Некоммерческое акционерное общество
АЛМАТИНСКИЙ УНИВЕРСИТЕТ ЭНЕРГЕТИКИ И СВЯЗИ
Кафедра «Электроника»
СХЕМОТЕХНИКА
КОНСПЕКТ ЛЕКЦИЙ
для студентов специальности
5В070400 – Вычислительная техника и программное обеспечение
Алматы 2011
СОСТАВИТЕЛИ: Б.С. Байкенов, А.Т. Ибраев. Схемотехника. Конспект лекций по дисциплине «Схемотехника» для студентов специальности 5В070400 –. Вычислительная техника и программное обеспечение – Алматы: АУЭС, 2011. – 101 с.
В конспекте лекций рассмотрены основы цифровой электроники и микропроцессорной техники – динамично развивающейся области науки и техники, играющей особую роль в современном мире. Изложение материала построено так и в таком объеме, чтобы подготовить студента к систематическому и самостоятельному изучению современных систем моделирования и проектирования. Лекционный материал состоит из двух разделов: цифровой схемотехники и микропроцессорных БИС.
В первом разделе рассмотрены цифровые устройства комбинационного и последовательностного типов, запоминающие устройства и программируемые логические матрицы. Второй раздел посвящен анализу структуры микропроцессора i8085/8086, командам, а также адаптерам и контроллерам микропроцессорной системы.
Конспект лекций составлен в целях закрепления основ построения цифровых устройств и микропроцессорных систем, и предназначена для студентов специальности 5В070400 – Вычислительная техника и программное обеспечение.
Ил. 84, табл. 24, библиогр. – 6 назв.
Рецензент: д-р. техн. наук, проф. Ш.А. Бахтаев
Печатается по плану издания Некоммерческого акционерного общества «Алматинский университет энергетики и связи» на 2011 г.
© НАО «Алматинский университет энергетики и связи», 2011 г.
Введение
Быстрорастущие потребности современного общества требуют широкомасштабного, тотального использования новейших технологий в различных отраслях экономики, так называемого Hi-Tec (High Technogy).
Крупнейший специалист в области информатики, академик Е.П.Велихов в одной из своих статей высказал гениальную по своей простоте мысль: «Тот, кто умеет делать компьютеры, владеет миром».
Все разнообразные средства цифровой техники: персональные компьютеры, микропроцессорные системы измерений и автоматизация технологических процессов, цифровая связь, телевидение, бытовая техника и т.д. строятся на единой элементной базе, в состав которой входят чрезвычайно разные по сложности микросхемы – от логических элементов, выполняющих простейшие операции, до сложнейших программируемых кристаллов, содержащих миллионы логических элементов.
С появлением микропроцессоров и СБИС с программируемой структурой произошло качественное изменение подхода к методам проектирования и изготовления средств автоматики.
Микропроцессор – это процессор, реализованный в виде одной или нескольких больших интегральных схем (БИС), обладающих функциональной завершенностью.
Микропроцессор способен выполнять команды, входящие в его систему команд. Меняя последовательность команд (программу), можно решать различные задачи на одном и том же микропроцессоре. Иначе говоря, в этом случае задачи структура аппаратных средств не связана с характером решаемой задачи. Это обеспечивает микропроцессорам массовое производство с соответствующим снижением стоимости.
Микропроцессорный комплект – набор БИС, в котором имеется возможность управления работой с помощью определенного набора команд.
Микропроцессорная система по своей структуре схожа с персональным компьютером, но имеет усеченный объем памяти и ограниченный набор средств сопряжения с внешним миром. В основе построения микропроцессорных систем лежит программно-аппаратный принцип. Меняя программу, одну и ту же стандартную микропроцессорную систему можно использовать во многих устройствах и системах: автоматического управления технологическим процессом, системах технической диагностики и контроля состояния объекта, включая охранные системы.
Основное отличие СБИС с программируемой структурой состоит в том, что системотехник может изменять структуру микросхемы, программно соединяя различные блоки.
Но прежде чем перейти изучению микропроцессоров и СБИС с программируемой структурой, необходимо ознакомиться с наиболее важными цифровыми элементами и устройствами, из которых собственно и состоит микропроцессор и его периферийные устройства.
1 Лекция. Логические элементы цифровых устройств
Преобразование цифровой информации сводится к простейшим операциям над логическими переменными 0 и 1, которые реализуются логическими элементами И, ИЛИ и НЕ. Условное обозначение логического элемента - прямоугольник, в котором ставится символ выполняемой операции, (операция инверсии изображается в виде кружка).

Рисунок 1.1 – Условные обозначения логических элементов
В схемах логические переменные 0 и 1 отображаются двумя различными уровнями напряжения: Uo и U1. Необходимо условиться, какой из двух уровней напряжения принять за Uo и какой за U1. Существуют понятие положительной и отрицательной логики. В положительной логике U1 > Uo, а в отрицательной U1 < Uо. В дальнейшем, если не оговорено иное, будем пользоваться положительной логикой.
Одни и те же преобразования логических переменных можно задать в различных формах: с помощью операций И, ИЛИ, НЕ (булевский базис), операции И-НЕ (базис Шеффера), операции ИЛИ-НЕ (базис Пирса), а также многими другими способами. Чаще всего встречаются базисы Шеффера и Пирса.
1.1 Статические параметры логических элементов
К статическим параметрам, задающим границы отображения переменных (0 и 1) на входе и выходе логического элемента (ЛЭ), относятся значения напряжений:
- по входу Uвx1min и Uвх0mах.;
- по выходу Uвых1min и Uвых0max
и токов:
- по входу Iвх1max и Iвх0mах;
- по выходу Iвых1mах и Iвых0mах.
Для нормальной работы элемента требуется, чтобы напряжение, отображающее логическую 1, было достаточно высоким, а напряжение, отображающее 0, - достаточно низким. Эти требования задаются параметрами Uвx1min и Uвх0mах. Входные напряжения данного элемента есть выходные напряжения предыдущего (источника сигналов). Уровни, гарантируемые на выходе элемента при соблюдении допустимых нагрузочных условий, задаются параметрами Uвых1min и Uвых0max. При высоком уровне выходного напряжения из элемента-источника ток вытекает, цепи нагрузки ток поглощают. При низком уровне выходного напряжения элемента-источника ток нагрузки втекает в этот
элемент, а из входных цепей элементов-приемников токи вытекают. Зная токи Iвых1mах и Iвых0mах, характеризующие возможности элемента-источника сигнала, и токи Iвх1max и Iвх0mах, потребляемые элементами-приемниками, можно контролировать соблюдение нагрузочных ограничений, обязательное для всех элементов схемы.
Быстродействие логических элементов определяется скоростями их перехода из одного состояния в другое. На рисунке 1.2 показана временная диаграмма работы логического элемента НЕ. Моментом изменения логического сигнала считают момент достижения им порогового уровня Uпор, за который принимают середину логического перепада сигнала, т. е. 0,5(Uо + U1).
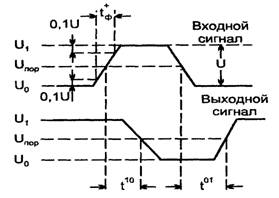
Рисунок 1.2 - Временная диаграмма работы логического элемента НЕ
На быстродействие ЦУ влияют также емкости, на перезаряд которых требуются затраты времени. В справочных данных приводятся входные и выходные емкости логических элементов, знание которых позволяет подсчитать емкости нагрузки в узлах схемы. Предельно допустимая емкость указывает границу, которую нельзя нарушать, поскольку при этом работоспособность элемента не гарантируется.
1.2 Типы выходов ЦЭ
Цифровые элементы (логические, запоминающие, буферные) могут иметь следующие типы выходов:
- логические;
- с открытым коллектором (стоком);
- с третьим состоянием;
- с открытым эмиттером (истоком).
1.2.1 Логический выход.
Логический выход формирует два уровня выходного напряжения (Uо и U1). Выходное сопротивление логического выхода стремятся сделать малым, способным развивать большие токи для перезаряда емкостных нагрузок и, следовательно, получения высокого быстродействия. Такой тип выхода используют в комбинационных схемах (дешифраторах, мультиплексорах, сумматорах, АЛУ и т.д).
Схемы логических выходов элементов ТТЛ и КМОП подобны двухтактным каскадам - в них оба фронта выходного напряжения формируются с участием активных транзисторов, работающих противофазно, что обеспечивает малые выходные сопротивления при любом направлении переключения выхода (см. рисунок 1.3).
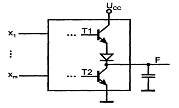
Рисунок 1.3 - Схема выходной цепи цифрового элемента
Особенность таких выходов состоит в том, что их нельзя соединять параллельно. Во-первых, это создает неопределенность, т. к. в точке соединения выхода, формирующего логическую 1, и выхода, формирующего логический 0, не будет нормального результата. Во-вторых, вследствие малых величин выходных сопротивлений уравнительный ток при этом может достигать достаточно большой величины, что может вывести из строя электрические элементы выходной цепи.
1.2.2 Элементы с тремя состояниями выхода.
Элементы с тремя состояниями выхода (типа ТС) кроме логических состояний 0 и 1 имеют состояние "отключено", в котором ток выходной цепи пренебрежимо мал. В это состояние (третье) элемент переводится специальным управляющим сигналом, обеспечивающим запертое состояние обоих транзисторов выходного каскада (Т1 и Т2 на рис.1.3) Сигнал управления элементом типа ТС обычно обозначается как ОЕ (Output Enable). При наличии разрешения (ОЕ = 1) элемент работает как обычно, выполняя свою логическую операцию, а при его отсутствии (ОЕ = 0) переходит в состояние "отключено". В ЦУ широко используются буферные элементы типа ТС для управляемой передачи сигналов по тем или иным линиям. Буферы могут быть неинвертирующими или инвертирующими, а сигналы ОЕ — Н-активными или L-активными, что ведет к наличию четырех типов буферных каскадов (см.рисунок 1 4).
Выходы типа ТС отмечаются в обозначениях элементов значком треугольника.
Выходы типа ТС можно соединять параллельно при условии, что в любой момент времени активным может быть только один из них. В этом случае отключенные выходы не мешают активному формировать сигналы в точке соединения выходов. Эта возможность позволяет применять элементы типа ТС в магистрально-модульных микропроцессорных и иных системах, где многие источники информации поочередно пользуются одной и той же линией связи.
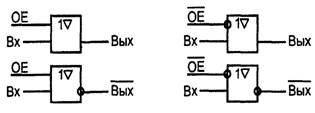
Рисунок 1.4 - Типы буферных каскадов с третьим состоянием
1.2.3 Выход с открытым коллектором.
Элементы с открытым коллектором имеют выходную цепь, заканчивающуюся одиночным транзистором, коллектор которого не соединен с какими-либо цепями внутри микросхемы (см. рисунок 1.5,а). Транзистор управляется от предыдущей части схемы элемента так, что может находиться в насыщенном или запертом состоянии. Насыщенное состояние трактуется как отображение логического нуля, запертое - 1. Насыщение транзистора обеспечивает на выходе напряжение Uо (малое напряжение насыщения "коллектор-эмиттер" Uкэн). Запирание же транзистора какого-либо уровня напряжения на выходе элемента не задает, выход при этом имеет фактически неизвестный "плавающий" потенциал, т. к. не подключен к каким-либо цепям схемы элемента. Поэтому для формирования высокого уровня напряжения при запирании транзистора на выходе элементов с открытым коллектором (типа ОК) требуется подключать внешние резисторы (или другие нагрузки), соединенные с источником питания.
Несколько выходов типа ОК можно соединять параллельно, подключая их к общей для всех выходов цепочке Ucc - R (см. рисунок 1.5, б). При этом можно получить режим поочередной работы элементов на общую линию, как и для элементов типа ТС, если активным будет лишь один элемент, а выходы всех остальных окажутся запертыми. Если же разрешить активную работу элементов, выходы которых соединены, то можно получить дополнительную логическую операцию, называемую операцией монтажной логики.
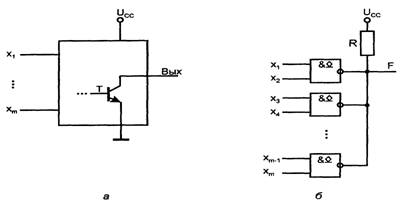
Рисунок 1.5 - Схема выходной цепи ЦЭ с открытым коллектором (а) и реализации операции И (б)
При реализации монтажной логики высокое напряжение на общем выходе возникает только при запирании всех транзисторов, т. к. насыщение хотя бы одного из них снижает выходное напряжение до уровня Uo = Uкэн. To есть для получения логической единицы на выходе требуется единичное состояние всех выходов: выполняется операция И. Поскольку каждый элемент выполняет операцию Шеффера над своими входными переменными, общий результат окажется следующим
![]() .
.
В обозначениях элементов с ОК после символа функции ставится ромб с черточкой снизу.
При использовании элементов с ОК в магистрально-модульных структурах требуется разрешать или запрещать работу того или иного элемента. Для элементов типа ТС это делалось с помощью специального сигнала ОЕ. Для элементов типа ОК в качестве входа ОЕ может быть использован один из обычных входов элемента. Если речь идет об элементе И-НЕ, то, подавая 0 на любой из входов, можно запретить работу элемента, поставив его выход в разомкнутое состояние независимо от состояния других входов. Уровень 1 на этом входе разрешит работу элемента.
1.2.4 Выход с открытым эмиттером
Выход с открытым эмиттером характерен для элементов типа ЭСЛ (эмиттерно-связанная логика). Для работы на магистраль такие элементы не используются. Возможность соединять друг с другом выходы с открытым эмиттером при объединении эмиттерных резисторов в один общий резистор приводит к схеме (см. рисунок 1.6), иногда называемой "эмиттерный дот" и используемой при построении логических схем для получения дополнительной операции монтажной логики.
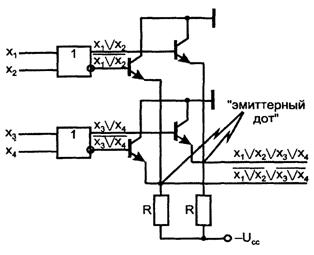
Рисунок 1.6 - Схема "эмиттерного дота"
Элементы ЭСЛ имеют противофазные выходы, на одном из которых реализуется функция ИЛИ, на другом — ИЛИ-НЕ. Соединяя прямые выходы нескольких элементов, получают расширение по ИЛИ (входные переменные соединяемых элементов образуют единую дизъюнкцию). Соединяя инверсные выходы, получают операцию И-ИЛИ относительно инверсий входных переменных, т. к. при этом
![]() .
.
Соединяя прямой выход с инверсным, можно получить функцию вида
![]() .
.
2 Лекция. ЦУ комбинационного типа
2.1 Этапы проектирования
Функциональные узлы делятся на комбинационные и последователъностные. В дальнейшем комбинационные узлы будем обозначать через КЦ (комбинационные цепи), а последовательностные через АП (автоматы с памятью). Основное различие между КЦ и АП заключаются в следующем:
- выходные величины КЦ зависят только от текущего значения входных величин (аргументов), предыстория значения не имеет.
После завершения переходных процессов в КЦ на их выходах устанавливаются выходные величины, на которые характер переходных процессов влияния не оказывает. Но в цифровых устройствах КЦ функционируют совместно с АП: во время переходных процессов на выходах КЦ появляются временные сигналы, называемые рисками. Со временем они исчезают, и выход КЦ приобретает значение, предусмотренное логической формулой, описывающей работу цепи. Однако риски могут быть восприняты элементами памяти АП, необратимое изменение состояния которых может радикально изменить работу ЦУ, несмотря на исчезновение сигналов рисков на выходе КЦ. Для исключения сбоев в работе ЦУ из-за явлений риска предусматривают запрещение восприятия сигналов КЦ элементами памяти на время переходных процессов. Прием информации с выходов КЦ разрешается только специальным сигналом синхронизации, подаваемым на элементы памяти после окончания переходных процессов в КЦ.
Таким образом, исключается воздействие ложных сигналов на элементы памяти. Соответствующие структуры называются синхронными.
Проектирование произвольной логики комбинационного типа производится по этапам.
Прежде всего, задается характер функционирования КЦ. Это может быть сделано различными способами, чаще всего пользуются таблицами истинности, задающими значение искомых функций на всех наборах аргументов. От таблицы легко перейти к СДНФ искомых функций (СДНФ - совершенная дизъюнктивная нормальная форма, т. е. дизъюнкция конъюнктивных членов одинаковой размерности). Для этого составляют логическую сумму тех наборов аргументов, на которых функция принимает единичное значение.
Например, для подлежащей воспроизведению функции трех аргументов, заданной таблице 2.1, получим СДНФ
![]() .
.
Таблица 2.1 – Таблица истинности ЦУ
|
x1 |
x2 |
x3 |
F |
x1 |
x2 |
x3 |
F |
|
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
|
0 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
|
0 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
|
0 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
Дальнейшие действия зависят от средств реализации функций, к которым в современной схемотехнике относятся:
1) Логические блоки табличного типа (LUTs, Look-Up Tables).
2) Логические блоки в виде последовательности матриц элементов И и ИЛИ (PLA, Programmable Logic Array; PAL, Programmable Array Logic).
3) Универсальные логические блоки на основе мультиплексоров (УЛМ).
4) Логические блоки, собираемые из логических элементов некоторого базиса (SLC, Small Logic Cells).
1. Если КЦ будет реализована на основе логических блоков табличного типа, то СДНФ явится окончательным выражением функции, и никаких дальнейших преобразований этой формы не потребуется. Дело в том, что табличный блок представляет собою память, в которой имеется столько ячеек, сколько необходимо для хранения всех значений функций, т. е. 2m, где m - число аргументов функции. Набор аргументов является адресом той ячейки, в которой хранится значение функции на этом наборе (0 или 1). СДНФ как раз и содержит все адреса, по которым нужно хранить единичные значения функции.
Если искомая функция выражена в какой-либо сокращенной
форме, то следует перевести ее в СДНФ. Для этого конъюнктивные члены, не содержащие
переменной хj, умножаются
на равную единице дизъюнкцию ![]()
Например,
![]()
![]() .
.
2. Если данный проект реализуется на логических блоках, в виде последовательно включенных матриц элементов И и ИЛИ либо их эквивалента на другом базисе, то исходную СДНФ можно минимизировать. Логические блоки с матрицами И и ИЛИ воспроизводят системы переключательных функций и имеют параметры: число входов, выходов и термов. Целью минимизации будет сокращение числа конъюнктивных термов в данной системе функций, т. е. поиск кратчайших дизъюнктивных форм. Практически это сводится к поиску минимальных форм дизъюнктивных нормальных форм (ДНФ), о чем говорится далее, и отбору среди них вариантов с достаточно малым числом термов.
3. Логические блоки на основе мультиплексоров рассмотрены в теме 3.
4. Синтез КЦ на логических блоках типа SLC, т. е. на вентильном уровне, является традиционным (термином "вентиль" называют базовые логические ячейки, выполняющие простейшие операции, например, элементы И-НЕ с двумя-тремя входами).
В этом варианте проектирование КЦ содержит следующие этапы:
- минимизацию логических функций;
- переход к заданному логическому базису.
Минимизация - такое преобразование логических функций, которое упрощает их в смысле заданного критерия. В начале было стремление минимизировать число логических элементов в схеме, что приводит к критерию сложности схемы в виде числа букв в реализуемых выражениях. Этот критерий учитывается так называемой ценой по Квайну - суммарным числом входов всех логических элементов схемы. Для минимизации по этому критерию разработано несколько методов, в их числе как аналитические, основанные на преобразованиях математических выражений, так и графические, основанные на применении карт Карно (диаграмм Вейча), удобных в использовании, если число аргументов не больше 6.
Следующий этап проектирования - переход к заданному логическому базису от исходных выражений, которые обычно получают в булевском базисе (И, ИЛИ, НЕ). Правила такого перехода известны: они основаны на применении теоремы де-Моргана. В частности, для перехода к базису Шеффера (И-НЕ) используется соотношение
![]() ,
,
а для перехода к базису Пирса (ИЛИ-НЕ) удобно вначале получить исходную булевскую форму путем инверсии искомой функции, а затем от нее перейти к базису ИЛИ-НЕ по соотношениям
![]() .
.
2.2 Двоичные дешифраторы
В зависимости от входного двоичного кода на выходе дешифратора возбуждается одна и только одна из выходных цепей. Двоичный дешифратор, имеющий n входов, должен иметь 2n выходов, соответствующих числу разных комбинаций в n-разрядном двоичном коде.
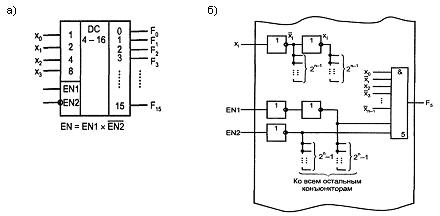
Рисунок 2.1 - Условное обозначение (а) и схема дешифратора (б)
В условном обозначении дешифраторов проставляются буквы DC (от англ. Decoder). Входы дешифратора принято обозначать их двоичными весами. Кроме информационных входов дешифратор обычно имеет один или более входов разрешения работы, обозначаемых как EN (Enable).
![]()
![]()
……………………..
![]()
Малоразрядность стандартных дешифраторов ставит вопрос о наращивании их разрядности. Для этого входное слово делится на поля. Разрядность поля младших разрядов соответствует числу входов имеющихся дешифраторов. Оставшееся поле старших разрядов служит для получения сигналов разрешения работы одного из дешифраторов, декодирующих поле младших разрядов.
В качестве примера на рисунке 2.2 приведена схема дешифрации пятиразрядного двоичного кода с помощью дешифраторов «3-8» и «2-4».
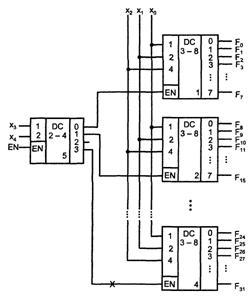
Рисунок 2.2 - Схема наращивания размерности дешифратора
Для получения нужных 32 выходов составляется столбец из четырех дешифраторов «3-8». Дешифратор «2-4» принимает два старших разряда входного кода. Возбужденный единичный выход этого дешифратора отпирает один из дешифраторов столбца по его входу разрешения. Выбранный дешифратор столбца расшифровывает три младших разряда входного слова. Каждому входному слову соответствует возбуждение только одного выхода.
Например, при дешифрации слова х4х3х2х1х0 = 110012 = 2510 на входе дешифратора первого яруса имеется код 11, возбуждающий его выход номер три (показано крестиком), что разрешает работу DC4. На входе DC4 действует код 001, поэтому единица появится на его первом выходе, т. е на 25 выходе схемы в целом, что и требуется.
Общее разрешение или запрещение работы схемы осуществляется по входу EN дешифратора первого яруса.
2.2.1 Двоичные шифраторы.
Двоичные шифраторы выполняют операцию, обратную по отношению к операции дешифратора: при возбуждении одного из входов шифратора на его выходе формируется двоичный код номера возбужденной входной линии. Полный двоичный шифратор имеет 2n входов и n выходов.
2.3 Мультиплексоры и демультиплексоры
Мультиплексоры осуществляют подключение одного из входных каналов к выходному под управлением управляющего (адресующего) слова. Разрядности каналов могут быть различными, мультиплексоры для коммутации многоразрядных слов составляются из одноразрядных.
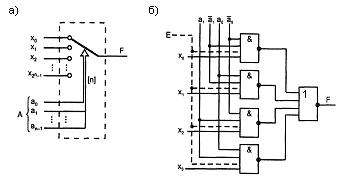
Рисунок 2.3 – Модель мультиплексора (а) и схема мультиплексора
на элементах И-НЕ (б)
Входы мультиплексора делятся на две группы: информационные и адресующие. Работу мультиплексора можно упрощенно представить с помощью многопозиционного ключа (см. рисунок 2.3,а.). Адресующий код А задает переключателю определенное положение, соединяя с выходом F один из информационных входов хi.
При нулевом адресующем коде переключатель занимает верхнее положение хо, с увеличением кода на единицу переходит в соседнее положение х1 и т. д.
Работа мультиплексора описывается соотношением
![]() .
.
При любом значении адресующего кода все слагаемые, кроме одного, равны нулю. Ненулевое слагаемое равно хj, где i - значение текущего адресного кода.
Схемотехнически мультиплексор реализует электронную версию показанного переключателя, имея, в отличие от него, только одностороннюю передачу данных. На рисунке 2.3,б показан мультиплексор с четырьмя информационными входами, двумя адресными входами и входом разрешения работы Е. При отсутствии разрешения работы (Е = 0) выход F становится нулевым независимо от информационных и адресных сигналов.
В стандартных сериях размерность мультиплексоров не более 16x1.
Наращивание размерности мультиплексоров возможно с помощью пирамидальной структуры из нескольких мультиплексоров. При этом первый ярус схемы представляет собою столбец, содержащий столько мультиплексоров, сколько необходимо для получения нужного числа информационных входов. Все мультиплексоры столбца адресуются одним и тем же кодом, составленным из соответствующего числа младших разрядов общего адресного кода (если число информационных входов схемы равно 2n, то общее число адресных разрядов равно n, младшее поле n1 адресного кода используется для адресации мультиплексоров первого яруса). Старшие разряды адресного кода, число которых равно n – n1, используются во втором ярусе, мультиплексор которого обеспечивает поочередную работу мультиплексоров первого яруса на общий выходной канал.
Пирамидальная схема, выполняющая функции мультиплексора «32 - 1» и построенная на 5 мультиплексорах меньшей размерности, показана на рисунке 2.4 (сокращение MUX от англ. Multiplexer).
