АЛМАТИНСКИЙ ИНСТИТУТ ЭНЕРГЕТИКИ И СВЯЗИ
Кафедра "Компьютерные технологии"
ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ
Алматы 2009
СОСТАВИТЕЛИ: Сатимова Е.Г. Проектирование баз данных. Методические указания к выполнению лабораторных работ для студентов специальностей 050704 – Вычислительная техника и программное обеспечение и 050703 – Информационные системы. – Алматы: АИЭС, 2009
В методических указаниях рассматривается разработка баз данных в среде MS SQL Server: от создания объектов базы данных, манипуляции данными до конструирования сложных запросов по поиску информации.
Ориентированный на работу с таблицами SQL не имеет достаточных средств для создания сложных прикладных программ. Поэтому он часто используется вместе с языками программирования высокого уровня. Одна лабораторная работа посвящена созданию клиентского приложения в любой среде программирования (например, Delphi или PHP).
По учебному плану в этом курсе предусматривается самостоятельная работа студентов. В методических указаниях приведены задания для самостоятельной работы.
Введение
Задачей курса "Проектирование Баз Данных" является не изучение особенностей той или иной СУБД, а освоение технологий создания и работы с базами данных. Проектирование информационных систем всегда начинается с определения цели проекта.
В настоящих методических указаниях решается задача анализа предметной области организации учебного процесса с использованием системы оценки освоения дисциплин для создания базы данных.
Хорошая база данных не получается случайно, структура ее содержимого должна тщательно прорабатываться, поэтому данный вопрос достаточно подробно рассмотрен в лабораторной работе №1 на базе MS Visio. Создание базы данных
На самом деле, проектирование базы данных — это важная часть работы с БД Даже хорошая СУБД будет плохо работать с неудачно спроектированной базой данных.
Время, по сути, сделало язык SQL стандартом de-facto в области работы с базами данных, а международные
стандарты языка SQL (стандарты SQL/89, SQL2, SQL/3) позволяют в значительной степени унифицировать
средства доступа к данным вне зависимости от используемой СУБД. В качестве используемой СУБД в
лабораторных работах применяется система управления базами данных MS SQL Server 2008,
хотя в равной степени это могла быть любая из современных СУБД.
Требование нужной информации из базы данных формулируется в виде запросов. Универсальным языком запросов к SQL Server является язык структурированных запросов SQL (Structured Query Language). Следует отметить, что язык SQL имеет множество диалектов, порожденных различными разработчиками. В последней версии MS SQL Server 2008 используется диалект Transact SQL, который базируется на SQL 2003 и очень близок к нему (SQL 2003- существующий на сегодня стандарт SQL для реляционных баз данных, установленный ANSI - Американским национальным институтом стандартов).
В методических указаниях достаточно подробно рассмотрены вопросы создания скриптов самой базы данных на языке SQL, манипуляции данными от создания простых до конструирования сложных запросов по поиску информации в спроектированной базе данных на диалекте Transact SQL.
На сегодняшний день нет идеальной системы управления базами данных, имеющей как развитый интерфейс, так и оптимизированную структуру. СУБД MS SQL Server 2008 не имеет интерфейса с пользователем в обычном понимании. Однако эта система является высокоэффективным хранилищем с развитыми средствами работы с данными и возможностями создавать приложения для работы с базой данных непрофессиональным пользователям. В методических указаниях приведен пример настройки доступа к источнику данных СУБД MS SQL Server 2008 среды Delphi для создания клиентского приложения.
Лабораторная работа № 1. Реализация структуры базы данных в MS Visio
1 Цель работы: а) получить навыки проектирования БД; б) ознакомление с методами и средствами создания ER-модели реляционных баз данных в среде MS Visio.
2 Задание на лабораторную работу
Спроектируйте модель данных учебного процесса в MS Visio: создайте представления «Преподаватели», «Кафедры», «Группы», «Студенты», «Предметы», «Учебный_процесс», «Успеваемость» и связи между ними на основании ER-диаграммы (Рисунок 1.6).
3 Методические указания к выполнению лабораторной работы
3.1 Концептуальное проектирование базы данных
Прежде чем реализовывать структуру базы данных в MS Visio, необходимо создать проект этой базы данных на контрольном примере.
Контрольный ( или тестовый ) пример представляет собой упрощенный вариант реальной задачи, просчитываемый вручную вплоть до получения конечного результата. В контрольном примере указываются требования к объему и составу данных используемой исходной информации и результатов решения.
С помощью контрольного примера проверяют постановку задач обработки данных и работоспособность отдельных программ и информационной системы в целом.
Правильно спроектированная БД облегчает управление данными и становится ценным поставщиком
информации. Плохо спроектированная БД вероятнее всего станет накопителем избыточной информации, т.
е. неоправданного дублирования данных. Избыточность, как правило, затрудняет выявление ошибок в данных.
На этапе анализа концептуальных требований и информационных потребностей необходимо решить
следующие задачи:· анализ требований пользователей к БД (концептуальных требований);
· выявление имеющихся задач по обработке информации, которая должна быть представлена в
БД (анализ приложений);· выявление перспективных задач (перспективных приложений);
· документирование результатов анализа.
Чтобы исследовать различные аспекты использования СУБД, мы рассмотрим сложный пример,
приближенный к действительности, – ведение электронной документации учебного заведения (вуза),
содержащую информацию об учебном процессе обучения студентов в вузах. Каждый вуз решает
данную задачу по-своему, чаще всего без использования баз данных. Наш пример не является
реальным примером обучения студентов в АИЭС или другом вузе, однако очень близок к тем
задачам, которые стоят в действительности перед деканатами АИЭС и других вузов.
Организация учебного процесса с использованием системы оценки освоения дисциплин характеризуется следующими особенностями: необходимо учитывать списки студентов групп; перечень изучаемых предметов; преподавательский состав кафедр, обеспечивающих учебный процесс; сведения о лекционных, практических и других видах занятий в каждой группе; результаты сдачи экзаменов по каждому из проведенных занятий. Учебная программа строится в соответствии с утвержденным графиком на каждую специальность до начала учебного процесса. Учебная программа включает предлагаемые на факультете обязательные и элективные курсы. Каждому студенту предлагается учебный план на основе рабочего, исходя из того, что в процессе обучения он должен набрать заданное количество кредитов.
3.2 Описание предметной области
Если в системе обрабатывается информация о студентах сущностью может являться студент, если обрабатывается информация об экзамене, то сущность – экзамен и т.п. Каждая сущность обладает определенным набором свойств (рассматриваем только свойства, представляющие интерес для пользователей в рамках проводимого исследования), которые запоминаются в информационной системе.
Так, например, в качестве свойств сущности СТУДЕНТ можно указать фамилию, дату рождения, место рождения, в качестве свойств сущности ЭКЗАМЕН – предмет, дату проведения экзамена, экзаменаторов.
Совокупность сущностей, характеризующихся в информационной системе одним и тем же перечнем свойств, называется классом сущностей (набором объектов). Так, например, совокупность всех сущностей СТУДЕНТ составляет класс сущностей СТУДЕНТ, совокупность всех сущностей ЭКЗАМЕН составляет класс сущностей ЭКЗАМЕН.
Класс сущностей описывается перечнем свойств сущностей, составляющих этот класс.
Экземпляром сущности будем называть конкретную сущность (сущность с конкретными значениями соответствующих свойств).
Пример класса сущностей СТУДЕНТ и конкретного экземпляра сущности:
Класс сущностей Экземпляр сущности
СТУДЕНТ
Фамилия Иванов
Дата рождения 21.05.87
Место рождения Нижний Новгород
Взаимоотношения сущностей выражаются связями (Relationships).
Различают классы связей и экземпляры связей. Классы связей – это взаимоотношения между классами сущностей, а экземпляры связи – взаимоотношения между экземплярами сущностей. Класс связей может затрагивать несколько классов сущностей.
Число классов сущностей, участвующих в связи, называется степенью связи n = 2, 3, … Так, например, класс сущностей СТУДЕНТ связан с классом сущностей ЭКЗАМЕН связью «сдает». Степень этой связи равна двум. В качестве примера связи степени три можно указать связь «родители» между тремя классами сущностей МАТЬ, ОТЕЦ, РЕБЕНОК. При n=2 связь называется бинарной.
Рассмотрим классификацию бинарных связей.
Числа, описывающие типы бинарных связей (1:1, 1:M, M:N), обозначают максимальное количество сущностей на каждой стороне связи. Эти числа называются максимальными кардинальными числами, а соответствующая пара чисел называется максимальной кардинальностью.
В зависимости от того, сколько экземпляров сущности одного класса связаны со сколькими экземплярами сущности другого класса, различают следующие типы связей:
· связь 1:1. Одиночный экземпляр сущности одного класса связан с одиночным экземпляром сущности другого класса. Примером является связь «соответствует» между классами сущностей ФАКУЛЬТЕТ и РАСПИСАНИЕ ЭКЗАМЕНОВ НА ФАКУЛЬТЕТЕ (каждому факультету соответствует свое расписание).
· связь 1:M. Единый экземпляр сущности одного класса связан со многими экземплярами сущности другого класса. Примером является связь «обучение» между классами сущностей ФАКУЛЬТЕТ и СТУДЕНТ (на одном факультете обучается много студентов).
· связь M:N. Несколько экземпляров сущности одного класса связаны с несколькими экземплярами сущности другого класса. Примером является связь «сдают» между классами сущностей СТУДЕНТ и ЭКЗАМЕН (каждый абитуриент сдает несколько экзаменов, и каждый экзамен сдают много студентов).
3.3 Описание информационного представления предметной области
В качестве основного понятия для описания предметной области, как уже отмечалось, используется понятие сущности (объекта), характеризуемой набором определенных свойств. Для информационного описания сущности вводится понятие атрибута. Атрибут – поименованное свойство (характеристика) сущности.
Атрибут представляет собой информационное отображение свойства сущности и принимает конкретное значение из множества допустимых значений. Так, например, для сущности СТУДЕНТ атрибут «фамилия» у конкретного экземпляра сущности принимает конкретное значение «Иванов».
Другим основным понятием для описания предметной области является понятие связи. Для представления связей между экземплярами сущностей могут использоваться атрибуты. В этом случае связь устанавливается путем включения в совокупность атрибутов сущности атрибута, однозначно идентифицирующего экземпляр сущности, находящийся в отношении с исходным экземпляром сущности.
Так, если мы рассмотрим класс сущностей ПРЕДМЕТ, представленный одной совокупностью атрибутов (название, номер), и класс сущностей УСПЕВАЕМОСТЬ , представленный другой совокупностью атрибутов (код студента, название предмета, дата экзамена, группа студента, оценка). Для представления связи «экзамены» (тип связи 1:1) в совокупность атрибутов УСПЕВАЕМОСТЬ можно включить атрибут «название предмета».
3.4 Построение ER-диаграмм
Чаще всего концептуальная модель представляется в виде диаграммы сущностей – связей (entity – relationship) или ER-диаграммы.
Процесс построения ER-диаграммы называется ER-моделированием. При этом используются следующие классические обозначения.
Класс сущностей представляется в виде четырехугольника. В четырехугольнике записано уникальное имя класса сущности (прописными буквами) и имена атрибутов строчными буквами.
СТУДЕНТ
Фамилия
Год рождения
Место рождения
Связи между сущностями обозначаются стрелками, рядом со стрелками указывается имя связи, а также максимальная кардинальность связи (максимальное число сущностей, которые могут участвовать в связи). Чтобы показать, что сущность обязана участвовать в связи (каждый экземпляр должен быть связан с экземпляром другого класса), на линию связи помещают перпендикулярную черту, а чтобы показать, что сущность может (но не обязана) участвовать в связи, на линию связи помещают овал.
Отношения между группами, предметами и преподавателями с их мощностями представлены на следующей схеме (рисунок 1.1). Атрибуты объектов на схеме не указаны.
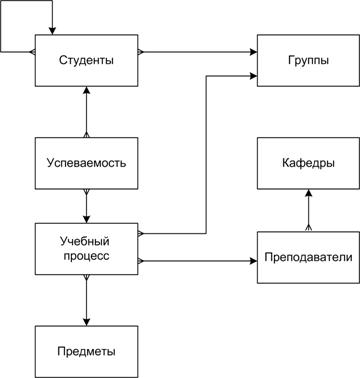
Рисунок 1.1 – Диаграмма учебного процесса
При описании сущностей выделяют особые совокупности атрибутов – ключи и внешние ключи. Ключ уникально идентифицирует экземпляр сущности и, вместе с внешним ключом, используется для реализации связей. На диаграммах атрибуты, входящие в первичный ключ, подчеркиваются (обозначение РК).
Важность понятий ключа и внешнего ключа будет проиллюстрирована далее на примерах.
Приведенные выше обозначения не являются общеупотребительными. Часто производитель программ, позволяющих рисовать ER-диаграммы, использует свою систему обозначений. Например, при использовании программы MS Visio в качестве основной используется так называемая реляционная нотация. В данной системе обозначений связи обозначаются стрелками между сущностями и названия связей не пишутся. Название сущности выделяется цветом, поля, входящие в первичный ключ, отделяются чертой от остальных атрибутов. Обязательные атрибуты отображаются с помощью полужирного шрифта.
Кроме того, слева от атрибута указывается, входит ли данный атрибут в первичный ключ, а также является ли атрибут внешним ключом.
На практике использование различных способов записи ER-диаграмм не представляет особой сложности – беглое ознакомление с соответствующим разделом документации позволяет быстро освоить используемую систему обозначений.
3.5 Выявление и моделирование сущностей и связей
При разработке концептуальной модели, прежде всего, следует определить сущности. С этой целью нужно сделать следующее:
· необходимо понять, какая информация должна храниться и обрабатываться, и можно ли это определить как сущность;
· присвоить этой сущности имя;
· выявить атрибуты сущности и присвоить им имя.
· выявив сущности, необходимо определить, какие связи имеются между ними.
· при определении связей (естественно, рассматриваем только те связи, которые имеют отношение к решаемым задачам обработки данных) необходимо учитывать следующее:
· то, как экземпляр одной сущности связан с экземпляром другой сущности;
· то, как должны быть установлены связи, чтобы была возможность ответа на все запросы пользователей (исходя из их информационных потребностей).
Поскольку вещи одного типа хранятся в отдельных объектных множествах, можем выделить следующие сущности: ГРУППЫ, СТУДЕНТЫ, КАФЕДРЫ, ПРЕПОДАВАТЕЛИ, ПРЕДМЕТЫ, УЧЕБНЫЙ ПРОЦЕСС, УСПЕВАЕМОСТЬ.
При создании концептуальной модели необходимо учитывать ряд условий – ограничений (в современной терминологии бизнес-правила):
В контрольном примере рассматривается только часть бизнес-правил учебного процесса.
Например:
· по результатам промежуточной аттестации студенту выставляется дифференцированная оценка в принятой в вузе системе баллов, характеризующая качество освоения студентом знаний, умений и навыков по данной дисциплине.
· студент не может учиться в двух группах одновременно.
· не может быть двух студентов с одинаковыми номерами зачетной книжки.
· преподаватель не может работать на нескольких кафедрах
· на кафедре работает много преподавателей
· преподаватель может вести один и тот же предмет в нескольких группах или несколько разных предметов в одной группе
· студенты сдают экзамены по предметам, которые они изучали.
Может быть сформулировано множество вопросов к базе данных, например: к какой группе относится студент, на каких кафедрах работают преподаватели, какие предметы, в каких группах они ведут, какую оценку получили студенты по определенным видам занятий по определенному предмету и т.д. Чтобы ответить на широкий круг возможных вопросов к базе данных, следует рассмотреть отношения между объектными множествами, необходимо присвоить связям имена и определить тип связей.
Между объектами ГРУППЫ и СТУДЕНТЫ существует отношение «один-ко-многим», поскольку одна группа включает много студентов, а один студент входит только в одну группу. Аналогично устанавливается связь между объектами КАФЕДРЫ и ПРЕПОДАВАТЕЛИ, которые также находятся в отношениях «один-ко-многим» (на одной кафедре работает много преподавателей, но каждый преподаватель работает на определенной кафедре). По каждому предмету проводится множество видов занятий в различных группах разными преподавателями. Это определяет отношения «многие-ко-многим» между множествами ГРУППЫ и ПРЕДМЕТЫ, ГРУППЫ и ПРЕПОДАВАТЕЛИ, ПРЕДМЕТЫ и ПРЕПОДАВАТЕЛИ, ПРЕДМЕТЫ и ВИДЫ_ЗАНЯТИЙ.
