Некоммерческое акционерное общество
АЛМАТИНСКИЙ УНИВЕРСИТЕТ ЭНЕРГЕТИКИ И СВЯЗИ
Кафедра компьютерных технологий
РАБОТА В MICROSOFT SQL SERVER 2008
Методические указания к выполнению лабораторных работ
для студентов всех форм обучения специальностей
5В070300 – “Информационные системы”
5В070400 – “Вычислительная техника и программное обеспечение”
Алматы 2011
СОСТАВИТЕЛИ: А. А. Аманбаев и Е.Г. Сатимова. Работа в Microsoft SQL Server 2008. Методические указания к выполнению лабораторных работ для студентов всех форм обучения специальностей 5В070300 – “Информационные системы”; 5В070400 –“ Вычислительная техника и программное обеспечение”. – Алматы: АУЭС, 2011. – 32 с.
Методические указания содержат указания по подготовке к проведению пяти лабораторных работ по установке, изучению, настройке и работе в в Microsoft SQL Server 2008; приведены описания каждой лабораторной работы, дана методика проведения и ход выполнения, оговорен перечень рекомендуемой литературы и контрольные вопросы в конце каждой темы.
Выполнение лабораторных работ определяет фундаментальную основу освоения инструментальной среды Microsoft SQL Server 2008 по курсу “Проектирование и защита баз данных”. Предметом изучения дисциплины “Проектирование и защита баз данных” является освоение основных принципов проектирования и создания баз данных различной степени сложности и назначения в среде Microsoft SQL Server 2008. Студенту важно понять как работать в данной сарверной СУБД, а также создавать базы данных,таблицы, запросы и объекты средствами Microsoft SQL Server 2008. Поскольку бакалавр вычислительной техники занимается созданием, внедрением, анализом и сопровождением, его профессиональная подготовка требует умения грамотно работать с различными СУБД. Предметом изучения в рассматриваемой дисциплине являются СУБД Microsoft SQL Server 2008.
Методические указания предназначены для студентов всех форм обучения специальности 5В070400. Они могут быть использованы и для организации лабораторных занятий по идентичным темам аналогичных дисциплин, запланированных для других специальностей.
Ил. 15, библиогр. – 10 назв.
Рецензент: д-р. физ-мат. наук, проф. З.К. Куралбаев.
Печатается по плану издания некоммерческого акционерного общества “Алматинский Университет энергетики и связи” на 2010 г.
© НАО “Алматинский Университет энергетики и связи”, 2011 г.
|
Введение |
4 |
|
1 Лабораторная работа Установка и настройка Microsoft SQL SERVER 2008 |
5 |
|
Цель работы: приобретение навыков установки и первоначальной настройки Microsoft SQL Server 2008 |
5 |
|
1.1 Рабочее задание |
5 |
|
1.2 Методические указания к выполнению |
5 |
|
Установка MS SQL Server 2008 |
6 |
|
2 Лабораторная работа. Создание файла данных и журнала транзакций |
16 |
|
Цель работы: изучить систему основных компонентов Microsoft SQL Server 2008, понять процесс создания файла данных, освоить управление базами данных при помощи команд языка T-SQL |
16 |
|
2.1 Рабочее задание |
16 |
|
2.2 Методические указания к выполнению |
16 |
|
3 Лабораторная работа. Создание таблиц |
24 |
|
Цель работы: изучить таблицы и типы данных полей, оОсвоить создание таблиц и основные операции с таблицами |
24 |
|
3.1 Рабочее задание |
24 |
|
3.2 Методические указания к выполнению |
24 |
|
4 Лабораторная работа. Создание представлений и фильтров |
36 |
|
Цель работы: изучить процесс создания запросов (представлений) и фильтров, понять процесс выполнения вычислений при помощи оператора SELECT |
36 |
|
4.1 Рабочее задание |
36 |
|
4.2 Методические указания к выполнению |
36 |
|
5 Лабораторная работа. Создание динамических запросов при помощи хранимых процедур |
56 |
|
Цель работы: изучить процесс создания динамических запросов при помощи хранимых процедур |
56 |
|
5.1 Рабочее задание |
56 |
|
5.2 Методические указания к выполнению |
56 |
|
Список использованной литературы |
67 |
Введение
В настоящий сборник включены лабораторные работы, целью которых является освоение студентом основных принципов проектирования и создания баз данных различной степени сложности и назначения в среде Microsoft SQL Server 2008 при изучении курса «Проектирование и защита баз данных».
Этапы выполнения лабораторной работы: проработка теоретической части, выполнение рабочего задания, создание отчета и защита его у преподавателя. Рабочее задание содержит работы по выполнению того или иного задания по рассматриваемой теме. Выполнение практических заданий дает возможность выработки навыков и знаний у студентов. В методических указаниях представлены лабораторные задания по базам данных, выполненным на Microsoft SQL Server 2008. Студентам предлагается параллельно выполнить одну и ту же лабораторную работу. В отчете студент должен продемонстрировать выполнение лабораторных работ на своем, выбранном им дистрибутиве.
Выполнение каждой лабораторной работы должно завершаться оформлением отчета. Отчеты должны быть оформлены по фирменному стандарту АУЭС и содержать не менее 20 принскринов, отчет о проделанной работе должен содержать:
- титульный лист;
- цель и задание работы;
- оглавление или содержание;
- введение;
- описание лабораторной работы;
- задание на выполнение работы;
- ответы на контрольные вопросы (итоги теоретической подготовки);
- результаты проделанной работы (принскрины по каждому пункту рабочего задания с пояснением);
- выводы своими словами (что получилось или не получилось, что оказалось в задании непонятно, какие навыки приобретены);
- заключение;
- список литературы.
1 Лабораторная работа. Установка и настройка Microsoft SQL SERVER 2008
Цель работы: приобретение навыков установки и первоначальной настройки Microsoft SQL Server 2008.
1.1 Рабочее задание
1 Установить в Windows виртуальную машину VmWare.
2 Установить Microsoft SQL Server 2008 на виртуальную машину.
1.2 Методические указания к выполнению
История создания
Родоначальником серии SQL Server и его основой является язык запросов SQL. Данный язык был создан компанией IBM в начале 1970г. Изначально он назывался SEQVEL (Structured English Query Language) В основу языка SQL, используемого в SQL Server, легла разновидность языка T-SQL (Transact – SQL).
В начале 80 г. фирма IBM и ее подрядчики Microsoft и Sybase создают первую версияю сетевой СУБД, которая называлась SQL Server версия 1.0, для операционной системы IBM OS/2. После этого под эту операционную систему было выпущено еще 3 версии SQL Server. В середине 80-х г. компания Microsoft и Sybase отделяются от фирмы IBM, и Microsoft начинает работу над своей операционной системой Windows и вместе с компанией Sybase начинает развитие SQL Server.
В середине 90-х г. (в частности в 1995г) Microsoft создала операционную систему Windows NT и вместе с компанией Sybase выпускает первую версию SQL Server для Windows версии 4.1.
После этого компания Sybase разрывает свои отношения с Microsoft и Microsoft создает Microsoft SQL Server 6.0. Данная версия была предназначена для работы в операционной системе Windows NT, 95 и 98. В 1999г. выходит версия Microsoft SQL Server 7.0, которая стала одной из самых популярных серверных СУБД в мире. В 2000г. выходит 8-я версия Micrsoft SQL Server 2000. В 2005 году выходит новая версия сервера, основанная на новой технологии NET, а в 2008 году выходит её улучшенная версия Microsoft SQL Server 2008.
Требования к аппаратному обеспечению
Минимальные:
- процессор: Intel (или совместимый) Pentium III 1000 МГц или выше;
- память: 512 МБ или более;
- жесткий диск: 20 ГБ или более.
Рекомендуемые:
- процессор: Intel Pentium4 3000 МГц или выше;
- память: 2 ГБ или более;
- жесткий диск: 100 ГБ или более.
Требования к программному обеспечению
Необходимо наличие установленных пакетов: Microsoft dotNET Framework 3.5 SP1,
Windows
Installer 4.5 и Windows
PowerShell 1.0.
Операционная система: MS Windows 2003 Server SP2 (Standard Edition, Enterprise Edition, Data Center Edition), MS Windows 2003 Small Business Server SP2
(Standard Edition, Premium Edition), MS Windows 2008 Server (Standard Edition, Enterprise Edition, Data Center Edition, Web Edition).
Кроме того, некоторые редакции SQL Server
2008, в том числе бесплатную редакцию (Express Edition),
можно устанавливать на следующие ОС: MS Windows XP SP2 (Home Edition,
Professional Edition, Media Center Edition, Tablet Edition), MS Windows Vista
(Home Basic Edition, Home Premium Edition, Business Edition, Enterprise
Edition, Ultimate Edition).
Примечание. 64-разрядные редакции SQL Server 2008 предъявляют другие требования к аппаратно-программному обеспечению.
Установка MS SQL Server 2008
1. Запустить программу-установщик (в бесплатной версии Express Edition обычно называется SQLEXPRADV_x86_RUS.exe) с правами администратора на данном компьютере.
2. В разделе «Планирование» нажать пункт «Средство проверки конфигурации»:

3. Нажать кнопку «Показать подробности» и убедиться, что все проверки успешно пройдены. Если будут обнаружены какие-то проблемы, то необходимо их устранить и запустить повторную проверку кнопкой «Включить заново». Затем закрыть данное окно кнопкой «ОК»:
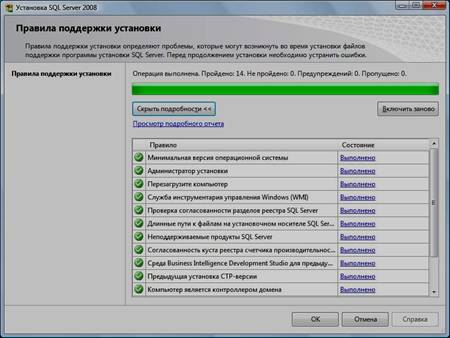
4. Нажать на раздел «Установка» и затем пункт «Новая установка изолированного SQL Server или добавление компонентов …»:
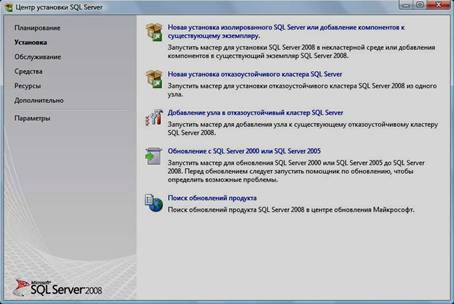
5. Нажать кнопку «Показать подробности» и убедиться, что все проверки успешно пройдены. Если будут обнаружены какие-то проблемы, то необходимо их устранить и запустить повторную проверку кнопкой «Включить заново». Затем нажать кнопку «ОК»:
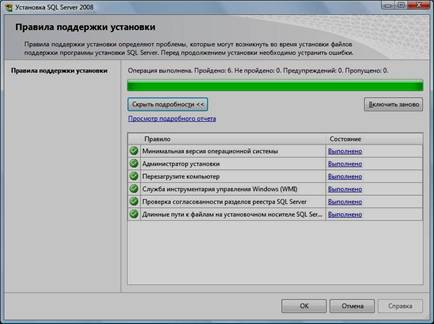
6. Ввести приобретенный ключ продукта (для бесплатной версии не требуется) и нажать кнопку «Далее»:
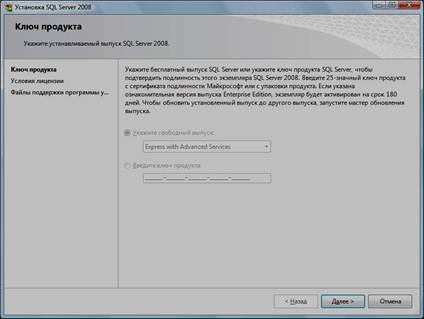
7. Прочитать лицензию, установить галочку и нажать кнопку «Далее»:
8. Нажать кнопку «Установить»:
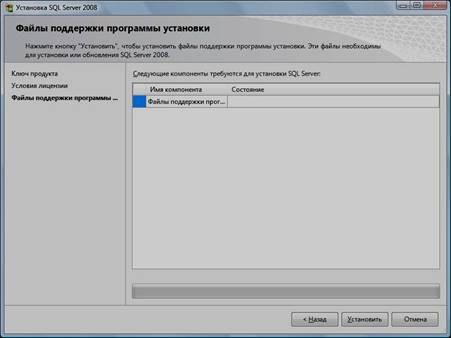
9. Нажать кнопку «Показать подробности» и убедиться, что все проверки успешно пройдены. Если будут обнаружены какие-то проблемы, то необходимо их устранить и запустить повторную проверку кнопкой «Включить заново». Затем нажать кнопку «Далее»:
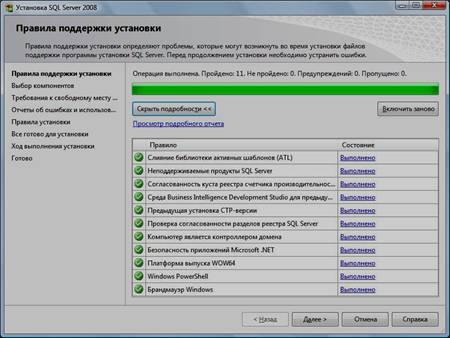
Примечание. Если появится предупреждение в строке «Брандмауэр Windows», то его можно проигнорировать – оно просто акцентирует Ваше внимание на том, что потребуется дополнительная настройка «Брандмауэра Windows» для доступа к SQL Server с других компьютеров (см. ниже).
