Некоммерческое акционерное общество
АЛМАТИНСКИЙ УНИВЕРСИТЕТ ЭНЕРГЕТИКИ И СВЯЗИ
Кафедра компьютерной технологии
ОРГАНИЗАЦИЯ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ И СЕТЕЙ
Конспект лекций
для студентов специальности
5В070400– Вычислительная техника и программное обеспечение
Алматы 2013
СОСТАВИТЕЛИ: Т.Т. Коржымбаев, Г.С. Нурмагамбетов. Конспект лекций по дисциплине «Организация вычислительных систем и сетей» для студентов специальности 5В070400 - . Вычислительная техника и программное обеспечение. – Алматы: АУЭС, 2013. - 67 с.
В конспекте лекций рассмотрены основы вычислительных машин и вычислительных систем играющие особую роль в современном мире. Изложение материала построено так и в таком объеме, чтобы подготовить студента к систематическому и самостоятельному изучению современных систем моделирования и проектирования.
Конспект лекций составлен в целях закрепления основ вычислительных машин и вычислительных систем и предназначен для студентов специальности 5В070400 – Вычислительная техника и программное обеспечение.
Ил. 42, табл. 1, библиогр. – 6 назв.
Рецензент: Башкиров М.В.
Печатается по плану издания Некоммерческого акционерного общества «Алматинский университет энергетики и связи» на 2013 г.
© НАО «Алматинский университет энергетики и связи», 2013 г.
Содержание
|
|
Введение |
4 |
|
1 |
Лекция №1. Базовые понятия информации |
5 |
|
2 |
Лекция №2. Компьютер – общие сведения |
8 |
|
3 |
Лекция №3. Многоуровневая компьютерная организация |
12 |
|
4 |
Лекция №4. Математическое обеспечение компьютеров |
15 |
|
5 |
Лекция №5. Вычислительные системы - общие сведения |
17 |
|
6 |
Лекция №6. Структурная организация ЭВМ – процессор |
23 |
|
7 |
Лекция №7. Структурная организация ЭВМ – память |
29 |
|
8 |
Лекция №8. Логическая организация памяти |
34 |
|
9 |
Лекция №9. Методы адресации |
38 |
|
10 |
Лекция №10. Внешняя память компьютера |
41 |
|
11 |
Лекция №11. Основные принципы построения ввода/вывода |
47 |
|
12 |
Лекция №12. Особенности архитектуры современных высокопроизводительных ВС |
52 |
|
13 |
Лекция №13. Архитектура многопроцессорных систем |
57 |
|
14 |
Лекция №14. Кластерные системы |
60 |
|
15 |
Лекция №15. Многомашинные системы-вычислительные сети |
62 |
|
|
Заключение |
66 |
|
|
Список литературы |
67 |
Введение
В настоящее время трудно представить себе, что без вычислительных машин или компьютеров можно обойтись. Компьютеры стали частью не только сферы производства, но и домашнего быта. Множество людей проводят часы за экраном своего компьютера, получая последние новости, биржевые сводки, цены, технические сведения, прогноз погоды и многое другое из сети Интернет, а также используют компьютер для игр и развлечений. При написании этого учебного пособия авторы также широко пользовались компьютером и материалами из Интернета. Это позволило не только подготовить рукопись значительно быстрее, но и сделать ее полнее и современнее.
Термин «электронная вычислительная машина», или ЭВМ, совершенно не означает, что она предназначена только для каких-либо вычислений. Это уже не просто вычислительные машины, а системы обработки данных, способные хранить информацию, редактировать, обновлять, выполнять сортировку и поиск нужных данных, формировать таблицы, диаграммы и отчеты, осуществлять логические преобразования, выдачу результатов и т. п. По этой причине в настоящее время вычислительную машину (особенно персональную) принято называть английским термином «компьютер».
Повсеместное внедрение компьютеров в современную жизнь, регулярное обновление их аппаратных и программных средств, постоянная модернизация и появление все новых компонентов требуют глубокого знания принципов их работы. Аппаратные средства компьютеров, а именно современные процессоры, память, периферийные устройства и устройства подключения вычислительных машин к сетям, описаны в учебной литературе явно недостаточно. Возможно, это вызвано тем, что, покупая «готовый» компьютер, потребитель не пытается узнать, как он устроен. Больше всего покупателя интересуют стандартные программные средства и их возможности для удовлетворения своих потребностей. Но невозможно понять работу программных средств, не обладая хотя бы минимальными знаниями об аппаратуре.
Небольшие по габаритным размерам, но обладающие достаточной вычислительной мощностью компьютеры стали широко доступными. Объединение нескольких таких машин между собой, т. е. создание компьютерных сетей, обеспечило получение самой разнообразной информации. В настоящее время компьютерами пользуется все цивилизованное человечество, это стало возможным благодаря дружественным программам и интерфейсам, ставшим непременной частью компьютера. Получила развитие всемирная сеть Интернет, объединившая средства вычислительной техники и техники связи и дающая возможность узнавать и сообщать последние новости. Теперь практически все машины тем или иным способом взаимодействуют с глобальными и локальными сетями, т. е. компьютеры становятся компонентами все более крупных систем.
1 Лекция №1. Базовые понятия информации
Цель лекции: изучение основных видов преобразования сигналов в информационных процессах.
Содержание лекции: информационные процессы. Способы представления информации и два класса ЭВМ. Представление данных в ЭВМ.
Мы понимаем под информацией все, так или иначе оформленные сведения или сообщения о вещах и явлениях, которые уменьшают степень неопределенности, хаотичности знаний об этих вещах или явлениях. Информация не есть нечто статичное, неизменное, она не существует вне взаимодействия объектов. Как правило, с ней все время что-то происходит, т.е. осуществляются информационные процессы. Эти процессы можно разделить на четыре группы – сбор, хранение, обработка и передача информации.
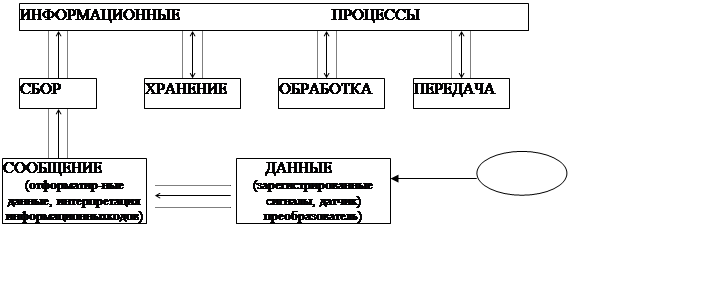
Рисунок 1.1 - Информационные процессы
Восприятие информации приемником – преобразователем осуществляется при помощи сигналов. Сигналы имеют различную физическую природу и являются продуктами энергообмена, имеющие в своей основе материальную природу. Данные– это зарегистрированные сигналы. Данные, несоответствующие ни каким целям объекта, не несут для него информацию и, поэтому, пропадают, возвращая объект в то состояние, в котором он был до получения этих данных.
1.2 Способы представления информации и два класса ЭВМ
Первая форма представления информации называется аналоговой или непрерывной. Величины, представленные в такой форме, могут принимать любые значения, в каком – то диапазоне. Они могут быть сколь угодно близки друг к другу и изменяться в произвольные моменты времени.
Вторая форма представления информации называется цифровой или дискретной.
1.3 Представление данных в ЭВМ
За основу представления данных в ЭВМ, как правило, принята двоичная система счисления. Как и десятичная система счисления, двоичная система (в которой используются лишь цифры 0 или 1) является позиционной системой счисления, т.е. в ней значение каждой цифры числа зависит от положения (позиции) этой цифры в записи числа. Каждой позиции присваивается определенный вес.
Кодирование чисел
Существуют два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел. Множество целых чисел, представимых в памяти ЭВМ, ограничено. Диапазон значений зависит от размера области памяти, используемой для размещения чисел. В k-разрядной ячейке может храниться 2k различных значений целых чисел. Чтобы получить внутреннее представление целого положительного числа N, хранящегося в k-разрядном машинном слове, необходимо:
1) перевести число N в двоичную систему счисления;
2) полученный результат дополнить слева незначащими нулями до k разрядов.
Кодирование текста
Множество символов, используемых при записи текста, называется алфавитом. Количество символов в алфавите называется его мощностью.
Для представления текстовой информации в компьютере чаще всего используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации, т. к. 28 = 256. Но 8 бит составляют один байт, следовательно, двоичный код каждого символа занимает 1 байт памяти ЭВМ.
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части - растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element). Код пикселасодержит информацию о его цвете. Для черно-белого изображения (без полутонов) пиксел может принимать только два значения: белый и черный (светится - не светится), а для его кодирования достаточно одного бита памяти: 1 - белый, 0 - черный. Пиксел на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 - черный, 10 - зеленый, 01 - красный, 11 - коричневый.
Кодирование звука
Из курса физики вам известно, что звук - это колебания воздуха. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), мы увидим плавно изменяющееся с течением времени напряжение. Для компьютерной обработки такой - аналоговый - сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел.
Поступим следующим образом. Будем измерять напряжение через равные промежутки времени и записывать полученные значения в память компьютера. Этот процесс называется дискретизацией (или оцифровкой), а устройство, выполняющее его - аналого-цифровым преобразователем (АЦП).

Для того чтобы воспроизвести закодированный таким образом звук, нужно выполнить обратное преобразование (для него служит цифро-аналоговый преобразователь - ЦАП), а затем сгладить получившийся ступенчатый сигнал.
Для представления данных существует три основных формата:
- двоичный с фиксированной запятой;
- двоичный с плавающей запятой;
- двоично-кодированный десятичный (BCD).
Если надо закодировать целое число со знаком, то старший бит регистра (ячейки памяти) используется для хранения знака (0 при положительном знаке числа и 1 при отрицательном) – формат с фиксированной запятой.
![]()
![]()
![]()
![]() Цифры числа
Цифры числа
Исходные возможности компьютера позволяют ему работать только с целыми числами, к тому же не самыми большими. Даже в случае 2х байтового слова, мы можем записать максимальное число 65536, учитывая необходимость отображения, как положительных чисел, так и отрицательных получаем только половину всех числовых значений. Способы представления чисел и программное обеспечение позволяют значительно расширить возможности компьютера. Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму:
3,1415926 = 0,31415926 · 101;
500 000 = 0,5 · 106;
123 456 789 = 0,1 · 1010.
Первая часть числа называется мантиссой- М, а вторая – порядком q.
Для того чтобы оперировать дробными числами или числами очень большой длины, используется понятие плавающей запятой. Плавающая запятая действует по принципу экспоненциального формата – числа вида -+M *q+p.
15 14 13 8 7 0
 Знак числа (мантиссы)
Знак числа (мантиссы)
Знак порядка Модуль Модуль
мантиссы порядка
Необходимо отметить что, вычисления с целыми числами выполняются очень быстро, в то время как вычисления с плавающей запятой в сотни раз медленнее.
Для реализации скоростных вычислений с плавающей запятой применяются числовые сопроцессоры (FPU – floatingpointunit). Данные в нем хранятся в 80-ти разрядных регистрах.
2 Лекция №2. Компьютер – общие сведения
Цель лекции: классификация компьютера и их характеристик, определяющих их применение в системах управления и других областях.
Содержание лекции: Материнская плата и ее электронные компоненты. Интерфейсные шины. Основные внешние устройства компьютера.
Компьютер, по существу, устройство способное исполнять четко определенную последовательность операций, предписанную программой. Очень грубо, все многообразие компьютеров можно разделить на три основных класса: персональные системы (от настольных, до карманных), мейнфреймы и сервера на их основе и суперкомпьютеры.
Основные электронные компоненты, определяющие структуру компьютера, размещаются на основной плате компьютера, которая называется системной или материнской (Mother Board). А контроллеры и адаптеры дополнительных устройств, либо сами эти устройства, выполняются в виде плат расширения (Dаughter Board — дочерняя плата) и подключаются к шине с помощью разъёмоврасширения, называемых также слотами расширения (англ. slot — щель, паз).
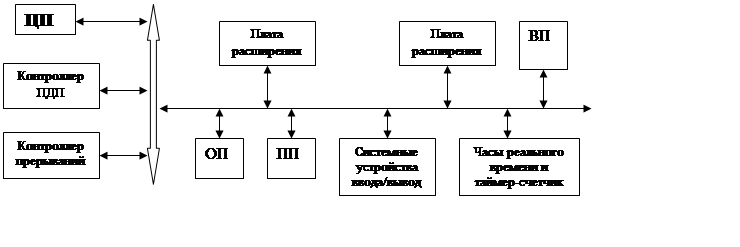
СМ
. . . . .
Рисунок 2.1- Структура персонального компьютера типа IBMPC
Функции основных узлов компьютера следующие:
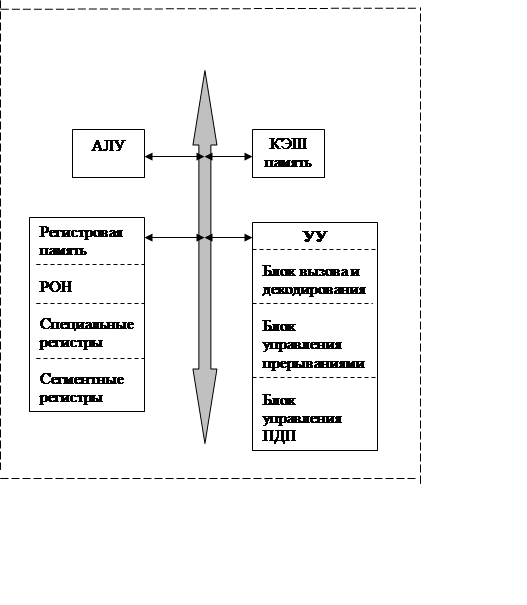
1) Контроллер прерываний преобразует аппаратные прерывания системной магистрали в аппаратные прерывания процессора и задает адреса векторов прерывания. Все режимы функционирования контроллера прерываний задаются программно процессором перед началом работы.
2) Контроллер прямого доступа к памяти принимает запрос на ПДП из системной магистрали, передает его процессору, а после предоставления процессором магистрали производит пересылку данных между памятью и устройством ввода/вывода. Все режимы функционирования контроллера ПДП задаются программно процессором перед началом работы. Использование встроенных в компьютер контроллеров прерываний и ПДП позволяет существенно упростить аппаратуру применяемых плат расширения.
3) Контроллер регенерации осуществляет периодическое обновление информации в динамической оперативной памяти путем проведения по шине специальных циклов регенерации.
4) Часы реального времени и таймер-счетчик — это устройства для внутреннего контроля времени и даты, а также для программной выдержки временных интервалов, программного задания частоты и синхронизации всех процессов.
5) Системные устройства ввода/вывода — это те устройства, которые необходимы для работы компьютера и взаимодействия со стандартными внешними устройствами по параллельному и последовательному интерфейсам. Они могут быть выполнены на материнской плате, а могут располагаться на платах расширения.
6) Платы расширения устанавливаются в слоты (разъемы) системной магистрали и могут содержать оперативную память и устройства ввода/вывода.
Таким образом, структура персонального компьютера из одношинной, применявшейся только в первых компьютерах, становится трехшинной.
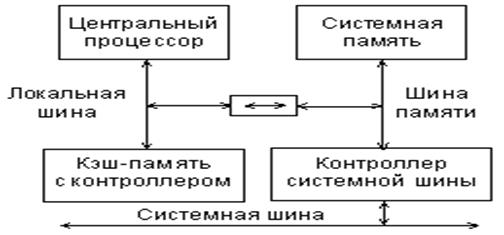
Рисунок 2.2 - Организация связей в случае трехшинной структуры
Назначение шин следующее:
- к локальной шине подключаются центральный процессор и кэш-память (быстрая буферная память);
- к шине памяти подключается оперативная и постоянная память компьютера, а также контроллер системной шины;
- к системной шине (магистрали) подключаются все остальные устройства компьютера.
