value ]
[ COLLATE collate _ value ]
9.5 Формирование запросов средствами языка SQL
Оператор SELECT. Оператор SELECT позволяет формировать запрос к базе данных. В результате выполнения этого оператора СУБД формирует результирующий набор (иногда также называемый набором данных). Если этот оператор был введен в интерактивном режиме взаимодействия с базой данных, то результат отображается в виде таблицы в текущем диалоговом окне.
Оператор SELECT имеет в стандарте SQL92 следующее формальное описание:
{ {function_agregate | expr [AS new_field_name] } .,:
| specification.* | *
[INTO list_variable]
FROM {{ имя _ таблицы [AS] [table_alias] [(field .,:)]}
| {subquery [AS] subquery_alas [(field .,:)]}
| union_table constructor_of_table_value
| {TABLE имя _ таблицы [AS] alias [(field .,:)]}
} .,:
[WHERE condition] [GROUP BY {{ имя _ таблицы | alias }.field} .,:
{COLLATE name}] [HAVING condition] [{ UNION | INTERSECT | EXCEPT } [ALL] [CORRESPONDING [BY (field.,:)]]
SELECT_operator | {TABLE имя _ таблицы } | constructor_of_table_value [ORDER BY] {{field_result [ASC|DESC]}.,:}
|{{ integer [ASC|DESC]}.,:} ;
После фразы SELECT указывается список выражений, определяющий значения, формируемые запросом. В самом простом случае список выражений является списком полей таблицы. Если требуется извлечение значений всех полей, то вместо списка полей можно указать символ *. Например:
SELECT * FROM tbl1;
1) Фраза FROM определяет одну или несколько таблиц или подзапрос-ов, используемых для извлечения данных.
2) Фраза INTO используется только во встроенном SQL, указывая переменные, в которые записывается результат запроса. При этом формируемый результирующий набор может содержать только одну строку.
3) Фраза WHERE определяет условие, которому должны удовлетворять все строки, используемые для формирования результирующего набора.
Функции агрегирования. Фраза GROUP BY оператора SELECT применяется для определения группы строк, над которыми выполняются функции агрегирования. Если в операторе SELECT указана фраза GROUP BY, то все имена столбцов, указываемые в списке для определения создаваемого результирующего набора, должны быть указаны с функциями агрегирования, поскольку для каждой группы строк в результирующий набор будет включена только одна строка, содержащая значения, полученные функциями агрегирования над данной группой строк.
Фраза HAVING оператора SELECT определяет предикат аналогично фразе WHERE, но применяемый к строкам, полученным в результате выполнения функций агрегирования.
Упорядочивание результирующего набора. Фраза ORDER BY применяется для упорядочивания результирующего набора, которое выполняется в соответствии со значениями столбцов, указанных в списке после фразы ORDER BY. Сначала производится упорядочивание по первому указанному столбцу, потом по второму и т.д. При упорядочивании можно указать опцию ASC (по возрастанию) или DESC (по убыванию).
Перекрестное соединение(CROSS JOIN). Если фраза FROM определяет более одной таблицы или подзапроса, то все эти таблицы соединяются. По умолчанию объединенная таблица представляет собой перекрестное соединение (CROSS JOIN), называемое также декартовым произведением (Cartesian product).
Рекомендуемая литература: 14-16.
Лекция 10. Программный (встроенный) T - SQL
Цель: показать основные возможности программирования в базе данных с использованием процедур и триггеров.
План:
1) П ользовательские функции.
2) П ользовательские хранимые процедур.
3) Пользовательские триггеры.
Пользовательские функции принадлежат к числу наиболее привлекательных объектов SQL Server . Возможность применения пользовательских функций ( User Defined Function — UDF ) появилась больше пяти лет тому назад, но до сих пор они остаются одними из самых недостаточно используемых и недооцененных объектов SQL Server .
Эти объекты произвели потрясающее впечатление на специалистов по базам данных сразу после их внедрения корпорацией Microsoft в версии SQL Server 2000, но со времени появления инфраструктуры . NET пользовательские функции приобрели еще большие возможности. А с точки зрения читателя настоящей книги, который ознакомился со всеми предыдущими главами, одна из наиболее замечательных особенностей пользовательских функций состоит в том, что ему уже известно почти все, что требуется для создания этих функций. Фактически пользовательские функции чрезвычайно напоминают хранимые процедуры и отличаются от последних только тем, что обладают некоторыми дополнительными характеристиками и возможностями, которые подчеркивают их особенности и обеспечивают применение во многих сложных ситуациях.
Хранимая процедура или функция есть объект реляционной базы данных, который является поименнованным набором операторов SQL и, в случае СУБД Oracle, набором операторов PL/SQL, который может быть скомпилирован и необязательно сохранен в базе данных. Если процедура сохраняется в базе данных, то она называется хранимой процедурой или функцией. Описание хранимых процедур и функций хранится в словаре данных реляционной базы данных.
Обычно хранимые процедуры используются для выполнения набора типовых действий, характерных для достижения целей создания базы данных, а хранимые функции - для вычисления значений.
Код хранимых процедур и функций хранится в базе данных. Поэтому использование хранимых процедур и функций для выполнения типовых операций, характерных для приложения базы данных, приводит к упрощению приложений за счет передачи обработки на сервер базы данных. Такой подход уменьшает накладные расходы за счет сокращения фазы синтаксического анализа и уменьшения времени передачи запроса на конкретное действие по вычислительной сети, что приводит в целом к снижению трафика сети. Обычно при этом улучшается производительность, но это необязательно для маломощных серверов баз данных.