10. Выбрать компоненты для установки (можно воспользоваться кнопкой «Выделить все») и нажать кнопку «Далее»:
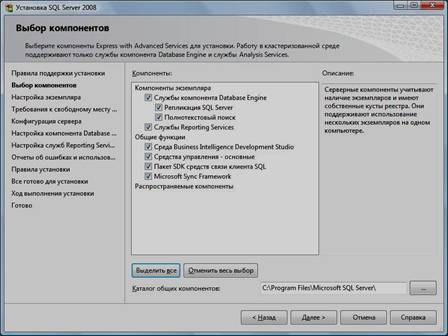
Внимание! Для
нормального функционирования ПО «Альта ГТД-ПРО» необходимо обязательно
установить компонент «Полнотекстовый поиск»!
Кроме того, для управления самим SQL Server необходимо установить компонент «Средства
управления – основные»!
11. Выбрать опцию «Экземпляр по умолчанию» и нажать кнопку «Далее»:
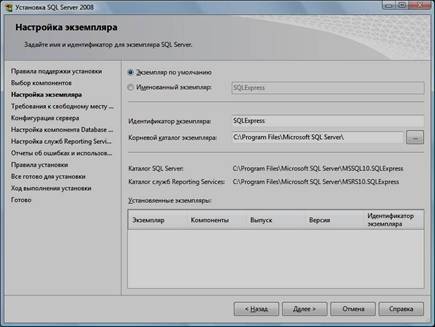
12. Нажать кнопку «Далее»:

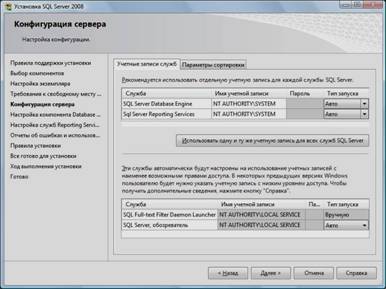
13. Выбрать опции, как показано на рисунке, и перейти на закладку «Параметры сортировки»:
Примечание. Если Вы хотите использовать «SQL Server Agent» (встроенный планировщик заданий, в бесплатную версию не входит) для выполнения регулярного резервного копирования файлов БД на другой компьютер в своей локальной сети (рекомендуется) и Ваша сеть построена с использованием домена Windows NT, то необходимо завести в Вашем домене отдельную учетную запись для SQL Server Agent и предоставить ей права на соответствующие ресурсы (более подробную информацию можно найти в справочной системе SQL Server). При такой конфигурации в этом окне необходимо в поля «Имя учетной записи» и «Пароль» ввести имя созданной учетной записи (вида ДОМЕН\ИМЯ) и ее пароль, как минимум, для службы «SQL Server Agent».
14. Выбрать опции, как показано на рисунке, и нажать кнопку «Далее»:
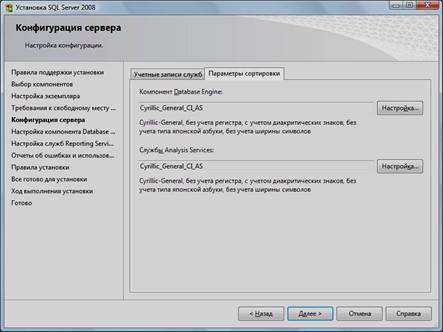
Примечание. Чтобы изменить опцию нажмите расположенную рядом кнопку «Настройка» и установите параметры, как показано на следующем рисунке:
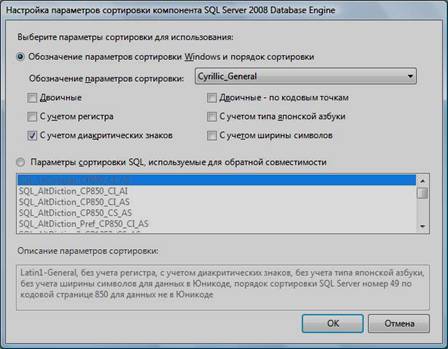
Внимание. Данную настройку нельзя будет изменить после установки. Будьте внимательны!
15. Выбрать опцию «Смешанный режим» и задать пароль для встроенной учетной записи администратора «sa» (эта учетная запись обладает максимальными правами доступа ко всем функциям и объектам на SQL-сервере). Дополнительно можно указать учетные записи пользователей Windows или целые группы пользователей Windows, которые должны обладать максимальными правами доступа к SQL Server (например, встроенную группу «Администраторы»). Затем перейти на закладку «Каталоги данных»:
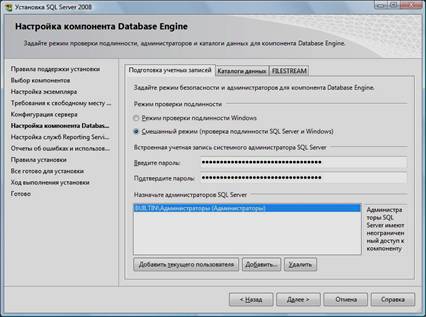
16. В поле «Корневой каталог данных» ввести путь к папке, где будут размещаться файлы баз данных (рекомендуется использовать отдельный от ОС физический диск), и нажать кнопку «Далее»:

17. Выбрать опции, как показано на рисунке, и нажать кнопку «Далее»:
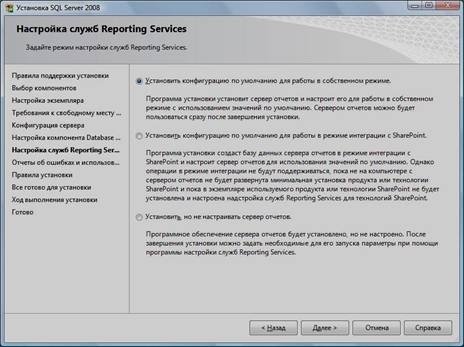
18. Выбрать опции, как показано на рисунке, и нажать кнопку «Далее»:
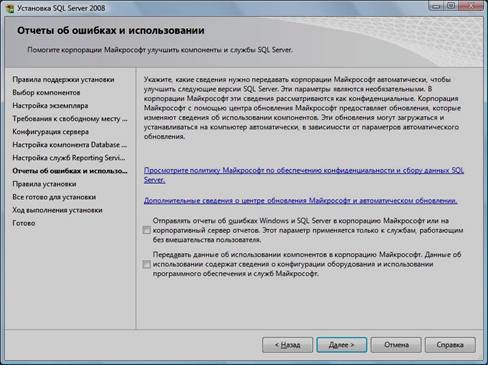
19. Нажать кнопку «Показать подробности» и убедиться, что все проверки успешно пройдены. Если будут обнаружены какие-то проблемы, то необходимо их устранить и запустить повторную проверку кнопкой «Включить заново». Затем нажать кнопку «Далее»:
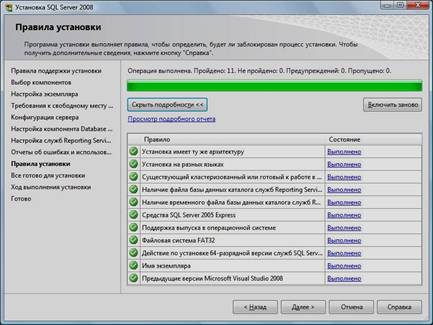
20. Нажать кнопку «Установить».
21. После завершения установки нажать кнопку «Далее»:
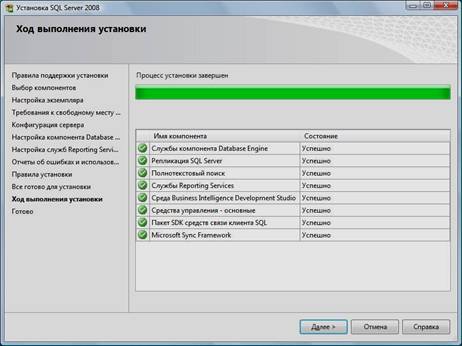
22. Нажать кнопку «Закрыть». На экране появится окно, сообщающее об успешной установке Microsoft SQL Server 2008.
2 Лабораторная работа. Создание файла данных и журнала транзакций
Цель работы: изучить систему основных компонентов Microsoft SQL Server 2008, понять процесс создания файла данных, освоить управление базами данных при помощи команд языка T-SQL.
2.1 Рабочее задание
Создать БД «Students», расположенную в файле «D:\Students.mdf» и имеющую начальный размер файла данных 1мб., максимальный размер файла данных 100мб. И шаг увеличения файла данных, равный 1мб. Файл журнала транзакций данной БД имеет имя «StudentsLog» и расположен в файле «D:\Students.ldf». Данный файл имеет начальный размер, равный 1мб., максимальный размер равный 100мб. И шаг увеличения, равный 1мб.
2.2 Методические указания к выполнению
Основные компоненты Microsoft SQL Server 2008
Все компоненты Microsoft SQL Server 2008 запускаются из меню «Пуск \ Программы \ Microsoft SQL Server 2008. В Microsoft SQL Server 2008 входят следующие компоненты:
1) Deployment Wizard – мастер по выводу информации хранимой на сервере;
2) SQL Server Installation Center – центр установки SQL Server 2008;
3) Reporting Services Configuration Manager – менеджер службы настройки отчётов;
4) SQL Server Configuration Manager – менеджер настройки сервера;
5) SQL Server Error and Usage Reporting – служба протоколирования работы сервера и служба отчётов об ошибках;
6) Microsoft Samples Overview – ссылка на сайт корпорации Microsoft, где можно просмотреть примеры работы с сервером;
7) SQL Server Books Online – полная справочная система по Microsoft SQL Server 2008. Она содержит справки, как по программированию, так и по администрированию сервера;
8) SQL Server Tutorials – учебники по работе с сервером;
9) Data Profile Viewer – просмотр профилей по работе с данными;
10) Execute Package Utility – инструменты по сжатию данных;
11) Database Engine Tuning Advisor – мастер настройки ядра базы данных;
12) SQL Server Profiler – настройка профилей по работе с данными;
13) Import and Export Data – импорт и экспорт данных;
14) SQL Server Business Intelligence Development Studio – интегрированная среда разработки Business Intelligence Development Studio;
15) SQL Server Management Studio – графическая оболочка для управления сервером и разработки баз данных.
Новую БД можно создать, используя стандартные команды языка T-SQL. Для создания новой БД необходимо сделать активную БД «Master». Это можно сделать либо выбором ее из выпадающего списка БД на панели инструментов, либо набором команды USE Master на вкладке нового запроса.
Замечание: все команды языка T-SQL набираются на вкладке нового запроса (SQLQuery). Для того чтобы создать новый запрос на панели инструментов необходимо нажать кнопку
Для выполнения команд языка T-SQL на панели инструментов необходимо нажать кнопку
![]()
или на вкладке нового запроса набрать команду GO.
Замечание: В Microsoft SQL Server БД состоит из двух частей:
- файл данных – файл, имеющий расширение mdf и где находятся все таблицы и запросы;
- файл журнала транзакций – файл, имеющий расширение ldf, содержит журнал, где фиксируются все действия с БД. Данный файл предназначен для восстановления БД в случае её выхода из строя.
Для создания нового файла данных используется команда CREATE DATABASE, которая имеет следующий синтаксис:
CREATE DATABASE <Имя БД>
(Name=<Логическое имя>, FileName=<Имя файла>
[Size=<Нач.размер>,][Maxsize=<Макс.размер>,][FileGrowth=<Шаг>])
[LOG ON(Name=<Логическое имя>, FileName=<Имя файла>
[Size=<Нач.размер>,][Maxsize=<Макс.размер >,][FileGrowth=<Шаг>])
Здесь:
- Имя БД – имя создаваемой БД,
- Логическое имя – определяет логическое имя файла данных БД, по которому происходит обращение к файлу данных,
- Имя файла – определяет полный путь к файлу данных,
- Нач.размер – начальный размер файла данных в Мб,
- Макс.размер – максимальный размер файла данных в Мб,
- Шаг – шаг увеличения файла данных, либо в Мб либо в %.
Параметры в разделе LOG ON аналогичны параметрам в разделе CREATE DATABASE. Однако они определяют параметры журнала транзакций.
Управление базами данных при помощи команд языка T-SQL
В языке запросов T-SQL с БД возможны следующие действия:
1) отображение сведений о БД: EXEC sp_helpdb <Имя БД>;
2) изменение параметров БД: EXEC sp_dboption <Имя БД>, <Параметр>, <Значение>;
3) добавления новых файлов, удаление файлов и переименования файлов, входящих в БД:
ALTER DATABASE <Имя БД>
ADD FILE (<Параметры>)|
REMOVE FILE <Логическое имя файла>|MODIFY FILE (<Параметры>) где раздел ADD FILE добавляет файл, REMOVE FILE удаляет, а раздел MODIFY FILE изменяет параметры файла;
4) сжатие всей БД: DBCC SHRINKDATABASE <Имя БД>;
5) сжатие конкретного файла БД: DBCC SHRINKFILE <Логическое имя файла>;
6) переименование БД: EXEC SP_RENAMEDB <Имя БД>,<Новое имя БД>;
7) удаление БД: DROP DATABASE <Имя БД>.
Замечание: вышеперечисленные команды используют следующие параметры:
- <Имя БД> - имя БД с которой производится действие;
- <Параметр> - изменяемый параметр;
- <Значение> - новое значение изменяемого параметра;
- <Параметры> - параметры файла БД, аналогичные параметрам, используемым в команде CREATE DATABASE;
- <Логическое имя файла> - логическое имя файла, входящего в БД;
- <Новое имя БД> - новое имя БД.
Для запуска среды разработки «SQL Server Management Studio» в меню «Пуск» выбираем пункт «Программы\Microsoft SQL Server 2008\SQL Server Management Studio».
После запуска среды разработки появится окно подключения к серверу «Connect to Server» (см. рисунок 2.1).