2.3 Основные внешние устройства компьютера
Клавиатура служит для ввода информации в компьютер и подачи управляющих сигналов. Она содержит стандартный набор алфавитно-цифровых клавиш и некоторые дополнительные клавиши — управляющие и функциональные, клавиши управления курсором, а также малую цифровую клавиатуру.
Видеосистема компьютера состоит из трех компонент:
- монитор (называемый также дисплеем);
- видеоадаптер;
- программное обеспечение (драйверы видеосистемы).
Видеоадаптер посылает в монитор сигналы управления яркостью лучей и синхросигналы строчной и кадровой развёрток. Монитор преобразует эти сигналы в зрительные образы. А программные средства обрабатывают видеоизображения — выполняют кодирование и декодирование сигналов, координатные преобразования, сжатие изображений и др.
Подавляющее большинство мониторов сконструированы на базе электронно-лучевой трубки (ЭЛТ), и принцип их работы аналогичен принципу работы телевизора. Мониторы бывают алфавитно-цифровые и графические, монохромные и цветного изображения. Современные компьютеры комплектуются, как правило, цветными графическими мониторами.
Наряду с традиционными ЭЛТ-мониторами все шире используются плоские жидкокристаллические (ЖК) мониторы.
Жидкие кристаллы — это особое состояние некоторых органических веществ, в котором они обладают текучестью и свойством образовывать пространственные структуры, подобные кристаллическим. Жидкие кристаллы могут изменять свою структуру и светооптические свойства под действием электрического напряжения. Меняя с помощью электрического поля ориентацию групп кристаллов и используя введённые в жидкокристаллический раствор вещества, способные излучать свет под воздействием электрического поля, можно создать высококачественные изображения, передающие более 15 миллионов цветовых оттенков.
Большинство ЖК-мониторов использует тонкую плёнку из жидких кристаллов, помещённую между двумя стеклянными пластинами. Заряды передаются через так называемую пассивную матрицу — сетку невидимых нитей, горизонтальных и вертикальных, создавая в месте пересечения нитей точку изображения (несколько размытого из-за того, что заряды проникают в соседние области жидкости).
Сенсорными экранами оборудуют рабочие места операторов и диспетчеров, их используют в информационно-справочных системах и т.д.
Видеоадаптер — это электронная плата, которая обрабатывает видеоданные (текст и графику) и управляет работой дисплея. Содержит видеопамять, регистры ввода вывода и модуль BIOS. Посылает в дисплей сигналы управления яркостью лучей и сигналы развертки изображения.
Графические акселераторы (ускорители) — специализированные графические сопроцессоры, увеличивающие эффективность видеосистемы. Их применение освобождает центральный процессор от большого объёма операций с видеоданными, так как акселераторы самостоятельно вычисляют, какие пиксели отображать на экране и каковы их цвета.
Манипуляторы (мышь, джойстик и др.) — это специальные устройства, которые используются для управления курсором.
Мышь имеет вид небольшой коробки, полностью умещающейся на ладони. Мышь связана с компьютером кабелем через специальный блок — адаптер, и её движения преобразуются в соответствующие перемещения курсора по экрану дисплея. В верхней части устройства расположены управляющие кнопки (обычно их три), позволяющие задавать начало и конец движения, осуществлять выбор меню и т.п.
Принтеры (печатающие устройства) - это устройства вывода данных из ЭВМ, преобразующие информационные ASCII-коды в соответствующие им графические символы (буквы, цифры, знаки и т.п.) и фиксирующие эти символы на бумаге.
Сканер - это устройство ввода в ЭВМ информации непосредственно с бумажного документа. Можно вводить тексты, схемы, рисунки, графики, фотографии и другую графическую информацию.
Сканеры являются важнейшим звеном электронных систем обработки документов и необходимым элементом любого "электронного стола". Записывая результаты своей деятельности в файлы и вводя информацию с бумажных документов в ПК с помощью сканера с системой автоматического распознавания образов, можно сделать реальный шаг к созданию систем безбумажного делопроизводства.
Сканеры весьма разнообразны, и их можно классифицировать по целому ряду признаков. Сканеры бывают черно-белые и цветные.
3 Лекция №3. Многоуровневая компьютерная организация
Цель лекции: изучение принципов построения современных ПК их структурной и функциональной организации.
Содержание лекции: архитектура комьютера. Классическая структура ЭВМ - модель фон Неймана.
Применительно к вычислительным системам в целом термин «архитектура» можно интерпретировать как распределение функций, реализуемых системой, по ее уровням и определение интерфейсов между этими уровнями. Очевидно, архитектура вычислительной системы предполагает многоуровневую, иерархическую организацию.
Взаимодействие между различными уровнями осуществляется посредством интерфейсов. Например, система в целом взаимодействует с внешним миром через набор интерфейсов: языки высокого уровня, системные программы и т.д. Большинство современных вычислительных систем состоят из трех и более уровней.
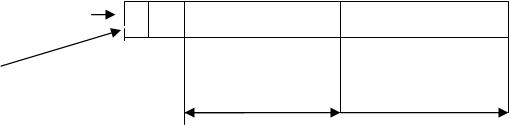
Совокупность всех возможных команд образует систему команд процессора. Именно система команд (расширенная или сокращенная) разделяет процессоры на RISC, CISC или векторные, суперскалярные и т.д. Машинная команда состоит из двух частей: операционной и адресной. Типовая структура трехадресной команды:
|
КОП |
Адрес 1-го операнда |
Адрес 2-го операнда |
Адрес результата |
Типовая структура двухадресной команды:
|
КОП |
Адрес 1-го операнда |
Адрес 2-го операнда |
В этом случае, результат операции записывается на место 1-го операнда.
Типовая структура одноадресной команды:
|
КОП |
Адрес операнда, результата или перехода |
Типовая структура безадресной команды:
|
КОП |
Расширение кода операции |
Уровень 5
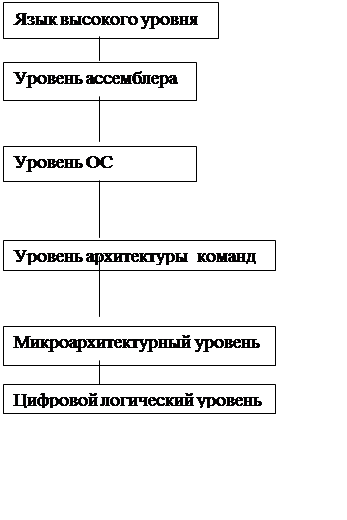 |
Трансляция (компилятор)
Уровень 4
Трансляция (ассемблер)
Уровень 3
Трансляция
Уровень 2
Интерпретация (микропрограмма)
Уровень 1
Аппаратное обеспечение
Уровень 0
Рисунок 3.1 - Шестиуровневое представление компьютера.
3.2 Классическая структура ЭВМ - модель фон Неймана
В каждой области науки и техники существуют некоторые фундаментальные идеи или принципы, которые определяют ее содержание и развитие. В компьютерной науке роль таких фундаментальных идей сыграли принципы, сформулированные независимо друг от друга двумя гениями современной науки - американским математиком и физиком Джоном фон Нейманом и советским инженером и ученым Сергеем Лебедевым.
Сущность "Неймановских Принципов" состояла в следующем:
1) двоичная система счисления - компьютеры на электронных элементах должны работать не в десятичной, а в двоичной системе счисления;
2) принцип программного управления и хранимой в памяти программы - компьютер работает под управлением программы, программа должна размещаться в одном из блоков компьютера - в запоминающем устройстве (первоначально программа задавалась путем установки перемычек на коммутационной панели);
3) принцип однородности - команды, так же как и данные, с которыми оперирует компьютер, хранятся в одном блоке памятии записываются в двоичном коде, то есть по форме представления команды и данные однотипны и хранятся в одной и той же области памяти;
4) принцип адресности – основная память структурно состоит из нумерованных ячеек, т.е. доступ к командам и данным осуществляется по адресу.
Структура ЭВМ фон Неймана приведена на рисунок 3.2.
Память Процессорное устройство

Рисунок 3.2 - Модель фон Неймана
Обычно в этих ЭВМ данные представляются в виде скалярных данных, векторов и матриц. Числа в ЭВМ представляются как целые.
Таким образом, ЭВМ с архитектурой фон Неймана, это ЭВМ с управлением потоком команд. Принято считать, что ВМ с архитектурой фон Неймана присущи следующие особенности:
1) единая, последовательно адресуемая память (обычные скалярные однопроцессорные системы, при этом наличие конвейера не меняет дела);
2) память является линейной и одномерной (одномерная – имеет вид вектора слов, память состоит из ячеек фиксированной длины и имеет линейную структуру адресации);
3) отсутствует явное различие между командами и данными;
4) ход выполнения вычислительного процесса определяется только централизованными и последовательными командами или, другими словами, управление потоком команд (выбрать адрес команды – выбрать данные – произвести действие и т.д.);
5) назначение данных не является их неотъемлемой, составной частью, назначение данных определяется логикой программ
4 Лекция № 4. Математическое обеспечение компьютеров
Цель лекции: изучение программных средств и их классификация.
Содержание лекции: программное обеспечение компьютера. Библиотеки стандартных программ и ассемблеры. Прикладные программы и CASE – технологии. Компьютерные сети и мультимедиа. Операционные системы.
4.1 Программное обеспечение компьютера
Иногда говорят, что вычислительная техника (hardware) без программ, олицетворяющих действия людей по управлению ею, мертва и бездушна как всякое железо. И только программное обеспечение (software) вдыхает жизнь в эти кристаллы, разъемы и провода, заставляет компьютеры делать все те чудеса, которым мы не перестаем удивляться.
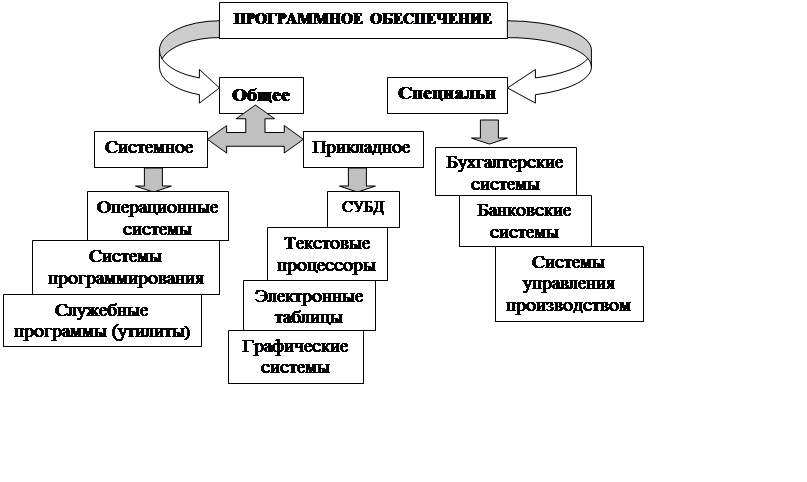
Рисунок 4.1 - Программное обеспечение компьютера
Пакеты прикладных программ представляют собой структурированные комплексы программ (часто со специализированными языковыми средствами), предназначенные для решения определенных задач, а также для расширения функций ОП (управления базами данных и др.). Аппаратные средства ЭВМ и система ее программного обеспечения образуют вычислительную систему.
Общее ПО, в свою очередь, подразделяется на системное, служащее для разработки программ и поддержки вычислительного процесса на компьютере (операционные системы, системы программирования, различные вспомогательные программы) и прикладное, иначе называемое пакетами прикладных программ (ППП). Типичными ППП являются текстовые процессоры, системы управления базами данных (СУБД), электронные таблицы, некоторые другие широко распространенные программы. Граница раздела между упомянутыми классами весьма условна и в процессе эволюции постоянно передвигается в пользу общего ПО.
4.2 Библиотеки стандартных программ и ассемблеры
Первые вычислительные машины вообще не имели никакого общего программного обеспечения. Программы для решения конкретных задач писались с нуля, в машинных двоичных кодах (для сокращения записи использовалась восьмеричная или шестнадцатеричная система, но это не меняло сути) в абсолютных адресах, они загружались в чистую оперативную память.
Вторая проблема была связана с мнемоническим кодированием и автоматическим распределением памяти. Вместо того, чтобы записывать коды операций двоичными цифрами программист писал текст программы на символическом языке, пользуясь мнемоническими обозначениями операций и условными адресами, а специальная программа автоматически преобразовывала мнемонические коды в понятные машине двоичные, и распределяла память для выполнения программы.. Языки программирования низкого уровня, в которых коды операций заменены мнемоническими обозначениями, стали называться языками ассемблера или автокодами (мнемокодами), а преобразующие программы — ассемблерами.
Диалоговые ОС и СУБД
Создание крупных информационных систем поставило перед разработчиками общего ПО проблему хранения больших массивов данных и организации их обработки множеством независимых программ. Так возникла концепция систем управления базами данных (СУБД).
Использование СУБД произвело настоящую революцию в индустрии обработки данных. Многие заказные кустарные программы, осуществляющие стандартные операции над данными, оказались ненужными, они были вытеснены надежными промышленными продуктами. Это— характерный пример того, как специальное ПО становится общим.
4.3 Прикладные программы и CASE –технологии
Повальное увлечение домашними компьютерами и потребительским софтом как-то отодвинуло в тень работы по совершенствованию серьезного общего программного обеспечения. По-видимому, самым большим успехом в этом направлении в 80-е годы можно считать разработку CASE-технологий, то есть технологий автоматизированного проектирования программного обеспечения (CASE — Computer Aided Software Design). Даже применение языков высокого уровня таких как Cobol, Pascal или C и средств СУБД не избавляет программиста от рутинной работы по проектированию связанных информационных таблиц и организации диалога. Программисту остается подправить текст, если он его почему-то не устраивает, пропустить через компилятор и получить готовую программу.
4.4 Компьютерные сети и мультимедиа
Развитие сетевых технологий потребовало разработки соответствующего слоя общего программного обеспечения. Историю и современное состояние компьютерных сетей, а также их программного обеспечения мы будем рассматривать позже, а сейчас несколько слов скажем еще об одном важном достижении, которое в 90-х годах перешло из разряда экспериментальных в общедоступные. Речь идет о мультимедиа-технологиях. Буквальный перевод слова multimedia — «многие среды». Имеются в виду типы объектов, с которыми имеет дело компьютер. В прежние времена вариантов было немного: стандартный компьютер вводил, обрабатывал и выводил только строки символов или неподвижные картинки, на большее не хватало ни мощности процессора, ни объема памяти, ни возможностей устройств вввода-вывода. Однако в последние годы эти характеристики достигли такого состояния, что появилась возможность существенно расширить класс обрабатываемых объектов.
4.5 Операционные системы
История операционных систем начинается в 60-е годы, когда для облегчения труда операторов и экономии машинного времени были созданы первые программы-автооператоры и мониторные системы. Впоследствии они развились в операционные системы следующих основных типов:
- пакетные (однозадачные и с мультипрограммированием);
- диалоговые (с разделением времени — ОС РВ);
- системы реального времени.
5 Лекция №5. Вычислительные системы - общие сведения
Цель лекции: изучение характеристики ЭВМ, определяющих их как объект обработки информации в системах управления.
