Некоммерческое акционерное общество
АЛМАТИНСКИЙ ИНСТИТУТ ЭНЕРГЕТИКИ И СВЯЗИ
Кафедра электроники и компьютерных технологий
АССЕМБЛЕР
Конспект лекций
для студентов всех форм обучения специальности 050704 – Вычислительная техника и программное обеспечение
Алматы 2009
СОСТАВИТЕЛИ: Мусатаева Г. Т., Байжанова Д. О. Ассемблер. Конспект лекций для студентов всех форм обучения специальности 050704 – Вычислительная техника и программное обеспечение. - Алматы: АИЭС, 2009 – 82 с.
В конспекте лекций излагаются основные понятия, синтаксис и семантика конструкции языка Ассемблер. Рассматриваются основные возможности языка и их применение при решении типовых задач программирования. Курс лекций снабжен контрольными вопросами и упражнениями, позволяющими студентам проверить свое знание пройденного материала.
1 Лекция 1. Представление данных
Цель первых двух лекций – дать основу и существенные элементы языка Ассемблера для написания своих первых программ. Речь пойдет о переменных и константах, арифметике, управлении последовательностью вычислений, функциях и простейшем вводе-выводе.
Минимальной единицей информации в компьютере является бит. Бит может принимать значения 0 или 1.
Группа из восьми бит представляет собой байт. Биты или разряды в байте пронумерованы от 0 до 7 справа налево:
|
Номера битов: |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
Значение битов: |
1 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
Байт может содержать числа без знака от 0 до 255 и числа со знаком от – 128 до + 127.
Два байта или шестнадцать бит представляют собой слово. Биты в слове пронумерованы от 0 до 15 справа налево:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15 |
|
|
|
|
|
|
8 |
7 |
|
|
|
|
|
|
0 |
||
Слово может содержать числа без знака от 0 до 65535 и числа со знаком от – 32768 до + 32767.
Четыре байта или два слова образуют двойное слово, состоящее из 32 бита, а два двойных слова – одно учетверенное слово (64 бита).
Все вычисления в компьютере производятся в двоичной системе счисления, т.е. в двоичном коде. Шестнадцатеричная форма представления чисел является краткой записью чисел в двоичном коде. Для этого четыре двоичных разряда записываются одним шестнадцатеричным разрядом. Кроме этих двух форматов представления чисел могут использоваться десятичный, двоично-десятичный (BCD) и ASCII - коды.
Двоичный код
В двоичном коде используются двоичные цифры 0 и 1. Признаком двоичного числа является буква В, которая ставится в конце. Например, 10101001В.
Значение двоичного числа определяется относительной позицией каждого бита и наличием единичных битов. Например:
10001010b = 1*27 + 0*26 + 0*25 + 0*24 + 1*23 + 0*22 + 1*21 + 0*20 =
= 128 + 8 + 2 = 138.
Десятичный код
В десятичном коде используются десятичные цифры от 0 до 9. Признаком десятичного числа является буква D, которая ставится в конце. Если в конце числа буква отсутствует, то число воспринимается как десятичное.
Шестнадцатеричный код
В шестнадцатеричном коде используются цифры от 0 до 9 и буквы от A до F. Признаком шестнадцатеричного числа является буква H, которая ставится в конце. Число должно обязательно начинаться с цифры. Байт содержит два шестнадцатеричных разряда, слово - четыре разряда, двойное слово - восемь разрядов. Например,
1BA8h = 1*163 + 11*162 + 10*161 + 8*160 = 4096+2816+160+8 = 7080
Ниже приведены двоичные, десятичные и шестнадцатеричные значения чисел от 0 до 15:
|
Двоич. |
Дес. |
Шест. |
Двоич. |
Дес. |
Шест. |
|
0000 |
0 |
0 |
1000 |
8 |
8 |
|
0001 |
1 |
1 |
1001 |
9 |
9 |
|
0010 |
2 |
2 |
1010 |
10 |
A |
|
0011 |
3 |
3 |
1011 |
11 |
B |
|
0100 |
4 |
4 |
1100 |
12 |
C |
|
0101 |
5 |
5 |
1101 |
13 |
D |
|
0110 |
6 |
6 |
1110 |
14 |
E |
|
0111 |
7 |
7 |
1111 |
15 |
F |
Двоично-десятичный код (BCD)
Двоично-десятичные числа записываются шестнадцатеричными цифрами. Двоично-десятичные числа могут быть представлены в упакованном или распакованном формате. В упакованном формате в байте могут содержаться две десятичные цифры: от 00 до 99h.
В распакованном формате в байте содержится одна цифра в младшей тетраде, старшая тетрада равна нулю: от 00 до 09h.
BCD коды используются в командах двоично-десятичной арифметики.
ASCII - код
Для обмена данными между процессором и принтером, клавиатурой или дисплеем используются ASCII коды. ASCII код (американский стандартный код для обмена информацией) используются для кодирования алфавитно-цифровой информации в компьютере.
Например, цифры от 0 до 9 имеют ASCII коды от 48 до 57 (30h до 39h). Заглавные буквы от "A" до "Z" имеют ASCII коды от 65 до 90 (от 41h до 5Ah), прописные буквы от "а" до "z" - от 097 до 122 (от 61h до 7Ah). Для вывода результата на экран нужно его представить в ASCII коде. Например: требуется вывести на экран число 17h. Для этого сначала его нужно распаковать, а затем преобразовать в ASCII код:
17h ® 0107h ® 3137h.
Представление отрицательных чисел
Отрицательные числа в компьютере представляются в дополнительном коде. Для изменения знака числа выполняют инверсию, т.е. заменяют в двоичном представлении числа все единицы нулями и нули единицами, а затем прибавляют 1. Например:
100 = 64h = 0110 0100b прямой код числа
инверсия ® 1001 1011b обратный код числа
+1 ® 1001 1100b = 9Ch дополнительный код числа
Операция получения дополнительного кода известна как операция дополнения до двух. В данном формате старший (7-й, 15-й, 31-й для байта, слова, двойного слова) бит всегда соответствует знаку числа: 0 – для положительных и 1 - для отрицательных.
Процесс подготовки программы на языке ассемблера фирмы Microsoft
Процесс подготовки и отладки программы включает следующие этапы:
· Подготовка исходного текста программы с помощью любого текстового редактора. Файл с исходным текстом должен иметь расширение .ASM;
· Трансляция программы c помощью ассемблера MASM.EXE с целью получения объектного файла;
· Компоновка объектного модуля с помощью компоновщика LINK. EXE с целью получения загрузочного ( исполнимого) файла;
· Отладка готовой программы с помощью интерактивного отладчика TurboDebugger (файл TD.EXE).
При выборе редактора для подготовки исходного текста программы следует иметь в виду, что многие текстовые процессоры (например , Microsoft Word) добавляют в выходной файл служебную информацию. Поэтому следует воспользоваться редактором, выводящим в выходной файл "чистый текст", без каких- либо управляющих символов. Если файл с исходным текстом программы назван P.ASM, то строка вызова ассемблера может иметь следующий вид:
MASM /Z /ZI /N P, P, P.
Ключ /Z разрешает вывод на экран строк исходного текста программы, в которых ассемблер обнаружил ошибки ( без этого ключа поиск ошибок пришлось бы проводить по листингу трансляции).
Ключ /ZI управляет включением в объектный файл номеров строк исходной программы и другой информации, не требуемой при выполнени программы, но используемой отладчиком.
Ключ /N подавляет вывод в листинг перечня символических обозначений в программе, от чего несколько уменьшается информативность листинга, но существенно сокращается его размер.
Стоящие далее параметры определяют имена модулей: исходного (P.ASM), объектного (P.OBJ) и листинга (P.LST). Точка с запятой подавляет формирование файла P.CRF с перекрестными ссылками.
Строка вызова компоновщика может иметь следующий вид:
LINK /CO P, P.
Ключ /CO передает в загрузочный файл символьную информацию, позволяющую отладчику TD выводить на экран полный текст исходной программы, включая метки, комментарии и проч. Стоящие далее параметры обозначают имена модулей: объектного (P. OBJ) и загрузочного (P.EXE). Точка с запятой подавляет формирование файла с листингом компоновки (P.MAP) и использование библиотечного файла с объектными модулями подпрограмм.
Компоновщик создает загрузочный модуль в формате .EXE.
Если исходная программа написана в формате .COM, то после трансляции и компоновки обычным образом ее надо преобразовать в файл типа .COM. Для этого используется включенная в состав DOS внешняя команда EXE2BIN:
EXE2BIN P P.COM.
Первый параметр обозначает исходный для команды EXE2BIN загрузочный файл P.EXE, второй - ожидаемый результат преобразования. Указание расширения .COM во втором параметре обязательно, так как по умолчанию команда EXE2BIN создает файл с расширением .BIN.
Основная литература – 4[4-14], 2[128-131].
Контрольные вопросы
1. Какие виды кодов используются при представлении чисел, данных?
2. Как вычисляется 20-разрядный адрес любой ячейки памяти?
3. Виды предложений ассемблера.
4. Этапы подготовки программы на языке ассемблера.
2 Лекция 2. Архитектурные особенности IBM PC
Краткий обзор семейства микропроцессоров фирмы INTEL
Важнейшей характеристикой любого микропроцессора является разрядность его внутренних регистров, а также внешних шин адресов и данных. Микропроцессор i8086 имеет 16-разрядную внутреннюю архитектуру и такой же разрядности шину данных. Таким образом, максимальное целое число (данное или адрес), с которым может работать микропроцессор, составляет 216-1=65535 (64К-1). Однако адресная шина микропроцессора i8086 содержит 20 линий, что соответствует адресному пространству 220=1 Мбайт. Для того, чтобы с помощью 16-разрядных адресов можно было обращаться в любую точку 20-разрядного адресного пространства, в микропроцессоре предусмотрена сегментная адресация памяти, реализуемая с помощью четырех сегментных регистров.
Суть сегментной адресации заключается в следующем. Исполнительный 20–разрядный адрес любой ячейки памяти вычисляется процессором путем сложения начального адреса сегмента памяти, в котором располагается эта ячейка, со смещением к ней (в байтах) от начала сегмента, которое обычно называют относительным адресом Сегментный адрес без четырех младших бит, т. е деленный на 16, хранится в одном из сегментных регистров. При вычислении исполнительного адреса процессор умножает содержимое сегментного регистра на 16 (путем сдвига влево на 4 двоичных разряда) и прибавляет к полученному 20-разрядному адресу относительный адрес. Умножение базового адреса на 16 увеличивает диапазон адресуемых ячеек до величины 64 кбайт*16 =1Мбайт.
Микропроцессор i80286, используемый как центральный процессор компьютеров IBM PC/AT, является усовершенствованным вариантом i8086, дополненным схемами управления памятью и ее защиты. Микропроцессор i80286 работает с 16-разрядными операндами, но имеет 24-разрядную адресную шину, что соответствует адресному пространству 224=16 Мбайт. Однако описанный выше способ сегментной адресации памяти не позволяет выйти за пределы 1 Мбайт. Для преодоления этого ограничения в микропроцессоре i80286 (так же, как и в микропроцессоре i80386) используются два режима работы: реального адреса и виртуального защищенного адреса, или просто защищенный режим. В реальном режиме микропроцессор i80286 функционирует фактически также, как микропроцессор i8086 с повышенным быстродействием и может обращаться лишь к 1 Мбайт адресного пространства. Оставшиеся 15 Мбайт памяти, даже если они установлены в компьютере, использоваться не могут.
В защищенном режиме по-прежнему используются сегменты и смещения в них, однако начальные адреса не вычисляются путем умножения на 16 содержимого сегментных регистров, а извлекаются из таблиц сегментных дескрипторов, индексируемых теми же сегментными регистрами. Каждый сегментный дескриптор занимает 6 байтов, из которых 3 байта (24 двоичных разряда) отводятся подсегментный адрес. Тем самым обеспечивая полное использование 24-разрядного адресного пространства.
В каждом сегментном регистре под индекс таблицы сегментных дескрипторов отводится 14 двоичных разрядов. Полный логический адрес адресуемой ячейки состоит из 14- разрядного индекса номера сегмента и 16-разрядного относительного адреса. Это позволяет каждой программе использовать до 230=1 Гбайт логического, или виртуального пространства, которое таким образом, в 64 раза превышает максимально возможный объем физической памяти. Операционная система виртуальной памяти хранит все сегменты выполняемых программ в большом дисковом пространстве, автоматически загружая в оперативную память те или иные сегменты по мере необходимости.
Микропроцессоры i80386 и i80486 являются высокопроизводительными процессорами с 32-разрядными шинами данных и адресов и 32-разрядной внутренней архитектурой. Последнее означает, что внутренние регистры этих процессоров, в отличии от процессоров ранних моделей, имеют длину 31- бита. Поэтому максимальное целое число, с которым может работать микропроцессор, составляет 232-1 = 4294967296 (4Гбайт). Во многих случаях использование 32-битовых операндов позволяет существенно упростить и ускорить вычисления. Помимо этого, в микропроцессорах i80386 и i80486 расширен состав регистров, что также предоставляет программисту значительные удобства. Наконец, в новых моделях процессоров имеются встроенные средства поддержки многозадачного режима, а также мультипроцессорных систем. Естественно, что эти процессоры, как и микропроцессор i80286, могут работать в реальном и защищенном режимах. В последнем случае микропроцессор позволяет адресовать до 232=4 Гбайта физической памяти и 246=64 Гбайт виртуальной. При этом следует подчеркнуть, что разработчиками обеспечена полная совместимость новых моделей процессоров со старым, в том смысле, что программы, написанные для процессоров i8086 - i80286, т.е с использованием 16-битовых операндов, выполняются на новых процессорах без всяких исправлений.
Распределение адресного пространства
В зависимости от модификации персонального компьютера и состава его периферийного оборудования распределение адресного пространства может несколько различаться. Тем не менее размещение основных компонентов системы довольно строго унифицировано. Типичная схема использования адресного пространства компьютера приведена на рисунке 1. Значение адресов на этом рисунке, как и повсюду далее в книге, даны в 16-ричной системе счисления. Признаком 16-ричного числа служит буква h, стоящая после числа.
|
|
Векторы прерываний |
00000h
|
|
||
|
256 байтов |
Область данных BIOS |
00400h
|
|
||
|
512 байтов |
Область данных DOS |
00500h
|
|
||
|
|
IO.SYS и MS DOS.SYS |
|
|
||
|
|
Загружаемые драйверы |
|
> Стандартная память (640Кбайт) |
||
|
|
COMAND.COM (резидентная часть) |
|
|
||
|
|
Свободная память для загружаемых прикладных и системных программ |
|
|
||
|
64 кбайт |
Графический буфер EGIA |
A0000h = |
|
||
|
32 кбайт |
UMB |
B0000h
|
|
||
|
32 кбайт |
Текстовой буфер EGIA |
B8000h |
|
||
|
64 кбайт |
ПЗУ - расширения BIOS |
C0000h |
> Верхняя память (384 Кбайт) |
||
|
64 кбайт |
UMB |
D0000h |
|
||
|
128 кбайт |
ПЗУ BIOS |
E0000h |
|
||
|
64 кбайт |
HMA |
100000h
|
|
||
|
(80286) До 4 Гбайт (80386/486 |
XMS
|
10FFF0h |
>Расширенная память |
Рисунок 1 - Типичное распределение адресного пространства
Первые 640 кбайт адресного пространства с адресами от 00000h до 9FFFFh отводятся под основную оперативную память, которую еще называют стандартной (conventional). Начальный килобайт оперативной памяти занят векторами прерываний (256 векторов по 4байта). Вслед за векторами прерываний располагается область данных BIOS, которая занимает адреса от 00400h до 004FFh. В этой области хранятся разнообразные данные, используемыми программами BIOS в процессе управлениям периферийным оборудованием, так здесь размещаются:
· входной буфер клавиатуры с системой указателей;
· адреса параллельных и последовательных портов;
· данные, характеризующие настройку видео системы (форма курсора и его текущее местоположение на экране, текущий видеорежим, ширина экрана и прочее);
· ячейки для отсчета текущего времени;
· область межзадачных связей и т. д.
Область данных BIOS заполняется информацией в процессе начальной загрузки компьютера и динамически модифицируется системой по мере необходимости; многие прикладные программы обращаются к этой области с целью чтения или модификации содержащейся в ней информации.
В области памяти, начиная с адреса 500h содержатся некоторые системные данные DOS. Вслед за областью данных DOS располагаются собственно операционная система, загружаемая из файлов IO. SYS и MSDOS.SYS (IBMBIO.COM и IBMDOS.COM для системы PC-DOS). Система обычно занимает несколько десятков Кбайт.
Перечисленные выше компоненты операционной системы занимают обычно 60-90 кбайт. Вся оставшаяся память до границы 640 кбайт ( называемая иногда транзитной областью) свободна для загрузки любых систем или прикладных программ. Оставшиеся 384 кбайт адресного пространства, называемого верхней (upper) памятью, первоначально были предназначены для размещения постоянных запоминающих устройств (ПЗУ). Практически под ПЗУ занята только часть адресов. В самом конце адресного пространства, в области F0000h…FFFFFh (или E0000h… FFFFFh) располагается основное постоянное запоминающее устройство BIOS, а начиная с адреса C0000h-так называемое ПЗУ расширений BIOS для обслуживания графических адаптеров и дисков. Часть адресного пространства верхней памяти отводится для адресации к видео буферам графического адаптера. Приведенное на рисунке расположение видео буферов характерно для адаптера EGA; для других адаптеров оно может быть иным, (например, видеобуфер простейшего монохромного адаптера MDA занимает всего 4 кбайт и располагается, начиная с адреса B0000h).
В состав компьютеров PC/AT наряду со стандартной памятью (640 кбайт) может входить расширенная (extended) память, максимальный объем которой зависит от ширины адресной шины процессора при использовании процессора 80386/486 - 4Гбайт. Эта память располагается за пределами первого мегабайта адресного пространства и начиная с адреса 100000h. Поскольку функционирование расширенной памяти подчиняется “Спецификации расширенной памяти” (Extended Memory Specification, сокращенно XMS), то и саму память часто называют XMS-памятью. Как уже отмечалось выше, доступ к расширенной памяти осуществляется в защищенном режиме, поэтому для MS DOS, работающей только в реальном режиме, расширенная память недоступна.
Первые 64 кбайт расширенной памяти, точнее, 64 кбайт- 16 байт с адресами от 100000h до 10FFEFh, носят специальное название область старшей памяти (Higih Memory Area, HMA). Эта область замечательна тем, что, хотя она находится за пределами первого мегабайта, к ней можно обратиться в реальном режиме работы микропроцессора.
Структура и образ памяти программы .EXE
Программы, выполняемые под управлением MS-DOS, могут принадлежать к одному из двух типов: .COM и .EXE. В программах типа .EXE код программы, данных и стек занимают отдельные сегменты, а в .COM – один сегмент.
Таким образом, размер программы типа .COM не может превысить 64 кбайт, а размер программы типа EXE практически неограничен, так как в нее может входить любое число сегментов программы и данных.
Структура типичной программы типа .EXE на языке ассемблера выглядит следующим образом.
|
Title |
Программа |
Типа |
.EXE |
|
|
Text |
segment |
'code' |
|
|
|
|
assume |
CS: text, |
DS:data |
|
|
Myproc |
proc |
|
|
|
|
|
move |
AX, data |
|
|
|
|
move |
DS,AX |
|
|
|
|
... |
|
|
;Текст программы |
|
|
Myproc |
Endp |
|
|
|
Text |
Ends |
|
|
|
|
data |
segment |
|
|
|
|
|
... |
|
|
;Определения данных |
|
data |
|
Ends |
|
|
|
stack |
segment |
stack 'stack' |
|
|
|
|
dw |
128dup (0) |
|
|
|
stack |
Ends |
|
|
|
|
|
End |
Myproc |
|
|
· Следует заметить, что при вводе исходного текста программы с клавиатуры можно использовать как прописные, так и строчные буквы. Однако с помощью соответствующих ключей можно заставить транслятор различать прописные и строчные буквы в именах.