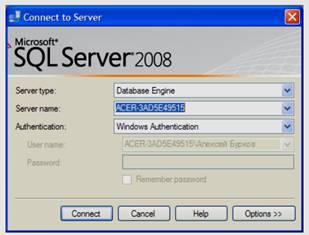
Рисунок 2.1 - Окно подключения к
серверу
В этом окне необходимо нажать кнопку «Connect»
Замечание: если при установке «Microsoft SQL Server 2008» был задан логин и пароль подключения к серверу, то перед нажатием кнопки «Connect», в выпадающем списке «Authentication» нужно выбрать «SQL Server Authentication», а затем необходимо ввести заданные при установке логин и пароль.
После нажатия кнопки «Connect» появится окно среды разработки «SQL Server Management Studio» (см. рисунок 2.2).
Данное окно имеет следующую структуру:
1) оконное меню содержит полный набор команд для управления сервером и выполнения различных операций;
2) панель инструментов содержит кнопки для выполнения наиболее часто производимых операций. Внешний вид данной панели зависит от выполняемой операции;
3) панель «Object Explorer» – обозреватель объектов. Обозреватель объектов – это панель с древовидной структурой, отображающая все объекты сервера, а также позволяющая производить различные операции как с самим сервером, так и с БД. Обозреватель объектов является основным инструментом для разработки БД;
4) рабочая область. В рабочей области производятся все действия с БД, а также отображается ее содержимое.
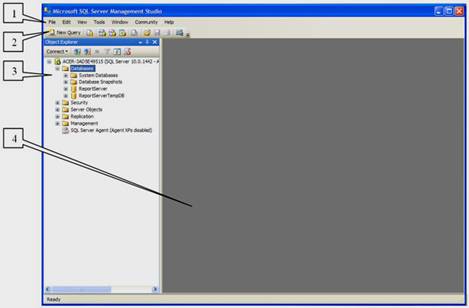
Рисунок 2.2
Замечание: в обозревателе объектов сами объекты находятся в папках. Чтобы открыть папку, необходимо щелкнуть по знаку «+» слева от изображения папки.
Перейдем непосредственно к созданию файла данных. Для этого в обозревателе объектов щелкните ПКМ на папке «Databases» (Базы данных) (см. рисунок. 2.2) и в появившемся меню выберите пункт «New Database» (Новая БД). Появится окно настроек параметров файла данных новой БД «New Database» (см. рисунок 2.3). В левой части окна настроек имеется список «Select a page». Этот список позволяет переключаться между группами настроек.
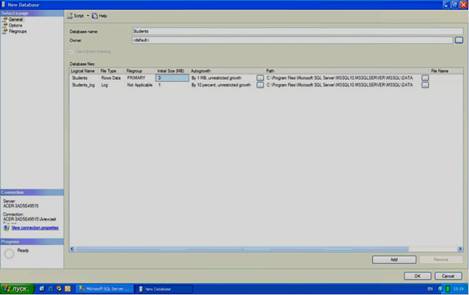
Рисунок 2.3
Настроим основные настройки «General». Для выбора основных настроек нужно просто щелкнуть мышью по пункту «General» в списке «Select a page». В правой части окна «New Database» появятся основные настройки.
Рассмотрим их более подробно. Верхней части окна расположено два параметра: «Database name» (Имя БД) и «Owner» (Владелец). Задайте параметр «Database name» равным «Students». Параметр «Owner» оставьте без изменений.
Под вышеприведенными параметрами в виде таблицы располагаются настройки файла данных и журнала транзакций. Таблица имеет следующие столбцы:
1) Logical Name – логическое имя файла данных и журнала транзакций. По этим именам будет происходить обращение к вышеприведенным файлам в БД. Можно заметить, что файл данных имеет то же имя что и БД, а имя файла журнала транзакций составлено из имени БД и суффикса «_log»;
2) File Type – тип файла. Этот параметр показывает, является ли файл файлом данных или журналом транзакций;
3) Filegroup – группа файлов, показывает к какой группе файлов относится файл. Группы файлов настраиваются в группе настроек «Filegroups»;
4) Initial Size (MB) – начальный размер файла данных и журнала транзакций в мегабайтах;
5) Autogrowth – автоувеличение размера файла. Как только файл заполняется информацией его размер автоматически увеличивается на величину, указанную в параметре «Autogrowth». Увеличение можно задавать как в мегабайтах так и в процентах. Здесь же можно задать максимальный размер файлов. Для изменения этого параметра надо нажать кнопку «…»;
6) Path – путь к папке, где хранятся файлы. Для изменения этого параметра также надо нажать кнопку «…»;
7) File Name – имена файлов. По умолчанию имена файлов аналогичны логическим именам. Однако файл данных имеет расширение «mdf», а файл журнала транзакций – расширение «ldf».
Замечание: для добавления новых файлов данных или журналов транзакций используется кнопка «Add», а для удаления - кнопка «Remove».
Рассмотрим второстепенные настройки файла данных. Для доступа к этим настройкам необходимо щелкнуть мышью по пункту «Options» в списке «Select a page». Появится следующее окно (см. рисунок. 2.4).
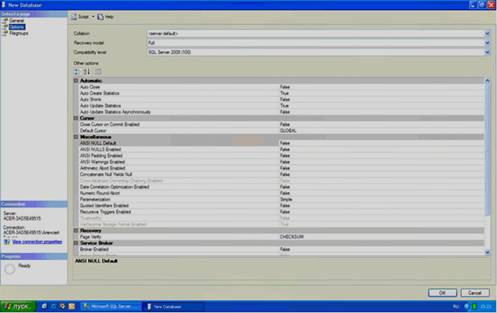
Рисунок 2.4
В правой части окна мы видим следующие настройки:
1) Collation – этот параметр отвечает за обработку текстовых строк, их сравнение, текстовый поиск и т.д. Рекомендуется оставить его как «<server default>». При этом данный параметр будет равен значению, заданному на вкладке «Collation», при установке сервера;
2) Recovery Model – модель восстановления. Данный параметр отвечает за информацию, предназначенную для восстановления БД, хранящуюся в файле транзакций. При наличии места на диске рекомендуется оставить этот параметр в значении «Full»;
3) Compatibility level – уровень совместимости, определяет совместимость файла данных с более ранними версиями сервера. Если планируется перенос данных на другую, более раннюю версию сервера, то ее необходимо указать в этом параметре;
4) Other options – второстепенные параметры. Данные параметры являются необязательными для изменения.
Рассмотрим последнюю группу настроек «Filegroups». Данная группа настроек отвечает за группы файлов. Для ее отображения в списке «Select a page» необходимо щелкнуть мышью по пункту «Options». Отобразятся настройки групп файлов (см. рисунок 2.5).
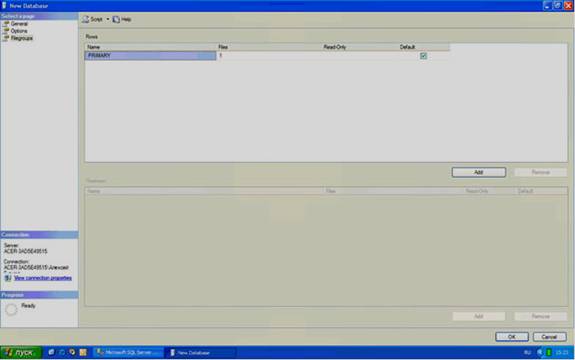
Рисунок 2.5
Группы файлов представлены в таблице «Rows» в правой части окна. Данная таблица имеет следующие столбцы:
1) Name – имя группы файлов.
2) Files – количество файлов входящих в группу.
3) Read only – файлы в группе будут только для чтения, их можно только просматривать, но нельзя изменять.
4) Default – группа по умолчанию. Все новые файлы данных будут входить в эту группу.
Замечание: как и в случае с файлами данных, для добавления новых групп используется кнопка «Add», а для - удаления кнопка «Remove».
Для переименования БД необходимо в обозревателе объектов щелкнуть по ней ПКМ и в появившемся меню выбрать пункт «Rename». Для удаления в это же меню выбираем пункт «Delete», для обновления – пункт «Refresh», а для изменения свойств описанных выше – пункт «Properties».
3 Лабораторная работа. Создание таблиц
Цель работы: изучить таблицы и типы данных полей, оОсвоить создание таблиц и основные операции с таблицами.
3.1 Рабочее задание
Создать и заполнять таблицы «Студенты», «Специальности», «Предметы» и «Оценки».
3.2 Методические указания к выполнению
Для создания таблиц в SQL Server в первую очередь необходимо сделать активной ту БД, в которой создается таблица. Для этого в новом запросе можно набрать команду: USE <Имя БД>, либо на панели инструментов необходимо выбрать в выпадающем списке рабочую БД. После выбора БД можно создавать таблицы.
Таблицы создаются командой:
CREATE TABLE <Имя таблицы>(<Имя поля1> <Тип1> [IDENTITY NULL|NOTNULL],<Имя поля2> <Тип2>, … ) Здесь:
<Имя таблицы> - имя создаваемой таблицы;
<Имя поля> - имена полей таблицы;
<Тип> - типы полей;
<IDENTITY NULL|NOT NULL> - поле счётчик.
Замечание: если имя поля содержит пробел, то оно заключается в квадратные скобки.
Для создания таблицы «Студенты», содержащую поля: Код студента (первичное поле связи, счётчик), Фамилия, Имя, Отчество, Адрес, Код специальности (вторичное поле связи), наберем следующий скрипт:
CREATE TABLE Студенты
([Код студента] Bigint Identity,
Фамилия Varchar(20),
Имя Varchar(15),
Отчество Varchar(20),
Адрес Varchar(100),
[Код специальности] Bigint)
Замечание: если необходимо создать вычислимое поле, то в команде Create Table у вычислимого поля вместо типа данных нужно указать выражение.
Пример: рассчитать средний балл студента по трем его оценкам.
CREATE TABLE Оценки
(ФИО Varchar(20),
Оценка1 int,Оценка2 int,Оценка3 int,[Средний балл] = (Оценка1+ Оценка2+ Оценка3)/3
Замечание: получение информации о таблице осуществляется применением команды: EXEC SP_HELP <Имя таблицы>. Удаление таблицы осуществляется командой: DROP TABLE <Имя таблицы>.
Заполнение таблиц
В SQL Server 2008 заполнение таблиц производится при помощи следующей команды:
INSERT <Имя таблицы> [(<Список полей>)]VALUES (<Значения полей>)
где <Имя таблицы> - таблица, куда вводим данные, (<Список полей>) – список полей, куда вводим данные, если не указываем, то подразумевается заполнение всех полей, в списке полей поля указываются через запятую, (<Значения полей>) – значение полей через запятую.
В качестве значений можно указать константу Default, то есть будет поставлено значение по умолчанию, либо можно подставить оператор Select. Здесь он используется как инструмент вычисления формул.
Пример: добавление записи, имеющей следующие значения полей ФИО = Иванов, Адрес = Москва, Код специальности = 5 в таблицу «Студенты».
INSERT Студенты (Фамилия, Имя, Отчество, Адрес, [Код специальности])
VALUES (‘Иванов’, ‘Антон’, ‘Антонович’, ‘Астана’, 5)
Удаление отдельных столбцов и отдельных строк из таблицы
Из таблицы можно удалить все столбцы, либо отдельные записи. Это осуществляется командой:
DELETE <Имя таблицы>[WHERE <Условие>]
где <Условие> - условие, которым удовлетворяют удаляемые записи, если условие не указаны, то удаляются все строки таблицы. Если условие указано, то удаляются записи поля, которых соответствуют условию.
Пример: Удалить записи из таблицы «Студенты», у которых поле Адрес = Астана.
DELETE СтудентыWHERE Адрес = ‘Астана’
Изменение данных в таблице.
Для этого используется следующая команда:
UPDATE <Имя таблицы>SET<Имя поля1> = <Выражение1>,[<Имя поля2> = <Выражение2>,]…[WHERE <Условие>]
Здесь <Имя поля1>, <Имя поля2> - имена изменяемых полей, <Выражение1>, <Выражение 2> - либо конкретные значения, либо NULL, либо операторы SELECT. Здесь SELECT применяется как функция.
<Условие> - условие, которым должны соответствовать записи, поля которых изменяем.
Пример: В таблице «Студенты» у студента Иванова поменять адрес Астана на Тараз, а код специальности вместо 5 поставить 3.
UPDATE СтудентыSETАдрес = ‘Тараз’, [Код специальности] = 3WHERE ФИО = ‘Иванов’
Замечание: в качестве выражения можно использовать математические формулы.
Например: SET [Средний балл]= (Оценка1+ Оценка2+ Оценка3)/3) вычисляет поле «Средний балл» как среднее полей «Оценка1», «Оценка2» и «Оценка3». При этом поля «Оценка1», «Оценка2» и «Оценка3» должны уже существовать и тип данных поля «Средний балл» должен быть с плавающей запятой (Например Real).
Замечание: если необходимо из таблицы удалить все записи, но сохранить ее структуру, для этого используют команду TRUNCATE TABLE <Имя таблицы> при этом все данные будут удалены, но сама таблица останется.
Все таблицы нашей БД находятся в подпапке «Tables» папки «Students» в окне обозревателя объектов (см. рисунок 3.1).
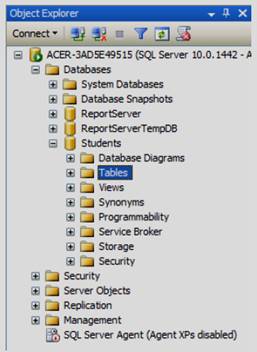
Рисунок 3.1
Создадим таблицу «Специальности». Для этого щелкните ПКМ по папке «Tables» и в появившемся меню выберите пункт «New Table». Появится окно создания новой таблицы (см. рисунок 3.2).