Содержание лекции: основные характеристики ЭВМ. Персональные компьютеры и рабочие станции. Увеличение производительности ЭВМ, за счет чего? Параллельные системы. Закон Амдала и его следствия.
5.1 Основные характеристики ЭВМ
К современным компьютерам и вычислительным системам предъявляются следующие требования:
- отношение стоимость/производительность;
- надежность и отказоустойчивость;
- совместимость и мобильность программного обеспечения.
Отношение стоимость/производительность.
Начнем с очевидного. Суперкомпьютеры – приоритет производительность, стоимостные характеристики на втором плане. Персональные компьютеры – на первом месте стоимостные характеристики, производительность на втором плане.
Между этими двумя крайними направлениями находятся конструкции, основанные на отношении стоимость/ производительность, в которых разработчики находят баланс между стоимостными параметрами и производительностью. Типичными примерами такого рода компьютеров являются миникомпьютеры и рабочие станции.
Производительность.
Зачастую производительность вычислительной машины подменяют термином быстродействие и при этом считают, что производительность это – среднестатистическое число операций (кроме операций ввода/вывода), выполняемых машиной в единицу времени.
В качестве единиц измерения используются:
- MIPS (Million Instruction Per Second) – миллион целочисленных операций в секунду;
- MFLOPS (Million Floating Operations Per Second) – миллион операций над числами с плавающей запятой в секунду, ну и конечно их производные T, G,…
Системная производительность измеряется с помощью синтезированных тестовых программ. Результаты оценки ЭВМ конкретной архитектуры приводятся относительно базового образца.
Важнейшей характеристикой вычислительных систем является надежность. Повышение надежности основано на принципе предотвращения неисправностей путем снижения интенсивности отказов и сбоев за счет применения электронных схем и компонентов с высокой и сверхвысокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечение тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры.
Отказоустойчивость - это такое свойство вычислительной системы, которое обеспечивает ей, как логической машине, возможность продолжения действий, заданных программой, после возникновения неисправностей. Введение отказоустойчивости требует избыточного аппаратного и программного обеспечения.
Масштабируемость представляет собой принципиальную возможность бесконфликтного изменения конфигурации компьютера в процессе эксплуатации, адаптируя его к конкретным условиям эксплуатации. Масштабируемость должна обеспечиваться архитектурой и конструкцией компьютера, а также соответствующими средствами программного обеспечения.
Совместимость
Совместимость проявляется на аппаратном и программном уровнях. Аппаратная совместимость дает возможность комплектовать аппаратуру разных производителей, что предполагает унификацию разъемов, электрических параметров и логики сигналов различных устройств. Программная совместимость обеспечивает работоспособность программы, написанной для одного компьютера, на другом без какой либо перекомпиляции и редактирования.
5.2 Персональные компьютеры и рабочие станции
Персональные компьютеры (ПК) появились в результате эволюции миникомпьютеров при переходе элементной базы машин с малой и средней степенью интеграции на большие и сверхбольшие интегральные схемы. ПК, благодаря своей низкой стоимости, очень быстро завоевали хорошие позиции на компьютерном рынке и создали предпосылки для разработки новых программных средств, ориентированных на конечного пользователя.
Сетевой компьютер (Net Computer) появился как компонент приложения клиент-сервер, имеющий минимальную конфигурацию ПО и предназначенный для работы в сети. Впервые об этом заявили в 1996 году Oracle, Sun Micro systems, IBM в совместном документе «Network Computer Reference Profile», в котором сформулировали основные черты NC – обработка информации, хранящейся на сервере; принцип бездисковых рабочих станций; должны поддерживать все сетевые протоколы IP, TCP, UDP …. – как можно дешевле и вообще не надо памяти.
Рабочая станция. Миникомпьютеры стали прародителями и другого направления развития современных систем – 64 -разрядных машин. Создание RISC-процессоров и микросхем памяти емкостью более 1 Мбайт привело к окончательному оформлению настольных систем высокой производительности, которые сегодня известны как рабочие станции.
X-терминалы.
X-терминалы представляют собой комбинацию бездисковых рабочих станций и стандартных ASCII-терминалов. Совсем недавно, как только стали доступными очень мощные графические рабочие станции, появилась тенденция применения "подчиненных" X-терминалов, которые используют рабочую станцию в качестве локального сервера.
На компьютерном рынке X-терминалы занимают промежуточное положение между персональными компьютерами и рабочими станциями. Как правило, стоимость X-терминалов составляет около половины стоимости сравнимой по конфигурации бездисковой машины и примерно четверть стоимости полностью оснащенной рабочей станции.
Серверы.
Существует несколько типов серверов, ориентированных на разные применения: файл-сервер, сервер базы данных, принт-сервер, вычислительный сервер, сервер приложений. Таким образом, тип сервера определяется видом ресурса, которым он владеет (файловая система, база данных, принтеры, процессоры или прикладные пакеты программ).
Файловые серверы небольших рабочих групп (не более 20-30 человек) проще всего реализуются на платформе персональных компьютеров и программном обеспечении Novell NetWare. Файл-сервер, в данном случае, выполняет роль центрального хранилища данных.
На базе многопроцессорных UNIX-серверов обычно строятся также серверы баз данных крупных информационных систем, так как на них ложится основная нагрузка по обработке информационных запросов. Подобного рода серверы получили название супер-серверов.
Современные супер-серверы характеризуются:
- наличием двух или более центральных процессоров RISC, либо CISC;
- многоуровневой шинной архитектурой, в которой запатентованная высокоскоростная системная шина связывает между собой несколько процессоров и оперативную память, а также множество стандартных шин ввода/вывода, размещенных в том же корпусе;
- поддержкой технологии дисковых массивов RAID;
- поддержкой режима симметричной многопроцессорной обработки, которая позволяет распределять задания по нескольким центральным процессорам или режима асимметричной многопроцессорной обработки, которая допускает выделение процессоров для выполнения конкретных задач.
Мейнфреймы.
Мейнфрейм - это синоним понятия "большая универсальная ЭВМ". Мейнфреймы и до сегодняшнего дня остаются наиболее мощными (не считая суперкомпьютеров) вычислительными системами общего назначения, обеспечивающими непрерывный круглосуточный режим эксплуатации.
В архитектурном плане мейнфреймы представляют собой многопроцессорные системы, содержащие один или несколько центральных и периферийных процессоров с общей памятью, связанных между собой высокоскоростными магистралями передачи данных. При этом основная вычислительная нагрузка ложится на центральные процессоры, а периферийные процессоры (в терминологии IBM - селекторные, блок-мультиплексные, мультиплексные каналы и процессоры телеобработки) обеспечивают работу с широкой номенклатурой периферийных устройств.
Суперкомпьютеры. Что такое суперЭВМ? Оксфордский толковый словарь по вычислительной технике, изданный в 1986 году, сообщает, что суперкомпьютер это очень мощная ЭВМ с производительностью свыше 10 MFLOPS (10 миллионов операций с плавающей запятой в секунду). Сегодня это средненький результат даже для ПК. Планки производительности в 10 TFLOPS были успешно перекрыты довольно давно. Суперкомпьютер ASCI WHITE, занимающий первое место в списке пятисот самых мощных компьютеров мира, объединяет 8192 процессора Power 3 с общей оперативной памятью в 4 Терабайта и производительностью более 12 триллионов операций в секунду, а суперкомпьютер IBMBlueGene/L достиг на тесте Linpack производительности в 153, 3 TFLOPS.
5.3 Увеличение производительности ЭВМ, за счет чего?
А почему суперкомпьютеры считают так быстро? Вариантов ответа может быть несколько, среди которых два имеют явное преимущество: развитие элементной базы и использование новых решений в архитектуре компьютеров. Более чем за полвека производительность компьютеров выросла почти в 800миллионов раз. При этом выигрыш в быстродействии, связанный с уменьшением времени такта с 2 микросекунд до 1.8 наносекунд, составляет лишь около 1000 раз. Откуда же взялось остальное? Ответ очевиден - использование новых решений в архитектуре компьютеров. Основное место среди них занимает принцип параллельной обработки команд и данных, воплощающий идею одновременного (параллельного) выполнения нескольких действий.
5.4 Параллельные системы
Итак, пути повышения производительности ВС заложены в ее архитектуре. С одной стороны это совокупность процессоров, блоков памяти, устройств ввода/вывода ну и конечно способов их соединения, т.е. коммуникационной среды. С другой стороны, это собственно действия ВС по решению некоторой задачи, а это операции над командами и данными. Вот собственно и вся основная база для проведения параллельной обработки. Параллельная обработка, воплощая идею одновременного выполнения нескольких действий, имеет несколько разновидностей: суперскалярность, конвейеризация, SIMD – расширения, HyperThreading, многоядерность.
Конвейерная обработка. Что необходимо для сложения двух вещественных чисел, представленных в форме с плавающей запятой? Целое множество мелких операций таких, как сравнение порядков, выравнивание порядков, сложение мантисс, нормализация и т.п. Процессоры первых компьютеров выполняли все эти "микрооперации" для каждой пары аргументов последовательно одна за одной до тех пор, пока не доходили до окончательного результата, и лишь после этого переходили к обработке следующей пары слагаемых. Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передавал бы результат следующему, одновременно принимая новую порцию входных данных. Получаем очевидный выигрыш в скорости обработки за счет совмещения прежде разнесенных во времени операций.
Суперскалярность. Как и в предыдущем примере, только при построении конвейера используют несколько программно-аппаратных реализаций функциональных устройств, например два или три АЛУ, три или четыре устройства выборки.
HyperThreading. Перспективное направление развитие современных микропроцессоров, основанное на многонитевой архитектуре. Основное препятствие на пути повышения производительности за счет увеличения функциональных устройств – это организация эффективной загрузки этих устройств.Если сегодняшние программные коды не в состоянии загрузить работой все функциональные устройства, то можно разрешить процессору выполнять более чем одну задачу (нить), чтобы дополнительные нити загрузили – таки все ФИУ (очень похоже на многозадачность).
Многоядерность. Можно, конечно, реализовать мультипроцессирование на уровне микросхем, т.е. разместить на одном кристалле несколько процессоров (Power 4). Но если взять микропроцессор вместе с памятью как ядра системы, то несколько таких ядер на одном кристалле создадут многоядерную структуру.
По каким же направлениям идет реализация высокопроизводительной вычислительной техники в настоящее время? Основных направлений четыре:
1) Векторно-конвейерные компьютеры. Конвейерные функциональные устройства и набор векторных команд - это две особенности таких машин. В отличие от традиционного подхода, векторные команды оперируют целыми массивами независимых данных, что позволяет эффективно загружать доступные конвейеры, т.е. команда вида A=B+C может означать сложение двух массивов, а не двух чисел.
2) Массивно-параллельные компьютеры с распределенной памятью. Идея построения компьютеров этого класса тривиальна: возьмем серийные микропроцессоры, снабдим каждый своей локальной памятью, соединим посредством некоторой коммуникационной среды - вот и все.
3) Параллельные компьютеры с общей памятью. Вся оперативная память таких компьютеров разделяется несколькими одинаковыми процессорами. Это снимает проблемы предыдущего класса, но добавляет новые - число процессоров, имеющих доступ к общей памяти, по техническим причинам нельзя сделать большим. В данное направление входят многие современные многопроцессорные SMP-компьютеры или, например, отдельные узлы компьютеров HP Exemplar и Sun StarFire.
4) Кластерные системы. Последнее направление, строго говоря, не является самостоятельным, а скорее представляет собой комбинации предыдущих трех. Из нескольких процессоров (традиционных или векторно-конвейерных) и общей для них памяти сформируем вычислительный узел. Если полученной вычислительной мощности не достаточно, то объединим несколько узлов высокоскоростными каналами.
5.5 Закон Амдала и его следствия
Предположим, что в вашей программе
доля операций, которые нужно выполнять последовательно, равна f, где
0<=f<=1 (при этом доля понимается не по статическому числу строк кода, а
по числу операций в процессе выполнения). Крайние случаи в значениях f
соответствуют полностью параллельным (f=0) и полностью последовательным (f=1)
программам. Так вот, для того, чтобы оценить, какое ускорение S может быть
получено на компьютере из 'p' процессоров при данном значении f, можно
воспользоваться законом Амдала: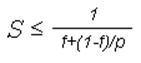 .
.
Если 9/10 программы исполняется параллельно, а 1/10 по-прежнему последовательно, то ускорения более, чем в 10 раз получить в принципе невозможно вне зависимости от качества реализации параллельной части кода и числа используемых процессоров.
6 Лекция №6. Структурная организация ЭВМ – процессор
Цель лекции: изучение принципов построения современных устройств обработки цифровой информации – процессоров, их структурной и функциональной реализации.
Содержание лекции: микропроцессорная система. Устройство управления. Интерфейсная часть МП. Архитектура системы команд и классификация процессоров.
Микропроцессорная система может рассматриваться как частный случай электронной системы, предназначенной для обработки входных сигналов и выдачи выходных сигналов (см.рисунок 6.1). В качестве входных и выходных сигналов при этом могут использоваться аналоговые сигналы, одиночные цифровые сигналы, цифровые коды, последовательности цифровых кодов.

Рисунок 6.1 - Электронная система
Любая система на "жесткой логике" обязательно представляет собой специализированную систему, настроенную исключительно на одну задачу или (реже) на несколько близких, заранее известных задач. Это имеет свои бесспорные преимущества. А именно логические элементы всегда обладают максимальным на данный момент быстродействием. Но в то же время большим недостатком цифровой системы на "жесткой логике" является то, что для каждой новой задачи ее надо проектировать и изготавливать заново.
Путь преодоления этого недостатка довольно очевиден: надо построить такую систему, которая могла бы легко адаптироваться под любую задачу, перестраиваться с одного алгоритма работы на другой без изменения аппаратуры. И задавать тот или иной алгоритм мы тогда могли бы путем ввода в систему некой дополнительной управляющей информации, программы работы системы (см.рисунок 6.2). Тогда система станет универсальной, или программируемой, не жесткой, а гибкой. Именно это и обеспечивает микропроцессорная система.
Таким образом, можно сделать следующий вывод. Системы на "жесткой логике" хороши там, где решаемая задача не меняется длительное время, где требуется самое высокое быстродействие, где алгоритмы обработки информации предельно просты. А универсальные, программируемые системы хороши там, где часто меняются решаемые задачи, где высокое быстродействие не слишком важно, где алгоритмы обработки информации сложные.
Ядром любой микропроцессорной системы является микропроцессор или просто процессор (от английского processor). Перевести на русский язык это слово правильнее всего как "обработчик", так как именно микропроцессор— это тот узел, блок, который производит всю обработку информации внутри микропроцессорной системы. Остальные узлы выполняют всего лишь вспомогательные функции: хранение информации (в том числе и управляющей информации, то есть программы), связи с внешними устройствами, связи с пользователем и т.д.
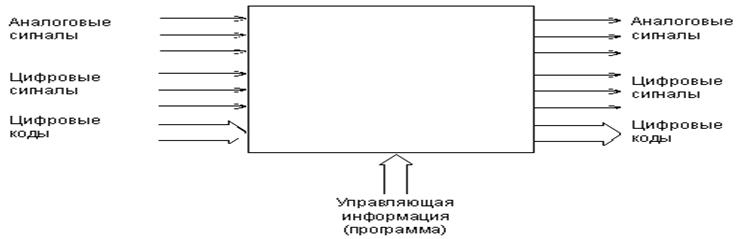
Рисунок 6.2 - Программируемая (она же
универсальная)
электронная система.