Рассмотрим теперь структуру приведенной программы. Оператор TITLE позволяет программе выводить текстовый заголовок, который будет выводиться на все страницы листинга трансляции. Программа состоит из трех сегментов: сегмента команд, или программного сегмента с произвольным именем text, сегмента данных с именем data и сегмента стека с именем stack (оба эти имени так же могут выбираться произвольно).
Каждый сегмент открывается оператором SEGMENT и закрывается оператором ENDS. Перед обоими операторами должно стоять имя сегмента. Порядок сегментов в большинстве сегментов роли не играет.
Слово 'CODE', стоящее в апострофах в строке описания сегмента команд, указывает класс сегмента - "программный". Классы сегментов анализируются компоновщиком и используются им при компоновке загрузочного модуля: сегменты принадлежащие одному классу, загружаются в память друг за другом. Для простых программ, включающих один сегмент команд и один сегмент данных, эта процедура не имеет значения
Текст сегмента команд начинается с оператора ASSUME, который позволяет транслятору сопоставить сегментные регистры и адресуемые ими сегменты. Определение CS: text указывает транслятору, что данный сегмент является программным и будет адресоваться с помощью сегментного регистра CS. Определение DS: data закрепляет за сегментом data сегментный регистр DS, как регистр, используемый по умолчанию, что позволяет ссылаться на переменные, описанные в сегменте data, без явного указания регистра DS. При этом ассемблер проверяет, действительно ли они описаны в сегменте data.
Собственно программа обычно состоит из процедур. Деление программ на процедуры не обязательно, но повышает ее наглядность и облегчает передачу управления на подпрограммы и в другие программные модули. В рассматриваемом примере сегмент команд содержит единственную процедуру Myproc, открываемую оператором PROC и закрываемую оператором ENDP. Перед обоими операторами указывается имя процедуры.
В первых строках программы инициализируется регистр DS. В него заносится сегментный адрес сегмента данных. Поскольку передача в сегментные регистры непосредственных значений не допускается, в качестве промежуточного регистра используется АХ. После того, как регистр DS инициализирован, программа может обращаться к данным, описанным в регистре данных.
Сегмент данных содержит описания всех переменных, используемых в программе.
Строка описания сегмента стека должна содержать класс сегмента - 'STACK', а также тип объединения - STACK. Тип объединения указывает компоновщику, каким образом должны объединяться одноименные сегменты разных модулей - накладываясь друг на друга (тип объединения COMMON) или присоединяясь друг к другу (тип объединения STACK для сегментов стека или PUBLIC для всех остальных). Хотя для одномодульных программ тип объединения значения не имеет, для сегмента стека обязательно указание типа STACK, поскольку в этом случае при загрузке программы выполняется автоматическая инициализация регистров SS (адресом начала сегмента стека) и SP (смещение конца сегмента стека). В приведенном примере для стека зарезервировано 128 слов памяти. Класс для сегмента стека указывать не обязательно.
Текст программы заканчивается директивой END, завершающей трансляцию. В качестве операнда этой директивы указывается точка входа в главную процедуру.
При загрузке в программы сегменты размещаются в памяти, как показано на рисунке 2.
Образ программы в памяти начинается с префикса программного сегмента (Program Segment Prefics, PSP), образуемого и заполняемого системой.
PSP всегда имеет размер 256 байтов содержит таблицы и поля данных, используемые системой в процессе выполнения программы. Вслед за PSP располагаются сегменты программы. Сегментные регистры автоматически инициализируются следующим образом: ES и DS указывают на начало PSP, CS- на начало сегмента команд, а SS- на начало сегмента стека. В указатель команд IP загружается относительный адрес точки входа в программу (из операнда директивы END), а указатель стека SP- смещение конца сегмента стека. Таким образом после загрузки программы в память адресуемыми оказываются все сегменты, кроме сегмента данных. Инициализация регистра DS в первых строках программы позволяет сделать адресуемым и этот сегмент
|
ES,DS-----> |
PSP (256 байтов) |
|
|
CS-----> |
Сегмент команд |
<¾¾IP |
|
|
Сегмент данных |
|
|
SS¾> |
Сегмент стека |
|
|
|
|
<-----SP |
|
Рисунок 2 - Образ памяти программы .EXE |
||
Структура и образ памяти программы .COM
Программа типа .COM отличается от программы типа .EXE тем, что содержит лишь один сегмент, включающий все компоненты программы: PSP, программный код (т.е оттранслированные в машинные коды программные строки), данные и стек. Структура типичной программы типа .COM на языке ассемблера выглядит следующим образом:
|
Title |
Программа |
Типа |
.COM |
|
|
Text |
segment |
'code' |
|
|
|
|
assume |
CS: text, |
DS:text |
|
|
|
org |
100h |
|
|
|
Myproc |
proc |
|
|
|
|
|
... |
|
|
;Текст программы |
|
Myproc |
Endp |
|
|
|
|
|
... |
|
|
;Определения данных |
|
Text |
Ends |
|
|
|
|
|
End |
Myproc |
|
|
Программа содержит единственный сегмент text, которому присвоен класс 'CODE '. В операторе ASSUME указано, что сегментные регистры CS и DS будут указывать этот единственный сегмент.
Оператор ORG 100h резервирует 256 байтов для PSP. Заполнять PSP будет по-прежнему система, но место под него в начале сегмента должен отвести программист. В программе нет необходимости инициализировать сегментный регистр DS, поскольку его, как и остальные сегментные регистры, инициализирует система. Данные можно разместить после программной процедуры ( как это показано на рисунке), или внутри нее, или даже перед ней. Следует только иметь ввиду, что при загрузке программы типа . COM регистр IP всегда инициализируется числом 100 h, поэтому сразу вслед за оператором ORGI 100h должна стоять первая выполнимая строка программы. Если данные желательно расположить в начале программы, перед ними следует поместить оператор перехода на реальную точку входа, например JMP Entry.
Образ памяти программы типа .COM показан на рисунке 3. После загрузки программы все сегментные регистры указывают на начало единственного сегмента, т.е фактически на начало PSP. Указатель стека автоматически инициализируется числом FFFEh. Таким образом, независимо от фактического размера программы ей выделяется 64 кбайт адресного пространства, всю нижнюю часть которого занимает стек.
|
CS, DS, ES, SS ¾> |
PSP (256 байтов) |
|
|
|
Программа и данные |
<¾ IP |
|
|
Стек |
|
|
|
|
<¾ SP = FFFEh
|
Рисунок 3 - Образ памяти программы .COM
Основная литература – 2[128-131].
Контрольные вопросы
1. Как вычисляется 20-разрядный адрес любой ячейки памяти?
2. Разрядность шин данных и адресов в i80386 и i486?
3. Отличия программ форматов .COM и .EXE?
3 Лекция 3. Пользовательские регистры микропроцессора
Программная модель микропроцессора содержит 32 регистра доступных для использования программистом. Данные регистры можно разделить на две большие группы: 16 пользовательских регистров и 16 системных регистров.
В программах на языке ассемблера регистры используются очень интенсивно. Большинство регистров имеют определенное функциональное назначение.
Пользовательские регистры
К этим регистрам относятся (см. рисунок 4):
- восемь 32-битных регистров, которые могут использоваться программистами для хранения данных и адресов (их еще называют регистрами общего назначения (РОН)):
- eax/ax/ah/al;
- ebx/bx/bh/bl;
- edx/dx/dh/dl;
- ecx/cx/ch/cl;
- ebp/bp;
- esi/si;
- edi/di;
- esp/sp.
- шесть регистров сегментов cs, ds, ss, es, fs, gs;
- регистры состояния и управления:
- регистр флагов eflags/flags;
- регистр указателя команды eip/ip.
Для обеспечения работоспособности программ, написанных для младших 16-разрядных моделей микропроцессоров фирмы Intel, начиная с i8086, можно использовать отдельно части одного большого 32-разрядного регистра. 32-разрядные регистры имеют приставку e (Extended).
Регистры общего назначения
Все регистры этой группы позволяют обращаться к своим “младшим” частям. Использовать для самостоятельной адресации можно только младшие 16 и 8-битные части этих регистров. Старшие 16 бит этих регистров как самостоятельные объекты недоступны.
К регистрам общего назначения относятся следующие регистры:
- eax/ax/ah/al (Accumulator register) — аккумулятор;
- ebx/bx/bh/bl (Base register) — базовый регистр;
- ecx/cx/ch/cl (Count register) — регистр-счетчик;
- edx/dx/dh/dl (Data register) — регистр данных.

Регистры EAX, EBX, ECX, EDX могут использоваться для любых целей – временного хранения данных, аргументов и результатов различных операций.
Следующие два регистра используются для поддержки так называемых цепочечных операций, то есть операций, производящих последовательную обработку цепочек элементов, каждый из которых может иметь длину 32, 16 или 8 бит:
esi/si (Source Index register) — индекс источника. Этот регистр в цепочечных операциях содержит текущий адрес элемента в цепочке-источнике;
edi/di (Destination Index register) — индекс приемника (получателя). Этот регистр в цепочечных операциях содержит текущий адрес в цепочке-приемнике.
В архитектуре микропроцессора на программно-аппаратном уровне поддерживается такая структура данных, как стек. Для работы со стеком в системе команд микропроцессора есть специальные команды, а в программной модели микропроцессора для этого существуют специальные регистры:
- esp/sp (Stack Pointer register) — регистр указателя стека. Содержит указатель вершины стека в текущем сегменте стека;
- ebp/bp (Base Pointer register) — регистр указателя базы кадра стека. Предназначен для организации произвольного доступа к данным внутри стека.
Большинство регистров могут использоваться при программировании для хранения операндов практически в любых сочетаниях.
Сегментные регистры
Имеется шесть сегментных регистров: cs, ss, ds, es, gs, fs. Микропроцессор аппаратно поддерживает структурную организацию программы в виде трех частей, называемых сегментами. Соответственно, такая организация памяти называется сегментной.
Для того чтобы указать на сегменты, к которым программа имеет доступ в конкретный момент времени, и предназначены сегментные регистры. Фактически в этих регистрах содержатся адреса памяти с которых начинаются соответствующие сегменты. Логика обработки машинной команды построена так, что при выборке команды, доступе к данным программы или к стеку неявно используются адреса во вполне определенных сегментных регистрах. Микропроцессор поддерживает следующие типы сегментов:
1. Сегмент кода. Содержит команды программы. Для доступа к этому сегменту служит регистр cs (code segment register) — сегментный регистр кода. Он содержит адрес сегмента с машинными командами, к которому имеет доступ микропроцессор (то есть эти команды загружаются в конвейер микропроцессора).
2. Сегмент данных. Содержит обрабатываемые программой данные. Для доступа к этому сегменту служит регистр ds (data segment register) — сегментный регистр данных, который хранит адрес сегмента данных текущей программы.
3. Сегмент стека. Этот сегмент представляет собой область памяти, называемую стеком. Работу со стеком микропроцессор организует по следующему принципу: последний записанный в эту область элемент выбирается первым. Для доступа к этому сегменту служит регистр ss (stack segment register) — сегментный регистр стека, содержащий адрес сегмента стека.
4. Дополнительный сегмент данных. Неявно алгоритмы выполнения большинства машинных команд предполагают, что обрабатываемые ими данные расположены в сегменте данных, адрес которого находится в сегментном регистре ds. Если программе недостаточно одного сегмента данных, то она имеет возможность использовать еще три дополнительных сегмента данных. Но в отличие от основного сегмента данных, адрес которого содержится в сегментном регистре ds, при использовании дополнительных сегментов данных их адреса требуется указывать явно с помощью специальных префиксов переопределения сегментов в команде. Адреса дополнительных сегментов данных должны содержаться в регистрах es, gs, fs (extension data segment registers).
Регистры состояния и управления
В микропроцессор включены несколько регистров (см. рисунок 4), которые постоянно содержат информацию о состоянии, как самого микропроцессора, так и программы, команды которой в данный момент загружены на конвейер. К этим регистрам относятся:
- регистр флагов eflags/flags;
- регистр указателя команды eip/ip.
Используя эти регистры, можно получать информацию о результатах выполнения команд и влиять на состояние самого микропроцессора. Рассмотрим подробнее назначение и содержимое этих регистров:
eflags/flags (flag register) — регистр флагов. Разрядность eflags/flags — 32/16 бит. Отдельные биты данного регистра имеют определенное функциональное назначение и называются флагами. Младшая часть этого регистра полностью аналогична регистру flags для i8086. На рисунке 5 показано содержимое регистра eflags.
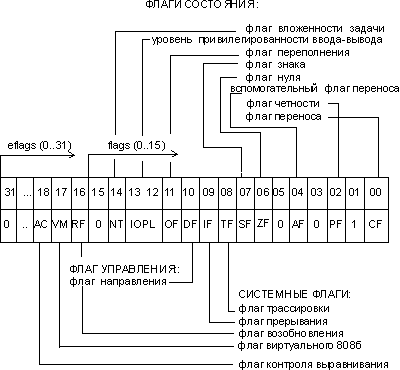
Рисунок 5 - Содержимое регистра eflags
Исходя из особенностей использования, флаги регистра eflags/flags можно разделить на три группы:
- 8 флагов состояния. Эти флаги могут изменяться после выполнения машинных команд. Флаги состояния регистра eflags отражают особенности результата исполнения арифметических или логических операций. Это дает возможность анализировать состояние вычислительного процесса и реагировать на него с помощью команд условных переходов и вызовов подпрограмм;
-
1 флаг управления. Обозначается df (Directory Flag).
Он находится в 10-м бите регистра eflags и используется цепочечными командами.
Значение флага df определяет направление поэлементной обработки в этих
операциях: от начала строки к концу (df=0) либо, наоборот, от конца строки к ее
началу (df=1). Для работы с флагом df существуют специальные команды: cld
(обнулить флаг df) и std (установить флаг df).
Применение этих команд позволяет привести флаг df в соответствие с
алгоритмом и обеспечить автоматическое увеличение или уменьшение счетчиков при
выполнении операций со строками;
- 5 системных флагов, управляющих вводом/выводом, маскируемыми прерываниями, отладкой, переключением между задачами и виртуальным режимом 8086. Прикладным программам не рекомендуется модифицировать без необходимости эти флаги, так как в большинстве случаев это приведет к прерыванию работы программы.
Флаги состояния
CF – Флаг переноса (Carry Flag). Устанавливается в 1, если в результате арифметической операции произошел перенос из старшего бита результата. Старшим является 7, 15 или 31-й бит в зависимости от размерности операнда. Если переноса не было, то CF=0.
PF - Флаг паритета (Parity Flag). Устанавливается в 1, если младший байт результата содержат четное число единиц, иначе – 0.
AF – Вспомогательный флаг переноса (Auxiliary carry Flag). Устанавливается в 1, если в результате предыдущей операции произошел перенос или заем между 3 и 4 разрядами, иначе – 0.
ZF - Флаг нуля (Zero Flag). Устанавливается в 1, если получен нулевой результат, иначе – 0.
SF – Флаг знака (Sign Flag). Он всегда равен старшему биту результата (биты 7, 15 или 31 для 8, 16 или 32-разрядных операндов соответственно).
OF – Флаг переполнения (Overflow Flag). Устанавливается в 1, если результат предыдущей арифметической операции над числами со знаком выходит за допустимые для них пределы.
IOPL – Уровень привилегий ввода-вывода (Input/Output Privilege Level). Используется в защищенном режиме работы микропроцессора для контроля доступа к командам ввода-вывода в зависимости от привилегированности задачи.
NT – флажок вложенности задачи (Nested Task).
Системные флаги
TF - Флаг трассировки (Trace Flag). Предназначен для организации пошаговой работы микропроцессора. Если TF=1 — микропроцессор генерирует прерывание с номером 1 после выполнения каждой машинной команды. Может использоваться при отладке программ, в частности отладчиками. А если TF=0 — обычная работа.
IF - Флаг прерывания (Interrupt enable Flag). Предназначен для разрешения или запрещения (маскирования) аппаратных прерываний (прерываний по входу INTR). 1—аппаратные прерывания разрешены; 0—аппаратные прерывания запрещены.
RF – Флаг возобновления (Resume Flag). Используется при обработке прерываний от регистров отладки.
VM – Флаг виртуального режима (Virtual 8086 Mode). Признак работы микропроцессора в режиме виртуального 8086. 1 — процессор работает в режиме виртуального 8086; 0 — процессор работает в реальном или защищенном режиме.
AC - Флаг контроля выравнивания (Alignment Check). Предназначен для разрешения контроля выравнивания при обращениях к памяти. Используется совместно с битом AM в системном регистре CR0. К примеру, Pentium разрешает размещать команды и данные с любого адреса. Если требуется контролировать выравнивание данных и команд по адресам кратным 2 или 4, то установка данных битов приведет к тому, что все обращения по некратным адресам будут возбуждать исключительную ситуацию.
eip/ip (Instraction Pointer register) — регистр-указатель команд. Регистр eip/ip имеет разрядность 32/16 бит и содержит смещение следующей подлежащей выполнению команды относительно содержимого сегментного регистра cs в текущем сегменте команд. Этот регистр непосредственно недоступен программисту, но загрузка и изменение его значения производятся различными командами управления, к которым относятся команды условных и безусловных переходов, вызова процедур и возврата из процедур. Возникновение прерываний также приводит к модификации регистра eip/ip.
Основная литература – 1[36-46], 2[20-24], 4[7-10],
Контрольные вопросы
1. Какие регистры общего назначения используются в микропроцессорах i486 и Pentium.
2. Какие флаги состояния существуют и их назначение.
3. Назначение флага управления.
4. Какие регистры используются для обращения к данным в сегменте стека?
5. Какие регистры могут использоваться в качестве базовых в микропроцессорах 80386 и старше?
4 Лекция 4. Системные регистры микропроцессора
Использование системных регистров жестко регламентировано. Именно они обеспечивают работу защищенного режима. Их также можно рассматривать как часть архитектуры микропроцессора, которая намеренно оставлена видимой для того, чтобы квалифицированный системный программист мог выполнить самые низкоуровневые операции.
Системные регистры можно разделить на три группы:
- четыре регистра управления;
- четыре регистра системных адресов;
- восемь регистра отладки.
Регистры управления
В группу регистров управления входят 4 регистра: CR0, CR1, CR2, CR3. Эти регистры предназначены для общего управления системой. Регистры управления доступны только программам с уровнем привилегий 0. Хотя микропроцессор имеет четыре регистра управления, доступными являются только три из них — исключается CR1, функции которого пока не определены (он зарезервирован для будущего использования).
Регистр CR0 содержит системные флаги, управляющие режимами работы микропроцессора и отражающие его состояние глобально, независимо от конкретных выполняющихся задач. Назначение системных флагов:
- pe (Protect Enable), бит 0 — разрешение защищенного режима работы. Состояние этого флага показывает, в каком из двух режимов — реальном (pe=0) или защищенном (pe=1) — работает микропроцессор в данный момент времени;
- mp (Math Present), бит 1 — наличие сопроцессора. Всегда 1;
- ts (Task Switched), бит 3 — переключение задач. Процессор автоматически устанавливает этот бит при переключении на выполнение другой задачи;
- am (Aligment Mask), бит 18 — маска выравнивания. Этот бит разрешает (am = 1) или запрещает (am = 0) контроль выравнивания;
- cd (Cache Disable), бит 30, — запрещение кэш-памяти. С помощью этого бита можно запретить (cd = 1) или разрешить (cd = 0) использование внутренней кэш-памяти (кэш-памяти первого уровня);
- pg (PaGing), бит 31, — разрешение (pg = 1) или запрещение (pg = 0) страничного преобразования. Флаг используется при страничной модели организации памяти.
Регистр CR2 используется при страничной организации оперативной памяти для регистрации ситуации, когда текущая команда обратилась по адресу, содержащемуся в странице памяти, отсутствующей в данный момент времени в памяти. В такой ситуации в микропроцессоре возникает исключительная ситуация с номером 14, и линейный 32-битный адрес команды, вызвавшей это исключение, записывается в регистр CR2. Имея эту информацию, обработчик исключения 14 определяет нужную страницу, осуществляет ее подкачку в память и возобновляет нормальную работу программы.