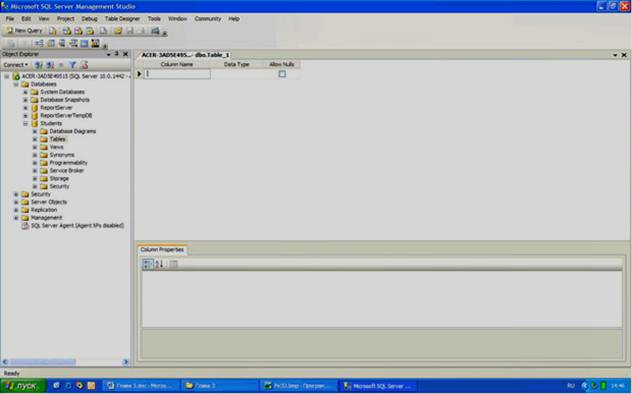
Рисунок 3.2
В правой части окна расположена таблица определения полей новой таблицы. Данная таблица имеет следующие столбцы:
1) Column Name – имя поля. Имя поля должно всегда начинаться с буквы и не должно содержать различных специальных символов и знаков препинания. Если имя поля содержит пробелы, то оно автоматически заключается в квадратные скобки.
2) Data Type – тип данных поля.
3) Allow Nulls – допуск значения Null. Если эта опция поля включена, то в случае незаполнения поля в него будет автоматически подставлено значение Null. То есть, поле необязательно для заполнения.
Замечание: под таблицей определения полей располагается таблица свойств выделенного поля «Column Properties». В данной таблице настраиваются свойства выделенного поля. Некоторые из них будут рассмотрены ниже.
Перейдем к созданию полей и настройке их свойств. В таблице определения полей задайте значения столбцов «Column Name», «Data Type» и «Allow Nulls», как показано на рисунке ниже (см. рисунок 3.3).
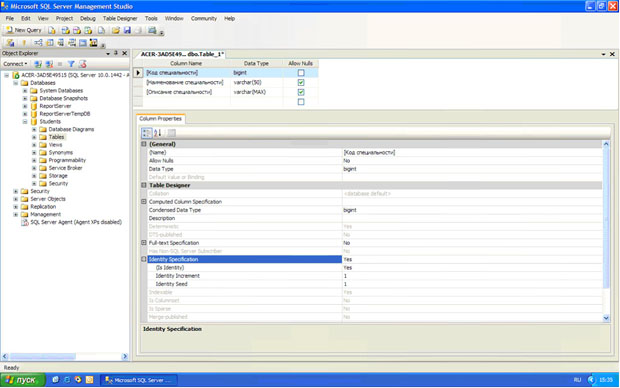
Рисунок 3.3
Из рисунка 3.3 следует, что наша таблица «Специальности» имеет три поля:
1) код специальности – числовое поле для связи с таблицей студенты,
2) наименование специальности – текстовое поле, предназначенное для хранения строк, имеющих длину не более 50 символов,
3) описание специальности – текстовое поле, предназначенное для хранения строк, имеющих неограниченную длину.
Замечание: так как поле «Код специальности» будет являться первичным полем связи в запросе, связывающем таблицы «Студенты» и «Специальности», то мы должны сделать его числовым счетчиком, то есть данное поле должно автоматически заполняться числовыми значениями. Более того, оно должно быть ключевым.
Сделаем поле «Код специальности» счетчиком. Для этого выделите поле, просто щелкнув по нему мышкой в таблице определения полей. В таблице свойств поля отобразятся свойства поля «Код специальности». Разверните группу свойств «Identity Specification» (Настройка особенности). Свойство «(Is Identity)» (Особенное) установите в значение «Yes» (Да). Задайте свойства «Identity Increment» (Увеличение особенности, шаг счетчика) и «Identity Seed» (Начало особенности, начальное значение счетчика) равными 1 (см. рисунок 3.3). Эти настройки показывают, что значение поля «Код специальности» у первой записи в таблице будет равным 1, у второй – 2 и т.д.
Теперь сделаем поле «Код специальности» ключевым полем. Выделите поле, а затем на панели инструментов нажмите кнопку с изображением ключа.
![]() .
.
В таблице определения полей, рядом с полем «Код специальности» появится изображение ключа, говорящее о том, что поле ключевое.
На этом настройку таблицы «Специальности» можно считать завершенной. Закройте окно создания новой таблицы, нажав кнопку закрытия
![]() .
.
в верхнем правом углу окна, над таблицей определения полей. Появится окно с запросом о сохранении таблицы (см. рисунок 3.4).

Рисунок 3.4
В этом окне необходимо нажать «Yes» (Да). Появится окно «Chose Name» (Задайте имя), предназначенное для определения имени новой таблицы (см. рисунок 3.5).
Рисунок 3.5
В этом окне задайте имя новой таблицы как «Специальности» и нажмите кнопку «Ok». Таблица «Специальности» отобразится в обозревателе объектов в папке «Tables» БД «Students» (см. рисунок 3.6).
Замечание: в обозревателе объектов таблица «Специальности» отображается как «dbo.Специальности». Префикс «dbo» обозначает, что таблица является объектом БД (Data Base Object). В дальнейшем при работе с объектами БД префикс «dbo» можно опускать.
Теперь перейдем к созданию таблицы «Предметы». Как и в случае с таблицей «Специальности», щелкните ПКМ по папке «Tables» и в появившемся меню выберите пункт «New Table». Создайте поля, представленные на рисунке ниже (см. рисунок 3.6).
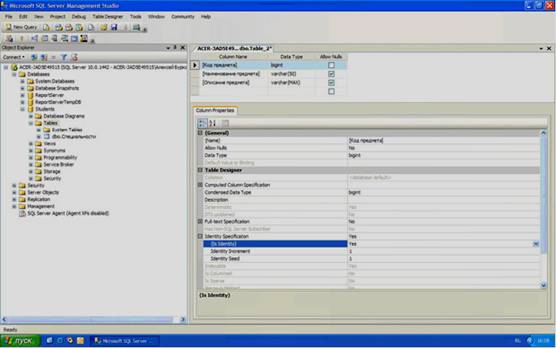
Рисунок 3.6
Сделайте поле «Код предмета» числовым счетчиком и ключевым полем, как это было сделано в таблице «Специальности». Закройте окно создания новой таблицы. В появившемся окне «Chose Name» задайте имя «Предметы» (см. рисунок 3.7).
Рисунок 3.7
Таблица «Предметы» появится в папке «Tables» в обозревателе объектов (см. рисунок 3.8).
После создания таблицы «Предметы» создайте таблицу «Студенты». Создайте новую таблицу аналогичную таблице, представленной на рисунке 3.8.
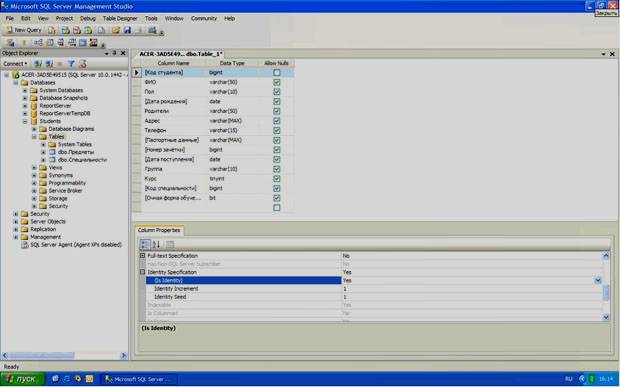
Рисунок 3.8
Рассматривая поля новой таблицы можно придти к следующим выводам:
- поле «Код студента» – это первичное поле для связи с таблицей оценки. Следовательно, данное поле необходимо сделать числовым счетчиком и ключевым (см. создание таблицы «Специальности» выше);
- поля «Фамилия», «Имя», «Отчество», «Пол», «Родители», «Адрес», «Телефон», «Паспортные данные» и «Группа» являются текстовыми полями различной длинны (для задания длинны выделенного текстового поля необходимо в таблице свойств выделенного поля установить свойство Length, равное максимальному количеству знаков текста вводимого в поле);
- поля «Дата рождения» и «Дата поступления» предназначены для хранения дат. Поэтому они имеют тип данных «date»;
- поле «Очная форма обучения» является логическим полем. В «Microsoft SQL Server 2008» такие поля должны иметь тип данных «bit»;
- поля «Номер зачетки» и «Курс» являются целочисленными. Единственным отличием является размер полей. Поле «Номер зачетки» предназначено для хранения целых чисел в диапазоне -263…+263 (тип данных «bigint»). Поле «Курс « предназначено для хранения целых чисел в диапазоне 0…255 (тип данных «tinyint»);
- поле «Код специальности» – это поле связи с таблицей «Специальности». Однако данное поле связи является вторичным, поэтому его можно сделать просто целочисленным, то есть, «bigint».
После определения полей таблицы «Студенты» закройте окно создания новой таблицы. В появившемся окне «Chose Name» задайте имя новой таблицы как «Студенты» (см. рисунок 3.9).
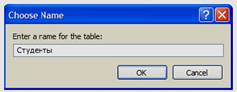
Рисунок 3.9
Таблица «Студенты» появится в папке «Tables» в обозревателе объектов (см. рисунок 3.10).
Создате таблицу «Оценки», для этого создайте поля, представленные на рисунке 3.10.
Таблица «Оценки» не имеет первичных полей связи. Следовательно, эта таблица не имеет ключевых полей. Поля «Код предмета 1», «Код предмета 2» и «Код предмета 3» являются вторичными полями связи, предназначенными для связи с таблицей «Предметы», поэтому они являются целочисленными (тип данных «bigint»). Поля «Дата экзамена 1», «Дата экзамена 2» и «Дата экзамена 3» предназначены для хранения дат (тип данных «date»). Поля «Оценка 1», «Оценка 2», и «Оценка 3» предназначены для хранения оценок. Задайте тип данных для этого поля «tinyint». Наконец, поле «Средний балл» хранит дробные числа и имеет тип «real».
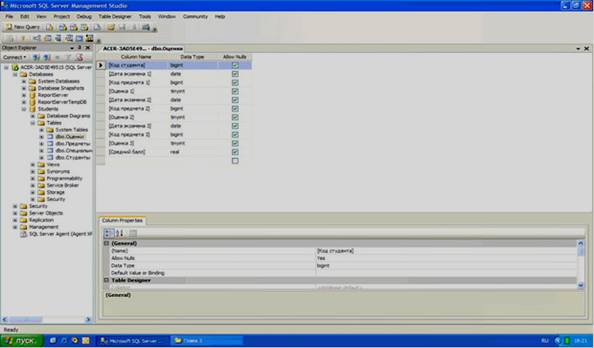
Рисунок 3.10
Закройте окно создания новой таблицы, задав имя таблицы как «Оценки» (см. рисунок 3.11).

Рисунок 3.11
После создания всех таблиц окно обозревателя объектов будет выглядеть так (см. рисунок 3.12).
Рисунок 3.12
Теперь рассмотрим операцию заполнения таблиц начальными данными.
Заполним таблицу «Специальности». Для заполнения этой таблицы в обозревателе объектов щелкните правой кнопкой мыши по таблице «Специальности» (см. рисунок 3.12) и в появившемся меню выберите пункт «Edit Top 200 Rows» (Редактировать первые 200 записей.). В рабочей области «Microsoft SQL Server Management Studio» проявится окно заполнения таблиц. Заполните таблицу «Специальности», как показано на рисунке 3.13.

Рисунок 3.13
Замечание: так как поле «Код специальности» является первичным полем связи и ключевым числовым счетчиком, то оно заполняется автоматически (заполнять его не нужно).
Закройте окно заполнения таблицы «Специальность», щелкнув по кнопке закрытия окна в верхнем правом углу, над таблицей
![]() .
.
После заполнения таблицы «Специальности» заполним таблицу «Предметы». Откройте ее для заполнения, как описано выше, и заполните, как показано на рисунке 3.14.
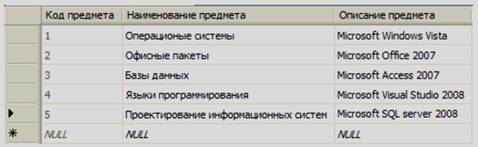
Рисунок 3.14
Закройте окно заполнения таблицы «Предметы» и перейдите к заполнению таблицы «Студенты». Откройте таблицу «Студенты» для заполнения и заполните ее.
Замечание: для заполнения дат в качестве разделителя можно использовать знак «.». Даты можно заполнять в формате «день.месяц.год».
Поле «Код специальности» является вторичным полем связи (для связи с таблицей «Специальности»). Следовательно, значения этого поля необходимо заполнять значениями поля «Код специальности» таблицы «Специальности». В нашем случая это значения от 1 до 5 (см. рисунок 3.13). Если у Вас коды специальностей в таблице «Специальности» имеют другие значения, то внесите их в таблицу «Студенты». По окончании заполнения, закройте окно заполнения таблицы «Студенты».
Наконец заполним таблицу «Оценки», как это показано на рисунке 3.16.
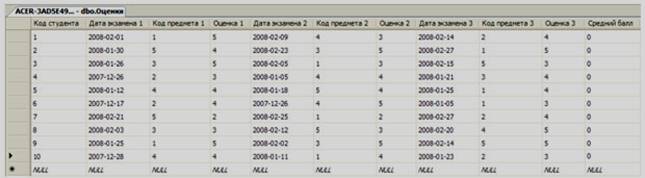
Рисунок 3.16
Поля с датами заполняются, как и в таблице «Студенты».
Замечание: Поля «Код предмета 1», «Код предмета 2» и «Код предмета 3» являются вторичными полями связи с таблицей «Предметы». Поэтому они должны быть заполнены значениями пол35я «Код предмета из этой таблицы», то есть значениями от 1 до 5 (см. рисунок 3.14).