3.6 Пример построения подробной диаграммы «сущность – связь» для предметной области «Учебный процесс»
Исходя из выше изложенного, можно выделить следующие базовые сущности нашей предметной области:
· Группы. Атрибуты этой таблицы – номер, название, количество студентов, курс. Эта сущность отводится для хранения сведений о группах. Так как названия групп формируются в зависимости от факультета, кафедры, года поступления и будут многократно встречаться в связях с другими сущностями базы данных, то их целесообразно нумеровать и ссылаться на эти номера. Для этого вводится целочисленный атрибут "Grup_ID" – это ключевое поле, которое будет наращиваться на единицу при вводе в базу данных нового наименования.
· Студенты. Атрибуты – номер, фамилия, имя, отчество, дата рождения, адрес, номер группы, студент-староста. Эта сущность отводится для хранения сведений о студентах. Использование имени, фамилии и отчества в качестве идентификатора является неудобным решением, а учитывая, что идентификаторы студентов будут многократно встречаться в связях с другими сущностями базы данных, то их целесообразно нумеровать и ссылаться на эти номера.
· Кафедры. Атрибуты - номер, название, телефон и адрес. Эта сущность вводится для хранения сведений о кафедрах вуза. "Chair_ID" – это целочисленное ключевое поле, которое будет наращиваться на единицу при вводе в базу данных нового наименования автоматически.
· Преподаватели. Атрибуты – номер, фамилия, имя, отчество, должность, ученая степень и принадлежность к кафедре. Эта сущность отводится для хранения сведений о преподавателях. Использование имени, фамилии и отчества в качестве идентификатора является неудобным решением, а учитывая, что идентификаторы преподавателей будут многократно встречаться в связях с другими сущностями базы данных, то их целесообразно нумеровать и ссылаться на эти номера. Для этого вводится целочисленный атрибут "Teach_ID" – это ключевое поле, которое и будет идентификатором данной сущности.
· Предметы. Атрибуты – номер, название, общее количество часов за семестр, лекционные часы, часы практикумов, лабораторные часы. Эта сущность отводится для хранения сведений о предметах. Атрибут "Subj_ID" – это ключевое поле, которое и будет идентификатором данной сущности. Атрибут «Subj_NAME» является текстовым типом данных для отображения названия предмета. Атрибут «Total_Hours» является целочисленным типом данных для отображения общего количества часов. Атрибут «Lection_Hours» является целочисленным типом данных для отображения количества лекционных часов. Атрибут «Practice_Hours» является целочисленным типом данных для отображения количества часов практикума. Атрибут «Labor_Hours» является целочисленным типом данных для отображения количества лабораторных часов.
Связи между сущностями базируются на бизнес-правилах, построенных на основе подробного описания операций.
В процессе ER-моделирования системы учебного процесса был получен следующий набор бизнес-правил для сущностей и связей.
Бизнес-правило 1
Студент не может учиться в двух группах одновременно. Не может быть двух студентов с одинаковыми номерами зачетной книжки. Не существует групп без старост, следовательно, первый вводимый в группу студент – староста этой группы, что реализуется рекурсивной связью.
На основе Бизнес-правила 1 мы получаем следующий сегмент ER-модели.
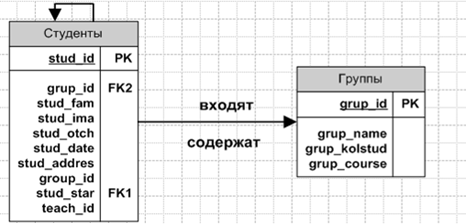
Рисунок 1.2 –ER–диаграмма бизнес-правила 1
Бизнес-правило 2
Преподаватель не может работать на нескольких кафедрах, преподаватель числится только на одной кафедре в данный момент времени. Тем временем на кафедре работают много преподавателей.
На основе Бизнес-правила 2 мы получаем следующий сегмент ER-Модели
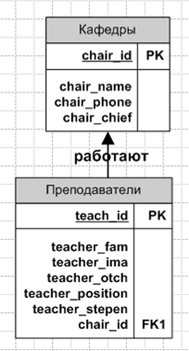
Рисунок 1.3 –ER–диаграмма бизнес-правила 2
Бизнес-правило 3
Каждая группа (соответственно и студент в ней) изучает конкретное множество предметов, которые ведут преподаватели. Преподаватель может вести один и тот же предмет в нескольких группах и несколько разных предметов изучаются одной группой. Связь «многие-ко-многим» реализуем через ассоциативную таблицу, так как на сегодня ни одна СУБД такую связь не реализует. То есть появляется еще одна таблица «Учебный процесс».
Учебный процесс. Сущность включает атрибуты номер группы, номер предмета, номер преподавателя, форма обучения, количество часов. Атрибут «Group_ID» отображает в формате integer группу, участвующую в учебном процессе. Атрибут "Subj_ID" отображает в формате integer предмет, относящийся к данной группе. Атрибут "Teach_ID" – это целочисленное поле, хранящее информацию о преподавателе, ведущем данный предмет. Атрибут "Kredit_count" – символьное поле, характеризующее форму обучения.
На основе Бизнес-правила 3 мы получаем следующий сегмент ER-Модели
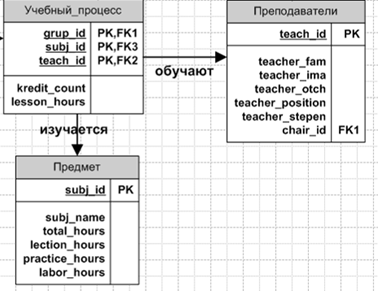
Рисунок 1.4 –ER–диаграмма бизнес-правила 3
Бизнес-правило 4
Студенты сдают экзамены по предметам, которые они изучали. Например, если студент входит в группу 1, а этой группой в учебном процессе изучался предмет 2, то студент должен будет сдать данный предмет. Связь «многие-ко-многим» реализуется через ассоциативную таблицу «Успеваемость»:
Успеваемость. Сущность включает атрибуты номер студента, номер группы, номер предмета, номер преподавателя, форму обучения, форму контроля, дату сдачи, итоговую оценку. Данная сущность хранит данные об успеваемости каждого студента.
На основе Бизнес-правила 4 мы получаем следующий сегмент ER-Модели
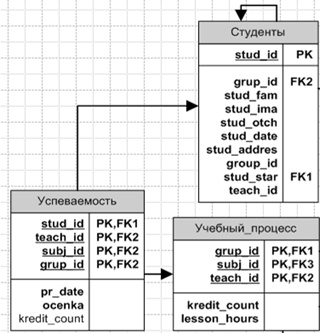
Рисунок 1.5 –ER–диаграмма бизнес-правила 4
База данных создаётся на основании схемы базы данных. Для преобразования ER–диаграммы в схему БД приведём уточнённую ER–диаграмму, содержащую атрибуты сущностей (рис. 1.6).
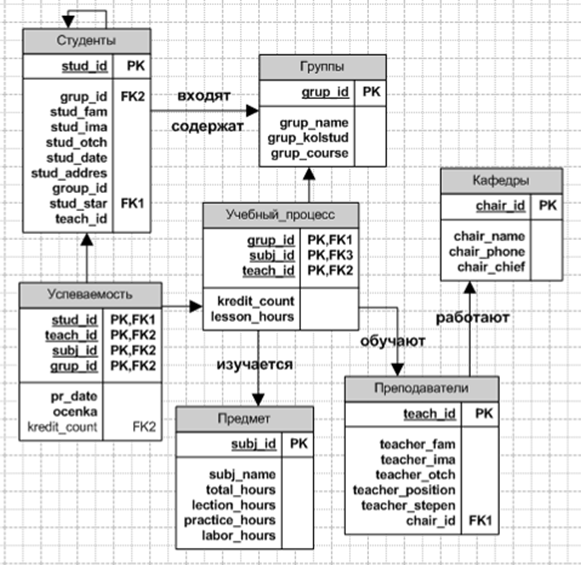
Рисунок 1.6 – Уточненная ER–диаграмма концептуальной модели учебного процесса
3.7 Преобразование концептуальной модели в реляционную модель
Концептуальная модель данных состоит из объектов, атрибутов, отношений, составных объектов. Каждая из этих конструкций должна быть преобразована в реляционные таблицы. Полученные в результате таблицы будут иметь четвертую нормальную форму. То есть дальнейшая нормализация модели не потребуется.
Преобразование объектных множеств и атрибутов. Объектное множество с атрибутами может быть преобразовано в реляционную таблицу с именем объектного множества в качестве имени таблицы и атрибутами объектного множества в качестве атрибутов таблицы. Если некоторый набор этих атрибутов может быть использован в качестве ключа таблицы, то он выбирается ключом таблицы. В противном случае в таблицу добавляется атрибут, значения которого будут однозначно определять объекты-элементы исходного объектного множества, и который, таким образом, может служить ключом таблицы. Преобразуем объектные множества ГРУППЫ, КАФЕДРЫ, ПРЕДМЕТЫ в реляционные таблицы с соответствующими названиями.
Каждое реляционное отношение соответствует одной сущности, и в него вносятся все атрибуты сущности. Для каждого отношения необходимо определить окончательно первичный ключ и внешние ключи (если они имеются). Отношения приведены в таблицах 2-8.
Для каждого отношения указаны атрибуты с их внутренним названием, типом и длиной. Типы данных обозначаются как:
N – числовой (numeric);
C – символьный (char);
D – дата (различная стандартная длина для каждой СУБД, поэтому она не указывается).
В полях примечание первичные и внешние ключи также подразумеваются обязательными полями (NOT NULL).
3.8 Создание модели базы данных Visio
Программа MS Visio предназначена для создания различного вида чертежей: от схем сетей до календарей, от планов офиса до блок-схем, а также структур баз данных.
Существует много типов документов Visio, но для создания практически всех документов можно воспользоваться тремя основными действиями:
1. Выбор и открытие шаблона.
2. Перетаскивание и соединение фигур.
3. Добавление текста (данных) в фигуры.
Выбор и открытие шаблона:
1. Откройте программу Visio 2007.
2. В списке Категории шаблонов выберите элемент Программное обеспечение и базы данных.
3. В диалоговом окне ПО и БД в области Готовые шаблоны дважды щелкните элемент Схема модели базы данных.
После открытия шаблона будут открыты необходимые коллекции фигур, которые называются наборами элементов. Наборы элементов, которые открываются с шаблоном Схема модели базы данных, называются Отношение сущности.
Рисунок 1.7 – Наборы элементов для работы с моделью базы данных в Visio
Перетащите первую фигуру (сущность) из набора элементов отношение сущности на страницу документа и отпустите кнопку мыши.
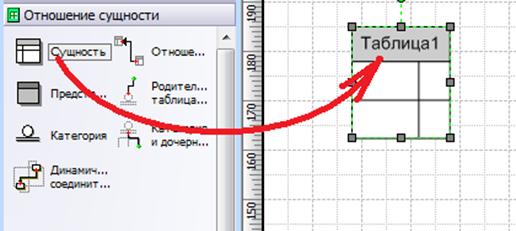
Рисунок 1.8 – Создание сущности (таблицы)
Фигуры Visio — это гораздо больше, чем просто изображения или символы.
Задайте свойства базы данных. Для этого щелкните по созданной фигуре (Таблица 1). Соответствующее окно (свойства базы данных, Рисунок 1.9) будет открыто в нижней части экрана.
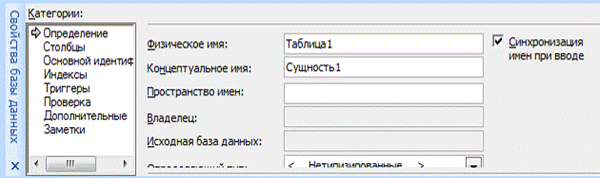
Рисунок 1.9 – Свойства базы данных
В категории Определение введите физическое имя сущности (Студенты). Затем перейдите в категорию Столбцы и введите данные соответствующие этой сущности.
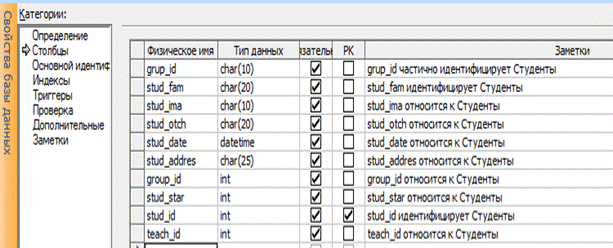
Рисунок 1.10 – Добавление атрибутов таблицы
В результате получается таблица показанная на рисунке 1.11.
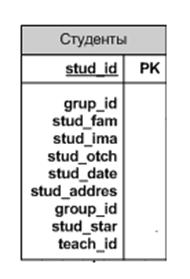
Рисунок 1.11 – Результат создания таблицы “Студенты”
Подобным образом необходимо создать все сущности базы данных “учебного процесса”, описанные в пункте 1.7.
После того, как создание всех сущностей завершено, необходимо создать отношения между таблицами. Для этого необходимо перетащить фигуру Отношение из набора элементов Отношение сущности (Рисунок 1.12)
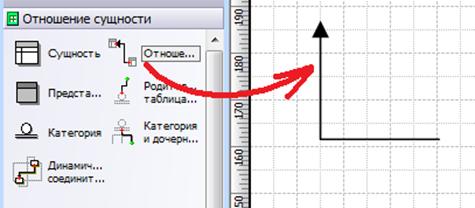
Рисунок 1.12 – Создание отношения
С помощью фигуры отношение необходимо соединить соответствующие таблицы подобно рисунку 1.6, не забывая о том, что стрелка должна быть направлена от дочерней таблицы к родительской. После создания связей между таблицами Внешние ключи расставляются автоматически по соответствующим атрибутам.
Контрольные вопросы:
1. Что такое концептуальная модель данных?
2. Что понимается под реляционной схемой базы данных?
3. Объясните смысл терминов: первичный ключ; внешний ключ; составной ключ; реляционная таблица; нормализация.
Лабораторная работа № 2. Реализация модели базы данных в среде СУБД MS SQL Server
1 Цель работы: а) создание базы данных в среде СУБД MS SQL Server 2008;
б) создание таблиц баз данных в среде СУБД MS SQL Server 2008.
2 Задание на лабораторную работу
1. Создать в MS SQL Server 2008 базу данных lab_study
2. Создать в базе данных lab_study таблицы по следующему плану:
a. таблицы Кафедры, Преподаватели – графическим способом в SQL Server Management Studio
b. таблицы Группы, Студенты - в Database Diagrams SQL Server Management Studio
c. таблицы Предметы, Учебный план, Успеваемость - скриптами в Object Explorer SQL Server Management Studio
3 Методические указания к выполнению лабораторной работы
3.1 Общие сведения о среде СУБД MS SQL Server
Microsoft SQL Server – это реляционная система управления базой данных (СУБД). В реляционных базах данных данные хранятся в таблицах. Взаимосвязанные данные могут группироваться в таблицы, кроме того, могут быть установлены также и взаимоотношения между таблицами. Отсюда и произошло название реляционные – от английского слова relational (родственный, связанный отношениями, взаимозависимый). Пользователи получают доступ к данным на сервере через приложения, а администраторы, выполняя задачи конфигурирования, администрирования и поддержки базы данных, производят непосредственный доступ к серверу.
SQL Server является масштабируемой базой данных, это значит, что она может хранить значительные объемы данных и поддерживать работу многих пользователей, осуществляющих одновременный доступ к базе данных.
СУБД SQL Server появилась в 1989 году и с тех пор значительно изменилась. Огромные изменения претерпели масштабируемость продукта, его целостность, удобство администрирования, производительность и функциональные возможности.
Cистема SQL Server может быть реализована либо как клиент-серверная система, либо как автономная "настольная" система. Тип проектируемой вами системы зависит от количества пользователей, которые должны одновременно осуществлять доступ к базе данных, и от характера работ, которые должны выполняться.
3.2 Задание на лабораторную работу
Реализуйте часть спроектированной модели данных учебного процесса в среде СУБД MS SQL Server:
Создайте таблицы «Преподаватели», «Кафедры», «Группы» и «Студенты».
В лабораторной работе для объектов рассматриваемой базы данных применяются названия на английском языке. Это связано с требованиями используемого программного обеспечения. Поэтому в приведенных ниже примерах база данных называется “Education”. Для создания любого объекта SQL Server существует несколько способов, базирующихся на выполнении определенной команды.