 Итак, микропроцессор способен выполнять множество операций. Но
откуда он узнает, какую операцию ему надо выполнять в данный момент? Именно это
определяется управляющей информацией, программой. Программа представляет собой
набор команд (инструкций), то есть цифровых кодов, расшифровав которые,
процессор узнает, что ему надо делать. Все команды, выполняемые процессором,
образуют систему команд процессора. Процессор представляет собой довольно
сложное цифровое устройство (см.рисунок 6.3).
Итак, микропроцессор способен выполнять множество операций. Но
откуда он узнает, какую операцию ему надо выполнять в данный момент? Именно это
определяется управляющей информацией, программой. Программа представляет собой
набор команд (инструкций), то есть цифровых кодов, расшифровав которые,
процессор узнает, что ему надо делать. Все команды, выполняемые процессором,
образуют систему команд процессора. Процессор представляет собой довольно
сложное цифровое устройство (см.рисунок 6.3).
Внутрисистемный интерфейс
Рисунок 6.3 - Пример структуры простейшего процессора
Часть цифрового вычислительного устройства, предназначенная для выработки последовательно управляющих сигналов, называется устройством управления.
Любое действие, выполняемое в операционном блоке, описывается некоторой микропрограммой и реализуется за один или несколько тактов. Элементарная функциональная операция, выполняемая за один тактовый интервал и приводимая в действие управляющим сигналом, называется микрооперацией. Совокупность микроопераций, выполняемых в одном такте, называется микрокомандой (МК). Если все такты должны иметь одну и ту же длину, а именно это имеет место при работе компьютера, то она устанавливается по самой продолжительной микрооперации. микрокоманды, предназначенные для выполнения некоторой функционально законченной последовательности действий, образуют микропрограмму. Например, микропрограмму образует набор микрокоманд для выполнения команды умножения. Устройство управления предназначено для выработки управляющих сигналов, под воздействием которых происходит преобразование информации в арифметико-логическом устройстве, а также операции по записи и чтению информации в/из запоминающего устройства.
Устройства управления делятся на:
- УУ с жесткой, или схемной логикой;
- УУ с программируемой логикой (микропрограммные УУ).
Микропрограммное устройство управления представлено на рисунке 6.4. Преобразователь адреса микрокоманды преобразует код операции команды, присутствующей в данный момент в регистре команд, в начальный адрес микропрограммы, реализующей данную операцию, а также определяет адрес следующей микрокоманды выполняемой микропрограммы по значению адресной части текущей микрокоманды.
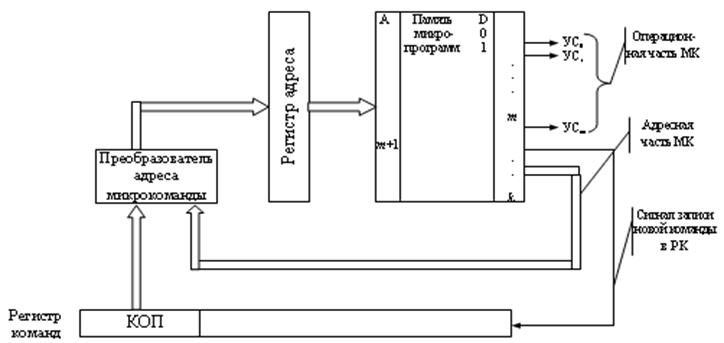
Рисунок
6.4 - Функциональная схема микропрограммного
устройства управления
Устройство управления содержит дешифратор операций - логический блок, выбирающий в соответствии с поступающим из регистра команд кодом операции (КОП) один из множества имеющихся у него выходов.
Постоянное запоминающее устройство микропрограмм - хранит в своих ячейках коды об управляющих сигналах (импульсах), необходимые для выполнения в блоках ПК операций обработки информации. Эти коды, по выбранному дешифратором операций в соответствии с кодом операции команды, считывает из ПЗУ микропрограмм необходимую последовательность управляющих сигналов.
Узел формирования адреса (находится в интерфейсной части МП) - устройство, вычисляющее полный адрес ячейки памяти (регистра) по реквизитам, поступающим из регистра команд и регистров микропроцессорной памяти.
Кодовые шины данных, адреса и инструкций - часть внутренней шины микропроцессора.
Интерфейсная часть включает в свой состав адресные регистры, узел формирования адреса, блок регистров команд, являющийся буфером команд в МП, внутреннюю интерфейсную шину МП и схемы управления шиной и портами ввода-вывода. Порты ввода-вывода - это пункты системного интерфейса компьютера, через которые МП обменивается информацией с другими устройствами. Всего портов у МП может быть 65536. Каждый порт имеет адрес - номер порта, хранящийся в соответствующей ячейке памяти. Порт любого устройства содержит аппаратуру сопряжения и два регистра памяти - для обмена данными и обмена управляющей информацией.
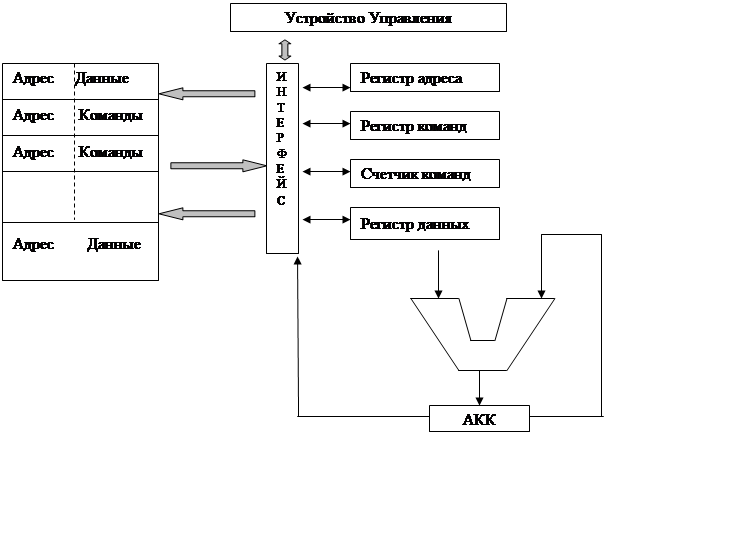
Тракт данных типичного процессора.
Тракт данных типичного фон-неймановского процессора состоит из регистров (обычно от 8 до 32), АЛУ и нескольких коммуникационных шин. Структура тракта, особенности архитектуры процессора зависят от структуры системы команд.
Такая последовательность шагов: выборка – декодирование – исполнение является основой работы всех компьютеров.
 ОП
ОП
Шина адреса
Шина чтения
Шина записи
АЛУ
Рисунок 6.5 - Структура «память-регистр»
 |
Регистровый файл
Входные регистры
АЛУ
АЛУ
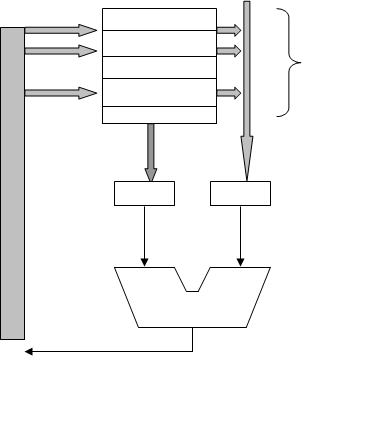
Рисунок 6.6 - Структура «регистр-регистр»
Итак, именно эволюция ЭВМ с интерпретатором (позже названных машинами с CISC процессорами) сформировала тенденцию использования:
- сложных, длинных команд;
- разнообразных форматов данных;
- разнообразных форматов команд.
Для CISC процессоров характерно:
- небольшое число РОН (до 16);
- большое количество машинных команд (свыше 200).
Для RISC процессоров характерно:
- все обычные команды непосредственно выполняются аппаратным обеспечением, они не интерпретируются микрокомандами;
- в повышении производительности главную роль играет параллелизм, одновременное выполнение большого числа команд и одновременная обработка большого количества данных.
Лекция №7. Структурная организация ЭВМ – память
Цель лекции: изучение системы памяти ЭВМ, способов увеличения представления данных для обработки, а также структурной и функциональной реализации памяти.
Содержание лекции: общие сведения памяти ЭВМ. Иерархия памяти компьютера. Оперативная память, типы ОП. Кэш-память.
7.1 Общие сведения памяти ЭВМ
Память ЭВМ - это совокупность всех запоминающих устройств, входящих в состав машины. Запоминающие устройства классифицируют по следующим признакам:
- по типу (полупроводниковые, магнитные, конденсаторные, оптоэлектронные, голографические, криогенные и т.д.);
- по функциональному назначению (ОЗУ, буферные - БЗУ, сверхоперативные – СОЗУ, внешние – ВЗУ, постоянные – ПЗУ, и т.д.);
- по способу организации обращения (с последовательным поиском, с прямым доступом, адресные, стековые, страничные, ассоциативные и т.д.);
- по характеру считывания (с разрушением или без);
- по способу хранения (статические или динамические);
- этим классификация не исчерпывается, но мы рассмотрим только основные типы.
Важнейшие характеристики – емкость, удельная емкость (плотность записи), быстродействие (продолжительность операции быстродействия, т.е. время затрачиваемое на поиск единицы информации), пропускная способность (количество данных, предаваемых в секунду).
 |
Все компьютеры используют четыре вида памяти: оперативную, постоянную, регистровую и внешнюю.
Оперативная память или память с произвольным доступом - Random Access Memory или ОЗУ предназначена для хранения информации, к которой приходится часто обращаться, и обеспечивает режимы ее записи, считывания и хранения. ОЗУ обладает адресным пространством, разделенным на несколько областей. Некоторые из них используются самой системой, другие предназначены для специальных целей.
 |
Верхняя граница определяется всем адресным пространством процессора
1 Мбайт
640 Кбайт
Распределение адресного пространства памяти (Intel – совместимые).
Для оценки производительности основной памяти используются два основных параметра: задержка и полоса пропускания. Задержка памяти традиционно оценивается двумя параметрами: временем доступа (access time) и длительностью цикла (cycle time). Время доступа – промежуток времени между запросом на чтение и выдачей запрошенного слова из памяти. Длительность цикла – определяется минимальным временем между двумя последовательными обращениями к памяти.
7.2 Иерархия памяти компьютера
Память ЭВМ представляет собой иерархию запоминающих устройств (ЗУ), отличающихся средним временем доступа к данным, объемом и стоимостью хранения одного бита.
Объем доступа Время Цена $/байт

Десятки байт ~ 0,01-1 нс 0.1-10
Сотни Кбайт - ~0,5-2 нс 0,1-0,5
Мбайт
Тысячи ~2-20 нс 0,01-0,1
Мегабайт
Сотни Десятки
Гигабайт мкс 0,001-0,01
Рисунок 7.1 - Иерархия ЗУ
Успешное или неуспешное обращение к более высокому уровню называются соответственно попаданием (hit) или промахом (miss). Попадание - есть обращение к объекту в памяти, который найден на более высоком уровне, в то время как промах означает, что он не найден на этом уровне. Доля попаданий (hit rate) или (hit ratio) есть доля обращений, найденных на более высоком уровне.
Таблица 7.1
|
Размер строки - line |
4-128 байт |
|
Hit time |
1-4 такта |
|
Miss Penalty |
8-32 такта |
|
Access time |
6-10 тактов |
|
Transfer time |
2-22 такта |
|
Miss rate |
1-2 % |
7.3 Оперативная память, типы ОП
В настоящее время наиболее распространены микросхемы памяти двух типов: статические ОЗУ – SRAM и динамические – DRAM. Разумеется, более быстрая память дороже стоит, поэтому SRAM используется, как правило, для кэш памяти, в регистрах микропроцессора и системах управления.
Динамическое ОЗУ со времени своего появления прошло несколько стадий роста и продолжает совершенствоваться. Вначале микросхемы динамического ОЗУ производились в DIP-корпусах. Затем их сменили модули SIPP, DIMM, SIMM и RIMM.
Первыми SIMM-модулями были 30-пиновые SIMM FPM DRAM, с частотой работы 29 МГц, затем 72-пиновые EDO RAM с частотой 50 МГц. DIMM (Dual Inline Memory Module) – модуль памяти с двойным расположением 168 выводов. Следует отметить, что разъем DIMM имеют много разновидностей DRAM.
SDRAM (Synchronic DRAM) – динамическое ОЗУ с синхронным интерфейсом, работающие на частотах 143 МГц и выше. ESDRAM – динамические ОЗУ с синхронным интерфейсом, с кэшом на самом модуле, работающие на частотах 200 МГц и выше. SLDRAM – имеет в своем составе SRAM, работает на частоте до 400 МГц. RDRAM, RIMM
7.4 Кэш-память
Одним из самых важных вопросов компьютерной техники был и остается вопрос построение такой системы памяти, которая могла бы передавать операнды процессору с той же скоростью, с которой он может их обрабатывать. Одним из способов решения этой проблемы – это технология сочетания маленькой и быстрой памяти с большой, но медленной или технология кэш-памяти.
Принцип действия кэш-памяти.
Основная память и кэш-память делятся на блоки фиксированного размера с учетом принципа локальности. Блоки внутри кэша называют строками кэш-памяти (cacheline). Если обращение к кэш-памяти нерезультативно, из основной памяти в кэш загружается вся строка, а не только необходимое слово. Возможно, через некоторое время понадобятся другие слова из этой строки.
Медленный ответ (кэш-промах)
 |
Запрос
Быстрый ответ
(кэш-попадание)
Рисунок 7.2 - Кэш-память и связь с процессором
№ блока строки кэш-памяти (байты данных)
|
![]() 254
254
![]() 2
2
1
![]() 0
0
Рисунок 7.3 - Структура ОП
В любой момент времени несколько строк находятся в кэш-памяти. Когда происходит обращение к памяти, контроллер кэша проверяет, есть ли нужное слово в данный момент в кэш-памяти, если нет тогда происходит загрузка необходимой строки из ОП. Существует множество вариаций данной схемы, различающихся временем доступа, производительностью и т.д.
Далее возможны два варианта:
- если данные обнаруживаются в кэше, т.е. произошло кэш-попадание (cache-hit), они считываются из нее и результат передается источнику запроса;
- если нужные данные отсутствуют в кэш-памяти, т.е. произошел кэш-промах (cache-miss), они считываются из основной памяти и одновременно копируются из ОП в кэш.
Способы организации кэш-памяти.
Чтобы описать некоторый уровень иерархии памяти надо ответить на следующие четыре вопроса:
1) Где может размещаться блок на верхнем уровне иерархии (размещение блока)?
2) Как найти блок, когда он находится на верхнем уровне? (идентификация блока) ?
3) Какой блок должен быть замещен в случае промаха? (замещение блоков) ?
4) Что происходит во время записи (стратегия записи)?
Рассмотрим организацию кэш-памяти в общем случае, отвечая на четыре вопроса об иерархии памяти:
1) Где может размещаться блок в кэш-памяти?
Принципы размещения блоков в кэш-памяти определяют три основных типа их организации:
1) Если каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти, то такая кэш-память называется кэшем с прямым отображением (direct mapped). Если некоторый блок основной памяти может располагаться на любом месте кэш-памяти, то кэш называется полностью ассоциативным (fully associative). Когда процессор запрашивает данные из ОП, начинается поиск во всех ячейках кэша. Если некоторый блок основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется множественно-ассоциативным (set associative).
2) Как найти блок, находящийся в кэш-памяти?
У каждого блока в кэш-памяти имеется адресный тег, указывающий, какой блок в основной памяти данный блок кэш-памяти представляет. Эти теги обычно одновременно сравниваются с выработанным процессором адресом блока памяти.
3) Какой блок кэш-памяти должен быть замещен при промахе?