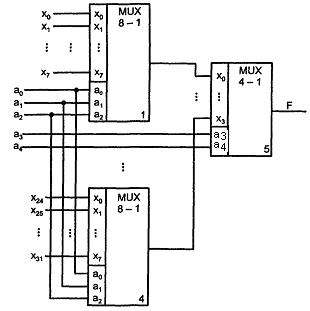
Рисунок 2.4 - Схема наращивания мультиплексоров
Демультиплексоры выполняют операцию, обратную операции мультиплексоров - передают данные из одного входного канала в один из нескольких каналов-приемников. Многоразрядные демультиплексоры составляются из нескольких одноразрядных.
3 Лекция. Универсальные логические модули
Известно, что общее число функций
n-аргументов
равно ![]() . С
ростом n число функций растет чрезвычайно быстро.
Универсальность УЛМ состоит в том, что для заданного
числа аргументов ее можно настроить на любую функцию.
. С
ростом n число функций растет чрезвычайно быстро.
Универсальность УЛМ состоит в том, что для заданного
числа аргументов ее можно настроить на любую функцию.
3.1 Первый способ настройки УЛМ
Первым способом настройки является фиксация некоторых
входов. Для этого способа справедливо следующее соотношение между числом
аргументов n и числом настроечных входов 2n.
Тогда число комбинаций для кода настройки, равное числу функций, есть ![]() . При этом на адресные
входы подают аргументы функции, а на информационные входы - сигналы настройки
(см. рисунок 3.1).
. При этом на адресные
входы подают аргументы функции, а на информационные входы - сигналы настройки
(см. рисунок 3.1).
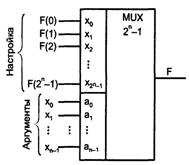
Рисунок 3.1- Схема использования мультиплексора в качестве УЛМ
Таким образом, для использования мультиплексора в качестве УЛМ следует изменить назначение его входов.
Действительно, каждому набору аргументов соответствует передача на выход одного из сигналов настройки. Если этот сигнал есть значение функции на данном наборе аргументов, то задача решена. Разным функциям будут соответствовать разные коды настройки: 0 и 1.
На рисунке 3.2 показан пример воспроизведения функции
неравнозначности ![]() с
помощью мультиплексора «4 - 1».
с
помощью мультиплексора «4 - 1».
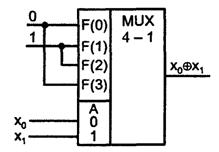
Рисунок 3.2 – Схема УЛМ, реализующую функцию «исключающее ИЛИ»
Большое число настроечных входов затрудняет реализацию УЛМ.
3.2 Второй способ настройки УЛМ
Уменьшение входов настройки заключается в расширении алфавита настроечных сигналов. Если от алфавита {0,1} перейти к алфавиту {0,1,xi }, где xi - литерал одного из аргументов, то число входов аргументов сократится на единицу, а число настроечных входов - вдвое. Перенос одного из аргументов в число сигналов настройки не влечет за собою каких-либо схемных изменений. На том же оборудовании будут реализованы функции с числом аргументов на единицу больше, чем при настройке константами.
Для нового алфавита код настройки находится следующим образом. Аргументы, за исключением xi, подаются на адресующие входы, что соответствует их фиксации в выражении для искомой функции, которая становится функцией единственного аргумента xi. Эту функцию, которую назовем остаточной, и нужно подавать на настроечные входы.
Если искомая функция зависит от n аргументов и в число сигналов настройки будет перенесен один из аргументов, то возникает n вариантов решения задачи, т. к. в сигналы настройки может быть перенесен любой аргумент.
В настроечные сигналы следует переводить аргумент, который имеет минимальное число вхождений в термы функции. В этом случае среди сигналов настройки увеличится число констант, что упрощает схемную реализацию УЛМ.
Пример воспроизведения функции трех аргументов ![]() показан на рисунке 3.3.
показан на рисунке 3.3.
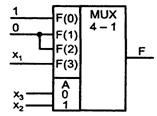
Рисунок 3.3 – Пример воспроизведения функции 3-х аргументов
Минимальное число вхождений в выражение функции имеет переменная х1, которую и перенесем в число сигналов настройки. Остаточная функция определится таблице 3.1.
Таблица 3.1
|
x2 |
x3 |
Fост |
|
0 |
0 |
1 |
|
0 |
1 |
0 |
|
1 |
0 |
0 |
|
1 |
1 |
х1 |
Если в сигналы настройки перевести два аргумента, то дополнительные логические схемы
будут двухвходовыми вентилями, что не усложняет УЛМ. В этом случае
мультиплексору нужно добавить блок выработки остаточных функций, в котором
формируются все функции 2-х переменных (за исключением констант 0 и 1 и
литералов самих переменных, которые не требуется вырабатывать). Пример
реализации функции 4-х аргументов ![]() при алфавите настройки {0,1,х1,х2}
показан на рисунке 3.3.
при алфавите настройки {0,1,х1,х2}
показан на рисунке 3.3.
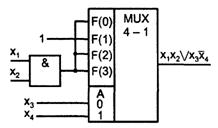
Рисунок 3.3 – Пример воспроизведения функции 4-х аргументов
Таблица остаточной функции для этого примера приведена в таблице 3.2.
Таблица 3.2
|
X4 |
x3 |
Fост |
|
0 |
0 |
х1х2 |
|
0 |
1 |
1 |
|
1 |
0 |
х1х2 |
|
1 |
1 |
х1х2 |
3.3 Пирамидальные структуры УЛМ
Дальнейшее расширение алфавита настройки за счет переноса трех и более переменных в сигналы настройки требует вычислений остаточных функций трех или более переменных. Вычисление таких остаточных функций с помощью мультиплексоров приводит к пирамидальной структуре (см. рисунок 3.4), в которой мультиплексоры первого яруса реализуют остаточные функции, а мультиплексор второго яруса вырабатывает искомую функцию.
При электронной настройке константами 0 и 1 схема воспроизводит функцию n аргументов, где n = k + р, причем k - число аргументов, подаваемых на мультиплексор второго яруса, р - число аргументов, от которых зависят остаточные функции, воспроизводимые мультиплексорами 0...2k - 1 первого яруса.
Для уменьшения аппаратных затрат в схеме следует стремиться к минимизации числа мультиплексоров в столбце, т. е. минимизации k и соответственно, максимальным р, поскольку их сумма k + р постоянна и равна n.
Сигналы настройки для мультиплексоров первого яруса можно искать разными способами:
1. Подстановкой (фиксацией) наборов аргументов, подаваемых на адресные входы мультиплексоров для получения остаточных функций, и далее сигналов настройки (см. таблицы 3.1 и 3.2).
2. С помощью разложения функции по Шеннону.
Разложение по одному из аргументов имеет вид
![]() .
.
Разложение функции по двум аргументам
![]() Разложение по
k
аргументам
Разложение по
k
аргументам
![]()
![]() .
.
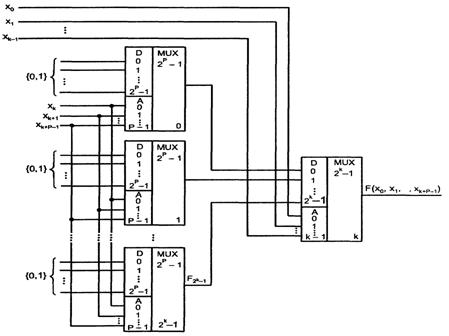
Рисунок 3.4 – Двухъярусная схема УЛМ
Структура формул разложения полностью соответствует реализации двухъярусным УЛМ. В первом ярусе реализуются функции Fi, (i = 0,..., 2k - 1), зависящие от n - k аргументов, которые используются как настроечные для второго яруса, мультиплексор которого воспроизводит функцию k аргументов.
3. Сигналы настройки можно получить непосредственно из таблицы истинности функции.
Пусть имеется функция 4-х переменных х3х2х1х0,
и переменная х3 считается старшим разрядом вектора аргументов. Функция
задана перечислением наборов аргументов, на которых она принимает единичные
значения, причем заданы десятичные значения этих наборов: 3, 4, 5, 6, 7, 11,
15. Аналитическое значение этой функции имеет вид ![]() .
.
Значения функции сведены в таблицу 3.3.
Таблица 3.3
|
х3 |
x2 |
x1 |
x0 |
F |
|
0 0 |
0 0 |
0 0 |
0 1 |
0 0 |
|
0 0 |
0 0 |
1 1 |
0 1 |
0 1 |
|
0 0 |
1 1 |
0 0 |
0 1 |
1 1 |
|
0 0 |
1 1 |
1 1 |
0 1 |
1 1 |
|
1 1 |
0 0 |
0 0 |
0 1 |
0 0 |
|
1 1 |
0 0 |
1 1 |
0 1 |
0 1 |
|
1 1 |
1 1 |
0 0 |
0 1 |
0 0 |
|
1 1 |
1 1 |
1 1 |
0 1 |
0 1 |
При электронной настройке УЛМ константами 0 и 1 требуется мультиплексор размерности «16 - 1», на настроечные входы УЛМ подаются значения самой функции из таблицы.
При переносе хо в сигналы настройки (алфавит настройки {0,1,хо}) требуется найти остаточную функцию, аргументами которой является вектор переменных
х3х2х1. Каждая комбинация этих переменных встречается в двух смежных строках таблицы 3.3. Просматривая таблицу по смежным (выделенные в отдельные ячейки) парам строк, видно, что остаточная функция соответствует таблице 3.4.
Таблица 3.4
|
х3 |
х2 |
х1 |
Fост |
|
0 0 |
0 0 |
0 1 |
0 х0 |
|
0 0 |
1 1 |
0 1 |
1 1 |
|
1 1 |
0 0 |
0 1 |
0 х0 |
|
1 1 |
1 1 |
0 1 |
0 х0 |
Для реализации этого варианта УЛМ достаточен мультиплексор "8-1", но для перестройки на другую функцию потребуется не только смена кода настройки, но и коммутация входов настройки для подачи литералов переменной на другие настроечные входы.
При переносе в сигналы настройки двух переменных (хо и х1) для поиска остаточных функций следует просмотреть четверки смежных строк таблицы 3.4 с неизменными наборами х2х3 - аргументами, подаваемыми на адресные входы УЛМ. Этот просмотр приводит к таблице 3.5.
Таблица 3.5
|
х3 |
х2 |
Fост |
|
0 |
0 |
х1хо |
|
0 |
1 |
1 |
|
1 |
0 |
х1хо |
|
1 |
1 |
х1хо |
Из таблицы 3.5 видно, что для воспроизведения функции достаточно использовать мультиплексор «4 - 1» с дополнительным конъюнктором для получения произведения xlxо. Но при перестройке на другую функцию потребуются и другие функции двух переменных, т. е. универсальный логический модуль должен включать в свой состав дополнительный логический блок.
Логические блоки на мультиплексорах используются в современных СБИС программируемой логики, выпускаемых ведущими мировыми фирмами. Модули относятся к настраиваемым и характеризуются порождающей функцией, реализуемой модулем, когда все его входы используются как информационные (т. е. для подачи на них аргументов). Эта функция при введении настройки, когда часть входов занята под настроечные сигналы, порождает некоторый список подфункций, зависящих от меньшего числа аргументов в сравнении с порождающей функцией. Создается перечень практически важных подфункций для того или иного настраиваемого модуля.
4 Лекция. Компараторы и схемы контроля
4.1 Компараторы
Компараторы (устройства сравнения) определяют отношения между двумя словами. Основными отношениями, через которые можно выразить остальные, можно считать два - "равно" и "больше".
Компараторы принимают значение 1, если соблюдается условие, указанное в индексе обозначения функции. Например, функция FA = B = 1, если А = В и принимает нулевое значение при А ≠ В.
Приняв в качестве основных отношения "равно" и "больше", для остальных можно записать:
![]()
В сериях цифровых элементов обычно имеются компараторы с тремя выходами: "равно", "больше" и "меньше" (см. рисунок 4.1). Для краткости записей в индексе выходных функций указывается только слово А.
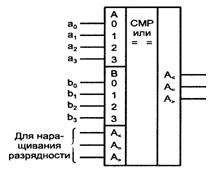
Рисунок 4.1 – Условное обозначение компаратора с тремя выходами
Устройства сравнения на равенство строятся на основе поразрядных операций над одноименными разрядами обоих слов. Слова равны, если равны все одноименные их разряды, т. е. если в обоих нули или единицы. Признак равенства разрядов
![]() .
.
Признак равенства слов
![]()
Схема компаратора на равенство в базисе И-НЕ показана на рисунке 4.2.
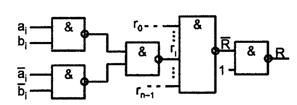
Рисунок 4.2 – Схема компаратора на равенство
Построение компаратора на "больше" для одноразрядных
слов (см. таблицу 4.1) требует реализации функции ![]() .
.
Таблица 4.1
|
a |
b |
FA>B |
|
0 |
0 |
0 |
|
0 |
1 |
0 |
|
1 |
0 |
1 |
|
1 |
1 |
0 |
Для общего случая n-разрядных слов имеем
![]() .
.
4.2 Схемы контроля
Задачи выявления ошибок решаются разными методами. Добавление функций контроля всегда связано с избыточностью - платой за новые возможности будут дополнительные аппаратные или временные затраты.
4.2.1 Мажоритарные элементы.
Задача мажоритарного элемента - произвести "голосование" и передать на выход величину, соответствующую большинству из входных. Ясно, что мажоритарный элемент может иметь только нечетное число входов.
Функционирование мажоритарного элемента, на входы которого поступают величины F1, F2, и F3 и по результатам голосования вырабатывается выходная величина F, представлено в таблице 4.2.
Таблица 4.2
|
F1 |
F2 |
F3 |
F |
a1 |
a0 |
|
0 |
0 |
0 |
0 |
0 |
0 |
|
0 |
0 |
1 |
0 |
1 |
1 |
|
0 |
1 |
0 |
0 |
1 |
0 |
|
0 |
1 |
1 |
1 |
0 |
1 |
|
1 |
0 |
0 |
0 |
0 |
1 |
|
1 |
0 |
1 |
1 |
1 |
0 |
|
1 |
1 |
0 |
1 |
1 |
1 |
|
1 |
1 |
1 |
1 |
0 |
0 |
Кроме выхода F, в таблице даны и выходы a1, ао - старший и младший разряды двухразрядного кода, указывающего номер отказавшего канала при F=1 (см. рисунок 4.4). Из таблицы легко получить функции, которые после несложных преобразований приводятся к следующим:
![]()
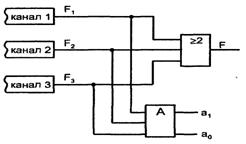
Рисунок 4.4 – Схема голосования с мажоритарным элементом
В схемах типа (см. рисунок 4.4) от мажоритарного элемента требуется особенно высокая надежность, т. к. его отказ делает бесполезной всю схему резервирования.
4.2.2 Контроль по модулю 2.
Контроль правильности передач и хранения данных - важное условие нормальной работы ЦУ.
Кодовая комбинация - набор из символов принятого алфавита.
Код - совокупность кодовых комбинаций, используемых для отображения информации.
Кодовое расстояние между двумя кодовыми комбинациями - число разрядов, в которых эти комбинации отличаются друг от друга.
Минимальное кодовое расстояние dmin - минимальное кодовое расстояние для любой пары комбинаций, входящих в данный код.
Кратностью ошибки называют число ошибок в данном слове (число неверных разрядов).
Из теории кодирования известны условия обнаружения и исправления ошибок при использовании кодов:
![]()
где dmjn - минимальное кодовое расстояние кода;
гобн и гиспр - кратность обнаруживаемых и исправляемых ошибок соответственно.
Вес кода - число единиц в данной комбинации.
Для двоичного кода минимальное кодовое расстояние dmjn = 1, поэтому он не обладает возможностями какого-либо контроля производимых над ним действий. Чтобы получить возможность обнаруживать хотя бы ошибки единичной кратности, нужно увеличить минимальное кодовое расстояние на 1. Это и сделано для кода контроля по модулю 2 (контроля по четности/нечетности).
При этом способе контроля каждое слово дополняется контрольным разрядом, значение которого подбирается так, чтобы сделать четным (нечетным) вес каждой кодовой комбинации. При одиночной ошибке в кодовой комбинации четность (нечетность) ее веса меняется, а такая комбинация не принадлежит к данному коду, что и обнаруживается схемами контроля. При двойной ошибке четность (нечетность) комбинации не нарушается - такая ошибка не обнаруживается. Легко видеть, что у кода с контрольным разрядом
dmin = 2.
При контроле по четности вес кодовых комбинаций делают четным, при контроле по нечетности - нечетным.
Контроль по модулю 2 реализуется с помощью схем свертки. Для практики типична многоярусная схема свертки пирамидального типа.
Примером ИС свертки по модулю 2 может служить микросхема ИП5 серии КР1533 (см. рисунок 4.5,а). Схема имеет 9 входов, что допускает свертку байта с девятым контрольным разрядом. Двумя выходами схемы являются Е (Even) и О (Odd). Если вес входной комбинации четный, то Е = 1 и О = 0, и наоборот, если вес нечетный.
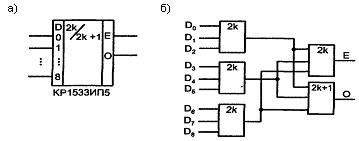
Рисунок 4.5 – Микросхема ИКР1533ИП5
Схемотехнически ИС КР1533ИП5 представляет собою пирамидальную структуру из трехвходовых элементов типа четность/нечетность (см. рисунок 4.5,б).
Передача данных с контролем по модулю 2 показана на рисунке 4.6. Входные данные обозначены через D, а на выходе из канала связи данные обозначены через D', поскольку вследствие ошибок они могут измениться.
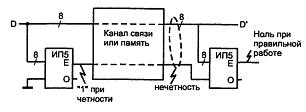
Рисунок 4.6 – Применение ИП5 для контроля канала связи (памяти)
4.2.3 Контроль с использованием кодов Хемминга.
Применение кодов Хемминга позволяет исправлять единичные ошибки приемном конце. Для получения кодовой комбинации кода Хемминга к информационному слову добавляется несколько контрольных разрядов. C целью определения значений контрольных разрядов примем, что контрольные разряды занимают позиции с номерами 2i (i = 0, 1, 2,...), т.е. 1, 2, 4, …
Каждый контрольный разряд ассоциируется с некоторой группой разрядов кодовой комбинации и выводит вес группы, в которую он входит, на четность/нечетность.
Первый контрольный разряд (1-я позиция) входит в группу разрядов с номерами, соответствующие двоичному коду хх...хх1, где х – 0 или 1. Иными словами в первую группу входят разряды с нечетными номерами: 1, 3, 5, 7, ... .
Второй контрольный разряд (2-я позиция) входит в группу разрядов с номерами, имеющими единицу во втором справа разряде, т. е. номерами, соответствующие двоичному коду хх...х1х. Это номера 2, 3, 6, 7, ... .
Третий контрольный разряд (4-я позиция) входит в группу, у которой номера разрядов имеют единицу в третьем справа разряде, соответствующий двоичному коду хх...1хх, т. е. с номерами 4, 5, 6, 7, ... .
Контрольные разряды выводят веса своих групп на четность/нечетность. Далее для определенности примем, что ведется контроль по четности. Производится столько проверок по модулю 2, сколько контрольных разрядов в кодовой комбинации, т. е. проверяется сохранение четности весов групп. Если в кодовой комбинации произошла ошибка, то в одних проверках она скажется, а в других - нет. Это и позволяет определить разряд, в котором произошла ошибка. Для восстановления правильного значения слова теперь остается только проинвертировать ошибочный разряд.
Пример: составить код Хемминга для четырехразрядного информационного слова А = а3а2а1а0 = 0110 (см. таблицу 4.3).
Таблица 4.3
|
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
|
р |
а3 |
а2 |
а1 |
р3 |
а0 |
р2 |
р1 |
|
0 1 1 0 1 0 |
0 0 0 0 0 0 |
0 0 0 0 1 1 |
0 0 1 1 0 0 |
0 0 1 1 1 1 |
0 1 0 1 0 1 |
0 1 0 1 1 0 |
0 1 1 0 0 1 |
|
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
|
1 0 … 1 |
0 1 … 1 |
1 0 … 1 |
1 0 … 1 |
0 1 … 1 |
1 0 … 1 |
0 1 … 1 |
0 0 … 1 |
Через р в таблице обозначен общий контрольный разряд для всей кодовой комбинации, через p1, р2, р3 - первый, второй и третий групповые контрольные разряды.
Не учитывая пока разряд р, получим, что правильная кодовая комбинация имеет вид:
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
|
0 |
1 |
1 |
0 |
0 |
1 |
1 |
Пусть во втором слева разряде (в 6-м разряде) произошла ошибка и принята комбинация:
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
|
0 |
0 |
1 |
0 |
0 |
1 |
1 |
Первая проверка (по группе разрядов с нечетными номерами) показывает сохранение четности, т. е. в этой группе ошибок нет, результат этой проверки отмечается нулем.
Вторая проверка (по разрядам 2, 3, 6, 7) обнаруживает нарушение четности веса комбинации, ее результат отмечается единицей.
Третья проверка (по разрядам 4, 5, 6, 7) также обнаруживает нарушение четности, ее результат отмечается единицей.
Результаты проверок образуют слово, называемое синдромом. Синдром указывает номер разряда, в котором произошла ошибка. В этом примере результаты проверок дают слово 110 = 610. Проинвертировав разряд номер 6, возвращаемся к правильной кодовой комбинации - ошибка исправлена.
Минимальное кодовое расстояние обычного кода Хемминга равно dmin =3. Добавление p разряда проверки общей четности приводит к модифицированному коду Хемминга с dmin = 4 и, соответственно, добавляет возможность обнаружения двойной ошибки. Обнаружение двойной ошибки основано на сопоставлении наличия или отсутствия признаков ошибки в синдроме и общей четности. Если обозначить через S любое ненулевое значение синдрома, то возможные ситуации, используемые для обнаружения двойной ошибки, окажутся следующими (см. таблицу 4.4).
Таблица 4.4
|
Синдром |
Свертка кода |
Результат |
|
0 |
0 |
Все правильно |
|
S |
1 |
Была единичная ошибка, исправлена |
|
S |
0 |
Есть ошибка двойной и большей кратности, слово использовать нельзя |
|
0 |
1 |
Код Хемминга относится к числу простых. Есть много более сложных кодов с большими корректирующими возможностями (БЧХ, код Файра, код Рида- Соломона и др.).
5 Лекция. Сумматоры
Сумматоры выполняют арифметическое сложение и вычитание чисел, являются ядром схем арифметико-логических устройств (АЛУ) процессоров.
5.1 Одноразрядный сумматор
Одноразрядный сумматор имеет три входа (два слагаемых и перенос из предыдущего разряда) и два выхода (суммы и переноса в следующий разряд).
Таблица 5.1 - Таблица истинности одноразрядного сумматора
|
ai |
bi |
ci-1 |
Si |
Ci |
|
0 |
0 |
0 |
0 |
0 |
|
0 |
0 |
1 |
1 |
0 |
|
0 |
1 |
0 |
1 |
0 |
|
0 |
1 |
1 |
0 |
1 |
|
1 |
0 |
0 |
1 |
0 |
|
1 |
0 |
1 |
0 |
1 |
|
1 |
1 |
0 |
0 |
1 |
|
1 |
1 |
1 |
1 |
1 |
Аналитические выражения функций суммы и переноса (С от англ. carry) имеют вид
![]() .
(5.1)
.
(5.1)
![]() .
(5.2)
.
(5.2)
Из таблицы 5.1 видно, что во всех строчках, кроме первой и последней,
![]() .
(5.3)
.
(5.3)
Формула (5.3) будет справедливой для всех строк
таблицы 5.1, если в 1-й строке было не ![]() , а
, а ![]() , т.е. по формуле (5.3) соблюдалось
равенство 0=1∙0 (проинвертировать функцию переноса
, т.е. по формуле (5.3) соблюдалось
равенство 0=1∙0 (проинвертировать функцию переноса ![]() ) и в последней строке добавить
) и в последней строке добавить ![]() .
.
С учетом этого формула (5.3) примет окончательный вид
![]() .
(5.4)
.
(5.4)
Схема сумматора, реализующая выражения (5.2 и 5.4), показана на рисунке 5.1,а.
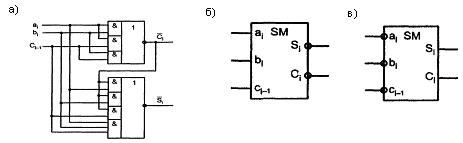
Рисунок 5.1 – Схема одноразрядного сумматора и условные обозначения (б,в)
Функция суммы Si, и функция переноса Ci обладают свойством самодвойственности (см. таблицу 5.1): при инвертировании всех аргументов инвертируется и значение функции, т. е.
![]() .
(5.5)
.
(5.5)
5.2 Последовательный сумматор
Сумматор для последовательных операндов содержит всего один одноразрядный сумматор, обрабатывающий поочередно разряд за разрядом, начиная с младшего. Сложив младшие разряды, одноразрядный сумматор вырабатывает сумму для младшего разряда результата и перенос, который запоминается на один такт. В следующем такте складываются вновь поступившие разряды слагаемых a1 и b1 с переносом из младшего разряда и т. д.
Схема сумматора последовательных операндов (см. рисунок 5.2,а), помимо сумматора, содержит сдвигающие регистры слагаемых A,B и суммы S, а также D-триггер запоминания переноса. Регистры A,B,S и D-триггер тактируются синхроимпульсами СИ. На рисунке 5.2,6 показана временная диаграмма, соответствующая операции сложения двух операндов 101 + 110= 1011 или в десятичном выражении 5 + 6 = 11.