Регистр CR3 также используется при страничной организации памяти. Это так называемый регистр каталога страниц первого уровня. Он содержит 20-битный физический базовый адрес каталога страниц текущей задачи. Этот каталог содержит 1024 32-битных дескриптора, каждый из которых содержит адрес таблицы страниц второго уровня. В свою очередь каждая из таблиц страниц второго уровня содержит 1024 32-битных дескриптора, адресующих страничные кадры в памяти. Размер страничного кадра — 4 кбайт.
Регистры системных адресов
Эти регистры еще называют регистрами управления памятью. Они предназначены для защиты программ и данных в мультизадачном режиме работы микропроцессора.
При работе в защищенном режиме микропроцессора адресное пространство делится на:
- глобальное — общее для всех задач;
- локальное — отдельное для каждой задачи.
Этим разделением и объясняется присутствие в архитектуре микропроцессора следующих системных регистров:
- регистра таблицы глобальных дескрипторов GDTR (Global Descriptor Table Register) имеющего размер 48 бит и содержащего 32-битовый (биты 16—47) базовый адрес глобальной дескрипторной таблицы GDT и 16-битовое (биты 0—15) значение предела, представляющее собой размер в байтах таблицы GDT;
- регистра таблицы локальных дескрипторов LDTR (Local Descriptor Table Register) имеющего размер 16 бит и содержащего так называемый селектор дескриптора локальной дескрипторной таблицы LDT. Этот селектор является указателем в таблице GDT, который и описывает сегмент, содержащий локальную дескрипторную таблицу LDT;
- регистра таблицы дескрипторов прерываний IDTR (Interrupt Descriptor Table Register) имеющего размер 48 бит и содержащего 32-битовый (биты 16–47) базовый адрес дескрипторной таблицы прерываний IDT и 16-битовое (биты 0—15) значение предела, представляющее собой размер в байтах таблицы IDT;
- 16-битового регистра задачи TR (Task Register), который подобно регистру ldtr, содержит селектор, то есть указатель на дескриптор в таблице GDT. Этот дескриптор описывает текущий сегмент состояния задачи (TSS — Task Segment Status). Этот сегмент создается для каждой задачи в системе, имеет жестко регламентированную структуру и содержит контекст (текущее состояние) задачи. Основное назначение сегментов TSS — сохранять текущее состояние задачи в момент переключения на другую задачу.
Регистры отладки
Это очень интересная группа регистров, предназначенных для аппаратной отладки. Средства аппаратной отладки впервые появились в микропроцессоре i486. Аппаратно микропроцессор содержит восемь регистров отладки, но реально из них используются только 6.
Регистры DR0, DR1, DR2, DR3 имеют разрядность 32 бит и предназначены для задания линейных адресов четырех точек прерывания. Используемый при этом механизм следующий: любой формируемый текущей программой адрес сравнивается с адресами в регистрах DR0...DR3, и при совпадении генерируется исключение отладки с номером 1. Регистр DR6 называется регистром состояния отладки. Биты этого регистра устанавливаются в соответствии с причинами, которые вызвали возникновение последнего исключения с номером 1.
Перечислим эти биты и их назначение:
- b0 — если этот бит установлен в 1, то последнее исключение (прерывание) возникло в результате достижения контрольной точки, определенной в регистре DR0;
- b1 — аналогично b0, но для контрольной точки в регистре DR1;
- b2 — аналогично b0, но для контрольной точки в регистре DR2;
- b3 — аналогично b0, но для контрольной точки в регистре DR3;
- bd (бит 13) — служит для защиты регистров отладки;
- bs (бит 14) — устанавливается в 1, если исключение 1 было вызвано состоянием флага tf = 1 в регистре eflags;
- bt (бит 15) устанавливается в 1, если исключение 1 было вызвано переключением на задачу с установленным битом ловушки в TSS t = 1.
Все остальные биты в этом регистре заполняются нулями. Обработчик исключения 1 по содержимому DR6 должен определить причину, по которой произошло исключение, и выполнить необходимые действия.
Регистр DR7 называется регистром управления отладкой. В нем для каждого из четырех регистров контрольных точек отладки имеются поля, с помощью которых можно уточнить следующие условия, при которых следует сгенерировать прерывание:
- место регистрации контрольной точки — только в текущей задаче или в любой задаче. Эти биты занимают младшие восемь бит регистра DR7 (по два бита на каждую контрольную точку (фактически точку прерывания), задаваемую регистрами DR0, DR1, DR2, DR3 соответственно). Первый бит из каждой пары — это так называемое локальное разрешение; его установка говорит о том, что точка прерывания действует, если она находится в пределах адресного пространства текущей задачи. Второй бит в каждой паре определяет глобальное разрешение, которое говорит о том, что данная контрольная точка действует в пределах адресных пространств всех задач, находящихся в системе;
- тип доступа, по которому инициируется прерывание: только при выборке команды, при записи или при записи/чтении данных. Биты, определяющие подобную природу возникновения прерывания, локализуются в старшей части данного регистра.
Большинство из системных регистров программно доступны.
Основная литература – 1[36-46 ], 2[20-24], 4[7-10],
Контрольные вопросы
1. Какие системные регистры используются в микропроцессорах i486 и Pentium.
2. Назначение системных флагов.
3. Назначение регистров системных адресов.
4. Какие регистры управления и отладки используются в микропроцессорах i486 и Pentium.
5 Лекция 5. Способы адресации операндов
Операнды могут находиться в регистрах, в памяти, в самих командах. Существуют различные способы задания адреса хранения операндов. В командах Ассемблера используются следующие способы адресации: регистровая, непосредственная, прямая, косвенная, адресация по базе со сдвигом, косвенная адресация с масштабированием, адресация по базе с индексированием, адресация по базе с индексированием и масштабированием.
Регистровая адресация
Операнд может находиться в любом регистре общего назначения или сегментном регистре:
mov AX, BX
Непосредственная адресация
Операнд находится в команде:
а) mov AX, 10 ; 10 - непосредственный операнд
б) mov BX, OFFSET A ; OFFSET A- непосредственный операнд
в) mov AX, K ; K - непосредственный операнд, если K определен с помощью
; псевдооператоров EQU или =, т.е. K EQU 10.
Прямая адресация
Операнд находится в памяти. В команде указывается адрес операнда: mov AX, A ;
A - адрес операнда, который описан в сегменте данных в виде оператора: A DW 10, 20, 30
mov AX, A+2 ; AX = 20
Косвенная адресация
Операнд находится в памяти, в регистре находится адрес операнда
mov AX, [BX] ; в BX находится адрес операнда
Квадратные скобки указывают на то, что в регистре находится адрес. До процессора 80386 для указания адреса операнда можно было использовать только BX, BP, SI, DI, но потом ограничения были сняты и адрес операнда можно считывать также из EAX, EBX, ECX, EDX, ESI, EDI, EBP и ESP.
Адресация по базе со сдвигом
Операнд находится в памяти, адрес операнда вычисляется сложением значения базового регистра и сдвига.
mov AX, [BX+2]
mov AX, [BP] +2
mov AX, 2[BX]
До процессора 80386 в качестве базового регистра можно было использовать только BX, BP, SI или DI и сдвиг мог быть только байтом или словом. Процессоры, начиная с 80386 и старше, могут использовать EAX, EBX, ECX, EDX, ESI, EDI, EBP и ESP. С помощью этого способа можно организовать доступ к одномерным массивам байтов.
Косвенная адресация с масштабированием
Этот метод полностью идентичен предыдущему, однако с его помощью можно прочитать элемент массива слов, двойных слов или учетверенных слов, просто поместив номер элемента в регистр:
mov AX, [ESI*2] +2
Множитель, который равен 1, 2, 4 или 8, соответствует размеру элемента массива – байту, слову, двойному слову или учетверенному слову. Из регистров можно использовать только EAX, EBX, ECX, EDX, ESI, EDI, EBP, ESP, но не SI, DI, BP или SP.
Адресации по базе с индексированием
В этом методе адресации смещение операнда в памяти вычисляется как сумма чисел, содержащихся в двух регистрах, и смещения, если оно указано. Допускаются следующие формы записи:
mov AX, 2[BX][SI]
mov AX, [BX+2][SI]
mov AX, [BX][SI]+2
mov AX, 2[BX][SI+2]
mov AX, [BX+SI+2]
Для 16-битных регистров допускаются следующие сочетания регистров: BX+SI, BX+DI, BP+SI и BP+DI, а для 32-битных – все восемь регистров общего назначения.
Для перечисленных способов адресации операнды находятся в сегменте данных, исключением является использование при адресации регистра BP(EBP), когда операнд находится в сегменте стека.
Адреса операндов загружаются в регистры с помощью команд:
mov BX, OFFSET TAB или lea BX, TAB
Адресации по базе с индексированием и масштабированием
Это самая полная схема адресации, в которую входят все случаи, рассмотренные ранее как частные. Полный адрес операнда можно записать как выражение, представленное на рисунке 6.
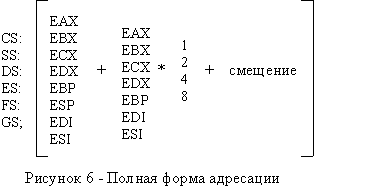
Смещение может быть байтом или двойным словом. Если ESP или EBP используются в роли базового регистра, селектор сегмента операнда берется по умолчанию из регистра SS, во всех остальных случаях - из DS.
Основная литература – 2[24-28].
Контрольные вопросы
1. Перечислите способы адресации операндов, находящихся в памяти.
2. Какие регистры могут содержать адреса операндов в микропроцессоре 8086?
3. Какие способы адресации удобно использовать для работы с массивами слов, двойных слов?
4. Приведите примеры полной формы адресации.
6 Лекция 6. Система команд микропроцессоров i80x86
Все микропроцессоры семейства i80х86 работают с набором команд i8086. Набор команд можно разделить на группы: команды пересылки данных, команды передачи управления, арифметические команды, команды манипулированиями битами, цепочечные команды, команды прерывания и команды управления микропроцессором.
6.1 Команды пересылки данных
Команды пересылки используются для пересылки данных, адресов, флагов.
Команды пересылки общего назначения
MOV - команда пересылки. Формат команды: MOV приемник, источник
Команда MOV пересылает операнд источник (байт, слово или двойное слово) на место операнда приемника, где в качестве приемника может использоваться регистр или ячейка памяти, а в качестве источника - регистр, ячейка памяти или константа.
С помощью команды MOV нельзя переслать:
а) содержимое одной ячейки памяти в другую;
б) содержимое одной ячейки памяти в сегментный регистр и наоборот;
в) содержимое одного сегментного регистра в другой сегментный регистр.
Эти пересылки можно выполнить через промежуточный регистр. В качестве промежуточного регистра используются регистры общего назначения, кроме SP.
В команде MOV разрешены пересылки: регистр - регистр, регистр - память, память - регистр, регистр - непосредственное значение, память - непосредственное значение. Например:
mov AX, DX
mov AX, FLDA[SI]
mov FLDA, AX
mov AL, 22h
mov FLDA[BP][SI], 33h
PUSH - команда записи в стек. Формат команды: PUSH источник
Команда PUSH записывает в стек слово или двойное слово. В качестве источника используется регистр или ячейка памяти. Hапример:
push CX
push TABL
POP - Команда чтения из стека. Формат команды: POP приемник
Команда POP читает из стека слово или двойное слово. В качестве приемника используется регистр или ячейка памяти. Hапример:
pop BX
pop TABL
ХСHG - команда обмена. Формат команды: ХСHG операнд1, операнд2
Команда меняет местами байты, слова или двойные слова. В качестве операндов могут использоваться регистры и ячейки памяти в сочетаниях: регистр - регистр, регистр - память.
Hапример: хсhg AX, DX
xchg BX, A[SI]
XLAT - Команда перекодировки. Формат команды: XLAT таблица_источник
Команда вычисляет адрес, равный ds:bx+(al), а затем выполняет замену байта в регистре al байтом из памяти по вычисленному адресу.
При использовании команды XLAT номер элемента, который нужно перекодировать заносится в регистр AL, а адрес таблицы_источника заносится в регистр BX. После выполнения команды XLAT результат заносится в регистр AL. Hапример:
; в сегмент данных
ASCII DB '0123456789'
; в сегмент кода
mov BX, offset ASCII
mov AL, 5
xlat ; AL=35h
Команды ввода-вывода
IN - Ввод операнда из порта. Формат команды: IN аккумулятор, порт
Команда IN пересылает байт, слово или двойное слово из порта в микропроцессор.
OUT - Вывод операнда в порт. Формат команды: OUT порт, аккумулятор
Команда пересылает байт, слово или двойное слово из микропроцессора в порт.
В качестве аккумулятора используются регистры AL (для пересылки байтов), AX (для пересылки слов) и EAX (для пересылки двойных слов), в качестве оператора порт используются номера портов от 0 до 255 или регистр DX. Hапример:
in AL, 60h
out 20h, AL
in AX, DX
out DX, AX
Команды пересылки адреса
LEA - Команда загрузки эффективного адреса. Формат команды: LEA приемник, источник
При выполнении команды в регистр приемник загружается 16-битное, либо 32-битное значение смещения операнда источник. В качестве операнда приемник используются регистры общего назначения. Операнд источник должен быть определен через директиву DW или DD. Например:
TAB DW 10h, 20h,30h
lea BX, TAB
Данная команда является альтернативой оператору ассемблера offset. В отличие от offset команда lea допускает индексацию операнда, что позволяет более гибко организовать адресацию операндов. Например:
; загрузить в регистр bx адрес пятого элемента массива mas.data
mas db 10 dup (0)
.code
... mov di, 4 lea bx, mas[di];или
lea bx, mas[4] ;илиlea bx, mas+4.
LDS/LES/LFS/LGS/LSS Загрузка сегментного регистра ds/es/fs/gs/ss указателем из памяти.
Формат команды: LDS приемник,источник.
Команда загружает младшее слово в регистр, указанный в команде, а старшее слово - в сегментный регистр DS. Например:
main DD 10000100h
lds BX, main
Команда LDS заменяет 3 команды MOV:
mov BX, offset main
mov AX, seg main
mov DS, AX
Команды LES, LFS, LGS, LSS выполняются аналогична LDS, но адрес сегмента загружается в регистры ES, FS, GS, SS соответственно.
Команды пересылки флагов
LAHF - Загрузка флагов в регистр AH.
Команда LAHF загружает младший байт регистра флагов в регистр AH.
SAHF - Установка флагов из регистра AH.
Команда SAHF переписывает разряды 0, 2, 4, 6, 7 регистра AH в младший байт регистра флагов.
PUSHF - Занесение флагов в стек.
Команда PUSHF сохраняет содержимое регистра флагов в стеке.
POPF - Извлечение флагов из стека.
Команда POPF читает слово из стека и записывает его в регистр флагов.
6.2 Команды передачи управления
Команды передачи управления обеспечивают переход из одной части программы в другую. По принципу действия они делятся на три группы:
1. Команды безусловной передачи управления:
- команды безусловного перехода;
- вызова процедуры и возврата из процедуры;
- вызова программных прерываний и возврата из программных прерываний.
2. Команды условной передачи управления:
- команды переходы по результату команды сравнения cmp;
- команды перехода по состоянию определенного флага;
- команды перехода по содержимому регистра cx (ecx).
3. Команды управления циклом:
- команда организации цикла со счетчиком cx (ecx);
- команда организации цикла со счетчиком cx (ecx) с возможностью досрочного выхода из цикла по дополнительному условию.
Команды безусловной передачи управления
Jmp - команда безусловного перехода. Формат команды: jmp [модификатор] адрес_перехода
Адрес_перехода представляет собой адрес в виде метки либо адрес области памяти, в которой находится указатель перехода. Имеется несколько кодов машинных команд безусловного перехода jmp. Адрес_перехода может находиться в текущем сегменте кода или в некотором другом сегменте. В первом случае переход называется внутрисегментным, или близким, во втором — межсегментным, или дальним. При внутрисегментном переходе изменяется только содержимое регистра eip/ip. Можно выделить три варианта внутрисегментного использования команды jmp: прямой короткий; прямой; косвенный. Модификатор может принимать следующие значения:
- near ptr — прямой переход на метку внутри текущего сегмента кода. Модифицируется только регистр eip/ip (use16 или use32) на основе указанного в команде адреса (метки);
- far ptr — прямой переход на метку в другом сегменте кода. Адрес перехода задается в виде непосредственного операнда или адреса (метки) и состоит из 16-битного селектора и 16/32-битного смещения, которые загружаются, соответственно, в регистры cs и ip/eip;
- word ptr — косвенный переход на метку внутри текущего сегмента кода. Модифицируется только eip/ip. Размер смещения 16 или 32 бит;
- dword ptr — косвенный переход на метку в другом сегменте кода. Модифицируются оба регистра, cs и eip/ip. Первое слово/двойное слово этого адреса представляет смещение и загружается в ip/eip; второе/третье слово загружается в cs.
CALL - вызов процедуры. Формат команды: CALL имя_процедуры
RET - возврат из процедуры.
Процедура представляет собой совокупность команд, которая написана один раз, но может быть исполнена по мере необходимости в любом месте программы.
Команда CALL осуществляет функции запоминания адреса возврата и передачи управления процедуре. Она помещает в стек смещение адреса возврата, если процедура определена с артибутом NEAR, и содержимое регистра сегмента команд CS, а затем смещение адреса, если она определена с атрибутом FAR. Процедуры с атрибутом NEAR могут быть вызваны только из того сегмента, в котором они находятся, а с FAR могут быть вызваны и из другого сегмента.
После сохранения адреса возврата команда CALL загружает смещение адреса метки “имя_процедуры” в указатель команд IP (EIP). Если процедура имеет атрибут FAR, то команда CALL загружает также сегментный адрес метки “имя_процедуры” в регистр CS.
Команда RET извлекает из стека адрес возврата. Если процедура имеет атрибут NEAR, то команда RET извлекает из стека одно слово (двойное слово) и загружает его в указатель команд IP (EIP). Если процедура имеет атрибут FAR, то команда RET извлекает из стека два (три) слова: сначала смещение адреса для загрузки в указатель команд IP (EIP), а затем адрес сегмента для загрузки в регистр CS.
Команды условной передачи управления
Команды условной передачи управления имеют следующий общий формат:
Jx метка_перехода,
где х - модификатор, состоящий их одной или нескольких букв, может принимать следующие значения:
- E (equal) – равно;
- N (not) – не;
- G (greater) – больше;
- L (less) – меньше;
- A (above) – выше;
- B (below) – ниже.
Модификаторы E, N используются для любых типов операндов, G и L – для чисел со знаком, A и B - для чисел со знаком.