Закройте окно заполнения таблицы «Оценки». На этом мы заканчиваем создание и заполнение таблиц нашей БД «Students».
3.3 Список контрольных вопросов
3.3.1 Описать общие схемы конфигурации сети.
3.3.2 Какие конфигурационные файлы по настройке сетей есть в системе и где они расположены?
3.3.3 Как подключиться к Wi-Fi-сети, например, кафедры КТ?
3.3.4 Как создать Wi-Fi-сеть?
4 Лабораторная работа. Создание представлений и фильтров.
Цель работы: изучить процесс создания запросов (представлений) и фильтров, понять процесс выполнения вычислений при помощи оператора SELECT.
4.1 Рабочее задание
1 Создать запрос «Запрос Студенты+Специальности».
2 Создать запрос «Запрос Студенты+Оценки.
3 Создать фильтры, отображающие студентов отдельных специальностей.
4.2 Методические указания к выполнению
Запросы предназначены для связи одной или нескольких таблиц, также они могут осуществлять отбор отдельных полей из таблицы и производить фильтрацию данных согласно условию, наложенному на одно или несколько полей, такие запросы называют фильтрами.
Для реализации запросов используют специальный язык запросов SQL (Standard Query Language).
В ИС запросы могут находиться как на стороне клиентского приложения, так и на стороне сервера. Если запрос хранится на стороне клиента, то он прописывается внутри объекта связи. В этом случае клиентское приложение не зависит от файла данных. Файл данных содержит только таблицы, поэтому мы легко можем модифицировать клиентское приложение, не затрагивая файл данных, но в этом случае запрос передается серверу через сеть, что может вызвать проблемы с безопасностью.
Если запрос хранится или выполняется на сервере, то сам запрос выступает в качестве компонента БД, вся передача информации происходит внутри файла данных, т.е. внутри самого сервера, клиентскому приложению только передаются результаты выполнения запроса. В этом случае обеспечивается высокая защита данных, но в случае изменения запроса придется менять сам файл данных.
Все запросы делятся на:
1) статические;
2) динамические
Структура статических запросов неизменна в ходе работы с программой, а динамические запросы могут меняться в зависимости от ситуации.
Замечание: обычно динамические запросы могут быть реализованы только при помощи запросов, выполняющиеся на стороне клиента. Если необходимо реализовать динамические запросы, которые выполняются на стороне сервера, то в этом случае необходимо использовать хранимые процедуры.
Хранимые процедуры – SQL запрос, хранимый на стороне сервера, и этот запрос имеет параметры, которые подставляются внутрь SQL кода. При вызове хранимой процедуры необходимо передавать внутрь ее значения параметра.
В основном запрос или хранимая процедура либо реализует связь между таблицами, либо осуществляет фильтрацию данных, некоторые SQL запросы также могут производить вычисления.
В случае связей между таблицами одна таблица всегда выступает первичной, а другая вторичной, связь происходит при помощи полей связи. При связи сопоставляются записи с одинаковыми значениями полей связи. Первичная таблица всегда заполняется первой, а ее поле связи заполняется автоматически (тип данных – счетчик). Вторичная таблица всегда заполняется после заполнения первичной таблицы, значения ее поля связи подставляется из значений поля связи первичной таблицы. Поля связи должны иметь одинаковый тип данных.
Существует четыре вида связи между таблицами:
1) одна к одной – одному полю в первичной таблице соответствует одно поле во вторичной таблице;
2) одна ко многим – одному полю в первичной таблице соответствует несколько полей во вторичной таблице;
3) многие к одной – нескольким полям в первичной таблице соответствует одно поле во вторичной таблице;
4) многие ко многим – одному полю в первичной таблице соответствует несколько полей во вторичной таблице и наоборот.
Запросы с первым видами связи называются простыми, а с остальными видами связи – сложными. Если в БД есть хотя бы две связанные таблицы, то БД – реляционной.
Чтобы создать запрос необходимо сделать активной БД, для которой создается запрос, затем в рабочей области редактора запросов создать запрос с помощью команды SELECT, имеющей следующий синтаксис:
SELECT [ALL|DISTINCT][TOP|PERCENT n]<Список полей>[INTO <Имя новой таблицы>][FROM <Имя таблицы >][WHERE <Условие>][GROUP BY <Поле>][ORDER BY <Поле > [ASC|DESC]]
[COMPUTE AVG|COUNT|MAX|MIN|SUM(<Выражение>)]
Здесь параметры ALL|DISTINCT показывают, какие записи обрабатываются: ALL обрабатывает все записи, DISTINCT только уникальные, удаляются повторения записей.
TOP n определяет, какое количество записей обрабатывают, если указан PERCENT, то n указывает процент от общего числа записей. <Список полей> - здесь указываются отображаемые поля из таблиц через запятую.
Замечания:
1) если имена отображаемых полей в разных таблицах не повторяются, то мы можем указывать только имена столбцов или полей без указания самих полей (ФИО, Должность). Если отображаются поля из разных таблиц с одинаковыми именами нужно указывать и имя таблицы <Имя поля>.<Имя таблицы>;
2) здесь же можно присваивать псевдонимы полям следующим образом <Имя поля> AS <Псевдоним>;
3) если необходимо вывести все поля из таблицы, то их можно заменить значком «*».
Раздел INTO. Если присутствует этот раздел, то на основе результатов запроса создается новая таблица. Параметр INTO - это имя новой таблицы.
Раздел FROM. Здесь указываются таблицы и запросы, через запятую, которые участвуют в новом запросе.
Замечание: в разделе FROM также можно задавать сложные связи, связь поля одной таблицы, с несколькими полями другой таблицы. В этом случае раздел FROM будет иметь следующий вид:
FROM <Таблица1> INNER JOIN <Таблица2> ON <Таблица1>.<поле1> оператор <Таблица2>.<поле2> …
Здесь устанавливается взаимосвязь таблицы 1 и таблицы2 по толю1 и полю2 в зависимости от оператора сравнения. Таких разделов INNER JOIN может быть сколько угодно.
Раздел WHERE. Данный раздел используют для создания простых запросов, в этом случае в качестве условия указываем связываемые поля, либо этот раздел используют для создания фильтров, здесь указывают условия отбора. В условиях отбора мы можем использовать стандартные логические операторы NOT, OR, AND.
Замечание: в своем стандартном виде запросы могут реализовывать только статичные фильтры, но не динамические. Для реализации динамических фильтров используются хранимые процедуры.
Раздел GROUP BY определяет поле для группировки записей в запросе.
Раздел ORDER BY определяет поле для сортировки записей в запросе. Если указан параметр ASC, то будет производиться сортировка по возрастанию, если DESC – по убыванию. По умолчанию используется сортировка по возрастанию.
Раздел COMPUTE позволяет в конце результатов выполнения запроса вывести некоторые итоговые вычисления по запросу. Возможны следующие виды вычислений: AVG – средняя параметра; COUNT – количество значений параметра не равных NULL; MAX и MIN – максимальные и минимальные значения параметра; SUM – сумма всех значений параметра, где <Выражение> - сам параметр. В качестве параметра обычно выступают какие-либо поля таблиц, участвующих в запросе.
Пример: данный запрос связывает две таблицы Сотрудники и Должности по полям Код. При своем выполнении он отображает первые 20 процентов сотрудников из обеих таблиц. Из таблицы сотрудники отображаются все поля, а из таблицы Должности - только поле должность. В конце результатов выводится количество отображенных сотрудников.
SELECT TOP 20 PERCENT *.Cотрудники, Должность.ДолжностиFROM Сотрудники, ДолжностиWHERE Код.Сотрудники = Код.ДолжностиCOMPUTE COUNT (ФИО.Сотрудники)
Пример: данный запрос из таблицы Операции выводит все записи, значение поля Месяц, у которых равняется «Май». Данные в результате группируются по полю операция и сортируются по сумме операции. В конце результатов запроса отображается общая сумма отобранных операций за май. Результаты данного запроса сохраняются в таблице «Сделки за май».
SELECT ALL Операция, СуммаINTO [Сделки за Май]FROM ОперацииWHERE Месяц = ‘Май’GROP BY ОперацияORDER BY Сумма
COMPUTE SUM (Сумма)
Замечание: в данном запросе при обозначении названия полей таблицы явно не указываются, так как использовалась только одна таблица.
Выполнение вычислений при помощи оператора SELECT. Встроенные функции.
Кроме связывания таблиц и отбора данных, оператор SELECT может использоваться для вычислений. В этом случае он имеет синтаксис:
SELECT <Выражение>
где <выражение> - какое-то математическое выражение или функция. Выражение имеет стандартный вид (как в Visual Basic), оно может включать в себя встроенные функции сервера.
Замечание: мы можем использовать встроенные функции и выражения в вычисляемых полях при создании таблиц.
В SQL Server существуют следующие встроенные функции разбития на группы.
Математические функции
Замечание: в качестве параметров функции будем указывать соответствующий им тип данных.
- ABC (numeric) – модуль числа;
- ACOS/ASIN/ATAN (Float) – арккосинус, арксинус, арктангенс в радианах;
- COS/SIN/TAN/COT (Float) – косинус, синус, тангенс, котангенс;
- CEILING (Numeric) – наименьшее целое, большее или равное параметру в скобках;
- DEGREES (Numeric) – преобразует радианы в градусы;
- EXP(Float) – экспонента, ех;
- FLOOR(Numeric) – наименьшее целое меньшее или равное выражению numeric;
- LOG(Float) – натуральный логарифм ln;
- LOG10(Float) – десятичный логарифм log10;
- PI () – число пи;
- POWER (Numeric,y) – возводит выражение Numeric в степень у;
- RADIANS (Numeric) – преобразует градусы в радианы;
- RAND () – генерирует случайное число типа данных Float, расположенное между нулем и единицей;
- ROUND (Numeric, Длина) – округляет выражение Numeric до заданной Длины (количество знаков после запятой);
- SIGN (Numeric) – выводит знак числа +/- или ноль;
- SQUARE (Float) – вычисляет квадрат числа Float;
- SQRT (Float) – вычисляет квадратный корень числа Float.
Примеры использования математических функций:
- SELECT ABC(-10) результат 10
- SELECT SQRT (16) результат 4
- SELECT ROUND (125.85,0) результат 126
- SELECT POWER (2,4) результат 16
Строковые функции
Строковые функции позволяют производить операции с одной или несколькими строками:
- 'Строка1'+ 'Строка2' присоединяет Строку1 к Строке2;
- ASCII(Char) возвращает ASCII код с самого левого символа выражения Char;
- CHAR(Int) выводит символ соответствующий ASCII коду в выражении Int;
- CHARINDEX(Образец, Выражение) выводит позицию Образца выражения, то есть где находится Образец в Выражении;
- DIFFERENCE(Выражение1, Выражение2) сравнивает два выражения, выводит числа от 0 до 4: 0 – выражения абсолютно различны; 4 – выражения абсолютно идентичны. Оба выражения типа данных Char;
- LEFT(Char, Int) выводит из строки Char Int символов слева;
- RIGHT(Char, Int) выводит из строки Char Int символов справа;
- LTRIM(Char) удаляет из строки Char пробелы слева;
- RTRIM(Char) удаляет из строки Char пробелы справа;
- WCHAR(Int) выводит выражение Int в формате Unicode;
- REPLACE(Строка1, Строка2, Строка3) меняет в Строке1 все элементы Строка2 на элементы Строка3;
- REPLICATE(Char, Int) повторяет строку Char Int раз;
- REVERSE(Сhar) производит инверсию строки Char, то есть располагает символы в обратном порядке;
- SPACE(Int) выводит Int пробелов;
- STR(Float) переводит число Float в строку;
- STUFF(Выражение1, Начало, Длина, Выражение2) удаляет из Выражения1 начиная с позиции символа Начало количество символов, равное параметру Длина, вместо них подставляет Выражение2;
- SUBSTRING(Выражение, Начало, Длина) из Выражения выводится строка заданной Длины начиная с позиции Начало;
- UNICODE(Char) выводит код в формате Unicode первого символа в строке Char;
- LOWERC(Char) переводит строку Char в маленькие буквы;
- UPPER(Char) переводит строку Char в заглавные буквы.
Примеры применения строковых функций:
- SELECT ASCII('G') - результат 71,
- SELECT LOWER(‘ABC’) - результат abc,
- SELECT Right(‘ABCDE,3’) - результат CDE,
- SELECT REVERCE('МИР') - результат РИМ.
Замечание. во всех строковых функциях значения выражения типа Char заключаются в одинарные кавычки.
Функции дат
В некоторых функциях дат используется так называемая часть дат, которая кодируется специальными символами:
- dd – число дат (от 1 до 31);
- dy – день года (число от 1 до 366);
- hh – значение часа (0-23);
- ms – значение секунд (от 0 до 999);
- mi – значение минут (0-59);
- qq – значение (1-4);
- mm – значение месяцев (1-12);
- ss – значение секунд (0-59);
- wk – значение номеров недель в году;
- dw – значение дней недели, неделя начинается с воскресенья (1-7);
- yy – значение лет (1753 -999).
Функции дат предназначены для работы с датами или времени. Существуют несколько следующие функции дат:
- DATEADD(часть, число, date) добавляет к дате date часть даты увеличенное на число;
- DATEDIFF(часть, date1, date2) выводит количество частей даты между date1 и date2;
- DATENAME(часть, date) выводит символьное значение частей даты к заданной дате (название дней недели);
- DATEPART(часть, date) выводит числовое значение части даты из заданной даты (номер месяца);
- DAY(date) выводит количество дней в заданной дате;
- MONTH (date) выводит количество месяцев в заданной дате;
- YEAR(date) выводит количество лет в заданной дате;
- GETDATE() выводит текущую дату установленную на компьютере;
Замечание: даты выводятся в Американском формате: месяц/день/год.