При возникновении промаха, контроллер кэш-памяти должен выбрать подлежащий замещению блок. Польза от использования организации с прямым отображением заключается в том, что аппаратные решения здесь наиболее простые. Выбирать просто нечего: на попадание проверяется только один блок и только этот блок может быть замещен.
4) Что происходит во время записи?
При обращениях к кэш-памяти на реальных программах преобладают обращения по чтению. Все обращения за командами являются обращениями по чтению и большинство команд не пишут в память. Обычно операции записи составляют менее 10% общего трафика памяти.
8 Лекция №8. Логическая организация памяти
Цель лекции: изучение памяти ВМ, способов увеличения представления данных для обработки, а также структурной и функциональной реализации памяти.
Содержание лекции: виртуальная память. Страничная организация памяти. Страничная организация памяти. Сегментная организация памяти.
Есть несколько способов, позволяющих согласовать разные объемы памяти, разные способы ее организации в представлении программистов и реально аппаратно существующей.
Традиционным решением было использование вспомогательной памяти и разделения программы на несколько частей, так называемых оверлеев, каждый из которых перемещался по мере надобности между основной и вспомогательной памятью. В дальнейшем этот метод развился в страничную организацию памяти, когда память разбивалась на блоки фиксированного объема – страницы. Именно они образовывали единое линейное пространство адресов и перемещались с диска на основную память. Однако и этот метод не вполне удовлетворил потребности программистов и эволюционировал в сегментную организацию памяти. Сегмент – область памяти определенного назначения, внутри которой поддерживается линейная адресация. Развитие методов организации вычислительного процесса в этом направлении привело к появлению метода, известного под названием – виртуальная память, о чем мы будем говорить более подробно ниже.
Таким образом, виртуальная память - это совокупность программно-аппаратных средств, позволяющих пользователям писать программы, размер которых превосходит имеющуюся оперативную память; для этого виртуальная память решает следующие задачи:
- размещает данные в запоминающих устройствах разного типа, например, часть программы в оперативной памяти, а часть на диске;
- перемещает по мере необходимости данные между запоминающими устройствами разного типа, например, подгружает нужную часть программы с диска в оперативную память;
- преобразует виртуальные адреса в физические.
Наиболее распространенными реализациями виртуальной памяти является страничное, сегментное и страничное - сегментное распределение памяти, а также свопинг.
 |
Виртуальный адрес
Данные
(или команды)
Физический адрес
Физический адрес
Данные Пересылка с применением ПДП
(или команды)
Рисунок 8.1 - Организация виртуальной памяти
8.2 Страничная организация памяти
Пусть наш компьютер имеет 16-битное поле адреса и всего лишь 4096 слов оперативной памяти (PDP-1). Программа, работающая на нем, могла бы обращаться к 65536 словам (216=65536), но такого количества слов просто нет. До изобретения виртуальной памяти все адреса, которые были равны или больше адреса 4096 считались бесполезными, не существующими.
Адресное пространство
 |
Адрес
Основная память – 16 К
8191 Отображение
4096 4095
0 0
4 К основной памяти
Рисунок 8.2 - Виртуальные адреса памяти с 4096 по 8191 отображаются в адресах основной памяти с 0 по 4095
В машине с виртуальной памятью будет иметь следующая последовательность действий:
1) Слова с 4096 до 8191 будут выгружены на диск.
2) Слова с 8102 до 12287 будут загружены с диска в основную память.
3) Отображение адресов изменится: теперь адреса с 8192 до 12287 соответствуют ячейкам памяти с 0 по 4095.
4) Выполнение программы продолжится.
Если теперь добавить в основную память еще три блока по 4 К, то мы сможем отобразить полностью 64 К адресного пространства на всего лишь 4К физической памяти. Такая технология автоматического наложения называется страничной организацией памяти, а куски программы. Необходимо подчеркнуть, что страничная организация памяти создает иллюзию большой линейной основной памяти такого же размера, как адресное пространство. Программист может писать программы и при этом ничего не знать о существовании страничной организации памяти, которые считываются с диска, называются страницами.
Страничное управление памятью – это общепринятый механизм организации виртуальной памяти с подкачкой страниц по запросу.
Виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами. Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами (или блоками). Размер страницы обычно выбирается равным степени двойки: 512, 1024 и т.д., это позволяет упростить механизм преобразования адресов. При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные - на диск. При загрузке операционная система создает для каждого процесса информационную структуру - таблицу страниц, в которой устанавливается соответствие между номерами виртуальных и физических страниц для страниц, загруженных в оперативную память, или делается отметка о том, что виртуальная страница выгружена на диск.
8.4 Сегментная организация памяти
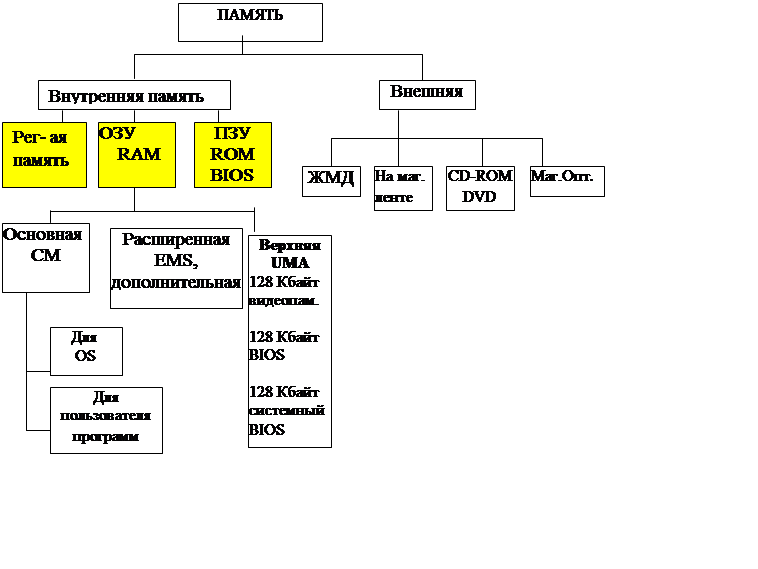
Память может логически организовываться в виде одного или множества блоков, сегментов произвольной длины (в реальном режиме фиксированной). Мы уже говорили, что в защищенном режиме возможно разбиение логической памяти на страницы размером 4 Кбайт (до 5 Мбайт в современных процессорах), каждая из которых может отображаться на любую область физической памяти. Сегментация и страничная трансляция адресов могут применяться совместно и по отдельности. Сегментация является средством организации логической памяти на прикладном уровне, а страничная трансляция адресов на системном уровне.
Для хранения кодов адресов памяти используются не отдельные регистры, а пары регистров:
- сегментный регистр определяет адрес начала сегмента (база сегмента), то есть положение сегмента в памяти;
- регистр указателя (регистр смещения) определяет положение рабочего адреса внутри сегмента.
Базовый регистр Сгенерированный процессором
таблицы страниц виртуальный адрес
 |
Таблицы страниц
Начальный Страничный блок
адрес
Адрес нужного
элемента таблицы
Управляющие биты
Физический адрес в основной памяти
Рисунок 8.3 - Страничное распределение памяти
 ПАМЯТЬ
ПАМЯТЬ
FFFFFH
16 битное расстояние
от базы – смещение
15 0 64 Кбайт
Адрес сегмента
16 байт 1 Мбайт
15 0 00000H
Рисунок 8.4 - Сегментная память процессора 8086
Цель лекции: изучение системы памяти ВМ методами адресации, а также структурной и функциональной организации памяти.
Содержание лекции: общие сведения о методах адресации. Прямая или абсолютная адресация. Непосредственная адресация. Косвенная (базовая) адресация. Регистровая адресация.
9.2 Общие сведения о методах адресации
Пространство памяти предназначено для хранения кодов команд и данных, для доступа к которым имеется богатый выбор методов адресации (около 24). Операнды могут находиться во внутренних регистрах процессора (наиболее удобный и быстрый вариант). Они могут располагаться в системной памяти (самый распространенный вариант). Наконец, они могут находиться в устройствах ввода/вывода (наиболее редкий случай). Определение места положения операндов производится кодом команды. Причем существуют разные методы, с помощью которых код команды может определить, откуда брать входной операнд и куда помещать выходной операнд. Эти методы называются методами адресации. Эффективность выбранных методов адресации во многом определяет эффективность работы всего процессора в целом.
9.2 Прямая или абсолютная адресация
Физический адрес операнда содержится в адресной части команды. Формальное обозначение:
Операндi = (Аi),
где Аi – код, содержащийся в i-м адресном поле команды.
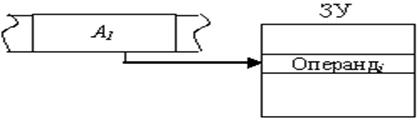
Рисунок 9.1 - Прямая адресация
Пример: moval,[2000] – передать операнд, который содержится по адресу 2000h в регистр AL.
AddR1,[1000] – сложить содержимое регистра R1 с содержимым ячейки памяти по адресу 1000h и результат переслать в R1.
Допускается использование прямой адресации при обращении, как к основной, так и к регистровой памяти.
9.3 Непосредственная адресация
В команде содержится не адрес операнда, а непосредственно сам операнд.
Операндi= Аi.

Рисунок 9.2 - Непосредственная адресация
Непосредственная адресация позволяет повысить скорость выполнения операции, так как в этом случае вся команда, включая операнд, считывается из памяти одновременно и на время выполнения команды хранится в процессоре в специальном регистре команд (РК). Пример: moveax, 0f0f0f0f0 – загрузить константу 0f0f0f0f0h в регистр eax.
9.4 Косвенная (базовая) адресация
Адресная часть команды указывает адрес ячейки памяти (см.рисунок 7.3,а) или номер регистра (см.рисунок 7.3,б), в которых содержится адрес операнда:
Операндi = ((Аi)).
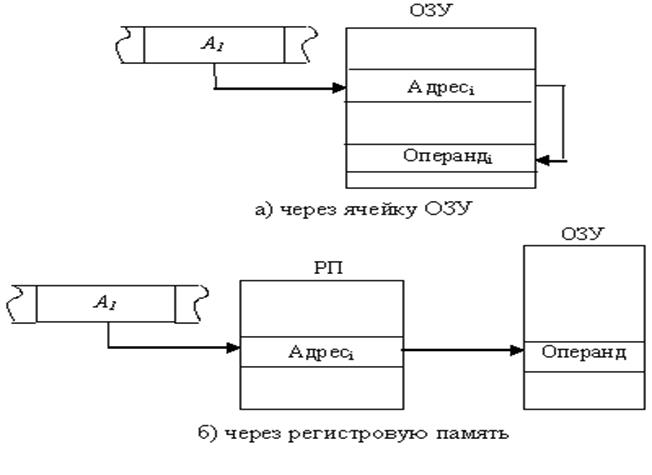
Рисунок 9.3 - Косвенная адресация
Применение косвенной адресации операнда из оперативной памяти при хранении его адреса в регистровой памяти существенно сокращает длину поля адреса, одновременно сохраняя возможность использовать для указания физического адреса полную разрядность регистра. Косвенная адресация не применяется по отношению к операндам, находящимся в регистровой памяти.
Пример: moval,[ecx] – передать в регистр AL операнд (содержимое) ячейки памяти, адрес которой находится в регистре ECX.
Предоставляемые косвенной адресацией возможности могут быть расширены, если в системе команд ЭВМ предусмотреть определенные арифметические и логические операции над ячейкой памяти или регистром, через которые выполняется адресация, например увеличение или уменьшение их значения на единицу (и не только на 1).
В этом случае речь идет о базовой адресации со смещением.
Пример: moveax,[eci+4] – передать в EAX операнд, который содержится по адресу ECI со смещением плюс 4.
Иногда, адресация, при которой после каждого обращения по заданному адресу с использованием механизма косвенной адресация, значение адресной ячейки автоматически увеличивается на длину считываемого операнда, называется автоинкрементной. Адресация с автоматическим уменьшением значения адресной ячейки называется автодекрементной.
9.5 Регистровая адресация
Предполагается, что операнд находится во внутреннем регистре процессора.
Например: moveax,cr0 – передать в EAX содержимое CR0 или
mov ecx,ecx – сбросить регистр ECX.
10 Лекция №10. Внешняя память компьютера
Цель лекции: изучение основных функции системы ввода/вывода, а также структурной и функциональной организации внешней памяти.
Содержание лекции: жесткий диск (Hard Disk Drive). Интерфейсы НМД. Структура хранения информации на жестком диске. Таблица размещения файлов. Кластер. Магнито-оптические диски. Дисковые массивы и уровни RAID. Лазерные компакт-диски CD–ROM.
10.1 Жесткий диск (HardDiskDrive)
Пока этим требованиям в наибольшей степени удовлетворяют так называемые жесткие диски (HDD — HardDiskDrive), хотя не исключено появление в будущем других устройств, обладающих лучшими свойствами. Три основных требования к жесткому диску — это емкость, быстродействие и минимальные габариты (о надежности мы не говорим, поскольку это, само собой, разумеется).
Конструкция жесткого диска.
Дисковый накопитель обычно состоит из набора пластин, представляющих собой металлические диски (сегодня большое распространение получили диски из композитных материалов), покрытые магнитным материалом и соединенные между собой при помощи центрального шпинделя. Над каждой поверхностью располагается считывающая головка. Каждая пластина содержит набор концентрических записываемых дорожек. Обычно дорожки делятся на блоки данных объемом 512 байт, иногда называемые секторами.
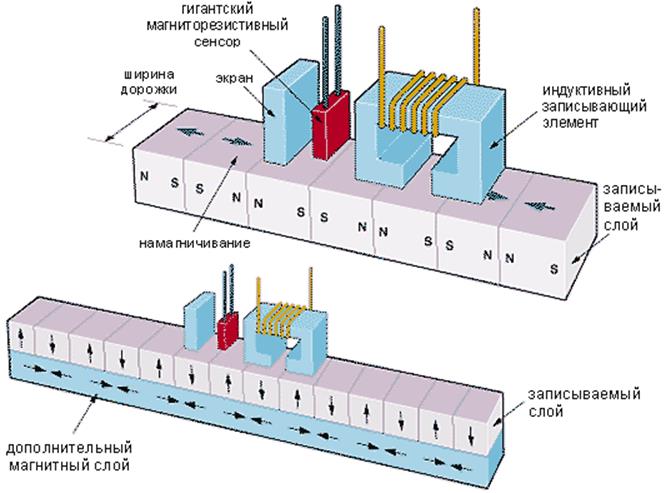
Перед данными располагается заголовок (header), состоящий из преамбулы(preamble), которая позволяет головке синхронизироваться перед чтением или записью данных и служебной адресной информацией. После данных идет код с исправлением ошибок (код Хемминга или код Рида-Соломона). Между соседними секторами находится межсекторный интервал. Так что форматированный сектор составляет уже 571 байт.
В состав компьютеров часто входят специальные устройства, называемые дисковыми контроллерами. К каждому дисковому контроллеру может подключаться несколько дисковых накопителей. Между дисковым контроллером и основной памятью может быть целая иерархия контроллеров и магистралей данных, сложность которой определяется главным образом стоимостью компьютера.