Размещение пользовательских баз может меняться в зависимости от версии SQL и размещения Program Files. Выяснить место расположения пользовательских баз можно из основного окна программы, выбрав из контекстного меню Свойства (Properties) любой базы в списке Databases. Также в окне свойств на вкладке TransactionLog просмотрите место расположения журнала транзакций. Команды резервного копирования и восстановления базы данных тоже выбираются в контекстном меню: строка Все задачи (All Tasks), команды Backup Databases и Restore Databases.
3.2.1 Создание базы данных
Физически база данных располагается в одном или нескольких файлах операционной системы. В одном файле операционной системы не может содержаться несколько баз данных. В этом файле хранятся такие объекты , как таблицы и индексы. Журнал транзакций – это рабочие области, которые SQL Server применяет для записи информации до и после выполнения транзакции. Эта информация может использоваться для отмены выполненной транзакции или для восстановления базы данных, если возникнет такая необходимость. В MS SQL Server 2008 журналы транзакций хранятся в отдельном файле, а не вместе с таблицами, как было в предыдущих версиях. Для создания базы данных с помощью Transact-SQL используется команда CREATE DATABASE.
CREATE DATABASE lab_study
ON PRIMARY
(NAME = education_data, FILENAME='C:\Program Files\Microsoft SQLServer\MSSQL\Data\education_data.mdf', size = 4, maxsize =25, filegrowth = 1 mb)
LOG ON
(NAME = education_log, FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL\Data\education_log.ldf', size = 4, maxsize = 20,
filegrowth =1 mb);
Внимание: Размещение базы и журнала транзакций - 'С:\…’ - может меняться в зависимости от версии SQL и размещения Program Files.
Здесь:
- education имя создаваемой базы данных.
- ON определяет список файлов на диске, в которых будет храниться информация базы данных.
- PRIMARY определяет файл, содержащий логическое начало базы данных и системных таблиц. В базе данных может быть только один первичный (PRIMARY) файл. Если этот параметр пропущен, то первичным считается первый файл в списке.
- LOG ON определяет список файлов на диске, в которых будет храниться журнал транзакций. Если этот параметр не определен, то размер журнала транзакций будет составлять 25% от общего размера файлов данных.
- education_data определяет логическое имя, которое SQL Server будет использовать для обращения к файлу.
- FILENAME задает параметры файла операционной системы (имя файла, который должен находиться на сервере, где установлен SQL Server, первоначальный и максимальный размеры базы данных и приращение для увеличения размера базы данных).
3.2.2 Создание таблиц
Определите текущую базу данных с помощью следующей команды:
USE lab_study;
Теперь все последующие команды будут выполняться именно в этой базе данных.
Таблицу можно создать с помощью оператора CREATE TABLE языка SQL.
Синтаксис
CREATE TABLE table_name
( { < column_definition > | < table_constraint > } [ ,...n ]
)
< column_definition > ::=
{ column_name data_type }
[ { DEFAULT constant_expression
| [ IDENTITY [ ( seed , increment ) ]
]
} ]
[ ROWGUIDCOL ]
[ < column_constraint > [ ...n ] ]
< column_constraint > ::=
[ CONSTRAINT constraint_name ]
{ [ NULL | NOT NULL ]
| [ PRIMARY KEY | UNIQUE ]
| REFERENCES ref_table [ ( ref_column ) ]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ]
}
< table_constraint > ::=
[ CONSTRAINT constraint_name ]
{ [ { PRIMARY KEY | UNIQUE }
{ ( column [ ,...n ] ) }
]
| FOREIGN KEY
( column [ ,...n ] )
REFERENCES ref_table [ ( ref_column [ ,...n ] ) ]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ]
}
Замечания
· Аргументы и ограничения рассматриваются в справке оператора CREATE TABLE;
· Определения столбца: при создании таблицы необходимо указать, по крайней мере, одно определение столбца.
Правила допустимости нулевого значения в рамках определения таблицы: допустимость нулевого значения столбца определяет, будет ли нулевое значение (NULL) принято в столбец как данные. NULL — это не ноль и не пробел. Это значит, что запись не была сделана или что было добавлено явное значение NULL, что обычно обозначает, что значение либо не известно, либо не применимо.
Креативная часть лабораторной работы:
Для работы в заданной базе данных необходимо использовать команду:
USE lab_study;
Создание таблицы Кафедры:
CREATE TABLE Chair (
Chair_ID int PRIMARY KEY,
Chair_NAME varchar(20) NOT NULL,
Chair_PHONE varchar (10) ,
Chair_CHIEF varchar (15)) ;
Создание таблицы Преподаватели:
CREATE TABLE Teacher (
Teach_ID bigint not null PRIMARY KEY ,
Teach_FAM varchar (20) NOT NULL,
Teach_IMYA varchar (10),
Teach_OTCH varchar (15),
Teach_POSITION varchar (18),
Teach_STEPEN varchar (12),
Chair_ID int NOT NULL) ;
Создание таблицы Группы:
CREATE TABLE Grup (
Grup_ID int identity (1,1) PRIMARY KEY,
Grup_NAME varchar (9) NOT NULL,
Grup_COURSE int NOT NULL ) ;
Так как слово GROUP является зарезервированным (часть конструкции GROUP BY), чтобы использовать его в качестве названия, необходимо всегда брать его в квадратные скобки [ ] либо не использовать это служебное слово в названиях элементов БД.
Создание таблицы Студенты (здесь приведены варианты описания ключей):
CREATE TABLE Students (
Stud_ID bigint,
Stud_FAM char(20) NOT NULL,
Stud_IMYA char(10),
Stud_OTCH char(15),
Stud_DATE datetime,
Stud_ADDRESS char(25),
Group_ID int NOT NULL REFERENCES [Grup] (Grup_ID ),
Stud_STAR bigint,
CONSTRAINT FK_students PRIMARY KEY (Stud_ID),
CONSTRAINT FK_students_students FOREIGN KEY (Stud_STAR) REFERENCES Students (Stud_ID)
);
Создание таблицы Предметы:
CREATE TABLE Subject (
Subj_ID int PRIMARY KEY ,
Subj_NAME varchar(20) NOT NULL,
Total_Hours int ,
Lection_Hours int,
Practice_Hours int,
Labor_Hours int ) ;
Создание таблицы Учебный план:
CREATE TABLE Study (
Grup_ID int NOT NULL REFERENCES Grup (Grup_ID ) ON DELETE CASCADE,
Subj_ID int NOT NULL REFERENCES Subject (Subj_ID) ,
Teach_ID bigint NOT NULL REFERENCES Teacher (Teach_ID),
Kredit_count int,
Lesson_Hours int not null,
CONSTRAINT PK_Study PRIMARY KEY (Grup_ID, Subj_ID, Teach_ID, Kredit_count)
) ;
Создание таблицы Успеваемость:
CREATE TABLE Progress (
Stud_ID bigint not null FOREIGN KEY REFERENCES Students (Stud_ID),
Grup_ID int not null,
Subj_ID int not null,
Teach_ID bigint not null,
Kredit_count int,
Pr_DATE datetime null,
OCENKA integer CHECK ( OCENKA in (0,1,2,3,4,5,6,7,8,9)) DEFAULT(0),
CONSTRAINT FK_Progress_Study FOREIGN KEY (Grup_ID, Subj_ID, Teach_ID, Kredit_count) REFERENCES Study (Grup_ID, Subj_ID, Teach_ID, Kredit_count ),
CONSTRAINT PK_Progress PRIMARY KEY (Stud_ID, Grup_ID, Subj_ID, Teach_ID, Kredit_count )
);
3.2.3 Изменение структуры таблиц
Структуру таблиц можно изменять командой ALTER TABLE.
Добавление полей. Добавьте в таблицу Students поле, где будет храниться информация о стипендии студентов:
ALTER TABLE Chair
ADD Chair_Cab char(10) not null;
Удаление полей из таблицы. Удалите введенное поле из таблицы:
ALTER TABLE Chair
DROP COLUMN Chair_Cab ;
Добавление ограничений. Если в таблице не были определенны первичные или внешние ключи, это также можно исправить с помощью ALTER TABLE.
Предположим, что в таблице Chair не был определен первичный ключ:
ALTER TABLE Chair
ADD CONSTRAINT PK_Chair PRIMARY KEY (Chair_ID)
В таблице Teacher (Преподаватели) не был описан один из внешних ключей, добавим его:
ALTER TABLE Teacher
ADD CONSTRAINT PK_Teacher_Chair FOREIGN KEY (Chair_ID) REFERENCES Chair (Chair_ID) ;
3.2.4 Удаление таблиц
Для удаления таблиц предназначена команда DROP.
Например
DROP Teacher
Будьте осторожны с командой DROP!
Контрольные вопросы
1. Что означает аббревиатура SQL?
2. Каковы главные отличия технологии клиент/сервер от технологии, использующей мэйнфрейм?
3. В рамках технологии клиент/сервер персональный компьютер является клиентом или сервером?
4. Какие типы данных допустимы при создании таблицы?
5. Как выполнить создание таблицы средствами меню программы MS SQL Server 2008?
6. Как выполнить создание таблицы средствами языка SQL?
7. Каким образом выполнить простейшие операции вставки строк данных в таблицу средствами SQL?
8. Каким образом выполнить простейшие операции модификации строк таблицы средствами SQL?
Лабораторная работа № 3 Манипуляция над данными
1 Цель работы: а) научить студентов заполнять базу данных скриптом и графической средой СУБД MS SQL Server 2008;
б) научить студентов удалять строки из таблицы базы данных скриптом в среде СУБД MS SQL Server 2008;
в) научить студентов измененять значения поля скриптом.
2 Задание на лабораторную работу
1. Заполните данными все таблицы вашей базы данных (команда INSERT).
Придерживайтесь следующих правил:
а) первыми заполняются таблицы, имеющие наименьшее количество связей (справочники);
б) соблюдайте правило категорной целостности: никакой ключевой атрибут строки не может быть пустым;
в) соблюдайте правило целостности на уровне ссылок: значение каждого внешнего ключа должно быть либо пустым, либо равным одному из текущих значений ключа другой таблицы.
2. Добавьте в таблицу Students поле Stud_STIP, в котором будет храниться информация о стипендии студентов (ALTER TABLE)
3. Заполните поле Stud_STIP таблицы Students различными данными, учитывая (используйте команду UPDATE).
4. Выполните по своему усмотрению команды по изменению данных в таблицах базы данных.
3 Методические указания к выполнению лабораторной работы
3.1 Команды манипуляции данными
Добавление новых строк в таблицу.
Синтаксис
INSERT [INTO]
table_name [ ( column_list ) ]
{ VALUES
( { DEFAULT | NULL | expression } [ ,...n] )
| derived_table
}
Замечание: аргументы и ограничения рассматриваются в справке оператора INSERT
Примечания:
· чтобы заменить данные в таблице, необходимо использовать инструкцию DELETE для очистки существующих данных перед загрузкой новых данных с помощью INSERT. Чтобы изменить значения столбца в существующей строке воспользуйтесь инструкцией UPDATE;
· если вставка column_list пропущена, список вставки столбцов, в котором указываются все столбцы таблицы в возрастающем порядке в соответствии с их порядковыми номе-рами, становится неявным;
· в column_list столбец таблицы можно определить только один раз. Если в column_list столбец отсутствует, SQL Server должен предоставить значение на основании определения столбца; в противном случае строку загрузить не удастся. SQL Server автоматически предоставляет значение для столбца в столбце:
• имеется свойство IDENTITY. Используется следующее значение приращения для идентификатора;
• имеется стандартное значение. Используется стандартное значение для столбца;
• неопределенное значение. Используется значение Null.
При вставке явных значений в столбец идентификаторов необходимо использовать список столбцов и список VALUES. Если в списке VALUES значения не расположены аналогично столбцам таблицы или отсутствуют значения для каждого столбца таблицы, необходимо использовать column_list для явного указания столбца, в котором хранится каждое входящее значение.
Если для указания значения столбца используется значение DEFAULT, то для этого столбца вставляется стандартное значение. Если стандартного значения для столбца не существует и в столбце могут быть значения Null, то вставляется значение NULL. Значение DEFAULT недопустимо для столбца идентификаторов.
При вставке строк применяются следующие правила:
• если значение загружается в столбец с типом данных char, varchar или varbinary, добавление или усечение замыкающих пробелов (пробелов для char и varchar, нулей для varbinary) определяется в соответствии с приведенной ниже таблицей;
|
Тип данных |
Стандартная операция |
|
char/binary |
Добавление исходного значения с замыкающими пробелами для столбцов char или с замыкающими нулями для столбцов binary к длине столбца. |
|
varchar |
Замыкающие пробелы в значениях символов, которые вставлены в столбцы varchar, не усекаются. Значения не добавляются к длине столбца. |
|
varbinary |
Замыкающие нули в двоичных значениях, которые вставлены в столбцы varbinary, не усекаются. Значения не добавляются к длине столбца. |
• если инструкция INSERT нарушает константу или правило, либо в ней присутствует значение, несовместимое с типом данных столбца, при выполнении инструкции происходит сбой и отображается сообщение об ошибке;
• если INSERT загружает несколько строк с помощью SELECT, любое нарушение правила или ограничения, возникающее в результате загрузки значений, приводит к остановке полной инструкции и строки не загружаются.
Примеры кода:
INSERT INTO Chair (Chair_ID,Chair_NAME,Chair_PHONE, Chair_CHIEF)
VALUES (50763,'Инж. Кибернетики','123456','Хисаров Б.’);
Создание записи «преподаватели»:
INSERT INTO Teacher (Teach_FAM, Teach_IMYA, Teach_OTCH,
Teach_POSITION, Teach_STEPEN, Chair_ID,Teach_ID)
VALUES ('Ахметова', 'Галия ', 'Сериковна', ' ', ' ',50763,77512);
3.2 Удаление строк из таблиц.
Это еще одна операция, которую необходимо уметь выполнять для поддержки базы данных. Для удаления строк из таблицы используется команда DELETE.
Синтаксис
DELETE
[ FROM ] table_name
[ WHERE < search_condition > ]
Замечание: аргументы и ограничения рассматриваются в справке оператора DELETE
Примечания:
· если предложение WHERE не указано, DELETE удаляет все строки из таблицы;
· если указаны условия поиска, они применяется к каждой строке таблицы. Все строки, результат условий поиска для которых — TRUE, помечаются для удаления;
· до проведения удалений для каждой строки в таблице проводится оценка условий поиска;
· все строки, помеченные для удаления, удаляются в конце выполнения инструкции DELETE перед проверкой ограничения целостности;
· сбой инструкции DELETE может произойти, если она нарушит ограничение FOREIGN KEY. Если инструкция DELETE удаляет несколько строк и одна из них нарушает ограничение, происходит отмена инструкции и возврат ошибки, удаления строк не происходит.
Пример кода
В следующем примере показано удаление всех строк из таблицы «Преподаватели»:
DELETE FROM Teacher
В следующем примере показано удаление всех строк из таблицы «Преподаватели», для которых «Должность» равно «Ассистент»:
DELETE FROM Teacher WHERE (Teach_Position= 'Ассистент');
В отличие от файловых СУБД, SQL Server не помечает записи как удаленные, а удаляет их физически, то есть восстановлению они не подлежат. Будьте осторожны с командой DELETE!
3.3 Изменение значения поля
Для изменения существующих значений в столбцах таблицы используется инструкция UPDATE.
Синтаксис
UPDATE table_name
[ WITH ( < table_hint > ) ]
SET
{ column_name = { expression | DEFAULT | NULL }} [ ,...n ]
[ WHERE < search_condition > ]
Замечание: аргументы и ограничения рассматриваются в справке оператора UPDATE
Примечания
• столбцы идентификаторов обновлять нельзя;
• если не указано предложение WHERE, обновляются все строки в таблице;
•перед обновлением строк в предложении WHERE проводится оценка условий поиска для каждой строки в таблице;
• если обновление строки нарушает ограничение или правило, либо настройку значения NULL для столбца, а также если новое значение является несовместимым типом данных, происходит отмена инструкции и возврат ошибки без обновления записей;
• все столбцы char имеют определенную границу по правому краю, до которой их можно заполнять;
• из данных, добавленных в varchar, удаляются все замыкающие пробелы, за исключением строк, содержащих только пробелы. Такие строки усекаются до одной пустой строки.