Хранимые процедуры и функции, как объекты базы данных, создаются командой CREATEи уничтожаются командой DROP. Команда создания хранимой процедуры имеет следующий синтаксис:
CREATE PROCEDURE [имя схемы].имя процедуры
[имя [(параметр [, параметр, ...])] {IS|AS}
Команда создания хранимой процедуры имеет следующий синтаксис:
CREATE FUNCTION [имя схемы].имя функции
[имя [(параметр [, параметр, ...])] RETURN тип данных
{ IS | AS }
программа на T - SQL ;
Как можно увидеть, синтаксис команды создания хранимой функции похож на синтаксис команды создания хранимой процедуры, за исключением того, что в описании функции используется предложение RETURN . Описание типа данных для возвращаемого значения требуется обязательно.
Триггеры. Триггер базы данных (database trigger) является объектом реляционной базы данных, который активизирует выполнение хранимой (или встроенной) Т-SQL-процедуры при изменении пользователем данных в таблице. Событие, управляющее запуском триггера, описывается в виде логических условий. Например, попытка модифицировать данные в таблице активизирует триггер, соответствующий данной команде манипулирования данными. Число триггеров на таблицу базы данных не ограничено.
Обычно триггеры используют для реализации ограничений ссылочной целостности, для предотвращения несогласованных изменений в базе данных (поддержка целостности базы данных), для выполнения скрытых операций при модификации, а также для снижения сетевого трафика за счет передачи обработки на сервер. Операции завершения транзакции выполняются после обработки триггеров.
Триггеры позволяют организовать автоматическую обработку таких событий как добавить, удалить, обновить запись, когда в каких-то других подчиненных таблицах предполагается сделать еще что-то. К примеру, если удалить, то каскадно удалить еще подчиненные записи. Если обновить ключ, то в дочерней таблице изменить ключ на новый. Можно, наоборот, не изменять – это может от стратегии зависеть. Могут быть выполнены какие-то дополнительные действия: посылаться какие-нибудь e - mail или и т.п. Т.е. вообще говоря, может быть запущен автоматически целый комплекс программ, который выполняется в случае выполнения тех или иных действий.
В процессе выполнения триггеров автоматически создаются триггерные таблицы, где хранятся изменяемые данные. Например, при добавлении в таблицу, то это триггерная таблица на вставку (это запись с новыми значениями). При обновлении – со старыми и новыми значениями, при удалении – только со старыми. К этим триггерным таблицам в теле триггера можно иметь доступ. Триггерные таблицы обычно имеют специфические названия, например, в SQL Server они называются deleted и inserted , в ORCALE они называются new и old . Доступ – <имя таблицы>.<имя поля>.
В СУБД существует такое понятие как ограничение, их мы записали в количестве 5 штук. Триггер – формально тоже некоторое ограничение на действие, механизм работы триггеров организован таким образом, что сперва проверяются все ограничения, если все ограничения выполнились, то только потом срабатывает триггер. Поэтому в некоторых случаях, если срабатывает ограничение, то дело до срабатывания триггера может и не доходить.
Тут надо отметить историческую справедливость, что фирма Sybase первая предложила использование триггеров. Несмотря на то, что триггеры имеют большую гибкость и могут содержать достаточно большие строчки кода, им присущ определенный недостаток. Во-первых, усложнение базы данных. Они хранятся на сервере, чем больше триггеров, тем больше объектно-системных таблиц. Далее, скрытие логики от пользователя: когда база данных разрабатывается первоначально «тут еще куда не шло», но когда начинается модернизация базы данных, и часто приглашаются другие программисты, понять логику работы триггеров достаточно тяжело. Потому как просто так запустить их нельзя (они запускаются специфическим образом) и их логику очень трудно понять. Кроме того, они неадекватно (или по-разному) влияют на производительность, поэтому оценить производительность в такой системе бывает достаточно трудно. Триггеры различаются по типу команд, на которые они реагируют.
Для создания триггера используется команда CREATE TRIGGER.
CREATE TRIGGER trigger_name ON { table | view }
[WITH ENCRYPTION ] {{ FOR | AFTER INSTEAD OF }
{[DELETE] [,] [INSERT] [,] [UPDATE] } [WITH APPEND ]
[NOT FOR REPLICATION ]
AS sql_statement [. . .n] }
Для отслеживания изменений, которые выполнил пользователь в таблице необходимо получить доступ к данным, которые были изменены пользовательским запросом. Эту информацию можно получить из таблиц inserted и deleted, которые автоматически создаются сервером при вызове триггера. В этих таблицах содержатся списки строк, которые будут соответственно вставлены и удалены по завершении транзакции. Структура таблиц inserted и deleted идентична структуре таблицы, для которой определен триггер.
Для каждого триггера создается свой комплект таблиц inserted и deleted, так что никакой другой триггер не сможет получить к ним доступ. В зависимости от команды, вызвавшей выполнение триггера, содержимое таблиц inserted и deleted может быть разным. Рассмотрим эти команды подробнее.
− Команда INSERT. В таблице inserted будут содержаться все строки, которые пользователь пытается вставить в таблицу. Таблица deleted не будет содержать ни одной строки. После завершения триггера все строки из таблицы inserted будут вставлены в таблицу.
− Команда DELETE. В таблице deleted будет приведен список строк, которые пользователь пытается удалить. Триггер может проверить каждую строку и решить, разрешено ли ее удаление. Таблица inserted не будет содержать ни одной строки.
− Команда UPDATE. При выполнении этой команды таблица deleted будет содержать старые значения строк, которые будут удалены при успешном завершении триггера. Новые значения строк содержатся в таблице inserted. Эти строки будут добавлены в исходную таблицу после успешного завершения триггера.
В логические таблицы inserted и deleted запрещено вносить любые изменения. Они являются своего рода копией журнала транзакций. При запуске триггера исходная таблица находится в состоянии, в которое ее привело бы успешное завершение транзакции (все изменения, добавления и удаления строк выполнены). Из триггера можно обращаться к таблице и изменять любые значения в ней. Таблицы inserted и deleted используются для отслеживания измененных строк.
Рекомендуемая литература: 12-16.
Лекция 11. Управление транзакциями в современных реляционных СУБД
Цель: рассмотреть защиту физической целостности с точки зрения транзакций.
План :
1) Понятие транзакции.