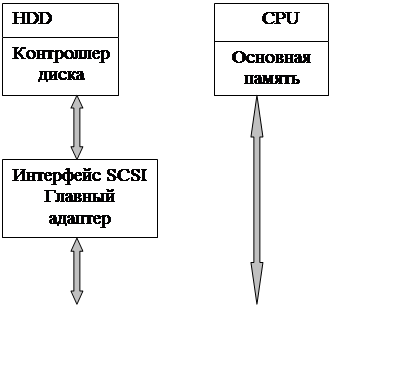
Необходимо отметить, что в последнее время все большее распространение получил интерфейс SCSI. Он не только более производителен, но и поддерживает до 16 устройств, что очень важно для файл-серверов и серверов сети.
 |
 Шина SCSI
Шина SCSI
Рисунок 10.2 - Структура интерфейсов НМД
10.3 Структура хранения информации на жестком диске
Компьютеру важно не просто записать информацию на диск, а так записать, ее, чтобы потом найти, причем быстро и безошибочно. Поэтому на жестком диске создается специальная структура для хранения данных. Операция создания такой структуры называется форматированием диска. После форматирования каждый файл, записанный на диск, может иметь собственный адрес, выраженный в числовой форме.
Несмотря на то, что физически жесткий диск состоит из п дисков и имеет 2п поверхностей, для изучения его структуры нам достаточно рассмотреть только одну поверхность. Эта поверхность разбивается на концентрические дорожки. В зависимости от конструкции диска таких дорожек может быть больше или меньше, и каждая дорожка имеет свой уникальный номер.
Если мы теперь вновь вспомним, что реальный жесткий диск имеет много поверхностей, то у нас появится новый термин — цилиндр. Дорожки с одинаковыми номерами, но принадлежащие разным поверхностям, образуют один цилиндр. Каждый цилиндр имеет номер, совпадающий с номером входящих в него дорожек.
Дорожки, в свою очередь, разбиваются на секторы. Длина каждого сектора равна 512 байтам данных. Таким образом, сектор — наименьший элемент структуры жесткого диска. Для того чтобы записать, а затем затребовать информацию, необходимо задать адрес, состоящий из трех чисел: номера цилиндра, номера поверхности (номера головки) и номера сектора. Этот метод называется CHS (CylinderHeadSector). Современным развитием этого метода является механизм трансляции линейных адресов и линейной адресации LBA (LogicalBlockAdressing), связанный однозначно с CHS.
10.4 Таблица размещения файлов
Файлы в канцелярском понимании — это «дела», с обычными человеческими именами, пылящиеся в таком месте, куда месяцами не ступает нога человека, но установить это место всегда можно по номеру «дела», если заглянуть в амбарную книгу, называемую реестром.
Роль такого «реестра» на жестком диске выполняет специальная таблица, которая называется FAT-таблицейFileAllocationTable (по-русски: таблица размещения файлов). Она находится на служебной дорожке жесткого диска и должна именовать, сохранять и производить поиск данных. Физическое повреждение секторов, в которых записана эта таблица, равносильно краху всей информации, хранящейся на жестком диске, поэтому эта таблица всегда продублирована, и операционная система компьютера бережно следит за тем, чтобы информация в разных экземплярах таблицы строго совпадала. Для ОС W.95/98 это были FAT 16 и FAT 32. В этих случаях размер кластера определялся объемом HDD. Однако FAT 32 поддерживал только 32 Гбайт (W.95) при размере кластера 16 Кбайт. Это заставило разработчиков перейти на NTFS начиная с ОС Windows 2000 (для ПК), хотя эта система успешно работала и с Win. NT. Основными преимуществами NTFS является умение управлять дисками с объемом несколько терабайт, исправлять ошибки после сбоев и защищать систему от несанкционированного доступа.
Хотя острота проблемы с кластеризацией пропала, особенно с внедрением NTFS мы должны понимать откуда она возникла.
Сейчас мы узнаем, откуда эти кластеры берутся. Мы работаем с файлами, имеющими имена, записанные символами (обычными человеческими буквами). Компьютер переводит эти имена в числовые адреса секторов с помощью таблицы размещения файлов. Этим занимается неоднократно упомянутая нами операционная система.
Имея 16 двоичных разрядов, можно задать 65536 разных адресов (216). При такой системе на диск можно записать 65536 различных файлов, и у каждого будет свой уникальный адрес. В те годы, когда размеры жестких дисков не превышали 32 мегабайта, это было очень неплохо. Сегодня средний размер жесткого диска вырос в сто раз, а количество уникальных адресов для записи файлов осталось тем же, каким было. Предельный размер диска, к какому вообще в принципе может адресоваться операционная система, работающая с 16-разрядной FAT-таблицей, сегодня составляет 2 Гбайт. А если мы поделим этот размер на 65536 адресов, то получим, что минимально адресуемое пространство жесткого диска составляет 32 Кбайт. Эта единица и называется кластером.
Поскольку кластер — это минимальное адресуемое дисковое пространство, значит, ни один файл не может занимать меньше места, чем составляет кластер. На больших дисках файл, имеющий размер 1 байт, займет все 32 Кбайт.
Другим направлением развития систем хранения информации являются магнито-оптические диски. Запись на магнито-оптические диски (МО-диски) выполняется при взаимодействии лазера и магнитной головки. Луч лазера разогревает до точки Кюри (температуры потери материалом магнитных свойств) микроскопическую область записывающего слоя, которая при выходе из зоны действия лазера остывает, фиксируя магнитное поле, наведенное магнитной головкой. В результате данные, записанные на диск, не боятся сильных магнитных полей и колебаний температуры.
10.7 Дисковые массивы и уровни RAID
RAID1: Зеркальные диски.
Зеркальные диски представляют традиционный способ повышения надежности магнитных дисков. Это наиболее дорогостоящий из рассматриваемых способов, так как все диски дублируются и при каждой записи информация записывается также и на проверочный диск. ввода/вывода и емкости памяти ради получения более высокой надежности.
RAID 2: матрица с поразрядным расслоением.
Один из путей достижения надежности при снижении потерь емкости памяти может быть подсказан организацией основной памяти, в которой для исправления одиночных и обнаружения двойных ошибок используются избыточные контрольные разряды. Один диск контроля четности позволяет обнаружить одиночную ошибку, но для ее исправления требуется больше дисков.
RAID 3: аппаратное обнаружение ошибок и четность.
Большинство контрольных дисков, используемых в RAID уровня 2, нужны для определения положения неисправного разряда. По существу, если контроллер может определить положение ошибочного разряда, то для восстановления данных требуется лишь один бит четности. Уменьшение числа контрольных дисков до одного на группу снижает избыточность емкости до вполне разумных размеров. Часто количество дисков в группе равно 5 (4 диска данных плюс 1 контрольный).
RAID 4: внутригрупповой параллелизм.
RAID уровня 4 повышает производительность передачи небольших объемов данных за счет параллелизма, давая возможность выполнять более одного обращения по вводу/выводу к группе в единицу времени. Логические блоки передачи в данном случае не распределяются между отдельными дисками, вместо этого каждый индивидуальный блок попадает на отдельный диск.
Главное отличие между системами уровня 3 и 4 состоит в том, что в последних расслоение выполняется на уровне сектора, а не на уровне битов или байтов.
10.8 Лазерные компакт-диски CD – ROM
Для переноса больших объемов данных используют лазерные компакт-диски, получившие обозначение CD-ROM (Compact Disc Read Only Memory). Сегодня диски CD-ROM являются основным типом носителя для распространения программного обеспечения. Если компьютер не имеет дисковода CD-ROM, установка нового программного обеспечения превращается в серьезную проблему.
CD-R
В отличие от CD-ROM могут не только читать диски, но и записывать их. Могут устанавливаться в компьютер вместо CD-ROM. Запись на диски CD-R осуществляется благодаря наличию на нем особо светочувствительного слоя, выгорающего под воздействием высокотемпературного лазерного луча. То есть перед нами нечто похожее на обычную фотографию. Правда, считывает CD-R по нынешним временам не слишком быстро - со скоростью 8-скоростного CD-ROM (8 x 150 = 1200 кб/c = 1,17 Мб/c), но ведь чтение - не главная его функция. Главная - запись. Писать CD-R может в 2-х режимах - односессионном (когда весь диск записывается в один прием) и многосессионном. CD-R - идеален для хранения всевозможных архивов (изображений, звуков, да и просто программ, загромождающих место на вашем жестком диске). Можно сделать копию содержимого всего жесткого диска (на всякий случай). И, конечно же, копировать аудио-, видеодиски и программы.
Новый стандарт перезаписываемых CD-ROM. Внешне диски не отличаются от обычных CD-R, объем - тот же - 640 Мб. Но технология записи CD-R и CD-RW разная.
На дисках CD-RW также имеются поглощающие и отражающие свет участки. Однако это не бугорки или ямки, как в дисководах CD-ROM и CD-R.
DVD.
На смену CD пришли Единые и Универсальные - DVD.
Сначала DVD расшифровывался так - Digital Video Disk - цифровой видеодиск нового поколения. Но позднее консорциум DVD отказался от этой расшифровки. DVD может быть односторонним и двухсторонним, однослойным и многослойным. Но фирмы, входящие в консорциум так до сих пор решение и не приняли. Поэтому пока остановились на односторонних и однослойных.
В дальнейшем появились DVD-RW, работающие с многослойными дисками объемом до и более 10 Гбайт.
Можно было бы продолжить обзор устройств внешней памяти, однако как бы мы не поспешали прогресс в этой области обогнать невозможно. С каждой минутой появляются не только новые устройства, но и совершенно новые принципы хранения информации.
11 Лекция №11. Основные принципы построения систем ввода/вывода
Цель лекции: изучение понятия интерфейса и его характеристики, а также структурной и функциональной организации памяти.
Содержание лекции: физические принципы организации ввода-вывода. Магистрально-модульный способ построения ЭВМ. Опрос устройств и прерывания. Организация передачи данных. Структура шин современного ПК.
11.1 Физические принципы организации ввода-вывода
Существует много разнообразных устройств, которые могут взаимодействовать с процессором и памятью: таймер, жесткие диски, клавиатура, дисплей, мышь, модемы и т. д., вплоть до устройств отображения и ввода информации в авиационно-космических тренажерах.
Интерфейс - это совокупность программных и аппаратных средств, предназначенных для передачи информации между компонентами ЭВМ и включающих в себя электронные схемы, линии, шины и сигналы адресов, данных и управления, алгоритмы передачи сигналов и правила интерпретации сигналов устройствами.
11.2 Магистрально-модульный способпостроения ЭВМ
Главным направлением решения указанных проблем является магистрально-модульный способ построения ЭВМ (см.рисунок 11.1) все устройства, составляющие компьютер, включая и микропроцессор, организуются в виде модулей, которые соединяются между собой общей магистралью. Обмен информацией по магистрали удовлетворяет требованиям некоторого общего интерфейса, установленного для магистрали данного типа. Каждый модуль подключается к магистрали посредством специальных интерфейсных схем (Иi).
Рисунок 11.1 - Магистрально-модульный принцип построения ЭВМ
В простейшем случае процессор, память и многочисленные внешние устройства связаны большим количеством электрических соединений – линий, которые в совокупности принято называть локальной магистралью компьютера. Внутри локальной магистрали линии, служащие для передачи сходных сигналов и предназначенные для выполнения сходных функций, принято группировать в шины. В современных компьютерах выделяют как минимум три шины: шину данных, адресную шину, шину управления.
Количество линий, входящих в состав шины, принято называть разрядностью (шириной) этой шины. Ширина адресной шины, например, определяет максимальный размер оперативной памяти, которая может быть установлена в вычислительной системе. Ширина шины данных определяет максимальный объем информации, которая за один раз может быть получена или передана по этой шине.
Что именно должны делать устройства, приняв информацию через свой порт, и каким именно образом они должны поставлять информацию для чтения из порта, определяется электронными схемами устройств, получившими название контроллеров. Контроллер может непосредственно управлять отдельным устройством (например, контроллер диска), а может управлять несколькими устройствами, связываясь с их контроллерами посредством специальных шин ввода-вывода (шина IDE, шина SCSI и т. д.).
Контроллеры устройств ввода-вывода весьма различны как по своему внутреннему строению, так и по исполнению (от одной микросхемы до специализированной вычислительной системы со своим процессором, памятью и т. д.), поскольку им приходится управлять совершенно разными приборами. Не вдаваясь в детали этих различий, мы выделим некоторые общие черты контроллеров, необходимые им для взаимодействия с вычислительной системой. Обычно каждый контроллер имеет по крайней мере четыре внутренних регистра, называемых регистрами состояния, управления, входных данных и выходных данных.
11.3 Опрос устройств и прерывания
Технический механизм, который позволяет внешним устройствам оповещать процессор о завершении команды вывода или команды ввода, получил название механизма прерываний.
Вместо выполнения очередной команды из потока команд он частично сохраняет содержимое своих регистров и переходит на выполнение программы обработки прерывания, расположенной по заранее оговоренному адресу. При наличии только одной линии прерываний процессор при выполнении этой программы должен опросить состояние всех устройств ввода-вывода, чтобы определить, от какого именно устройства пришло прерывание (polling прерываний), выполнить необходимые действия (например, вывести в это устройство очередную порцию информации или перевести соответствующий процесс из состояния ожидание в состояние готовность) и сообщить устройству, что прерывание обработано (снять прерывание).
В большинстве современных компьютеров процессор стараются полностью освободить от необходимости опроса внешних устройств, в том числе и от определения с помощью опроса устройства, сгенерировавшего сигнал прерывания. Устройства сообщают о своей готовности процессору не напрямую, а через специальный контроллер прерываний, при этом для общения с процессором он может использовать не одну линию, а целую шину прерываний. Каждому устройству присваивается свой номер прерывания, который при возникновении прерывания контроллер прерывания заносит в свой регистр состояния и, возможно, после распознавания процессором сигнала прерывания и получения от него специального запроса выставляет на шину прерываний или шину данных для чтения процессором. Номер прерывания обычно служит индексом в специальной таблице прерываний, хранящейся по адресу, задаваемому при инициализации вычислительной системы, и содержащей адреса программ обработки прерываний – векторы прерываний. Для распределения устройств по номерам прерываний необходимо, чтобы от каждого устройства к контроллеру прерываний шла специальная линия, соответствующая одному номеру прерывания.
11.4 Организация передачи данных
В ЭВМ используются два основных способа организации передачи данных между памятью и периферийными устройствами: программно-управляемая передача и прямой доступ к памяти (ПДП).
Программно-управляемая передача данных осуществляется при непосредственном участии и под управлением процессора.
Альтернативой программно-управляемому обмену служит прямой доступ к памяти - способ быстродействующего подключения внешнего устройства, при котором оно обращается к оперативной памяти, не прерывая работы процессора. Такой обмен происходит под управлением отдельного устройства - контроллера прямого доступа к памяти (КПДП).
Структура ЭВМ, имеющей в своем составе КПДП, представлена на рисуноке 11.2
Рисунок 11.2 - Обмен данными в режиме прямого доступа к памяти
Перед началом работы контроллер ПДП необходимо инициализировать: занести начальный адрес области ОП, с которой производится обмен, и длину передаваемого массива данных. В дальнейшем по сигналу запроса прямого доступа контроллер фактически выполняет все те действия, которые обеспечивал микропроцессор при программно-управляемой передаче.
Для освобождения процессора от операций последовательного вывода данных из оперативной памяти или последовательного ввода в нее был предложен механизм прямого доступа внешних устройств к памяти – ПДП или Direct Memory Access – DMA. Давайте кратко рассмотрим, как работает этот механизм.
Для централизации эти обязанности обычно возлагаются не на каждое устройство в отдельности, а на специальный контроллер – контроллер прямого доступа к памяти. Контроллер прямого доступа к памяти имеет несколько спаренных линий – каналов DMA, которые могут подключаться к различным устройствам.
Структура системы ввода-вывода.