Примеры функции работ с датами:
- SELECT DATEADD(dd,5,11/20/07) - результат Nov/25/2007;
- SELECT DATEDIFF(dd,11/20/07, 11/25/07) – результат 5 дней;
- SELECT DATENAME(mm, 11/20/07) - результат November;
- SELECT DATEPART(mm, 11/20/07) - результат 11.
Замечание: в выражениях оператора SELECT можно использовать операции сравнения. В результате будет либо истина TRUE, либо ложь FALSE. Можно использовать следующие операторы: =, <, >, >=, <=, <>, !<(не меньше), !>(не больше), !=(не равно). Приоритет операции задается круглыми скобками.
Системные функции предназначены для получения информации о базе данных и ее содержимом. В SQL сервере существуют следующие системные функции:
- COL_LENGTH(таблица, поле) выводит ширину поля;
- DATALENGTH(выражение) выводит длину выражения;
- GETAHSINULL(имя БД) выводит допустимо или недопустимо использовать в БД значение NULL;
- IDENTINCR(таблица) выводит шаг увеличения поля счетчика в таблице;
- IDENT_SEED(таблица) выводит начальное значение счетчиков в таблице;
- ISDATE(выражение) выводит единицу, если выражение является датой и ноль, если не является;
- ISNUMERIC(выражение) выводит единицу, если выражение является числовым и ноль, если не числовым;
- NULIFF(выражение1, выражение2) выводит ноль если выражение1 равно выражению 2.
Агрегатные функции позволяют вычислять итоговые значения по полям таблицы:
- AVG(поле) – выводит среднее значение поля;
- COUNT(*) – выводит количество записей в таблице;
- COUNT(поле) – выводит количество всех значений поля;
- MAX(поле) – выводит максимальное значение поля;
- MIN(поле) – выводит минимальное значение поля;
- STDEV(поле) – выводит средне квадратичное отклонение всех значений поля;
- STDEVP(поле) – выводит среднеквадратичное отклонение различных значений поля;
- SUM(поле) – суммирует все значений поля;
- TOP n [Percent] – выводит n первых записей из таблица, либо n% записей из таблицы;
- VAR(поле) – выводит дисперсию всех значений поля;
- VARP(поле) – выводит дисперсию всех различных значений поля.
Примеры использования агрегатных функций:
- SELECT AVG(возраст) FROM Студенты – выводит средний возраст студента из таблицы «Студенты».
- SELECT COUNT(ФИО) FROM Студенты – выводит количество различных ФИО из таблицы «Студенты».
- SELECT Top 100 * FROM Студенты – выводит первые 100 студентов из таблицы «Студенты».
В обозревателе объектов «Microsoft SQL Server 2008» все запросы БД находятся в папке «Views» ( см. рисунок 4.1).
Рисунок 4.1
Создадим запрос «Запрос Студенты+Специальности», связывающий таблицы «Студенты» и «Специальности» по полю связи «Код специальности». Для создания нового запроса необходимо в обозревателе объектов в БД «Students» щелкнуть ПКМ по папке «Views», затем в появившемся меню выбрать пункт «New View». Появится окно «Add Table» (Добавить таблицу), предназначенное для выбора таблиц и запросов, участвующих в новом запросе (см.рисунок 4.2).
Рисунок 4.2
Добавим в новый запрос таблицы «Студенты» и «Специальности». Для этого в окне «Add Table» выделите таблицу «Студенты» и нажмите кнопку «Add» (Добавить). Аналогично добавьте таблицу «Специальности». После добавления таблиц участвующих в запросе, закройте окно «Add Table». Появится окно конструктора запросов (см. рисунок 4.3).
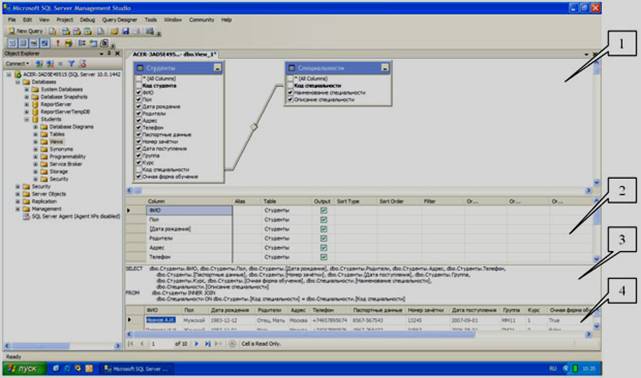
Рисунок 4.3
Замечание: окно конструктора запросов состоит из следующих панелей:
1) Схема данных отображает поля таблиц и запросов, участвующих в запросе, позволяет выбирать отображаемые поля, позволяет устанавливать связи между участниками запроса по специальным полям связи. Эта панель включается и выключается следующей кнопкой на панели инструментов
![]() .
.
2) Таблица отображаемых полей показывает отображаемые поля (столбец «Column»), позволяет задавать им псевдонимы (столбец «Alias»), позволяет устанавливать тип сортировки записей по одному или нескольким полям (столбец «Sort Type»), позволяет задавать порядок сортировки (столбец «Sort Order»), позволяет задавать условия отбора записей в фильтрах (столбцы «Filter» и «Or…»). Также эта таблица позволяет менять порядок отображения полей в запросе. Эта панель включается и выключается следующей кнопкой на панели инструментов
![]() .
.
3) Код SQL код создаваемого запроса на языке T-SQL. Эта панель включается и выключается следующей кнопкой на панели инструментов
![]() .
.
4) Результат показывает результат запроса после его выполнения. Эта панель включается и выключается следующей кнопкой на панели инструментов
![]() .
.
Замечание: если необходимо снова отобразить окно «Add Table» для добавления новых таблиц или запросов, то для этого на панели инструментов «Microsoft SQL Server 2008» нужно нажать кнопку
![]() .
.
Замечание: если необходимо удалить таблицу или запрос из схемы данных, то для этого нужно щелкнуть ПКМ и в появившемся меню выбрать пункт «Remove» (Удалить).
Теперь перейдем к связыванию таблиц «Студенты» и «Специальности» по полям связи «Код специальности». Чтобы создать связь, необходимо в схеме данных перетащить мышью поле «Код специальности» таблицы «Специальности» на такое же поле таблицы «Студенты». Связь отобразится в виде ломаной линии, соединяющей эти два поля связи (см. рисунок 4.3).
Замечание: если необходимо удалить связь, то для этого необходимо щелкнуть по ней ПКМ и в появившемся меню выбрать пункт «Remove».
После связывания таблиц (а также при любых изменениях в запросе) в области кода T-SQL будет отображаться T-SQL код редактируемого запроса.
Определим поля, отображаемые при выполнении запроса. Отображаемые поля обозначаются галочкой (слева от имени поля) на схеме данных, а также отображаются в таблице отображаемых полей. Чтобы сделать поле отображаемым при выполнении запроса, необходимо щелкнуть мышью по пустому квадрату (слева от имени поля) на схеме данных, в квадрате появится галочка.
Замечание: если необходимо сделать поле невидимым при выполнении запроса, то нужно убрать галочку, расположенную слева от имени поля на схеме данных. Для этого просто щелкните мышью по галочке. Если необходимо отобразить все поля таблицы, то необходимо установить галочку слева от пункта «* (All Columns)» (Все поля), принадлежащего соответствующей таблице на схеме данных.
Определите отображаемые поля нашего запроса, как это показано на рисунке 4.3 (Отображаются все поля, кроме полей с кодами, то есть полей связи).
На этом настройку нового запроса можно считать законченной. Перед сохранением запроса проверим его работоспособность, выполнив его. Для запуска запроса на панели инструментов нажмите кнопку
![]() .
.
Либо щелкните ПКМ в любом месте окна конструктора запросов и в появившемся меню выберите пункт «Execute SQL» (Выполнить SQL). Результат выполнения запроса появиться в виде таблицы в области результата (см. рисунок 4.3). Если запрос выполняется правильно, то необходимо сохранить. Для сохранения запроса закройте окно конструктора запросов, щелкнув мышью по кнопке закрытия расположенной в верхнем правом углу окна конструктора (над схемой данных). Появится окно с вопросом о сохранении запроса (см. рисунок 4.4).
![]()
Рисунок 4.4
В данном окне необходимо наддать кнопку «Yes» (Да). Появится окно «Choose Name» (Выберите имя) (см. рисунок 4.5).
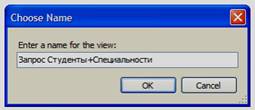
Рисунок 4.5
В данном окне зададим имя нового запроса «Запрос Студенты+Специальности» и нажмем кнопку «Ok». Запрос появится в папке «Views» БД «Students» в обозревателе объектов (см. рисунок 4.6).
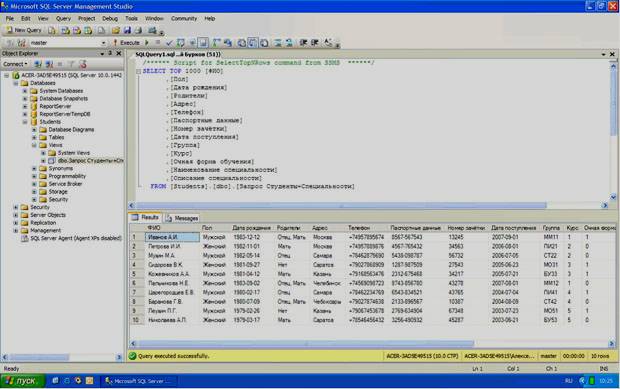
Рисунок 4.6
Для проверки работоспособности созданного запроса вне конструктора запросов запустим вновь созданный запрос «Запрос Студенты + Специальности» без использования конструктора запросов. Для выполнения уже сохраненного запроса необходимо щелкнуть ПКМ по запросу и в появившемся меню выбрать пункт «Select top 1000 rows» (Отобразить первые 1000 записей). Результат представлен на рисунке 4.6. Перейдем к созданию запроса «Запрос Студенты+Оценки». В обозревателе объектов в БД «Students» щелкните ПКМ по папке «Views», затем в появившемся меню выберите пункт «New View». Появиться окно «Add Table» (см. рисунок 4.2).
В запросе «Запрос Студенты+Оценки» мы связываем таблицы «Студенты» и «Оценки» по полям связи «Код студента». Следовательно, в окне «Add Table» в новый запрос добавляем таблицы «Студенты» и «Оценки». Более того, в данном запросе таблица «Оценки» связывается с таблицей «Предметы» не по одному полю, а по трем полям, то есть поля «Код предмета 1», «Код предмета 2» и «Код предмета 3» таблицы «Оценки» связаны с полем «Код предмета» таблицы «Предметы». Поэтому добавим в запрос три экземпляра таблицы «Предметы» (по одному экземпляру для каждого поля связи таблицы оценки). В итоге в запросе должны участвовать таблицы «Студенты», «Оценки» и три экземпляра таблицы «Предметы» (в запросе они будут называться «Предметы», «Предметы_1» и «Предметы_2»). После добавления таблиц закройте окно «Add Table», появится окно конструктора запросов.
В окне конструктора запросов установите связи между таблицами и определите отображаемые поля, как показано на рисунке 4.7.

Рисунок 4.7
Теперь поменяем порядок отображаемых полей в запросе, для этого в таблице отображаемых полей необходимо перетащить поля мышью вверх или вниз за заголовок строки таблицы (столбец перед столбцом «Column»). Расположите отображаемые поля в таблице отображаемых полей и задайте псевдонимы для каждого из полей, просто записав псевдонимы в столбце «Alias» таблицы отображаемых полей, как на рисунке 4.8.
Проверьте работоспособность нового запроса, выполнив его. Обратите внимание на то, что реальные названия полей были заменены их псевдонимами. Закройте окно конструктора запросов. В появившемся окне «Choose Name» задайте имя нового запроса «Запрос Студенты+Оценки» (см. рисунок 4.9).

Рисунок 4.8
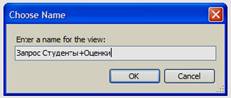
Рисунок 4.9
Проверьте работоспособность нового запроса вне конструктора. Для этого запустите запрос. Результат выполнения запроса «Запрос Студенты+Оценки» должен выглядеть, как на рисунке 4.10.
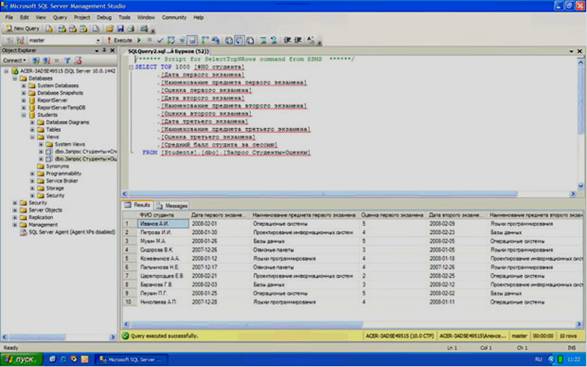
Рисунок 4.10
Рассмотрим создание фильтров. На основе запроса «Запрос Студенты+Специальности» создадим фильтры, отображающие студентов отдельных специальностей. Создайте новый запрос. Так как он будет основан на запросе «Запрос Студенты+Специальности», то в окне «Add Table» перейдите на вкладку «Views» и добавьте в новый запрос «Запрос Студенты+Специальности» (см. рисунок 4.11). Затем закройте окно «Add Table».