2) Управление транзакциями на сервере.
3) Виды транзакций.
Современные СУБД являются многопользовательскими. Следовательно, всегда есть возможность одновременного обращения нескольких пользователей к одной базе данных, и даже – к одним и тем же данным. При этом возникает масса проблем, связанных с попытками одновременного изменения или удаления данных.
11.1 Понятие транзакции
При работе ЭВМ возможны сбои в работе (например, из-за отключения электропитания), повреждение машинных носителей данных. При этом могут быть нарушены связи между данными, что приводит к невозможности дальнейшей работы. Развитые СУБД имеют сред-ства восстановления базы данных. Важнешим используемым понятием является понятие «транзакции». Транзакция – последовательный набор команд SQL, образующих логически завершенный блок, который выполняется как единое целое.
Управления транзакциями основывается на требованиях ACID ( Atomicity, Consistency, Isolation и Durability).
Управление требованиями ACID берет на себя сервер. Программист (и DBA) должен лишь выбрать нужный уровень изоляции и разработать эффективные алгоритмы обработки данных.
Для каждой транзакции сервер накладывает на данные блокировки, которые обеспечивают выполнение требований ACID.
Блокировка (lock) – временно накладываемое ограничение на выполнение некоторых операций обработки данных.
В состав СУБД, как правило, входит менеджер блокировок, который управляет блокировками. В случае отсутствия механизма блокировок возникают следующие ситуации ( р - отдельный кортеж таблицы ).
Проблема последнего изменения (the lost update problem)
|
|
Транзакция А |
Транзакция В |
Транзакция С |
|
T1 |
Взять р |
Взять р |
Взять р |
|
T2 |
Изменить р |
- |
- |
|
T3 |
- |
Изменить р |
- |
|
T4 |
- |
- |
Изменить р |
Данные, считанные транзакцией А в первый раз, могут отличаться от данных, считанных ею во второй раз, т.к. в это время транзакция В успела изменить эти данные.
Для решения указанных проблем американским институтом стандартов ANSI был разработан стандарт на уровни блокирования, состоящий из четырех уровней:
Уровень 0 – запрет «загрязнения» данных (no trashing of data).
Изменять данные может только одна транзакция. Если другой транзакции необходимо изменить эти же данные, она должна дождаться завершенгия первой транзакции.
Уровень 1 – запрет на «грязное» чтение (no dirty reads).
Если транзакция начала изменение данных, то никакая другая транзакция не сможет прочитать эти данные до тех пор, пока первая транзакция не завершится.
Уровень 2 – запрет неповторяемого чтения (no nonrepeatable reads).
Если транзакция считывает данные, то никакая другая транзакция не сможет их изменить. Таким образом, при повторном чтении данных они будут находиться в исходном состоянии.
Уровень 3 – запрет фантомов (no phantom).
11.2 Управление транзакциями на сервере
Все команды, выполняемые пользователями на сервере, производятся в теле транзакций. По умолчанию, каждая команда выполняется как отдельная транзакция. Пользователь может объединить несколько команд в одну транзакцию, явно указав ее начало и конец. SQL Server 2000 поддерживает три способа определения транзакции ( явное, автоматическое и неявное).
11.2.1 Явные транзакции.
Для явной транзакции требуется явное указание начала и конца транзакции:
Начало транзакции
BEGIN TRAN[SACTION] [tran_name | @tran_name_var [WITH MARK [‘de’]]],
где
− tran_name – имя транзакции (до 32 допустимых для именования символов) – используется для именования вложенных транзакций;
− @tran_name_var – имя переменной типа char, nchar, varchar, nvarchar;
− WITH MARK – маркирует транзакцию в журнале транзакций для того, чтобы при восстановлении журнала транзакций, вернуть базу данных в состояние, предшествующее или следующее за отметкой;
− De – текст отметки.
11.2.2 Автоматические транзакции ( autocommit transactions , по умолчанию в SQL Server 2000).
В этом режиме каждая команда инициирует начало новой транзакции. Если команда выполнена успешно, то сделанные ей изменения фиксируются, иначе – отменяются. Для транзакции, состоящей из нескольких команд, явно задается начало и конец транзакции. Переход в режим автоматических транзакций выполняется установкой параметра сервера
IMPLICIT _ TRANSACTION в положение OFF .
SET IMPLICIT_TRANSACTION OFF
11.2.3 Неявные ( подразумеваемые ) транзакции (implicit transactions).
В этом режиме транзакция начинается сразу, как только закончена предыдущая транзакция, т.е. начало транзакции не указывается. Транзакция продолжается до тех пор, пока пользователь явно не откатит или не подтвердит успешное завершение транзакции. После этого стартует новая транзакция.
Автоматическое завершение транзакции в этом случае возможно, если сервер встречает одну из команд: ALTER TABLE, CREATE, DROP, SELECT, INSERT, DELETE, UPDATE, GRANT, REVOKE, OPEN, FETCH.
Переход в режим автоматических транзакций выполняется установкой параметра сервера
IMPLICIT_TRANSACTION в положение ON.
SET IMPLICIT_TRANSACTION ON
Сервер работает в режиме либо автоматических, либо неявных транзакций. Режим явных транзакций реализуется поверх этих двух.
11.3 Распределенные транзакции
Распределенные транзакции используются, когда пользователь обращается к разным базам данных, даже если эти базы данных физически управляются одной и той же СУБД. Все такие базы данных, к которым обращаются пользователи при распределенной транзакции, называются менеджерами ресурсов.
СУБД для работы с менеджерами ресурсов используют transaction manager (TM), который в SQL Server 200 называется MS Distributed Transaction Coordinator (MS DTS), удовлетворяющий спецификации X/OPEN XA.
При исполнении распределенных транзакций основная проблема – их завершение, т.к. в случае разных менеджеров ресурсов скорости исполнения частей распределенной транзакции могут различаться на порядки, и могут возникать проблемы просроченных соединений.