Пример
В следующем примере показано обновление таблицы преподавателей путем установления ученой степени преподавателю с порядковым номером 2:
UPDATE Teacher
SET Teach_Stepen = 'Профессор' WHERE Teach_ID = 2;
Контрольные вопросы
1. Какие команды манипуляции данными вы знаете?
2. Дайте определение целостности данных.
3. Сформулируйте правило целостности на уровне ссылок.
4. Что означает определение поля NOT NULL?
5. Если поле определено как NULL, значит ли это, что в это поле обязательно должно быть что-нибудь введено?
6. Что означает определение поля identity?
Лабораторная работа № 4. Простые запросы к базе данных.
1 Цель работы: научить студентов создавать простые запросы к базе данных скриптом и в графической среде СУБД MS SQL Server 2008.
2 Задание на лабораторную работу
Перед выполнением задания рекомендуется проработать все примеры, приведенные в п.п. 3.1 – 3.6.
Выполните поиск информации в отдельных таблицах:
1. Список преподавателей с указанием их должностей в алфавитном порядке.
2. Названия кафедр с фамилиями заведующих.
3. Список студентов с различными фамилиями, обучающихся в первой группе (предполагается, что в этой группе есть однофамильцы).
4. Список студентов, у которых стипендия больше 2000.
5. Список студентов, проживающих в Астане и Караганде.
6. Список студентов второй группы, у которых нет стипендии.
7. Список студентов третьей группы, фамилии которых начинаются на букву «А».
8. Список студентов, которые родились в 1988 году.
9. Посчитайте суммарную стипендию студентов третьей группы.
10. Посчитайте среднее число лекционных часов по всем предметам.
11. Сколько студентов введено в базу данных?
12. Выведите всю информацию о предметах.
13. Список студентов, которые не проживают в Алматы.
14. Список студентов, чьи дни рождения в мае.
15. Номера студентов с минимальной оценкой из ведомости успеваемости.
16. Номера студентов с максимальной оценкой из ведомости успеваемости.
3 Методические указания к выполнению лабораторной работы
3.1 Извлечение информации из таблиц
Запрос к базе данных представляет собой операцию выборки, которая сужает диапазон считываемой информации и ограничивает ее столбцами и строками, соответствующими заданным критериям.
Для выборки данных в Transact-SQL используется инструкция SELECT. Большинство реальных запросов SQL предназначено для выборки не всех, а определенных строк и столбцов таблиц.
Инструкция SELECT
Извлекает строки из базы данных и позволяет выбирать одну или несколько строк или столбцов в одной или нескольких таблицах. Это основной структурный компонент SQL, используемый для отправки запросов. Инструкция SELECT не изменяет, не вставляет и не удаляет данные.
Синтаксис
SELECT select_list
[ FROM table_source ]
[ WHERE search_condition ]
[ GROUP BY group_by_expression ]
[ HAVING search_condition ]
[ ORDER BY order_expression [ ASC | DESC ] ]
Замечания
Инструкция SELECT описывает запрос к системе. Выполнение запроса не обновляет данные. Результатом запроса является таблица идентично структурированных строк, в каждой из которых содержится одинаковый набор столбцов. Инструкция SELECT однозначно определяет, какие столбцы будут существовать в этой таблице результатов и какие строки ее заполнят. Инструкция SELECT не сообщает системе последовательность выполнения запроса; система сама выполняет запрос оптимальным в данном случае способом, используя внутренний модуль оптимизации на основе сведений о затратах. Результат должен гарантированно отвечать описанной ниже канонической стратегии выполнения. Единственное различие может заключаться в порядке расположения строк в таблице, хотя любой другой порядок может быть задан предложением ORDER BY.
Стратегия выполнения
1. Создайте объединение таблиц в предложении FROM. При использовании явного синтаксиса JOIN результат JOIN будет явным. Если в предложении FROM имеется список таблиц, разделенных запятыми, это неявное объединение таблиц векторным произведением.
2. При наличии предложения WHERE следует применять данные условия поиска к строкам, полученным после шага 1, и сохранять только те строки, которые удовлетворяют условию.
3. Если в предложении SELECT нет объединений, как нет и предложения GROUP BY, перейдите к шагу 7.
4. Если есть предложение GROUP BY, разделите строки, полученные после шага 2, на несколько групп так, чтобы у всех строк в каждой группе было одинаковое значение по всем столбцам группирования. Если предложения GROUP BY нет, поместите все строки в одну группу.
5. К каждой группе, полученной после шага 4, примените предложение HAVING, если таковое указано. Останутся только те группы, которые удовлетворят предложению HAVING.
6. Для каждой группы, полученной после шага 5, создайте одну строку результата путем оценки списка выбора в предложении SELECT в данной группе.
7. Если в предложении SELECT содержится ключевое слово DISTINCT, удалите все повторяющиеся строки, полученные в результате шага 6.
Если есть предложение ORDER BY, выполните сортировку результатов шага 7, как указано выражением порядкаю
SELECT _LIST
Указывает столбцы, возвращаемые запросом.
Синтаксис
SELECT [ ALL | DISTINCT ] TOP (expression) < select_list >
< select_list > ::=
{ *
| { table_name | table_alias }.*
| { column_name | expression } [ [ AS ] column_alias ]
} [ ,...n ]
Замечание: аргументы и ограничения рассматриваются в справке оператора SELECT
Рассмотрим только аргумент column_alias - альтернативное имя для замены имени столбца в наборе результатов запроса. Например, для столбца «quantity» может быть указан псевдоним «Quantity», «Quantity to Date» или «Qty». Кроме того, псевдонимы используются для указания имен для результатов выражений, например:
SELECT AVG(Stud_STIP) AS Средняя_стипендия
FROM Students
Примечание: column_alias можно использовать в предложении ORDER BY, но нельзя использовать в предложениях WHERE, GROUP BY и HAVING.
Предложение FROM используется для указания таблиц для извлечения строк. Предложение FROM является необязательным.
Примечание: возвращающие табличное значение функции не поддерживаются
Синтаксис и аргументы рассматриваются в справке команды.
[ FROM { < table_source > } [ ,...n ]
< table_source > ::=
table_name [ [ AS ] table_alias ]
| < joined_table >
| <derived_table> [ [ AS ] table_alias ]
< joined_table > ::=
< table_source > < join_type > < table_source > ON <search_condition >
| <table_source> CROSS JOIN <table_source>
| <left_table_source> { CROSS | OUTER } APPLY <right_table_source>
| ( < joined_table > )
< join_type > ::=
[ INNER | { { LEFT | RIGHT } [ OUTER ] } ] JOIN ]
left_table_source::= table_source
right_table_source::=table_source
Рассмотрим особенности применения аргумента JOIN:
CROSS JOIN указывает векторное произведение двух таблиц.
INNER указывает, что все совпадающие пары строк возвращены. Отмена несовпадающих строк из обеих таблиц. Задается по умолчанию, если тип объединения не указан.
LEFT [ OUTER ] указывает, что все строки таблицы слева, которые не соответствуют указанному условию, включаются в результирующий набор в дополнение ко всем строкам, которые возвращаются внутренним объединением. Для выходных столбцов таблицы слева указано значение NULL.
RIGHT [ OUTER ] указывает, что все строки таблицы справа, которые не соответствуют указанному условию, включаются в результирующий набор в дополнение ко всем строкам, которые возвращаются внутренним объединением. Для выходных столбцов таблицы справа указано значение NULL.
JOIN показывает, что указанные таблицы следует объединить.
ON < search_condition > указание условия, на котором основывается объединение. Условие может указать любой допустимый предикат, однако часто используются столбцы и операторы сравнения.
Замечания:
· если тот же запрос может быть написан как с оператором JOIN, так и с ключевым словом APPLY, запрос с применением JOIN может оказаться быстрее;
· если в right_table_source есть ссылки на таблицы, не привязанные к таблицам, перечисленным в right_table_source, то необходимо либо привести в соответствие имя или псевдоним таблицы в left_table_source, либо привести в соответствие имя или псевдоним таблицы во внешнем предложении FROM (если во вложенном запросе в предложении WHERE или списке SELECT указан оператор APPLY). Если и в первом случае и во втором имеются совпадающие ссылки, первый имеет больший приоритет;
· операторы APPLY имеют тот же приоритет, что и операторы JOIN. При отсутствии скобок последовательность операторов JOIN и APPLY будет вычисляться слева направо.
Дополнительные сведения см. в электронной документации по SQL Server в разделах «Использование предложения FROM» и «Использование APPLY».
Примеры
Следующий пример предоставляет больше сведений об использовании предложения FROM
SELECT Teach_ID, Teach_FAM, Teach_IMYA
FROM Teacher
Использование простого предложения FROM
SELECT Teach_ID, Teach_FAM, Teach_IMYA
FROM Teacher
ORDER BY Teach_ID
Использование CROSS JOIN
В следующем примере возвращается перекрестное произведение двух таблиц, Students и Group. Возвращается список всех возможных сочетаний строк Stud_ID и Group_ID:
SELECT S.Stud_ID, G.Grup_Id
FROM Students S
CROSS JOIN Grup G
ORDER BY S.Stud_ID, G.Grup_ID
Использование LEFT OUTER JOIN
Следующий пример соединяет две таблицы по столбцу Group_ID и сохраняет строки из левой таблицы, не имеющие соответствий. Таблица Students сравнивается с таблицей Group по столбцам Group_ID, которые имеются в обеих таблицах. В результирующем наборе отражаются все студенты (как входящие в группы, так и не входящие):
SELECT S.Stud_FAM,S.Stud_IMYA, G.GRUP_NAME
FROM Students S
LEFT OUTER JOIN Grup G ON S.Grup_ID = G.Grup_ID
ORDER BY G.Grup_NAME
Использование INNER JOIN
Следующий пример возвращает имена только тех студентов, кто записан в группы:
SELECT S.Stud_FAM,S.Stud_IMYA, G.GRUP_NAME
FROM Students S
LEFT OUTER JOIN Grup G ON S.Grup_ID = G.Grup_ID
ORDER BY G.Grup_NAME
Использование RIGHT OUTER JOIN
Следующий пример соединяет две таблицы по столбцу Group_ID и сохраняет строки из левой таблицы, не имеющие соответствий. Таблица Group сравнивается с таблицей Students по столбцам Group_ID, которые имеются в обеих таблицах. В результирующем наборе отражаются все группы (как со студентами, так и без):
SELECT S.Stud_FAM,S.Stud_IMYA, G.GRUP_NAME
FROM Students S
RIGHT OUTER JOIN Group G ON S.Grup_ID = G.Grup_ID
ORDER BY G.Grup_NAME
3.2 Задание таблиц в запросе
Процесс отбора данных начинается с задания нужных нам таблиц базы данных. Для этого в инструкции SELECT используется предложение FROM.
В следующей инструкции SELECT предложение FROM указывает, что возвратить надо все данные, которые находятся в таблице “Students ”:
SELECT *
FROM Students
Использование звездочки (*) в инструкции SELECT возвращает все столбцы. Это избавляет от необходимости специально указывать их в запросе.
Задание столбцов. При работе с инструкцией SELECT следует помнить, что можно отделить данные по вертикали, ограничив количество возвращаемых столбцов или по горизонтали, когда задаются подходящие строки.
Столбцы со значениями, возвращаемыми из таблиц базы данных, указываются в виде списка сразу после ключевого слова SELECT и отделяются друг от друга запятыми:
SELECT Stud_ID, Stud_FAM, Stud_IMA, Stud_ADDRESS
FROM Students
В этой команде:
− SELECT - ключевое слово;
− Stud_ID, Stud_FAM, Stud_IMA, Stud_ADDRESS - список столбцов из таблицы, которые выбираются запросом. Любые другие столбцы, не указанные в этом списке игнорируются;
− FROM - ключевое слово, после него перечисляются таблицы - источник данных.
Выбранные строки и столбцы таблиц базы данных всегда собираются во временную таблицу. В большинстве случаев эта таблица существует ровно столько времени, сколько нужно, чтобы данные были переданы запрашивающему их клиенту.
Столбцы таблицы можно отобразить в отличном от первоначального порядке (переставить):
SELECT Stud_ID, Stud_ADDRESS, Stud_FAM, Stud_IMA
FROM Students
Возможность изменения порядка отображения столбцов таблицы базы данных соответствует характеристикам реляционной базы данных, поскольку доступ к информации реляционной базы данных не зависит от реального способа хранения информации. Можно отображать один и тот же столбец таблицы в нескольких местах. Это удобно при необходимости улучшить восприятие таблицы.
DISTINCT - аргумент, который обеспечивает устранение двойных значений в команде SELECT. Предположим, необходимо узнать, какие студенты в настоящий момент имеют хотя бы по одной оценке (сами оценки пока не нужны, нужен только список кодов студентов):
SELECT Stud_ID
FROM Progress
При выполнении этой команды, коды дублируются (некоторые студенты имеют по несколько оценок). Для получения списка без дубликатов надо ввести:
SELECT DISTINCT Stud_ID
FROM Progress
DISTINCT может указываться только один раз в команде SELECT. Если выбираются несколько столбцов, то DISTINCT опускает строки, где все выбранные поля идентичны. Строки, в которых некоторые значения одинаковы, а некоторые различны, будут сохранены.
Если вместо DISTINCT указать ALL, это будет иметь противоположный эффект, дублирование строк сохранится. Поскольку это тот же самый случай, когда не указывается никакой аргумент, то ALL, по существу, лишь пояснительный аргумент.
3.3 Ограничение строк таблицы
Таблицы имеют тенденцию становиться очень большими. Поскольку обычно только некоторые их них интересуют Вас в данное время, имеется возможность устанавливать критерии, чтобы определить какие строки будут выбраны. Для этого используется ключевое слово WHERE - предложение команды SELECT, позволяющее задавать условие, которое может быть верным или неверным для любой строки таблицы. Команда извлекает только те строки из таблицы, для которых это условие верно. Синтаксис предложения WHERE:
WHERE имя_столбца оператор_сравнения значение
Инструкция SELECT с предложением WHERE сужает результирующий набор запроса. Она может возвратить всего одну строку или даже вообще не возвратить ничего, если строки, совпадающие с указанным в инструкции критерием, не найдены.
Предположим, необходимо получить имена и фамилии всех студентов с отчеством “Николаевич”:
SELECT Stud_FAM, Stud_IMA
FROM Students
WHERE Stud_OTCH = 'Николаевич'
Когда в запросе имеется предложение WHERE, SQL Server просматривает всю таблицу построчно и исследует каждую строку, чтобы определить верно ли утверждение.
Примечание: строковые константы типа 'Москва' в Transact-SQL ограничиваются либо апострофами ', либо кавычками ".
Теперь попробуем построить запрос с числовым полем в предложении WHERE. Выберем всех студентов со стипендией 1200:
SELECT *
FROM Students
WHERE Stud_STIP = 1200
В следующем примере показано использование предложения WHERE для получения общего количества стипендии приходящегося на группу с номером 5:
SELECT SUM(Stud_STIP) AS ' Сумма стипендии'
FROM Students
WHERE Group_ID=5
Сортировка вывода. Обычно требуется, чтобы данные как-то были упорядочены. Упорядочение задается с помощью ключевого слова ORDER BY (по умолчанию упорядочение по возрастанию). Синтаксис предложения ORDER BY:
ORDER BY Столбец1 | Целое_значение [ACS | DESC]
Например, выведем список студентов в алфавитном порядке: SELECT Stud_ID, Stud_FAM
FROM Students
ORDER BY Stud_FAM
Если после имени столбца указать имя еще одного столбца, то по значениям второго столбца будут упорядочены строки, содержащие одинаковые значения в первом столбце. Столбец, указанный в списке ключевого слова ORDER BY, можно заменить числом, соответствующим порядку столбца в списке (параметр Целое_значение ):
SELECT Grup_ID, Stud_ID, Stud_FAM
FROM Students
ORDER BY 1, 3 DESC
Параметры ASC (ascending) – по возрастанию, DESC (descending) – по убыванию задают порядок сортировки.
Примечания:
· столбцы данных типа text и image нельзя использовать в предложении ORDER BY;
· ASC указывает, что сортировку значений в выбранных столбцах следует выполнить в возрастающем порядке, от самого нижнего до самого верхнего;
· DESC указывает, что сортировку значений в выбранных столбцах следует выполнить в убывающем порядке, от самого верхнего до самого нижнего. Нулевые значения считаются самыми нижними допустимыми значениями.