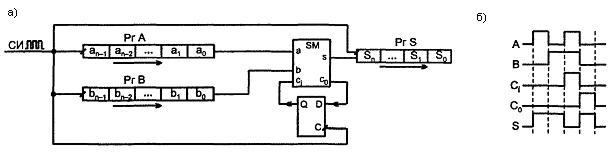
Рисунок 5.2 – Схема последовательного сумматора (а) и
временная диаграмма (б)
5.3 Параллельный сумматор с последовательным переносом
Сумматор для параллельных операндов с последовательным переносом строится как цепочка одноразрядных, соединенных последовательно по цепям переноса. Для схемы с одноразрядными сумматорами, вырабатывающими инверсии суммы и переноса, такая цепочка имеет вид, приведенный на рисунке 5.3, поскольку функции суммы и переноса самодвойственны (5.5). Там, где в разряд сумматора должны подаваться инверсные аргументы, в их линиях имеются инверторы, а там, где вырабатывается инверсная сумма, инвертор включен в выходную цепь.
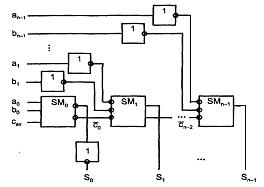
Рисунок 5.3 – Схема параллельного сумматора с последовательным переносом
5.4 Параллельный сумматор с параллельным переносом
Сумматоры для параллельных операндов с параллельным переносом разработаны для получения максимального быстродействия.
Сумматоры с параллельным переносом не имеют последовательного распространения переноса вдоль разрядной сетки. Во всех разрядах результаты вырабатываются одновременно, параллельно во времени. Сигналы переноса для данного разряда формируются специальными схемами, на входы которых поступают все переменные, необходимые для выработки переноса, т. е. те, от которых зависит его наличие или отсутствие. Одноразрядные сумматоры, имеющиеся в разрядных схемах, здесь упрощены, т. к. от них выход переноса не требуется, достаточно одного выхода суммы (см. рисунок 5.4). Обозначение CR от слова саrrу (перенос).
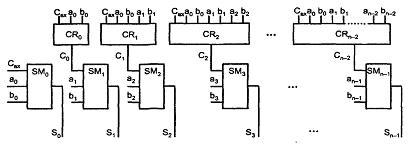
Рисунок 5.4 – Структура сумматора с параллельным переносом
Функция генерации принимает 1, если перенос на выходе данного разряда появляется независимо от наличия или отсутствия входного переноса. Очевидно, что эта функция gi = аibi.
Функция прозрачности (транзита) принимает 1, если
перенос на выходе данного разряда появляется только при наличии входного
переноса. Эта функция hi
=
aivbi.
Строго говоря, ![]() , но т. к. при аi
= bi
= 1, т. е. в ситуации, где между функциями ИЛИ и ИСКЛЮЧАЮЩЕЕ ИЛИ проявляется
разница, перенос все равно формируется из-за gi = 1, допустимо
заменить функцию прозрачности на дизъюнкцию. Теперь выражение для сигнала
переноса можно записать в виде
, но т. к. при аi
= bi
= 1, т. е. в ситуации, где между функциями ИЛИ и ИСКЛЮЧАЮЩЕЕ ИЛИ проявляется
разница, перенос все равно формируется из-за gi = 1, допустимо
заменить функцию прозрачности на дизъюнкцию. Теперь выражение для сигнала
переноса можно записать в виде ![]() .
.
Для произвольного разряда с номером i можно записать
![]() . (5.6)
. (5.6)
Предпочтительна схема на элементах И-НЕ (у стандартных элементов имеется до восьми входов по И). Перевод полученных выражений в базис И-НЕ дает выражения
![]() ,
,
![]() ,
,
![]() .
(5.7)
.
(5.7)
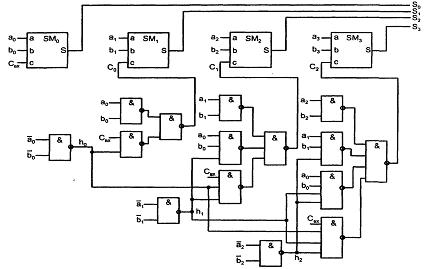
Рисунок 5.5 – Вариант схемы сумматора с параллельным переносом
Схема сумматора (см. рисунок 5.5) соответствует полученным выражениям. Диапазон разрядностей, в которых проявляются достоинства сумматоров с параллельным переносом, невелик. До n = 3...4 применяются схемы сумматоров с последовательным переносом, до n = 8 с параллельным переносом, а после n = 8 – сумматоры групповой структуры.
5.5 Сумматоры групповой структуры
В сумматорах групповой структуры схема с разрядностью n делится на L групп по m разрядов (n = Lm). В группах и между ними возможны различные виды переносов, что порождает множество вариантов групповых сумматоров. Ниже рассмотрены основные варианты: с последовательным и параллельным переносами между группами. Групповой сумматор с последовательным переносом при L группах имеет L - 1 блоков переноса. Блоки переноса включены последовательно и образуют тракт передачи переноса (см. рисунок 5.6). Слагаемые разбиты на m-разрядные поля, суммируемые в группах. Результат также составляется из m-разрядных полей.
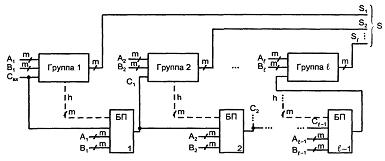
Рисунок 5.6 – Схема группового сумматора с последовательным переносом
Блоки переноса БПi (i = 1...) анализируют слагаемые в пределах группы, и если из группы должен быть перенос, то он появляется на выходе блока для подачи на вход следующей группы и в цепочку распространения переноса от младших групп к старшим.
Сумматор с параллельными межгрупповыми переносами строится по структуре, сходной со структурой сумматора с параллельным переносом, в которой роль одноразрядных сумматоров играют группы.
При построении обычного сумматора с параллельными переносами каждый разряд характеризовался функциями генерации и прозрачности gi = aibi и hi = aivbi.
С помощью этих функций вырабатывался сигнал переноса по соотношению
![]() .
.
В групповом сумматоре с параллельными межгрупповыми переносами роль одного "разряда" играет группа, которую также характеризуют функциями генерации и прозрачности. Обозначив эти функции большими буквами, можем записать соотношения:
![]() , (5.8)
, (5.8)
согласно которому группа прозрачна при прозрачности всех ее разрядов, и
![]() ,
(5.9)
,
(5.9)
справедливость которого видна из предыдущего изложения способа построения сумматора с параллельным переносом.
Из групп собирается та же схема ,что и из одноразрядных сумматоров, с параллельными межгрупповыми переносами согласно выражению для переноса на выходе группы с номером i:
![]() .
(5.10)
.
(5.10)
Структура группового сумматора с параллельными межгрупповыми переносами показана на рисунке 5.7, где разрядность и число групп приняты равными 4. Функции прозрачности Н, могут вырабатываться как функции операндов или через использование функций прозрачности разрядов h, которые имеются в группах, если в них организован параллельный перенос (штриховые линии).
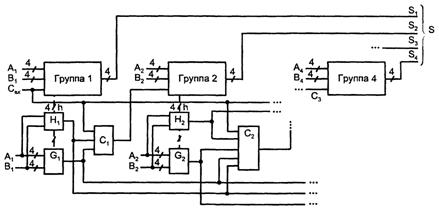
Рисунок 5.7 – Схема группового сумматора с параллельным переносом
5.5.1 Сумматор с условным переносом.
Сумматор с условным переносом - СБИС программируемой логики, улучшающая быстродействие сумматоров с последовательным переносом.
Сумматор с n разрядами делят на две равные группы с разрядностями n/2. Старшую группу дублируют, так что в схему входят три сумматора с разрядностью n/2.
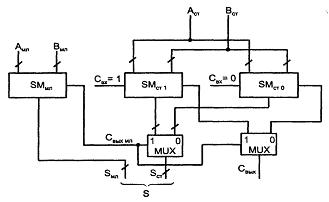
Рисунок 5.8 – Схема сумматора с условным переносом
На одном суммируются младшие поля операндов Aмл и Вмл. На втором - старшие поля операндов при условии Свх = 1, в третьем - старшие поля операндов при условии Свх = 0. После получения результата в младшем сумматоре становится известным фактическое значение переноса в старший сумматор, и из двух заготовленных заранее результатов выбирается тот, который нужен в данном случае. Цепь последовательного переноса здесь как бы укорачивается вдвое, т. к. обе половины сумматора работают параллельно во времени.
6 Лекция. АЛУ и матричные умножители
6.1 Арифметико-логические устройства
Основой АЛУ (Arithmetic-Logic Unit) служит сумматор, схема которого дополнена логикой, расширяющей функциональные возможности и обеспечивающей его перестройку с одной операции на другую. Обычно АЛУ четырехразрядные и для наращивания разрядности объединяются с формированием последовательных или параллельных переносов. Логические возможности АЛУ разных технологий (ТТЛШ, КМОП, ЭСЛ) сходны.
АЛУ (см. рисунок 6.1) имеет входы операндов А и В, входы выбора операций S, вход переноса Ci и вход М (Mode), сигнал которого задает тип выполняемых операций: логические (М = 1) или арифметико-логические (М = 0). Результат операции вырабатывается на выходах F, выходы G и Н дают функции генерации и прозрачности, используемые для организаций параллельных переносов при наращивании размерности АЛУ. Сигнал Со - выходной перенос, а выход А = В - выход сравнения на равенство с открытым коллектором.
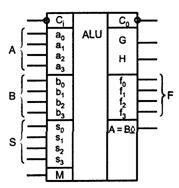
Рисунок 6.1 – Условное обозначение АЛУ
Перечень выполняемых АЛУ операций дан в таблице 6.1. Для краткости двоичные числа S3S2S1S0 представлены их десятичными эквивалентами. Входной перенос поступает в младший разряд слова - 000Сi. Логические операции поразрядные. При арифметических операциях учитываются межразрядные переносы.
16 логических операций позволяют воспроизводить все функции двух переменных. В арифметико-логических операциях встречаются и логические и арифметические операции одновременно.
Например, ![]() - вначале поразрядно выполняются операции
инвертирования (В), логического сложения (АvВ) и умножения
(АВ), а затем полученные указанным образом два четырехразрядных числа
складываются арифметически.
- вначале поразрядно выполняются операции
инвертирования (В), логического сложения (АvВ) и умножения
(АВ), а затем полученные указанным образом два четырехразрядных числа
складываются арифметически.
При операциях над словами большой размерности АЛУ соединяются друг с другом с организацией последовательных (см. рисунок 6.2,а) или параллельных (см. рисунок 6.3,б) переносов. В последнем случае совместно с АЛУ применяют микросхемы - блоки ускоренного переноса (CRU, Carry Unit), получающие от отдельных АЛУ функции генерации и прозрачности, а также входной перенос и вырабатывающие сигналы переноса по известным формулам.
Таблица 6.1 – Перечень операций АЛУ
|
S |
Логические функции (М=1) |
Арифметико-логические функции (М=0) |
|
0 1 2 3 |
0000 |
A + Ci
1111 +Ci |
|
4 5 6 7 |
|
|
|
8 9 10 11 |
В АВ |
A + AB + Ci A + B + Ci
AB + 1111 + Ci |
|
12 13 14 15 |
1111
А |
A + A + Ci A v B + A + Ci
A + 1111 + Ci |
Блок CRU вырабатывает также функции генерации и прозрачности для всей группы обслуживаемых им АЛУ, что при необходимости позволяет организовать параллельный перенос на следующем уровне (между несколькими группами из четырех АЛУ).
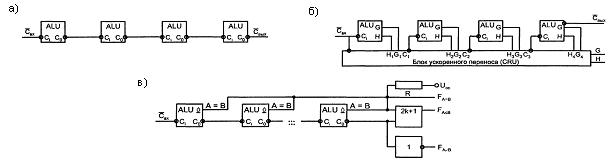
Рисунок 6.2 - Схемы наращивания АЛУ при последовательном (а) и параллельном (б) переносах и реализация функций компаратора для группы (в)
На рисунке 6.2,в показаны способы выработки сигналов сравнения слов для группы АЛУ. Выход сравнения на равенство выполняется по схеме монтажной логики для выходов типа ОК. Комбинируя сигнал равенства слов с сигналом переноса на выходе группы при работе АЛУ в режиме вычитания, легко получить функции Fa≥b и Fa≤b. Если А<В, то при вычитании возникает заем из старшего разряда и Fa≤b = 1. Если заем отсутствует (А>В), то получим Fa≥b = 1.
6.2 Матричные умножители
Структура матричных умножителей тесно связана со структурой математических выражений, описывающих операцию умножения.
Пусть имеются два целых двоичных числа без знаков Am = am-1...ao и
Bn=bn-1...bo. Их перемножение выполняется по известной схеме "умножения столбиком". Если числа четырехразрядные, т. е. m = n = 4, то
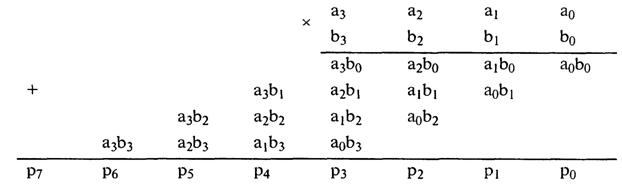
Члены вида aibj, где i = 0... (m - 1) и j = 0... (n - 1) вырабатываются параллельно во времени конъюнкторами. Их сложение в столбцах, которое можно выполнять разными способами, составляет основную операцию для умножителя и определяет почти целиком время перемножения.
Матричные перемножители могут быть просто множительными блоками (МБ) или множительно-суммирующими (МСБ), последние обеспечивают удобство наращивания размерности умножителя.
МСБ реализует операцию Р = Аm х Вn + Сm + Dn, т. е. добавляет к произведению два слагаемых: одно разрядности m, совпадающей с разрядностью множимого, другое разрядности n, совпадающей с разрядностью множителя.
6.2.1 Множительно-суммирующие блоки.
Множительно-суммирующий блок для четырехразрядных операндов без набора конъюнкторов, вырабатывающих члены вида аibj, показан на рисунке 6.3, а, где для одноразрядного сумматора принято обозначение (см. рисунок 6.3,б).
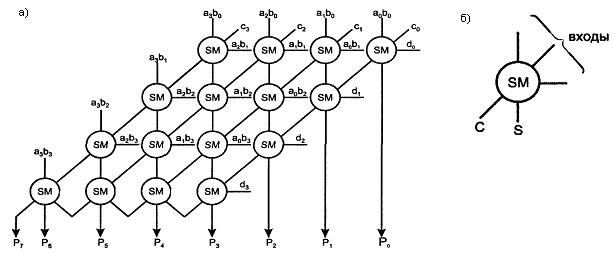
Рисунок 6.3 – Схема МСБ для четырехразрядных сомножителей (а) и обозначение одноразрядного сумматора для данной схемы (б)
Для построения МСБ чисел равной разрядности требуется n2 конъюнкторов и n2 одноразрядных сумматоров.
6.2.2 Схемы ускоренного умножения.
Рассмотрим процесс умножения по модифицированному алгоритму Бута -умножение сразу на два разряда. Уменьшение суммирований частичных произведений существенно сокращает время произведения. К этому приводит алгоритм, основанный на следующих рассуждениях.
Пусть требуется вычислить произведение
![]() . (6.1)
. (6.1)
Непосредственное воспроизведение соотношения (6.1) связано с выработкой частичных произведений вида
Abi2i (i = 0...n - 1). (6.2)
Число таких произведений равно разрядности множителя n.
Выражение (6.1) можно видоизменить с помощью соотношения
![]() . (6.3)
. (6.3)
Это соотношение позволяет разреживать последовательность степеней в сумме частичных произведений. Можно, например, исключить четные степени, как показано на рисунке 6.4.
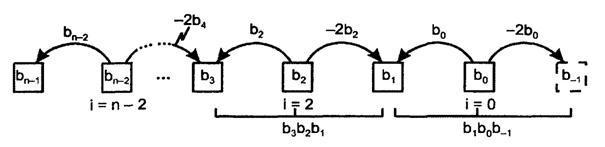
Рисунок 6.4 – Исключение четных степеней множителя
Исключение четных (или нечетных) степеней не только изменяет значения оставшихся частичных произведений, но и сокращает их число примерно вдвое, что ускоряет выработку произведения. По формуле (6.3) для расширения разрядной сетки "разносят по соседям" члены с четными степенями b222,bo2o,
b-22-2 в выражении (6.1) для множителя В.
После чего оставшиеся частичные произведения для любого i-го разряда имеют вид
![]() .
(6.4)
.
(6.4)
Если сравнить (6.1) и (6.4), то частичных произведений уменьшилось примерно вдвое. При применении этого алгоритма говорят об умножении сразу на два разряда (левые i+1 и правые i-1 коэффициенты от четного разряда i).
Используя (6.4) для всех возможных сочетаний bi+1, bi, bi-1, можно составить таблицу 6.2 частичных произведений.
Таблица 6.2
|
bi+1 |
bi |
bi-1 |
Значение скобки |
Ri/2i |
Операция для получения Ri/2i |
|
0 |
0 |
0 |
0 |
0 |
Замена А нулем |
|
0 |
0 |
1 |
1 |
А |
Скопировать А |
|
0 |
1 |
0 |
1 |
А |
Скопировать А |
|
0 |
1 |
1 |
2 |
2А |
Сдвиг А влево |
|
1 |
0 |
0 |
-2 |
-2А |
Сдвиг А влево и перевод в доп.код |
|
1 |
0 |
1 |
-1 |
-А |
Перевод А в доп.код |
|
1 |
1 |
0 |
-1 |
-А |
Перевод А в доп.код |
|
1 |
1 |
1 |
0 |
0 |
Замена А нулем |
Пример.
Пусть требуется умножить 1010 на 0111, т. е. 10∙7 = 70. При разреживании частичных произведений оставим только нечетные (см. рисунок 6.4).
Тогда по формуле (6.4) получим
![]() .
.
Из полученного выражения видно, что необходимо расширить разрядную сетку множителя В влево на 1 разряд и вправо на 2 разряда, т.е.
В = b4b3b2b1bob-1b-2 = 0011100.
Первому частичному произведению соответствует тройка bob-1b-2 = 100. Из таблицы 6.2 получаем, что этой тройке соответствует частичное произведение
R-1 = -2А∙2-1 = -А,
для получения которого требуется перевести А в дополнительный код. Сама величина А в пределах разрядной сетки произведения должна быть записана как 0001010, ее обратный код 1110101 и дополнительный код 1110110.
Второму частичному произведению соответствует тройка b2b1bo = 111, следовательно, второе частичное произведение равно R1 = 0 (см. таблицу 6.2).
Третьему частичному произведению соответствует тройка b4b3b2 = 001, следовательно, оно имеет вид R3 = А∙23 = 1010000 (сдвиг А на 3 разряда влево).
Для получения результата заданного умножения требуется сложить частичные произведения:
1110110
1010000
-----------
1000110 = 26 + 22 + 21 = 64 + 4 + 2 =70.
Схема, реализующая алгоритм быстрого умножения, показана на рисунке 6.5.
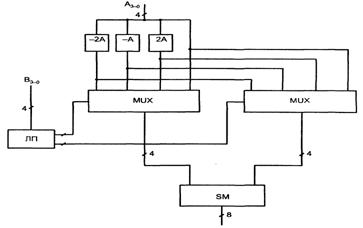
Рисунок 6.5 – Схема быстрого умножения
Множимое А поступает на ряд преобразователей, заготавливающих все возможные варианты частичных произведений (-2А, -А, 2А), кроме самого А и нуля, которые не требуют схемной реализации. Множитель В поступает на логический преобразователь ЛП, который анализирует тройки разрядов, декодирует их и дает мультиплексорам (MUX) сигналы выбора того или иного варианта частичных произведений (см. таблицу 6.2). Окончательный результат получается путем суммирования частичных произведений с учетом их взаимного сдвига в разрядной сетке. Размерность умножителя «4х4».
7 Лекция. Триггеры и регистры
7.1 Триггеры
Триггеры - элементарные автоматы, содержащие элемент памяти (фиксатор) и схему управления. Фиксатор строится на двух инверторах, связанных друг с другом "накрест", так что выход одного соединен с входом другого. Такое соединение дает цепь с двумя устойчивыми состояниями (см. рисунок 7.1.). Если на выходе инвертора 1 имеется логический ноль, то он обеспечивает на выходе инвертора 2 логическую единицу и наоборот.
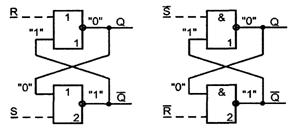
Рисунок 7.1 – Варианты схем асинхронного RS-триггера
Установочные сигналы показаны на рисунке 7.1
штриховыми линиями. Буквой R латинского алфавита (от Reset) обозначен сигнал
установки триггера в 0 (сброса), а буквой S (от Set) - сигнал установки в
состояние логической 1 (установки). Состояние триггера считывается по значению
прямого выхода, обозначаемого как Q или второго выхода с инверсным сигналом ![]() . Для
RS-триггера
на элементах ИЛИ-НЕ установочным сигналом является 1, поскольку только он
приводит логический элемент в 0 независимо от сигналов на других входах
элемента (см. рисунок 7.1,а). Для RS-триггера на элементах И-НЕ
установочным сигналом является нулевой (см. рисунок 7.1,б).
. Для
RS-триггера
на элементах ИЛИ-НЕ установочным сигналом является 1, поскольку только он
приводит логический элемент в 0 независимо от сигналов на других входах
элемента (см. рисунок 7.1,а). Для RS-триггера на элементах И-НЕ
установочным сигналом является нулевой (см. рисунок 7.1,б).
7.1.1 Классификация триггеров.
Классификация триггеров проводится по признакам логического функционирования и способу записи информации (см. рисунок 7.2).
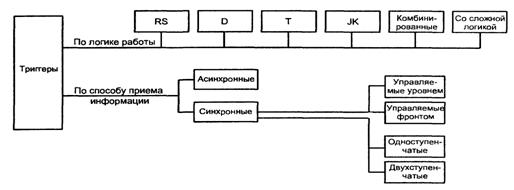
Рисунок 7.2 – Классификация триггеров
По логическому функционированию различают триггеры типов RS, D, T, JK и др. Кроме того, используются комбинированные триггеры, в которых совмещаются одновременно несколько типов, и триггеры со сложной входной логикой (группами входов, связанных между собой логическими зависимостями).
Триггер типа RS имеет два входа - установки в единицу (S) и установки в ноль (R). Одновременная подача сигналов установки S и сброса R не допускается (эта комбинация сигналов называется запрещенной).
Триггер типа D (от слова Delay - задержка) имеет один вход. Его состояние повторяет входной сигнал, но с задержкой, определяемой тактовым сигналом.
Триггер типа Т изменяет свое состояние каждый раз при поступлении входного сигнала. Имеет один вход, называется триггером со счетным входом или счетным триггером.
Триггер типа JK универсален, имеет входы установки (J) и сброса (К), подобные входам триггера RS. В отличие от последнего, допускает ситуацию с одновременной подачей сигналов на оба входа (J = К = 1). В этом режиме работает как счетный триггер относительно третьего (тактового) входа.
В комбинированных триггерах совмещаются несколько режимов. Например, триггер типа RST - счетный триггер, имеющий также входы установки и сброса.
Примером триггера со сложной входной логикой служит JK-триггер с группами входов J1J2J3 и К1К2К3, соединенными операцией конъюнкции:
![]() .
.
По способу записи информации различают асинхронные (нетактируемые) и синхронные (тактируемые) триггеры. В нетактируемых переход в новое состояние вызывается непосредственно изменениями входных информационных сигналов. В тактируемых, имеющих специальный вход С(от слова Clock), переход происходит только при подаче на этот вход тактовых сигналов. Тактовые сигналы называют также синхронизирующими, исполнительными, командными и т. д.
По способу восприятия тактовых сигналов триггеры делятся на управляемые уровнем и управляемые фронтом. Управление уровнем означает, что при одном
уровне тактового сигнала триггер воспринимает входные сигналы и реагирует на них, а при другом не воспринимает и остается в неизменном состоянии. При управлении фронтом разрешение на переключение дается только в момент перепада тактового сигнала (на его фронте или спаде).
Триггеры, управляемые фронтом, называют также триггерами с динамическим управлением. Динамический вход может быть прямым или инверсным. Прямое динамическое управление означает разрешение на переключение при изменении тактового сигнала с нулевого значения на единичное, инверсное - при изменении тактового сигнала с единичного значения на нулевое.
По характеру процесса переключения триггеры делятся на одноступенчатые и двухступенчатые.
В одноступенчатом триггере переключение в новое состояние происходит сразу, в двухступенчатом - по этапам. Двухступенчатые триггеры состоят из входной и выходной ступеней. Переход в новое состояние происходит в обеих ступенях поочередно. Один из уровней тактового сигнала разрешает прием информации во входную ступень при неизменном состоянии выходной ступени. Другой уровень тактового сигнала разрешает передачу нового состояния из входной ступени в выходную.
На рисунке 7.3 показаны процессы, происходящие в синхронных (тактируемых) триггерах. На диаграммах тактовых импульсов отмечено содержание процессов на отдельных этапах, под диаграммами даны обозначения входов для соответствующих триггеров.