Распределенные транзакции стартуют, если:
1) в запросе явно используется несколько баз данных;
2) приложение начинает локальную транзакцию, из которой вызывается удаленная хранимая процедура. Если параметр базы данных REMOTE_PROC_TRANSACTION установлен в ON, то локальная транзакция автоматически расширяется до распределенной;
3) приложение начинает распределенную транзакцию, используя методы OLE DB или ODBC;
4) сервер встречает команду BEGIN DISTRIBUTED TRANSACTION, для завершения/отката которой используются стандартные команды ROLLBACK и COMMIT.
Поведение сервера для всех открываемых соединений регулируется таким образом:
EXEC sp_configure ’remote proc trans’ {0 | 1}
В рамках отдельного соединения можно перекрыть настройки сервера, изменив параметр SET REMOTE _ PROC _ TRANS { ON | OFF }.
Несколько общих правил работы с транзакциями:
1) Придерживаться одного стиля управления транзакциями: либо – все вызывается явно, либо – все вызывается неявно.
2) Придерживаться одного механизма обращения к данным.
11.4 Вложенные транзакции
Существует особый вид транзакций, называемых «вложенными»(nested) транзакциями.
Вложенная транзакция – транзакция, выполнение которой инициируется из тела уже активизированной транзакции.
Вложенные транзакции оформляются так, что новая транзакция стартует, если старая еще не закрыта. Завершение транзакции верхнего уровня откладывается до момента завершения вложенной транзакции. Если транзакция самого нижнего уровня откладывается, то (!) откатываются и все транзакции верхних уровней, включая первый уровень.
Закрытие транзакций происходит снизу вверх, т.е. первая команда COMMIT(ROLLBACK) закрывает самую нижнюю транзакцию. В случае отката на любом уровне вложенности разрешается указать имя только самой верхней транзакции, таким образом, откатываются все транзакции, вплоть до самой верхней. Если же требуется откатить часть транзакций, то используется команда.
SAVE TRAN [ SACTION ] { savepoint _ name | @ savepoint _ var },
где savepoint_name (имя точки сохранения) следует указывать явно.
Это имя затем можно указывать в ROLLBACK для определения места отката.
11.5 Управление блокировками
Вообще, пользователю не нужно ничего делать для управления блокировками. Однако существуют средства изменения типа блокировки для конкретного запроса. Можно регулировать время ожидания разблокирования ресурса.
SET LOCK_TIMEOUT period,
где period – время ожидания , в миллисекундах. Если period=0, то в случае, если ресурс заблокирован, сразу же выдается сообщение об ошибке. По умолчанию period=-1, что равносильно бесконечному времени ожидания.
Т.к. каждая блокировка требует памяти и процессорного времени, можно регулировать количество одновременных блокировок:
EXEC sp_configure ’locks’ n,
где n – значение от 5000 до 21474831047. По умолчанию n=0, что означает автоматическое конфигурирование в зависимости от количества
активных пользователей.
Рекомендуемая литература: 1, 4, 11, 17, 18.
Лекция 12. Обеспечение безопасности СУБД
Цель: рассмотреть безопасность серверов и баз данных с точки зрения уровней доступа пользователей.
План:
1) Выборочный и обязательный подходы к созданию системы безопасности.
2) Стандарты.
3) Классы безопасности.
4) «Розовая» книга.
5) Поддержка безопасности в языке SQL.
6) Реализация системы безопасности в современных СУБД. Роли и права.
При реализации системы секретности в современных СУБД используется один из двух подходов к обеспечению секретности данных:
1) Избирательный подход, при котором пользователь обладает различными полномочиями при работе с разными объектами.
2) Обязательный подход, при котором каждому объекту присваивается некоторый классификационный уровень, а каждый пользователь обладает некоторым уровнем допуска.
Совершенно очевидно, что СУБД лишь реализует принятые на этапе проектирования стратегические решения по обеспечению секретности, разграничению прав доступа. Для этого в СУБД должны присутствовать такие компоненты:
1) Компонент определения полномочий на некотором языке (возможно, на SQL).
2) Компонент регулирования доступа на основании определенных полномочий – подсистема полномочий.
3) Компонент идентификации пользователя/группы. Современные СУБД позволяют задавать полномочия сразу группе пользователей. Набор полномочий, приписанный группе пользователей, часто называют ролью.
12.1.1 Избирательное управление доступом .
При избирательном подходе пользователю назначается набор полномочий в том случае, если эти полномочия отличаются от принятых в конкретной системе баз данных по умолчанию. Т.е. все пользователи обладают некоторым минимальным набором полномочий (возможно, пустым), и только некоторым назначаются дополнительные полномочия. Причем, одному пользователю могут быть назначены разные полномочия при работе с разными объектами.
12.1.2 Обязательное управление доступом.
Обязательная схема жестче, по сравнению с избирательными схемами секретности, и применяется к базам данных, структура которых редко меняется. Основная идея обязательной схемы состоит в том, что каждому объекту данных приписывается некоторый уровень допуска (например, «секретно», «совершенно секретно», и т.д.), а каждому пользователю назначается один уровень допуска, с теми же значениями, что и для объектов данных.
12.1.3 Стандарты. Классы безопасности.
В “оранжевой” книге определяется четыре класса безопасности (security classes) – D, C, B, A. Класс D обеспечивает минимальную защиту, класс С – избирательную, В – обязательную, а класс А – проверенную защиту.
Избирательная защита: класс С делится на два подкласса – С1 и С2 (более безопасный, чем С1).
Согласно требованиям класса С1 необходимо разделение данных и пользователя, т.е. наряду с поддержкой концепции общего доступа к данным здесь возможна организация раздельного использования данных пользователями.
Для систем класса С2 необходимо дополнительно организовать учет на основе процедур входа в систему, аудита (отслеживания обращений к ресурсам) и изоляции ресурсов.
Обязательная защита: класс В делится на три подкласса В1, В2 и В3 (В3 наиболее безопасный).