Замечание: в предложении ORDER BY нет ограничения по числу элементов.
При использовании предложения ORDER BY с инструкцией UNION сортируемые столбцы должны быть именами или псевдонимами столбцов, указанными в первой инструкции SELECT. Например, первая из следующих инструкций SELECT выполнится успешно, а во время выполнения второй произойдет сбой:
Create t1 (col1 int, col2 int);
Create t2 (col3 int, col4 int);
SELECT * from t1
UNION
SELECT * from t2
ORDER BY col1;
Данная инструкция успешно выполняется, поскольку имя «col1» принадлежит первой таблице (t1)
SELECT * from t1
UNION
SELECT * from t2
ORDER BY col3;
Данная инструкция дает сбой, поскольку имя «col3» не принадлежит первой таблице (t1)
3.4 Операции в условиях для отбора данных
Transact-SQL позволяет строить сложные условия отбора записей и для этого использует операторы отношения, логические операторы и специальные операторы.
Операторы отношения:
· = Равно
· > Больше чем
· < Меньше чем
· >= Больше или равно
· <= Меньше или равно
· <> Не равно
Они имеют стандартные значения для символьных значений и дат.
Символьные значения сравниваются в терминах их кодов.
Предположим, что нам надо увидеть всех студентов со стипендией выше 1200:
SELECT *
FROM Students
WHERE Stud_STIP > 1200
Логические операторы:
· AND логическое "И"
· OR логическое "ИЛИ"
· NOT логическое отрицание
Оператор AND сравнивает два логических значения и возвращает TRUE (истина), если оба значения истинны (т.е. равны TRUE), в остальных случаях - FALSE (ложь). Оператор OR возвращает TRUE, если хотя бы один из аргументов равен TRUE. Оператор NOT возвращает TRUE, если его аргумент равен FALSE и наоборот.
Использование логических операторов значительно увеличивает возможности команды SELECT.
Логический оператор AND (логическое И) имеет смысл, если возвращаемые в результате выполнения запроса строки должны удовлетворять обоим условиям сравнения, заданным в предложении WHERE:
SELECT *
FROM Students
WHERE Stud_IMYA = 'Алексей' AND
Stud_ADDRESS = 'Таугуль'
Если в таблице имеется две строки, в которых значение в столбце Stud_IMA равно 'Алексей' (то есть имеются тезки), то логический оператор AND позволяет выбрать ту строку, в которой значение столбца Stud_ADDRESS равно «Таугуль» (то есть того Алексея, который живет в Таугуле).
C помощью оператора OR можно выбрать несколько значений из одного столбца:
SELECT *
FROM Students
WHERE Stud_IMYA = 'Алексей' OR
Stud_IMYA = 'Николай'
Оператор NOT указывается перед столбцом в операциях сравнения:
SELECT *
FROM Students
WHERE NOT Stud_ADDRESS = 'Таугуль'
Этот запрос позволяет считать из таблицы Students те строки, которые содержат информацию обо всех студентах, кроме тех, кто проживает в микрорайоне Таугуль.
Для группировки выражений Transact-SQL позволяет использовать круглые скобки ( ).
Например:
SELECT *
FROM Students
WHERE NOT (Stud_IMYA = 'Алексей' OR
Stud_IMYA = 'Николай')
3.5 Специальные операторы: IN, BETWEEN, LIKE, IS NULL
Оператор IN определяет список значений, в который должно входить значение поля. Например, если необходимо найти всех студентов с именем 'Алексей' и 'Николай', можно использовать такой запрос:
SELECT *
FROM Students
WHERE Stud_IMYA IN ('Алексей' , 'Николай')
Набор значений для оператора IN заключается в круглые скобки, значения разделяются запятыми.
Оператор BETWEEN похож на оператор IN. В отличие от списка допустимых значений, BETWEEN определяет диапазон значений. В запросе необходимо указать слово BETWEEN, затем начальное значение, ключевое слово AND и конечное значение. Первое значение должно быть меньше второго. Следующий запрос выберет студентов с оценками между 3 и 5:
SELECT *
FROM Progress
WHERE Ocenka BETWEEN 3 AND 5
Оператор LIKE применим только к символьным полям, с которыми он используется, чтобы находить подстроки. То есть, он ищет поле символа, чтобы видеть совпадает ли с условием часть его строки. В качестве условия он использует специальные символы:
· символ подчеркивания '_' замещает любой одиночный символ. Например, 'к_т' будет соответствовать 'кот' и 'кит', но не 'крот';
· знак процента % замещает последовательность любого числа символов. Например, '%м%р' будет соответствовать 'компьютер' и 'омар'.
Давайте выберем студентов, чьи имена начинаются с буквы 'О':
SELECT *
FROM Students
WHERE Stud_IMYA LIKE 'О%'
Оператор LIKE удобен при поиске значений - можно использовать ту часть значения, которую помните.
Часто необходимо различать строки, содержащие значения NULL в каком-либо столбце. Так как NULL указывает на отсутствие значения, для сравнненя с NULL существует специальный оператор - IS NULL. Выберем из нашей базы студентов с NULL значениями в столбце Stud_STIP:
SELECT *
FROM Students
WHERE Stud_STIP IS NULL
3.6 Обобщение данных с помощью агрегатных функций
Агрегатные функции берут группы значений и сводят их к одиночному значению. SQL Server предоставляет несколько агрегатных функций:
· COUNT производит подсчет строк, удовлетворяющих условию запроса;
· SUM вычисляет арифметическую сумму всех значений колонки;
· AVG вычисляет среднее арифметическое всех значений;
· MAX определяет наибольшее из всех выбранных значений;
· MIN определяет наименьшее из всех выбранных значений.
Функции SUM и AVG применимы только к числовым полям. С функциями COUNT, MAX, MIN могут использоваться числовые или символьные поля. При применении к символьным полям MAX, MIN сравнивают значения в алфавитном порядке. Агрегатные функции при своей работе игнорируют значения NULL.
Чтобы найти среднюю стипендию студентов, можно ввести запрос:
SELECT AVG (Stud_STIP)
FROM Students
Функция COUNT несколько отличается от остальных. Она подсчитывает число значений в данной колонке или число строк в таблице. Например, подсчитаем количество студентов, сдавших учебные предметы:
SELECT COUNT( DISTINCT Stud_ID)
FROM Progress
Обратите внимание, что в приведенном выше примере используется ключевое слово DISTINCT - это означает что подсчитываться будет количество уникальных значений в колонке Stud_ID таблицы Progress. Если опустить его, результат изменится.
Чтобы подсчитать общее число строк в таблице, используйте функцию COUNT со звездочкой вместо имени поля:
SELECT COUNT (*)
FROM Students
Предложение GROUP BY позволяет задавать Вам подмножество значений, для которых применяется агрегатная функция. Это дает возможность объединять поля и агрегатные функции в одном предложении SELECT. Предположим, что надо найти номера студентов с минимальной оценкой из ведомости успеваемости:
SELECT Stud_ID, MIN(ocenka )
FROM Progress
GROUP BY Stud_ID
Чтобы названия столбцов были осмысленными, измените предыдущую инструкцию следующим образом (примените псевдонимы для столбцов):
SELECT Stud_ID, MIN(ocenka) AS Мин_оценка
FROM Progress
GROUP BY Stud_ID
GROUP BY применяет агрегатные функции к группам записей. Условие формирования группы - одинаковое значение поля (в данном случае Stud_ID). GROUP BY можно использовать с несколькими полями. Усложним предыдущий запрос:
SELECT Stud_ID, Pr_Date, MAX(ocenka )
FROM Progress
GROUP BY Stud_ID, Pr_DATE
То есть мы выбираем строки с номерами студентов и максимальные оценки, полученные ими на каждую дату. Дни, в которые не было оценок, не будут показаны.
В следующем примере возвращается информация о количестве студентов в группах.
SELECT Grup_ID, COUNT(*) AS 'Количество'
FROM Students
GROUP BY Grup_ID
Ключевое слово HAVING используется в операторе SELECT вместе с ключевым словом GROUP BY, чтобы указать, какие из групп должны быть представлены в выводе.
Задает условие поиска, удовлетворяющее данную группу. Условие поиска может использовать статистические и нестатистические выражения. В нестатистических выражениях можно использовать только столбцы, отмеченные в предложении GROUP BY как столбцы группирования. Причина в том, что сгруппированные столбцы имеют общие для всей группы свойства. Аналогичным образом, статистические выражения имеют общее для всей группы свойство. Условие поиска предложения HAVING выражает предикат над свойствами группы.
Типы данных image и text нельзя использовать в предложении HAVING.
Для GROUP BY ключевое слово HAVING играет ту же роль, что и WHERE для ORDER BY. Предположим, что мы хотим получить максимальную оценку каждого студента, которая больше 4. Для достижения такого эффекта применяется предложение HAVING, которое определяет критерий, используемый для удаления групп из результата запроса, как это делает предложение WHERE для отдельных строк:
SELECT Stud_ID, Pr_DATE, MAX (ocenka )
FROM Progress
GROUP BY Stud_ID, Pr_DATE
HAVING MAX (ocenka ) > 4
Агрегатные функции позволяют не просто выбирать определенные значения из базы, но и производить их обобщение и анализ.
В следующем примере возвращается список всех групп, в которых больше 20 студентов:
SELECT Grup_ID, COUNT(*) AS 'Количество'
FROM Stud
GROUP BY Grup_ID HAVING (COUNT(*))>20
3.7 Построение вычисляемых полей и выборка записей по дате
В общем случае для создания вычисляемого (производного) поля в списке SELECT следует указать некоторое выражение языка SQL. В этих выражениях применяются арифметические операции сложения, вычитания, умножения и деления, а также встроенные функции языка SQL. Можно указать имя любого столбца (поля) таблицы или запроса, но использовать имя столбца только той таблицы или запроса, которые указаны в списке предложения FROM соответствующей инструкции. При построении сложных выражений могут понадобиться скобки.
Стандарты SQL позволяют явным образом задавать имена столбцов результирующей таблицы, для чего применяется фраза AS.
Пример. Получить список студентов с указанием фамилии и инициалов студентов:
SELECT Grup_id, Stud_FAM+' '+ Left(Stud_IMYA,1)+'.'+ Left(Stud_OTCH, 1) +'.' AS 'Ф.И.О'
FROM Students
В запросе использована встроенная функция Left, позволяющая вырезать в текстовой переменной один символ слева в данном случае.
При обращении к базе данных для выборки каких-то записей по дате нужно написать символьную строку приблизительно такого вида:
SELECT *
FROM SomeTable
WHERE Time <= '02/29/2000'
Пример. Получить список студентов с указанием года и месяца рождения:
SELECT Stud_FAM, Year(Stud_DATE) AS Год, Month (Stud_DATE) AS Месяц
FROM Students
В запросе использованы встроенные функции Year и Month для выделения года и месяца из даты.
Запрос:
выбрать для каждого преподавателя его два инициала с точкой и фамилию,
например, W.J.SMITH.
SELECT left(Teach_IMYA,1) + '.' + ' '+ left(Teach_OTCH,1) + '.' + ' ' + Teach_FAM
FROM Teacher
Контрольные вопросы
1. Назовите обязательные составляющие оператора SELECT.
2. Для всех ли данных в выражении ключевого слова WHERE обязательно нужно использовать кавычки?
3. К какому разделу SQL относится оператор SELECT?
4. Можно ли в выражении для ключевого слова WHERE задать несколько условий?
5. Допустимы ли кавычки для значений числовых полей?
6. Играет ли роль тип данных при использовании функции COUNT.
7. Чтобы группировать данные по столбцу, должен ли этот столбец бытьуказан в списке ключевого слова SELECT?
8. При использовании ключевого слова ORDER BY в операторе SELECT обязательно ли использовать ключевое слово GROUP BY?
Лабораторная работа № 5 Создание сложных запросов
1 Цель работы: научить студентов создавать сложные запросы к базе данных скриптом и в графической среде СУБД MS SQL Server 2008.
2 Задание на лабораторную работу
Перед выполнением задания рекомендуется проработать все примеры, приведенные в п.п. 3.1 – 3.3.
Получите следующую информацию из базы данных:
1. Список преподавателей, ведущих дисциплины «Информатика» и «Физика».
2. Список студентов, имеющих неудовлетворительные оценки.
3. Список студентов, не сдавших экзамен по высшей математике.
4. Список преподавателей кафедры «Информатика».
5. Список кафедр с указанием фамилий заведующих кафедр.
6. Список названий групп с указанием фамилий старост этих групп.
7. Списки студентов каждой группы с их оценками по всем предметам.
8. В каких группах проводятся занятия по предмету «Информатика»?
9. Какие виды занятий по Информатике проводятся в первой группе?
10. Сколько часов занятий по каждому предмету в каждой группе проводится в семестре?
3 Методические указания к выполнению лабораторной работы
3.1 Объединение таблиц в запросах
Использование псевдонимов для имен таблиц. Псевдонимы назначаются таблицам с целью сокращения объема печатания, а также для использования при рекурсивном связывании таблиц.
Пример:
SELECT A.Teach_ID, B.Chair_NAME
FROM Teacher A
INNER JOIN Chair B ON A.Chair_ID=B.Chair_ID
Рекурсивное связывание удобно использовать, когда все необходимые данные размещаются в одной таблице, но требуется каким-то образом сравнить одни записи таблицы с другими. В нашей базе в таблице Students хранятся фамилии студентов и номера старост этих студентов. Получим список студентов с фамилиями их старост:
SELECT A.Stud_FAM, B.Stud_FAM
FROM Students A
LEFT JOIN Students B ON A.Stud_Star = B.Stud_ID
Связывание по нескольким ключам. Предположим вы хотите увидеть, по каким видам работ и по каким предметам какие студенты какие получили оценки (для этого требуется связать четыре таблицы):
SELECT Students.Stud_FAM, Subject.Subj_NAME , Progress.OCENKA
FROM Students
JOIN Progress ON Stud.Stud_ID = Progress.Stud_ID
JOIN Subject ON Subject.subj_id = Progress.subj_id
3.2 Использование подзапросов
Запросы могут управлять другими запросами. Это делается путем помещения запроса внутрь условия другого запроса и использования вывода внутреннего запроса в верном или неверном условии.
Обычно внутренний запрос генерирует значение, которое проверяется в условии внешнего запроса, определяющего верно оно или нет. Например, мы знаем фамилию студента - Сидоров, но не знаем его кода (Stud_ID), и хотим получить все его оценки из таблицы Progress: SELECT *
FROM Progress
WHERE Stud_ID = (
SELECT Stud_ID
FROM Students
WHERE Stud_FAM = 'Сидоров' )
Чтобы выполнить внешний (основной запрос), сначала выполняется внутренний запрос (подзапрос) внутри предложения WHERE. При выполнении подзапроса просматривается таблица Students, в которой выбираются строки, где поле Stud_FAM равно 'Сидоров', затем извлекается значение поля Stud_ID. Пусть единственной строкой будет Stud_ID = 30104. Далее полученное значение помещается в условие основного запроса, вместо самого подзапроса, так что условие примет вид:
WHERE Stud_ID = 301004
При использовании подзапросов в условиях, основанных на операциях сравнения (больше, меньше, равно, не равно и т.д.), необходимо убедиться, что подзапрос будет возвращать одно и только одно значение. Если ваш подзапрос не вернет никакого значения, то основной запрос не выведет никаких значений.
Если Вы хотите использовать подзапрос, который возвращает несколько строк, то необходимо использовать оператор IN. Например, если в базе несколько студентов с фамилией Сидоров и все имеют оценки:
SELECT *
FROM Progress
WHERE Stud_ID IN (
SELECT Stud_ID
FROM Students
WHERE Stud_FAM = 'Сидоров' )
Найдем все оценки для предмета ТЭЦ:
SELECT Progress.OCENKA
FROM Progress
JOIN subject ON Progress.subj_id= subject.subj_id
WHERE progress.Subj_ID IN (
SELECT Subj_ID
FROM Subject
WHERE Subj_NAME = 'ТЭЦ')
Этот результат можно получить и с помощью объединения:
SELECT Progress.OCENKA
FROM subject
JOIN progress ON subject.subj_id=progress.subj_id
WHERE Subj_NAME = 'ТЭЦ'
Хотя этот запрос эквивалентен предыдущему, SQL Server должен будет просмотреть каждую возможную комбинацию строк из двух таблиц и проверить их соответствие условию.