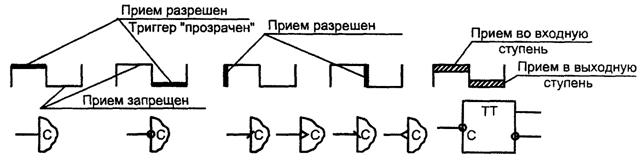
Рисунок 7.3 - Временные диаграммы, поясняющие работу синхронных триггеров, и условные обозначения тактирующих входов
В схемах буферных регистров используется термин "триггер-защелка" (Latch). Под этим понимается триггер, который прозрачен при одном уровне тактового сигнала и переходит в режим хранения при другом. Двухступенчатый триггер обозначается двумя буквами ТТ. Двухступенчатые триггеры часто называют также триггерами типа MS (англ. Master-Slave, т. е. хозяин - раб): входная ступень вырабатывает новое значение выходной переменной Q, а выходная его копирует.
С синхронизацией (тактированием) триггера связаны два параметра - время предустановки tSU (Set-Up Time) и время выдержки tH (Hold Time).
Время tSU - это интервал до поступления синхросигнала, в течение которого информационный сигнал должен оставаться неизменным (см. рисунок 7.4).
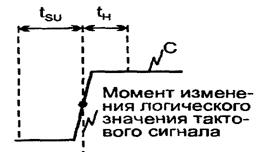
Рисунок 7.4 – Время нарастания переднего фронта синхроимпульса
Время выдержки tH - это время после поступления синхросигнала, в течение которого информационный сигнал должен оставаться неизменным. Соблюдение времен предустановки и выдержки обеспечивает правильное восприятие триггером входной информации.
7.1.2 Схемотехника триггеров.
Между триггерами RS и D с одной стороны и Т, JK с другой имеется существенная разница. RS, D-триггеры имеют разомкнутую структуру, а Т, JK-триггеры замкнутую с обратной связью, т.е. используют выходные сигналы для воздействия на свои входы.
D-триггер получается из триггера RS, если подавать на вход S значение D, а на вход R его инверсию (см. рисунок.7.5,а). Информационный сигнал D запоминается только в момент синхроимпульса С (см. рисунок 7.5,б).
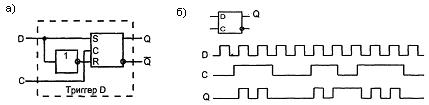
Рисунок 7.5 – Схема D-триггера (а) и временная диаграмма (б)
Т-триггер образуется на основе триггера RS по схеме (см. рисунок 7.6,а). В этом случае роль счетного входа играет тактирующий вход С.
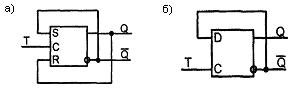
Рисунок 7.7 – Схема Т-триггера
При каждом разрешении приема информации по входу тактирования С Т-триггер по обратным связям принимает состояние, противоположное текущему, т. е. переключается. Т-триггер аналогичным способом можно получить и на основе D-триггера (см. рисунок 7.6, б).
Работоспособность счетного Т-триггера обеспечивается применением в рассматриваемой структуре непрозрачных триггеров (двухступенчатых или с динамическим управлением) или внутренних задержек.
Схема JK-триггера (см. рисунок 7.7) зависит от таблицы 7.1.
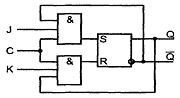
Рисунок 7.7 – Схема JK-триггера
Таблица 7.1 – Таблица истинности JK-триггера
|
J |
K |
Qн |
|
0 |
0 |
Q |
|
0 |
1 |
0 |
|
1 |
0 |
1 |
|
1 |
1 |
|
Во избежание режима генерации, как и для счетного Т-триггера, здесь требуется применять RS-триггер двухступенчатого типа или с динамическим управлением.
7.2 Регистры
7.2.1 Классификация регистров.
Регистры оперируют с множеством связанных переменных, составляющих слово. Над словами выполняется ряд операций: прием, выдача, хранение, сдвиг в разрядной сетке, поразрядные логические операции.
Регистры состоят из разрядных схем, в которых имеются триггеры и логические элементы.
По количеству линий передачи переменных регистры делятся на однофазные и парафазные, по системе синхронизации на однотактные, двухтактные и многотактные.
Однако главным классификационным признаком является способ приема и выдачи данных. По этому признаку различают параллельные (статические) регистры, последовательные (сдвигающие) и параллельно-последовательные.
В параллельных регистрах прием и выдача слов производятся по всем разрядам одновременно. В них хранятся слова, которые могут быть подвергнуты поразрядным логическим преобразованиям.
В последовательных регистрах слова принимаются и выдаются разряд за разрядом. Их называют сдвигающими, т. к. тактирующие сигналы при вводе и выводе слов перемещают их в разрядной сетке. Сдвигающий регистр может быть нереверсивным (с однонаправленным сдвигом) или реверсивным (с возможностью сдвига в обоих направлениях).
Последовательно-параллельные регистры имеют входы-выходы одновременно последовательного и параллельного типа. Имеются варианты с последовательным входом и параллельным выходом (SIPO, Serial Input - Parallel Output), параллельным входом и последовательным выходом (PISO).
В параллельных (статических) регистрах схемы разрядов не обмениваются данными между собой. Общими для разрядов обычно являются цепи тактирования, сброса/установки, разрешения выхода или приема, т. е. цепи управления. Пример схемы статического регистра, построенного на D- триггерах с прямыми динамическими входами, имеющего входы сброса R и выходы с третьим состоянием, управляемые сигналом EZ, показан на рисунке 7.8.
Для современной схемотехники характерно построение регистров именно на D-триггерах, преимущественно с динамическим управлением. Многие имеют выходы с третьим состоянием, некоторые регистры относятся к числу буферных, т. е. рассчитаны на работу с большими емкостными или низкоомными активными нагрузками. Это обеспечивает их работу непосредственно на магистраль (без дополнительных схем интерфейса).
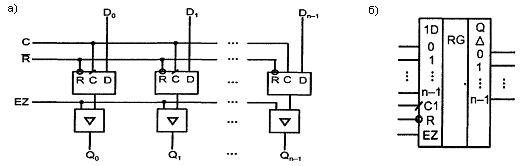
Рисунок 7.8 – Схема статического регистра (а) и его условное обозначение (б)
7.2.2 Сдвигающие регистры.
Последовательные (сдвигающие) регистры представляют собою цепочку разрядных схем, связанных цепями переноса.
В однотактных регистрах со сдвигом на один разряд вправо (см. рисунок 7.9,а) слово сдвигается при поступлении синхросигнала. Вход и выход последовательные (DSR- Data Serial Right). На рисунке 7.9,б показана схема регистра со сдвигом влево (вход данных DSL - Data Serial Left).

Рисунок 7.9 – Схема регистра сдвига вправо (а) и влево (б)
На рисунке 7.10 иллюстрируется принцип построения реверсивного регистра, в котором имеются связи триггеров с обоими соседними разрядами, но соответствующими сигналами разрешается работа только одних из этих связей.
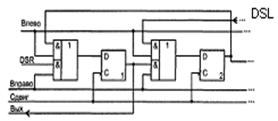
Рисунок 7.10 – Схема реверсивного регистра
8 Лекция. Двоичные счетчики
К счетчикам относят автоматы, которые под действием входных импульсов переходят из одного состояния в другое, фиксируя тем самым число поступивших на их вход импульсов в том или ином коде. Основной операцией является изменение содержимого счетчика на единицу. Прибавление такой единицы соответствует операции инкрементации (INR), вычитание - операции декрементации (DCR).
Счетчик характеризуется модулем счета М, который определяет число возможных состояний. После поступления на счетчик М входных сигналов начинается новый цикл, повторяющий предыдущий.
8.1 Классификация счетчиков
По способу кодирования внутренних состояний различают двоичные счетчики, счетчики Джонсона, счетчики с кодом «1 из N» и др.
По направлению счета счетчики делятся на суммирующие (прямого счета), вычитающие (обратного счета) и реверсивные (с изменением направления счета).
По принадлежности к тому или иному классу автоматов говорят о синхронных или асинхронных счетчиках.
Счетчики строятся из разрядных схем, имеющих межразрядные связи. Соответственно организации этих связей различают счетчики с последовательным, параллельным и комбинированными переносами.
Возможные режимы работы счетчика:
- регистрация числа поступивших на счетчик сигналов;
- деление частоты.
В первом режиме результат - содержимое счетчика, во втором режиме выходными сигналами являются импульсы переполнения счетчика.
Быстродействие счетчика характеризуется временем установления в нем нового состояния (первый режим), а также максимальной частотой входных сигналов fmax.
Как и любой автомат, счетчик можно строить на триггерах любого типа, однако удобнее всего использовать для этого триггеры типа Т (счетные) и JK, имеющие при J = К = 1 счетный режим.
Состояние счетчика читается по выходам разрядных схем как слово Qn-1Qn-2…Qo, входные сигналы поступают на младший разряд счетчика.
8.2 Двоичные счетчики
8.2.1 Последовательные и параллельные счетчики.
Двоичный счетчик - счетчик, имеющий модуль М = 2n, где n - целое число. Счетный триггер делит частоту входных импульсов на два. Поэтому счетчик может быть построен в виде цепочки последовательно включенных счетных триггеров (см. рисунок 8.1,а). Представление счетчика цепочкой Т-триггеров справедливо как для суммирующего, так и для вычитающего вариантов, поскольку закономерность по соотношению частот переключения разрядов сохраняется как при просмотре таблицы сверху вниз (прямой счет), так и снизу вверх (обратный счет).
Различия при этом состоят в направлении переключения предыдущего разряда, вызывающего переключение следующего. При прямом счете следующий разряд переключается при переходе предыдущего в направлении 1-0, а при обратном - при переключении 0-1.

Рисунок 8.1 – Структура последовательного счетчика (а) и ее реализация на триггерах с прямым динамическим управлением (б)
Следовательно, различие между вариантами заключается в разном подключении входов триггеров к выходам предыдущих. Если схема строится на счетных триггерах с прямым динамическим управлением, то характер подключения следующих триггеров к предыдущим для получения счетчиков прямого и обратного счета будет соответствовать схеме на рисунке 8.1,б.
Из различия вариантов прямого и обратного счета следует также и способ построения реверсивного счетчика (см. рисунок 8.2) путем переноса точки съема сигнала с триггера на противоположный выход под действием управляющего сигнала и с помощью элемента И-ИЛИ-НЕ, как показано на рисунке, либо элемента И-ИЛИ.
Рисунок 8.2 – Схема реверсивного счетчика
Полученные структуры относятся к асинхронным счетчикам, т. к. в них каждый триггер переключается выходным сигналом предыдущего, и эти переключения происходят не одновременно.
Максимальным быстродействием обладают синхронные счетчики с параллельным переносом. Структура суммирующего синхронного счетчика с параллельным переносом, реализованного на триггерах с управлением фронтом (см. рисунок 8.3).
Рисунок 8.3 – Схема параллельного счетчика прямого счета
8.2.2 Счетчики с групповой структурой.
В связи с ограничениями на построение параллельных счетчиков большой разрядности широкое распространение получили счетчики с групповой структурой, в которых счетчик разбивается на группы, связанные цепями межгруппового переноса (см. рисунок 8.4).
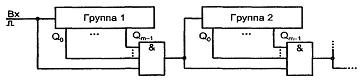
Рисунок 8.4 – Схема счетчика групповой структуры
При единичном состоянии всех триггеров группы приход очередного входного сигнала создаст перенос из этой группы. Эта ситуация подготавливает межгрупповой конъюнктор к прямому пропусканию входного сигнала на следующую группу.
Если уменьшить разрядность группы до единицы и использовать синхронные Т-триггеры, то получится схема синхронного счетчика с последовательным переносом (см. рисунок 8.5).
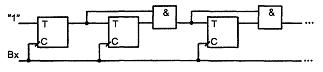
Рисунок 8.5 – Схема счетчика с последовательным переносом
Схема относится к числу синхронных, т. к. все триггеры срабатывают одновременно под действием единого входного сигнала. В этом проявляется быстрая реакция схемы на входной сигнал: она такая же, как и в счетчике с параллельным переносом. Однако по максимальной частоте входных сигналов эта схема существенно уступает схеме с параллельным переносом.
8.3 Двоично-кодированные счетчики с произвольным модулем
Счетчик с модулем, не равным целой степени числа 2, т. е. с произвольным модулем, реализуется на основе нескольких методов. Такой двоичный счетчик имеет 2n - М = L лишних состояний, подлежащих исключению.
Способы исключения лишних состояний многочисленны, и для любого М можно предложить множество реализаций счетчика. Исключая некоторое число первых состояний, получим ненулевое начальное состояние счетчика, что приводит к отсутствию естественного порядка счета и регистрации в счетчике кода с избытком. Исключение последних состояний позволяет сохранить естественный порядок счета.
Рассмотрим два способа построения счетчиков с произвольным модулем: модификации межразрядных связей и управлении сбросом.
При построении счетчика с модифицированными межразрядными связями последние, лишние, состояния исключаются непосредственно из таблицы функционирования счетчика. При этом после построения схемы обычным для синтеза автоматов способом получается счетчик, специфика которого состоит в нестандартных функциях возбуждения триггеров, и, следовательно, в нестандартных связях между триггерами, что и объясняет название способа. Схема получается как специализированная, изменение модуля счета требует изменения самой схемы, т. е. легкость перестройки с одного модуля на другой отсутствует.
При управлении сбросом выявляется момент достижения содержимым счетчика значения М-1. Это является сигналом сброса счетчика в следующем такте, после чего начинается новый цикл. Этот вариант обеспечивает легкость перестройки счетчика на другие значения модуля, т. к. требуется изменять лишь код, с которым сравнивается содержимое счетчика для выявления момента сброса.
8.3.1 Первый способ построения счетчика.
Построение счетчика первым способом проиллюстрируем примером для М = 5, начав с таблицы 8.1.
Таблица 8.1
|
Исходное состояние |
Следующее состояние |
Функция возбуждения |
||||||
|
Q2 |
Q1 |
Q0 |
Q2 |
Q1 |
Q0 |
J2 K2 |
J1 K1 |
J0 K0 |
|
0 |
0 |
0 |
0 |
0 |
1 |
0 X |
0 X |
1 X |
|
0 |
0 |
1 |
0 |
1 |
0 |
0 X |
1 X |
X 1 |
|
0 |
1 |
0 |
0 |
1 |
1 |
0 X |
X 0 |
1 X |
|
0 |
1 |
1 |
1 |
0 |
0 |
1 X |
X 1 |
X 1 |
|
1 |
0 |
0 |
0 |
0 |
0 |
X 1 |
0 X |
0 X |
При нахождении функций возбуждения триггеров использован "словарь" таблицы 8.2.
Таблица 8.2
|
Переход |
J K |
|
0→0 |
0 X |
|
0→1 |
1 X |
|
1→0 |
X 1 |
|
1→1 |
X 0 |
Вместо символа произвольного сигнала X можно
подставлять любую переменную (0 или 1). На основании таблицы 8.1 запишем: ![]() (в столбце J2 оставлена
всего одна единица), J1 = Q0,
(в столбце J2 оставлена
всего одна единица), J1 = Q0, ![]() . Для функций Ki (i
= 0, 1, 2) выберем варианты с наибольшим числом констант, чтобы меньше
нагружать источники сигналов. Примем, что К2= 1, К1 =J1
и К0 = 1.
. Для функций Ki (i
= 0, 1, 2) выберем варианты с наибольшим числом констант, чтобы меньше
нагружать источники сигналов. Примем, что К2= 1, К1 =J1
и К0 = 1.
Схема счетчика приведена на рисунке 8.6.
В спроектированной схеме счетчика лишние состояния исключены в том смысле, что они не используются при нормальном функционировании счетчика. Но при сбоях или после подачи на схему напряжения питания в начале ее работы лишние состояния могут возникать.
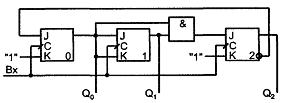
Рисунок 8.6 – Схема счетчика с модулем 5
Взяв каждое лишнее состояние, найдем для него функции возбуждения триггеров, определяющие их переходы в следующее состояние. При необходимости найдем таким же способом следующий переход и т. д. Для взятого примера лишними являются состояния 101, 110 и 111.
В состоянии 101 Q2 = 1, Q1 = 0 и Q0 = 1. Зная функции возбуждения триггеров, находим, что J0 = 0, К0 = 1, J1 = K1 = 1, J2 = 0, К2 = 1. Следовательно, триггеры 0 и 2 сбросятся, а триггер 1 переключится в противоположное текущему состояние и из лишнего состояния 101 счетчик перейдет в состояние 010. Аналогичным способом можно получить результаты для состояний 100 и 111. В итоге можно построить диаграмму состояний счетчика (граф переходов), в которой учтен не только рабочий цикл (состояния - кружки), но и поведение автомата, попавшего в неиспользуемые состояния (прямоугольники). Такая диаграмма состояний показана на рисунке 8.7.
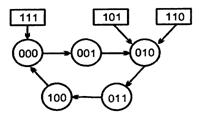
Рисунок 8.7 – Диаграмма состояний счетчика с модулем 5
Из диаграммы видно, что рассматриваемый счетчик обладает свойством самозапуска (самовосстановления после сбоя) - независимо от исходного состояния он приходит в рабочий цикл после начала работы.
8.3.2 Второй способ построения счетчика.
Второй метод построения счетчиков с произвольным модулем - метод управляемого сброса - позволяет изменять модуль счета очень простым способом, не требующим изменений самой схемы счетчика.
Рассмотрим этот способ применительно к реализации синхронного счетчика с параллельным переносом (см. рисунок 8.3). Функции возбуждения двоичного счетчика указанного типа, как известно, имеют вид Jj = Kj = Q0Q1…Qi-1 (в младшем триггере J0 = K0 = 1). Введем в эти функции сигнал сброса R, изменив их следующим образом:
![]() ,
,
Кi = Ji v R.
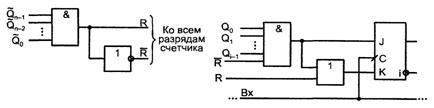
Рисунок 8.8 – Схема счетчика с управляемым сбросом
Пока сигнал сброса отсутствует (R = 0), функции Jj и Kj не отличаются от соответствующих функций двоичного счетчика. Когда сигнал R приобретает единичное значение, все функции Ji становятся нулевыми, Kj - единичными, что заставляет все триггеры сброситься по приходе следующего такта.
Если сигнал R появится как следствие появления в счетчике числа М-1, то будет реализована последовательность счета 0, 1, 2,..., М-1, 0..., т. е. счетчик с модулем М.
Схемы всех разрядов счетчика с управляемым сбросом не зависят от модуля счета. Кроме разрядных схем, счетчик содержит один конъюнктор, вырабатывающий сигнал сброса при достижении содержимым счетчика значения М-1 (см. рисунок 8.8).
9 Лекция. Запоминающие устройства
9.1 Классификация ЗУ
Для классификации ЗУ важнейшим признаком является способ доступа к данным.
При адресном доступе код на адресном входе указывает ячейку, с которой ведется обмен. Все ячейки адресной памяти в момент обращения равнодоступны.
Адресные ЗУ делятся на RAM (Random Access Memory) u ROM (Read-Only Memory). Русские синонимы термина RAM: ОЗУ (оперативные ЗУ) или ЗУПВ (ЗУ с произвольной выборкой). Оперативные ЗУ хранят данные, участвующие в обмене при исполнении текущей программы, которые могут быть изменены в произвольный момент времени. Запоминающие элементы ОЗУ, как правило, не обладают энергонезависимостью.
В ROM (русский эквивалент - ПЗУ, т. е. постоянные ЗУ) содержимое либо вообще не изменяется, либо изменяется, но редко и в специальном режиме. Для рабочего режима это "память только для чтения".
RAM делятся на статические и динамические. В первом варианте запоминающими элементами являются триггеры, сохраняющие свое состояние,
пока схема находится под питанием и нет новой записи данных. Во втором варианте данные хранятся в виде зарядов конденсаторов, образуемых элементами МОП-структур. Саморазряд конденсаторов ведет к разрушению данных, поэтому они должны периодически (каждые несколько мс) регенерироваться. Регенерация данных в динамических ЗУ осуществляется с помощью специальных контроллеров.
Статические ЗУ называются SRAM (Static RAM), а динамические - DRAM (Dynamic RAM).
Динамические ЗУ характеризуются наибольшей информационной емкостью и невысокой стоимостью, поэтому именно они используются как основная память ЭВМ.
Память типа Flash по запоминающему элементу подобна памяти типа EEPROM (или иначе E2PROM), но имеет структурные и технологические особенности, позволяющие выделить ее в отдельный вид.
В ЗУ с последовательным доступом записываемые данные образуют некоторую очередь. Считывание происходит из очереди слово за словом либо в порядке записи, либо в обратном порядке. Моделью такого ЗУ является последовательная цепочка запоминающих элементов, в которой данные передаются между соседними элементами.
Прямой порядок считывания имеет место в буферах FIFO с дисциплиной "первый пришел - первый вышел" (First In - First Out), а также в файловых и циклических ЗУ.
Разница между памятью FIFO и файловым ЗУ состоит в том, что в FIFO запись в пустой буфер сразу же становится доступной для чтения, т. е. поступает в конец цепочки (модели ЗУ). В файловых ЗУ данные поступают в начало цепочки и появляются на выходе после некоторого числа обращений, равного числу элементов в цепочке. Записываемые данные объединяют в блоки, обрамляемые специальными символами конца и начала (файлы). Прием данных из файлового ЗУ начинается после обнаружения приемником символа начала блока.
В циклических ЗУ слова доступны одно за другим с постоянным периодом, определяемым емкостью памяти. К такому типу среди полупроводниковых ЗУ относится видеопамять (VRAM).
Считывание в обратном порядке свойственно стековым ЗУ, для которых реализуется дисциплина "последний пришел — первый вышел". Такие ЗУ называют буферами LIFO (Last In — First Out).
Ассоциативный доступ реализует поиск информации по некоторому признаку, а не по ее расположению в памяти (адресу или месту в очереди). В наиболее полной версии все хранимые в памяти слова одновременно проверяются на соответствие признаку, например, на совпадение определенных полей слов (тегов — от английского слова tag) с признаком, задаваемым входным словом (теговым адресом). На выход выдаются слова, удовлетворяющие признаку. Основная область применения ассоциативной памяти в современных ЭВМ -кэширование данных.
9.2 Основные структуры ЗУ
Для статических ОЗУ и памяти типа ROM наиболее характерны структуры 2D, 3D и 2DM.
9.2.1 Структура 2D.
В структуре 2D (см. рисунок 9.1) запоминающие элементы ЗЭ организованы в прямоугольную матрицу размерностью М = k x m,
где М - информационная емкость памяти в битах;
k - число хранимых слов; m - их разрядность.
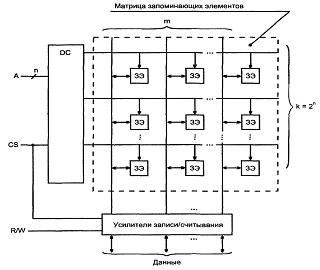
Рисунок 9.1 – Структура ЗУ типа 2D
ДШ адресного кода DC при наличии разрешающего сигнала CS (Chip Select - сигнала выбора микросхемы) активизирует одну из выходных линий, разрешая одновременный доступ ко всем элементам выбранной строки, хранящей слово, адрес которого соответствует номеру строки. Направление обмена определяется усилителями чтения/записи под воздействием сигнала R/W (Read - чтение, Write - запись).
Структура типа 2D применяется лишь в ЗУ малой емкости, т. к. число выходов дешифратора равно числу хранимых слов.
9.2.2 Структура 3D.
Структура 3D имеет двухкоординатную выборку запоминающих элементов (см. рисунок 9.2).
Код адреса разрядностью n делится на две половины, каждая из которых декодируется отдельно. Выбирается запоминающий элемент, находящийся на пересечении активных линий выходов обоих дешифраторов. Таких пересечений будет как раз
![]() .
.
Суммарное число выходов обоих дешифраторов составляет
![]() ,
,
что гораздо меньше, чем 2n при реальных значениях n.
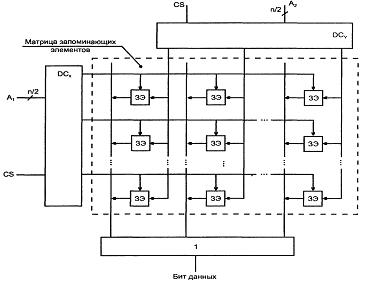
Рисунок 9.2 – Структура ЗУ типа 3D с одноразрядной организацией
9.2.3 Структура 2DM.
ЗУ типа ROM (см. рисунок 9.3) структуры 2DM для матрицы запоминающих элементов с адресацией от дешифратора DCx , который выбирает целую строку.
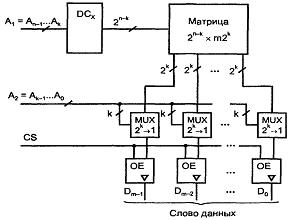
Рисунок 9.3 – Структура ЗУ типа 2DM для ROM
Однако в отличие от структуры 2D, длина строки не равна разрядности хранимых слов, а многократно ее превышает. При этом число строк матрицы уменьшается и, соответственно, уменьшается число выходов DC. Для выбора одной из строк служат не все разряды адресного кода, а их часть An-1... Ak. Остальные разряды адреса (Ak-1…A0) используются, чтобы выбрать необходимое слово из того множества слов, которое содержится в строке. Это выполняется с помощью мультиплексоров, на адресные входы которых подаются коды Ak-1…A0. Длина строки равна m2k, где m - разрядность хранимых слов. Из каждого "отрезка" строки длиной 2k мультиплексор выбирает один бит. На выходах мультиплексоров формируется выходное слово. По разрешению сигнала CS, поступающего на входы ОЕ управляемых буферов с тремя состояниями, выходное слово передается на внешнюю шину.