Для класса В1 необходимо обеспечить «отмеченную защиту» (т.е. каждый объект должен содержать отметку о его уровне безопасности), а также неформальное сообщение о действующей системе безопасности.
Для класса В2 необходимо дополнительно обеспечить формальное утверждение о действующей стратегии безопасности, а также обнаружить и исключить плохо защищенные каналы передачи информации.
Для класса В3 необходимо дополнительно обеспечить поддержку аудита и восстановления данных, а также назначение администратора режима безопасности.
Проверенная защита: класс А является наиболее безопасным.
12.2 Директивы SQL для обеспечения секретности
В стандарте SQL предусмотрена поддержка только избирательного управления доступом. Она включает в себя механизм представлений (views) и подсистему привилегий.
Директива GRANT устанавливает привилегии пользователю.
GRANT список_привилегий, разделенный запятыми ON объект TO список пользователей, разделенный запятыми [WITH GRANT OPTION]
Различают такие типы привилегий:
1) USAGE - для использования некоторого домена;
2) SELECT – разрешена выборка;
3) INSERT – разрешено добавление записей;
4) UPDATE – разрешено обновление записей ;
5) DELETE – разрешено удаление записей;
6) EXECUTE- разрешено выполнение хранимых процедур;
7) REFERENCES – разрешено обращение в ограничениях целостности к специальным объектам.
Объект – домен или отношение.
Опция WITH GRANT OPTION - присваивает пользователю полномочия предоставления полномочий другим пользователям.
Директива REVOKE отменяет полномочия, выданные пользователем А пользователю В.
REVOKE [ GRANT OPTION FOR ] список_привилегий.
ON объект FROM список пользователей, разделенный запятыми option;
где option – одно из значений {CASCADE, RESTRICT},
CASCADE–отмена всех привилегий.
RESTRICT – запрет на отмену привилегии.
12.3 Основные понятия системы безопасности
Система безопасности СУБД основывается на таких понятиях как учетная запись, роль, группа, пользователь.
Каждый пользователь проходит два этапа проверки системы безопасности при попытке доступа к данным:
1) Этап 1 – аутентификация;
2) Этап 2 – получение доступа к данным.
Первый этап относится к уровню работы всего сервера СУБД. На первом этапе пользователь идентифицирует себя с помощью логического имени (login) и пароля (password).
Логическое имя и пароль хранятся на сервере СУБД в виде учетной записи (account).
Если данные были введены правильно, то считается, что процедура аутентификации пройдена, и данный сервер СУБД разрешает попытку доступа к конкретной базе данных.
Однако сама по себе аутентификация не дает пользователю права доступа к каким бы то ни было данным. Для получения доступа к данным необходимо, чтобы учетной записи пользователя соответствовал некоторый пользователь базы данных (database user).
Пользователь базы данных – совокупность разрешений и запретов на работу с данными в конкретной базе данных.
На втором этапе учетная запись пользователя отображается в пользователя базы данных, и получает все привилегии, соответствующие этому пользователю базы данных. Второй этап задействует систему безопасности конкретной базы данных, а не всего сервера СУБД.
Пользователи баз данных могут объединяться в роли (иногда – группы) для упрощения управления системой безопасности.
Роли базы данных объединяют нескольких пользователей в административную единицу и позволяют назначать права доступа к объектам базы данных для роли, наделяя этими правами всех участников этой роли.
Различают пользовательские и встроенные роли. Встроенные роли создаются автоматически при установке сервера СУБД (и не могут меняться). Различают встроенные роли уровня СУБД и уровня конкретной базы данных. Так, например, в SQL Server есть такие роли сервера:
|
Встроенная роль сервера |
Назначение |
|
Sysadmin |
Может выполнять любые действия в SQL Server |
|
Serveradmin |
Выполняет конфигурирование и выключение сервера |
|
Setupadmin |
Управляет связанными серверами и процедурами, автоматически запускающимися при запуске SQL Server |
|
Securityadmin |
Управляет учетными записями и правами на создание базы данных, также может читать журнал ошибок. |
|
Processadmin |
Управляет процессами, запущенными в SQL Server |
|
Dbcreator |
Может создавать и модифицировать базы данных |
|
Diskadmin |
Управляет файлами SQL Server |
|
Bukladmin |
Может вставлять данные с использованием средств массового копирования, не имея непосредственного доступа в таблицам. |
SQL Server поддерживает такие встроенные роли уровня базы данных
|
Встроенная роль сервера |
Назначение |
|
Db_owner |
Имеет все права в базе данных |
|
Db_accessadmin |
Может добавлять или удалять пользователей |
|
Db_securityadmin |
Управляет всеми разрешениями, объектами, ролями и членами ролей |
|
Db_ddladmin |
Может выполнять любые команды DDL, кроме GRANT, DENY, REVOKE |
|
Db_backupoperator |
Может выполнять команды DBCC, CHECKPOINT, BACKUP |
|
Db_datareader |
Может просматривать любые данные в таблице |
|
Db_datawriter |
Может модифицировать любые данные в любой таблице |
|
Db_denydatareader |
Запрещается просматривать данные в таблице |
|
Db_denydatawriter |
Запрещается модифицировать данные в таблице |
Кроме указанных ролей существует еще одна, неудаляемая роль – public. Участниками этой роли являются все пользователи, имеющие доступ к базе данных. Нельзя явно указать участников этой роли, т.к. все пользователи уже включены в нее.
Рекомендуемая литература: 3, 4, 17, 18.
Лекция 13. Планирование ёмкости базы данных
Цель: рассмотреть управление дисковым пространством СУБД.
План:
1) Размер БД.
2) Производительности БД.
3) Объём внешней памяти.
Одна из важных функций системного администратора и администратора базы данных это выделение, управление и мониторинг необходимого пространства для SQL Server и базы данных. Оценка требуемого базе данных пространства может помочь планировать ваше пространства и определить требования аппаратной части.
