Алматинский институт энергетики и связи
Кафедра инженерной кибернетики
ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ
Конпект лекций для студентов всех форм обучения
специальности 5В0702 – Автоматизация и управление
Алматы 2010
СОСТАВИТЕЛЬ: Ибраева Л.К. Проектирование баз данных. Конспект лекций для студентов всех форм обучения специальности 5В0702 – Автоматизация и управление. – Алматы: АИЭС, 2010 – 63 с.
Конспект лекций составлен в соответствии с рабочей программой дисциплины «Проектирование баз данных» для студентов всех форм обучения специальности 5В0702 – Автоматизация и управление и содержит 15 лекций. Конспект предназначается в помощь студентам при изучении теоретического материала и для подготовки к экзаменам, лабораторным занятиям, выполнению расчетно-графических работ.
Введение
Развитие вычислительной техники оказало значительное влияние на многие стороны жизни общества. За последние десятилетия значительно расширились сферы применения вычислительной техники и соответствующий рост ее влияния на повседневную жизнь. Автоматизированная система, организующая данные и выдающая информацию представляет собой информационную систему. Одна из наиболее сложных и ответственных задач, связанных с созданием информационной системы - проектирование баз данных. В результате её решения должны быть определены содержание базы данных, эффективный для всех её будущих пользователей способ организации данных и инструментальные средства управления данными.
Процесс проектирования базы данных представляет собой последовательность переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели. В общем случае можно выделить следующие этапы проектирования: системный анализ и словесное описание информационных объектов предметной области; проектирование концептуальной модели предметной области — частично формализованное описание объектов предметной области в терминах некоторой семантической модели; выбор конкретной системы управления базами данных; описание базы данных в терминах выбранной системы и, наконец, физическое проектирование базы данных, то есть выбор эффективного размещения базы данных на внешних носителях для обеспечения наиболее эффективной работы приложения.
Современная волна информационных технологий управления данными основывается на использовании систем управления реляционными базами данных. Все языки манипулирования данными, созданные до появления реляционных баз данных были ориентированы на операции с данными, представленными в виде логических записей файлов. Это требовало от пользователей детального знания организации хранения данных и достаточных усилий для указания не только того, какие данные нужны, но и того, где они размещены, и как шаг за шагом получить их. Современные языки баз данных ориентированы в большей степени на конечный результат обработки данных, чем на процедуру этой обработки.
В конспектах лекций приводятся основные сведения о развитии технологии баз данных; трехуровневая архитектура систем баз данных; основные понятия концептуального и реляционного подхода к проектированию баз данных; принципы нормализации базы данных.
1 Лекция. Развитие технологии баз данных
Содержание лекции: основные понятия информационных систем.
Цель лекции: изучить историю развития технологии баз данных, методы обработки данных.
1.1 Информационные системы
Информационные системы (ИС) – функционирующий на основе ЭВМ и других технических средств информатики комплекс, обеспечивающий сбор, хранение, актуализацию и обработку информации в целях поддержки какого- либо вида деятельности. Другими словами: информационная система – автоматизированная система, организующая данные и выдающая информацию.
Информационная система представляет собой программно-аппаратный комплекс, обеспечивающий выполнение следующих функций:
- надежное хранение информации в памяти компьютера;
- выполнение специфических для данного приложения преобразований информации и вычислений;
- предоставление пользователям удобного и легко осваиваемого интерфейса.
К числу основных компонентов такой системы относятся средства программного обеспечения, средства компьютеров или сети компьютеров, лингвистические средства интерфейсов пользователей, собственно информационные ресурсы, которые хранит и обрабатывает система.
В этом контексте мы различаем понятия данные и информация. Под данными будем подразумевать разрозненные факты, например: Корпорация Microsoft находится в США. Информация же – это обработанные данные. Информация полезна руководителям в вопросах принятия решений.
Серьезность влияния, оказываемого информацией на планирование и принятие решений, привела к пониманию того, что информация – ресурс, обладающий определенной ценностью, и, следовательно, нуждается в упорядочении и управлении. Если менеджеры хорошо информированы, то они с большей вероятностью будут принимать своевременные решения. Появившиеся информационные системы, использующие базы данных, стали основополагающим средством снабжения менеджеров точной и своевременной информацией.