9.3 ЗУ типа ROM
9.3.1 Масочные ЗУ.
Элементом связи в масочных ЗУ могут быть диоды, биполярные транзисторы, МОП-транзисторы и т. д. В матрице диодного ROM(M) (см. рисунок 9.4) горизонтальные линии являются линиями выборки слов, а вертикальные - линиями считывания. Считываемое слово определяется расположением диодов в узлах координатной сетки. При наличии диода высокий потенциал выбранной горизонтальной линии передается на соответствующую вертикальную линию, и в данном разряде слова появляется сигнал логической единицы. При отсутствии диода потенциал близок к нулевому, т. к. вертикальная линия через резистор связана с землей.
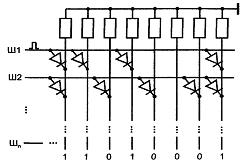
Рисунок 9.4 – Диодная матрица масочного ЗУ
9.3.2 ЗУ типа PROM.
В ЗУ типа PROM микросхемы программируются устранением специальных перемычек. После программирования остаются только необходимые.
На рисунке 9.5 показан многоэмиттерный транзистор (МЭТ) с плавкими перемычками.
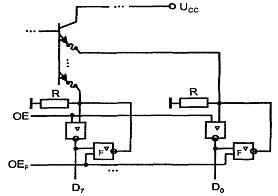
Рисунок 9.5 – Схема МЭТ с плавкими перемычками
Выходы этого ЗЭ передаются во внешние цепи через буферные каскады с тремя состояниями, работа которых разрешается сигналом ОЕ. При этом сигнал разрешения работы формирователей импульсов программирования OEF отсутствует, и они не влияют на работу схемы. При программировании буферы данных переводятся в третье состояние (ОЕ = 0), а работа формирователей F разрешается. Слово, которое нужно записать в данной ячейке, подается на линии данных D7...D0. Те разряды слова, в которых имеются единицы, будут иметь на выходах формирователей низкий уровень напряжения. Соответствующие эмиттеры МЭТ окажутся под низким напряжением и через них пройдет ток прожигания перемычки. При чтении отсутствие перемычки даст нулевой сигнал на вход буфера данных. Так как буфер инвертирующий, с его выхода снимется единичный сигнал, т. е. тот, который и записывался. Адресация обеспечивается дешифратором адреса, подающим высокий уровень потенциала на базу адресуемого МЭТ.
9.3.3 ЗУ типов EPROM и EEPROM.
В EPROM стирание выполняется с помощью облучения кристалла ультрафиолетовыми лучами, ее русское название РПЗУ-УФ (репрограммируемое ПЗУ с УФ-стиранием). В EEPROM стирание производится электрическими сигналами, ее русское название РПЗУ-ЭС (репрограммируемое ПЗУ с электрическим стиранием). Английские названия расшифровываются как Electrically Programmable ROM и Electrically Erasable Programmable ROM. Программирование PROM и репрограммирование EPROM и EEPROM производятся в лабораторных условиях с помощью либо специальных программаторов, либо специальных режимов без специальных приборов (для EEPROM).
ЗЭ современных EPROM являются транзисторы типов МНОП и ЛИЗМОП (ЛИЗ - Лавинная Инжекция Заряда).
МНОП-транзистор отличается от обычного МОП-транзистора двухслойным подзатворным диэлектриком. На поверхности кристалла расположен тонкий слой двуокиси кремния SiO2, далее более толстый слой нитрида кремния Si3N4 и затем уже затвор (см. рисунок 9.6,а).
Рисунок 9.6 – Структура транзисторов типов МНОП (а) и ЛИЗМОП
с двойным затвором (б)
На границе диэлектрических слоев возникают центры захвата заряда. Благодаря туннельному эффекту, носители заряда могут проходить через тонкую пленку окисла толщиной не более 5 нм и скапливаться на границе раздела слоев. Этот заряд и является носителем информации, хранимой МНОП-транзистором. Заряд записывают созданием под затвором напряженности электрического поля, достаточной для возникновения туннельного перехода носителей заряда через тонкий слой SiO2- На границе раздела диэлектрических слоев можно создавать заряд любого знака в зависимости от направленности электрического поля в подзатворной области.
При программировании ЗУ используются относительно высокие напряжения, около 20 В. После снятия высоких напряжений туннельное прохождение носителей заряда через диэлектрик прекращается и заданное транзистору пороговое напряжение остается неизменным.
Принцип работы ЛИЗМОП с двойным (плавающим) затвором близок к принципу работы МНОП-транзистора - здесь также между управляющим затвором и областью канала помещается область, в которую при программировании можно вводить заряд, влияющий на величину порогового напряжения транзистора (см. рисунок 9.6,б). Только область введения заряда представляет собою не границу раздела слоев диэлектрика, а окруженную со всех сторон диэлектриком проводящую область (обычно из поликристаллического кремния), в которую, как в ловушку, можно ввести заряд, способный сохраняться в ней в течение очень длительного времени. Эта область и называется плавающим затвором.
При подаче на управляющий затвор, исток и сток импульса положительного напряжения относительно большой амплитуды 20...25 В в обратно смещенных р-n переходах возникает лавинный пробой, область которого насыщается электронами. Часть электронов, имеющих энергию, достаточную для преодоления потенциального барьера диэлектрической области, проникает в плавающий затвор. Снятие высокого программирующего напряжения восстанавливает обычное состояние областей транзистора и запирает электроны в плавающем затворе, где они могут находиться длительное время.
9.4 ЗУ типа RAM
9.4.1 ОЗУ статического типа (SRAM).
В качестве элемента памяти используется простейший D-триггер-защелка. Например, в микросхеме 537РУ10 каждая ЯП состоит из восьми триггеров и располагаются ячейки на кристалле в виде прямоугольной матрицы.
На рисунке 9.7 приведены обозначения: (A0 .. An-1) - n-адресные входы; DIO(0-7) – входы к двунаправленной восьмиразрядной шине данных; OE - вход разрешения выходов; CS - вход выбора микросхемы; WE - вход разрешения записи, который часто обозначают по другому - WR/RD, подчеркивая этим, что при низком значении сигнала на этом входе производится запись байта, а при высоком уровне - чтение.
Рисунок 9.7 – Структура ЗУ типа 3D и условное обозначение
Доступ к произвольной ЯПj производится с помощью прямоугольного дешифратора, состоящего из двух обычных дешифраторов, причем k-адресных линий заводится на дешифратор столбцов (DCc), а оставшиеся n-k линий подключены к дешифратору строк (DCr). Количество строк и столбцов будет соответственно равно 2n-k и 2k, т.е. общее количество, обслуживаемых ЯП , равно 2k ∙ 2n-k = 2n.
Статическая память может быть синхронной и асинхронной. В асинхронной памяти выдача и прием информации определяется подачей комбинационных сигналов. В синхронной памяти выдача и прием информации тактируется.
9. 4.2 ОЗУ динамического типа (DRAM).
В качестве элемента памяти используется микроконденсатор в интегральном исполнении, размеры которого значительно меньше D-триггера статической памяти. По этой причине, при одинаковых размерах кристалла, информационная емкость DRAM выше, чем у SRAM. Количество адресных входов и габариты должны увеличиться. Чтобы не допустить этого, адресные линии внутри микросхемы разбиваются на две группы, например старшая и младшая половина (см. рисунок 9.8). Две одноименные k-линии каждой группы подключаются к двум выходам внутреннего k-го демультиплексора "1 в 2", а его вход соединяется с k-ым адресным входом микросхемы. Количество адресных входов, при этом уменьшается в два раза, но зато передача адреса в микросхему должна производиться, во-первых, в два приема, что несколько уменьшает быстродействие, и, во-вторых, потребуется дополнительный внешний мультиплексор адреса. В процессе хранения бита конденсатор разряжается. Чтобы этого не допустить, заряд необходимо поддерживать.
Основные отличия динамического ОЗУ от статического:
- мультиплексированием адресных входов;
- необходимостью регенерации хранимой информации;
- повышенной емкостью (до нескольких Мбит) и более сложной схемой управления.
На рисунке 9.8 приведено условное обозначение м/с 565РУ7 емкостью 256K*1 (218К) и способ подключения 18-ти линий адреса к девяти адресным входам с помощью 9-ти мультиплексоров "2 в 1", например, двух счетверенных селекторов-мультиплексоров типа 1533КП16.
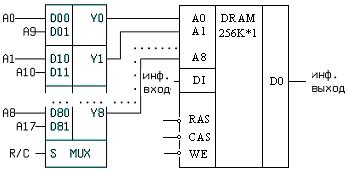
Рисунок 9.8 – Схема динамического ОЗУ
Элементы памяти расположены на кристалле в виде матрицы 512 * 512 = 29 * 29, управляемой двумя линейными дешифратороми строк и столбцов, каждый с 9-ю адресными входами (структура 3D). Если сигнал строка/столбец R/C на входе выбора S мультиплексора равен нулю, то A(0..8) = Y(0..8) и в микросхему передается адрес строки. Этот адрес фиксируется отрицательным фронтом строба адреса строк RAS. При R/C = 1 на выходы мультиплексора передается адрес столбцов A(9..17), который защелкивается отрицательным перепадом строба адреса столбцов CAS. Вход WE управляет записью/ чтением. Оперативная память персональных ЭВМ - (SIMM, EDO, SDRAM..) является динамической памятью. Время обращения к ней меньше 10нс, а емкость достигает 256M в одном корпусе.
Динамическая память может быть синхронной и асинхронной. В асинхронной памяти выдача и прием информации определяется подачей комбинационных сигналов. В синхронной памяти выдача и прием информации тактируется. DRAM работают в режиме чтения/записи и режиме регенерации.
10 Лекция. ПЛМ и ПМЛ
В цифровые системы обработки информации входят процессор, память, периферийные устройства и интерфейсные схемы. Наряду со стандартными в системе присутствуют и некоторые нестандартные части, специфичные для данной разработки. Это относится к схемам управления блоками, обеспечения их взаимодействия и др. Заказать для системы специализированные ИС высокого уровня интеграции затруднительно, т.к. это связано с очень большими затратами средств и времени на проектирование БИС/СБИС.
Возникшее противоречие нашло разрешение на путях разработки БИС/СБИС с программируемой и репрограммируемой структурой.
Первыми представителями указанного направления явились программируемые логические матрицы ПЛМ (PLA, Programmable Logic Array), программируемая матричная логика ПМЛ (PAL, Programmable Array Logic) и базовые матричные кристаллы БМК, называемые также вентильными матрицами ВМ (GA, Gate Array).
PLA и PAL в английской терминологии объединяются также термином PLD, Programmable Logic Devices.
Развитие БИС/СБИС с программируемой и репрограммируемой структурой оказалось настолько перспективным направлением, что привело к созданию новых эффективных средств разработки цифровых систем, таких как CPLD (Complex PLD), FPGA (Field Programmable GA) и SPGA (System Programmable GA). В рамках современных БИС/СБИС с программируемой и репрограммируемой структурой стала решаться и задача создания целой системы на одном кристалле.
10.1 Программируемые логические матрицы (ПЛМ)
Основой ПЛМ служит последовательность программируемых матриц элементов И и ИЛИ. В структуру входят также блоки входных и выходных буферных каскадов (БВх и БВых). Основными параметрами ПЛМ являются число входов m, число термов (конъюнкция) L и число выходов n (см. рисунок 10.1).
Рисунок 10.1 – Базовая структура ПЛМ
Входные буферы преобразуют однофазные входные сигналы в парафазные и формируют сигналы необходимой мощности для питания матрицы элементов И. Выходные буферы обеспечивают необходимую нагрузочную способность выходов, разрешают или запрещают выход ПЛМ на внешние шины с помощью сигнала ОЕ.
ПЛМ реализует дизъюнктивную нормальную форму (ДНФ) воспроизводимых функций (двухуровневую логику). Воспроизводимые функции являются комбинациями из любого числа термов, формируемых матрицей И. Какие именно термы будут выработаны и какие комбинации этих термов составят выходные функции, определяется программированием ПЛМ.
10.1.1 Схемотехника ПЛМ.
Выпускаются ПЛМ как на основе биполярной технологии, так и на МОП- транзисторах. В матрицах имеются системы горизонтальных и вертикальных связей, в узлах пересечения которых при программировании создаются или ликвидируются элементы связи.
На рисунке 10.2 показана схемотехника (без буферов) биполярной ПЛМ К556РТ1 с программированием пережиганием перемычек.
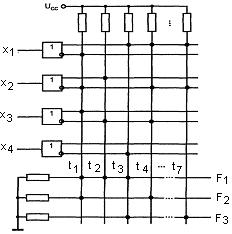
Рисунок 10.2 – Схема ПЛМ
Показан фрагмент для воспроизведения системы функций
![]() ;
;
![]() ;
;
![]() .
.
размерностью
4, 7, 3. Параметрами микросхемы К556РТ1 являются 16, 48, 8. Элементами связей в
матрице И служат диоды, соединяющие горизонтальные и вертикальные шины, как
показано на рисунке 10.3,а, изображающем цепи выработки терма
t1. Совместно с резистором и источником питания цепи
выработки термов образуют обычные диодные схемы И. При программировании в схеме
оставляются только необходимые элементы связи, а ненужные устраняются
пережиганием перемычек. В данном случае на вход конъюнктора поданы ![]() . Высокий уровень
выходного напряжения (логическая единица) появится только при наличии высоких
напряжений на всех входах.
. Высокий уровень
выходного напряжения (логическая единица) появится только при наличии высоких
напряжений на всех входах.
Элементами связи в матрице ИЛИ служат транзисторы (см. рисунок 10.3,б), включенные по схеме эмиттерного повторителя относительно линий термов и образующие схему ИЛИ относительно выхода (горизонтальной линии).
При изображении запрограммированных матриц наличие элементов связей (целые перемычки) отмечается точкой в соответствующем узле.
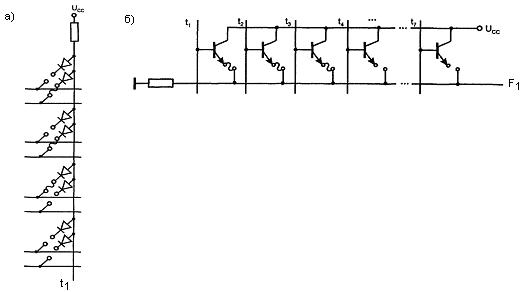
Рисунок 10.3 – Схема матриц И (а) и ИЛИ (б)
В схемах на МОП-транзисторах в качестве базовой логической ячейки используют инвертирующие (ИЛИ-НЕ, И-НЕ). Правила де Моргана, говорят о фактическом совпадении функциональных характеристик биполярной ПЛМ и ПЛМ на МОП-транзисторах: если на входы последней подавать аргументы, инвертированные относительно аргументов биполярной ПЛМ, то на выходе получим результат, отличающийся от выхода биполярной ПЛМ только инверсией.
Терм t1 в данном случае равен:
![]() ,
,
а функция:
![]() .
.
Поиск функций минимальных по числу термов следует вести до уровня, когда число термов становится равным L - параметру имеющихся ПЛМ. Дальнейшая минимизация не требуется. Если размерность имеющихся ПЛМ обеспечивает решение задачи в ее исходной форме, то минимизация не требуется вообще.
Для упрощения используются изображения схем ПЛМ, в которых многовходовые элементы И, ИЛИ условно заменяются одновходовыми. Единственная линия входа таких элементов пересекается с несколькими линиями входных переменных. Если пересечение отмечено точкой, данная переменная подается на вход изображаемого элемента, если точки нет, то переменная на элемент не подается.
С помощью ПЛМ можно воспроизводить не только дизъюнктивные нормальные формы переключательных функций, но и скобочные формы. В этом случае сначала получают выражения в скобках, а затем они рассматриваются как аргументы для получения окончательного результата. В схеме появляются обратные связи - промежуточные результаты с выхода вновь подаются на входы. Пусть, например, требуется получить функцию:
![]() .
.
Для этого следует применить включение ПЛМ по схеме (см. рисунок 10.4).
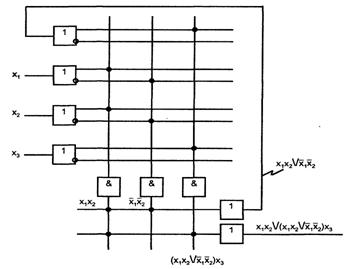
Рисунок 10.4 – Схема ПЛМ с ОС
10.2 Программируемая матричная логика (ПМЛ)
В ПМЛ (см. рисунок 10.5) выходы элементов И (выходы первой матрицы) жестко распределены между элементами ИЛИ (входами матрицы ИЛИ).
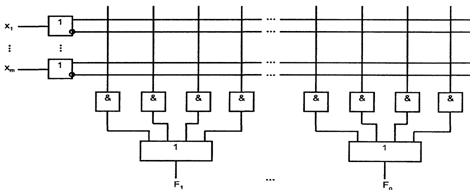
Рисунок 10.5 – Схема ПМЛ
В показанной ПМЛ m входов, n выходов и 4n элементов И, поскольку каждому элементу ИЛИ придается по четыре конъюнктора.
В сравнении с ПЛМ схемы ПМЛ имеют меньшую функциональную гибкость, т. к. в них матрица ИЛИ фиксирована, но их изготовление и использование проще.
Для ПМЛ важно уменьшить число элементов И для каждого выхода, но если для ПЛМ стремятся искать представление функции с наибольшим числом общих термов, то для ПМЛ это не требуется, поскольку элементы И фиксированы по своим выходам и не могут быть использованы другими выходами (т. е. для других функций).
10.3 Базовые матричные кристаллы
Развитие полузаказных БИС/СБИС привело к появлению ряда их разновидностей. Применительно к БМК - это канальные, бесканальные и блочные архитектуры. Термин БМК характерен для литературы на русском языке. В английской терминологии принят термин GA (Gate Array), чему соответствует русский термин - вентильная матрица.
Основа БМК первого поколения - совокупность регулярно расположенных на кристалле базовых ячеек (БЯ), между которыми имеются свободные зоны для создания соединений (каналы). Эта архитектура называется канальной.
Базовые ячейки занимают внутреннюю область БМК, в которой они расположены по строкам и столбцам, и содержат группы нескоммутированных
элементов (транзисторов, резисторов и др.). В периферийной области кристалла размешены ячейки ввода-вывода, набор схемных компонентов которых ориентирован на реализацию связей БМК с внешними цепями.
Таким образом, БМК является заготовкой, которая преобразуется в требуемую схему выполнением необходимых соединений. Потребитель может реализовать на основе БМК некоторое множество устройств определенного класса, задав для кристалла тот или иной вариант рисунка межсоединений компонентов.
Первые БМК (фирмы Amdahl Corp., США) выполнялись по схемотехнике ЭСЛ, для которой полный процесс изготовления включал 13 операций с фотошаблонами. Для изготовления схемы на основе БМК (такие схемы называют МАБИС или БИСМ) требуются только 3 индивидуальных (переменных) шаблона для задания рисунка межсоединений. Соответственно этому сроки и стоимость проектирования МАБИС в 3-5 раз меньше, чем для полностью заказных БИС/СБИС.
В настоящее время уровень интеграции БМК достиг миллионов вентилей на кристалле. При проектировании БМК стремятся наилучшим образом сбалансировать число базовых ячеек, трассировочные ресурсы кристалла и число контактных площадок для подключения внешних выводов.
Основные понятия и определения.
Базовая ячейка (БЯ) - некоторый набор схемных элементов, регулярно повторяющийся на определенной площади кристалла. Этот набор может состоять из нескоммутированных элементов, а также из частично скоммутированных. Базовые ячейки внутренней области БМК именуются матричными базовыми ячейками (МБЯ), ячейки периферийной зоны - периферийными базовыми ячейками (ПБЯ).
Применяются два способа организации ячеек БМК:
- из элементов МБЯ может быть сформирован один логический элемент, а для реализации более сложных функций используются несколько ячеек;
- из элементов МБЯ может быть сформирован любой функциональный узел, а состав элементов ячейки определяется схемой самого сложного узла.
Функциональная ячейка (ФЯ) - функционально законченная схема, реализуемая путем соединения элементов в пределах одной или нескольких БЯ.
Библиотека функциональных ячеек - совокупность ФЯ, используемых при проектировании МАБИС. Эта библиотека создается при разработке БМК и избавляет проектировщика МАБИС от работы по созданию на кристалле тех или иных типовых подсхем, т. к. предоставляет для их реализации готовые решения. Библиотека содержит большое число (сотни) функциональных элементов, узлов и их частей. Пользуясь библиотекой, проектировщик реализует схемы, работоспособность которых уже проверена, а параметры известны. Работая с библиотекой, он ведет проектирование на функционально-логическом уровне, поскольку проблемы схемотехнического уровня уже решены при создании библиотеки. Библиотечные элементы имеют различную сложность (логические элементы, триггеры, более сложные узлы или их фрагменты). В состав библиотечного элемента могут входить одна или несколько БЯ. Площадь библиотечного элемента кратна площади БЯ. При проектировании МАБИС функциональная схема изготовляемого устройства, как принято говорить, должна быть покрыта элементами библиотеки.
Эквивалентный вентиль (ЭВ) — группа элементов БМК, соответствующая возможности реализации логической функции вентиля (двухвходовой элемент И-НЕ либо ИЛИ-НЕ). Понятие "эквивалентный вентиль" предназначено для оценки логической сложности БМК.
Каналы трассировки - пути на БМК для возможного размещения межсоединений.
Трассировочная способность БМК - площадь, отводимой для межэлементных связей в ортогональных направлениях. Учитывается и число слоев межсоединений.
11 Лекция. Архитектура МПС
11.1 Основные задачи МПС
МПС решает следующие основные задачи:
- сбор информации;
- обработка;
- представление результатов измерения и (в случае необходимости) передача этих данных по каналу связи.
МПС представляет собой совокупность аппаратных (Hard Ware) и программных средств (Soft Ware). Причем аппаратные средства обеспечивают максимальную производительность или быстродействие, а программные средства - расширение круга задач, решаемых МПС.
Микропроцессор (МП) - центральная часть любой микропроцессорной системы - включает в себя АЛУ и устройство управления, реализующее командный цикл. МП может функционировать только в составе МПС, включающей в себя память, устройства ввода/вывода, вспомогательные схемы (тактовый генератор, контроллеры прерываний и ПДП, шинные формирователи, регистры-защелки и др.).
Все команды, выполняемые процессором, образуют систему команд процессора. Структура и объем системы команд процессора определяют его быстродействие, гибкость, удобство использования. Всего команд у процессора может быть от нескольких десятков до нескольких сотен. Система команд может быть рассчитана на узкий круг решаемых задач (специализированные процессоры) или на максимально широкий круг задач (универсальные процессоры). Коды команд могут иметь различное количество разрядов (занимать от 1 до 8 байт). Каждая команда имеет свое время выполнения, поэтому время выполнения всей программы зависит не только от количества команд в программе, но и от того, какие именно команды используются.
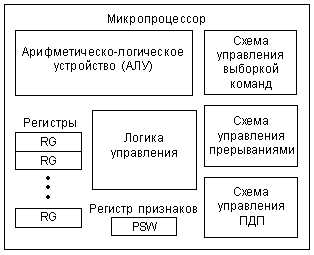
Рисунок 11.1 - Структура простейшего процессора
11.2 Шинная структура связей
Для достижения максимальной универсальности и упрощения протоколов обмена информацией в микропроцессорных системах применяется так называемая шинная структура связей между отдельными устройствами, входящими в систему.
При шинной структуре связей все сигналы между устройствами передаются по одним и тем же линиям связи, но в разное время (это называется мультиплексированной передачей). Причем передача по всем линиям связи может осуществляться в обоих направлениях (так называемая двунаправленная передача). В результате количество линий связи существенно сокращается, а правила обмена (протоколы) упрощаются. Группа линий связи, по которым передаются сигналы или коды называется шиной (англ. bus).
Достоинство: все устройства, подключенные к шине, должны принимать и передавать информацию по одним и тем же правилам (протоколам обмена информацией по шине). Соответственно, все узлы, отвечающие за обмен с шиной в этих устройствах, должны быть единообразны, унифицированы.
Недостаток: все устройства подключаются к каждой линии связи параллельно. Поэтому неисправность любого устройства может вывести из строя всю систему, если она портит линию связи.
В системах с шинной структурой связей применяют все три существующие разновидности выходных каскадов цифровых микросхем:
- стандартный выход или выход с двумя состояниями (обозначается 2С, 2S, реже ТТЛ, TTL);
- выход с открытым коллектором (обозначается ОК, OC);
- выход с тремя состояниями или (что то же самое) с возможностью отключения (обозначается 3С, 3S).
У выхода 2С два ключа замыкаются по очереди, что соответствует уровням логической единицы (верхний ключ замкнут) и логического нуля (нижний ключ замкнут). У выхода ОК замкнутый ключ формирует уровень логического нуля, разомкнутый - логической единицы. У выхода 3С ключи могут замыкаться по очереди (как в случае 2С), а могут размыкаться одновременно, образуя третье, высокоимпедансное, состояние. Переход в третье состояние (Z-состояние) управляется сигналом на специальном входе EZ (см. рисунок 11.2).