Разработчики операционных систем получают возможность освободиться от написания и тестирования этих специфических программных частей, получивших название драйверов, передав эту деятельность производителям самих внешних устройств.
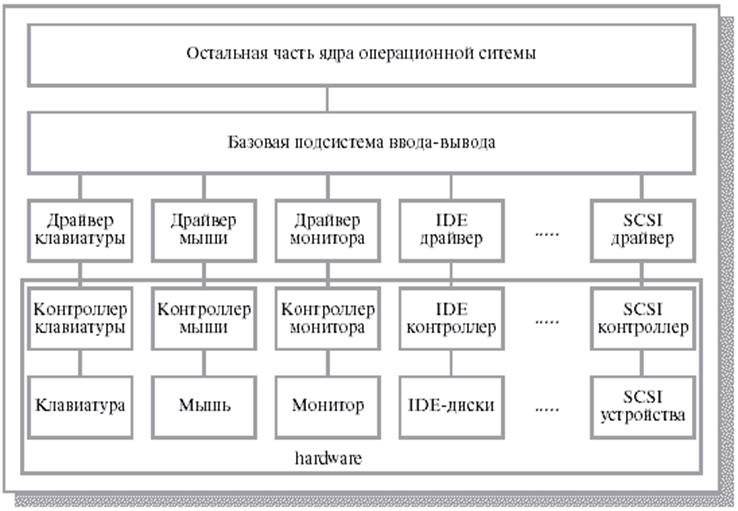
Рисунок 11.3 - Структура системы ввода-вывода
11.5 Структура шин современного ПК
Особенностью современных ПК является совместное применение шин EISA, MCA, VLB, PCI, PCMCIA (CardBus) и AGP (см.рисунок 11.3).
С ростом частоты работы ЦП и изменения времени доступа к ОЗУ пропускная способность шины ISA в 8 Мбайт/сек стала тормозить работу процессора. С дальнейшим ростом частоты работы ЦП тормозом в работе стало ОЗУ. Тогда ввели дополнительную высокоскоростную кэш - память, что уменьшило простои ЦП. Все ПУ продолжали работать через системную шину, но кроме ISA появились более скоростные шины EISA и MCA.
Для интерфейса, соединяющего два устройства (модуля), различаются три возможных режима обмена: дуплексный, полудуплексный и симплексный.
Шины могут быть синхронными (осуществляющими передачу данных только по тактовым импульсам) и асинхронными (осуществляющими передачу данных в произвольные моменты времени), а также использовать различные схемы арбитража (то есть способа совместного использования шины несколькими устройствами).

Шина Локальная Шина памяти
кэш-памяти шина Шина PCI
![]()
(AGP)
Шина EISA или MCA
Рисунок 11.3 - Современный ПК с набором шин
- PCI, EISA, SCSI, USB
В системе ввода-вывода различные ПУ подключались к разным шинам. Медленные - к ISA, а высокоскоростные - к РСI. Важнейшее отличие шины PCI от шины ISA заключается в возможности динамического конфигурирования периферийных устройств, то есть система распределяет ресурсы между периферийными устройствами оптимальным образом и без постороннего вмешательства. С появление шины РСI стало целесообразным использовать высокоскоростные параллельные и последовательные интерфейсы ПУ (SCSI, ATA, USB). Появление шины РСI не сняло всех проблем по качественному выводу визуальной информации для 3-х мерных изображений, "живого" видео. Здесь уже требовались скорости в сотни Мбайт/сек. В 1996г. фирма Intel разработала новую шину AGP, предназначенную только для связи ОЗУ и процессора с видеокартой монитора. Эта шина обеспечивала пропускную способность в сотни Мбайт/сек. Она непосредственно связывала видеокарту с ОЗУ минуя шину РСI.
Мост – устройство, применяемое для объединения шин, использующих разные или одинаковые протоколы обмена. Мост – это сложное устройство, которое осуществляет не только коммутацию каналов передачи данных, но и производит управление соответствующими шинами.
В структуре компьютера, использующего шину РСI, применяются три типа мостов.Мост шины – южный мост (РСIBridge), производящий подключение шины РСI к другим шинам, например, ISA или ЕISA. Главный мост – северный мост (HostBridge), соединяющий шину РСI с системной шиной, кроме того, этот мост содержит контроллер ОЗУ, арбитр и схему автоконфигурации. Одноранговый мост (Peer-to-Peer) для соединения двух шин РСI между собой. Это делается для увеличения числа устройств, подключаемых к шине.
Номинальной рабочей частотой шины PCI Express является 2,5 ГГц. Физическая реализация шины передачи данных - это две дифференциальные пары проводников с импедансом 50 Ом (первая пара работает на прием, вторая - на передачу), данные по которым передаются с использованием избыточного кодирования по схеме "8/10" с исправлением ошибок.
12 Лекция №12. Особенности архитектуры современных высокопроизводительных ВС
Цель лекции: изучение специализированных систем обработки данных высокой производительности.
Содержание лекции: классификация архитектур по параллельной обработке данных. Параллелизм на уровне команд – однопроцессорные архитектуры. Суперскалярная архитектура.
12.1 Классификация архитектур по параллельной обработке данных
В 1966 году М.Флинном (Flynn) был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса:
1) SISD (single instruction stream / single data stream)- одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций.
2) MISD (multiple instruction stream / single data stream)- множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должны выполнятся над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, не было создано.
3) SIMD (single instruction stream / multiple data stream)- одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров, в пределах от 1024 до 16384, которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных. Другим подклассом SIMD-систем являются векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов.
4) MIMD(multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. Считаем, что множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD компьютерах, которые обычно называют конвейерными или векторными, вторая – в параллельных компьютерах.
12.2 Параллелизм на уровне команд – однопроцессорные архитектуры
Процесс выборки с упреждением подразделяет выполнение команды в два этапа: вызов и собственно выполнение.
Выполнение каждой команды складывается из ряда последовательных этапов (шагов, стадий), суть которых не меняется от команды к команде. С целью увеличения быстродействия процессора и максимального использования всех его возможностей в современных микропроцессорах используется конвейерный принцип обработки информации. По очередному тактовому импульсу каждая команда в конвейере продвигается на следующую стадию обработки, выполненная команда покидает конвейер, а новая поступает в него.
Выполнение типичной команды можно разделить на следующие этапы:
1) С 1 – выборка команды (по адресу, заданному счетчиком команд, из памяти извлекается команда и помещается в буфер);
2) С 2 – декодирование команды (определение КОП и типа операндов);
3) С 3 – выборка операндов (определение местонахождения операндов и вызов их из регистров);
4) С 4 – выполнение команды;
5) С 5 – запись результата в нужный регистр.
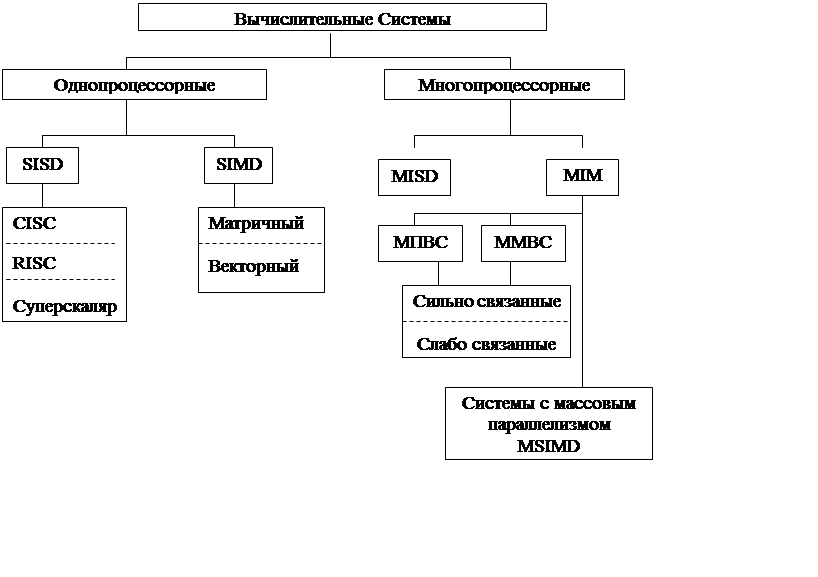
Рисунок 12.1 - Классификация ВС
Работу конвейера можно условно представить в виде временной диаграммы на которой обычно изображаются выполняемые команды, номера тактов и этапы выполнения команд.
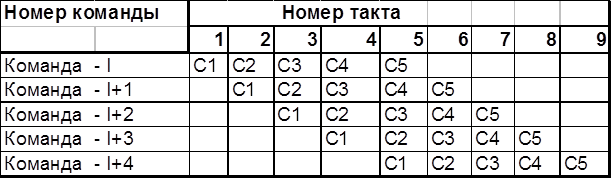
Рисунок 12.2 - Диаграмма работы простейшего конвейера
Однако, при конвейерной обработке часто возникают конфликты, которые препятствуют выполнению очередной команды в предназначенном для нее такте. Конфликты могут иметь различное происхождение, но в целом их можно охарактеризовать как структурные, по управлению и по данным.

Рисунок 12.3 - Эффект конвейеризации – четырехкратное ускорение
Структурные конфликты возникают в том случае, когда аппаратные средства процессора не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением. Эту ситуацию можно было бы ликвидировать двумя способами. Первый предполагает увеличение времени такта до такой величины, которая позволила бы все этапы любой команды выполнять за один такт. Однако при этом существенно снижается эффект конвейерной обработки, так как все этапы всех команд будут выполняться значительно дольше, в то время как обычно нескольких тактов требует выполнение лишь отдельных этапов очень небольшого количества команд. Второй способ предполагает использование таких аппаратных решений, которые позволили бы значительно снизить затраты времени на выполнение данного этапа (например, использовать матричные схемы умножения).
Наиболее эффективным методом снижения потерь от конфликтов по управлению служит предсказание переходов. Методы предсказания переходов делятся на статические и динамические. При использовании статических методов до выполнения программы для каждой команды условного перехода указывается направление наиболее вероятного ветвления. Методы динамического прогнозирования учитывают направления переходов, реализовывавшиеся этой командой при выполнении программы.
Конфликты по данным возникают в случаях, когда выполнение одной команды зависит от результата выполнения предыдущей команды. Устранение конфликтов по данным типов WAR и WAW достигается путем отказа от неупорядоченного исполнения команд, но чаще всего путем введения буфера восстановления последовательности команд.
12.3 Суперскалярная архитектура
Смысл суперскалярной обработки - наличие в аппаратуре средств, позволяющих одновременно выполнять две и более скалярных операций, т.е. команд обработки пары чисел.
Функции стадии С1 (выборка команд а также тезис – один конвейер хорошо, а два лучше) позволяют реализовать структуру с двойным конвейером.
С1 С2 С3 С4 С5
 |
Рисунок 12.4 - Двойной конвейер из пяти стадий
13 Лекция №13. Архитектура многопроцессорных ВС
Цель лекции: изучение специализированных архитектур многопроцессорной вычислительной системы.
Содержание лекции: основные сведения о микропроцессорной вычислительной системе. SMP архитектура. MPP архитектура. Гибридная архитектура (NUMA). PVP архитектура. Организация когерентности многоуровневой иерархической памяти.
13.1 Основные сведения о микропроцессорной вычислительной системе
Одной из отличительных особенностей многопроцессорной вычислительной системы является сеть обмена, с помощью которой процессоры соединяются друг с другом и/или с памятью. Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, другая - на использовании общей памяти. К первой группе относятся машины с общей (разделяемой) основной памятью, объединяющие до нескольких десятков (обычно менее 32) процессоров. В многопроцессорной системе с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти.
SMP архитектура (symmetric multiprocessing) - cимметричная многопроцессорная архитектура. Главной особенностью систем с архитектурой SMP является наличие общей физической памяти, разделяемой всеми процессорами.
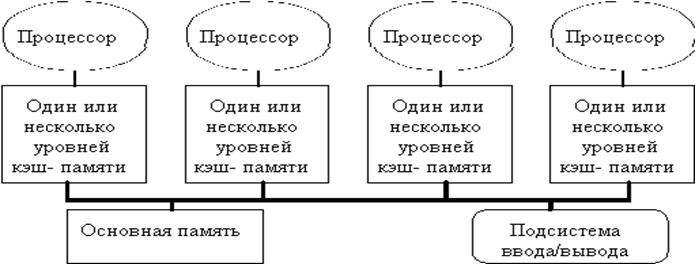 |
Сравнительно небольшое количество процессоров в таких машинах позволяет иметь одну централизованную общую память и объединить процессоры и память с помощью одной шины. Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является наиболее популярным. Структура подобной системы представлена на рисуноке 13.1.
Рисунок 13.1 - Многопроцессорная система с общей памятью
Память является способом передачи сообщений между процессорами, при этом все вычислительные устройства при обращении к ней имеют равные права и одну и ту же адресацию для всех ячеек памяти. Поэтому SMP архитектура называется симметричной.
13.3 MPP архитектура
MPP архитектура (massive parallel processing) - массивно-параллельная архитектура. Главная особенность такой архитектуры состоит в том, что память физически разделена. В этом случае система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти (ОП), два коммуникационных процессора (рутера) или сетевой адаптер, иногда - жесткие диски и/или другие устройства ввода/вывода. О
На рисунке 13.2 показана структура такой системы.
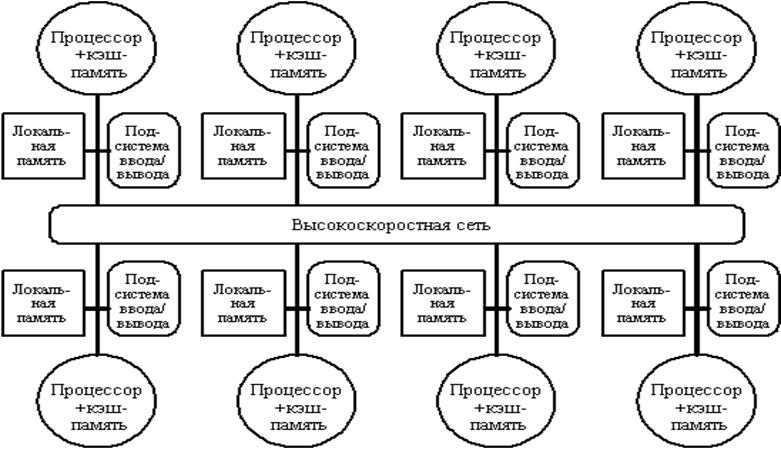
Рисунок 13.2 - Многопроцессорная система с распределенной памятью
Главным преимуществом систем с раздельной памятью является хорошая масштабируемость: в отличие от SMP-систем в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодняшний день устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров (ASCI Red, ASCI Blue Pacific).
Недостатки: отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами.
13.4 Гибридная архитектура (NUMA)
Сегодня стало уже общепринятым, что в многопроцессорных системах с общим полем памяти для достижения наилучшего масштабирования необходимо отказаться от классической архитектуры SMP (узким местом которой является общая шина или коммутатор) в пользу ccNUMA. В последнем случае многопроцессорные системы строятся на базе SMP-узлов, содержащих процессоры и оперативную память, а узлы связываются между собой посредством общесистемного межсоединения, в роли которого обычно выступает коммутатор. Поэтому доступ процессоров к локальной оперативной памяти своего узла осуществляется быстрее, чем к оперативной памяти другого узла; таким образом, доступ оказывается «неоднородным», о чем и говорит сокращение NUMA (Non-Unifrom Memory Access), а сс означает coherent cash («когерентный кэш»).