1.2 Файлы и файловые системы
Развитие технологии баз данных явилось результатом развития в течение нескольких десятилетий способов обработки данных и управления информацией. Обработка данных развивалась от примитивных методов 50-х годов прошлого века к сложным интегрированным системам сегодняшнего дня. Первые системы обработки данных выполняли канцелярскую работу, сокращая лишь количество бумаг. Современные системы перешли к накоплению и управлению информацией. Сегодня наиболее важная функция систем управления базами данных – служить основой информационных систем корпоративного пользования.
В истории вычислительной техники можно проследить развитие двух основных областей ее использования. Первая область — применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Развитие этой области способствовало интенсификации методов численного решения сложных математических задач, появлению языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ. Характерной особенностью данной области применения вычислительной техники является наличие сложных алгоритмов обработки, которые применяются к простым по структуре данным, объем которых сравнительно невелик.
Вторая область, которая непосредственно относится к нашей теме, — это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Обычно такие системы имеют дело с большими объемами информации, имеющей достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы, автоматизированные системы управления предприятиями, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т. д.
Важным шагом в развитии именно информационных систем явился переход к использованию централизованных систем управления файлами. С точки зрения прикладной программы, файл — это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Правила именования файлов, способ доступа к данным, хранящимся в файле, и структура этих данных зависят от конкретной системы управления файлами и, возможно, от типа файла. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса во внешней памяти и обеспечение доступа к данным. Пользователи видят файл как линейную последовательность записей и могут выполнить над ним ряд стандартных операций: создать файл (требуемого типа и размера); открыть ранее созданный файл; прочитать из файла некоторую запись (текущую, следующую, предыдущую, первую, последнюю); записать в файл на место текущей записи новую, добавить новую запись в конец файла.
В разных файловых системах эти операции могли несколько отличаться, но общий смысл их был именно таким. Главное, что следует отметить, это то, что структура записи файла была известна только программе, которая с ним работала, система управления файлами не знала ее. И поэтому для того, чтобы извлечь некоторую информацию из файла, необходимо было точно знать структуру записи файла с точностью до бита. Каждая программа, работающая с файлом, должна была иметь у себя внутри структуру данных, соответствующую структуре этого файла. Поэтому при изменении структуры файла требовалось изменять структуру программы, а это требовало новой компиляции, то есть процесса перевода программы в исполняемые машинные коды. Такая ситуация характеризовалась как зависимость программ от данных. Для информационных систем характерным является наличие большого числа различных пользователей (программ), каждый из которых имеет свои специфические алгоритмы обработки информации, хранящейся в одних и тех же файлах. Изменение структуры файла, которое было необходимо для одной программы, требовало исправления и перекомпиляции и дополнительной отладки всех остальных программ, работающих с этим же файлом. Это было первым существенным недостатком файловых систем, который явился толчком к созданию новых систем хранения и управления информацией.
Первые коммерческие компьютерные системы использовались в основном для ведения бухгалтерии. Затраты ручного труда на эту работу столь велики, что стоимость компьютерных систем быстро окупалась. Так как эти системы выполняли обычные работы с документами, они были названы системами обработки данных. Компьютерные файлы соответствовали папкам для бумаг. Эти файлы допускали только последовательный доступ. Это означает, что каждая запись в файле может быть прочитана только после того, как прочитаны все предшествующие ей записи. В 60-е годы, когда хранение информации на диске обходилось относительно дорого, большинство файлов хранилось на ленте, и записи извлекались и обрабатывались последовательно.
Вторая область использования вычислительной техники возникла несколько позже первой. Это связано с тем, что на заре вычислительной техники возможности компьютеров по хранению информации были очень ограниченными. Говорить о надежном и долговременном хранении информации можно только при наличии запоминающих устройств, сохраняющих информацию после выключения электрического питания. Оперативная (основная) память компьютеров этим свойством обычно не обладает. В первых компьютерах использовались два вида устройств внешней памяти — магнитные ленты и барабаны. Емкость магнитных лент была достаточно велика, но по своей физической природе они обеспечивали последовательный доступ к данным. Магнитные же барабаны (они ближе всего к современным магнитным дискам с фиксированными головками) давали возможность произвольного доступа к данным, но имели ограниченный объем хранимой информации.