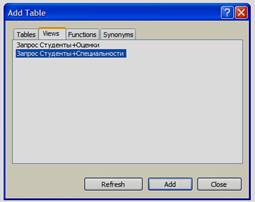
Рисунок 4.11
В появившемся окне конструктора запросов определите в качестве отображаемых полей все поля запроса «Запрос Студенты+Специальности» (см. рисунок 4.12).
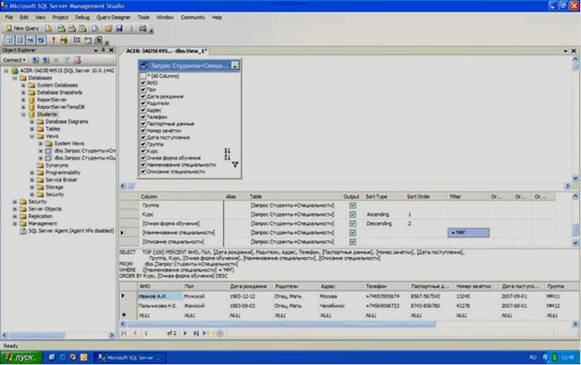
Рисунок 4.12
Замечание: для отображения всех полей запроса в данном случае мы не можем использовать пункт «* (All Columns)» (Все поля). Так как в этом случае мы не можем устанавливать критерий отбора записей в фильтре, а также невозможно установить сортировку записей.
Установим критерий отбора записей в фильтре. Пусть наш фильтр отображает только студентов имеющих специальность «ММ». Для определения условия отбора записей в таблице отображаемых полей в строке, соответствующей полю, на которое накладывается условие, в столбце «Filter», необходимо задать условие. В нашем случае условие накладывается на поле «Наименование специальности». Следовательно, в строке «Наименование специальности», в столбце «Filter» нужно задать следующее условие отбора «='ММ'» (см. рисунок 4.12).
Настроим сортировку записей в фильтре. Пусть при выполнении фильтра сначала происходит сортировка записей по возрастанию по полю «Очная форма обучения», а затем по убыванию по полю «Курс». Для установки сортировки записей по возрастанию, в таблице определяемых полей, в строке для поля «Очная форма обучения», в столбце «Sort Type» (Тип сортировки), задайте «Ascending» (По возрастанию), а в строке для поля «Курс» задайте «Descending» (По убыванию). Для определения порядка сортировки для поля «Очная форма обучения» в столбце «Sort Order» (Порядок сортировки) поставьте 1, а для поля «Курс» поставьте 2 (см. рисунок 4.12), то есть, при выполнении запроса записи сначала сортируются по полю «Очная форма обучения», а затем - по полю «Курс».
Замечание: после установки условий отбора и сортировки записей на схеме данных напротив соответствующих полей появятся специальные значки. Значки
![]() и
и ![]()
обозначают сортировку по возрастанию и убыванию, а значок
![]()
показывает наличие условия отбора.
После установки сортировки записей в фильтре проверим его работоспособность, выполнив его. Результат выполнения фильтра должен выглядеть как на рисунке 4.12. Закройте окно конструктора запросов. В качестве имени нового фильтра в окне «Choose Name» задайте «Фильтр ММ» (см. рисунок 4.13) и нажмите кнопку «Ok».
Рисунок 4.13
Фильтр «Фильтр ММ» появится в обозревателе объектов. Выполните созданный фильтр вне окна конструктора запросов. Результат должен быть таким же, как на рисунке 4.14.
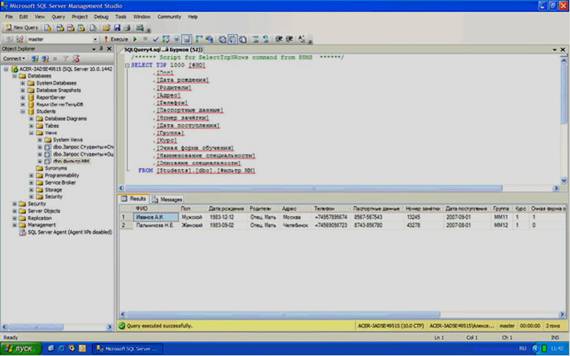
Рисунок 4.14
Самостоятельно создайте фильтры для отображения других специальностей. Данные фильтры создаются аналогично фильтру «Фильтр ММ» (смотри выше). Единственным отличием является условие отбора, накладываемое на поле «Наименование специальности», оно должно быть не «='ММ'», а «='ПИ'», «='СТ'», «='МО'» или «='БУ'». При сохранении фильтров задаем их имена соответственно их условиям отбора, то есть «Фильтр ПИ», «Фильтр СТ», «Фильтр МО» или «Фильтр БУ». Проверьте созданные фильтры на работоспособность.
Теперь на основе запроса «Запрос Студенты+Специальности» создадим фильтры, отображающие студентов, имеющих отдельных родителей. Для начала создадим фильтр для студентов, из родителей только «Отец». Создайте новый запрос и добавьте в него запрос «Запрос Студенты+Специальности» (см. рисунок 4.11). После закрытия окна «Add Table» сделайте отображаемыми все поля запроса (см. рисунок 4.15).
В таблице отображаемых полей в строке для поля «Родители», в столбце «Filter», задайте условие отбора, равное «='Отец'». Проверьте работу фильтра, выполнив его. В результате выполнения фильтра окно конструктора запросов должно выглядеть, как на рисунке 4.15.

Рисунок 4.15
Закройте окно конструктора запросов. В окне «Choose Name» задайте имя нового фильтра как «Фильтр Отец» (см. рисунок 4.16).
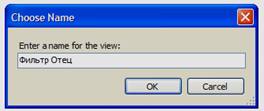
Рисунок 4.16
Выполните фильтр «Фильтр Отец» вне конструктора запросов. Результат должен быть аналогичен рисунку 4.17.
Создайте фильтры для отображения студентов с другими вариантами родителей. Данные фильтры создаются аналогично фильтру «Фильтр Отец» (смотри выше). Единственным отличием является условие отбора, накладываемое на поле «Родители», оно должно быть не «='Отец'», а «='Мать'», «='Отец, Мать'» или «='Нет'». При сохранении фильтров задаем их имена соответственно их условиям отбора, то есть «Фильтр Мать», «Фильтр Отец и Мать» или «Фильтр Нет родителей». Проверьте созданные фильтры на работоспособность.
Наконец создадим фильтры для отображения студентов очной и заочной формы обучения. Начнем с очной формы обучения. Создайте новый запрос и добавьте в него запрос «Запрос Студенты+Специальности». Как и ранее, сделайте все поля запроса отображаемыми (см. рисунок 4.18).
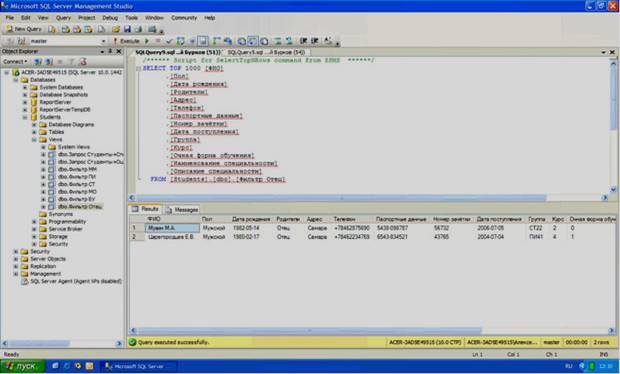
Рисунок 4.17
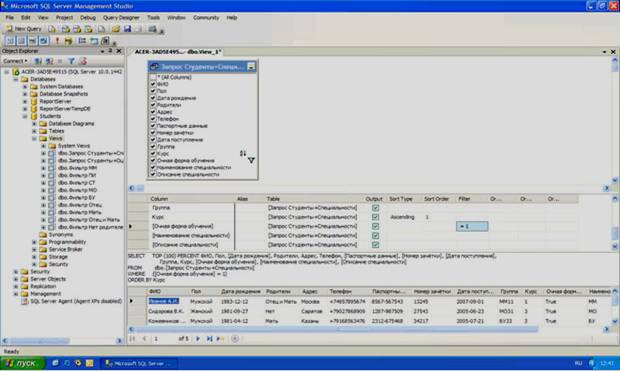
Рисунок 4.18
В таблице отображаемых полей в столбце «Filter», в строке для поля «Очная форма обучения» установите условие отбора, равное «=1».
Замечание: Поле «Очная форма обучения» является логическим полем, оно может принимать значения «True» или «False». В качестве синонимов этих значений можно использовать 1 и 0 соответственно.
Установите сортировку по возрастанию, по полю курс, задав в строке для этого поля, в столбце «Sort Type» значение «Ascending». Проверьте работу фильтра, выполнив его. После выполнения фильтра окно конструктора запросов должно выглядеть точно так же, как на рисунке 4.18.
Закройте окно конструктора запросов. Сохраните фильтр под именем «Фильтр очная форма обучения» (см. рисунок 4.19).
Рисунок 4.19
После появления фильтра «Фильтр очная форма обучения» в обозревателе объектов выполните фильтр вне окна конструктора запросов. Результат выполнения фильтра «Фильтр очная форма обучения» представлен на рисунке 4.20.
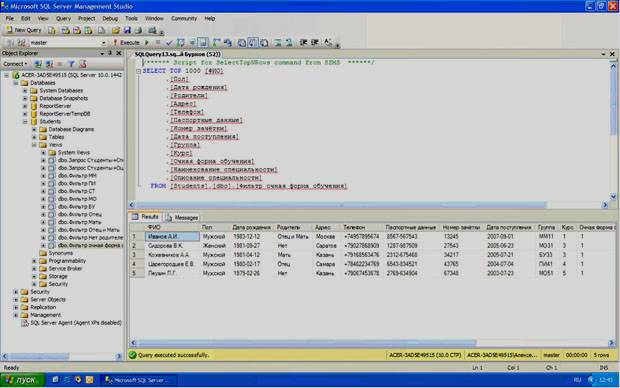
Рисунок 4.20
Самостоятельно создайте фильтр для отображения студентов заочной формы обучения. Данный фильтр создается точно также как и фильтр «Фильтр очная форма обучения». Единственным отличием является условие отбора, накладываемое на поле «Очная форма обучения», оно должно быть не «=1», а «=0». При сохранении фильтра задайте его имя как «Фильтр заочная форма обучения». Проверьте созданный фильтр на работоспособность.
5 Лабораторная работа. Создание динамических запросов при помощи хранимых процедур.
Цель работы: изучить процесс создания динамических запросов при помощи хранимых процедур.
5.1 Рабочее задание
1 Создать процедуру, вычисляющую среднее трех чисел.
2 Создать хранимую процедуру для отбора студентов из таблицы студенты по их «ФИО».
5.2 Методические указания к выполнению
Замечание: в SQL сервере хранимые процедуры реализуют динамические запросы, выполняемые на стороне сервера.
Рассмотрим создание хранимых процедур при помощи команд языка SQL. Чтобы отобразить хранимые процедуры рабочей БД панели «Object Explorer», нужно выделить пункт «Stored Procedures». Чтобы создать новую процедуру при помощи команд языка SQL, нужно щелкнуть ЛКМ по кнопке
![]()
на панели инструментов. В рабочей области окна сервера появится вкладка SQLQuery1.sql, где нужно набрать код новой процедуры, который имеет следующий синтаксис:
CREATE PROCEDURE <Имя процедуры>
[@<Параметр1> <Тип1>[=<Значение1>],
@<Параметр2> <Тип2>[=<Значение2>], …]
[WITH ENCRYPTION]
AS <Команды SQL>
Здесь:
- Имя процедуры – имя создаваемой хранимой процедуры.
- Параметр1, Параметр2, … - параметры передаваемые в процедуру.
- Значение1, Значение2, … - значения параметров по умолчанию.
- Тип1, Тип2, … - типы данных параметров.
- WITH ENCRYPTION – включает шифрование данных.
- Команды SQL – SQL запрос, который выполняется при запуске процедур.
Замечание: SQL запрос включает в себя параметры, если параметры сравниваются с какими-то полями или выражениями, то они должны иметь точно такой же тип данных, как эти поля или выражения.
Замечание: после создания процедура помещается в раздел Stored Procedures текущей БД на панели «Object Explorer». Если дважды щелкнуть по процедуре ЛКМ, то она откроется для редактирования на вкладке «SQLQuery».
Чтобы посмотреть информацию о хранимой процедуре, необходимо выполнить команду:
EXEC SP_HELPTEXT <Имя процедуры>
Хранимые процедуры могут быть запущены следующей командой
EXEC <Имя процедуры> [<Параметр1>, <Параметр2>, …]
Здесь:
- <Имя процедуры> - имя выполняемой процедуры;
- Параметр1, Параметр2, … - значение параметров.
Пример: создание хранимой процедуры, который выводит имя студентов, у которых средний балл больше заданной величины:
CREATE PROCEDURE СрБАЛЛ
@X Real
AS
SELECT *
FROM Студенты
WHERE
(Оценка1+ Оценка2+ Оценка3)/3>@X
Команда вызова вышенабранной процедуры выглядит следующим образом:
EXEC СрБАЛЛ 4
Команда выводит всех студентов, у которых средний балл больше 4.
Для работы с хранимыми процедурами в обозревателе объектов необходимо выделить папку «Programmability/Stored Procedures» базы данных «Students» (см. рисунок 5.1).
Рисунок 5.1
Создадим процедуру, вычисляющую среднее трех чисел. Для создания новой хранимой процедуры щелкните ПКМ по папке «Stored Procedures» (см. рисунок 5.1) и в появившемся меню выберите пункт «New Stored Procedure». Появиться окно кода новой хранимой процедуры (см. рисунок 5.2).