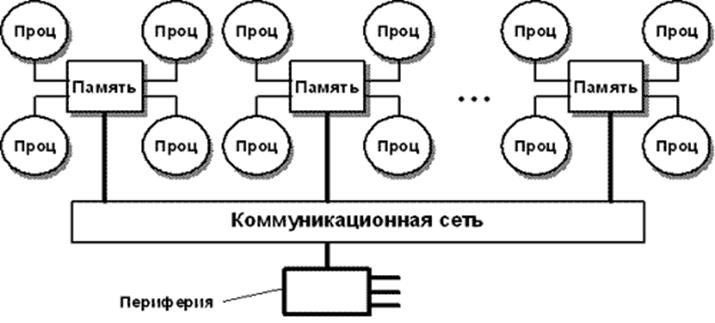
Рисунок 13.3 - Гибридная архитектура
13.5 PVP архитектура
PVP (Parallel Vector Process) - параллельная архитектура с векторными процессорами. Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров (1-16) работают одновременно с общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP).
13.6 Организация когерентности многоуровневой иерархической памяти
Понятие когерентности кэшей описывает тот факт, что все центральные процессоры получают одинаковые значения одних и тех же переменных в любой момент времени. Действительно, поскольку кэш-память принадлежит отдельному компьютеру, а не всей многопроцессорной системе в целом, данные, попадающие в кэш одного компьютера, могут быть недоступны другому. Чтобы избежать этого, следует провести синхронизацию информации, хранящейся в кэш-памяти процессоров.
14 Лекция № 14. Кластерные системы
Цель лекции: изучение эффективного управления и контроля работы вычислительной системы.
Содержание лекции: концепция кластерных систем.
14.1 Концепция кластерных систем
В общих чертах мы уже познакомились с многопроцессорными и многомашинными вычислительными системами. Однако с некоторыми конкретными и, в тоже время. Практическими системами необходимо познакомиться более близко. К таким системам относятся кластерные системы.
Впервые в классификации вычислительных систем термин "кластер" определила компания Digital Equipment Corporation (DEC). По определению DEC, кластер - это группа вычислительных машин, которые связаны между собою и функционируют как один узел обработки информации.
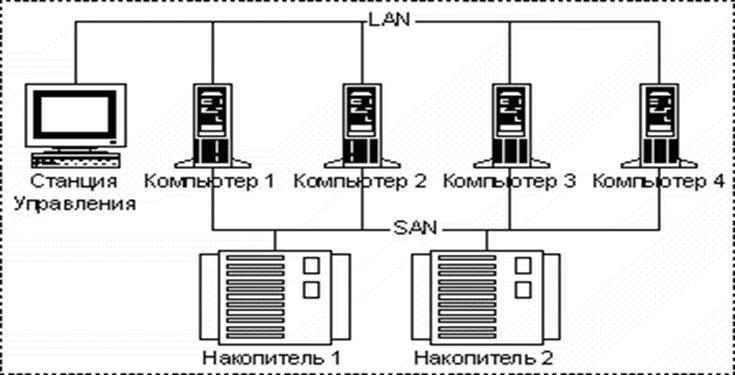 |
Кластер функционирует как единая система, то есть для пользователя или прикладной задачи вся совокупность вычислительной техники выглядит как один компьютер. Именно это и является самым важным при построении кластерной системы.
 |
Рисунок 14.1 - Кластерная система
1) LAN – Local Area Network, локальная сеть.
2) SAN – Storage Area Network, сеть хранения данных.
К общим требованиям, предъявляемым к кластерным системам, относятся:
1) Высокая готовность.
2) Высокое быстродействие.
3) Масштабирование.
4) Общий доступ к ресурсам.
5) Удобство обслуживания.
 |
В общем случае кластер функционирует как мультипроцессорная система, поэтому, важно понимать классификацию таких систем в рамках распределения программно-аппаратных ресурсов.
Рисунок 14.2 - Тесно связанная мультипроцессорная система
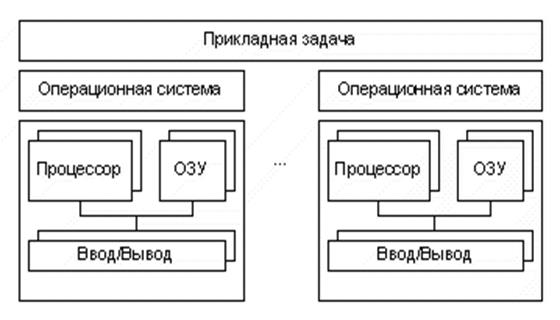 |
Рисунок 14.3 - Умеренно связанная мультипроцессорная система
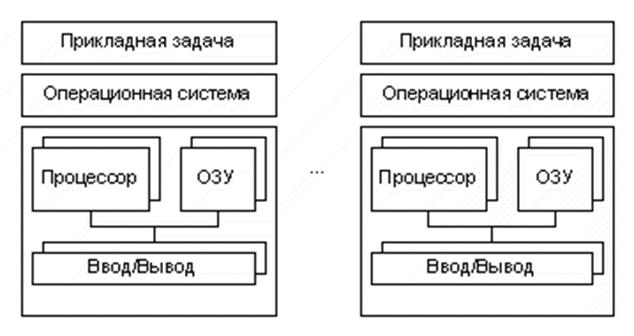 |
Рисунок 14.4 - Слабо связанная мультипроцессорная система
15 Лекция №15. Многомашинные системы – вычислительные сети
Цель лекции: изучения принципов построения вычислительных сетей, их функционирование и организация.
Содержание лекции: назначение компьютерной сети и ее модели. Многослойная модель сети.
Взаимодействие удаленных процессов как основа работы вычислительных сетей. Многоуровневая модель построения сетевых вычислительных систем. Проблемы адресации в сети.
15.1 Назначение компьютерной сети и ее модели
Многомашинная система (мультикомпьютер) – это вычислительный комплекс (ВК), включающий в себя несколько компьютеров (каждый из которых работает под управлением собственной ОС), а также программные и аппаратные средства связи компьютеров, которые обеспечивают передачу данных в транспортной системе ВК. Связь между компьютерами многомашинной системы менее тесная, чем между процессорами в мультипроцессоре.
Компьютерные сети, также могут быть отнесены к распределенным вычислительным системам, в которых программные и аппаратные связи являются еще более слабыми, а автономность процессов проявляется в наибольшей степени. Каждый компьютер (узел сети) работает под управлением собственной ОС, взаимодействие между компьютерами осуществляется за счет передачи сообщений через сетевые адаптеры (сетевые карты) и каналы связи, содержащие наряду с линиями связи коммутационное оборудование.
Предположим, что пользователь другого компьютера хотел бы распечатать текст. Сложность состоит в том, что к его компьютеру не подсоединен принтер, и требуется воспользоваться тем принтером, который связан с другим компьютером.
|
|
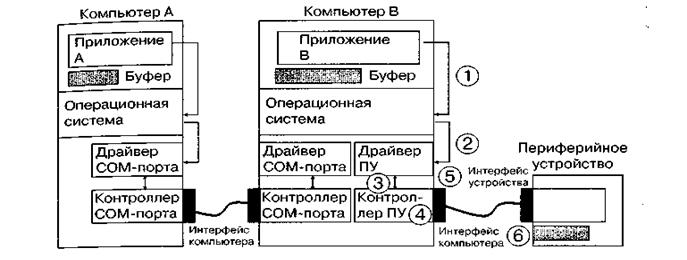
Рисунок 15.1 - Связь двух компьютеров
Даже поверхностно рассматривая работу сети, можно заключить, что вычислительная сеть — это сложный комплекс взаимосвязанных и согласованно функционирующих программных и аппаратных компонентов.
Весь комплекс программно-аппаратных средств сети может быть описан многослойной моделью.
Хотя компьютеры и являются центральными элементами обработки данных в сетях, в последнее время не менее важную роль стали играть коммуникационные устройства. Кабельные системы, повторители, мосты, коммутаторы, маршрутизаторы и модульные концентраторы из вспомогательных компонентов сети превратились в основные наряду с компьютерами и системным программным обеспечением, как по влиянию на характеристики сети, так и по стоимости.
Образующим программную платформу сети, являются операционные системы (ОС). От того, какие концепции управления локальными и распределенными ресурсами положены в основу сетевой ОС, зависит эффективность работы всей сети.
Самый верхний слой сетевых средств образуют различные сетевые приложения, такие как сетевые базы данных, почтовые системы, средства архивирования данных, системы автоматизации коллективной работы и т.д.

Рисунок 15.2 - Многослойная модель сети.
Вычислительная сеть — это многослойный комплекс взаимосвязанных и согласованно функционирующих программных и аппаратных компонентов: компьютеров, коммуникационного оборудования, операционных систем, сетевых приложений.
15.3 Взаимодействие удаленных процессов как основа работы вычислительных сетей
Все перечисленные выше цели объединения компьютеров в вычислительные сети не могут быть достигнуты без организации взаимодействия процессов на различных вычислительных системах. Будь то доступ к разделяемым ресурсам или общение пользователей через сеть – в основе всего этого лежит взаимодействие удаленных процессов, т. е. процессов, которые находятся под управлением физически разных операционных систем.
В современных сетевых вычислительных комплексах решение вопросов организации взаимоисключений при использовании общей линии связи, как правило, также находится вне компетенции операционных систем и вынесено на физический уровень организации взаимодействия. Ответственность за корректное использование коммуникаций возлагается на сетевые адаптеры.
Для того чтобы описать взаимодействие удаленных процессов и понять, какие функции и как должны выполнять дополнительные части сетевых операционных систем, отвечающих за такое взаимодействие, нам понадобится не менее фундаментальное понятие – протокол.
Различные способы решения проблем по существу, представляют собой различные соглашения, которых должны придерживаться сетевые части операционных систем, т. е. различные сетевые протоколы. Именно наличие сетевых протоколов позволяет организовать взаимодействие удаленных процессов. При рассмотрении перечисленных выше проблем необходимо учитывать, с какими сетями мы имеем дело.
15.4 Многоуровневая модель построения сетевых вычислительных систем
Даже беглого взгляда на перечень проблем, связанных с логической организацией взаимодействия удаленных процессов, достаточно, чтобы понять, что построение сетевых средств связи – задача более сложная, чем реализация локальных средств связи.
Каждый уровень может взаимодействовать непосредственно только со своими соседями, руководствуясь четко закрепленными соглашениями – вертикальными протоколами, которые принято называть интерфейсами.
Формальный перечень правил, определяющих последовательность и формат сообщений, которыми обмениваются сетевые компоненты различных вычислительных систем, лежащие на одном уровне, мы и будем называть сетевым протоколом.
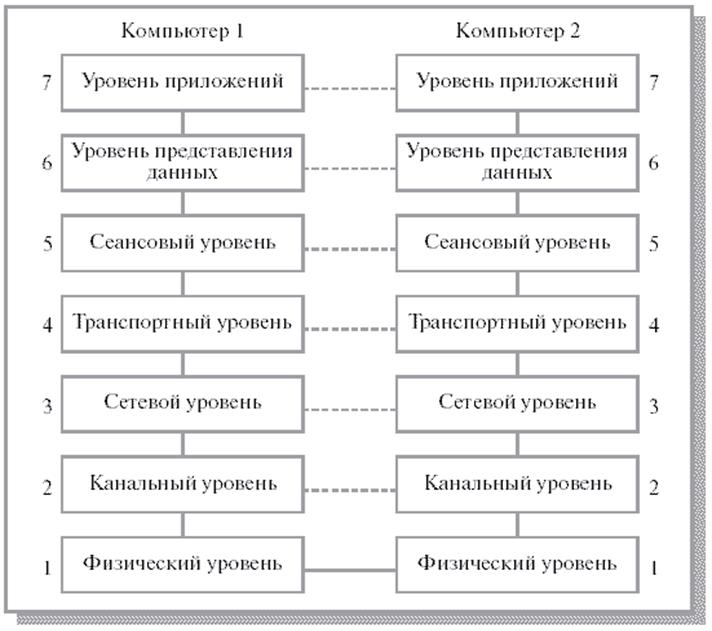
Рисунок 15.3 - Семиуровневая эталонная модель OSI/ISO
Всю совокупность вертикальных и горизонтальных протоколов (интерфейсов и сетевых протоколов) в сетевых системах, построенных по «слоеному» принципу, достаточную для организации взаимодействия удаленных процессов, принято называть семейством протоколов или стеком протоколов. Сети, построенные на основе разных стеков протоколов, могут быть объединены между собой с использованием вычислительных устройств, осуществляющих трансляцию из одного стека протоколов в другой, причем на различных уровнях слоеной модели
Эталоном многоуровневой схемы построения сетевых средств связи считается семиуровневая модель открытого взаимодействия систем (Open System INTerconnection – OSI), предложенная Международной организацией Стандартов (International Standard Organization – ISO) и получившая сокращенное наименование OSI/ISO
Любой пакет информации, передаваемый по сети, должен быть снабжен адресом получателя. Если взаимодействие подразумевает двустороннее общение, то в пакет следует также включить и адрес отправителя.
Существует два принципиально разных подхода к решению этой проблемы: маршрутизация от источника передачи данных и одношаговая маршрутизация.
Маршрутизация от источника передачи данных легко реализуется на промежуточных компонентах сети, но требует полного знания маршрутов на конечных компонентах. Она достаточно редко используется в современных сетевых системах, и далее мы ее рассматривать не будем.
Для работы алгоритмов одношаговой маршрутизации, которые являются основой соответствующих протоколов, на каждом компоненте сети, имеющем возможность передавать информацию более чем одному компоненту, обычно строится специальная таблица маршрутов.
При дистанционно-векторной маршрутизации компоненты операционных систем на соседних вычислительных комплексах сети, занимающиеся выбором маршрута (их принято называть маршрутизатор или router), периодически обмениваются векторами, которые представляют собой информацию о расстояниях от данного компонента до всех известных ему адресатов в сети.
Векторно-дистанционные протоколы обеспечивают достаточно разумную маршрутизацию пакетов, но не способны предотвратить возможность возникновения маршрутных петель при сбоях в работе сети. Поэтому векторно-дистанционная машрутизация может быть эффективна только в относительно небольших сетях.
Заключение
Основными причинами объединения компьютеров в вычислительные сети являются потребности в разделении ресурсов, ускорении вычислений, повышении надежности и облегчении общения пользователей.
Вычислительные комплексы в сети могут находиться под управлением сетевых или распределенных вычислительных систем. Основой для объединения компьютеров в сеть служит взаимодействие удаленных процессов. При рассмотрении вопросов организации взаимодействия удаленных процессов нужно принимать во внимание основные отличия их кооперации от кооперации локальных процессов.
Базой для взаимодействия локальных процессов служит организация общей памяти, в то время как для удаленных процессов – это обмен физическими пакетами данных.
Организация взаимодействия удаленных процессов требует от сетевых частей операционных систем поддержки определенных протоколов. Сетевые средства связи обычно строятся по «слоеному» принципу. Формальный перечень правил, определяющих последовательность и формат сообщений, которыми обмениваются сетевые компоненты различных вычислительных систем, лежащие на одном уровне, называется сетевым протоколом.
Список литературы
1. Таненбаум Э. Архитектура компьютера. - Питер, 2002.
2. Хелд Г. Технологии передачи данных. - Питер, 2003.
3. Столлингс В. Современные компьютерные сети. - Питер, 2003.
4. Олифер В.Г., Олифер Н.А. Компьютерные сети. - Питер, 2000.
5. Иванова Е.М., Жарков С.В. Организация ЭВМ и вычислительных систем, МГИЭМ, Учебное пособие. - М., 2002.
Сводный план 2013 г., поз. 313