Эти ограничения не являлись слишком существенными для чисто численных расчетов. Даже если программа должна обработать (или произвести) большой объем информации, при программировании можно продумать расположение этой информации во внешней памяти (например, на последовательной магнитной ленте), обеспечивающее эффективное выполнение этой программы. Однако в информационных системах совокупность взаимосвязанных информационных объектов фактически отражает модель объектов реального мира. А потребность пользователей в информации, адекватно отражающей состояние реальных объектов, требует сравнительно быстрой реакции системы на их запросы. И в этом случае наличие сравнительно медленных устройств хранения данных, к которым относятся магнитные ленты и барабаны, было недостаточным.
Можно предположить, что именно требования нечисловых приложений вызвали появление съемных магнитных дисков с подвижными головками, что явилось революцией в истории вычислительной техники. Эти устройства внешней памяти обладали существенно большей емкостью, чем магнитные барабаны, обеспечивали удовлетворительную скорость доступа к данным в режиме произвольной выборки, а возможность смены дискового пакета на устройстве позволяла иметь практически неограниченный архив данных.
С появлением магнитных дисков началась история систем управления данными во внешней памяти. Появилась необходимость произвольного доступа к записям в файле. Произвольный доступ к данным – возможность напрямую обращаться к конкретной записи без предварительной сортировки или последовательного чтения всех записей.
До этого каждая прикладная программа, которой требовалось хранить данные во внешней памяти, сама определяла расположение каждой порции данных на магнитной ленте или барабане и выполняла обмены между оперативной памятью и устройствами внешней памяти с помощью программно-аппаратных средств низкого уровня (машинных команд или вызовов соответствующих программ операционной системы). Такой режим работы не позволяет или очень затрудняет поддержание на одном внешнем носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации данных во внешней памяти.
В шестидесятые годы прошлого века широко распространились индексные файлы. Эти файлы позволяют выбрать одно или несколько полей для точного задания того, какую запись извлекать. Эти поля были названы ключами.
Ключ – поля данных, однозначно определяющих запись в файле. Индексные файлы можно представить как файлы, состоящие из двух частей. Это не обязательно физическое совмещение этих двух частей в одном файле, в большинстве случаев индексная область образует отдельный индексный файл, а основная область образует файл, для которого создается индекс.
В зависимости от организации индексной и основной областей различают два типа файлов: с плотным индексом и с неплотным индексом. Эти файлы имеют еще дополнительные названия, которые напрямую связаны с методами доступа к произвольной записи, которые поддерживаются данными файловыми структурами.
Файлы с плотным индексом называются также индексно-прямыми файлами, а файлы с неплотным индексом называются также индексно-последовательными файлами.
2 Лекция. Информационные системы, использующие базы данных
Содержание лекции: необходимость появления баз данных.
Цель лекции: изучить недостатки файловых систем и причины появления информационных систем, использующих базы данных.
2.1 Недостатки файловых систем
Несмотря на появление файлов с произвольным доступом, быстро стало очевидным, что файловые системы любого типа обладают некоторыми недостатками.
Эти недостатки следующие:
1. избыточность данных. Многие приложения используют свои собственные файлы данных, и следовательно, одна и та же единица данных повторяется в различных файлах. Например, в банке одно и то же имя клиента встречается в файлах, содержащих сведения о сберегательных, текущих счетах, о ссудах. Более того, хотя это одно и то же имя клиента, соответствующие поля в разных файлах могут называться по-разному. Кроме того, одно и то же поле в разных файлах может иметь разную длину. Вследствие такой избыточности необходимы лишние затраты на поддержание и хранение данных. Эта избыточность может порождать противоречия между разными версиями общих данных.
Информационные системы, использующие базы данных, позволяют избавиться от подобной избыточности, поскольку все приложения используют один и тот же набор данных. Существенная информация записывается один раз. То есть все приложения будут пользоваться согласованными данными;
2. слабый контроль данных. В файловой системе нет централизованного контроля. Один и тот же элемент данных может иметь различные имена, терминология в различных отделах может быть разной. Например, банк может в термин счет вкладывать один смысл применительно к сбережениям и совсем другой применительно к ссудам. Разные значения одного и того же термина называют омонимами. И, наоборот, разные слова могут иметь одинаковые значения. Например, банк может говорить о владельце счета или клиенте, вкладывая в этот термин один и тот же смысл. Термины, имеющие одно и то же значение, называются синонимами.