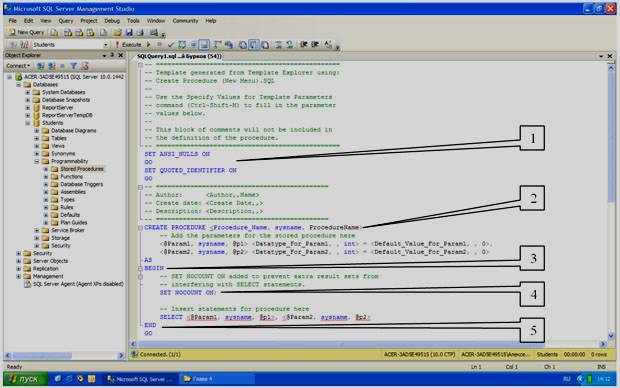
Рисунок 5.2
Хранимая процедура имеет следующую структуру (см. рисунок 5.2):
1) область настройки параметров синтаксиса процедуры. Позволяет настраивать некоторые синтаксические правила, используемые при наборе кода процедуры. В нашем случае это:
- SET ANSI_NULLS ON включает использование значений NULL (Пусто) в кодировке ANSI,
- SET QUOTED_IDENTIFIER ON включает возможность использования двойных кавычек для определения идентификаторов;
2) область определения имени процедуры (Procedure_Name) и параметров передаваемых в процедуру (@Param1, @Param2). Определение параметров имеет следующий синтаксис:
@<Имя параметра> <Тип данных> = <Значение по умолчанию>
Параметры разделяются между собой запятыми;
3) начало тела процедуры, обозначается служебным словом «BEGIN»;
4) тело процедуры, содержит команды языка программирования запросов T-SQL;
5) конец тела процедуры, обозначается служебным словом «END».
Замечание: в коде зеленым цветом выделяются комментарии. Они не обрабатываются сервером и выполняют функцию пояснений к коду. Строки комментариев начинаются с подстроки “–“. Далее в коде мы не будем отображать комментарии, они будут свернуты. Слева от раздела с комментариями будет стоять знак “+”, щелкнув по которому можно развернуть комментарий.
Наберем код процедуры вычисляющей среднее трех чисел, как это показано на рисунке 5.3.
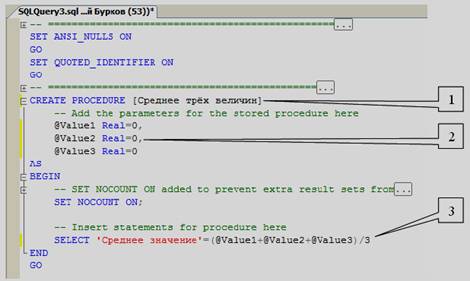
Рисунок 5.3
Рассмотрим код данной процедуры более подробно (см. рисунок 5.3):
1) CREATE PROCEDURE [Среднее трех величин] определяет имя создаваемой процедуры как «Среднее трех величин»;
2) @Value1 Real = 0, @Value2 Real = 0, @Value3 Real = 0 определяют три параметра процедуры Value1, Value2 и Value3. Данным параметрам можно присвоить дробные числа (Тип данных Real), значения по умолчанию равны 0;
3) SELECT 'Среднее значение'=(@Value1+@Value2+@Value3)/3 вычисляет среднее и выводит результат с подписью «Среднее значение».
Остальные фрагменты кода рассмотрены выше (см. рисунок 10.2).
Для создания процедуры, выполним вышеописанный код, нажав кнопку
![]() .
.
(Выполнить) на панели инструментов. В нижней части окна с кодом появиться сообщение «Command(s) completed successfully.». Закройте окно с кодом, щелкнув мышью по кнопке закрытия
![]() .
.
расположенной в верхнем правом углу окна с кодом процедуры.
Проверим работоспособность созданной хранимой процедуры. Для запуска хранимой процедуры необходимо создать новый пустой запрос, нажав на кнопку
![]() .
.
(Новый запрос) на панели инструментов. В появившемся окне с пустым запросом наберите команду EXEC [Среднее трех величин] 1, 7, 9 и нажмите кнопку
![]()
на панели инструментов, как на рисунке 5.4.
В нижней части окна с кодом появиться результат выполнения новой хранимой процедуры: Среднее значение 5,66667 (см. рисунок 5.4).
Теперь создадим хранимую процедуру для отбора студентов из таблицы студенты по их «ФИО». Для этого создайте новую хранимую процедуру, как это описано выше, и наберите код новой процедуры как на рисунке 5.5.
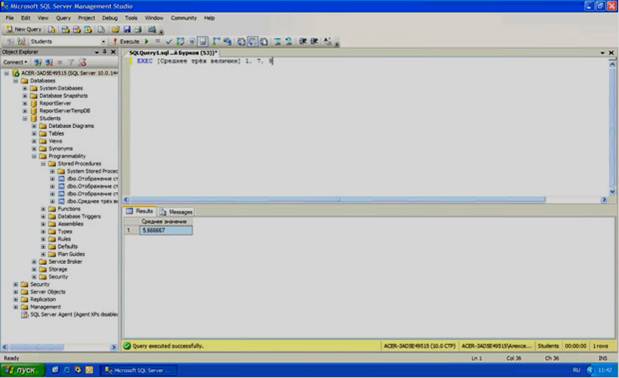
Рисунок 5.4

Рисунок 5.5
Рассмотрим код процедуры «Отображение студентов по ФИО» более подробно (см. рисунок 5.5):
1) CREATE PROCRDURE [Отображение студентов по ФИО] определяет имя создаваемой процедуры как «Отображение студентов по ФИО»;
2) @FIO Varchar(50)='' определяют единственный параметр процедуры FIO. Параметру можно присвоить текстовые сроки переменной длины, длиной до 50 символов (Тип данных Varchar(50)), значения по умолчанию равны пустой строке;
3) SELECT * FROM dbo.Студенты WHERE ФИО=@FIO отобразить все поля (*) из таблицы студенты (dbo.Студенты), где значение поля ФИО равно значению параметра FIO (ФИО=@FIO).
Выполним вышеописанный код и закроем окно с кодом, как описано выше и проверим работоспособность созданной хранимой процедуры. Создайте новый пустой запрос. В появившемся окне с пустым запросом наберите команду EXEC [Отображение студентов по ФИО] 'Иванов А.И.' и нажмите кнопку
![]()
на панели инструментов (см. рисунок 5.6).
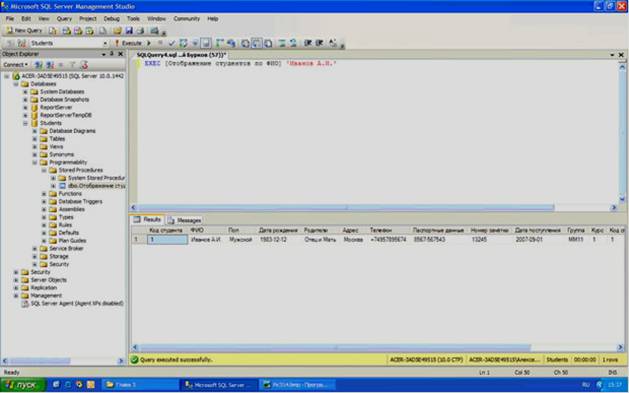
Рисунок 5.6
В нижней части окна с кодом появиться результат выполнения хранимой процедуры «Отображение студентов по ФИО» (рисунок 5.6).
Теперь перейдем к более сложной задаче – отобразить студентов, у которых средний балл выше заданного. Создайте новую хранимую процедуру и наберите код новой процедуры, как на рисунке 5.7.
Рассмотрим код процедуры «Отображение студентов по ФИО» более подробно (см. рисунок 5.7):
1) CREATE PROCRDURE [Отображение студентов по среднему баллу] определяет имя создаваемой процедуры как «Отображение студентов по среднему баллу»;
2) @Grade Real=0 определяют параметр процедуры Grade. Параметру можно присвоить дробные числа (Тип данных Real), значения по умолчанию равны 0;
3) SELECT * FROM [Запрос Студенты+Оценки] WHERE ([Оценка первого экзамена]+[Оценка второго экзамена]+[Оценка третьего экзамена]) /3>@Grade отобразит все поля (*) из запроса «Запрос Студенты+ Оценки» (Запрос Студенты+Оценки), где средний балл больше чем значение параметра Grade (([Оценка первого экзамена] + [Оценка второго экзамена]+[Оценка третьего экзамена])/3>@Grade).
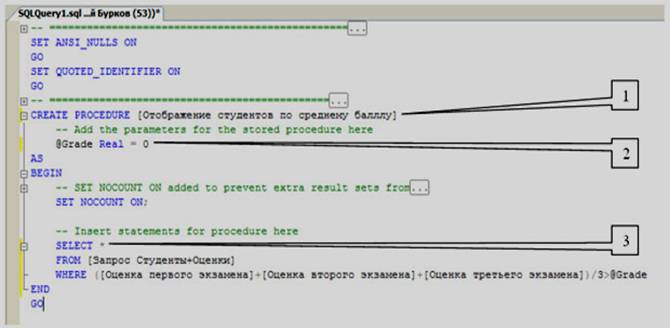
Рисунок 5.7
Выполним вышеописанный код и закроем окно с кодом, как описано выше. Проверим, как работает запрос, описанный выше. Для этого создайте новый запрос и в нем наберите команду EXEC [Отображение студентов по среднему баллу] 3.5 и выполните ее (см. рисунок 5.8).
В нижней части окна с кодом появится результат выполнения хранимой процедуры «Отображение студентов по среднему баллу» (см. рисунок 5.8).
В заключение решим более сложную задачу – отображение студентов старше заданного возраста. Причем возраст будет автоматически вычисляться в зависимости от даты рождения.
Создадим новую хранимую процедуру и наберем код новой процедуры, как представлено на рисунке 5.9.

Рисунок 5.8
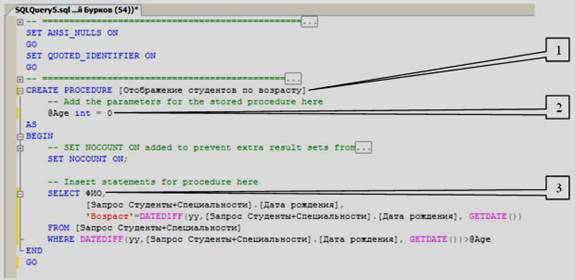
Рисунок 5.9
Рассмотрим код создаваемой процедуры «Отображение студентов по возрасту» более подробно (см. рисунок 5.9):
1) CREATE PROCRDURE [Отображение студентов по возрасту] определяет имя создаваемой процедуры как «Отображение студентов по возрасту»;
2) @Age int=0 определяют параметр процедуры Grade. Параметру можно присвоить целые числа (Тип данных int), значения по умолчанию равны 0;
3) ФИО, [Запрос Студенты+Специальности].[Дата рождения], 'Возраст'=DATEDIFF(yy,[Запрос Студенты+Специальности].[Дата рождения], GETDATE()) отображает из запроса «Запроса Студенты+Специальности» (FROM [Запрос Студенты+Специальности]) поля «ФИО» (ФИО) и «Дата рождения» ([Запрос Студенты+Специальности].[Дата рождения]), а также отображает возраст студента ('Возраст') в годах (yy), вычисленный, исходя из его даты рождения и текущей даты (DATEDIFF(yy,[Запрос Студенты+ Специальности].[Дата рождения], GETDATE())). Более того, выводятся студенты возраст которых больше определенного в параметре «Age» (DATEDIFF(yy,[Запрос Студенты+Специальности].[Дата рождения], GETDATE())>@Age).
Замечание: встроенная функция DATEDIFF вычисляющая количество периодов между двумя датами, имеет следующий синтаксис:
DATEDIFF(<период>,<начальная дата>, <конечная дата>)
Выполним код запроса «Отображение студентов по возрасту», а затем закроем окно с кодом, как описано выше. Проверим, как работает запрос. Для этого создадим новый запрос и в нем наберем команду EXEC [Отображение студентов по возрасту] 26 и выполните ее. Должен появиться результат аналогичный результату, представленному на рисунке 5.10.
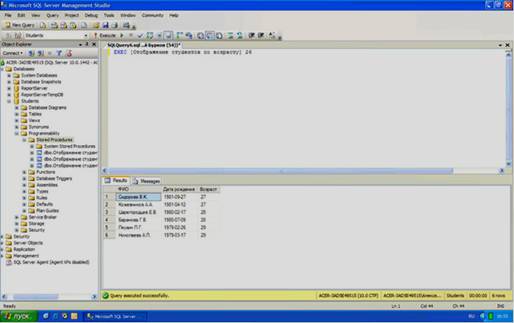
Рисунок 5.10
На этом мы заканчиваем описание хранимых процедур и переходим к рассмотрению пользовательских функций. В итоге обозреватель объектов должен иметь вид, как на рисунке 5.11.

Рисунок 5.11
Список литературы
1. У. Роберт, К. Майкл, Р. Роберт, Ф. Фабио, Д. Фармер. SQL Server 2008. Ускоренный курс для профессионалов. Вильямс – Москва – Санкт Петербург – Киев, 2008 – 768 с.
2. Проектирование информационных систем в Microsoft SQL Server 2008 и Visual Studio 2008 http://www.intuit.ru/department/se/pisqlvs2008/.
3. Стивенс Р, Программирование баз данных. М.: ООО «Бином-Пресс», 2007 – 384 с.
4. Б. Найт, К. Пэтел, В. Снайдер, Р. Лофорт, С. Уорт. Microsoft SQL Server 2008: руководство администратора для профессионалов. Вильямс – Москва – Санкт Петербург – Киев, 2008 – 855 c.
5. Жилинский А. Самоучитель Microsoft SQL Server 2008. БХВ-Петербург, 2009 – 240 с.
Сводный план 2010 г. поз. 196