Когда планируется база данных, то настраивается логическая структура. Под этой структурой несколько физических файлов и объектов которые отнимают дисковое пространство. Они включают журнал транзакций, таблицы и индексы которые составляют файлы данных.
Когда создаётся база данных, SQL Server создаёт копию базы данных model, включающую системные таблицы, которые содержат информацию о файлах, объектах, правах доступа и ограничениях. Эти таблицы увеличиваются в размере когда вы создаёте объекты в базе данных. Каждый объект, который вы создаёте генерирует новую строку, которая вставляется в одну или несколько системных таблиц.
Рассматриваются следующие факторы, когда рассчитывается размер пространства базы данных, которую она будет занимать:
1) размер базы данных model и системных таблиц, включая проектируемое приращение;
2) количество данных в таблицы, включая планируемое приращение;
3) количество и размер индексов, особенно размер ключевого поля, количество строк и фактор заполнения свойств;
4) размер файла журнала транзакций, на который влияет частота модификаций, размер каждой транзакции и как часто вы резервируете или очищаете журнал;
5) размер системных таблиц, таких как количество пользователей, объектов и подобного.
В начале выделяется под журнал транзакций от 10 до 25 процентов размера вашей базы данных для OLTP окружения. Вы можете выделить меньший процент для баз данных используемых напрямую для запросов.
После того, как определяется количество пространства, выделенное для базы данных model, рассчитывается количество данных в вашей таблице, включая проектируемое приращение. Это может быть рассчитано с помощью определения общего количества строк, размера строк, количества строк в странице и общее количество страниц, необходимых для каждой таблицы в базе данных.
Можно оценить количество страниц необходимых для таблиц и дисковое пространство, которое будет занимать таблица, если вы знаете количество символов для каждой строки и приблизительное количество строк, которые будут храниться в таблице.
Используем следующий метод: посчитать количество байтов в строке по общему количеству байтов в каждой колонке. Если одна или более колонок объявлена с изменчивым размером, вы можете прибавить среднее значение колонки для всех строк. Определим количество строк, содержащихся в каждой странице данных. Чтобы сделать это, разделим 8060 на количество байтов в строке. Округлим результат в меньшую сторону до ближайшего целого числа; Разделим среднее количество строк в таблице на количество строк хранящихся в каждой странице данных. Результат равен количеству страниц, которые необходимы для хранения вашей таблицы.
Для обеспечения наибольшей производительности своей базы данных, используем следующим способом: использовать RAID для улучшения производительности и обеспечения терпимости к ошибкам. использовать аппаратный RAID для более быстрого доступа к данных, и увеличения защищённости данных, и использовать подходящий уровень RAID для достижения прироста производительности, который вы хотите обеспечить и необходимый уровень терпимости к ошибкам. Если возможно, используйте RAID с параллельной записью прежде чем использовать файловые группы; Помещайте файлы данных и журнал транзакций на отдельные физические диски с отдельными контроллерами ввода вывода. Это позволяет журналу транзакций при операциях записи не соперничать с конкурирующими INSERT, UPDATE или Delete операциями в базе данных; Используйте файловые группы определённые пользователем, для помещения объектов базы данных на отдельные диски для облегчения стратегии резервного копирования в очень больших базах данных. Это позволяет вам установить индивидуальную стратегию резервного копирования основанную на частотерезервирования данных. Если вы имеете группу файлов, которая изменяется очень часто, вы можете резервировать эту таблицу или объект чаще.
Определение требований к операционной обстановке. Для выполнения этого этапа необходимо знать (хотя бы ориентировочно) объём работы издательства (т.е. количество книг, авторов и заказчиков), а также иметь представление о характере и интенсивности запросов.
Объём внешней памяти, необходимый для
функционирования системы, складывается из двух составляющих: память, занимаемая
модулями СУБД (ядро, утилиты, вспомогательные программы), и память, отводимая
под данные (
![]() ). Наиболее существенным обычно является
). Наиболее существенным обычно является
![]() . Объём памяти
. Объём памяти
![]() , требуемый для хранения данных, можно
приблизительно оценить по формуле
, требуемый для хранения данных, можно
приблизительно оценить по формуле
где li – длина записи в i-й таблице (в байтах), Ni – примерное (максимально возможное) количество записей в i-й таблице, Na – количество записей в архиве i-й таблицы. Коэффициент 2 перед суммой нужен для того, чтобы выделить память для хранения индексов, промежуточных данных, для выполнения объёмных операций (например, сортировки) и т.п.
Посчитаем приблизительно, какой объём внешней памяти потребуется для хранения данных. Примем ориентировочно, что:
1) одновременно осуществляется около пятидесяти проектов, работа над проектом продолжается в среднем два месяца (по 0,3К);
2) в компании работает 100 сотрудников (по 0,2К на каждого сотрудника);
3) издательство сотрудничает с тридцатью авторами (по 0,2К);
4) в день обслуживается порядка двадцати заявок (по 0,1К);
5) устаревшие данные переводятся в архив.
Тогда объём памяти для хранения данных за первый год примерно составит:
Mc = 2(100*0,2+6(50*0,3)+30*0,2+250(20*0,1)) = 1232 К или 1,2 М,
где 250 – количество рабочих дней в году, а 12 мес./2 мес. = 6. Объём памяти будет увеличиваться ежегодно на столько же при сохранении объёма работы.
Объём памяти, занимаемый программными модулями пользователя, обычно невелик по сравнению с объёмом самих данных, поэтому может не учитываться. Требуемый объём оперативной памяти определяется на основании анализа интенсивности запросов и объёма результирующих данных.
Рекомендуемая литература: 16, 18.
Лекция 14. Настройка производительности системы
Цель: рассмотреть повышение эффективности выполнения операторов SQL с помощью индексов.
План:
1) Понимание индекса.
2) Принципы работы индекса.
3) Синтаксис индекса.