Система управления базами данных осуществляет централизованный контроль данных и помогает избежать недоразумений, порожденных омонимами и синонимами.
Далее, поскольку файловые системы являются общим хранилищем файлов, принадлежащих, вообще говоря, разным пользователям, системы управления файлами должны обеспечивать авторизацию доступа к файлам. В общем виде подход состоит в том, что по отношению к каждому зарегистрированному пользователю данной вычислительной системы для каждого существующего файла указываются действия, которые разрешены или запрещены данному пользователю.
В большинстве современных систем управления файлами применяется подход к защите файлов, впервые реализованный в ОС UNIX. В этой ОС каждому зарегистрированному пользователю соответствует пара целочисленных идентификаторов: идентификатор группы, к которой относится этот пользователь, и его собственный идентификатор в группе. При каждом файле хранится полный идентификатор пользователя, который создал этот файл, и фиксируется, какие действия с файлом может производить его создатель, какие действия с файлом доступны для других пользователей той же группы и что могут делать с файлом пользователи других групп. Администрирование режимом доступа к файлу в основном выполняется его создателем-владельцем. Для множества файлов, отражающих информационную модель одной предметной области, такой децентрализованный принцип управления доступом вызывал дополнительные трудности. И отсутствие централизованных методов управления доступом к информации послужило еще одной причиной разработки СУБД;
3. недостаточные возможности управления данными. Индексные файлы позволяют обращаться к определенной записи по ключу. Этого достаточно до тех пор, пока нам нужна отдельная запись. Если же нам нужен набор связанных данных, то такую информацию трудно или даже невозможно извлечь из файловой системы. Это связано с тем, что файловые системы не позволяют устанавливать связь между данными разных файлов.
Системы управления базами данных были специально разработаны для того, чтобы упростить связывание данных из разных файлов;
4. большие затраты труда программиста. В файловой системе новая прикладная программа требует нового набора файлов. Даже если существующий файл содержит необходимую информацию, приложению требовался еще какой-либо набор данных. В результате программисту надо писать еще одну программу. То есть между данными и программами существовала жесткая зависимость.
Базы данных позволили разделить программы и данные, так что программа в некотором смысле независима от деталей определения данных;
5. следующей причиной стала необходимость обеспечения эффективной параллельной работы многих пользователей с одними и теми же файлами. В общем случае системы управления файлами обеспечивали режим многопользовательского доступа. Если операционная система поддерживает многопользовательский режим, вполне реальна ситуация, когда два или более пользователя одновременно пытаются работать с одним и тем же файлом. Если все пользователи собираются только читать файл, ничего страшного не произойдет. Но если хотя бы один из них будет изменять файл, для корректной работы этих пользователей требуется взаимная синхронизация их действий по отношению к файлу.
В системах управления файлами обычно применялся следующий подход. В операции открытия файла (первой и обязательной операции, с которой должен начинаться сеанс работы с файлом) среди прочих параметров указывался режим работы (чтение или изменение). Если к моменту выполнения этой операции некоторым пользовательским процессом PR1 файл был уже открыт другим процессом PR2 в режиме изменения, то в зависимости от особенностей системы процессу PR1 либо сообщалось о невозможности открытия файла, либо он блокировался до тех пор, пока в процессе PR2 не выполнялась операция закрытия файла.
При подобном способе организации одновременная работа нескольких пользователей, связанная с модификацией данных в файле, либо вообще не реализовывалась, либо была очень замедлена.
Эти недостатки послужили тем толчком, который заставил разработчиков информационных систем предложить новый подход к управлению информацией. Этот подход был реализован в рамках новых программных систем, названных впоследствии Системами Управления Базами Данных (СУБД), а сами хранилища информации, которые работали под управлением данных систем, назывались базами или банками данных (БД и БнД).