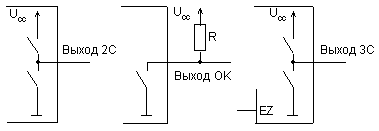
Рисунок 11.2 - Три типа выходов цифровых микросхем
Выходные каскады типов 3С и ОК позволяют объединять несколько выходов микросхем для получения мультиплексированных (см. рисунок 11.3) или двунаправленных (см. рисунок 11.4) линий.
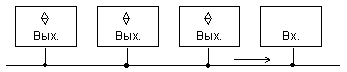
Рисунок 11.3 - Мультиплексированная линия
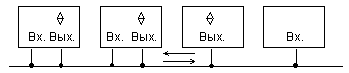
Рисунок 11.4 - Двунаправленная линия
При этом в случае выходов 3С необходимо обеспечить, чтобы на линии всегда работал только один активный выход, а все остальные выходы находились бы в это время в третьем состоянии, иначе возможны конфликты.
Объединенные выходы ОК могут работать все одновременно, без всяких конфликтов.
Типичная структура МПС приведена на рисунке 11.6. Она включает в себя три основных типа устройств:
- процессор;
- память, включающую оперативную память (ОЗУ, RAM — Random Access Memory) и постоянную память (ПЗУ, ROM —Read Only Memory), которая служит для хранения данных и программ;
- устройства ввода/вывода (УВВ, I/O - Input/Output Devices), служащие для связи микропроцессорной системы с внешними устройствами, для приема (ввода, чтения, Read) входных сигналов и выдачи (вывода, записи, Write) выходных сигналов.
Все устройства микропроцессорной системы объединяются общей системной шиной (системной магистралью). Системная магистраль включает в себя четыре основные шины нижнего уровня:
- шина адреса (Address Bus);
- шина данных (Data Bus);
- шина управления (Control Bus);
- шина питания (Power Bus).
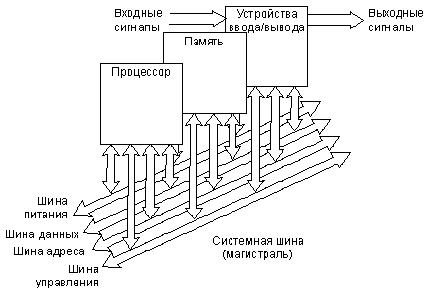
Рисунок 11.5 - Структура микропроцессорной системы
Шина адреса (ША) служит для определения адреса (номера) устройства, с которым процессор обменивается информацией в данный момент. Каждому устройству (кроме процессора), каждой ячейке памяти в микропроцессорной системе присваивается собственный адрес. Когда код какого-то адреса выставляется процессором на шине адреса, устройство, которому этот адрес приписан, понимает, что ему предстоит обмен информацией. Шина адреса может быть однонаправленной или двунаправленной.
Шина данных (ШД) - это основная шина, которая используется для передачи информационных кодов между всеми устройствами микропроцессорной системы. Обычно в пересылке информации участвует процессор, который передает код данных в какое-то устройство или в ячейку памяти или же принимает код данных из какого-то устройства или из ячейки памяти. Но возможна также и передача информации между устройствами без участия процессора. Шина данных всегда двунаправленная.
Шина управления (ШУ) в отличие от шины адреса и шины данных состоит из отдельных управляющих сигналов. Каждый из этих сигналов во время обмена информацией имеет свою функцию. Некоторые сигналы служат для стробирования передаваемых или принимаемых данных (то есть определяют моменты времени, когда информационный код выставлен на шину данных).
Шина питания предназначена не для пересылки информационных сигналов, а для питания системы. Она состоит из линий питания и общего провода. В микропроцессорной системе может быть один источник питания (чаще +5 В) или несколько источников питания (обычно еще –5 В, +12 В и –12 В). Каждому напряжению питания соответствует своя линия связи.
Для обращения к любой ячейке памяти процессор выставляет ее адрес на шину адреса и передает в нее информационный код по шине данных или же принимает из нее информационный код по шине данных. В памяти (оперативной и постоянной) находятся также и управляющие коды (команды выполняемой процессором программы), которые процессор также читает по шине данных с адресацией по шине адреса. Постоянная память используется в основном для хранения программы начального пуска микропроцессорной системы (BIOS), которая выполняется каждый раз после включения питания.
11.3 Режимы работы МПС
Практически любая развитая МПС (в том числе и компьютер) поддерживает три основных режима обмена по магистрали:
- программный обмен информацией;
- обмен с использованием прерываний (Interrupts);
- обмен с использованием прямого доступа к памяти (ПДП, DMA — Direct Memory Access).
Программный обмен информацией является основным в любой МПС. Он предусмотрен всегда, без него невозможны другие режимы обмена. В этом режиме процессор является единоличным хозяином (или задатчиком, Master) системной магистрали. Все операции (циклы) обмена информацией в данном случае инициируются только процессором, все они выполняются строго в порядке, предписанном исполняемой программой.
Обмен по прерываниям используется тогда, когда необходима реакция МПС на какое-то внешнее событие, на приход внешнего сигнала. В случае компьютера внешним событием может быть, например, нажатие на клавишу клавиатуры или приход по локальной сети пакета данных. Компьютер должен реагировать на это, соответственно, выводом символа на экран или же чтением и обработкой принятого по сети пакета.
В общем случае организовать реакцию на внешнее событие можно тремя различными путями:
- с помощью постоянного программного контроля факта наступления события (так называемый метод опроса флага или polling);
- с помощью прерывания, то есть насильственного перевода процессора с выполнения текущей программы на выполнение экстренно необходимой программы;
- с помощью прямого доступа к памяти, то есть без участия процессора при его отключении от системной магистрали.
До сих пор мы рассматривали только один тип архитектуры микропроцессорных систем — архитектуру с общей, единой шиной для данных и команд (одношинную, или принстонскую, фон-неймановскую архитектуру). Соответственно, в составе системы в этом случае присутствует одна общая память, как для данных, так и для команд (см. рисунок 11.6).
Но существует также архитектура с раздельными шинами данных и команд (двухшинная или гарвардская архитектура). Эта архитектура предполагает наличие в системе отдельной памяти для данных и отдельной памяти для команд (см. рисунок 11.7). Обмен процессора с каждым из двух типов памяти происходит по своей шине.
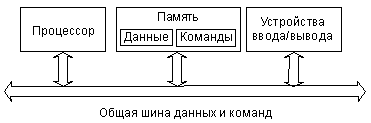
Рисунок 11.6 - Фон-нейманская архитектура МПС
Архитектура с общей шиной распространена гораздо больше, она применяется, например, в персональных компьютерах и в сложных микрокомпьютерах. Архитектура с раздельными шинами применяется в основном в однокристальных микроконтроллерах.
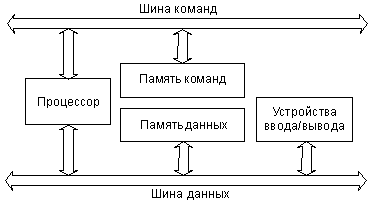
Рисунок 11.7 - Гарвардская архитектура МПС
Архитектура с общей шиной (принстонская, фон-неймановская) проще, она не требует от процессора одновременного обслуживания двух шин, контроля обмена по двум шинам сразу. Наличие единой памяти данных и команд позволяет гибко распределять ее объем между кодами данных и команд.
12 Лекция. Микропроцессор i8085
12.1 Общие сведения
Фирма Intel разработала первый МП, затем целый ряд их семейств и в настоящее время по разным оценкам производит 85...92% от общего объема выпуска микропроцессоров.
Существует множество архитектур процессоров, которые делятся на две основные категории - RISC и CISC.
RISC - Reduced (Restricted) Instruction Set Computer - процессоры с сокращенной системой команд. Эти процессоры обычно имеют набор однородных регистров универсального назначения, причем их число может быть большим. Система команд отличается относительной простотой, коды инструкций имеют четкую структуру, как правило, с фиксированной длиной. В результате аппаратная реализация такой архитектуры позволяет с небольшими затратами декодировать и выполнять эти инструкции за минимальное (в пределе 1) число тактов синхронизации.
CISC - Complete Instruction Set Computer - процессоры (компьютеры) с полным набором инструкций, к которым относится и семейство х86. Состав и назначение их регистров существенно неоднородны, широкий набор команд усложняет декодирование инструкций, на что расходуются аппаратные ресурсы. Возрастает число тактов, необходимое для выполнения инструкций. Процессоры х86 имеют самую сложную в мире систему команд. В процессорах семейства х86, начиная с 486, применяется комбинированная архитектура - CISC-процессор имеет RISC-ядро.
Различают следующие способы организации вычислительного процесса:
- один поток команд - один поток данных (Simple Instruction - Simple Data, SISD) - характерно для традиционной фон-неймановской архитектуры (иногда вместо Simple пишут Single);
- один поток команд - множественный поток данных (Simple Instruction - Multiple Data, SIMD) - технология MMX;
- множественный поток команд - один поток данных (Multiple Instruction - Simple Data, MISD);
- множественный поток команд - множественный поток данных (Multiple Instruction - Multiple Data, MIMD).
Микросхема процессора обязательно имеет выводы трех шин: шины адреса, шины данных и шины управления. Иногда некоторые сигналы и шины мультиплексируются, чтобы уменьшить количество выводов микросхемы процессора.
Важнейшие характеристики процессора - это количество разрядов его шины данных, количество разрядов его шины адреса и количество управляющих сигналов в шине управления. Разрядность шины данных определяет скорость работы системы. Разрядность шины адреса определяет допустимую сложность системы. Количество линий управления определяет разнообразие режимов обмена и эффективность обмена процессора с другими устройствами системы.
Кроме выводов для сигналов трех основных шин, процессор всегда имеет вывод (или два вывода) для подключения внешнего тактового сигнала или кварцевого резонатора (CLK), т.к. процессор представляет собой тактируемое устройство. Тактовая частота процессора определяет только его внутреннее быстродействие, а не внешнее.
Рисуок 12.1 – Схема включения процессора
Сигнал, который имеется в каждом процессоре, — это сигнал начального сброса RESET. При включении питания, при аварийной ситуации или зависании процессора подача этого сигнала приводит к инициализации процессора, заставляет его приступить к выполнению программы начального запуска. По сути, этот вход представляет собой особую разновидность радиального прерывания.
Шина питания современного процессора обычно имеет одно напряжение питания (+5В или +3,3В) и общий провод ("землю"). В некоторых процессорах предусмотрен режим пониженного энергопотребления.
Для подключения процессора к магистрали используются буферные микросхемы, обеспечивающие, если необходимо, демультиплексирование сигналов и электрическое буферирование сигналов магистрали. Иногда протоколы обмена по системной магистрали и по шинам процессора не совпадают между собой, тогда буферные микросхемы еще и согласуют эти протоколы друг с другом. Иногда в микропроцессорной системе используется несколько магистралей (системных и локальных), тогда для каждой из магистралей применяется свой буферный узел. Такая структура характерна, например, для персональных компьютеров.
12.2 Структура микропроцессора i8085
На рисунке 12.2 представлена внутренняя структура МП i8085, включающего в себя 8-разрядное АЛУ с буферным регистром и схемой десятичной коррекции, блок РОН, регистры указателя стека SP и счетчика команд PC, первичный управляющий автомат УА, буферные схемы шин адреса и данных и схему управления системой.
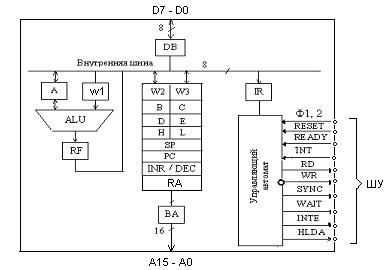
Рисунок 12.2 - Внутренняя структура МП i8085
Внешний интерфейс представлен 8-разрядной двунаправленной шиной данных D[7:0], 16-разрядной шиной адреса A[15:0] и группой линий управления.
Микропроцессор имеет внутреннюю восьмиразрядную шину данных, через которую его блоки обмениваются информацией. На схеме приняты следующие обозначения:
- AC (Accumulator) — регистр-аккумулятор, выполненный на двухступенчатых триггерах и способный хранить одновременно два слова (один из операндов и результат операции);
- W1 - регистр временного хранения одного из операндов;
-
ALU (Arithmetic-Logic Unit) — арифметико-логическое устройство, выполняющее
действия над двумя словами-операндами, подаваемыми на его входы. Аккумулятор
служит источником и приемником данных.
АЛУ непосредственно выполняет лишь операции сложения, вычитания, сдвига,
сравнения слов, поразрядные логические операции (конъюнкцию, дизъюнкцию,
сложение по модулю 2). Более сложные операции (умножение, деление и др.)
выполняются по подпрограммам. В АЛУ имеется схема перевода двоичных чисел в
двоично-десятичные (DA, Decimal Adjust);
- RF (Register Rags) — регистр флажков, т. е. битов, указывающих признаки результатов арифметических или логических операций, выполненных в АЛУ. Указываются пять признаков: Z (Zero) — нулевой результат, С перенос, AC (Auxiliary Carry) — вспомогательный перенос, S (Sign) – Знак, Р(Parity) - четность веса слова. Признак вспомогательного переноса (между младшим и старшим полубайтами) нужен при выполнении операций в двоично-десятичном коде. Признаки служат для управления ходом процесса обработки информации.
С внутренней шиной данных через мультиплексор связан блок регистров, часть которых специализирована, другая часть (регистры общего назначения, РОН) программно доступна и может быть использована по усмотрению программиста. Регистры обозначены через W2, W3, В, С, D, E, H, L, SP и РС. Регистры W2 и W3 предназначены только для временного хранения данных при выборке команды из памяти и недоступны для программиста. Регистры В, С, D, E, H, L относятся к регистрам общего назначения, т. к. могут быть использованы по усмотрению программиста. Эти восьмиразрядные регистры могут применяться либо по отдельности, либо в виде пар В-С, D-E, H-L, играющих роль 16-разрядных регистров. Пары регистров именуются по первым регистрам пары как пары В, D, Н. Пара H-L, как правило, используется для размещения в ней адресов при косвенной регистровой адресации. В блоке регистров имеются также 16-разрядные регистры SP и PC.
Регистр SP (Stack Pointer) - указатель стека. Стек (магазинная память) удобен для запоминания массива слов, т. к. при этом не требуется адресовать каждое слово отдельно. Слова загружаются в стек в определенном порядке, при считывании также заранее известен порядок их следования. При организации типа LIFO (Last In — First Out) последнее записанное в стек слово при считывании появляется первым. Основное назначение стека - обслуживание прерываний программы и выполнения подпрограмм.
Программный счетчик PC (Program Counter) дает адрес команды, и может обращаться в любую из 64К ячеек адреса памяти. При сбросе МП PC принимает нулевое состояние, которое, таким образом, является адресом первой исполняемой команды, иначе говоря, выполнение программы начинается с нулевой ячейки. Длина команды составляет 1...3 байта. Содержимое программного счетчика после выборки очередного байта из памяти автоматически инкрементируется, так что в PC появляется адрес следующей команды, если текущая команда была однобайтовой, или следующего байта текущей команды в противном случае. Второй и третий байты команды поступают в регистры W2 и W3, которые не адресуются программой и используются только блоком внутреннего управления.
Схема INC/DEC (Increment/Decrement) изменяет передаваемые через нее слова на +1 или - 1.
Регистр команд IR (Instruction Register) принимает из памяти первый байт команды (код операции), который после дешифрации порождает сигналы, необходимые для реализации машинных циклов, предписанных кодом операции.
Блок управляющего автомата использует выход регистра команд для синхронизации циклов, генерации сигналов состояния и управления шиной (внешними устройствами).
При обмене между МП и памятью (или ВУ) адрес соответствующей ячейки памяти (или ВУ) от выбранной команды или одной из регистровых пар передается в регистр адреса RA.
Буфер адреса ВА с тремя состояниями выхода выдает сигналы старших разрядов адреса на линии адресной шины A.
12.3 Командный цикл микропроцессора
МП выбирает из памяти и выполняет одну команду за другой, пока не дойдет до команды «Останов»(HLT). Выборка и выполнение одной команды образует командный цикл. Командный цикл состоит из одного или нескольких машинных циклов (МЦ). Каждое обращение к памяти или ВУ требует машинного цикла, который связан с передачей байта в МП или из него. В свою очередь машинный цикл делится на 3 – 5 тактов Т, число которых зависит от типа машинного цикла.
Командный цикл (КЦ) начинается с выборки команды (OF, Opcode Fetch) по адресу, хранящемуся в PC. Первый машинный цикл М1 всегда OF, в нем МП получает первый байт команды. После этого могут быть еще один или два машинных цикла типа MR (Memory Read), поскольку команда может быть однобайтной, двухбайтной или трехбайтной. Для реализации команды может потребоваться от 1 до 5 обращений к памяти (ВУ). Хотя обращения к ЗУ/ВУ располагаются в разных частях КЦ, выполняются они по единым правилам, соответствующим интерфейсу МПС и реализованы на общем оборудовании управляющего автомата. Действия МПС по передаче в/из МП одного байта данных/команды называются машинным циклом.
Командный цикл представляет собой последовательность машинных циклов (от 1 до 5 ), которые принято обозначать M1, M2,..M5.
Машинный цикл (МЦ) обязательно включает в себя действия по передаче байта информации. Кроме того, в некоторых МЦ дополнительно реализуются действия по пересылке или преобразованию информации внутри МП. Поэтому длительность МЦ может быть различной - за счет различного числа содержащихся в них машинных тактов (T1, T2,...).
Машинный такт (такт) образует пара сигналов тактового генератора Ф1, Ф2, поэтому длительность такта постоянна и равна периоду тактового генератора (за исключением такта Tw).
Таким образом, просматривается иерархия процедур при работе микропроцессора:
Командный цикл - Машинный цикл - Машинный такт.
Каждому такту соответствует определенное состояние управляющего автомата. Любой МЦ обязательно содержит такты T1, T2, T3, предназначенные для передачи байта по интерфейсу. Машинные циклы, в которых осуществляется передача или преобразование информации в МП, содержат дополнительно один Т4 или два такта T4, T5. МП вырабатывает несколько типов МЦ, основными из которых являются циклы «Чтение» и «Запись».
МЦ микропроцессора предусматривает возможность обмена как в синхронном, так и в асинхронном режиме. Если в составе МПС использованы только "быстрые" устройства, т.е. такие, которые могут работать с тактовой частотой МП, то передача информации в МЦ осуществляется в синхронном режиме. В этом случае на вход READY МП подается константа "1" и после такта T2 начинается такт T3. При работе с "медленными" устройствами, быстродействие которых не позволяет переключаться с частотой тактового генератора МП, необходимо "растянуть" во времени МЦ, реализовав асинхронный принцип обмена. Для этого в начале МЦ обмена с "медленными" устройствами на входе READY формируется уровень логического нуля. В такте T2 МП анализирует состояние READY, и если READY = 0, то МП после T2 переходит не к T3, а к такту ожидания Tw, который может длиться произвольное число периодов тактового генератора. Переход к T3 осуществляется по фазе Ф1, если в предыдущей Ф2 READY установился в "1".
С помощью входа READY можно не только согласовывать работу МП с устройствами различного быстродействия, но и реализовывать пошаговый и потактовый режимы работы МП.
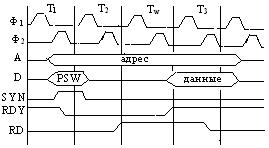
Рисунок 12.3 - Цикл "чтение " на магистрали ISA
Таким образом, в машинном цикле выполняются следующие действия:
- выдача адреса;
- выдача информации о начатом МЦ (PSW);
![]() - анализ значения входных сигналов;
- анализ значения входных сигналов;
- при необходимости - ожидание сигнала READY = 1;
- прием/выдача данных;
- при необходимости - внутренняя обработка/пересылка данных.
Существуют следующие типы машинных циклов:
1) Выборки команды (OF, Opcode Fetch).
2) Чтение из памяти (MR, Memory Read).
3) Записи в память (MW, Memory Write).
4) Чтение из ВУ (IOR, Input-Output read).
5)Записи в ВУ (IOW, Input-Output Write).
6) Подтверждение прерывания (INA, Interrupt Acknowledge).
7) Освобождение шин (BI, Bus Idle).
8) Останов (HALT).
В начале каждого МЦ на линии шины данных D[7:0] выдается байт дополнительной управляющей информации ( PSW).
Наличие на D[7:0] управляющей информации отмечается специальным выходным сигналом SYNC.
Байт управляющей информации присутствует на шине данных (ШД) один такт, а использоваться может в течение всего МЦ. Поэтому в МПС, использующих информацию PSW, предусматривается специальный, внешний по отношению к МП, регистр-защелка для фиксации PSW.
13 Лекция. Адресация и команды
Команда – это такое двоичное слово, которое заставляет МП выполнять определенные действия. Набор команд – совокупность всех команд, которые может выполнить МП. Команда состоит из двух частей: кода операции (коп – opcode) и адреса. КОП сообщает схеме управления «что делать» и длину команды для счетчика команд; а адрес указывает местонахождение данных, участвующие в данной операции. Набор команд для микропроцессоров серии i8085 составляет 75-80 команд. Число команд значительно больше, чем число КОП, поскольку при формировании команды один и тот же код операции может использоваться при различных способах адресации. Сокращенное буквенное обозначение КОП с числовой формой записи адреса называется языком программирования Ассемблер. Программа-транслятор Ассемблера преобразует мнемоническое обозначение КОП в соответствующие двоичные коды называемые машинным кодом. МП имеет команды различной длины: 1, 2 или 3 байта. Тип обращения к данным называют способом адресации.
Существуют следующие способы адресации:
- неявная – адреса источника и приемника информации указаны в однобайтной команде неявно, а как бы встроены в команду. Например, MOV A, B – opcode = 78h – команда пересылки данных из регистра В в регистр А (В → А). 78h = 01111000 : 01 – код команды пересылки для СУ, 111 – адрес регистра А, 000 – адрес регистра В;
- непосредственная – КОП всегда размещается в первом байте команды, а непосредственно за ним следуют данные, занимающие 2 или 2 байта в зависимости от команды. MVI A, 6Dh 3E – КОП, 6Д – данное (число) двухбайтная команда пересылки числа 6Д в регистр А (6Д → А), занимает две ячейки памяти;
- прямая – после КОП помещается адрес памяти или устройства ввода-вывода (интерфейса), т.е. адрес указывается прямо в команде. STA 83F8 – трехбайтная команда пересылки из регистра А в ячейку памяти по адресу 83F8. 32 (КОП) – F8(мл.байт) – 83(ст.байт);
- косвенная – однобайтная команда, в КОП которой указывается адрес регистровой пары (HL, SP), содержащей адрес данных в памяти. MOV A, M - 7Eh – КОП, пересылка (копирование) из ячейки памяти, адрес которой находится в регистровой паре HL.
13.1 Команды микропроцессора i8085
Команды МП приведены в таблице 13.1: в первой графе даны мнемокоды с обозначениями регистров через r, пар регистров через rp, ячеек памяти через М, 3 и 2-го байтов команды через b3b2, адресов ВУ через port.
Таблица 13.1 – Команды микропроцессора i8085
|
Ассемблер |
КОП |
Длина, байт |
Содержание |
|
Команды пересылки |
|||
|
MOV r1, r2 |
01ПППИИИ |
1 |
Пересылка r2 → r1 |
|
MOV r, M |
01ППП110 |
1 |
Пересылка М → r |
|
MVI r, b2 |
00ППП110 |
2 |
Пересылка байта → r |
|
LXI rpb3b2 |
00ПР0001 |
3 |
Загрузка 2 байтов → rр |
|
LDA b3b2 |
3A |
3 |
Прямая загрузка А |
|
SHLD b3b2 |
22 |
3 |
Прямая запись HL → M |
|
STA b3b2 |
32 |
3 |
Прямая запись A → M |
|
Арифметические и логические команды |
|||
|
ADD r |
10000ИИИ |
1 |
А + r → А |
|
ADD M |
86 |
1 |
А + М → А |
|
ADI b2 |
С6 |
2 |
А + байт → А |
|
ADC r |
10001ИИИ |
1 |
А + r + С → А |
|
ACI b2 |
СЕ |
2 |
А + байт + С → А |
|
SUB r |
10010ИИИ |
1 |
А - r → А |
|
SUI b2 |
D6 |
2 |
А - байт → А |
|
SBB r |
10011ИИИ |
1 |
А - байт - С → А |
|
INR r |
00ППП100 |
1 |
Инкремент регистра |
|
INR M |
34 |
1 |
Инкремент памяти |
|
DCR r |
00ППП101 |
1 |
Декремент регистра |
|
DCR M |
35 |
1 |
Декремент памяти |
|
DAA |
27 |
1 |
BC → BCD |
|
Продолжение таблицы 13.1 |
|||
|
ANA r |
10100ИИИ |
1 |
Лог.И А & r → A |
|
ORA r |
10110ИИИ |
1 |
Лог. ИЛИ А + r → A |
|
CMA |
2F |
1 |
Лог. НЕ инверсия А |
|
XRA r |
10101ИИИ |
1 |
Искл. ИЛИ А + r → А |
|
CMP r |
10111ИИИ |
1 |
Сравнение А - r |
|
CPI b2 |
FE |
2 |
Сравнение А - байт |
|
RLC |
07 |
1 |
Цикл. сдвиг А влево |
|
RRC |
0F |
1 |
Цикл. сдвиг А вправо |
|
Команды управления |
|||
|
JMP b3b2 |
C3 |
3 |
Безусловный переход |
|
Jусл b3b2 |
11УУУ010 |
3 |
Условный переход |
|
CALL b3b2 |
CD |
3 |
Вызов подпрограммы |
|
RET |
C9 |
1 |
Возврат |
|
Специальные команды |
|||
|
PUSH rp |
11РП0101 |
1 |
Пересылка rp в стек |
|
POP rp |
11РП0001 |
1 |
Загрузка rp из стека |
|
IN port |
DB |
2 |
Ввод в А |
|
OUT port |
D3 |
2 |
Вывод из А |
|
EI |
FB |
1 |
Разр-е прерывания |
|
DI |
F3 |
1 |
Запрет прерывания |
|
NOP |
00 |
1 |
Нет операции |
|
HLT |
76 |
1 |
Останов |
Во второй графе ИИИ – адрес источника данных; ППП – адрес приемника; ПР – пары регистров. Адреса РОН: 000 – В; 001 – С; 010 – Д; 011 – Е; 100 – Н; 101 – L; 111 – A.