Говоря попросту, индекс - это указатель на данные в таблице. Индекс как объект базы данных имеет много общего с указателем, обычно помещаемым в конце книги. Например, если вы хотите найти в книге все страницы, относящиеся к определенной теме, то сначала вы обращаетесь к указателю, в котором все рассматриваемые темы перечислены в алфавитном порядке, и только потом находите в книге нужные страницы. Индекс базы данных работает точно так же в том смысле, что он предоставляет вашему запросу информацию о точном физическом расположении данных в таблице. С помощью индексов вы получаете доступ к различным частям файлов базы данных, содержащим реальную информацию, однако с вашей точки зрения вы при этом всего лишь обращаетесь к соответствующим таблицам. Что по-вашему будет быстрее: просматривать в поисках необходимой информации всю книгу страница за страницей или, обратившись к указателю, сразу определить номера всех нужных страниц? Нет сомнения, что применение указателя в этом случае гораздо более эффективно. Однако все эти рассуждения справедливы только для книги относительно большого размера. В том случае, когда в книге содержится всего несколько страниц, гораздо быстрее отыскать нужную информацию просто перелистывая эти страницы, чем постоянно переключать свое внимание с указателя на найденный материал и обратно.
Создание и удаление индексов не оказывает никакого влияния на сами данные, хотя их удаление может приводить к снижению эффективности выборки информации. Индексы занимают дисковое пространство, при этом их размер может превосходить размер самих таблиц.
При создании индекса в нем сохраняется информация о местонахождении значений, относящихся к индексируемому столбцу таблицы. В процессе добавления в таблицу новых данных индекс также дополняется новыми записями. При выполнении запроса к базе данных, в условие поиска которого входит индексированный столбец, поиск значений, определенных в предложении WHERE, происходит прежде всего именно в индексе. Если этот поиск оказывается успешным, индекс возвращает точное местоположение искомых данных в таблице. Рисунок 14.1 наглядно иллюстрирует, каким образом работает индекс.
|
|
|
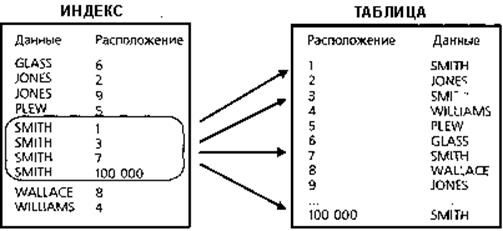
Рисунок 14.1- Доступ к таблице с помощью индекса
Предположим, что должен быть выполнен следующий запрос:
SELECT *
FROM TABLE_NAME
WHERE NAME = 'SMITH';
Как показано на рисунке 14.1, сначала по индексу, построенному для фамилий сотрудников, происходит поиск всех значений, совпадающих с символьной строкой ' SMITH '. После того, как местонахождение данных определено, очень быстро можно отыскать в таблице и сами данные (в рассматриваемом примере это фамилии сотрудников). Как видите, данные расположены в индексе в алфавитном порядке. Если бы при выполнении этого запроса у таблицы отсутствовал соответствующий индекс, был бы выполнен ее полный просмотр; это значит, что для поиска информации, относящейся ко всем служащим по фамилии SMITH, пришлось бы просматривать все строки данных таблицы.
Команда CREATE INDEX . Как и в случае многих других операторов SQL, у различных производителей реляционных баз данных синтаксис команды CREATE INDEX имеет существенные отличия.
Базовый синтаксис оператора CREATE INDEX, принятый в большин-стве реализации, имеет следующий вид:
CREATE INDEX ИМЯ ИНДЕКСА ON ИМЯ ТАБЛИЦЫ
Все последующие отличия в синтаксисе оператора CREATE INDEX в основном связаны с широким применением различными производителями многочисленных опций. Некоторые реализации допускают использование предложения STORAGE (аналогично оператору CREATE TABLE), упорядочение информации по возрастанию и убыванию (опции ASC и DESC), а также применение кластеров. Обязательно выясните, какой именно синтаксис команды CREATE INDEX применяется в вашей конкретной реализации.
Типы индексов . Вы можете создавать для таблиц базы данных различные типы индексов, однако все они служат одной и той же цели - повышению производительности базы данных за счет ускорения поиск информации. В этой главе мы рассмотрим простые, составные и уникальные индексы.
Простейшей и вместе с тем наиболее распространенной разновидностью индексов является простой (или одностолбцовый) индекс. Из его названия ясно, что одностолбцовый индекс создается на основе единственного столбца таблицы.
Базовый синтаксис для построения простого индекса имеет следующий вид:
CREATE INDEX ИМЯ_ИНДЕКСА ON ИМЯ_ТАБЛИЦЫ (ИМЯ_СТОЛБЦА)
Например, для таблицы EMPLOYEE_TBL вы могли бы создать индекс по полю, содержащему фамилии служащих вашей компании, с помощью следующей команды:
CREATE INDEX NAME_IDX ON EMPLOYEE_TBL (LAST NAME) ;
Уникальные индексы используются не только с целью повышения производительности системы, но и для поддержки целостности данных. Уникальный индекс не допускает введения в таблицу дублирующих значений. Во всех других отношениях он ничем не отличается от обычного индекса.
Cинтаксис для построения уникального индекса имеет следующий вид:
CREATE UNIQUE INDEX ИМЯ_ИНДЕКСА ON ИМЯ_ТАБЛИЦЫ (ИМЯ_СТОЛБЦА)
Например, для таблицы EMPLOYEE_TBL вы могли бы создать уникальный индекс по полю, содержащему фамилии служащих вашей компании, с помощью следующей команды:
CREATE UNIQUE INDEX NAME_IDX ON EMPLOYEE_TBL (LAST NAME) ;
Единственным недостатком этого индекса является то, что теперь каждая фамилия служащего в таблице EMPLOYEE_TBL должна быть уникальной, что, вообще говоря, представляется не совсем логичным.