Команды условного перехода удобно применять для проверки различных условий, возникающих в ходе выполнения программы. Многие команды формируют признаки результатов своей работы в регистре flags (eflags). Это обстоятельство используется командами условного перехода для работы. Ниже приведены перечень команд условного перехода, анализируемые ими флаги и соответствующие им логические условия перехода.
|
Команда |
Состояние проверяемых флагов |
Условие перехода |
|
JA |
CF = 0 и ZF = 0 |
если выше |
|
JAE |
CF = 0 |
если выше или равно |
|
JB |
CF = 1 |
если ниже |
|
JBE |
CF = 1 или ZF = 1 |
если ниже или равно |
|
JC |
CF = 1 |
если перенос |
|
JE |
ZF = 1 |
если равно |
|
JZ |
ZF = 1 |
если 0 |
|
JG |
ZF = 0 и SF = OF |
если больше |
|
JGE |
SF = OF |
если больше или равно |
|
JL |
SF <> OF |
если меньше |
|
JLE |
ZF=1 или SF <> OF |
если меньше или равно |
|
JNA |
CF = 1 и ZF = 1 |
если не выше |
|
JNAE |
CF = 1 |
если не выше или равно |
|
JNB |
CF = 0 |
если не ниже |
|
JNBE |
CF=0 и ZF=0 |
если не ниже или равно |
|
JNC |
CF = 0 |
если нет переноса |
|
JNE |
ZF = 0 |
если не равно |
|
JNG |
ZF = 1 или SF <> OF |
если не больше |
|
JNGE |
SF <> OF |
если не больше или равно |
|
JNL |
SF = OF |
если не меньше |
|
JNLE |
ZF=0 и SF=OF |
если не меньше или равно |
|
JNO |
OF=0 |
если нет переполнения |
|
JNP |
PF = 0 |
если количество единичных битов результата нечетно (нечетный паритет) |
|
JNS |
SF = 0 |
если знак плюс (знаковый (старший) бит результата равен 0) |
|
JNZ |
ZF = 0 |
если нет нуля |
|
JO |
OF = 1 |
если переполнение |
|
JP |
PF = 1 |
если количество единичных битов результата четно (четный паритет) |
|
JPE |
PF = 1 |
то же, что и JP, то есть четный паритет |
|
JPO |
PF = 0 |
то же, что и JNP |
|
JS |
SF = 1 |
если знак минус (знаковый (старший) бит результата равен 1) |
|
JZ |
ZF = 1 |
если ноль |
|
JCXZ |
не влияет |
если регистр CX=0 |
|
JECXZ |
не влияет |
если регистр ECX=0 |
Логические условия “больше” и “меньше” относятся к сравнениям целочисленных значений со знаком, а "выше и “ниже” — к сравнениям целочисленных значений без знака. С целью удобства ассемблер допускает несколько различных мнемонических обозначений одной и той же машинной команды условного перехода. Изначально в микропроцессоре i8086 команды условного перехода могли осуществлять только короткие переходы в пределах -128...+127 байт, считая от следующей команды. Начиная с микропроцессора i386, эти команды уже могли выполнять любые переходы в пределах текущего сегмента команд. Для реализации межсегментных переходов необходимо комбинировать команды условного перехода и команду безусловного перехода jmp.
Командам условной передачи управления могут предшествовать любые команды, изменяющие состояние флагов, но обычно они используются совместно с командой сравнения СМР.
Команды управления циклами
Команды управления циклами обеспечивают условные передачи управления при организации циклов. Каждая команда уменьшает содержимое регистра счетчика СХ на 1, а затем использует его новое значение для принятия решения о выполнении или невыполнении перехода.
LOOP - повторять цикл до конца счетчика. Формат команды: LOOP метка.
Команды уменьшает содержимое регистра счетчика СХ на 1 и передает управление оператору метка, если содержимое регистра СХ не равно нулю. Команда LOOP завершает выполнение цикла только, если содержимое регистра СХ станет равным нулю. Однако во многих приложениях требуются такие циклы, которые должны завершаться при выполнении определенных условий до того, как содержимое регистра СХ достигает нуля. Такое альтернативное завершение цикла обеспечивается командами LOOPE (повторить цикл, если равно) и LOOPNE (повторить цикл, если не равно).
LOOPE (LOOPZ) - повторять цикл, пока равно (нуль). Команда уменьшает содержимое регистра СХ на 1, а затем осуществляет переход, если содержимое регистра СХ не равно 0 и флаг нуля ZF равен единице. Таким образом повторение цикла завершается, если либо содержимое регистра СХ равно нулю, либо флаг нуля ZF равен нулю, либо оба они равны нулю. Обычно команда LOOPE используется для поиска первого ненулевого результата в серии операций.
LOOPNE (LOOPNZ) - повторять цикл, пока не равно (нуль). Команда уменьшает содержимое регистра СХ на 1, затем осуществляет переход, если содержимое регистра СХ не равно нулю и флаг нуля ZF равен нулю. Таким образом, повторение цикла завершается, если либо содержимое регистра СХ равно нулю, либо флаг нуля ZF равен единице, либо будет выполнено и то и другое. Обычно команда LOOPNE используется для поиска первого нулевого результата в серии операций.
Основная литература – 1[202-228], 2[28-34, 47-54].
Контрольные вопросы
1. Какие данные можно пересылать с помощью команд пересылки?
2. Отличия при пересылке адреса с помощью команд MOV и LEA.
3. Как влияют на флаги команды пересылки?
4. На какие группы делятся команды передачи управления?
5. Условия выхода из цикла для команд LOOPE и LOOPNE.
7 Лекция 7. Система команд микропроцессоров i80x86
Арифметические команды
Сложение двоичных чисел
Микропроцессор выполняет сложение операндов по правилам сложения двоичных чисел. Выход результата за разрядную сетку фиксируется установкой флага переноса CF. Это предполагает включение участков кода после операции сложения, в которых анализируется флаг CF.
В системе команд микропроцессора имеются три команды двоичного сложения:
INC операнд — операция инкремента, то есть увеличения значения операнда на 1;
ADD приемник, источник — команда сложения с принципом действия:
приемник = приемник + источник
ADC приемник, источник — команда сложения с учетом флага переноса CF. Принцип действия команды:
приемник = приемник + источник + CF.
Рассмотрим пример вычисления суммы чисел
; Вычисление суммы чисел
a db 254
xor AX, AX
add AL, 17
add AL, a
jnc m1 ; если нет переноса, то перейти на m1
adc AH,0 ; в ax сумма с учетом переноса
m1: ...
Микропроцессор не различает числа со знаком и без знака. Вместо этого у него есть средства фиксирования возникновения характерных ситуаций, складывающихся в процессе вычислений. К ним относятся:
- флаг переноса CF, установка которого в 1 говорит о том, что произошел выход за пределы разрядности операндов;
- команда ADC, которая учитывает возможность такого выхода (перенос из младшего разряда).
- регистрация состояния старшего (знакового) разряда операнда, которое осуществляется с помощью флага переполнения OF.
Так как микропроцессор не знает о существовании чисел со знаком и без знака, то вся ответственность за правильность действий с получившимися числами ложится на программиста. Проанализировать флаги CF и OF можно командами условного перехода JC\JNC и JO\JNO соответственно.
Вычитание двоичных чисел
К командам вычитания относятся следующие:
- DEC операнд — операция декремента, то есть уменьшения значения операнда на 1;
- CMP приемник, источник - команда сравнения. Команда CMP так же, как и команда SUB, выполняет вычитание операндов и устанавливает флаги, но результат никуда не записывает. Флаги, устанавливаемые командой CMP, можно анализировать специальными командами условного перехода.
- SUB приемник, источник — команда вычитания; ее принцип действия:
- приемник = приемник – источник.
- SBB приемник, источник — команда вычитания с учетом заема (флага CF). Ее принцип действия: приемник = приемник - источник – CF.
Команда SBB подобна ADC, но теперь уже флаг CF выполняет роль индикатора заема 1 из старшего разряда при вычитании чисел.
После команды вычитания чисел без знака нужно анализировать состояние флага CF. Если он установлен в 1, то это говорит о том, что произошел заем из старшего разряда и результат получился в дополнительном коде.
При вычитании двоичных чисел со знаком, как и в случае знакового сложения переполнение мантиссы, когда значащий разряд числа изменил знаковый разряд операнда, можно отследить по содержимому флага переполнения OF. Его установка в 1 говорит о том, что результат вышел за диапазон представления знаковых чисел (т.е. изменился старший бит) для операнда данного размера, и программист должен предусмотреть действия по корректировке результата.
Умножение чисел
Для умножения чисел без знака предназначена команда: mul операнд.
Операнд может находиться в памяти или в регистре и иметь размер 8, 16 или 32 бит. В команде указан всего лишь один операнд. Второй операнд задан неявно. Его местоположение фиксировано и зависит от размера сомножителей. Так как в общем случае результат умножения больше, чем любой из его сомножителей, то его размер и местоположение должны быть тоже определены однозначно. Варианты размеров сомножителей и размещения второго операнда и результата:
|
Байт * |
AL |
= AX |
|
Слово * |
AX |
= DX:AX |
|
Двойное слово * |
EAX |
= EDX:EAX |
Для умножения чисел со знаком предназначена команда: imul операнд
Эта команда выполняется так же, как и команда MUL.
Отличительной особенностью команды IMUL является только формирование знака.
Если результат мал и умещается в одном регистре (то есть если CF = OF = 0), то
содержимое другого регистра (старшей части) является расширением знака — все
его биты равны старшему биту (знаковому разряду) младшей части результата.
В противном случае (если CF = OF = 1) знаком результата является знаковый бит
старшей части результата, а знаковый бит младшей части является значащим битом
двоичного кода результата.
В микропроцессорах i486 и старше команда IMUL допускает более широкие возможности
по заданию местоположения операндов. Это сделано для удобства
использования.
Деление чисел
Для деления чисел без знака предназначена команда: div делитель. Делитель может находиться в памяти или в регистре и иметь размер 8, 16 или 32 бит. Местонахождение делимого фиксировано и так же, как в команде умножения, зависит от размера операндов. Результатом команды деления являются значения частного и остатка. Расположение операндов и результата при делении:
|
Делимое |
Делитель |
Частное |
Остаток |
|
AX |
Байт (регистр или ячейка памяти) |
AL |
AH |
|
DX: AX |
Слово (регистр или ячейка памяти) |
AX |
DX |
|
EDX: EAX |
Двойное слово (регистр или ячейка памяти) |
EAX |
EDX |
После выполнения команды деления содержимое флагов неопределенно, но возможно возникновение прерывания с номером 0, называемого “деление на ноль”. Этот вид прерывания относится к так называемым исключениям. Прерывание 0, “деление на ноль”, при выполнении команды DIV может возникнуть по одной из следующих причин:
- делитель равен нулю;
- частное не входит в отведенную под него разрядную сетку.
Пример. Деление чисел
del _b label byte
del dw 29876
delt db 45
...xor ax, ax
; последующие две команды можно заменить одной mov ax, delmov ah, del_b ; старший байт делимого в ahmov al, del_b+1 ; младший байт делимого в aldiv delt ; в al — частное, в ah — остаток ...
Для деления чисел со знаком предназначена команда: IDIV делитель.
Для этой команды справедливы все рассмотренные положения, касающиеся команд и чисел со знаком. Отметим лишь особенности возникновения исключения 0, “деление на ноль”, в случае чисел со знаком. Оно возникает при выполнении команды IDIV по одной из следующих причин:
- делитель равен нулю;
- частное не входит в отведенную для него разрядную сетку.
Арифметические операции над двоично-десятичными числами
Отдельных команд сложения, вычитания, умножения и деления BCD-чисел нет. Складывать и вычитать можно двоично-десятичные числа как в упакованном формате, так и в неупакованном, а делить и умножать можно только неупакованные BCD-числа.
Сложение неупакованных BCD-чисел
Для коррекции операции сложения двух однозначных неупакованных BCD-чисел в системе команд микропроцессора существует специальная команда AAA (ASCII Adjust for Addition) — коррекция результата сложения для представления в символьном виде. Эта команда не имеет операндов. Она работает неявно только с регистром AL и анализирует значение его младшей тетрады:
- если это значение меньше 9, то флаг CF сбрасывается в 0 и осуществляется переход к следующей команде;
- если это значение больше 9, то выполняются следующие действия:
а) к содержимому младшей тетрады AL (но не к содержимому всего регистра!) прибавляется 6, тем самым значение десятичного результата корректируется в правильную сторону;
б) флаг CF устанавливается в 1, тем самым фиксируется перенос в старший разряд, для того чтобы его можно было учесть в последующих действиях.
Приведем пример программы сложения двух неупакованных BCD-чисел.
; Сложение неупакованных BCD-чиселlen equ 2 ; разрядность числаb db 1, 7 ; неупакованное число 71c db 4, 5 ; неупакованное число 54sum db 3 dup (0)
...xor bx, bx
mov cx, len
m1:
mov al, b[bx]
adс al, c[bx]
aaa
mov sum[bx], al.
В примере порядок ввода BCD-чисел обратен нормальному, то есть цифры младших разрядов расположены по меньшему адресу. Но это вполне логично по нескольким причинам:
- во-первых, такой порядок удовлетворяет общему принципу представления данных для микропроцессоров Intel;
- во-вторых, это очень удобно для поразрядной обработки неупакованных BCD-чисел, так как каждое из них занимает один байт.
Вычитание неупакованных BCD-чисел
AAS (ASCII Adjust for Substraction) — коррекция результата вычитания для представления в символьном виде. Команда AAS также не имеет операндов и работает с регистром AL, анализируя его младшую тетраду следующим образом:
- если ее значение меньше 9, то флаг CF сбрасывается в 0 и управление передается следующей команде;
- если значение тетрады в AL больше 9, то команда AAS выполняет следующие действия:
а) из содержимого младшей тетрады регистра AL вычитает 6;
б) обнуляет старшую тетраду регистра al;
в) устанавливает флаг CF в 1, тем самым фиксируя воображаемый заем из старшего разряда.
Команда AAS применяется вместе с основными командами вычитания SUB и SBB.
b db 1, 7 ; неупакованное число 71 c db 4, 5 ; неупакованное число 54subs db 2 dup (0)
len equ 2 ; разрядность чисел …xor ax, ax ; очищаем ax
xor bx, bx
mov cx, len ; загрузка в cx счетчика циклаm1:
mov al, b[bx]
sbb al, c[bx]
aas
mov subs[bx], al
inc bx
loop m1
jc m2 ; анализ флага заема
Умножение неупакованных BCD-чисел
Для того чтобы умножать числа произвольной размерности, нужно реализовать процесс умножения самостоятельно, взяв за основу некоторый алгоритм умножения, например “в столбик”. Для того чтобы перемножить два одноразрядных BCD-числа, необходимо:
- поместить один из сомножителей в регистр AL (как того требует команда MUL);
- поместить второй операнд в регистр или память, отведя байт;
- перемножить сомножители командой MUL (результат, как и положено, будет в AX);
- результат, конечно, получится в двоичном коде, поэтому его нужно скорректировать.
AAM (ASCII Adjust for Multiplication) — коррекция результата умножения для представления в символьном виде. Она не имеет операндов и работает с регистром AX следующим образом:
- делит AL на 10;
- результат деления записывается так: частное в AL, остаток в AH.
В результате после выполнения команды AAM в регистрах AL и AH находятся правильные двоично-десятичные цифры произведения двух цифр.
Команду AAM можно применять для преобразования двоичного числа в регистре AL в неупакованное BCD-число, которое будет размещено в регистре AX: старшая цифра результата в AH, младшая — в AL. Понятно, что двоичное число должно быть в диапазоне 0...99.
Деление неупакованных BCD-чисел
Процесс выполнения операции деления двух неупакованных BCD-чисел несколько отличается от других. Здесь также требуются действия по коррекции, но они должны выполняться до основной операции деления. Предварительно в регистре AX нужно получить две неупакованные BCD-цифры делимого. Далее нужно выдать команду AAD:
AAD (ASCII Adjust for Division) — коррекция деления для представления в символьном виде.
Команда не имеет операндов и преобразует двузначное неупакованное BCD-число в регистре AX в двоичное число. Это двоичное число впоследствии будет играть роль делимого в операции деления. Кроме преобразования, команда AAD помещает полученное двоичное число в регистр AL. Делимое, естественно, будет двоичным числом из диапазона 0...99.
Алгоритм, по которому команда AAD осуществляет это преобразование, состоит в следующем:
- умножить старшую цифру исходного BCD-числа в AX (содержимое AH) на 10;
- выполнить сложение AH + AL, результат которого (двоичное число) занести в AL;
- обнулить содержимое AH.
AAD ; коррекция перед делениемDIV C.
Команду AAD можно использовать ее для перевода неупакованных BCD-чисел из диапазона 0...99 в их двоичный эквивалент.
Арифметические действия над упакованными BCD-числами
Сложение упакованных BCD-чисел
Упакованные BCD-числа можно только складывать и вычитать.
DAA (Decimal Adjust for Addition) — коррекция результата сложения для представления в десятичном виде. Команда DAA преобразует содержимое регистра AL в две упакованные десятичные цифры. Получившаяся в результате сложения единица (если результат сложения больше 99) запоминается в флаге CF, тем самым учитывается перенос в старший разряд.
b db 17h ; упакованное число 17h c db 45h ; упакованное число 45mov al, b
add al, c
daa
jnc $+4 ; переход через команду, если результат <= 99 mov sum+1,ah ; учет переноса при сложении (результат > 99) mov sum, al ; младшие упакованные цифры результата
Вычитание упакованных BCD-чисел
Аналогично сложению, микропроцессор рассматривает упакованные BCD-числа как двоичные и, соответственно, выполняет вычитание BCD-чисел как двоичных. При программировании вычитания упакованных BCD-чисел программист должен сам осуществлять контроль за знаком. Это делается с помощью флага CF, который фиксирует заем из старших разрядов. Само вычитание BCD-чисел осуществляется простой командой вычитания SUB или SBB. Коррекция результата осуществляется командой DAS:
DAS (Decimal Adjust for Substraction) — коррекция результата вычитания для представления в десятичном виде. Команда DAS преобразует содержимое регистра AL в две упакованные десятичные цифры.
Команды преобразования типов
В системе команд микропроцессора есть несколько команд, которые могут облегчить программирование алгоритмов, производящих арифметические вычисления.
В арифметических операциях должны участвовать операнды одного формата. Для выполнения арифметических операций, имеющих разные размеры операндов, в системе команд микропроцессора есть так называемые команды преобразования типа. Эти команды расширяют байты в слова, слова — в двойные слова и двойные слова — в учетверенные слова (64-разрядные значения). Команды преобразования типа особенно полезны при преобразовании целых со знаком, так как они автоматически заполняют старшие биты вновь формируемого операнда значениями знакового бита старого объекта.
CBW - Команда преобразует байт в слово. Воспроизводит 7-й бит регистра AL во всех битах регистра АН.
CWD - Команда преобразует слово в двойное слово. Воспроизводит 15-й бит регистра АХ во всех битах регистра DX.
CWDE — команда преобразования слова (в регистре ax) в двойное слово (в регистре eax) путем распространения значения старшего бита ax на все биты старшей половины регистра eax;
CDQ — команда преобразования двойного слова (в регистре eax) в учетверенное слово (в регистрах edx:eax) путем распространения значения старшего бита eax на все биты регистра edx.
Они позволяют выполнять операции над смешанными данными.
cbw ; сложить байт в AL
add AX, BX ; со словом в ВХ
cbw ; умножить байт в AL на
imul BX ; слово в ВХ
cwd ; разделить слово в AL на
idiv BX ; слово в ВХ
cbw ; сложить байт в AL со
add AX, BX ; словом в ВХ
Основная литература – 1[153-183], 2[34-45].
Контрольные вопросы
1. Где находятся сомножители и результат при выполнении команды умножения?
2. Где находятся делимое, делитель и результат при выполнении команды деления?
3. Перечислите команды коррекции.
4. Назначение команд преобразования типов.
5. Чем отличается команда CMP от команды SUB?
8 Лекция 8. Команды обработки битов
Логические команды
Логические команды действуют по правилам формальной логики. Так как логические команды манипулируют битами операндов, то обычно при записи значений таких операндов используют шестнадцатеричную систему счисления. К логическим командам относятся AND (логическое умножение), OR (логическое сложение), XOR (сложение по модулю два), NOT (логическое отрицание), TEST (логической проверки).
Операндами команд AND, OR, XOR могут быть байты, слова или двойные слова. В этих командах можно сочетать два регистра, регистр с ячейкой памяти или непосредственное значение с регистром или ячейкой памяти.
AND - логическое "И". Формат команды: AND приемник, источник.
В каждой позиции бита, где оба операнда содержат единицу, операнд приемник также будет содержать единицу. В тех же позициях, где операнды имеют любую другую комбинацию значений, приемник будет содержать нуль.
Состояние флагов после выполнения команды: OF = CF = 0, SF, ZF и PF изменяют свое значение.
OR - логическое "ИЛИ". Формат команды:: OR приемник, источник.
Команда устанавливает в единицу те биты операнда приемника, в значениях которых хотя бы один из операндов содержит единицу.
Состояние флагов после выполнения команды: OF = CF = 0, SF, ZF и PF изменяют свое значение.
XOR - логическое "ИСКЛЮЧАЮЩЕЕ ИЛИ". Формат команды:: XOR приемник, источник.
Команда устанавливает в единицу все те биты приемника, в позициях которых операнды имеют различные значения, т.е. те биты, в позициях которых один из операндов имеет значение нуль, а другой единице. Если оба операнда содержат в данной позиции либо нуль, либо единицу, то команда обнуляет этот бит приемника.