ADD – addition – сложение;
SUB – subtraction – вычитание.
13.2 Структурная схема МПС
В состав микропроцессорной системы входят следующие микросхемы:
- центральный процессор i8085;
- генератор тактовых импульсов (ГТИ) i8284A;
- контроллер прерываний i8259;
- регистр защелка i8282 для фиксации адреса внешних устройств;
- шинный формирователь i8286 (двунаправленный буфер данных);
- оперативная память RAM i2142;
- программируемое ПЗУ PROM i2716;
- программируемый параллельный интерфейс (ППИ) i82С55.
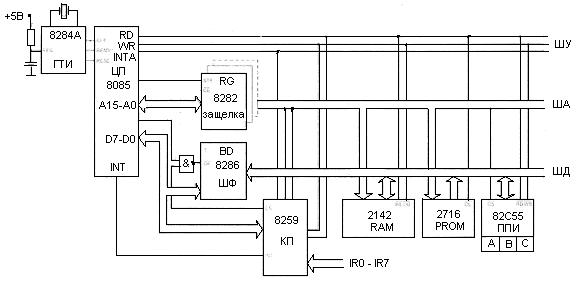
Рисунок 13.1 – Схема МПС на базе i8085
13.3 Устройства индикации
Семисегментные индикаторы позволяют наблюдать содержимое регистров МП и ячеек памяти, отображать другую информацию. Каждому индикатору соответствует ячейка ОЗУ, где хранится семисегментный код, управляющий свечением сегментов индикатора. Информация из этих ячеек посылается на индикаторы при помощи специальной схемы, которая обеспечивает динамический режим индикации. Каждый бит в этих ячейках соответствует определенному сегменту (см. рисунок 13.2). Если бит равен 1, то соответствующий сегмент будет гореть, и наоборот. Ячейка памяти 83F8H соответствует правому индикатору, 83FFH – левому (всего восемь).
|
Бит |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
Сегмент |
H |
G |
F |
E |
D |
C |
B |
A |
|
|
|
|
|
|
|
|
|
|
Рисунок 13.2 – Схема семисегментного индикатора
Обмен информацией с внешними устройствами осуществляется через программируемый интерфейс i82C55.
Программы пишутся на языке ассемблера, т. е. с использованием мнемоники. Для того чтобы МП “понимал” команду, ее нужно перевести в машинный язык (код). Поскольку МП имеет дело непосредственно с цифровыми сигналами, команды Ассемблера закодированы в двоичным коде. Для большой наглядности и компактности двоичный код переводят в шестнадцатеричный. Например, код 00111100 в шестнадцатеричном виде записывается 3С, что для МП 8085 означает команду увеличения содержимого регистра А (аккумулятора) на 1 и на языке Ассемблера записывается как INR A.
Написанные на Ассемблере программы подвергаются ручной трансляции и загрузке в ОЗУ, причем загрузка производится в последовательные ячейки памяти. Ручная трансляция осуществляется при помощи таблицы 13.1 мнемонических обозначений команд i8085.
Например, приведем программу (см. таблицу 13.2), которая выводит на индикатор цифру «8». Для этого необходимо подать единичные импульсы на все сегменты, кроме Н (индикатор имеет адрес 83F8h). Проставляя в соответствующие разряды байта «1» (см. рисунок 13.2), получим двоичный код: 01111111. Код 7Fh сначала записывается в аккумулятор МП командой MVI A, 7Fh (коп-3E), а затем содержимое А пересылается на индикатор.
Таблица 13.2
|
Адрес |
Содержимое |
Оператор |
Операнд |
Комментарий |
|
|
8000 8001 8002 8003 8004 8005 |
3E 7F 32 F8 83 76 |
MVI
STA
|
A, 7Аh
83F8h
|
Цифра «8»
Останов |
|
14 Лекция. Арифметические и логические команды
14.1 Арифметические команды
Одной из основных арифметических функций, выполняемых МП, является сложение. При сложении одного двоичного числа с дополнительным кодом другого реализуется операция вычитания. Сложение может быть повторено множество раз, а многократное прибавление есть не что иное, как операция умножения. Повторяющееся вычитание представляет собой операцию деления.
Сложение двоичных чисел подобно сложению десятичных. В обоих случаях операция начинается с обработки найме наименьших значащих цифр, расположенных в крайней справа позиции.
Перенос 110 0110 0000 С
Слагаемое 062 0011 1110 А
Слагаемое 049 0011 0001 В
-------------------- -------------
Сумма 111 0110 1111 А
Операция вычитания положительных двоичных чисел также подобна десятичным.
Заем /перенос/ 1 0000 0010 С
Уменьшаемое 62 0011 1110 А
Вычитаемое 49 0011 0001 В
-------------------- ------------
Разность 13 0000 1101 А
Отрицательные двоичные числа представляются в дополнительном коде (дополнение до 2), формирование которого состоит из двух этапов: получение обратного кода и добавление единицы. Если число положительное, то старший бит /знака/ равен 0, в противном случае 1. Обратный код двоичного числа есть результат инвертирования кода этого числа. В выше приведенном примере отрицательное число можно представить в дополнительном коде
0011 0001 число 49 в прямом коде
------------
1100 1110 обратный код 49
0000 0001 единица, добавляемая к обратному коду
------------
1100 1111 дополнительный код 49
Тогда разность двух чисел будет равна
0011 1110 А в старшем бите 0, следовательно число
+ положительное
1100 1111 В
----------------
0000 1101 А
При умножении двух двоичных чисел выполняются два действия: сдвиг и сложение. Сдвиг множимого влево обусловлен тем, что результат умножения двоичного числа на 1 есть, само это число.
Деление – обратная операция умножения, т.е. вычитание до тех пор, пока уменьшаемое не станет меньше вычитаемого. Для выполнения арифметических операций умножения и деления пользователю необходимо написать соответствующую подпрограмму. Операция "сложение" реализуется командой АDD r, которая складывает содержимое регистра r с содержимым регистра А. В зависимости от места нахождения данных, команды сложения могут быть с памятью и А (АDD М), данными и А (АDI байт).
Операция "вычитание" осуществляется командой SUB r, при которой из содержимого регистра А вычитается содержимое регистра r. Аналогично команды вычитания могут быть с памятью и A (SUI байт).
14.2 Логические (побитные) команды
Для проведения операций с данными, в которых каждый бит является самостоятельной булевой переменной, используются логические команды: НЕ, И, ИЛИ, Исключающее ИЛИ.
Функцию НЕ реализует однобайтовая команда СМА (коп - 2F), которая инвертирует содержимое аккумулятора.
Функцию И выполняет команда ANA B - коп А0.
Функция ИЛИ выполняется командой ОRА r, которая объединяет по "ИЛИ" содержимое регистров A и r.
Функция "Исключающая ИЛИ" реализуется командой XRA r, выполняя при этом логическую функцию над содержимым регистров A и r. На практике для очистки аккумулятора используют команду XRA A (коп AF), что дает нулевой результат в каждом бите.
i8085 позволяет работать с двоично-десятичным кодом (ВСD), в котором десятичные числа каждого разряда представляются двоичными. В следствие этого двоичные числа превышающие 9 (1001+1111) недопустимы в ВСD. С этой целью в МП предусмотрена команда DАА (коп 27), осуществляющая десятичную коррекцию: если полубайт содержимого аккумулятора больше 9, то прибавляется 6. Как правило, десятичная коррекция выполняется после операции сложения.
К дополнительным логическим командам i8085 следует отнести команду СМР r, осуществляемую сравнение содержимого аккумулятора и регистра r путем вычитания одного из другого, не изменяя при этом содержимое А. Результат сравнения определяется по битам флагов : нуля Z = 1, если А = r; переноса C = 1, если А < r. При решении некоторых задач необходимо увеличить/уменьшить заданное число в 2 раза. Для этого можно воспользоваться командами циклического сдвига RRC (вправо) или RLC (влево), при которой содержимое аккумулятора сдвигается вправо/влево на один разряд.
Команды RAR и RAL отличаются тем, что циклический сдвиг вправо (влево) содержимого аккумулятора осуществляется через бит флага переноса (С).
Команда CMC (коп 3F), инвертирует бит флага переноса (C).
14.3 Команды условных переходов
Коды условий в команде условного перехода приведены в таблице 14.1.
Таблица 14.1
|
УУУ |
Условие |
Содержание |
|
000 |
NZ |
Неравенство нулю |
|
001 |
Z |
Равенство нулю |
|
010 |
NC |
Отсутствие переноса |
|
011 |
C |
Наличие переноса |
|
100 |
PO |
Нечетность |
|
101 |
PE |
Четность |
|
110 |
P |
Плюс |
|
111 |
M |
Минус |
Например, команда условного перехода из обобщенной формы Jусл b3b2 переводится в вариант JNZ b3b2 – переход к команде с адресом b3b2, если признак результата говорит о том, что результат не равен нулю. Признаки формируются в регистре признаков, формат которого представляется в виде:
![]()
причем S = 0 означает «плюс», S = 1 – «минус»; Z = 0 – неравенство нулю, Z = 1 – равенство нулю; С или АС = 1 – наличие переноса (9 бит и 5 бит соответственно), С или АС = 0 – его отсутствие; Р = 0 – нечетность, Р = 1 – четность. Разряды 5, 3, 1 содержат константы и для признаков не используются.
Операция сравнения производится вычитанием операндов с установкой признака результата Z, или S, но результат вычитания из АЛУ в аккумулятор не сбрасывается.
Таблица 14.2 – Программа с арифметическими командами
|
Адрес |
Содержимое |
Команда |
Комментарий |
|
8000
|
ЗЕ
|
MVI A,A7h
MVI B,23h
MVI C,93h
SUB В ADD С JNC 8012
MVI A, 00h
ACI 00h
STA 83F4h
STA 83F2h
CALL INDC
HLT
HLT
|
A7h → A
|
|
8001
|
A7
|
|
|
|
8002
|
06
|
23h → В
|
|
|
8003
|
23
|
|
|
|
8004
|
0Е
|
93h → С
|
|
|
8005
|
93
|
|
|
|
8006
|
90
|
(A-B) → A
|
|
|
8007
|
81
|
(A + С) → A
|
|
|
8008
|
D2
|
Если нет переноса -
|
|
|
8009
|
12
|
Ml
|
|
|
800A
|
80
|
|
|
|
800B
|
3E
|
|
|
|
800C
|
00
|
|
|
|
800D
|
CE
|
(A+0+АC) → A
|
|
|
800E
|
32
|
Вывод на
|
|
|
800F
|
F4
|
индикаторы
|
|
|
8010
|
83
|
|
|
|
8011
|
00
|
|
|
|
8012
|
32
|
Вывод на
|
|
|
8013
|
F2
|
индикаторы
|
|
|
8014
|
83
|
|
|
|
8015
|
CD
|
П/п: с 83F8 и 83F9; |
|
|
8016
|
C0
|
83FА и 83FB
|
|
|
8017
|
01
|
|
|
|
8018
|
76
|
останов
|
15 Лекция. Интерфейс ввода-вывода i82С55
15.1 Общие сведения
Подсистема ввода/вывода (ПВВ) обеспечивает связь МП с внешними устройствами, к которым будем относить:
- устройства ввода/вывода (УВВ): клавиатура, дисплей, принтер, датчики и исполнительные механизмы, АЦП, ЦАП, таймеры и т.п.;
- внешние запоминающие устройства (ВЗУ): накопители на магнитных дисках, "электронные диски" и др.
В рамках рассмотрения ПВВ будем полагать термины "УВВ" и "ВУ" синонимами, т.к. обращение к ним со стороны процессора осуществляется по одним законам.
ПВВ должна обеспечивать выполнение следующих функций:
- согласование форматов данных, т.к. процессор всегда передает/принимает данные в параллельной форме, а некоторые ВУ (например, НМД) – в последовательной. С этой точки зрения различают устройства параллельного и последовательного интерфейса. В рамках параллельного обмена не производится преобразование форматов передаваемых слов, в то время как при последовательном обмене осуществляется преобразования параллельного кода в последовательный и наоборот;
- организация режима обмена – формирование и прием управляющих сигналов, идентифицирующих наличие информации на различных шинах, ее тип, состояние ВУ (Готово, Занято, Авария), регламентирующих временные параметры обмена. По способу связи процессора и ВУ (активного и пассивного) различают синхронный и асинхронный обмен. При синхронном обмене временные характеристики обмена полностью определяются МП, который не анализирует готовность ВУ к обмену и фактическое время завершения обмена. Синхронный обмен возможен только с устройствами, всегда готовыми к нему (например, двоичная индикация).
При асинхронном обмене МП анализирует состояние ВУ и/или момент завершения обмена. Временные характеристики обмена в этом случае могут определяться ВУ;
- адресную селекцию внешнего устройства.
Процесс ввода/вывода может быть под управлением МП или ВУ (контроллера ПДП). В первом случае методы ввода/вывода разделяются на два вида: по опросу и по прерыванию.
Метод ввода/вывода по опросу подразумевает регулярную проверку процессором готовности ВУ к ответу. К недостаткам этого метода следует отнести низкое быстродействие. Необходимо, чтобы процессор и внешние устройства были согласованны по скорости. Эффективность низка, если информация поступает редко (процессор опрашивает ВУ, а информации нет).
15.2 Программируемый периферийный интерфейс i8255
Программируемый периферийный интерфейс (programmable peripheral interface – PPI) i8255 имеет 40 выводов:
- три порта А(РА7 – РА0), В(РВ7 – РВ0), С(РС7 – РС0) для ввода-вывода данных;
- буфер данных БД (Д7 – Д0) для временного хранения данных;
- блок управления.
Блок управления имеет 6 выводов: CS – выбор микросхемы для операции программирования, считывания или записи; А0, А1 – выбор порта ввода-вывода (00 – порт А, 01 – В, 10 – С, 11 – регистр команд блока управления); RD, WR – для операции чтения или записи; RESET – сигнал сброса в исходное состояние, т.е. все порты ППИ используются как устройства ввода данных в МП.
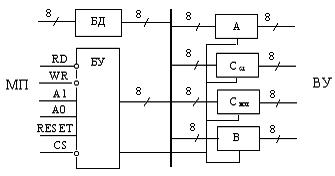
Рисунок 15.1 – Структурная схема ППИ
Порты А, В, С могут быть запрограммированы как по отдельности, так и по группам: группа А – порт А и старший полубайт порта С (РС7 – РС4); группа В – порт В и младший полубайт порта С (РС3 – РС0).
ППИ работает в трех режимах:
- 0 режим – основной (не стробированный);
- 1 режим – стробированный ввод-вывод ( однонаправленный);
- 2 режим – стробированный двунаправленный обмен.
15.2.1 Режим 0.
В режиме 0 можно запрограммировать ППИ так, что порты будут соединены в группы:
- два однобайтных и два полубайтных порта (порт С) – 16 возможных комбинаций ввода-вывода либо три однобайтных порта – 8 возможных комбинаций из портов А, В и С.
При выводе данных из аккумулятора (А) МП (по команде OUT, адрес порта) они запоминаются в буферном регистре ППИ, а затем через шину порта пересылаются в назначенный порт.
При вводе данных в аккумулятор МП регистры А, В, С становятся «прозрачными» (не фиксируют данные) и по команде (IN, адрес порта) транслируют данные из шины порта на системную шину данных (Д7 – Д0) микропроцессора.
15.2.2 Режим 1.
В этом режиме 6 разрядов порта С используются для синхронизации обмена данными между МП и ВУ через порты А и В, т.е. используются только два порта А и В. При этом режим 1 может быть запрограммирован как стробированный ввод или стробированный вывод.
Стробированный ввод режима 1 предполагает функционирование порта А и/или порта В как устройства ввода с защелками. Это позволяет внешним данным сохраняться в порте, пока МП не будет готов их извлечь. Многие устройства ввода-вывода принимают или выдают информацию намного медленнее, чем это делает МП. Существует метод управления процессом ввода-вывода информации, называемый квитированием (handshaking) или опросом (poling), который синхронизирует работу устройства ввода/вывода с МП. Например, устройством, требующим квитирования, является параллельный принтер со скоростью печати 100 знаков в секунду (cps). Процесс опрашивания принтера о его занятости называется опросом, а процедура передачи данных на принтер с одновременным сигналом Strobe – квитированием.
15.3 Программирование интерфейса
ППИ программируется с помощью двух командный байтов регистра команд, показанных на рисунках 15.2 и 15.3.
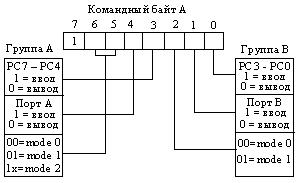
Рисунок 15.2 – Командный байт А регистра команд ППИ
Следует обратить внимание на то, что 7-й двоичный разряд регистра команд выбирает командный байт А или командный байт В. Командный байт А программирует функции групп А и В, тогда как командный байт В предназначен для установки разрядов порта С в состояние логической 1 или сбрасывает их в 0, но только в случае, если интерфейс программируется в режиме 1 или 2.
Выводы группы В, порт В (РВ7 – РВ0) и младшая часть порта С (РС3 – РС0) программируются на ввод или вывод. Группа В функционирует в режиме 0 или в режиме 1. Режим 0 является основным режимом ввода-вывода, который позволяет осуществлять программирование выводов группы В как обычный вход и захват выходных соединений. Работа в режиме 1 предполагает выполнение операций со стробированием для выводов группы В, причем при этом данные передаются через порт В, а для сигналов квитирования предусмотрен порт С.
Выводы группы А, порт А (РА7 – РА0) и старшая часть порта С (РС7 – РС4), так же как и группа В, программируются на вход или выход. Разница состоит в том, что группа А может функционировать в режимах 0, 1 и 2. Функционирование в режиме 2 является двунаправленным режимом работы только для порта А. Если в 7-й разряд командного байта поместить логический 0, то выбирается командный байт В.
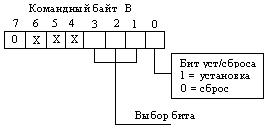
Рисунок 15.3 – Командный байт В регистра команд ППИ
Этот командный байт дает возможность устанавливать в 1 или сбрасывать в 0 любой разряд порта С, при работе ППИ в режиме 1 или 2. В противном случае командный байт В не используется для программирования. В системе управления часто используется функция установки или очистки управляющего бита порта С. Функция установки/сброса битов свободна от сбоя, поскольку в течение выполнения команды установки/сброса другие, не участвующие в операции выводы порта С, не будут изменяться.
Адрес ППИ определяется «нулем» в том разряде, где есть соединение в схеме линий А7 – А2 и входа CS. Например, вход интерфейса CS (выбор микросхемы) соединен с линией А2. Тогда группа адресов адаптера будет следующей: порт А – 11111000 – F8h; порт В – 11111001 – F9h; порт С – 11111010 - FАh; командный регистр – 11111011 - FВh.
Для программирования ППИ в режиме 0 с портами А, В, Сст (РС7 – РС4) на выход данных из МП, а Смл (РС3 – РС0) на вход, необходимо выполнить следующие команды:
MVI A, 81h
OUT FB
Только после программирования интерфейса можно работать с портами А, В и С.
16 Лекция. Контроллер прерываний i8259
Внешние устройства, включенные в подсистему прерываний, должны реализовать несколько функций - формирование запроса, анализ ответа процессора, выдачу вектора прерывания. Кроме того, в подсистеме необходимо обеспечить приоритет обслуживания запросов. Перечисленные функции могут быть реализованы на специальных устройствах - контроллерах прерываний, которые выпускаются в виде БИС в составе многих микропроцессорных комплектов.
Программируемый контроллер прерываний i8259 (К580ВН59) позволяет организовать более гибкую и эффективную подсистему прерываний в МПС.
Отличительной особенностью контроллера i8259 является то, что он генерирует код команды CALL, поэтому область векторов прерываний (по-прежнему компактная) может располагаться по произвольным адресам памяти. Структурная схема контроллера прерываний представлена на рисунке 16.1.
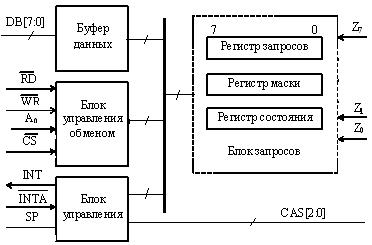
Рисунок 16.1 - Структура контроллера прерываний i8259 (К580ВН59)
Программируемый контроллер прерываний включает в себя блоки связи с системной шиной, управления и запросов. Блок запросов содержит три 8-разрядных регистра - регистр запросов РгЗ, в котором фиксируются запросы от источников прерываний, регистр маски РгМ, определяющий подмножество источников, которым разрешены прерывания и регистр состояний РгС, в котором фиксируются запросы, принятые на обслуживание.
Состав управляющих линий контроллера включает стандартные линии подключения к системной шине : D[7:0], A0, WR\, RD\, CS\; линии, передающие запрос на прерывания процессору и ответ МП INT и INTA\ соответственно. Линии запросов z7..z0 соединяют контроллер с источниками прерываний. Контроллер может обслуживать до 8 источников прерываний. При большем числе источников возможно каскадное включение контроллеров, причем один из контроллеров будет ведущим, а остальные (не более 8) - ведомыми. Для назначения роли контроллера в системе предназначен вход SP (H - уровень соответствует ведущему контроллеру). Для организации взаимодействия каскадированных контроллеров прерываний предназначены линии CAS[2:0].
Программирование контроллера осуществляется путем загрузки в специальные регистры двух или трех управляющих слов, форматы которых показаны в таблице 16.1. Загрузка этих слов осуществляется командами инициализации в начале работы системы.
Таблица 16.1
|
Команда |
A0 |
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
КИ1 |
0 |
|
А7 |
А6 |
А5 |
1 |
0 |
F |
S |
0 |
|
КИ2 |
1 |
|
A15 |
A14 |
A13 |
A12 |
A11 |
A10 |
A9 |
A8 |
|
КИ3-1 |
1 |
|
z7 |
z6 |
z5 |
z4 |
z3 |
z2 |
z1 |
z0 |
|
КИ3-2 |
1 |
|
x |
x |
x |
x |
x |
n |
n |
n |
В команде КИ1 разряд S определяет количество контроллеров прерываний в системе : "1" - один контроллер, "0" - более одного (имеет место каскадирование). Разряд F задает шаг между соседними адресами подпрограмм, обслуживающих прерывания : "1" - 4 байта, "0" - 8 байт.
Разряды A7, A6, A5 вместе со всеми разрядами КИ2 образуют старшие 11 бит адреса подпрограммы. При значении F = 1 вектор прерывания (адресная часть команды CALL) формируется следующим образом :
A15 A14 A13 A12 A11 A10 A9 A8 A7 A6 A5 n n n 0 0,
где nnn - номер обслуживаемого запроса на прерывание (номер входа z).
Если задан шаг между адресами 8 байт (F = 0), то разряд A5 игнорируется и вектор генерируется след. образом :
A15 A14 A13 A12 A11 A10 A9 A8 A7 A6 n n n 0 0 0.
Третья команда инициализации (КИ-3) подается (и принимается контроллером) только при наличии нескольких контроллеров в системе (S = 0), причем формат этой команды различен для ведущего и ведомых контроллеров.
Ведущему контроллеру командой КИ3-1 указывается, к каким его входам z подключены ведомые контроллеры (в соответствующем разряде КИ3-1 будет установлена "1"). "0" в разряде КИ3-1 означает, что на соответствующий вход z подключен обычный источник прерываний.
Каждому ведомому контроллеру в трех младших разрядах КИ3-2 указывается номер входа ведущего контроллера, к которому подключен данный ведомый. Состояние разрядов КИ3-2[7:3] безразлично.
Помимо команд инициализации, выполняемых один раз в начале работы МПС, контроллер в любое время может выполнить команды управления (КУ), позволяющие установить маску запросов (КУ1), задать режим приоритета запросов (КУ2) или определить будущую операцию. Форматы команд управления приведены в таблице 16.2.
Таблица 16.2
|
Команда |
A0 |
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
|
КУ1 |
1 |
|
m7 |
m6 |
m5 |
m4 |
m3 |
m2 |
m1 |
m0 |
|
|
КУ2 |
0 |
|
ЦП |
К |
СВ |
0 |
0 |
k2 |
k1 |
k0 |
|
|
КУ3 |
0 |
|
x |
СМ1 |
СМ0 |
0 |
1 |
СП |
Р1 |
Р0 |
|
Команда КУ1 устанавливает новое значение в регистр маски, причем если разряд РгМ установлен в "1", то соответствующий вход z считается замаскированным и прерывание от этого источника запрещено.
КУ2 задает тип приоритета запросов (ЦП = 0 - фиксированный приоритет, z0 -высший, z7 -низший; ЦП = 1 - циклический приоритет). При циклическом приоритете этой же командой задается номер входа (в разрядах k[2:0]), которому присвоен низший приоритет. После обслуживания любого запроса приоритеты входов циклически меняются на одну позицию. Разряд СВ КУ2 позволяет сбросить бит регистра РгС, номер которого задан битами k[2:0] КУ2. Разряд К определяет, используется ли в команде поле k[2:0].