2.2 Информационные системы, использующие базы данных
Терминология в СУБД, да и сами термины «база данных» и «банк данных» частично заимствованы из финансовой деятельности. Это заимствование не случайно и объясняется тем, что работа с информацией и работа с денежными массами во многом схожи, поскольку и там и там отсутствует персонификация объекта обработки: две банкноты достоинством в сто рублей столь же неотличимы и взаимозаменяемы, как два одинаковых байта (естественно, за исключением серийных номеров). Вы можете положить деньги на некоторый счет и предоставить возможность вашим родственникам или коллегам использовать их для иных целей. Вы можете поручить банку оплачивать ваши расходы с вашего счета или получить их наличными в другом банке, и это будут уже другие денежные купюры, но их ценность будет эквивалентна той, которую вы имели, когда клали их на ваш счет. К тому же первые коммерческие компьютерные системы использовались для ведения бизнеса.
База данных (БД) – упорядоченный набор хранимых данных, связанных общей темой или назначением. Основное назначение базы данных – быстрый поиск содержащейся в ней информации.
Система управления базами данных (СУБД) – программное обеспечение, осуществляющее управление базой данных.
Понятие базы данных шире, чем просто набор данных. Кроме собственно базы данных имеется набор прикладных программ, которые работают с этими данными, обрабатывая их обычным способом, а также соответствующее оборудование и люди.
Банк данных (БнД) — это система специальным образом организованных данных — баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
Программа, выполняющая конкретную практическую задачу в бизнесе, называется прикладной программой или приложением. Набор таких программ, совместно выполняющих связанные задачи, называется прикладной системой. В нашем контексте программы, с помощью которых пользователи работают с базой данных будем называть приложениями.
В общем случае с одной базой данных могут работать множество различных приложений. Например, если база данных моделирует некоторое предприятие, то для работы с ней может быть создано приложение, которое обслуживает подсистему учета кадров, другое приложение может быть посвящено работе подсистемы расчета заработной платы сотрудников, третье приложение работает как подсистема складского учета, четвертое приложение посвящено планированию производственного процесса.
При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями.
Информационная система, использующая базы данных, или система баз данных состоит из четырех компонентов: оборудования, программного обеспечения (СУБД), данных (БД) и людей (пользователи, администрация, обслуживающий персонал).
В удачно разработанной и функционирующей системе все четыре компонента взаимодействуют, образуя единую систему, выполняющую нужные задачи: обслуживающий персонал, советуясь с пользователями, определяет необходимые данные и создает структуру базы данных, отвечающую потребностям пользователей. Затем структура базы данных сообщается СУБД через словарь данных. Пользователи вводят в систему данные, следуя определенным процедурам (инструкциям). Хранение введенных данных обеспечивается оборудованием. Прикладные программы, обслуживающие доступ к базе данных, разрабатываются программистами, а пользователи запускают их на компьютерах. Эти программы выдают информацию, которая нужна руководству компании и ее клиентам.
Информационные системы, использующие базы данных, позволили преодолеть недостатки файловых систем. Одна из основных целей систем баз данных – обеспечение независимости данных, то есть независимости приложений от изменений в структуре хранения и стратегии доступа. В базе данных может поддерживаться целостность данных, то есть их точность и непротиворечивость.
3 Лекция. История развития систем управления базами данных
Содержание лекции: рассмотреть вопросы развития систем управления базами данных
Цель лекции: изучить историю развития систем управления базами данных.
3.1 Базы данных на больших ЭВМ
Стремительное развитие вычислительной техники, изменение ее принципиальной роли в жизни общества повлияло также и на развитие технологии баз данных. Можно выделить четыре этапа в развитии данного направления в обработке данных. Однако необходимо заметить, что все же нет жестких временных ограничений в этих этапах.
Первый этап развития СУБД связан с организацией баз данных на больших машинах. Базы данных хранились во внешней памяти центральной ЭВМ, пользователями этих баз данных были задачи, запускаемые в основном в пакетном режиме. Интерактивный режим доступа обеспечивался с помощью консольных терминалов, которые не обладали собственными вычислительными ресурсами и служили только устройствами ввода-вывода для центральной ЭВМ. Программы доступа к базе данных писались на различных языках и запускались как обычные числовые программы. Мощные операционные системы обеспечивали возможность условно параллельного выполнения всего множества задач.