NOT - логическое "НЕ". Формат команды: NOT операнд
Команда инвертирует состояние каждого бита регистра или ячейки памяти и ни на какие флаги не воздействует. Таким образом, команда заменяет нуль на единицу, а каждую единицу на нуль.
TEST - команда логической проверки. Формат команды: TEST приемник, источник.
Команда выполняет операцию AND над операндами, но воздействует только на флаги и не изменяет значения операндов. Состояние флагов после выполнения команды: OF = CF = 0, SF, ZF и PF изменяют свое значение.
Команды сдвига и циклического сдвига
Есть семь команд, осуществляющих сдвиг 8, 16 или 32- битового содержимого регистров или ячеек памяти на одну или несколько позиций влево или вправо. Три из них сдвигают операнд, а остальные четыре его вращают или циклически сдвигают. Для всех семи команд флаг переноса CF является как бы расширением операнда - битом 9, 17 или 33. Он приобретает значение бита, сдвинутого за один из концов операнда. Команды сдвига и циклического сдвига вправо перемещают во флаге переноса CF значение нулевого бита, а влево - значение бита 7, 15 или 31.
Команды делятся на две группы. Логические команды сдвигают операнд, не считаясь с его знаком. Арифметические команды сохраняют старший, знаковый бит операнда.
Общий формат команд сдвига: коп операнд, счетчик.
Команды сдвига и циклического сдвига имеют два операнда: приемник и счетчик. Приемником может быть 8, 16 или 32-битовый регистр общего назначения или ячейка памяти. Счетчик может быть непосредственным значением или значением без знака в регистре CL.
SAL - арифметический сдвиг влево.
SAR - арифметический сдвиг вправо.
Команды сдвигают числа со знаком. Команда SAR сохраняет знак операнда. Команда SAL - не сохраняет знак, но заносит 1 во флаг переполнения OF в случае изменения знака операнда.
При каждом сдвиге операнда команда SAL заносит 0 в вакантный нулевой бит этого операнда.
SHL – логический сдвиг влево.
SHR – логический сдвиг вправо.
Команды сдвигают числа без знака. Команда SHL идентична команде SAL. Команда SHR аналогична команде SHL, но сдвигает число вправо. При каждом сдвиге операнда команда SHR заносит ноль в вакантный старший бит этого операнда (бит 7, бит 15 или бит 31).
Состояние флагов после выполнения команд: Изменяются значения флагов OF, SF, ZF, PF, CF.
Поскольку сдвиг операнда на один бит влево удваивает значение операнда (умножение на 2), а сдвиг на один бит вправо уменьшает значение операнда вдвое (деление на 2), то команды сдвига можно использовать в качестве команд быстрого умножения и деления. Принцип действия команд SAL, SHL, SAR и SHR показан на рисунке 7.
Команды циклического сдвига сохраняют сдвинутые за пределы операнда биты, помещая их обратно в операнд. Сдвинутый за пределы операнда бит запоминается во флаге переноса CF.
ROL - циклический сдвиг влево.
ROR - циклический сдвиг вправо.
При исполнении этих команд вышедший за пределы операнда бит входит в него с противоположного конца.
RCL - циклический сдвиг влево через флаг переноса.
RCR - циклический сдвиг вправо через флаг переноса.
При исполнении этих команд в противоположный конец операнда помещается значение флага переноса CF.
Состояние флагов после выполнения команд: изменяются значения флагов OF, CF. Принцип действия команд показан на рисунке 8.

Основная литература – 1[184-201], 2[34-45].
Контрольные вопросы
1. Чем отличаются команды логического умножения (AND) и логической проверки (TEST)?
2. С помощью какой логической команды можно инвертировать отдельные биты байта, слова или двойного слова?
3. Назовите команды арифметического сдвига.
4. Назовите команды логического сдвига.
5. Назовите команды циклического сдвига.
9 Лекция 9. Цепочечные команды. Команды прерывания
9.1 Цепочечные команды
Эти команды также называют командами обработки строк символов. Цепочечные команды позволяют производить действия над блоками байтов, слов или двойных слов памяти. Эти блоки (или строки) могут состоять из числовых (двоичных или двоично-десятичных значений), алфавитно-цифровых значений (типа символов в коде ASCII), а также из любых других значений, которые могут храниться в памяти в виде двоичных кодов.
Цепочечные команды представляют возможность выполнения 5 основных операций, называемых примитивами, которые обрабатывают строку по одному элементу (байту, слову или двойному слову) за прием. Каждый примитив представлен тремя командами. Одна команда имеет один или два операнда, а две остальные не имеют операндов. Микропроцессор предполагает, что строка-приемник находится в дополнительном сегменте, а строка-источник – в сегменте данных. Процессор адресует строку-приемник через регистр индекса приемника DI (EDI), а строку-источник - через регистр индекса источника SI (ESI).
Так как команды обработки строк предназначены для действия над группой элементов, то они автоматически модифицируют указатели для адресации следующего элемента строки.
Бит флага направлений DF в регистре флагов микропроцессора определяет, будут значения регистров SI и DI увеличены или уменьшены по завершении выполнения команды обработки строк. Если флаг направления DF равен нулю, то значения регистров SI и DI увеличиваются, если флаг DF равен единице, то они уменьшаются.
Можно сделать так, чтобы одна команда обработки строк обработала группу последовательных элементов памяти. Для этого перед ней надо указать префикс повторения. Он представляет собой не команду, а однобайтовый модификатор, который заставляет микропроцессор выполнить аппаратные повторения команды обработки строк.
Префиксы повторения.
Префиксы повторения заставляют микропроцессор повторять цепочечную команду. Число повторений извлекается из регистра СХ (ECX).
Префикс REP - дает указание повторять, пока не обнаружится конец строки, т.е. пока значение регистра СХ не станет равным нулю.
Остальные префиксы повторения используют при решении о продолжении или прекращении повторений флаг нуля ZF.
Следовательно, они используются с командами сравнения строк и поиска значения в строке, которые воздействуют на флаг нуля ZF.
Префикс REPE (повторять, пока равно), имеющий синоним REPZ (повторять, пока нуль), повторяет команду, пока флаг нуля ZF равен единице и значение регистра СХ не равно нулю. Префикс REPNE (повторять, пока не равно), имеющий синоним REPNZ (повторять, пока не нуль), обеспечивает повторение, пока флаг нуля ZF равен нулю и значение регистра СХ не равно нулю.
Команды пересылки строк.
MOVS – пересылка строк. Формат команды: MOVS строка_приемник,строка_источник
Команда копирует байт, слово или двойное слово из сегмента данных в дополнительный сегмент.
Микропроцессор использует регистр индекса источника SI (ESI) для адресации в сегменте данных и регистр индекса приемника DI (EDI) для адресации в дополнительном сегменте. Можно заменить сегмент, соответствующий регистру SI (ESI), но не регистру DI (EDI). Можно добиться копирования строки из одной части дополнительного сегмента в другую. Сама команда MOVS пересылает только один элемент, но с помощью префикса REP можно этой командой переслать строку размером до 64 Кбайт данных (если размер адреса в сегменте 16 бит — use16) или до 4 Гбайт данных (если размер адреса в сегменте 32 бит - use32). Групповая пересылка с помощью команды МOVS осуществляется с помощью следующих пяти шагов:
1. Обнулить флаг направления DF или установить его в зависимости от того, будет ли пересылка осуществляться от младших адресов к старшим или наоборот.
2. Загрузить смещение адреса строки_источника в регистр SI (ESI) используя команду LEA.
LEA SI, строка_источник.
3. Загрузить смещение адреса стоки_приемника в регистр DI (EDI): LEA DI, ES:строка_приемник.
4. Загрузить счетчик элементов в регистр СХ: MOV CX,100.
5. Исполнить команду MOVS c префиксом REP: REP MOVS строка_приемник, строка_источник.
Программа должна включать дополнительный сегмент, вмещающий строку_приемник, и сегмент данных, вмещающий строку_источник. Обычно для строки_приемника память резервируется директивой вида:
строка_приемник DB 100 DUP.
Если строки приемника и источника определены с помощью директивы DB, то Ассемблер преобразует MOVS в команду MOVSB, если DW – MOVSW и если DD – MOVSD.
MOVSB - переслать строку байтов.
MOVSW - переслать строку слов.
MOVSD - переслать строку двойных слов.
В этих командах не требуются операнды.
Обычно регистр SI (ESI) адресуется к сегменту данных, но с помощью префикса замены сегмента в операнде_источнике можно использовать другой сегмент. Например:
LEA SI, ES: строка_источник ; копирует строку_источник в
LEA DI, ES: строка_приемник ;строку_приемник
Обе строки находятся в дополнительном сегменте. Если обе строки находятся в сегменте данных, то нужно использовать команды:
PUSH DS
POP ES
Команды сравнения строк
CMPS – сравнение строк. Формат команды: CMPS строка_приемник, строка_источник.
Сравнивает операнд-источник с операндом-приемником и возвращает результат через флаги. Команды не изменяют значение операндов. Строка_приемник - строка в сегменте данных, адресуемая регистром SI (ESI). Строка_источник - строка в дополнительном сегменте, адресуемая регистром DI (EDI).
Команда CMPS сравнивает операнды с помощью их вычитания. Она вычитает операнд-приемник из операнда-источника. Для сравнения нескольких элементов команду CMPS надо использовать с префиксом повторения REPE (REPZ) или REPNE (REPNZ). Флаг направления DF определяет обработку в порядке возрастания (DF равен нулю) или убывания (DF равен единице) адресов элементов, а регистры SI (ESI) и DI (EDI) соответствующим образом изменяются после каждой операции.
Проверка результатов сравнения осуществляется повторением операций. Повторение операций сравнения может завершиться в двух случаях: если значение регистра СХ стало равным нулю или флаг нуля ZF равен нулю (REPE) или единице (REPNE). Выяснить, что привело к прекращению сравнений, легче всего, указав после команды CMPS команду условной передачи управления, проверяющую значение флага ZF, а именно JE (JZ) или JNE (JNZ). Ассемблер преобразует команду CMPS либо в команду CMPSB (при сравнении байтов), в команду CMPSW (при сравнении строк), либо в команду CMPSD (при сравнении двойных строк).
Команды сканирования строк
Они позволяют осуществить поиск заданного значения в строке, находящейся в дополнительном сегменте. Смещение адреса первого элемента строки должно быть помещено в регистр DI (EDI). При сканировании строки байтов искомое значение должно находиться в регистре AL, слов - в регистре АХ, а двойных слов - в регистре EАХ.
SCAS - сканировать строку. Формат команды: SCAS строка_приемник
Для выполнения действий более чем над одним элементом надо воспользоваться префиксами повторения REPE (REPZ) или REPNE (REPNZ). Если искомый элемент строки обнаружен, то смещение адреса следующего за ним элемента возвращается в регистре DI (EDI), а флаг нуля ZF полагается равным 0. Ассемблер преобразует команду SCAS в команду SCASB (при поиске байта), либо в команду SCASW (при поиске слова), либо в команду SCASD (при поиске двойного слова).
Команды загрузки и сохранения строки
LODS – загрузка строки. Формат команды: LODS строка_источник
Команда LODS пересылает операнд-источник, адресованный регистром SI (ESI), из сегмента данных в регистр AL (при пересылке байта), в регистр АХ (при пересылке слов), или в регистр EАХ (при пересылке двойных слов), а затем изменяет регистр SI (ESI) так, чтобы он указал на следующиий элемент строки. Его значение увеличивается, если флаг направления DF равен нулю, и уменьшается, если флаг DF равен единице. Команда LODS имеет сокращенные формы LODSB (загрузить строку байтов), LODSW (загрузить строку слов) и LODSD (загрузить строку двойных слов).
STOS – сохранение строки. Формат команды: LODS строка_приемник
Команда STOS пересылает байт из регистра AL, слово из регистра АХ или двойное слово из регистра EАХ в элемент операнда строка_приемник, находящийся в дополнительном сегменте и адресуемый регистром DI (EDI), а затем изменяет значение регистра DI (EDI) так, чтобы оно указывало на следующий элемент строки. Это значение увеличивается, если флаг направления DF равен нулю, и уменьшается, если флаг DF равен единице. Будучи повторяемой, команда STOS удобна для заполнения строки заданным значением.
9.2 Команды прерывания
Подобно вызову процедуры прерывание заставляет микропроцессор сохранить в стеке информацию для последующего возврата, а затем исполнить программу обработки прерывания.
Прерывание всегда вызывает косвенный переход к своей прграмме обработки за счет получения ее адреса из 32-битового вектора прерывания. Сохраняя в стеке адрес прерывания, сохраняют еще и флаги. Прерывания могут быть инициированы внешним устройством системы или специальной командой прерывания из программы. Есть три различные команды прерывания - две команды вызова и одна команда возврата.
INT - Команда прерывания. Формат команды: INT тип_прерывания
Тип прерывания это номер, идентифицирующий один из 256 различных векторов, находящихся в памяти.
При исполнении команды INT микропроцессор производит следующие действия:
1. Помещает в стек значение регистра флагов.
2. Обнуляет флаг трассировки OF и флаг включения/выключения прерываний IF.
3. Помещает в стек значение регистра CS.
4. Вычисляет адрес вектора прерывания, умножая тип прерывания на 4.
5. Загружает второе слово вектора прерываний в регистр CS.
6. Помещает в стек значение регистра указателя команд IP.
7. Загружает в регистр указателя команд IP первое слово вектора прерывания.
После команды INT в стеке окажутся значения регистра флагов и регистров CS и IP. Флаги трассировки TF и прерывания IF будут равны нулю. Пара регистров CS и IP будет указывать на начальный адрес программы обработки прерывания. Затем микропроцессор начнет исполнять эту программу.
INTO - команда прерывания по переполнению. Она представляет собой команду условного прерывания. Команда инициирует прерывание лишь тогда, когда флаг переполнения OF равен единице.
IRET - команда возврата после прерывания. Действие команды то же, что и у команды RET для процедуры. Поэтому она исполняется последней при исполнении микропроцессором программы обработки прерывания. Команда IRET извлекает из стека три 16-битовых значения и загружает их в регистр указателя команд IP, регистр CS и регистр флагов.
9.3 Команды управления микропроцессором
Эти команды позволяют управлять работой микропроцессора из программы. Делятся на три группы.
Команды управления флагами
У микропроцессора есть семь команд, которые позволяют изменять флаг переноса CF, флаг направления DF и флаг прерывания IF.
STC - Команда установки флага переноса, т.е. флаг CF будет равен единице.
CLC - Команда обнуления флага переноса, т.е. флаг CF будет равен нулю.
Они полезны для установки нужного состояния флага CF перед исполнением команд циклического сдвига с флагом переноса RCL и RCR.
CMC - Команда инвертирования флага переноса. Переводит флаг CF в нуль, если он имел состояние единицы и наоборот.
STD - Команда установки флага направления, т.е. флаг DF будет равен единице.
CLD – Команда обнуления флага направления, т.е. флаг DF будет равен нулю.
Эти команды используются для указания направления обработки строк. Если флаг направления DF равен нулю, то после каждой операции над строкой значения индексных регистров SI и DI увеличиваются, если флаг DF равен единице, то они уменьшаются.
CLI - Команда обнуления флага прерывания. Обнуляет флаг прерывания IF, что заставляет микропроцессор игнорировать маскируемые прерывания, инициируемые внешними устройствами системы. Однако немаскируемые прерывания обрабатываются. Это прерывание для выдачи сообщений об ошибке в ячейке памяти.
STI - Команда установки флага прерываний. Переводит флаг прерывания IF в состояние единица, что разрешает микропроцессору реагировать на прерывания, инициируемые внешними устройствами.
Команды внешней синхронизации
Эти команды используются в основном для синхронизации действий микропроцессора с внешними событиями.
HLT - Команда останова. Переводит микропроцессор в состояние останова.
WAIT - Команда ожидания. Переводит микропроцессор на холостой ход.
ESC - Команда "убежать". Заставляет микропроцессор извлечь содержимое указанного в ней операнда и передать его на шину данных, тем самым она обеспечивает другим микропроцессорам системы возможность получения своих команд из потока команд микропроцессора.
Формат команды: ESC внешний_код,источник
Внешний_код это 6-битовый непосредственный операнд, а источник - регистр или переменная.
Команда холостого хода
NOP - нет операции. Она не действует ни на флаг, ни на регистры, ни на ячейки памяти, а только увеличивает значение указателя команд IP.
Команда NOP удобна при тестировании последовательности команд. Ее можно сделать последней в тестируемой программе и тем самым получить удобное место для остановки трассировки.
Основная литература - 1[229-249], 2[54-60]
Контрольные вопросы
1. Максимальный размер строки, который может обработать цепочечная команда.
2. Виды и назначение префиксов повторения.
3. Примитивы цепочечных команд. Форматы цепочечных команд.
4. Действия микропроцессора при исполнении команды INT.
5. Команда, изменяющая только значение указателя команд.
10 Лекция 10. Директивы ассемблера
Программа на языке ассемблер состоит из операторов. В качестве операторов могут использоваться команды, макрокоманды и директивы.
Директивы управляют процессом ассемблирования, и не генерируют машинных кодов.
Директива определения сегмента.
Программа оформляется в виде отдельных сегментов и может включать сегменты данных, стека, кода и дополнительный. При описании сегмента начало задается директивой SEGNENT, а конец - директивой ENDS. Сегмент описывается по следующему формату:
Имя_сегмента SEGMENT [тип_выравнивания] [тип_объединения] [класс] [тип_размера_сегмента]
...
Имя_сегмента ENDS
Тип_выравнивания сегментов определяет границу начала сегмента и может принимать следующие значения:
- BYTE - сегмент начинается с любого адреса;
- WORD - сегмент начинается c адреса, кратного двум ( ххх0b);
- DWORD сегмент начинается c адреса, кратного четырем ( xx00b);
- PAPA - сегмент начинается на границе параграфа c адреса, кратного 16 ( xxx0h) - используется по умолчанию;
- PAGE - сегмент начинается на границе 256-байтовой страницы с адреса, кратного 256 (xx00h);
- MEMPAGE — сегмент начинается по адресу, кратному 4 Кбайт (x000h).
Тип_объединения сегментов сообщает компоновщику, как нужно комбинировать сегменты различных модулей, имеющие одно и то же имя.
Используются следующие типы объединения:
- PRIVATE — сегмент не будет объединяться с другими сегментами с тем же именем вне данного модуля – используется по умолчанию;
- PUBLIC – соединяет все сегменты с одинаковыми именами, длина объединенного сегмента равна сумме длин объединяемых сегментов;
- COMMON - располагает все сегменты с одним и тем же именем по одному адресу. Все сегменты с данным именем будут перекрываться и совместно использовать память. Длина объединенного сегмента равна наибольшей из длин объединяемых сегментов;
- STACK - определение сегмента стека. Заставляет компоновщик соединить все одноименные сегменты и вычислять адреса в этих сегментах относительно регистра SS. Длина сегмента равна сумме объединяемых сегментов. Если сегмент стека создан, а комбинированный тип STACK не используется, программист должен явно загрузить в регистр ss адрес сегмента (подобно тому, как это делается для регистра DS);
- MEMORY - вызывает размещение сегмента данных после сегмента кода. Размер сегмента определяется аналогично объединению COMMON;
- AT-ПАРАГРАФ. Данный операнд обеспечивает определение меток и переменных по фиксированным адресам.
Hапример, для определения адреса дисплейного видеобуфера используется
- VIDEO-RAM SEGMENT AT 0B800H.
Класс. Данный операнд заключенный в апострофы, используется для группирования сегментов при компоновке. В качестве операнда "класс" можно использовать имена 'STACK', 'CODE', 'DATA'.
Тип размера сегмента. Для процессоров i80386 и выше сегменты могут быть 16 или 32-разрядными. Это влияет, прежде всего, на размер сегмента и порядок формирования физического адреса внутри него. Используются следующие типы размеров сегмента:
USE16 — это означает, что сегмент допускает 16-разрядную адресацию. При формировании физического адреса может использоваться только 16-разрядное смещение. Соответственно, такой сегмент может содержать до 64 Кбайт кода или данных;
USE32 — сегмент будет 32-разрядным. При формирования физического адреса может использоваться 32-разрядное смещение. Поэтому такой сегмент может содержать до 4 Гбайт кода или данных.