Все вышеприведенные подзапросы объединяет то, что все они выбирают один единственный столбец. Это обязательно, поскольку их результат сравнивается с одиночным значением. Команды типа SELECT * запрещены в подзапросах.
Подзапросы можно также использовать в предложении HAVING. Эти подзапросы могут использовать собственные предложения GROUP BY или HAVING. Следующий запрос является тому примером:
SELECT Ocenka, COUNT (DISTINCT Stud_ID )
FROM Progress
GROUP BY Ocenka
HAVING Ocenka > (
SELECT AVG(ocenka )
FROM Progress
WHERE Pr_DATE >01/09/05)
Эта команда подсчитывает студентов с оценкой выше средней, сдавших экзамен после 01.09.05.
3.3 Связанные подзапросы
При использовании подзапросов можно обратиться во вложенном подзапросе к таблицам из внешнего подзапроса. Например, как найти всех студентов, сдавших экзамены 1 марта :
SELECT *
FROM Stud C
WHERE '2008-03-01' IN (
SELECT Pr_DATE
FROM Progress O
WHERE O.Stud_ID = C.Stud_ID )
Связанные запросы можно использовать для сравнения таблицы с собой. Например, можно найти всех студентов с баллом выше среднего:
SELECT Stud_ID
FROM Progress O
WHERE ocenka > (
SELECT AVG(ocenka )
FROM Progress O1
WHERE O1.Stud_ID = O.Stud_ID )
Использование оператора EXISTS. Оператор EXISTS берет подзапрос, как аргумент, и оценивает его как верный, если подзапрос возвращает какие-либо записи, и неверный, если тот не делает этого. Вот как выполняется поиск всех групп, в которых учится хотя бы один студент:
SELECT Grup_ID
FROM [Gruppa] G
WHERE EXISTS (
SELECT *
FROM Students
WHERE Stud.Grup_ID = G.Grup_ID)
Внутренний подзапрос выбирает всех студентов которые учатся в группе. Оператор EXISTS во внешнем условии отмечает, что подзапрос вернул некоторые данные, следовательно, условие верное. Подзапрос будет выполнен один раз для всего внешнего запроса и имеет одно значение во всех случаях. Поэтому EXISTS, когда используется таким образом, делает условие верным или неверным для всех строк сразу.
Использование операторов ANY, ALL. Рассмотрим новый способ поиска студента, сдавшего экзамен:
SELECT * FROM Students
WHERE Stud_ID = ANY (
SELECT Stud_ID
FROM Progress)
Оператор ANY берет все значения, выведенные подзапросом, и оценивает их как верные, если любое из них равняется значению в текущей строке внешнего запроса. Это означает, что подзапрос должен выбирать значения такого же типа как и те, которые сравниваются в основном условии.
В приведенном выше запросе можно было бы использовать оператор IN. Однако оператор ANY можно применять не только с оператором равенства.
Оператор ALL считает условие верным, если каждое значение, выбранное подзапросом, удовлетворяет условию внешнего запроса. Выберем тех студентов, у которых стипендия выше 1500:
SELECT *
FROM Students
WHERE Stud_STIP > ALL(
SELECT Stud_stip
FROM Students
WHERE Stud_STIP = 1500 )
Использование команды UNION. Команда UNION объединяет вывод нескольких запросов с исключением повторяющихся строк. Например, приведенный ниже запрос выводит всех студентов и преподавателей, чьи фамилии размещены между буквами К и С:
SELECT Stud_FAM
FROM Students
WHERE Stud_FAM BETWEEN 'К' AND 'С'
UNION
SELECT Teach_FAM
FROM Teacher
WHERE Teach_FAM BETWEEN 'К' AND 'С'
Для применения команды UNION существует 2 правила:
• число и порядок следования колонок должны быть одинаковы во всех запросах
• типы данных должны быть совместимы
UNION автоматически исключает дубликаты строк из вывода. Если вы хотите, чтобы все строки из запросов попали в результат, используйте UNION ALL:
SELECT Stud_FAM
FROM Students
UNION ALL
SELECT Teach_FAM
FROM Teacher
Контрольные вопросы
1. Можно ли иметь несколько ключевых слов AND в выражении, заданном ключевым словом WHERE?
2. Что такое рекурсивное связывание?
3. При связывании таблиц должны ли они связываться в том же порядке, в каком они указаны в выражении ключевого слова FROM?
4. При использовании в операторе запроса таблицы-связки, обязательно ли выбирать в запросе ее столбцы?
5. Можно ли связывать в запросе не один, а несколько столбцов таблиц?
6. Какая часть оператора SQL задает условия связывания таблиц? 7. Что будет, если в запросе указать выборку из двух таблиц, но не связать их?
8. Для чего используются псевдонимы таблиц? 9 . Что такое подзапрос? Как он работает?
Лабораторная работа № 6. Представления
1 Цель работы: научить студентов создавать представления к базе данных скриптом и в графической среде СУБД MS SQL Server 2008.
2 Задание на лабораторную работу
Выполните упражнения, приведенные в п.3.1-3.5.
Создайте следующие представления:
a) отображающее список групп и старост этих групп;
b) отображающее список студентов не сдавших экзамен по предмету;
c) которое отображало бы содержимое таблицы «Успеваемость» в удобном для пользователя виде (без идентификаторов);
d) отображающее список студентов живущих в общежитии;
e) отображающее форматированный список студентов в одном поле (формат: Сидоров А.С. (группа));
f) отображающее таблицу «учебный процесс» в удобочитаемом виде (без идентификаторов).
3 Методические указания к выполнению лабораторной работы
3.1 Общие сведения о представлениях
Представление (view) является своего рода виртуальной таблицей, обеспечивающей доступ пользователей к некоторому подмножеству данных, составленному из одной или более таблиц. Для пользователя представление как обычная таблица, но при этом само по себе оно не содержит данных. Физически представление реализовано в виде SQL-запроса, на основе которого производится выборка данных из одной или более таблиц или представлений. Таблицы, на основе которых создается представление, называются базовыми (base table). В самом простом случае можно создать представление на базе одной таблицы, которое будет содержать точно такой же набор данных, как и исходная таблица. На практике такие представления редко используются. Более сложные представления могут объединять столбцы из нескольких таблиц. При этом, задав условие для выборки, можно сделать доступным из представления только ограниченное множество строк из этих таблиц. Когда из представления исключается один или более столбцов базовой таблицы, говорят, что на таблицу наложен вертикальный фильтр. Если в определении представления установлено одно или более условий для выборки строк, говорят, что на таблицу наложен горизонтальный фильтр.
Механизм представлений позволяет ограничить доступ пользователей к конфиденциальным данным в таблице. Каждый раз, когда пользователь обращается к представлению, сервер осуществляет выборку данных, в соответствии с запросом, содержащемся в определении этого представления. При этом проверяется актуальность всех ссылок в запросе на предмет существования объектов, требующихся для его выполнения. Если одна из таблиц, включенных в запрос, окажется недоступной, то станет невозможным использование представления в целом.
Представления создаются с помощью оператора CREATE VIEW. Аналогично оператору CREATE TABLE, операторCREATE VIEW можно использовать только для создания представления, которого до сих пор не существовало.
CREATE VIEW имя_представления
AS
SELECT список_выбора
[ FROM таблицы_источники ]
[ WHERE условие_отбора ]
Лучший способ понять, что такое представления, — рассмотреть конкретный пример. Представление можно создать на базе данных одной или нескольких таблиц, а также других представлений.
3.2 Представление на базе одной таблицы:
Создадим представление StudAddress из таблицы Students:
CREATE VIEW StudAddress
AS
SELECT Stud_ID, Stud_FAM, Stud_IMA,Stud_ADDRESS
FROM Students
Создадим представление StudStip из таблицы Students:
CREATE VIEW StudStip
AS
SELECT distinct stud_fam,stud_stip
FROM stud
На первый взгляд, бессмыслено создавать представление на базе одной таблицы. Однако некоторые столбцы таблицы могут содержать данные, доступ к которым отдельным категориям пользователей может оказаться не желательным или наооборот (например, размер стипендии студента). Или попросту нет необходимости в опредеоенных данных из той или иной таблицы (допустим, нас интересуют только фамилия , имя и адрес студента). В данном случае создается представление на базе некоторой таблицы, из которого исключаются конфиденциальные, либо не нужные данные.
Для удаления представлений из базы данных используется команда DROP VIEW имя_представления. У этой команды есть две опции – RESTRICT и CASCADE. Если используется RESTRICT и в условиях имеются зависимые представления, то оператор DROP VIEW возвращает ошибку. При использовании опции CASCADE и наличии зависимых представлений оператор DROP VIEW завершается успешно, и все зависимые представления тоже удаляются.
3.3 Удаление представления
Представления удаляются с помощью оператора DROP VIEW <имя_представления >:
DROP VIEW StudAddress
3.4 Представление на базе нескольких таблиц
Чаще всего представления используются для упрощения работы с SQL, и нередко это относится к объединениям.
Создадим представление PrepodChair на базе двух таблиц teacher и chair, которое бы содержало фамилии преподавателей, работающих на кафедрах:
CREATE VIEW PrepodChair
AS
SELECT teacher.teach_fam, chair.chair_name
FROM teacher, chair
WHERE teacher.chair_id=chair.chair_id
Создадим представление Studoсenka из таблиц Students, Subject и Progress, в котором отражается список студентов с их оценками по предметам:
CREATE VIEW Studocenka
AS
SELECT stud.stud_fam, subject.subj_name, progress.ocenka
FROM stud,subject,progress
WHERE (progress.stud_id=stud.stud_id) and (progress.subj_id=subject.subj_id)
Представления чрезвычайно полезны для упрощения иcпользования вычисляемых полей. Создадим представление Otli4n, в котором отражается количество отличников по предметам в группе:
CREATE VIEW Otli4n
AS
SELECT g.grup_name as [Группа], s.subj_name as [Предмет],
count(p.ocenka) as[Колличество отличников]
FROM progress p join gruppa g on g.grup_id = p.grup_id
JOIN subject s on s.subj_id = p.subj_id where p.ocenka in (8,9)
GROUP BY g.grup_name, s.subj_name
Таким образом, представления могут значительно упростить сложные операторы SQL. Используя представления, можно один раз записать код SQL и затем повторно использовать его, если возникает такая необходимость.
Другим наиболее частым случаем использования представлений является переформатирование выбранных данных. Предположим, что результаты регулярно требуются в определенном формате. Вместо того, чтобы выполнять объединение каждый раз, когда в этом возникает необходимость, можно создать представление и использовать его вместо объединения.
Можно использовать представления для переформатирования данных. Создадим представление отражающее преподавателей, работающих на кафедрах в определенном формате:
CREATE VIEW PrepodChair2
AS
SELECT left(Teach_IMA,1) +'.'+left(Teach_OTCH,1) +'.'+ left(Teach_FAM,15)+'('+left(teach_position,10)+')' AS [Teacher] , chair_name AS [Chair]
FROM Teacher, chair
WHERE chair.chair_id=teacher.chair_id
3.5 Представление на базе представлений
Поскольку представлнения представляют собой виртуальные таблицы, то на их базе также можно создавать другие представления. Допустим, нам требуется создать представление отображающее количество грантников и платников на специальностях. Данное представление, конечно, можно сделать на основе сложных запросов, однако, сделаем его на базе двух представлений Grantn (грантники) и Platn (платники).
Сначала необходимо создать и заполить таблицу Speciality (Специальности):
CREATE TABLE Speciality (
Spec_ID int not null PRIMARY KEY,
Spec_NAME char (20) not null,)
Далее необходимо добавить атрибут spec_id в таблицу Students, создать внешний ключ на spec_id в таблице Spec:
ALTER TABLE stud
ADD spec_id int foreign key references Spec (spec_id)
Создадим представление Grantn, отражающее специальность и количество грантов на этой специальности:
CREATE VIEW Grantn
AS
SELECT spec.spec_name, count (distinct stud_id) as 'grant'
FROM students, Spec
WHERE stud.spec_id=spec.spec_id and Stud_stip is not null
GROUP BY spec_name
Создадим представление Plat, отражающее специальность и количество платников на этой специальности:
CREATE VIEW plat
AS
SELECT spec.spec_name, count (distinct stud_id) as 'plat'
FROM stud, Spec
WHERE stud.spec_id=speciality.spec_id and Stud_stip is null
GROUP BY spec_name
Теперь создадим собствено само представление StudSpecGP, отражающее специальность и количество платников, грантников на базе представлений Grantn и Plat:
CREATE VIEW plat
AS
SELECT p.spec_name AS ' Speciality' ,
(SELECT [grant] FROM Grantn WHERE grantn.spec_name= g.spec_name) AS 'Gratniki',
(SELECT [plat] FROM plat WHERE plat.spec_name= p.spec_name) AS 'Platniki'
FROM grantn g, plat p
WHERE g.spec_name=p.spec_name
GROUP BY g.spec_name, p.spec_name
Контрольные вопросы
1. Что такое представление?
2. Как называются таблицы, на основе которых создается представление?
3. Что означают понятия «Вертикальный», «Горизонтальный» фильтры?
4. Что случится, если таблица, на основе которой строится представление, будет удалена?
5. Как представление можно использовать для защиты данных?
6. Содержит ли данные представление?
7. Для достижения каких целей используют представления?
Лабораторная работа № 7. Хранимые процедуры, функции и триггеры
1 Цель работы: научить студентов создавать хранимые процедуры, функции и триггеры к базе данных скриптом и в графической среде СУБД MS SQL Server 2008.
2 Задание на лабораторную работу
Выполните упражнения, приведенные в п.3.1.-3.3.
Создайте процедуры, позволяющие выполнить следующие действия:
1. Отчислить/Зачислить студента.
2. Увеличить суммы стипендий всех студентов на 15%.
3. Ставить студентам оценки за различные виды работ(практика, контрольная, семестровая, курсовой проект, экзамен) по различным предметам.
4. Найти неуспевающих студентов.
5. Объединить две группы в одну.
6. Закрепление преподавателя по предмету за определенными группами, у которых преподаватель ведет предмет (Ввод информации в таблицу Study).
7. В вузы на очную форму обучения принимаются абитуриенты моложе 35 лет. Создайте триггер, позволяющий контролировать возраст студента при выполнении зачисления студента (ввода данных в таблицу Students).
8. Теоретически в БД можно ошибочно внести оценку студенту по предмету, который он не изучает вовсе. Задача: разработать триггер, контролирующий соответствие информации об оценках по предметам (таблицы Progress и Subject) с информацией о предметах изучаемых студентами(таблица Study).
9. Создать триггер, который бы журналировал действия определенного пользователя БД производимые над какой-либо таблицей в определенный промежуток времени.
10. Теоретически в БД можно ошибочно ввести стипендию студенту, который закрыл сессию с удовлетворительными оценками. Задача: разработать триггер, контролирующий оценки полученные студентом и наличие его стипендии.
11. Создать функцию, возвращающую количество студентов в конкретной группе.
12. Создать функцию, возвращающую количество грантников на конкретной специальности.
3 Методические указания к выполнению лабораторной работы
3.1 Использование процедур
Команды SQL (CREATE TABLE, INSERT, UPDATE, SELECT) дают возможность сообщить базе данных, что делать, но не как делать. Сообщить ядру базы данных, каким образом следует обрабатывать данные, можно посредством составления процедур. Хранимые процедуры – это набор операторов SQL, созданный для удобства использования в программах. Сохраненную процедуру использовать проще, чем каждый раз записывать весь набор входящих в нее операторов SQL. Сохраненные процедуры можно вкладывать одну в другую (уровень вложенности не может превышать 16).
Сохраненная процедура может возвращать значения, выполнять сравнения вводимых пользователем значений с заранее установленными условиями, вычислить какие-либо результаты и т.п.
Некоторые из преимуществ использования сохраненных процедур:
· операторы процедуры уже сохранены в базе данных;
· операторы процедуры уже проверены и находятся в готовом для использования виде;
· при использовании процедур результат получается быстрее;
· возможность сохранения процедур позволяет использовать модульное программирование;
· сохраненные процедуры могут вызывать другие процедуры;
· сохраненные процедуры могут вызываться другими программами.