Особенности этого этапа развития выражаются в следующем:
- все СУБД базируются на мощных мультипрограммных операционных системах, поэтому в основном поддерживается работа с централизованной базой данных в режиме распределенного доступа;
- функции управления распределением ресурсов в основном осуществляются операционной системой;
- поддерживаются языки низкого уровня манипулирования данными, ориентированные на навигационные методы доступа к данным;
- значительная роль отводится администрированию данных;
- проводятся серьезные работы по обоснованию и формализации реляционной модели данных, и создается первая система (System R), реализующая идеологию реляционной модели данных;
- результаты научных исследований открыто обсуждаются в печати, идет мощный поток общедоступных публикаций, касающихся всех аспектов теории и практики баз данных, и результаты теоретических исследований активно внедряются в коммерческие СУБД;
- появляются первые языки высокого уровня для работы с реляционной моделью данных. Однако отсутствуют стандарты для этих первых языков.
3.2 Эпоха персональных компьютеров
Персональные компьютеры стремительно перевернули представление о месте и роли вычислительной техники в жизни общества. Появилось множество программ, предназначенных для работы неподготовленных пользователей. Системные программисты были отодвинуты на второй план. И, конечно, это сказалось и на работе с базами данных. Появились программы, которые назывались системами управления базами данных и позволяли хранить значительные объемы информации, они имели удобный интерфейс для заполнения данных, встроенные средства для генерации различных отчетов. Эти программы позволяли автоматизировать многие учетные функции, которые раньше велись вручную. Постоянное снижение цен на персональные компьютеры сделало их доступными не только для организаций и фирм, но и для отдельных пользователей. Компьютеры стали инструментом для ведения документации и собственных учетных функций. Это все сыграло как положительную, так и отрицательную роль в области развития баз данных. Кажущаяся простота и доступность персональных компьютеров и их программного обеспечения породила множество дилетантов. Однако доступность персональных компьютеров заставила пользователей из многих областей знаний, которые ранее не применяли вычислительную технику в своей деятельности, обратиться к ним. И спрос на развитые удобные программы обработки данных заставлял поставщиков программного обеспечения поставлять все новые системы, которые принято называть настольными (desktop) СУБД.
Особенности этого этапа следующие:
- все СУБД были рассчитаны на создание баз данных в основном с монопольным доступом и это понятно. Компьютер персональный, он не был подсоединен к сети, и база данных на нем создавалась для работы одного пользователя. В редких случаях предполагалась последовательная работа нескольких пользователей, например, сначала оператор, который вводил бухгалтерские документы, а потом главбух, который определял проводки, соответствующие первичным документам;
- большинство СУБД имели развитый и удобный пользовательский интерфейс. В большинстве существовал интерактивный режим работы с базой данных как в рамках ее описания, так и в рамках проектирования запросов. Кроме того, большинство СУБД предлагали развитый и удобный инструментарий для разработки готовых приложений без программирования. Инструментальная среда состояла из готовых элементов приложения в виде шаблонов экранных форм, отчетов, этикеток, графических конструкторов запросов, которые достаточно просто могли быть собраны в единый комплекс;
- во всех настольных СУБД поддерживался только внешний уровень представления реляционной модели, то есть только внешний табличный вид структур данных;
- при наличии высокоуровневых языков манипулирования данными типа реляционной алгебры и SQL в настольных СУБД поддерживались низкоуровневые языки манипулирования данными на уровне отдельных строк таблиц;
- в настольных СУБД отсутствовали средства поддержки ссылочной и структурной целостности базы данных. Эти функции должны были выполнять приложения, однако скудость средств разработки приложений иногда не позволяла это сделать, и в этом случае эти функции должны были выполняться пользователем, требуя от него дополнительного контроля при вводе и изменении информации, хранящейся в базе данных;
- наличие монопольного режима работы фактически привело к вырождению функций администрирования и в связи с этим — к отсутствию инструментальных средств администрирования баз данных.
- и, наконец, последняя и в настоящий момент весьма положительная особенность — это сравнительно скромные требования к аппаратному обеспечению со стороны настольных СУБД. Вполне работоспособные приложения, разработанные, например, на Clipper, работали на PC 286.