Упрощенные директивы определения сегмента
.CODE [имя] Начало или продолжение сегмента кода
.DATA Начало или продолжение сегмента инициализированных данных. Также используется для определения данных типа near
.CONST Начало или продолжение сегмента постоянных данных (констант) модуля
.DATA? Начало или продолжение сегмента неинициализированных данных. Также используеться для определения данных типа near
.STACK[размер] Начало или продолжение сегмента стека модуля. Параметр [размер] задает размер стека
.FARDATA[имя] Начало или продолжение сегмента инициализированных данных типа far
.FARDATA[имя] Начало или продолжение сегмента неинициализированных данных типа far
Директива определения процедуры
Программа может включать в себя одну или несколько процедур. При описании процедуры начало задается директивой PROC, а конец - директивой ENDP. Процедура описывается по следующему формату:
Имя_процедуры PROC [атрибут_дистанции]
. . .
RET
Имя_процедуры ENDP.
В качестве атрибута дистанции используются операнды FAR (дальний) и NEAR (близкий).
При использовании атрибута дистанции FAR обращение к процедуре можно осуществлять из другого программного сегмента, а при использовании NEAR - только из сегмента, где оно описывается.
Команда RET выполняет возврат из процедуры. Процедуры могут быть вложенными. Степень вложенности ограничивается только размером сегмента стека.
Директива ASSUME
Директива ASSUME сообщает Ассемблеру, какие программные сегменты относятся к программе, и загружает адреса для сегментов кода и стека. Загрузку сегментных адресов для дополнительного сегмента и сегмента данных обеспечивает программист.
Директива ASSUME описывается в сегменте кода следующим образом:
ASSUME SS:имя_стек, DS:имя_дан, CS:имя_код, ES:имя_доп.дан
Если программа не использует какой-либо сегмент, то его можно опустить или указать NOTHING.
Hапример:
ASSUME ss:sseg,ds:dseg,cs:cseg или
ASSUME ss:sseg,ds:dseg,cs:cseg,es:nothing.
Кроме того с помощью NOTHING можно отменить предыдущее назначение сегментного регистра.
Директива завершения программы END
Директива END сообщает Ассемблеру, где завершить трансляцию и описывается следующим образом:
END [метка_входа].
Метка_входа должна присутствовать только в главном программном модуле, в остальных не обязательна. В качестве метки_входа может использоваться имя основной процедуры, либо метка начала программы.
Директивы определения данных
Для определения данных используются следующие директивы:
- DB - определить байт;
- DW - определить слово;
- DD - определить двойное слово;
- DQ - определить восемь байт или четыре слова;
- DT - определить десять байт.
Формат директивы определения данных имеет вид:
[имя] Dn выражение
В качестве выражения могут использоваться:
- константа;
- таблица, массив или строка;
- символьная строка.
Константа
С помощью директив определения данных можно:
- задать переменную в виде константы: A DB 10;
- занять место в памяти, не указывая начального значения: A DB ?
Если переменная, описанная с помощью директивы DD
A DD 10203040H ,
а нам нужен определенный байт, то к нему можно обратиться следующим образом:
mov AL, byte ptr A ; AL=40h
mov AL, byte prt A+2 ; AL=20h
для обращения к определенному слову:
mov AX ,word prt A ; AX=3040h
mov AX, word prt A+2 ; AX=1020h
C помощью директивы DW в памяти можно сохранить адрес смещения (указатель) какой-либо метки или процедуры:
adr_near DW main
Полный адрес метки или процедуры (вектор) можно записать в память с помощью директивы DD:
adr_ far DD main
Таблица
При описании таблицы элементы таблицы записываются через запятую:
tab DB 10, 20, 30, 40, 50
Можно просто занять место в памяти для таблицы:
tab DB 5 dup (?)
Здесь каждый элемент таблицы имеет длину 1 байт.
tab DW 5 dup (?)
В этом случае для таблицы резервируется 10 байт, для каждого элемента 2 байта или слово. Оператор DUP обозначает дублировать. Следует помнить, что независимо от размера элемента обращение к элементам таблицы идет по младшему байту элемента.
Например:
mas DB 1122h, 3344h, 5566h, 7788h ;
здесь адрес нулевого слова (счет начинается с нуля) определяется по адресу байта со значением 22h
mas - адрес байта со значением 22h
mas+1 - адрес байта со значением 11h
mas+2 - адрес первого слова массива
mas+4 - адрес второго слова массива
Символьная строка
С помощью директивы DB в памяти можно хранить любой текст. Любые символы, заключенные в апострофы, являются символьной cтрокой. В память каждый символ будет записан в ASCII-коде.
Hапример: STR DB 'символьная строка'.
Директивы определения идентификаторов.
К директивам определения идентификаторов относятся директивы EQU и =.
Эти директивы присваивают имена данным и в памяти места не занимают. Используется следующий формат:
ИМЯ EQU выражение
ИМЯ = числовое_выражение.
Отличие директивы EQU от = в том, что с помощью директивы = можно поменять числовое_выражение.
C помощью директивы EQU можно присвоить имя константе, регистру, комбинации адресов, определить синоним.
Директива внешних ссылок
К директивам внешних ссылок относятся директивы PUBLIC, EXTRN и INCLUDE. Директива PUBLIC указывает, что заданный идентификатор доступен из других программных модулей. В качестве идентификатора может использоватся переменная, метка, константа. Директива имеет формат: PUBLIC идентификатор [,..]
Hапример
public A
dseg segment
A DW 1020h
dseg ends.
Директива EXTRN обьявляет, что в данном программном модуле используются имена, описанные в других программных модулях. Формат директивы: EXTRN имя : тип [,..].
В качестве имени используются переменные, метки, константы. Тип элемента зависит от того как определяется имя.
Если имя является переменной и описывается в сегменте данных, то тип принимает значение WORD, DWORD, BYTE.
Если имя является меткой, то тип принимает значение FAR или NEAR.
Если имя является константой и описывается с помощью директив EQU или = ,то тип принимает значение ABS.
Директива INCLUDE вставляет во время трансляции в программу текст файла, указанного в директиве. Формат директивы: INCLUDE имя_файла.
Директивы управления листингом
К ним относятся директивы PAGE, TITLE и SUBTTL. Директива PAGE задает размер страницы листинга. Формат директивы PAGE имеет вид:
PAGE [число_строк] [,число_столбцов].
Количество строк может изменяться в пределах от 10 до 255.
Столбец указывает количество символов в строке и изменяется в пределах от 59 до 255. По умолчанию устанавливаются размеры страницы 66 строк по 80 символов в строке.
Директива PAGE без операндов делает прогон листа.
Директива TITLE вверху на каждой странице печатает заголовок программы. Формат директивы: TITLE текст.
Максимальная длина текста - 60 символов.
Директива SUBTTL печатает подзаголовок на следующей строке после заголовка, имеет формат:
SUBTTL текст.
Основная литература - 2[108-109]
Контрольные вопросы:
1. Как размещаются данные в памяти, определенные с помощью директив DW, DD?
2. Аргументы директивы SEGMENT.
3. Для чего используются директивы внешних ссылок.
4. директива подключения файла.
11 Лекция 11. Организация программ. Макроопределения
11.1 Организация многомодульных программ
При разработке сложных программных комплексов бывает удобно часть процедуры выделить в отдельный исходный модуль, транслируемый самостоятельно.
После трансляции объектные модули этих процедур могут войти в состав объектной библиотеки, подсоединяемой к основной программе на этапе компоновки. Структура такого программного комплекса может выглядеть следующим образом:
; MAIN.ASM -файл с главной процедурой
text segment public ‘code’`
extrn subpr: proc ; subpr - внешняя ссылка
mymain proc
…
call subpr ; Прямой ближний вызов
…
mymain endp
text ends
end mymain ; mymain - точка входа в главную
; процедуру
;MYSUB.ASM - файл с подпрограммой
text segment public ` code `
public subpr ; subproc - процедура " общего пользования"
subpr proc near ; Ближняя процедура
…
ret
subpr endp
text ends
end ;без точки входа
Программные сегменты обоих исходных модулей имеют одно имя text, что обеспечивает их слияние компоновщиком в единый сегмент. Тип объединения PUBLIC определяет способ слияния - конкатенацию, т.е. подсоединение второго модуля к концу первого (так же действует описатель STACK, используемый в сегментах стеков, в то время как тип объединения COMMON требует от компоновщика наложения одноименных сегментов друг на друга).
Директива EXTERN в главном модуле определяет, что символьное обозначение subpr является внешней ссылкой и представляет собой имя процедуры. Внешняя ссылка будет разрешена на этапе компоновки.
Процедуры, вызываемые из других программных модулей, должны быть определены как процедуры "общего пользования" с помощью директивы PUBLIC. В этом случае их имена записываются транслятором в объектный модуль, что позволяет компоновщику разрешить ссылки на них.
В приведенном примере предполагается, что программные модули после слияния образуют один сегмент команд, т.е. что их суммарный размер (в машинных кодах) не превышает 64 кбайт. Поэтому процедура-подпрограмма объявлена ближней (near), а в главной процедуре использована команда прямого ближнего вызова.
Модуль с подпрограммой заканчивается директивой завершения трансляции END без параметра - в многомодульных программных комплексах только тот модуль, который содержит главную процедуру, оканчивается директивой END с указанием входной точки этой процедуры.
Файлы MAIN.ASM и MYSUB.ASM с исходными текстами компонентов комплекса следует порознь оттранслировать, а затем скомпоновать в единый загрузочный модуль:
MASM MAIN, MAIN, MAIN;
MASM MYSUB, MYSUB, MYSUB;
LINK MAIN + MYSUB, PROG.
В результате трансляции будут получены файлы MAIN.OBJ, MAIN.LST, MYSUB.OBJ и MYSUB.LST; компоновщик объединит модули MAIN.OBJ и MYSUB.OBJ и образует загрузочный (выполнимый модуль) PROG. EXE.
Другой вариант процедуры разработки многомодульного программного комплекса - помещение объектного модуля MYSUB. OBJ в библиотеку объектных модулей с последующим извлечением его оттуда компоновщиком. Библиотекой целесообразно пользоваться при наличии большого числа объектных модулей, используемых в различных программных комплексах. В этом случае после трансляции файла MYSUB.ASM объектный файл MYSUB.OBJ записывается в создаваемую пользователем библиотеку объектных файлов. Включение объектных файлов с подпрограммами во вновь создаваемую объектную библиотеку выполняется следующим образом:
LIB MYOBJ.LIB + MYSUB.OBJ, MYOBJ.LST.
В этой команде LIB - имя программы библиотекаря, MYSUB.OBJ - имя помещаемого в библиотеку объектного файла, а MYOBJ.LST - имя создаваемого файла с каталогом библиотеки. Знак ‘+’ перед именем модуля обозначает, что этот модуль надо добавить в библиотеку (знак ‘–‘ удаляет данный модуль). В файл MYOBJ.LST будет помещено оглавление библиотеки.
Все расширения, кроме расширения файла с каталогом, можно опустить, так как по умолчанию предполагаются именно указанные в примере расширения.
Если объектная библиотека уже имеется, и мы хотим добавить в нее вновь созданные объектные модули, в строке вызова библиотекаря надо в качестве последнего параметра еще раз указать имя библиотеки:
LIB MYOBJ + NEW1 + NEW2, MYOBJ.LST, MYOBJ.
Здесь первый параметр определяет имя исходной библиотеки, а последний - имя создаваемой библиотеки, расширенной за счет добавления новых модулей. Это имя может совпадать с именем старой библиотеки, но может и отличатся от него.
При наличии объектной библиотеки в строке вызова компоновщика в качестве четвертого параметра команды следует указать имя библиотеки:
LINK/ CO MAIN.OBJ, PROG.EXE, PROG.MAP, MYOBJ.LIB.
В приведенном примере MAIN.OBJ - объектный файл с основной программой, PROG.EXE - результирующий выполняемый модуль, PROG.MAP - карта выполнимого модуля, а MYOBJ.LIB - объектная библиотека со требуемыми подпрограммами. Как и в предыдущих примерах, все расширения можно опустить, так они предполагаются или назначаются по умолчанию. Карта выполнимого модуля обычно не нужна (в ней мало полезной информации), а имя загрузочного модуля по умолчанию совпадает с именем объектного (при разных расширениях). Поэтому приведенную команду можно упростить:
LINK MAIN, PROG , , MYOBJ.LIB.
В результате выполнения этой команды компоновщик создаст выполнимый модуль PROG.EXE.
Если суммарный размер главной программы и подпрограмм (в машинных кодах) превышает 64кбайт, загрузочный модуль может быть многосегментным. Структура такого программного комплекса может выглядеть следующим образом:
; MAIN. ASM - файл с главной процедурой
text1 segment ‘code’
extern subpr:proc
text1 ends
text segment ‘code’
mymain proc
…
call far ptr subpr
…
mymain ends
text ends
end mymain
;MYSUB.ASM - файл с подпрограммой
text1 segment ‘code’
public subpr
subpr proc far
…
subpr endp
text1 ends
end
Поскольку сегменты text (с главной программой) и text1 (с подпрограммой) имеют разные имена, они не будут объеденены компоновщиком в один сегмент. В исходном модуле, содержащем вызов подпрограммы, она должна быть описана директивой EXTRN. Однако это описание должно находится в сегменте, одноименным с сегментом подпрограммы. Поэтому в модуль MAIN.ASM включен пустой пока что сегмент text1, содержащий лишь одну строку - объявление вызываемой процедуры EXTRN SUBPR: PROC. Далее следует основной сегмент команды text с главной программой. В ней использован прямой дальний вызов; процедура-подпрограмма, в свою очередь, атрибутом FAR объявлена дальней. Трансляция и компоновка выполняется так же, как и в случае многомодульной односегментной программы.
11.2 Макрокоманды
Программы, написанные на языке ассемблера часто содержат повторяющиеся участки текста с одинаковой структурой. Такой участок текста можно оформить в виде макроопределения и списка фактических аргументов, что приводит к генерации всего требуемого текста, называемого макрорасширением. Варьируя фактические аргументы, можно сохраняя неизменной структуру макрорасширения, изменить отдельные его элементы.
Макроопределение должно начинаться строкой с именем макроопределения и директивой MACRO, в поле аргументов которого указывается список формальных аргументов. Заканчивается макроопределение директивой ENDM.
Пусть в программе требуется неоднократно сохранять в стеке содержимое трех регистров, но в каждом конкретном случае номера регистров и их порядок отличаются в виде макроопределения:
psh macro a, b, c
push a
push b
push c
endm
Появление в исходном тексте программы строки
psh AX, BX, CX
приведет к генерации следующего фрагмента текста
push AX
push BX
push CX
Если же в исходном тексте имеется строка
psh DX, ES, BP
то соответствующее макрорасширение будет иметь вид:
push DX
push ES
push BP
В качестве фактических аргументов могут выступать любые обозначения ассемблера, допустимые для данной команды. В частности, макровызов
psh mem, [BX], ES:[17]h
приведет к следующему макрорасширению:
push mem
push [BX]
push ES:[17]
Если какие-то строки макроопределения должны быть помещены (например, с целью организации циклов), то обозначения меток должны быть объявлены локальными с помощью оператора LOCAL. В этом случае ассемблер, генерируя макрорасширения, будет создавать собственные расширения меток, не повторяющиеся при повторных вызовах одной и той же макрокоманды:
delay macro
local point
mov CX, 20000
point: loop point
endm
Текст макроопределения можно включить непосредственно в текст программы, однако в тех случаях, когда макрокоманды описывают некоторые стандартные процедуры широкого назначения, например программную задержку или вывод на экран строки текста, целесообразно тексты макроопределений поместить в макробиблиотеку.
Макробиблиотека представляет собой файл с текстами макроопределений. Макроопределения записываются в этот файл точно в таком же виде, как и в текст программы. Ниже приведен текст файла макробиблиотеки с произвольным именем MYMACRO.MAC, содержащей две макрокоманды.
; Макрокоманда outprog завершения программы
outprog macro
mov AX, 4C00h
int 21h
endm
; Макрокоманда delay небольшой программной задержки
delay macro
local point
mov CX, 20000
point: loop point
endm
Функционально макроопределения похожи на процедуры. И те, и другие достаточно один раз где-то описать, а затем вызывать их специальным образом. На этом их сходство заканчивается, и начинаются различия, которые в зависимости от целевой установки можно рассматривать и как достоинства и как недостатки:
- в отличие от процедуры, текст которой неизменен, макроопределение в процессе макрогенерации может меняться в соответствии с набором фактических параметров. При этом коррекции могут подвергаться как операнды команд, так и сами команды. Процедуры в этом отношении объекты менее гибки;
- при каждом вызове макрокоманды ее текст в виде макрорасширения вставляется в программу. При вызове процедуры микропроцессор осуществляет передачу управления на начало процедуры, находящейся в некоторой области памяти в одном экземпляре. Код в этом случае получается более компактным, хотя быстродействие несколько снижается за счет необходимости осуществления переходов.
Макродирективы
С помощью макросредств ассемблера можно не только частично изменять входящие в макроопределение строки, но и модифицировать сам набор этих строк и даже порядок их следования. Сделать это можно с помощью набора макродиректив (далее — просто директив). Их можно разделить на две группы:
-директивы повторения WHILE, REPT, IRP и IRPC. Директивы этой группы предназначены для создания макросов, содержащих несколько идущих подряд одинаковых последовательностей строк. При этом возможна частичная модификация этих строк;
- директивы управления процессом генерации макрорасширения EXITM и GOTO. Они предназначены для управления процессом формирования макрорасширения из набора строк соответствующего макроопределения. С помощью этих директив можно как исключать отдельные строки из макрорасширения, так и вовсе прекращать процесс генерации. Директивы EXITM и GOTO обычно используются вместе с условными директивами компиляции, поэтому они будут рассмотрены вместе с ними.
Директивы WHILE и REPT
Директивы WHILE и REPT применяют для повторения определенное количество раз некоторой последовательности строк. Эти директивы имеют следующий синтаксис:
WHILE константное_выражение
последовательность_строк
ENDM
REPT константное_выражение
последовательность строк
ENDM
Следующие две директивы, IRP и IRPC, делают этот процесс более гибким, позволяя модифицировать на каждой итерации некоторые элементы в последовательность_строк.
Директива IRP
Директива IRP имеет следующий синтаксис:
IRP формальный_аргумент,<строка_символов_1,...,строка_символов_N>
последовательность_строк
ENDM
Действие данной директивы заключается в том, что она повторяет последовательность_строк N раз, то есть столько раз, сколько строк_символов заключено в угловые скобки во втором операнде директивы IRP. Повторение последовательности_строк сопровождается заменой в ней формального_аргумента строкой символов из второго операнда. Так, при первой генерации последовательности_строк формальный_аргумент в них заменяется на строка_символов_1. Если есть строка_символов_2, то это приводит к генерации второй копии последовательности_строк, в которой формальный_аргумент заменяется на строка_символов_2. Эти действия продолжаются до строка_символов_N включительно.
К примеру, рассмотрим результат определения в программе следующей конструкции:
irp ini,<1,2,3,4,5>
db ini
endm.
Макрогенератором будет сгенерировано следующее макрорасширение:
db 1
db 2
db 3
db 4
db 5
Директива IRPC
Директива IRPC имеет следующий синтаксис:
IRPC формальный_аргумент,строка_символов
последовательность строк
ENDM.
Действие данной директивы подобно IRP, но отличается тем, что она на каждой очередной итерации заменяет формальный_аргумент очередным символом из строка_символов. Понятно, что количество повторений последовательность_строк будет определяться количеством символов в строка_символов. К примеру:
irpc rg,
push rg&x
endm
В процессе макрогенерации эта директива развернется в следующую последовательность строк:
push ax
push bx
push cx
push dx
Директивы условной компиляции
Директива EXITM не имеет операндов, и ее действие заключается в том, что она немедленно прекращает процесс генерации макрорасширения, начиная с того места, где она встретилась в макроопределении.