Составными называются индексы, построенные по двум или более столбцам таблицы. При создании составных индексов вы обязательно должны принимать во внимание соображения, связанные с производительностью системы, поскольку порядок столбцов составного индекса оказывает ощутимое влияние на скорость поиска данных. Исходя из общих соображений, в целях оптимальной производительности системы первым следует помещать наиболее ограничивающее значение. В то же время первыми желательно помещать и столбцы, которые почти всегда задаются в условиях поиска.
Cинтаксис для создания составного индекса имеет следующий вид:
CREATE INDEX ИМЯ_ИНДЕКСА ON ИМЯ_ТАБЛИЦЫ (ИМЯ_СТОЛБЦА1, ИМЯ_СТОЛБЦА2)
Далее следует пример построения составного индекса:
CREATE INDEX ORD_IDX ON ORDERS_TBL (CUST_ID, PROD_ID) ;
В этом примере мы создали составной индекс по двум столбцам таблицы ORDERS_TBL: CUST_ID и PROD_ID. При этом мы исходили из предложения, что оба этих столбца довольно часто совместно используются в качестве условия поиска в предложениях WHERE запросов.
Принимая решение относительно применения простого или составного индекса, вы должны исходить из числа столбцов, обычно задаваемых в предложениях WHERE запросов в качестве условий фильтрации. Если в этом случае используется только один столбец, хорошим выбором будет простой индекс. Если же в предложениях WHERE в качестве фильтров часто используются два или более столбцов, следует отдать предпочтение составному индексу.
В каких случаях следует применять индексы .
Для того, чтобы первичные ключи могли успешно работать, совместно с ними неявно создаются уникальные индексы. Прекрасными кандидатами для создания индексов также являются внешние ключи, поскольку они часто используются для соединения с родительскими таблицами. Как правило, большинство столбцов, используемых при соединении таблиц (или даже все они), должно быть проиндексировано. Следует внимательно отнестись к возможности построения индексов и для тех столбцов, на которые вам часто приходится ссылаться в предложениях ORDER BY и GROUP BY.
В каких случаях применение индексов является нежелательным ?
Несмотря на то, что индексы предназначены для повышения производительности базы данных, иногда их применение является нежелательным. Принимая решение об отказе от применения индексов, вы должны руководствоваться следующими соображениями:
1) Индексы не следует применять в случае небольших таблиц.
2) Индексы не следует применять для столбцов, задание которых в качестве фильтров в предложениях where запросов, приводит к возвращению из таблиц большого в процентном отношении количества данных. Например, вы вряд ли найдете в указателе книги такие слова, как "и" или "на" в силу их очень большой употребительности.
3) В принципе допустимо индексирование таблиц, для которых сравнитель-но часто выполняется широкомасштабное пакетное обновление данных. Однако следует иметь в виду, что это приводит к значительному замедле-нию пакетной обработки. Противоречие, связанное с наличием индекса у часто загружаемой и обновляемой таблицы, может быть разрешено, на-пример, путем удаления этого индекса перед началом пакетной обработки с его последующим восстановлением после ее завершения.
4) Индексы не следует применять для столбцов, содержащих большое коли-чество нулевых значений.
5) Также не следует индексировать столбцы, данные в которых подвержены слишком частому изменению, поскольку поддержка индекса в этом слу-чае может оказаться сопряженной с чрезмерными затратами ресурсов.
Следует проявлять особую осторожность при использовании в индексах полей большого размера, поскольку в силу высоких требований к ресурсам, предъявляемых системой ввода/вывода, в этом случае неизбежно страдает производительность базы данных.
Рекомендуема литература: 4, 17, 18.
Список литературы
1 Дейт, К. Дж. Введение в системы баз данных, 8-е издание.: Пер. с англ. - М.: Издательский дом "Вильяме", 2005.
2 Роб П., Коронел К. Системы баз данных: проектирование, реализация и управление. - 5-е изд.: СПб.: БХВ-Петербург, 2004.
3 Кренке Д. Теория и практика построения баз данных. 8-е изд. – СПб.: Питер, 2003.
4 Бегг К., Коннолли Т. Базы данных. Проектирование, реализация и сопровождение. Теория и практика. - изд.: Вильямс, 2003.
5 Основы баз данных: курс лекций: учеб. пособие / С.Д. Кузнецов. –М.:Интернет-Ун-т Информ. Технологий, 2005.
6 Вендров А.М. CASE-технологии. Современные методы и средства проектирования информационных систем. - М.: Финансы и статистика, 1998.
7 Вендров А.М. Проектирование программного обеспечения экономических информационных систем. - М.: Финансы и статистика, 2000.
8 Фаулер М., Скотт К. UML в кратком изложении. Применение стандартного языка объектного моделирования. - М.: Мир, 1999
9 Буч Г. Объектно-ориентированный анализ и проектирование с примерами приложений на C++. 2-е изд.- М.: Бином; СПб.: Невский диалект, 1999.
10 Буч Г., Рамбо Д., Джекобсон А. Язык UML: руководство пользователя. - М.: ДМК, 2000.
11 Когаловский М.Р. Энциклопедия технологий баз данных. -М.: Финансы и статистика, 2002.
12 Гектор Гарсиа-Молина, Джеффри Ульман, Дженифер Уидом. Системы баз данных. Полный курс.- М., С.-Петербург, Киев: Вильямс, 2003.
13 Боуман Дж., Эмерсон С., Дарновски М. Практическое руководство по SQL.
14 Дж. Гофф, П. Вайнберг SQL : Полное руководство: Пер. с англ. -2-е изд. – К.: Изд. BHV /. 2001.
15 Форта, Бен. Освой самостоятельно SQL. 10 минут на урок, 3-е изд. : Пер. с англ. — М. : Издательский дом "Вильяме", 2005.
16 Клайн К . SQL . Справочник .
17 Ролланд Ф., Основные концепции баз данных .
18 Дибетта П. Знакомство с Microsoft SQL Server 2005 / Пер. с англ.-М.: Издательско-торговый дом “Русская Редакция”, 2005. -288 с.:ил.