3.3 Распределенные базы данных
Хорошо известно, что история развивается по спирали, поэтому после процесса «персонализации» начался обратный процесс — интеграция. Множится количество локальных сетей, все больше информации передается между компьютерами, остро встает задача согласованности данных, хранящихся и обрабатывающихся в разных местах, но логически друг с другом связанных, возникают задачи, связанные с параллельной обработкой транзакций — последовательностей операций над базой данных, переводящих ее из одного непротиворечивого состояния в другое непротиворечивое состояние. Успешное решение этих задач приводит к появлению распределенных баз данных, сохраняющих все преимущества настольных СУБД и в то же время позволяющих организовать параллельную обработку информации и поддержку целостности БД.
Особенности данного этапа:
- практически все современные СУБД обеспечивают поддержку полной реляционной модели;
- большинство современных СУБД рассчитаны на многоплатформенную архитектуру, то есть они могут работать на компьютерах с разной архитектурой и под разными операционными системами, при этом для пользователей доступ к данным, управляемым СУБД на разных платформах, практически неразличим;
- необходимость поддержки многопользовательской работы с базой данных и возможность децентрализованного хранения данных потребовали развития средств администрирования баз данных с реализацией общей концепции средств защиты данных;
- потребность в новых реализациях вызвала создание серьезных теоретических трудов по оптимизации реализаций распределенных баз данных и работе с распределенными транзакциями и запросами с внедрением полученных результатов в коммерческие СУБД;
- все современные СУБД имеют средства подключения клиентских приложений, разработанных с использованием настольных СУБД, и средства экспорта данных из форматов настольных СУБД второго этапа развития;
- разрабатывается ряд стандартов в рамках языков описания и манипулирования данными начиная с SQL89, SQL92, SQL99 и технологий по обмену данными между различными СУБД, к которым можно отнести и протокол ODBC (Open DataBase Connectivity), предложенный фирмой Microsoft;
- начались работы, связанные с концепцией объектно-ориентированных баз данных.
3.4 Перспективы развития систем управления базами данных
Этот этап характеризуется появлением новой технологии доступа к данным — интранет. Основное отличие этого подхода от технологии клиент-сервер состоит в том, что отпадает необходимость использования специализированного клиентского программного обеспечения. Для работы с удаленной базой данных используется стандартный броузер Интернета, и для конечного пользователя процесс обращения к данным происходит аналогично скольжению по Всемирной Паутине. При этом встроенный в загружаемые пользователем HTML-страницы код, написанный на языках Java, Java-script, Perl, PHP и других, отслеживает все действия пользователя и транслирует их в низкоуровневые SQL-запросы к базе данных, выполняя, таким образом, ту работу, которой в технологии клиент-сервер занимается клиентская программа. Удобство данного подхода привело к тому, что он стал использоваться не только для удаленного доступа к базам данных, но и для пользователей локальной сети предприятия. Простые задачи обработки данных, не связанные со сложными алгоритмами, требующими согласованного изменения данных во многих взаимосвязанных объектах, достаточно просто и эффективно могут быть построены по данной архитектуре. В этом случае для подключения нового пользователя к возможности использовать данную задачу не требуется установка дополнительного клиентского программного обеспечения. Однако алгоритмически сложные задачи рекомендуется реализовывать в архитектуре «клиент-сервер» с разработкой специального клиентского программного обеспечения.
У каждого из вышеперечисленных подходов к работе с данными есть свои достоинства и свои недостатки, которые и определяют область применения того или иного метода, и в настоящее время все подходы широко используются.
4 Лекция 4 Системный анализ предметной области
Содержание лекции: вопросы анализа моделируемой части реального мира.
Цель лекции: изучить подходы системного анализа моделируемой предметной области.
4.1 Предметная область информационной системы
Каждая информационная система в зависимости от ее назначения имеет дело с той или иной частью реального мира, который принято называть предметной областью.
Предметная область - некоторая совокупность реальных объектов, которые представляют интерес для ее пользователей.
Существует этап, предшествующий этапу проектирования базы данных. Модель этого этапа должна выражать информацию о предметной области в виде, независимом от используемой СУБД.