Директива GOTO имя_метки переводит процесс генерации макроопределения в другое место, прекращая тем самым последовательное разворачивание строк макроопределения. Метка.
Директивы компиляции по условию
Данные директивы предназначены для организации выборочной трансляции фрагментов программного кода. Такая выборочная компиляция означает, что в макрорасширение включаются не все строки макроопределения, а только те, которые удовлетворяют определенным условиям. То, какие конкретно условия должны быть проверены, определяется типом условной директивы.
Всего имеется 10 типов условных директив компиляции:
- директивы IF и IFE — условная трансляция по результату вычисления логического выражения;
- директивы IFDEF и IFNDEF — условная трансляция по факту определения символического имени;
- директивы IFB и IFNB — условная трансляция по факту определения фактического аргумента при вызове макрокоманды;
- директивы IFIDN, IFIDNI, IFDIF и IFDIFI — условная трансляция по результату сравнения строк символов.
Условные директивы компиляции имеют общий синтаксис и применяются в составе следующей синтаксической конструкции:
IFxxx логическое_выражение_или_аргументы
фрагмент_программы_1
ELSE
фрагмент_программы_2
ENDIF
Основная литература – 1[280-309], 2[108-126].
Контрольные вопросы
1. Как помещается объектный модуль в библиотеку объектных модулей?
2. Назначение макрокоманд.
3. Как используются макродирективы повторения?
4. Перечислите макродирективы условной компиляции.
12 Лекция 12. Основы программирования для MS DOS
12.1 Обращение к системным средствам из прикладной программы
Обращение к функциям DOS и BIOS осуществляется с помощью программных прерываний (команда INT).
Система прерываний машин типа IBM PC в принципе не отличается от любой другой системы векторизованных прерываний. Самое начало оперативной памяти от адреса 0000h до03FFh отводится под векторы прерываний - четырехбайтовые области, в которых хранятся адреса программ обработки прерываний (ПОП). В два старшие байта каждого вектора записывается сегментный адрес ПОП, в два младшие - относительный адрес точки входа в ПОП в сегменте. Векторы, как и соответствующие им прерывания, имеют номера, называемые типами, причем вектор с номером 0 (вектор типа 0) располагается начиная с адреса 0, вектор типа 1 - с адреса 4, вектор типа 2 с адреса 8 и т.д. Вектор с номером N занимает, таким образом, байты памяти от N*4 до N*4+3. Всего в выделенные под векторы области памяти помещается 256 векторов.
Обращение из прикладной программы к системным функциям осуществляется единообразно. В регистр AH засылается номер функции (не путать с типом прерывания!), в другие регистры - исходные данные, необходимые для выполнения конкретной системной программы. После этого выполняется команда INT с числовым аргументом, указывающим тип (номер) прерывания, например, INT 21h.
Большинство функций DOS и многие функции BIOS возвращают в флаге переноса CF код завершения. Если функция выполнилась успешно, CF=0, в случае любой ошибки CF=1. В последнем случае в одном из регистров (чаще всего в АХ) возвращается еще и код ошибки. Таким образом, типичная процедура обращения к системным средствам выглядит следующим образом:
mov AH,func ; func - номер функции
; Заполнение тех или иных регистров (AL, BX, ES, BP и др.)
; параметрами, необходимыми для выполнения данной функции
…
int 21h ;Переход в MS-DOS
jc error ; Строка выполняется сразу
; после возврата из DOS
; Продолжение программы
…
error cmp AX,1 ;Анализ кода завершения
je err1
cmp AX2
je err2
…
Аналогично вызываются и функции BIOS.
12.2. Системные средства ввода данных с клавиатуры
Операционная система предоставляет несколько способов ввода данных с клавиатуры:
- обращение клавиатуре, как к файлу, с помощью прерывания DOS INT 21h c функцией 3Fh;
- использование группы функции DOS INT 21h из диапазона 1…Ch, обеспечивающих посимвольный ввод с клавиатуры в разных режимах;
- посимвольный ввод путем обращения в обход DOS непосредственно к драйверу BIOS с помощью прерывания INT 16h.
Ввод с клавиатуры средствами файловой системы (INT 21h функция 3Fh) осуществляется точно так же, как и чтение из файла. Обычно используется предопределенный дескриптор 0, закрепленный за стандартным устройством ввода (по умолчанию за клавиатурой). Число вводимых символов указывается в регистре СХ, однако ввод завершается лишь после того, как нажата клавиша <Enter>, независимо от того сколько фактически введено символов. Поэтому при вводе строк с клавиатуры нет необходимости заранее задавать их длину, достаточно загрузить в регистр СХ максимальную длину строки, например 80 байт. В любом случае в регистре АХ возвращается число реально введенных байтов, при этом учитывается так же и два байта (0Аh и 0Dh), поступающие во входной буфер при нажатии клавиши <Enter>.
Второй способ получения данных с клавиатуры в программу, с помощью функции DOS из диапазона 1…Ch обеспечивает более разнообразные возможности. Для ввода с клавиатуры можно использовать 7 функций прерывания INT 21h:
01h – вывод символа с эхом;
06h – прямой ввод – вывод через консоль;
07h – ввод символа без эха и без отработки Ctrl/C;
08h –ввод символа без эха и с отработкой Ctrl/C;
0Аh – буферизированный ввод строки с эхом;
0Bh - проверка состояния стандартного устройства;
0Ch – сброс входного буфера и ввод.
Функции 01h, 06h, 07h и 08h при каждом вызове вводят в программу один символ из кольцевого буфера ввода; при необходимости ввести группу символов (строку) функции следует использовать в цикле. Различаются эти функции наличием или отсутствием эха, а так же реакцией на ввод с клавиатуры сочетания < Ctrl> /C. Функции 01h и 0Аh отображают вводимые символы на экране (эхо); функции 07h и 08h этого не делают, что дает возможность вводить данные тайком от окружающих ( например, пароль или ключ). Второе важное различие описываемых функций касается их реакции на ввод сочетания < Ctrl> /C. При выполнении функции 01h и 08h DOS проверяет каждый введенный символ и, обнаружив во входном потоке код < Ctrl> /C (03 h), аварийно завершает программу. Функции же 06h и 07h пропускают код < Ctrl> /C в программу, не инициируя по нему никаких специальных действий. Такой метод ввода используется прикладными программами, если перед завершением в них должны быть выполнены определенные программные действия ( сброс буферов на диск, модификация файлов и проч.). Аварийное завершение такой программы средствами DOS по коду < Ctrl> /C могло бы привести к нарушению ее работоспособности.
Функция 0Аh передает в буфер пользователя строку, введенную с клавиатуры; строка должна заканчиваться нажатием клавиши <Enter>. Длина строки может достигать 254 символов. Вводимые символы отображаются на экране; при вводе < Ctrl> /C происходит аварийное завершение программы.
Функция 0Bh позволяет проверить наличие в кольцевом буфере ввода ожидаемых символов. При обнаружении символов программа должна извлечь их из буфера одной из функции ввода; если символов нет, программа может продолжить выполнение.
Функция 0Bh чувствительна к < Ctrl> /C. Функция 0Ch служит для организации ввода с предварительной очисткой кольцевого буфера.
Все функции, кроме 0Ch, вводят в программу наиболее старый из скопившихся в кольцевом буфере ввода символов. Функция 0Ch сначала очищает кольцевой буфер и лишь, затем ожидает ввода символа с клавиатуры. В результате коды всех ранее нажатых (по предположению – случайно) клавиш теряются. При этом режим ввода (с эхом или без него и т. д.) определяется тем, какая именно функция ввода (01h, 07h, 08h или 0Аh) реализуется “ внутри “ функции 0Ch.
Функции 01h, 07h, 08h и 0Аh являются синхронными, т.е при отсутствии символа в кольцевом буфере ждут его ввода. Функция 06h позволяет определить состояние кольцевого буфера и при наличии в нем кода извлечь этот код и обработать его, а при отсутствии - продолжить выполнение программы.
Функции 01h, 06h, 07h и 08h позволяют вводить в программу расширенные коды ASC II. Для этого обнаружив, что введенный код ASC II равен нулю, следует выполнить функцию повторно. Это дает возможность управления прикладными программами с помощью функциональных клавиш, а так же сочетаний <Alt>/ цифра, <Alt>/ буква и др.
3.Работа с клавиатурой на уровне BIOS (INT 16h) позволяет считывать двухбайтовые коды, поступающие в кольцевой буфер ввода (код ASC II + скен-код) и анализировать слово флагов клавиатуры (нажатие клавиш <Shift>, <Caps Lock> и др.).
Для ввода используются следующие функции прерывания INT 16h:
00h – чтение двухбайтового кода из входного буфера;
01h – чтение состояния клавиатуры и двухбайтового кода без извлечения его из буфера;
02h – чтение флагов клавиатуры.
Функция 00h позволяет в одном действии получить полный двухбайтовый код нажатой клавиши или комбинации клавиш, из которого в частности, можно извлечь скен-код (некоторые программы идентифицируют нажатые клавиши не по кодам ASCII, а по их скан-кодам), а также получить значащую часть расширенного кода ASCII (при нажатии например функциональных клавиш). Функция 00h является синхронной: при выполнении программа останавливается в ожидании нажатия клавиши.
Функция 01h относится к числу асинхронных: определив состояние клавиатуры (точнее буфера ввода), она возвращает управление программе. Состояние буфера возвращается в флаге ZF: если в буфере имеются ожидающие ввода в программу символы ZF=0, если же буфер пуст, ZF=1. При наличии в буфере кода символа его можно проанализировать, так как он возвращается функцией в регистре AX (AH=скен-код, AL=код ASCII). Необходимо однако иметь в виду, что функция 01h, копируя двухбайтовый код в регистр АХ, не очищает при этом кольцевой буфер. Забрать символ с очисткой буфера можно затем функцией 00h.
Функция 02h – чтение флагов клавиатуры – передает в программу содержимое слова флагов (ячейка 417h). Она может использоваться программами, работающими на уровне скен-кодов, для определения состояния клавиш <Shift>, <Caps Lock> и др.
Основная литература – 2[140-150], 3[85-102].
Контрольные вопросы
1. Функции DOS для ввода с клавиатуры.
2. Функции BIOS для ввода с клавиатуры.
3. Какие функции используются для ввода с клавиатуры без отображения на экране?
13 Лекция 13. Работа с файлами
Операции с файлами предполагают использование дескрипторов (файловых индексов, файловых описателей).
Процедура обращения к файлу в общем случае распадается на следующие операции:
- создание файла с заданным именем в указанном каталоге или открытие файла, если он был создан ранее;
- запись в файл или чтение из файла всего содержимого либо любой его части;
- закрытие файла.
Обращение к открытому файлу (запись чтение изменение характеристик файла и т.д.) осуществляется по присвоенному ему дескриптору; неоткрытый файл дескриптора не имеет и система работать с ним не может. Наконец при закрытии файла освобождается выделенный ему блок описания файла вместе с дескриптором.
Файловые функции DOS чтение и записи через дескрипторы характерны тем, что их можно использовать и для ввода и вывода через стандартные устройства компьютера. При этом для работы со стандартными устройствами DOS предоставляет пять предопределенных дескрипторов:
0 - стандартный ввод (CON);
1 - стандартный вывод (CON);
2 - стандартная ошибка (CON);
3 - стандартный вспомогательный порт ( AUX);
4 - стандартный принтер (PRN).
Для облегчения ориентации в многочисленных функциях DOS, осуществляющих операции над файлами, каталогами и дисками, их удобно разбить на смысловые группы.
1. Создание, открытие и закрытие файла:
3Ch - создать файл;
5Ah - создать временный файл;
5Bh - создать новый файл;
3Dh - открыть файл;
3Eh - закрыть файл;
68h - сбросить файл на диск;
41h - удалить файл;
2. Запись и чтение данных:
42h - установить указатель;
3Fh - читать из файла или устройства;
40h - записать в файл или устройство.
3. Изменение характеристик файла:
43h - получить или установить атрибуты файла;
56h - переименовать файл;
57h - получить или установить дату и время создания файла.
4. Поиск файла:
1Ah - установить адрес области передачи данных (DTA);
2Fh - получить адрес области передачи данных (DTA);
4Eh - найти первый файл;
4Fh - найти следующий файл.
5. Операции над каталогами:
39h - создать каталог;
3Ah - удалить каталог;
3Bh - сменить текущий каталог;
47h - получить текущий каталог;
6. Операции над дисками:
19h - получить текущий диск;
0Eh - сменить текущий диск;
36h - получить информацию о диске.
Функции 3Ch и 5Bh позволяют создать файл с заданной спецификацией. Спецификация файла, т.е. путь к нему вместе с именем файла и расширением указывается в виде символьной строки, завершающейся двоичным нулем (“строки ASCIIZ”). Адрес этой строки заносится в регистры DS:DX. В регистре СХ задается код атрибутов создаваемого файла: 0 - отсутствие атрибутов, 1 - только для чтения, 2 - скрытый, 4 - системный, 8 - метка тома, 20h - атрибут архива. Таким образом, с помощью этих функций можно создать как “настоящий” файл, так и метку тома (в корневом каталоге диска). В регистре АХ возвращается дескриптор созданного файла, которым можно в дальнейшем пользоваться для записи в файл или чтения из него. Различие функции 3Ch и 5Bh проявляется лишь в случае, когда файл с заданной спецификацией уже существует. Функция 3Ch при этом фактически уничтожает имеющийся файл и создает новый с тем же именем, а функция 5Bh завершается с CF=1.
Функция 5Ah используется для создания временного файла, имя которому (являющейся функцией текущего времени) дает система. В регистрах DS:DX указывается адрес пути к файлу (не имени файла!) в виде строки ASCIIZ, в конце которой должны быть предусмотрены 13 пустых байтов, куда DOS поместит обратный слеш и имя создаваемого файла, завершаемое двоичным нулем. При необходимости файлу можно придать любые атрибуты кроме атрибута метки тома.
Обычно временные файлы удаляются перед завершением программы, причем забота об этом лежит на программисте (автоматически файл не удаляется). Для записи в созданный временный файл следует использовать дескриптор, возвращаемый функцией 5Ah в регистре АХ.
Для каждого открытого файла DOS создает и поддерживает указатель, который представляет собой относительный номер байта в файле, начиная от которого будут выполняться запись или чтение данных. Указатель только что открытого или созданного файла позицируется системой на начало файла, а функции чтения или записи смещают его на число прочитанных или записанных байтов. Таким образом, повторное использование функции чтения или записи реализует последовательный доступ к файлу. Для организации прямого доступа к произвольному месту файла предусмотрена функция 42h, позволяющая задать положение указателя относительно начала файла ( для этого надо задать AL =0), конца файла (AL =2) или текущего положения указателя (AL =1). Само значение смещения указателя (со знаком) заносится в регистры СХ (старшая половина) DX (младшая).
Функция 3Fh и 40h используется для чтения из файла или устройства (функция 3Fh) и записи в файл или устройство (функция 40h). Перед вызовом функции в регистр BX помещается дескриптор, в регистр СХ - число читаемых или записываемых байтов, а в регистры DS:DX - адрес буфера в программе пользователя.
Иногда возникает необходимость найти в некотором каталоге все файлы, удовлетворяющие условиям шаблона групповой операции (например, все файлы с расширением .TXT или все файлы с именем EXAMPLE и любыми расширениями). Поиск файлов по заданным шаблонам групповых операций осуществляется с помощью функций 4Eh (найти первый файл) и 4Fh (найти следующий файл). Для их использования необходимо с помощью функций 1Ah организовать в программе область передачи данных (Disk transfer area, DTA) размером не менее 43 байтов, либо с помощью функций 2Fh получить адрес области передачи данных, созданной DOS. Известно, впрочем, что в качестве DTA DOS использует область PSP от байта 80h до конца. DOS помещает в DTA информацию о найденном файле (атрибуты, время и дата создания, размер и т.д.). В частности в байтах 1Eh… 2Ah DTA содержится имя и расширение файла в виде строки ASCIIZ.
При поиске файлов по заданному шаблону сначала активизируется функция 4Eh. В регистры DS:DX помещается адрес строки ASCIIZ с путем к рассматриваемому каталогу, а в регистр СХ - код операции атрибутов искомого файла. 0 обозначает "нормальный" файл, т.е файл без атрибутов, 1 - только для чтения, 2 - скрытый, 4 - системный, 8 - метка тома, 10h - каталог, 20h - атрибут архивации. Если установлены атрибуты поиска, то ищутся как нормальные файлы так и файлы с заданными атрибутами. В случае успешного нахождения заданного файла функция возвращает CF = 0, а имя и расширение файла в виде строки ASCIIZ помещается в DTA, в байты 1Eh… 2Ah. Получив имя файла, можно открыть его с помощью функции 3Dh и выполнить далее требуемые операции (чтение, запись и т.д.).
Поиск следующих файлов, удовлетворяющих условиям заданного шаблона, осуществляется с помощью функции 4Fh, которая используется так же, как и функция 4Eh поиска первого файла. При необходимости функцию 4Fh можно активизировать многократно, пока CF=1 не покажет, что все файлы, удовлетворяющие условиям заданного шаблона, исчерпаны.
Основная литература – 2[127-150, 183-192], 3[65-66].
Контрольные вопросы
1. Назовите стандартные дескрипторы устройств.
2. После выполнения каких функций работы с файлами ОС присваивает дескриптор (логический номер) файлу?
1. В каком формате задается имя файла при вызове функции создания файла?
2. Функции DOS для работы с файлами.
3. Функции DOS для работы с каталогами.
14 Лекция 14. Основы программирования в операционной системе Windows
Структура программы для Windows отличается от структуры программ для MS DOS. Можно выделить три типа структуры программ, которые условно можно назвать как классическая структура, диалоговая (основное окно - диалоговое), консольная, или безоконная структура.
Программирование в Windows основывается на использовании функций API (Application Program Interfase, т.е. интерфейс программного приложения). Все взаимодействия с внешними устройствами и ресурсами операционной системы будет происходить посредством таких функций.
Главным элементом программы в среде Windows является окно. Для каждого окна определяется своя процедура обработки сообщений. Окно может содержать элементы управления: кнопки, списки, окна редактирования и др. Эти элементы, по сути, также являются окнами, но обладающими особыми свойствами. События, происходящие с этими элементами (и самим окном), приводят к приходу сообщений в процедуру окна.
Операционная система Windows использует линейную модель памяти. Другими словами, всю память можно рассматривать как один сегмент. Это означает, что адрес любой ячейки памяти будет определятся содержимым одного 32-битного регистра, например EBX.
Операционная система Windows является многозадачной средой. Каждая задача имеет свое адресное пространство и свою очередь сообщений.
Начнем с того, как можно вызвать функции API. Выберем любую функцию API, например, MessageBox:
int MessageBox (HWND hwnd, LPCTSTR 1pText, LPCTSTR 1pCaption, UINT uType).
Данная функция выводит на экран окно с сообщением и кнопкой (или кнопками) выхода. Смысл параметров: hWnd – дескриптор окна, в котором будет появляться окно-сообщение, lpText – текст, который будет появляться в окне, lpCaption – текст в заголовке окна, uType – тип окна, в частности можно определить количество кнопок выхода.
Теперь о типах параметров. Все они в действительности 32-битные целые числа: HWND – 32-битное целое, LPCTSTR – 32-битный указатель на строку, UINT – 32-битное целое.
Часть API-функций получила суффикс “A”. Дело с том, что функции имеют два прототипа: с суффиксом “A” - поддерживают ANSI, а с суффиксом “W” - Unicode. Поэтому к имени функции добавляется суффикс «А», кроме того, при использовании MASM необходимо также в конце имени добавить @16. Таким образом, вызов указанной функции будет выглядеть так: CALL MessageBoxA@16. А так же быть с параметрами? Их следует аккуратно поместить в стек. Запомните правило: СЛЕВА НАПРАВО – СНИЗУ ВВЕРХ. Итак, пусть дескриптор окна расположен по адресу HW, строки – по адресам STRl и STR2, а тип окна-сообщения – это константа. Самый простой тип имеет значение 0 и называется MB_OK. Имеем следующее:
MB_OK equ 0
STR1 DB “Неверный ввод!”, 0
STR2 DB “Сообщение об ошибке”, 0
HW DWORD ?