В SQL Server процедуры создаются с помощью оператора следующего вида:
CREATE PROCEDURE имя_процедуры
[ [ ( ] @имя_параметра
ТИП_ДАННЫХ [(ДЛИНА) | (ТОЧНОСТЬ) [, МАСШТАБ ])
[=DEFAULT][OUTPUT] ]
[, @ИМЯ_ПАРАМЕТРА
ТИП_ДАННЫХ [(ДЛИНА) | (ТОЧНОСТЬ) [, МАСШТАБ ])
[=DEFAULT][OUTPUT] ]
[WITH RECOMPILE]
AS операторы SQL
Сохраненные процедуры используются следующим образом:
EXECUTE [ @ = ] имя_процедуры
[ [ @ имя_параметра =] значение |
[ @ имя_параметра = ] @ переменная [ OUTPUT ] ]
[WITH RECOMPILE]
Например, мы хотим увеличить на единицу значения номеров курсов (в поле Grup_COURSE) в таблице GRUPPA:
CREATE PROCEDURE new_course
AS UPDATE GRUPPA SET Grup_COURSE = Grup_COURSE +1
Проверим работу процедуры: EXEC new_course
SELECT *
FROM GRUPPA
Вернем таблицу GRUPPA в первоначальное состояние: CREATE PROCEDURE old_course AS UPDATE GRUPPA SET Grup_COURSE = Grup_COURSE -1
Проверим работу процедуры:
EXEC old_course
SELECT *
FROM GRUPPA Пример процедуры, которую можно использовать для добавления новых групп:
CREATE PROCEDURE new_gruppa
( @Grup_ID int ,
@Grup_NAME char (9),
@Grup_KOLSTUD int,
@Grup_COURSE int )
AS
INSERT INTO Gruppa
VALUES (@Grup_NAME, @Grup_KOLSTUD, @Grup_COURSE);
Столбец Grup_ID таблицы GRUPPA имеет тип identity, поэтому определяется только при вводе.
Работа этой процедуры проверяется следующим образом:
EXEC new_gruppa 18, 'ECT-04-5', 25, 1
Обратите внимание, что при вводе данных система автоматически присваивает полю Grup_ID очередное значение независимо от того, какое значение определил пользователь.
Простая процедура по использованию оператора SELECT:
CREATE PROCEDURE spisok_stud AS SELECT * from Students
Процедура для добавления преподавателя:
CREATE PROCEDURE new_teacher
( @Teach_ID bigint,
@Teach_FAM char (20), @Teach_IMA char (10),
@Teach_OTCH char (15),
@Teach_POSITION char (18),
@Teach_STEPEN char (12),
@Chair_ID integer)
AS
INSERT INTO Teacher
VALUES(@Teach_ID,@Teach_FAM,@Teach_IMA, @Teach_OTCH,@Teach_POSITION,@Teach_STEPEN, @Chair_ID)
Работа этой процедуры проверяется следующим образом:
EXEC new_teacher <список параметров>
Процедура для добавления нового предмета:
СREATE PROCEDURE new_subject
( @subj_name char(20),
@lection_hours int,
@practice_hours int,
@labor_hours int)
AS
declare @subj_id int
declare @total_hours int
IF not exists (select subj_name from subject
WHERE subj_name=@subj_name)
begin
SET @subj_id = (select max(subj_id) from subject)+1
SET @total_hours = @lection_hours + @practice_hours + @labor_hours
INSERT INTO subject
VALUES (@subj_id, @subj_name, @total_hours, @lection_hours, @practice_hours, @labor_hours)
end
Работа этой процедуры проверяется следующим образом:
EXEC new_subject '3',20,20,30
Данная процедура прежде чем добавить предмет проверяет существование такого предмета в таблице. Т.о., используя условные операторы, можно выполнять те или иные действия по проверке.
Процедура добавления нового судента:
CREATE PROCEDURE new_stud
(@stud_id int,
@stud_fam char(20),
@stud_ima char(20),
@stud_otch char(20),
@stud_date datetime,
@stud_addr char(20),
@grup_name char(20),
@grup_kurs int,
@stip smallmoney,
@spec char(20))
AS
declare @grup_id int;
declare @spec_id int;
declare @kolvo int;
INSERT INTO gruppa
VALUES(@grup_name,0,@grup_kurs);
INSERT INTO spec
VALUES(@spec);
SELECT @grup_id=(SELECT grup_id FROM gruppa WHERE grup_name=@grup_name);
SELECT @spec_id=(SELECT id_spec FROM spec WHERE nazv=@spec);
INSERT INTO students
VALUES(@stud_id,@stud_fam,@stud_ima,@stud_otch,@stud_date,@stud_addr,@grup_id,@stud_id,@stip,@spec_id);
SELECT @kolvo=(select count(stud_id) from students where grup_id=@grup_id);
UPDATE gruppa
SET grup_kolstud=@kolvo WHERE grup_id=@grup_id
Работа этой процедуры проверяется следующим образом:
EXEC new_stud 65785,'Иванов','Иван','Иванович', '08/05/89', 'Almaty', 'BVT-77-7',2,1000,'ВЧиПО'
3.2 Функции
Для расширения возможностей Transact-SQL по обработке данных в SQL Server реализован ряд встроенных функций.
Существующее многообразие встроенных функций SQL Server можно условно разделить на несколько категорий:
- математические функции;
- строковые функции;
- функции для работы с датами;
- статистические функции;
- криптографические функции;
- ранжирующие функции;
- функции приведения типов;
- системные функции.
Каждая функция имеет ряд свойств, определяющих возможность использования ее в вычисляемых столбцах.
Функция представляет собой именованный блок кода, возвращающий по результатам своего выполнения некоторое значение. Возвращаемое значение может быть как величиной, так и набором строк. Функции могут участвовать в выражениях, вызываться в теле хранимых процедур, а также в теле других функций.
Помимо встроенных функций, присутствующих в системе по умолчанию, пользователи могут создавать собственные функции. Поскольку их можно включать в любое выражение, пользовательские функции представляют собой удобный и гибкий механизм обработки данных.
Для создания функции следует использовать оператор CREATE FUNCTION следующего формата:
CREATE FUNCTION имя_функции
([ < @имя_параметра> AS <тип_данных> [=<значение_по_умолчанию>]])
RETURNS <возвращаемый_тип_данных>
AS
операторы SQL
Функция определения возраста студента (например, мы ходим узнать возраст студента по id_stud):
CREATE FUNCTION GetStudentAge(@uid int)
RETURNS varchar(200)
AS
BEGIN
declare @age datetime
SELECT @age=Stud_DATE
FROM Students WHERE Stud_ID=@uid
SET @age=GETDATE()-@age;
RETURN convert(varchar(20),YEAR(@age)-1900)+' лет, '+convert(varchar(20),MONTH(@age)-1)+' месяцев и '+convert(varchar(20),DAY(@age)-1)+' дней'
END
Данную пользовательскую функцию можно использовать в следующем запросе:
SELECT Stud_FAM as [Фамилия], Stud_IMA as [Имя], Stud_DATE as [Дата рождения], dbo.GetStudentAge(Stud_ID) as [Возраст]
FROM Students
ORDER BY Stud_DATE ASC
Т.о., создавая пользовательские функции, можно значительно упростить сложность запросов.
3.3 Триггеры
Триггер – это откомпилированная процедура, используемая для выполнения действий, инициируемых происходящими в базе данных событиями. Триггер представляет собой сохраненную в базе данных процедуру, которая запускается тогда, когда в отношении таблицы выполняются определенные действия. Триггер может выполняться до или после операторов INSERT, UPDATE или DELETE. Наиболее распространенное применение триггеров – это проверка сложных критериев в базе данных. Триггер - особый инструмент SQL-сервера, поддерживающий целостность данных в БД .
Рассмотрим простой пример. Стипендия студента не может превышать 15000. Определим триггер, который не позволял бы вводить сумму стипендии больше 15000. Для создания триггера с помощью утилиты SQL Server Enterprise Manager необходимо выбрать таблицу Progress в списке объектов базы данных, после чего выполнить команду контекстного меню Аll tasks (Все задачи) - Manage Triggers. Эти действия приведут к открытию диалогового окна свойств триггера.
CREATE TRIGGER tri_stip
ON stud
FOR INSERT, UPDATE
AS
/*описываются локальные переменные*/
DECLARE @stip smallmoney
/* определяется информация о вставляемых записях*/
SELECT @stip = U.stud_stip
FROM Inserted U
IF @stip >15000
BEGIN
/*Команда ROLLBACK используется для того, чтобы отменить модификацию данных в случае, если база заблокирована*/
ROLLBACK TRAN
RAISERROR ('Стипендия студента не может превышать 15000', 16,10)
END
Определим триггер tri_ins_progress для таблицы Progress, который будет запускаться каждый раз, когда запись вставляется в таблицу Progress или модифицируется. Если экзамен или зачет сданы не в срок (например, после 15-го числа месяца), то запись не принимается:
CREATE TRIGGER tri_ins_progress
ON Progress
FOR INSERT, UPDATE
AS
/*описываются локальные переменные*/
DECLARE @nDayOfMonth TINYINT
/* определяется информация о вставляемых записях*/
SELECT @nDayOfMonth = DATEPART (Day, I.Pr_DATE)
FROM Progress P, Inserted I
WHERE P.Stud_ID = I.Stud_ID AND P.Ocenka = I.Ocenka
/*проверяется условие вставки записи*/
/*и при необходимости сообщается об ошибке*/
IF @ nDayOfMonth >15
BEGIN
/*Команда ROLLBACK используется для того, чтобы отменить
модификацию данных в случае, если база заблокирована*/
ROLLBACK TRAN
RAISERROR ('Вводить оценки, полученные до 15-го числа', 16,10)
END
Попробуйте ввести в таблицу Progress данные об оценках, полученных
студентами позже 15-го числа.
Триггер можно удалить следующим образом: DROP TRIGGER имя_триггера
или из контекстного меню Аll tasks (Все задачи) - Manage Triggers выбором имени триггера из списка.
Триггер на добавление студента:
CREATE TRIGGER tr_ins_stud
ON Students
FOR INSERT
AS
DECLARE @grup integer
SELECT @grup=I.Grup_ID
FROM Inserted I
UPDATE Gruppa
SET Grup_KOLSTUD = Grup_KOLSTUD+1
WHERE Gruppa.Grup_ID=@grup
Пусть нам необходимо знать, кто (пользователь) и когда производил изменения оценок студентов. Для этого необходимо создать таблицу журнала и собственно тригер.
Создайте таблицу для журналирования изменений
CREATE TABLE journ (
mod_oper CHAR(20), /* Тип производимой операции */
mod_datetime DATEtime, /*Дата изменеия */
mod_user VARCHAR(30), /*Пользователь БД */
mod_id INTEGEr, /* id студента чья оценка была изменена*/
mod_ocen integer /* Измененая оценка*/
old_ocen integer
)
Тригер, регистрирующий изменения оценки:
CREATE TRIGGER treg
ON Progress
FOR Update
AS
DECLARE @id int, @ocen int, @old_ocen int
SELECT @old_ocen=P.ocenka,@id = P.stud_id , @ocen = U.ocenka
FROM Progress P, Inserted U
INSERT INTO journ VALUES('Обновлена',Current_timestamp,Current_USER,@id, @ocen,@old_ocen);
Данный тригер будет вносить информацию о изменениях оценок студентов.
Контрольные вопросы
1. Может ли сохраненная процедура вызывать другую сохраненную процедуру?
2. В чем преимущества использования процедур?
3. В чем преимущества использования функций?
4. Каковы различия между процедурами и функциями?
5. Когда выполняются триггеры – до или после выполнения команд INSERT, UPDATE и DELETE?
6. Можно ли изменить триггер?
Лабораторная работа № 8. Права пользователей. Разработка системы пользователей базы данных
1 Цель работы: научить студентов разрабатывать систему безопасности СУБД и базы данных скриптом и в графической среде.
2 Задание на лабораторную работу
Выполните упражнения, приведенные в п.3.1-3.7.
Выполните следующие задания:
1. Для работы с базой данных будут использованы две роли – studentABD_XX и teacherABD_XX (XX – номер компьютера, за которым сидит исполнитель работы). Назначить роли teacherABD_XX полный доступ ко всем объектам базы данных на просмотр таблиц и выполнение запросов SELECT, но не на создание новых таблиц и не на изменение данных в таблицах. Назначить роли studentABD_XX доступ владельца базы данных, т.е. полный доступ на чтение и на изменение любых объектов базы данных. Составьте план выполнения необходимых хранимых процедур для того, чтобы выполнить такие действия, на бумаге.
2. Пусть к данной базе данных будут иметь доступ два пользователя роли teacherABD_XX (teachABD1_XX, teachABD2_XX) и один пользователь роли studentABD_XX (studABD1_XX). Составьте план выполнения необходимых хранимых процедур для того, чтобы выполнить такие действия, на бумаге.
3. Задайте от одной до трех учетных записей для доступа к серверу. Составьте план выполнения необходимых хранимых процедур для того, чтобы выполнить такие действия, на бумаге.
4. Откройте CIS в приложении Borland SQL Explorer.
5. В окне запросов ввести по очереди все запросы на создание системы пользователей и учетных записей для доступа к БД. Выполнить эти запросы.
3 Методические указания к выполнению лабораторной работы
3.1 Требования к программному обеспечению:
СУБД MS SQL Server должна иметь запись о пользователе user (пароль-user) с привилегиями db_owner для всех объектов в рабочем пространстве CIS.
3.2 Система безопасности СУБД
Система безопасности СУБД основывается на таких понятиях как учетная запись, роль, группа, пользователь.
Каждый пользователь проходит два этапа проверки системы безопасности при попытке доступа к данным:
- этап 1 – аутентификация;
- этап 2 – получение доступа к данным.
Первый этап относится к уровню работы всего сервера СУБД. На первом этапе пользователь идентифицирует себя с помощью логического имени (login) и пароля (password).
Логическое имя и пароль хранятся на сервере СУБД в виде учетной записи (account).
Если данные были введены правильно, то считается, что процедура аутентификации пройдена, и данный сервер СУБД разрешает попытку доступа к конкретной базе данных.
Однако сама по себе аутентификация не дает пользователю права доступа к каким бы то ни было данным. Для получения доступа к данным необходимо, чтобы учетной записи пользователя соответствовал некоторый пользователь базы данных (database user).
Пользователь базы данных – совокупность разрешений и запретов на работу с данными в конкретной базе данных.
На втором этапе учетная запись пользователя отображается в пользователя базы данных и получает все привилегии, соответствующие этому пользователю базы данных. Второй этап задействует систему безопасности конкретной базы данных, а не всего сервера СУБД.
В разных базах данных одной и той же учетной записи могут соответствовать одинаковые или разные имена пользователя базы данных с разными правами доступа.
В том случае, когда учетная запись пользователя не отображается в пользователя базы данных, клиент все же может получить доступ к базе данных под гостевым именем guest (если оно не запрещено администратором БД). Гостевой вход позволяет минимальный доступ к данным только в режиме чтения.
Пользователи баз данных могут объединяться в роли (иногда – группы) для упрощения управления системой безопасности.
Роли базы данных объединяют нескольких пользователей в административную единицу и позволяют назначать права доступа к объектам базы данных для роли, наделяя этими правами всех участников этой роли.
Различают пользовательские и встроенные роли. Встроенные роли создаются автоматически при установке сервера СУБД (и не могут меняться). Различают встроенные роли уровня СУБД и уровня конкретной базы данных. Так, например, в SQL Server 2000 есть такие роли сервера:
|
Встроенная роль сервера |
Назначение |
|
Sysadmin |
Может выполнять любые действия в SQL Server |
|
Serveradmin |
Выполняет конфигурирование и выключение сервера |
|
Setupadmin |
Управляет связанными серверами и процедурами, автоматически запускающимися при запуске SQL Server |
|
Securityadmin |
Управляет учетными записями и правами на создание базы данных, также может читать журнал ошибок. |
|
Processadmin |
Управляет процессами, запущенными в SQL Server |
|
Dbcreator |
Может создавать и модифицировать базы данных |
|
Diskadmin |
Управляет файлами SQL Server |
|
Bukladmin |
Может вставлять данные с использованием средств массового копирования, не имея непосредственного доступа в таблицам. |
SQL Server 2000 поддерживает такие встроенные роли уровня базы данных:
|
Встроенная роль базы данных |
Назначение |
|
Db_owner |
Имеет все права в базе данных |
|
Db_accessadmin |
Может добавлять или удалять пользователей |
|
Db_securityadmin |
Управляет всеми разрешениями, объектами, ролями и членами ролей |
|
Db_ddladmin |
Может выполнять любые команды DDL, кроме GRANT, DENY, REVOKE |
|
Db_backupoperator |
Может выполнять команды DBCC, CHECKPOINT, BACKUP |
|
Db_datareader |
Может просматривать любые данные в любой таблице |
|
Db_datawriter |
Может модифицировать любые данные в любой таблице |
|
Db_denydatareader |
Запрещается просматривать данные в любой таблице |
|
Db_denydatawriter |
Запрещается модифицировать данные в любой таблице |
Кроме указанных ролей, существует еще одна, неудаляемая роль – public. Участниками этой роли являются все пользователи, имеющие доступ к базе данных. Нельзя явно указать участников этой роли, т.к. все пользователи уже включены в нее.