Команда КУ3 позволяет установить или сбросить режим спецмаскирования, при котором на обслуживание принимаются запросы с приоритетом ниже текущего.
КУ3[6:5] = 11 - установить режим спецмаскирования, КУ3[6:5] = 10 - снять режим спецмаскирования, КУ3[6:5] = 0x - не воздействует. Эта же команда подготавливает в следующем такте один из допустимых к чтению объектов: регистр запросов при КУ3[1:0] = 10; регистр состояний при КУ3[1:0] = 11; номер запроса с наивысшим приоритетом по формату таблицы 16.3 при КУ3[2:0] = 10x. Считывание осуществляется командой IN при A0 = 0, WR = 0. Признак INT отмечает наличие запроса, а код w[2:0] определяет номер незамаскированного запроса с наивысшим приоритетом. Результатом чтения информации по формату таблицы 16.3 можно воспользоваться при организации программной идентификации источника прерывания.
Таблица 16.3
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
INT |
x |
x |
x |
x |
w2 |
w1 |
w0 |
Считывание содержимого регистра маски может осуществляться командой IN при A0 = 1 без предварительной загрузки команды КУ3.
17 Лекция. Контроллер ПДП i8237A
17.1 Структура контроллера ПДП
БИС i8237A(К580ВТ57) предназначена для управления передачей информации между ВУ и ЗУ в режиме ПДП. Основное назначение контроллера - формирование последовательности адресов и управляющих сигналов.
Контроллер ПДП имеет четыре независимых канала обмена. В каждом канале размещено пять регистров: 2 регистра адреса (базовый РАiб и текущий РАiт ) и 2 регистра счета слов (базовый РСiб и текущий РСiт ) и регистр режима РРi. Структурная схема контроллера показана на рисунке 17.1.
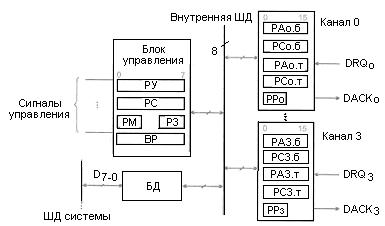
Рисунок 17.1 - Контроллер прямого доступа в память
При программировании в оба адресных регистра загружается одно и тоже значение адреса, а оба регистра счета слов – одно и тоже значение размера блока. При ПДП меняются состояния текущих регистров адреса и счета слов. Оба работают в режиме счетчиков и при передаче очередного слова регистр адреса инкрементируется/декрементируется в зависимости от программирования контроллера, а регистр счета слов декрементируется. Когда регистр-счетчик РСiт дойдет до нулевого состояния, вырабатывается сигнал конца счета. Этим заканчивается режим блочного обмена с ПДП.
Базовые регистры адреса и счета слов позволяют реализовать режим автоинициализации канала. В них начальные адреса и размеры блоков сохраняются неизменными и, если в конце ПДП вновь загрузить текущие регистры теми же кодами, то можно повторить вывод того же блока данных. Например, при управлении дисплеем для поддержания изображения – повтор блока данных с частотой 25Гц.
Кроме того, каждый канал содержит восьмиразрядный регистр режима.
|
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
РР: |
R1 |
R2 |
ID |
AI |
EN3 |
EN2 |
EN1 |
EN0 |
В регистре режимов разряды имеют следующий смысл:
R[7:6] – режим (00 – по требованию, 01 – одиночные передачи, 10 – блочные, 11 – каскадированная схема;
ID – инкрементирование/декрементирование;
AI – автоинициализация (0 – запрещена, 1 – разрешена);
EN[1:0] – выбор канала 3..0.
EN[3:2] – тип передач (00 – контроль, 01 – запись, 10 – чтение, 11 – запрет)
В режиме обмена по требованию передачи выполняются до выработки контроллером признака конца счета или поступления внешнего сигнала EOP (End of Process) или перехода сигнала DRQ в пассивное состояние, т.е. до истощения ВУ в смысле исчерпания его данных. При этом возобновление данных в ВУ позволяет продолжить ПДП с помощью изменения сигнала DRQ. В периодах между ПДП, когда позволено работать процессору, промежуточные значения адресов и счетчика слов хранятся в текущих регистрах.
Контроллер включает в себя, помимо четырех каналов ПДП, блок управления, обеспечивающего связь с системной шиной, разрешение конфликтных ситуаций в соответствии с заданной системой приоритетов и управление работой контроллера в различных режимах. В блок управления входят 3 восьмиразрядных регистра (РУ – регистр управления; РС – регистр состояния; ВР – временный регистр) и два четырехразрядных регистра (РМ – масок; РЗ – запросов).
Регистр управления РУ программируется процессором, сбрасывается по сигналу RESET или Master Clear.
|
РУ: |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
В регистре управления РУ:
0 – передачи П – П каналов 0 и 1 (1 – разрешены; 0 – нет);
1 – см. в тексте;
2 – контроллер (1 – запрещен; 0 – разрешен);
3 – синхронизация (1 – ускоренная; 0 – нормальная);
4 – вид приоритета (1 – кольцевой; 0 – фиксированный);
5 – запись (1 – удлиненная; 0 – обычная);
6 – полярность DRQ (1 – L; 0 – H);
7 - полярность DACK (1 – H; 0 – L).
Не расшифрованный на рисунке бит 1 имеет следующий смысл. При Д0 = 0, когда запрещены передачи «память-память» (П-П), состояние этого бита безразлично. При передачах П-П и Д1 = 1 запрещается, а при Д1 = 0 разрешается оставление адреса в канале 0.
Регистр состояния РС содержит информацию о текущем состоянии контроллера и может читаться процессором. РС позволяет определять, какие каналы закончили ПДП и какие требуют его.
Регистр масок РМ имеет биты, соответствующие 4 каналам. Установка бита запрещает действие входного запроса DRQ. Если канал не запрограммирован на автоинициализацию, то по окончании ПДП он вырабатывает сигнал ЕОР, при этом устанавливается бит маски этого канала.
Весь регистр устанавливается сигналом RESET, что запрещает запросы до поступления команды сброса регистра Clear Mask Rg, разрешающий начать прием запросов.
Регистр запросов РЗ позволяет контроллеру реагировать на запросы ПДП, исходящие от программы. Каждый канал имеет свой бит в этом регистре, биты немаскируемы, но подчиняются приоритету. Весь регистр одновременно сбрасывается сигналом RESET.
Временный регистр ВР используется при передачах типа «память-память» для временного хранения данных и всегда содержит последний байт, переданный в предыдущей операции, если не сброшен сигналом RESET.
В контроллере применено мультиплексирование шин для передачи старшего байта адреса через шину данных во внешний регистр, где этот байт фиксируется стробом ADSTB. Далее старший байт адреса выдается указанным внешним регистром, а шина данных используется для других передач.
В работе контроллера можно выделить две фазы – простоя и активную. В фазе простоя контроллер находится, когда на его входах нет запросов ПДП. В этой фазе контроллер может быть запрограммирован с помощью процессора. Состояние программируемости продолжается и после начала действий ПДП, до момента, когда контроллер запросил захвата шин (сигнал HRQ), но еще не получил от процессора ответа (сигнал HLDA) o предоставлении ПДП. При простое контроллер постоянно в каждом такте проверяет линии (не поступил ли запрос от ВУ) и CS (не обращается ли процессор к регистрам). В последнем случае линии адреса А3-0 выбирают регистры, а по стробам IOR и IOW производятся чтение или запись. После поступления сигнала HLDA, когда процессор освободил шины системы, начинаются рабочие состояния контроллера.
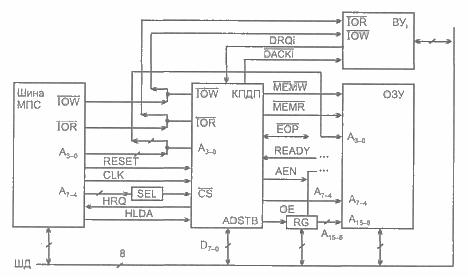
Рисунок 17.2 – Схема взаимодействия блоков МПС с ПДП
Они проходят в активной фазе и, если требуется, вводятся такты ожидания с учетом сигнала готовности/неготовности READY участников обмена. Для передач «ВУ → память» генерируются пары одновременных сигналов IOR и MEMW; для передач «память → ВУ» - пары IOW и MEMR. Запрос незамаскированного канала порождает запрос прерывания HRQ для процессора, реализующего один из четырех вариантов ПДП, указанных 7 и 6 битами регистра режима.
17.2 Выводы и сигналы контроллера
D7-0 - двунаправленные линии системной ШД с тремя состояниями;
RESET - сброс внутренних регистров контроллера и внешних выходных управляющих сигналов. Сброс регистра режима РР дезактивирует контроллер, он перестает реагировать на запросы ПДП до выполнения программы инициализации;
CLK - тактовый сигнал синхронизации (обычно сигнал Ф2 от микропроцессора);
IOW - в режиме программирования это входной сигнал, осуществляющий запись в тот или иной регистр контроллера, в режиме ПДП — выходной сигнал, стробирующий запись байта в ВУ;
IOR - в режиме программирования входной сигнал чтения того или иного регистра контроллера, в режиме ПДП - выходной, стробирующий введение данных от ВУ;
A3-0 - линии адреса, в режиме программирования входные, адресуют регистры контроллера, в режиме ПДП - выходные, дают 4 младших разряда адреса, формируемого контроллером;
CS - в режиме программирования разрешает работу контроллера, в режиме ПДП отключен. Вырабатывается дешифрацией адреса контроллера;
A7-4 - линии адреса, формируемого контроллером в режиме ПДП, в других режимах переходят в третье состояние;
READY - готовность. Отсутствие этого сигнала переводит контроллер в состояние ожидания. Сигнал используется, если быстродействие основной памяти недостаточно для работы в синхронизме с ВУ, и тогда он удлиняет циклы обращения к памяти;
MEMW, MEMR - сигналы записи и чтения памяти в режиме ПДП. В циклах чтения и записи контроллер вырабатывает парные сигналы IOW и MEMR или IOR и MEMW;
HQR (Hold Request) - запрос захвата шин, выдается контроллером микропроцессору на его вход HOLD при наличии запроса от ВУ;
HLDA - подтверждение захвата, поступает от МП и разрешает переход в режим ПДП;
AEN (Address Enable) - разрешение адреса, указывает на режим ПДП, может быть использован для блокировки шин адреса в других устройствах с целью запрета их ошибочной работы. Переводит адресные шины невыбранных устройств в третье состояние;
ADSTB - сигнал выдачи адреса, разрешающий запись старшего байта адреса, вырабатываемого контроллером, по ШД во внешний регистр-защелку, хранящий адрес до конца цикла;
DRQi (i = 0 – 3) - запрос ПДП, формируемый ВУ. Для передачи одного байта должен быть снят внешним устройством по получении сигнала DACKi от контроллера.
Для передачи массива данных должен удерживаться ВУ до
получения
от контроллера сигнала ТС. Входы DRQi имеют фиксированные приоритеты
(у DRQ0 высший) или круговой приоритет;
DACKi (i = 0 – 3) - подтверждение (разрешение) ПДП. Информирует ВУ о предоставлении ему очередного цикла ПДП. Устанавливается и сбрасывается для передачи каждого байта данных. Вырабатывается согласно приоритетам входов DRQi;
EOP - двунаправленный, информирует о завершении ПДП, генерируется в конце счета самим контроллером, может поступать извне. Появление внутреннего или внешнего ЕОР заставляет контроллер прекратить ПДП, сбросить запрос и, если разрешена автоинициализация, загрузить текущие регистры канала от базовых.
Возможность организации передачи типа «память-память» позволяет простыми средствами перемещать блок данных из одной области адресного пространства в другую. Установка младшего бита регистра управления определяет использование каналов 0 и 1 для передач «память-память». Передачи начинаются программной установкой запроса DRQ в канале 0. После подтверждения ПДП сигналом HLDA контроллер читает данные из области памяти соответственно адресам в регистре текущего адреса канала 0, которые формируются обычным способом (инкрементированием регистра адреса). Прочитанный байт помещается в регистр временного хранения (ВР). Затем канал 1 выполняет операцию передачи из ВР в память соответственно текущим адресам в своем адресном регистре. Регистр счета слов канала 1 декрементируется. Когда в ходе передач текущий регистр счета слов канала 1 обнулится, генерируется признак конца счета, обуславливающий появление сигнала ЕОР, прекращающего ПДП - обслуживание.
18 Лекция. 16-разрядный i8086
18.1 Общие сведения
16-разрядный МП i8086 явился дальнейшим развитием линии однокристальных МП, начатой i8085. Наряду с увеличением разрядности в i8086 реализован ряд новых архитектурных решений:
- расширена система команд (по набору операций и способам адресации);
- архитектура МП ориентирована на мультипроцессорную работу: разработана группа вспомогательных БИС (контроллеров и специализированных процессоров) для организации мультипроцессорных систем различной конфигурации;
- начато движение в сторону совмещения во времени выполнения различных операций: МП включает два параллельно работающих устройства - обработки данных и связи с магистралью, что позволяет совместить во времени процессы обработки информации и передачи ее по магистрали;
- введена новая организация памяти, которая используется во всех старших моделях семейства INTEL - сегментация памяти.
Для сохранения преемственности модели с i8085 в i8086 предусмотрено два режима работы - "минимальный" и "максимальный", причем в минимальном режиме i8086 работает просто как быстрый 16-разрядный i8085 с расширенной системой команд (архитектура МПС на базе i8086-min напоминает архитектуру на базе i8085).
Максимальный режим ориентирован на работу i8086 в составе мультипроцессорных систем, в которых, помимо нескольких центральных процессоров i8086, могут функционировать специализированные процессоры ввода/вывода i8089, сопроцессоры "плавающей арифметики" i8087.
Определим более четко введенные выше понятия.
Центральный процессор – поддерживает собственный командный цикл, выполняет программу, хранящуюся в системной памяти, по сбросу системы управление, как правило, передается центральному процессору (или одному из ЦП, если их несколько в системе).
Специализированный процессор – поддерживает собственный командный цикл, выполняет программу, хранящуюся в системной памяти, но инициализируется только по команде ЦП, по окончании выполнения программы сообщает ЦП о завершении работы.
Сопроцессор не поддерживает собственный командный цикл, выполняет команды, выбираемые для него ЦП из общего потока команд. По сути дела сопроцессор является расширением ЦП.
18.2 Внутренняя структура МП
Архитектура МП представляет собой структуру 16/16/20, т.е. 16-разрядные шины данных и управления, и 20-разрядную шину адреса.
Структурная схема МП i8086 представлена на рисунке 8.1. МП включает в себя два основных устройства:
- устройство сопряжения (УС);
- операционное устройство (ОУ).
. 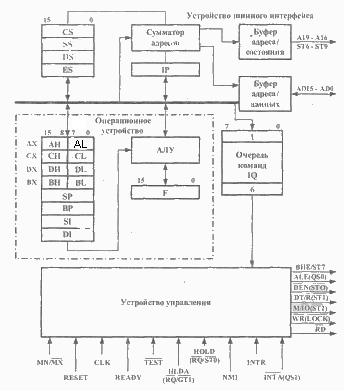
Рисунок 18.1 – Структура микропроцессора i8086
Операционное устройство предназначено для выполнения команд и включает в себя 16-разрядное АЛУ, РОН, и регистры флагов для формирования сигналов.
Устройство сопряжения предназначено для опережающей выборки команд, которые хранятся в очереди, и формирования физического адреса команды и данных с использованием сумматора. Кроме того, устройство сопряжения включает в себя сегментные регистры CS, DS, ES, SS и указатели команд IP
Важная особенность МП заключается в совмещении выборки команд и их исполнения, что существенно повышает производительность МПС в целом, т.к. по сути дела МП представляет собой двухступенчатый конвейер.
18.2.1 Сегменты и смещения памяти.
Адрес памяти представляет собой комбинацию сегментного адреса и смещения. Сегментный адрес, заданный одним из сегментных регистров, определяет начало сегмента памяти объемом 64 Кбайт. Смещение задает положение ячейки памяти внутри сегмента.
Сегментные регистры, в сочетании с другими регистрами, используются при генерировании адреса памяти.
В МП i8086-80286 (16 бит) используется базово-индексная адресация, при которой положение данных в памяти определяется суммой содержимого базового регистра (ВР или ВХ) и индексного регистра (DI или SI).
Например, MOV CL, [DX + DI] - команда пересылки (копирования) байта из сегмента данных по смещению, равному сумме DX и DI.
Сегментные регистры:
CS (code - код)
Сегмент кода представляет собой область памяти, в которой содержатся инструкции программы. Сегментный регистр CS определяет стартовый адрес этой области памяти. В реальном режиме CS указывает непосредственно на сегмент кода - область размером 64 Кбайт. В защищенном режиме CS указывает на дескриптор, в котором хранится описание сегмента кода, включая начальный адрес и размер сегмента. Размер сегмента кода в процессорах 8088—80286 ограничен 64 Кбайт, но в защищенном режиме 32-битных процессоров может достигать 4 Гбайт.
DS (data - данные)
Сегмент данных представляет собой область памяти для хранения данных программы. Адрес данных определяется сочетанием сегментного адреса в регистре DS и смещения, значение которого находится в самой инструкции либо в регистре-указателе. Размер сегмента данных в процессорах 8088 – 80286 не превышает 64 Кбайт, для 32-битных процессоров ограничен 4 Гбайт.
SS (stack – стек)
Регистр определяет область памяти для системного стека. Адрес вершины стека образуется сочетанием значений SS и ESP/BP. Регистр EBP/BP в паре с SS применяется для доступа к данным, расположенным в любой точке сегмента стека.
ES (extra – дополнительные данные)
Регистр указывает местоположение операнда-приемника при выполнении строковых инструкций.
FS и GS
Дополнительные сегментные регистры, предназначенные для поддержки добавочных сегментов данных; доступны в процессорах 80386 – Pentium 4.
Рисунок 18.2 иллюстрирует вычисление адреса памяти по значениям сегментного адреса и смещения. Сегмент занимает адреса 10000Н-1FFFFH (всего 64 Кбайт). Поскольку сегмент начинается с адреса 10000Н, а смещение составляет F000H, то адрес ячейки памяти равен 1F000Н. Напомним, что значение смещения определяет расстояние в байтах начала сегмента.
Следует обратить внимание, что начало сегмента на рисунке 10.2 расположено по адресу 10000Н, в то время как сегментный регистр содержит 1000Н. В реальном режиме при вычислении адреса сегмента к значению сегментного регистра микропроцессор добавляет справа 0Н. Так формируется 20-битный адрес памяти, определяющий начало сегмента. Расширение адреса до 20 бит позволяет адресовать 1 Мбайт памяти. Например, если сегментный регистр содержит 1200Н, то посредством этого регистра доступна память размером 64 Кбайт с адреса 12000Н. Если значение сегментного регистра равно 120Н, он адресует сегмент памяти с адреса 1200Н. Поскольку значение сегментного регистра дополняется 0Н, в реальном режиме сегменты выровнены по 16-байтным границам. Промежуток в 16 байт между соседними сегментами называется параграфом.
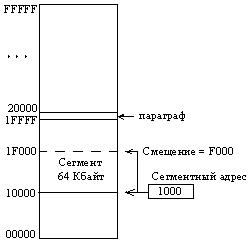
Рисунок 18.2 – Механизм адресации памяти
Поскольку в реальном режиме сегмент имеет фиксированную длину 64 Кбайт, то конечный адрес сегмента равен сумме начального адреса и FFFFH. Например, если сегментный регистр содержит 2000Н, то первый адрес в сегменте равен 20000Н, а последний – 20000Н + FFFFH, т.е. 2FFFFH.
В таблице 18.1 показаны несколько значений сегментного регистра и соответствующие им адреса границ сегмента в памяти.
Таблица 18.1
|
Значение сегментного регистра |
Начальный адрес |
Конечный адрес |
|
2000Н |
20000Н |
2FFFFH |
|
2001H |
20010H |
3000FH |
|
2100H |
21000H |
30FFFH |
|
AB00H |
AB000H |
BAFFFH |
При формировании адреса памяти значение смещения, как часть адреса, прибавляется к стартовому адресу сегмента. Например, если сегментный регистр содержит 1000Н, а смещение составляет 2000Н, то микропроцессор обратится к памяти по адресу 12000Н. Составляющие адреса - сегмент и смещение - часто записывают парами через двоеточие. Например, 1000:2000 означает сегмент 1000Н и смещение 2000Н.
В микропроцессорах 80386—Pentium 4, а также в некоторых версиях процессора 80286 наличие сегмента FFFFH позволяет адресовать в реальном режиме помимо I Мбайта еще одну область памяти объемом 64 Кбайт минус 16 байт. Это так называемая высокая память, которая находится в диапазоне адресов 0FFFF0H—10FFEFH и доступна программам реального режима при установке драйвера HIMEM.SYS. Если сегментный адрес равен FFFFH, то при добавлении смещения микропроцессор устанавливает активный уровень на адресной линии А20. Например, при сочетании сегмента и смещения FFFF:4000, результирующий адрес составляет FFFF0H + 4000H = 103FF0H. Обратите внимание, что в адресе 103FF0H бит 20 установлен в 1. Если управление линией А20 не поддерживается, то бит 20 адреса не передается, и микропроцессор обращается к ячейке по адресу 03FF0H.
В некоторых методах адресации смещение задается суммой значений регистров и/или постоянной величины, которая может превысить предельную длину сегмента — FFFFH. Например, если сегментный адрес равен 4000Н, а смещение определяется суммой составляющих F000H и 3000H, то процессор обратится к ячейке по адресу 42000Н, а не по адресу 52000Н. Дело в том, что результат сложения F000H и З000Н составляет не 12000Н, а всего 2000Н, поскольку ограничен 16 битами. Перенос при сложении отбрасывается - на определение адреса памяти он не влияет. В итоге генерируется адрес, соответствующий сегменту и смещению 4000:2000, т. е. 42000Н.
18.2.2 Сегменты и смещения, действующие по умолчанию.
Каждый из сегментных регистров связан по умолчанию с определенными источниками смещений. Правила, устанавливающие соответствие между сегментными регистрами и источниками смещений, действуют как в реальном, так и в защищенном режиме. Например, сегментный регистр кода всегда используется в паре с регистром указателя инструкции - для доступа к следующей исполняемой инструкции. Выбор между парами регистров CS: IP и CS:EIP определяется режимом микропроцессора.
Сегментный регистр CS определяет начало сегмента кода, а указатель инструкции ЕIР/IР задает смещение внутри кодового сегмента. Например, если в реальном режиме CS = 1400Н, a IP = 1200Н, то микропроцессор считывает инструкцию из памяти по адресу 14000Н + 1200Н = 15200Н.
Для доступа к стеку применяются пары регистров SS:SP (SS:ESP) и SS:BP (SS:EBP). Например, если SS = 2000Н, а ВР = З000Н, то при использовании ВР в качестве указателя микропроцессор обратится к памяти по адресу 23000Н. Заметим, что в реальном режиме в качестве смещения используются только младшие 16 бит расширенного регистра. Поэтому в процессорах 80386 – Pentium 4 при работе в реальном режиме не следует задавать значения смещений в регистрах-указателях больше FFFFH. В противном случае система остановится. Возможные сочетания сегментов и 16-битовых смещений, действующих по умолчанию, приведены в таблице 18.2.
Таблица 18.2
|
Сегмент |
Смещение |
Назначение адреса |
|
CS |
IP |
Адрес инструкции |
|
SS |
SP or BP |
Адрес стека |
|
DS |
BX, DI, SI, 8b or 16b |
Адрес данных |
|
ES |
DI (для строковой ком-ды) |
Адрес приемника строковой ком-ды |
Процессоры 80386 – Pentium 4 располагают большим числом сочетаний сегментов и источников смещений, т.к. в отличие от микропроцессоров 8086 – 80286 имеют не четыре сегмента, а шесть и 32-битные смещения.
Список литературы
1. Гусев В. Г. Электроника и микропроцессорная техника: Учебник для вузов. – М.: Высшая школа, 2006. – 799 с.
2. Опадчий Ю.Ф. Аналоговая и цифровая электроника: Учебник для вузов. /Под ред. О.П.Глудкина. – М.: Горячая линия‑Телеком, 2005. – 768 с.
3. Новиков Ю.В., Скоробогатов П.К. Основы микропроцессорной техники. – М.: БИНОМ. Лаборатория знаний, 2006.
4. Угрюмов Е.П. Цифровая схемотехника. – СПб.: БХВ-Петербург, 2002. – 528 с.
5. Шанаев У.Т. Цифровые устройства и микропроцессоры. Методические указания к выполнению лабораторных работ. – Алматы: АУЭС, 2010. – 25 с.
6. Байкенов Б.С. 8085-симулятор. Методические указания к выполнению лабораторных работ. – Алматы: АУЭС, 2010. – 24 с.
Содержание
Введение 3
1 Лекция 4
2 Лекция 9
3 Лекция 15
4 Лекция 20
5 Лекция 26
6 Лекция 32
7 Лекция 38
8 Лекция 44
9 Лекция 49
10 Лекция 57
11 Лекция 63
12 Лекция 69
13 Лекция 75
14 Лекция 79
15 Лекция 82
16 Лекция 86
17 Лекция 89
18 Лекция 94
Список литературы 100
Св. план 2011 г., поз. 369