…
PUSH MB_OK
PUSH OFFSET STR1
PUSH OFFSET STR2
PUSH HW
CALL MessageBox@16.
Результат выполнения любой функции – это, как правило, целое число, которое возвращается в регистре EAX.
Аналогичным образом в ассемблере легко воспроизвести те или иные Си-структуры. Рассмотрим, например, структуру, определяющую системное сообщение:
typedef struct tagMSG { // msq
HWND hwnd;
UINT message;
WPARAM wParam;
LPARAM lParam;
DWORD time;
POINT pt;
} MSG;
На ассемблере эта структура будет иметь вид:
MSGSTRUCT STRUC
MSHWND DD ?
MSMESSAGE DD ?
MSWPARAM DD ?
MSLPARAM DD ?
MSTIME DD ?
MSPT DD ?
MSGSTRUCT ENDS.
Теперь обратимся к структуре всей программы. Рассмотрим классическую структуру программы под Windows. В такой программе имеется главное окно, а следовательно, и процедура главного окна. В целом, в коде программы можно выделить следующие секции:
- регистрация класса окон;
- создание главного окна;
- цикл обработки очереди сообщений;
- процедура главного окна.
Конечно, в программе могут быть и другие разделы, но данные разделы образуют основной скелет программы. Разберем эти разделы по порядку.
Регистрация класса окон
Регистрация класса окон осуществляется с помощью функции RegisterClassA, единственным параметром которой является указатель на структуру WNDCLASS, содержащую информацию об окне.
Создание окна
На основе зарегистрированного класса с помощью функции Create WindowExA (или Create WindowA) можно создать экземпляр окна.
Цикл обработки очереди сообщений
Вот как выглядит этот цикл на языке Си:
while (GetMessage (&msq, NULL, 0, 0))
{
/ / разрешить использование клавиатуры,
/ / путем трансляции сообщений о виртуальных клавишах
/ / в сообщения о алфавитно-цифровых клавишах
TranslateMessage (&msq);
/ / вернуть управление Windows и передать сообщение дальше
/ / процедуре окна
DispatchMessage (&msg);
}
Функция GetMessage() «отлавливает» очередное сообщение из ряда сообщений данного приложения и помещает его в структуру MSG.
Что касается функции TranslateMessage, то ее компетенция касается сообщений WM_KEYDOWN и WM_KEYUP, которые транслируются в WM_CHAR и WM_DEDCHAR, а также WM_SYSKEYDOWN и WM_SYSKEYUP, преобразующиеся в WM_SYSCHAR и WM_SYSDEADCHAR. Смысл трансляции заключается не в замене, а в отправке дополнительных сообщений. Так, например, при нажатии и отпускании алфавитно-цифровой клавиши в окно сначала придет сообщение WM_KEYDOWN, затем WM_KEYUP, а затем уже WM_CHAR.
Как можно видеть, выход из цикла ожиданий имеет место только в том случае, если функция GetMessage возвращает 0. Это происходит только при получении сообщения о выходе (сообщение WM_QUIT). Таким образом, цикл ожидания играет двоякую роль: определенным образом преобразуются сообщения, предназначенные для какого-либо окна, и ожидается сообщение о выходе из программы.
Процедура главного окна
Вот прототип функции окна на языке С:
LRESULT CALLBACK WindowFunc (HWND hwnd, UINT message, WPARAM wParam, PARAM lParam).
Оставив в стороне тип возвращаемого функцией значения, обратите внимание на передаваемые параметры. Вот смысл этих параметров: hwnd – идентификатор окна, message – идентификатор сообщения, wParam и lParam – параметры, уточняющие смысл сообщения (для каждого сообщения могут играть разные роли или не играть никаких). Все четыре параметра имеют тип DWORD.
А теперь рассмотрим «скелет» этой функции на языке ассемблера.
WNDPROC PROC
PUSH EBP
MOV EBP, ESP ; теперь EBP указывает на вершину стека
PUSH EBX
PUSH ESI
PUSH EDI
PUSH DWORD PTR [EBP+14H] ; LPARAM (lParam)
PUSH DWORD PTR [EBP+10H] ; WPARAM (wParam)
PUSH DWORD PTR [EBP+0CH] ; MES (message)
PUSH DWORD PTR [EBP+08H] ; HWND (hwnd)
CALL DefWindowProcA@16
POP EDI
POP ESI
POP EBX
POP EBP
RET 16
WNDPROC ENDP.
Прокомментируем фрагмент. RET 16 – выход с освобождением стека от четырех параметров (16 = 4*4).
Доступ к параметрам осуществляется через регистр ЕВР:
DWORD PTR [EBP+14H] ; LPARAM (lParam)
DWORD PTR [EBP+10H] ; WPARAM (wParam)
DWORD PTR [EBP+0CH] ; MES (message) – код сообщения
DWORD PTR [EBP+08H] ; HWND (hwnd) – дескриптор окна.
Функция DefWindowProc вызывается для тех сообщений, которые не обрабатываются в функции окна.
Передачи параметров через стек
Передача параметров через стек не единственный способ передачи параметров, но именно через стек передаются параметры API-функциям, поэтому на это необходимо обратить внимание.
Состояния стека до и после вызова процедуры приводится на рисунке 9.
Рисунок демонстрирует стандартный вход в процедуру, практикующийся в таких языках высокого уровня, как Паскаль и Си.
При входе в процедуру, выполняется стандартная последовательность команд:
PUSH EBP
MOV EBP, ESP
SUB ESP, N; N – количество байт для локальных переменных.
Адрес первого параметра определяется как [EBP+8H]. Адрес первой локальной переменной, если она зарезервирована, определяется как [EBP-4] (имеется в виду переменная типа DWORD).
В конце процедуры идут команды:
MOV ESP, EBP
POP EBP
RET M
Здесь М – объем, взятый у стека для передачи параметров.

Такого же результата можно добиться, используя команду ENTER N,0 (PUSH EBP\MOV EBP, ESP\SUB ESP) в начале процедуры и LEAVE (MOV ESP, EBP\POP EBP) в конце процедуры.
Эти команды появились еще у 286-ого процессора и дали возможность несколько оптимизировать транслируемый код программы, особенно в тех случаях, когда речь идет о больших по объему модулях, создаваемых на языке высокого уровня.
Существуют два основных подхода, связанных со структурой процедуры и ее вызова. Условно первый подход можно назвать Си-подходом, а второй – Паскаль-подходом.
Первый подход предполагает, что процедура «не знает», сколько параметров находится в стеке. Естественно, в этом случае освобождение стека от параметров должно происходить после команды вызова процедуры, например, с помощью команды POP или команды ADD ESP,N (N – количество байт в параметрах).
Второй подход основан на том, что количество параметров фиксировано, а стек можно освободить в самой процедуре. Это достигается выполнением команды RET N (N – количество байт в параметрах). Вызов функций API осуществляется по второй схеме.
Основная литература – 5[27-44]
Контрольные вопросы
1. Какова классическая структура программы под Windows?
2. Какую модель памяти использует операционная система Windows?
3. Назначение API-функции MessageBoxA.
4. Назначение цикла обработки очереди сообщений, и какие API-функции используются в нем?
5. Какие параметры передаются через стек в процедуре главного окна?
15 Лекция 15. Консольные приложения
Консольные приложения удобно использовать, когда нет необходимости и времени для создания графического интерфейса, а программа должна что-то делать, например, обрабатывать большие объемы информации. Самая знаменитая консольная программа – это Far. Консольные приложения очень компактны не только в откомпилированном виде, но и в текстовом варианте. Но главное, консольное приложение имеет такие же возможности обращаться к ресурсам Windows посредством API-функций, как и обычное графическое приложение.
Для вывода текстовой информации используется функция API WriteConsloleA:
BOOL WriteConsole (HANDLE hConsoleOutput, CONST VOID *lpBuffer,
DWORD nNumberOfCharsToWrite, LPDWORD lpNumberOfCharsWritten, LPVOID lpReserved).
Параметры имеют следующий смысл:
1-й параметр – дескриптор буфера вывода консоли, который может быть получен при помощи функции GetStdHandle.
2-й параметр – указатель на буфер, где находится выводимый текст.
3-й параметр – количество выводимых символов.
4-й параметр – указывает на переменную, куда будет помещено количество действительно выведенных символов.
5-й параметр – резервный параметр, должен быть равен нулю.
Поскольку информация выводится в консольном окне, кодировка всех строковых констант должна быть DOS-овской. При запуске программы как Windows-приложения консольное окно появляется лишь на секунду. В чем тут дело? Дело в том, что консольные приложения могут создать свою консоль. В этом случае весь ввод-вывод будет производиться в эту консоль. Если же приложение консоль не создает, то здесь может возникнуть двоякая ситуация: либо наследуется консоль, в которой программа была запущена, либо Windows создает для приложения свою консоль.
Для того, чтобы создать свою консоль, используется функция AllocConsole. По завершении программы все выделенные консоли автоматически освобождаются. Однако, это можно сделать и принудительно, используя функцию FreeConsole. Для того, чтобы получить дескриптор консоли, используется функция GetStdHandle, аргументом которой может являться следующая из трех констант:
STD_INPUT_HANDLE equ –10 ; для ввода
STD_OUTPUT_HANDLE equ –11 ; для вывода
STD_ERROR_HANDLE equ –12 ; для сообщения об ошибке.
Следует отметить, что один процесс может иметь только одну консоль, поэтому выполнение в начале программы FreeConsole обязательно. При запуске программы в «чужой» консоли она наследует эту консоль, поэтому, пока мы не выполним функцию FreeConsole, новой консоли не создать – чужой консоли эта функция закрыть не может.
Для чтения из буфера консоли используется функция ReadConsole:
BOOL ReadConsole (HANDLE hConsoleInput, LPVOID lpBuffer, DWORD nNumberOfCharsToRead, LPDWORD lpNumberOfCharsRead, LPVOID lpReserved)
Значения параметров этой функции следующие:
1-й, дескриптор входного буфера.
2-й, адрес буфера, куда будет помещена вводимая информация.
3-й, длина этого буфера.
4-й, количество фактически прочитанных символов.
5-й, зарезервировано.
Установить позицию курсора в консоли можно при помощи функции SetConsoleCursorPosition:
BOOL SetConsoleCursorPosition (HANDLE hConsoleOutput, COORD dwCursorPosition)
со следующими параметрами:
1-й, дескриптор входного буфера консоли.
2-й, структура COORD:
COORD STRUC
X WORD ?
Y WORD ?
COORD ENDS.
Следует подчеркнуть, что вторым параметром является не указатель на структуру (что обычно бывает), а именно структура. На самом деле для ассемблера это просто двойное слово (DWORD), у которого младшее слово – координата X, а старшее слово – координата Y.
Установить цвет выводимых букв можно с помощью функции SetConsoleTextAttribute:
BOOL SetConsoleTextAttribute (HANDLE hConsoleOutput, WORD wAttributes).
Первым параметром этой функции является дескриптор выходного буфера консоли, а вторым – цвет букв и фона. Цвет получается путем комбинации (сумма или операция «ИЛИ») двух или более из представленных ниже констант. Причем возможна «смесь» не только цвета и интенсивности, но и цветов.
FOREGROUND_BLUE equ 1h ; синий цвет букв
FOREGROUND_GREEN equ 2h ; зеленый цвет букв
FOREGROUND_RED equ 4h ; красный цвет букв
FOREGROUND_INTENSITY equ 8h ; повышенная интенсивность
FOREGROUND_BLUE equ 10h ; синий свет фона
FOREGROUND_GREEN equ 20h ; зеленый цвет фона
FOREGROUND_RED equ 40h ; красный цвет фона
FOREGROUND_INTENSITY equ 80h ; повышенная интенсивность
Для определения заголовка окна консоли используется функция SetConsoleTitle:
BOOL SetConsoleTitle (LPCTSTR lpConsoleTitle)
единственным параметром, которой является адрес строки с нулем на конце. Здесь следует оговорить следующее: если для вывода в само окно консоли требовалась DOS-кодировка, то для установки заголовка требуется Windows-кодировка. Посмотрим, как можно решить эту проблему средствами Windows.
Существует специальная функция CharToOem:
BOOL CharToOem (LPCTSTR lpszSourse, LPTSTR lpszDest).
Первым параметром этой функции является указатель на строку, которую следует перекодировать, а вторым параметром – на строку, куда следует поместить результат. Причем поместить результат можно и в строку, которую перекодируем. Вот и все, проблема перекодировки решена. Мы рассмотрели несколько консольных функций, всего их около пятидесяти. Для большинства консольных функций характерно то, что при правильном их завершении возвращается ненулевое значение. В случае ошибки в EAX помещается ноль.
Обработка команд мыши и клавиатуры в консольном приложении
Возможность такой обработки делает консольные приложения весьма гибкими, расширяя круг задач, которые можно решить в этом режиме.
Рассмотрим одну весьма необычную, но чрезвычайно полезную API-функцию. Эта функция wsprintfA.
int wsprintf (LPTSTR lpBuffer, LPCTSTRlpszFormatSring, [arguments]).
Эта функция является неким аналогом библиотечной СИ-функции – sprintf. первым параметром функции является указатель на буфер, куда помещается результат форматирования. Второй – указатель на форматную строку, например: «Числа: %lu, %lu». Далее идут указатели на параметры (либо сами параметры, если это числа), число которых определено только содержимым форматной строки. Поскольку количество параметров не определено, то стек придется освобождать нам. Заметим также, что прототипом этой функции для библиотеки import32.lib (TASM32) будет не wsprinftA, a _wsprinftA (!). Наконец отметим, что если функция выполнена успешно, то в EAX будет возвращена длина скопированной строки.
В основе получения информации о клавиатуре и мыши в консольном режиме является функция ReadConsoleInput:
BOOL ReadConsoleInput (HANDLE hConsoleInput, PINPUT_RECORD lpBuffer, DWORD nLength, LPDWORD lpNumberOfEventsRead).
Параметры этой функции:
1-й, дескриптор входного буфера консоли.
2-й, указатель на структуру (или массив структур), в которой содержится информация о событиях, происшедших с консолью. Ниже мы подробно рассмотрим эту структуру.
3-й, количество получаемых информационных записей (структур).
4-й, указатель на двойное слово, содержащее количество реально полученных записей.
А теперь, подробно разберемся со структурой, в которой содержится информация о консольном событии. Прежде всего, отметим, что в Си эта структура записывается с помощью типа данных UNION. И при описании этой структуры мы обойдемся без STRUCT и UNION. Следует заметить, что в начале этого блока данных идет двойное слово, младшее слово которого определяет тип события. В зависимости от значения этого слова последующие байты (максимум 18) будут трактоваться, так или иначе.
Но вернемся к типу события. Всего системой зарезервировано пять типов событий:
KEY_EVENT equ 1h ; клавиатурное событие
MOUSE_EVENT equ 2h ; событие с мышью
WINDOW_BUFFER_EVENT equ 4h ; изменился размер окна
MENU_EVENT equ 8h ; зарезервировано
FOCUS_EVENT equ 10h ; зарезервировано
А теперь разберем значение других байт структуры в зависимости от происшедшего события.
Событие KEY_EVENT
|
Смещение |
Длина |
Значение |
|
+4 |
4 |
При нажатии клавиши значение поля больше нуля |
|
+8 |
2 |
Количество повторов при удержании клавиши |
|
+10 |
2 |
Виртуальный код клавиши |
|
+12 |
2 |
Скан-код клавиши |
|
+14 |
2 |
Для функции ReadConsoleInputA – младший байт равен ASCII-коду клавиши. Для функции ReadConsoleInputW слово содержит код клавиши в двухбайтной кодировке (Unicode) |
|
+16 |
4 |
Содержится состояния управляющих клавиш Может являться суммой следующих констант: RIGHT_ALT_PRESSED equ 1h LEFT_ALT_PRESSED equ 2h RIGHT_CTRL_PRESSED equ 4h LEFT_CTRL_PRESSED equ 8h SHIFT_PRESSED equ 10h NUMLOCK_ON equ 20h SCROLLLOCK_ON equ 40h CAPSLOCK_ON equ 80h ENHANCED_KEY equ 100h Смысл констант очевиден. |
|
Событие MOUSE_EVENT |
||
|
Смещение |
Длина |
Значение |
|
+4 |
4 |
Младшее слово – Х-координата курсора мыши, старшее слово – Y-координата мыши |
|
+8 |
4 |
Описывает состояние кнопок мыши. Первый бит – левая кнопка, второй бит – правая кнопка, третий бит – средняя кнопка. Бит установлен – кнопка нажата |
|
+12 |
4 |
Состояние управляющих клавиш Аналогично предыдущей таблице |
|
+16 |
4 |
Может содержать следующие значения: MOUSE_MOV equ 1h; было движение мыши DOUBLE_CL equ 2h; был двойной щелчок |
Событие WINDOW_BUFFER_SIZE_EVENT
По смещению +4 находится двойное слово, содержащее новый размер консольного окна. Младшее слово – это размер по Х, старшее слово – размер по Y. Да, когда речь идет о консольном окне, все размеры и координаты даются в «символьных» единицах.
Что касается последних двух событий, то там также значимым является двойное слово по смещению +4.
Основная литература - 1[419-480], 2[413-436].
Контрольные вопросы
1. Какая функция API используется для вывода текстовой информации?
2. Какая функция API используется для того, чтобы создать свою консоль?
3. Какая функция API используется для чтения из буфера консоли?
4. Какая функция API используется для установки позиции курсора в консоли?
5. Какая функция API используется для установки цвет выводимых букв?
Список литературы
1. Юров В., Хорошенко С. Ассемблер. - СПб.: Питер, 1999. – 534 с.
2. Зубков С.В. Assembler для DOS, Windows и Unix. - М.: ДМК, 1999. – 382 с.
3. Пирогов В.Ю. ASSEMBLER. Учебный курс. - М.: Нолидж, 2001. – 434 с.
4. Финогенов К.Г. Самоучитель по системным функциям MS-DOS. - М.: МП "МАЛИП", 1993. – 688 с.
5. Пирогов В.Ю. ASSEMBLER для Windows. - М.: Издатель Молгачева С.В., 2002. – 465 с.
6. Том Сван. Освоение Turbo Assembler. М.: Диалектика, 1996. – 445 с.
7. Рудаков П.И., Финогенов К.Г. Язык ассемблера: уроки программирования. - М.: ДИАЛОГ-МИФИ, 2001. – 589 с.
8. Скэнлон Л. ПЭВМ IBM PC и XT. Программирование на языке Ассемблера. - М.: Pадио и Связь, 1989. – 687 с.
9. Абель П. Язык Ассемблера для IBM PC и программирования. - М.: Высшая школа, 1992. - 456 с.
10. Брэдли Л. Программирование на языке Ассемблера для персональных ЭВМ IBM. М.: Радио и Связь, 1988. – 856 с.
11. Нортон П., Соухэ Д. Язык Ассемблера для IBM РС. Пер. с англ., - М.: Компьютер, 1993. - 931 с.
12. Hортон П. ПК фирмы IBM и OS MS-DOS. - М.: ДМК, 1991. – 651 с.
Содержание
1 Лекция 1. Представление данных
2 Лекция 2. Архитектурные особенности IBM PC
3 Лекция 3. Пользовательские регистры микропроцессора
4 Лекция 4. Системные регистры микропроцессора
5 Лекция 5. Способы адресации операндов
6 Лекция 6. Система команд микропроцессоров i80x86
7 Лекция 7. Система команд микропроцессоров i80x86
8 Лекция 8. Команды обработки битов
9 Лекция 9. Цепочечные команды. Команды прерывания
10 Лекция 10. Директивы ассемблера
11 Лекция 11. Организация программ. Макроопределения
12 Лекция 12. Основы программирования для MS DOS
13 Лекция 13. Работа с файлами
14 Лекция 14. Основы программирования в операционной системе Windows
15 Лекция 15. Консольные приложения