3.2.1 Манипулирование элементами системы безопасности СУБД
3.2.1.1 Создание учетной записи
Для создания учетной записи в MS SQL Server 2000 используется системная хранимая процедура sp_addlogin:
Ее формат таков:
sp_addlogin [@loginname=] login
[, [@passwd=] password]
[, [@defdb=] database]
[, [@deflanguage=] language]
[, [@sid=] SID]
[, [@encryptopt=] encryption_option]
где:
login - логическое имя (login);
password - пароль, который будет ассоциироваться с данной учетной записью;
database - база данных по умолчанию. Сразу же после установления соединения с сервером пользователь будет работать в этой базе данных;
language - язык сообщений, выдаваемых сервером СУБД пользователю;
SID - двоичное число, которое будет являться идентификатором безопасности создаваемой учетной записи. Используя эту возможность, можно создавать на разных серверах СУБД учетные записи с одинаковыми идентификаторами безопасности;
encryption_option определяет, будет ли шифроваться пароль данной учетной записи. По умолчанию, пароль шифруется.
Пример. Добавить учетную запись teacher к базе данных education.
EXEC sp_addlogin teacher, 123, education
3.2.1.2 Создание пользователя базы данных
Для создания пользователя базы данных в MS SQL Server 2000 используется системная хранимая процедура sp_grantdbaccess (ранее - sp_adduser).
Ее формат таков:
sp_grantdbaccess [@loginame=] login
[,[@name_in_db=] user [OUTPUT]]
Использование параметра OUTPUT заставляет хранимую процедуру поместить значение параметра user созданного пользователя в некоторую переменную, для дальнейшей обработки.
Формат процедуры sp_adduser:
sp_adduser [@loginname=] login
[, [@name_in_db=] user]
[, [@grpname=] role]
где:
login - логическое имя (login), которое необходимо связать с создаваемым пользователем;
user - имя создаваемого пользователя базы данных, с которым будет ассоциироваться данная учетная запись. В базе данных не должно быть пользователя с таким именем;
role - роль, в которую данный пользователь будет включен.
Пример. Добавить нового пользователя teacher_adb к базе данных education.
EXEC sp_adduser teacher, teacher_adb, db_owner
3.2.1.3 Создание роли базы данных
Для создания роли базы данных в MS SQL Server 2000 используется системная хранимая процедура sp_addrole:
Ее формат таков:
sp_addrole [@rolename=] role
[, [@ownername=] owner]
где:
role - имя создаваемой роли. Должно быть уникальным в пределах БД;
owner - имя владельца роли. Владельцем может быть только роль или пользователь из этой базы данных. По умолчанию, владелец – dbo.
Эта процедура не может быть запущена как часть транзакции, определенной пользователем. Исполнять эту процедуру могут только участники роли сервера sysadmin, либо участники ролей db_securityadmin, db_owner.
Пример. Добавление роли Managers.
EXEC sp_addrole Managers
3.2.1.4 Добавление пользователя в роль
Используется процедура sp_addrolemember вида:
sp_addrolemember [@rolename=] role,
[@membername=] security_account]
где:
role - имя роли, в которую добавляется пользователь;
security_account – пользователь базы данных.
Пример. Добавление пользователя teacher_abd в роль Managers.
EXEC sp_addrolemember Managers, teacher_abd
3.2.1.5 Удаление ролей, учетных записей
Перечислим в той очередности, которая разрешается в SQL Server 2000, процедуры удаления пользователей и ролей из базы данных.
Процедура sp_droprolemember вычеркивает участника из роли:
sp_droprolemember [@rolename = ] role ,
[@membername = ] security_account
Процедура sp_droprole удаляет роль (в том случае, если предварительно из роли были удалены все участники):
sp_droprole [@rolename=] role
Процедура sp_revokedbaccess (и ее устаревший аналог sp_dropuser) удаляет пользователя базы данных:
sp_revokedbaccess [@name_in_db =] name
Процедура sp_droplogin удаляет учетную запись из реестра сервера СУБД:
sp_droplogin [@loginame=] login
3.2.1.6 Просмотр информации об учетных записях, ролях, привилегиях
Для просмотра информации о текущих назначениях пользователей, ролей используются хранимые процедуры sp_helpuser, sp_helplogins, sp_helprole, sp_helprolemember.
Параметры их вызовов таковы:
sp_helpuser [[@name_in_db=] security_account]
sp_helplogins [[@LoginNamePattern=] login]
sp_helprole [[@rolename=] role]
sp_helprolemember [[@rolename=] role]
Контрольные вопросы
1. Как создать пользователя базы данных?
2. В чем преимущества учетной записи?
3. В чем преимущества использования системы безопасности СУБД?
4. Каковы понятия системы безопасности СУБД?
5. Какие бывают встроенные роли сервера СУБД?
6. Какие бывают встроенные роли базы данных?
Лабораторная работа № 9. Разработка клиентских приложений
1 Цель работы: научить студентов разрабатывать клиентское приложение
для базы данных.
2 Задание на самостоятельную работу
Задание на самостоятельную работу выдается преподавателем.
2.1 Проанализируйте данные выбранной (по варианту) предметной области. Определите информационные потребности и представления данных базы данных с точки зрения определенной группы пользователей. Сформулируйте возможные вопросы к моделируемой области.
2.2 Спроектируйте информационно-логическую модель для указанной предметной области, позволяющую ответить на широкий круг вопросов моделируемой области: выделите объектные множества и возможные связи между ними. Отразите объекты и отношения между ними на концептуальной схеме.
2.3 Преобразуйте созданную концептуальную модель в реляционную. 2.4 Опишите среду разработки базы данных. 2.5 Создайте таблицы базы данных. Заполните их данными. 2.6 Выполните поиск информации в вашей базе данных, чтобы получить ответы на поставленные вопросы. В этом разделе необходимо продемонстрировать по возможности большинство из изученных средств поиска.
2.7 Разработайте приложение в Delphi для доступа к данным базы данных и для получения результатов разнообразных запросов.
2.8 Оформите пояснительную записку к самостоятельной работе. В пояснительную записку входит:
- описание предметной области с точки зрения конкретных пользователей;
- концептуальная модель;
- реляционная схема базы данных;
- описаны все команды, использованные для реализации проекта и работы с базой данных: создание объектов, формирование базы данных (заполнение таблиц данными); выполнение запросов к базе данных; результаты выполнения этих команд;
- описание возможностей приложения в Delphi с распечаткой текстов модулей.
2.9 Студент сдает преподавателю пояснительную записку и выполненную работу (на дискете).
2.10 После проверки пояснительной записки преподавателем студент допускается к защите своего проекта. Защита работы предусматривает демонстрацию работы приложения, ответы на контрольные вопросы.
3 Методические указания по использованию технологии ADO при создании клиентского приложения.
ADO (Active Data Objects) - это высокоуровневый компонент технологии доступа к данным от Microsoft. (т.н. MDAC - Microsoft Data Access Components). На самом деле ADO является частью более крупномасштабной технологии под названием Microsoft Data Access Components (MDAC). Термин MDAC является общим обозначением для всех разработанных компанией Microsoft технологий, связанных с БД. К этому набору относятся ADO, OLE DB, ODBC и RDS (Remote Data Services).
В процессе установки MDAC в системе автоматически устанавливаются провайдеры:
· ODBC OLE DB используется для обратной совместимости с ODBC. Подробнее ознакомившись с работой ADO, вы узнаете об ограничениях, присущих этому провайдеру.
· Jet OLE DB — поддержка MS Access и других локальных баз данных. Мы вернемся к рассмотрению этих провайдеров далее.
· SQL Server обеспечивает взаимодействие с SQL Server 7, SQL Server 2000 и Microsoft Database Engine (MSDE). MSDE — это упрощенная версия SQL Server, в которой отсутствует большинство инструментов, а кроме того, добавлен специальный код, который намеренно снижает производительность в случае, если к базе данных одновременно подключаются более пяти пользователей. К преимуществам MSDE следует отнести то, что этот механизм распространяется бесплатно и полностью совместим с SQL Server.
· OLE DB для OLAP может использоваться напрямую, однако чаще обращение к нему осуществляется через ADO Multi-Dimentional (ADOMD). ADOMD — это дополнительная технология ADO, специально разработанная для Online Analytical Processing (OLAP). Если ранее вы работали с Delphi Decision Cube, Excel Pivot Tables или Access Cross Tabs, значит, вы работали с одной из форм OLAP. Помимо уже перечисленных здесь провайдеров, компания Microsoft осуществляет поддержку некоторых других провайдеров OLE DB, которые входят в состав других продуктов или в состав SDK.
· Active Directory Services OLE DB входит в состав ADSI SDK; AS/400 OLE DB и VSAM OLE DB входят в состав SNA Server; Exchange OLE DB входит в состав Microsoft Exchange 2000.
· Indexing Service OLE DB входит в состав Microsoft Indexing Service — внутренний механизм Windows, ускоряющий поиск информации в файлах при помощи построения каталога с файловой информацией. Служба индексирования Indexing Service интегрирована в IIS и часто используется для индексирования веб-узлов.
· Internet Publishing OLE DB позволяет разработчикам манипулировать каталогами и файлами с использованием HTTP.
· Существует также категория провайдеров OLE DB, которые называются провайдерами обслуживания (service providers). Как следует из имени, эти провайдеры обеспечивают обслуживание других провайдеров OLE DB и зачастую активизируются автоматически без участия программиста. Например, служба Cursor Service активизируется в случае, если вы создаете курсор на стороне клиента, а провайдер Persistent Recordset активизируется в случае, если вы собираетесь сохранить данные на локальном диске.
Четыре компонента наборов данных (ADODataSet, ADOTable, ADOQuery и ADOStoredProc) фактически полностью реализованы общим для них базовым классом TCustomADODataSet. Этот компонент несет ответственность за выполнение большинства функций, присущих набору данных. Производные компоненты являются тонкими оболочками, которые делают доступными для внешнего мира те или иные возможности базового компонента. Таким образом, компоненты обладают множеством общих черт. Компоненты ADOTable, ADOQuery и ADOStoredProc предназначены для упрощения адаптации кода, ориентированного на BDE. Однако следует иметь в виду, что эти компоненты нельзя считать полностью идентичными эквивалентами аналогичных компонентов BDE. Различия обязательно проявят себя при разработке фактически любого приложения за исключением, может быть, самых тривиальных. В качестве основного компонента при разработке новых программ следует считать компонент ADODataSet, так как, во-первых, этот компонент является достаточно удобным, а во-вторых, его интерфейс сходен с интерфейсом ADO Recordset.
3.1 Реализация просмотра таблицы в клиентском приложении
Запустите Delphi CG 2009. Необходимы следующие компоненты из палитры:
ADOConnection, ADOTable, DataSource и DBGrid.
Рисунок 9.1 – Форма приложения
Определим настройки подключения компонента ADOConnection к нашей базе данных.
Щелкните по свойству ConnectionString компонента ADOConnection.
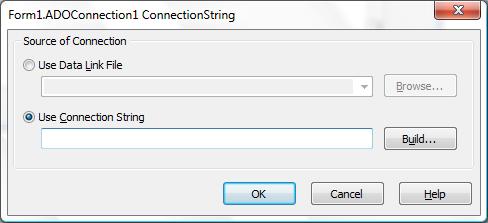
Рисунок 9.2 – Настройка соединения с БД
В открывшемся окне щелкните по кнопке Build… Во вкладке Поставщик данных выберите Microsoft OLE DB Provider for SQL Server (Рисунок 9.3).
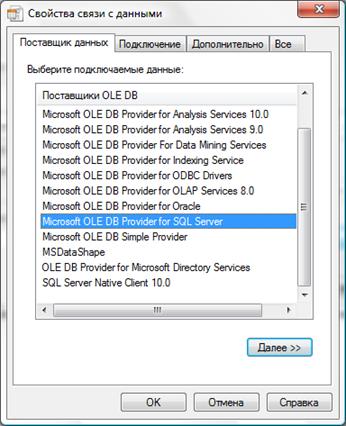
Рисунок 9.3 – Настройка поставщика данных
В настройках подключения выберите необходимую базу данных и в качестве авторизации учетные сведения Windows NT (Рисунок 9.4). Активируем соединение.
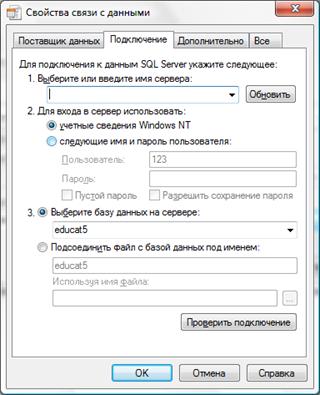
Рисунок 9.4 – Настройка подключения к базе данных
Далее необходимо настроить свойства компонента ADOTable. В качестве свойства Connection установить выше настроенное соединение, а также выбрать таблицу данные которой мы хотим получить.
Затем с помощью компонента DataSource связываем таблицу (DBGrid) и данные из ADOTable.
Ставим свойство Active компонента ADOTable в значение true. В результате получим данные необходимой таблицы (Рисунок 9.5).
Рисунок 9.5 – Данные считанные с таблицы “Subject” базы данных учебного процесса.
3.2 Реализация запроса к базе данных
Необходимы следующие компоненты из палитры:
- ADOConnection, ADOQuery, DataSource и DBGrid.
- ADOConnection настраивается аналогичным образом (пункт 3.1). В качестве свойства Connection компонента ADOQuery ставится ADOConnection, предварительно настроенный.
В качестве свойства SQL компонента ADOQuery вводится запрос (Рисунок 9.6).
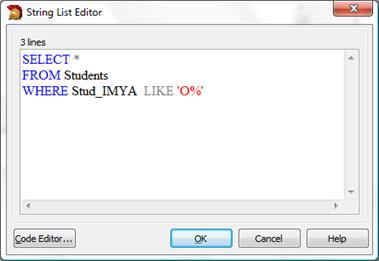
Рисунок 9.6 – Запрос в базу данных
Далее активируем запрос (Active = true). В результате в таблицу вернуться данные согласно запросу.
Список литературы
1. Хансен Г., Хансен Д. Базы данных: разработка и управление. – М.: ЗАО «Издательство БИНОМ», 1999.
2. Питер Роб, Карлос Коронел Системы баз данных: проектирование, реализация и управление, 5-е издание, – BHV Санкт-Петербург, 2004. -1040 с.,
3. Кренке Д. Теория и практика построения баз данных. Изд.9 – Питер, 2005.
4. MICROSOFT SQL SERVER 2005. Реализация и обслуживание. Учебный курс Microsoft/ Пер. с английского – М. «Русская редакция», Спб.: «Питер», 2007. – 768 стр. ил.
5. Мамаев Е. MS SQL Server 2000. Проектирование и реализация баз данных. Сертификационный экзамен. - BHV, СПб. 2004г., 416с
6. Плю Р., Стефенс Р., Райан К. Освой самостоятельно SQL за 24 часа. – М.: Издательский дом «Вильямс», 2000.
7. Кандзюба С.П., Громов В.Н. Delphi 6/7. Базы данных и приложения. – СПб: ООО «ДиаСофт», 2002.
8. Бобровский С. Delphi 5: учебный курс. – СПб: Издательство «Питер», 2000.
Лабораторная работа № 1. Реализация структуры базы данных в MS Visio
Лабораторная работа № 2. Реализация модели базы данных в среде СУБД MS SQL Server
Лабораторная работа № 3 Манипуляция над данными
Лабораторная работа № 4. Простые запросы к базе данных.
Лабораторная работа № 5 Создание сложных запросов
Лабораторная работа № 6. Представления
Лабораторная работа № 7. Хранимые процедуры, функции и триггеры
Лабораторная работа № 8. Права пользователей. Разработка системы пользователей базы данных