Итак, на первом этапе проектирования необходимо выполнить cистемный анализ предметной области
С точки зрения проектирования базы данных в рамках системного анализа, необходимо провести подробное словесное описание объектов предметной области и реальных связей, которые присутствуют между описываемыми объектами. Желательно, чтобы данное описание позволяло корректно определить все взаимосвязи между объектами предметной области.
В общем случае существуют два подхода к выбору состава и структуры предметной области:
- функциональный подход — он реализует принцип движения «от задач» и применяется тогда, когда заранее известны функции некоторой группы лиц и комплексов задач, для обслуживания информационных потребностей которых создается рассматриваемая база данных. В этом случае мы можем четко выделить минимальный необходимый набор объектов предметной области, которые должны быть описаны;
- предметный подход — когда информационные потребности будущих пользователей базы данных жестко не фиксируются. Они могут быть многоаспектными и весьма динамичными. Мы не можем точно выделить минимальный набор объектов предметной области, которые необходимо описывать. В описание предметной области в этом случае включаются такие объекты и взаимосвязи, которые наиболее характерны и наиболее существенны для нее. База данных, конструируемая при этом, называется предметной, то есть она может быть использована при решении множества разнообразных, заранее не определенных задач.
Конструирование предметной базы данных в некотором смысле кажется гораздо более заманчивым, однако трудность всеобщего охвата предметной области с невозможностью конкретизации потребностей пользователей может привести к избыточно сложной схеме базы данных, которая для конкретных задач будет неэффективной.
Чаще всего па практике рекомендуется использовать некоторый компромиссный вариант, который, с одной стороны, ориентирован на конкретные задачи или функциональные потребности пользователей, а с другой стороны, учитывает возможность наращивания новых приложений.
Системный анализ должен заканчиваться:
- подробным описанием информации об объектах предметной области, которая требуется для решения конкретных задач и которая должна храниться в базе данных;
- формулировкой конкретных задач, которые будут решаться с использованием данной базы;
- описанием входных документов, которые служат основанием для заполнения данными базы данных;
- кратким описанием алгоритмов решения задач;
- описанием выходных документов, которые должны генерироваться в системе.
4.2 Примеры описания предметной области
Пример 1. Пусть требуется разработать информационную систему для компании, которая занимается издательской деятельностью. База данных создаётся для информационного обслуживания редакторов, менеджеров и других сотрудников компании и должна содержать данные о сотрудниках компании, книгах, авторах, финансовом состоянии компании и предоставлять возможность получать разнообразные отчёты.
В соответствии с предметной областью система строится с учётом следующих особенностей: каждая книга издаётся в рамках контракта; книга может быть написана несколькими авторами; контракт подписывается одним менеджером и всеми авторами книги; каждый автор может написать несколько книг (по разным контрактам); порядок, в котором авторы указаны на обложке, влияет на размер гонорара; если сотрудник является редактором, то он может работать одновременно над несколькими книгами; у каждой книги может быть несколько редакторов, один из них – ответственный редактор; каждый заказ оформляется на одного заказчика; в заказе на покупку может быть перечислено несколько книг.
Каждая издающаяся книга, характеризуется следующими параметрами: авторы, название, тираж, дата выхода, цена одного экземпляра, общие затраты на издание, авторский гонорар.
Об авторах книг необходимо иметь следующую информацию: фамилия, имя, отчество, РНН, паспортные данные, домашний адрес, телефоны. Для авторов необходимо хранить сведения о написанных книгах.
О каждом сотруднике издательства хранятся следующие сведения: фамилия, имя, отчество, табельный номер, пол, дата рождения, паспортные данные, РНН, должность, оклад, домашний адрес и телефоны. Для редакторов необходимо хранить сведения о редактируемых книгах; для менеджеров – сведения о подписанных контрактах.
Для отражения финансового положения компании в системе нужно учитывать заказы на книги. Для заказа необходимо хранить номер заказа, заказчика, адрес заказчика, дату поступления заказа, дату его выполнения, список заказанных книг с указанием количества экземпляров.
Система создаётся для обслуживания следующих групп пользователей: администрация (дирекция); менеджеры; редакторы; сотрудники компании, обслуживающие заказы.
Пользователи должны иметь возможность информационной поддержки базы данных: ведение базы данных (запись, чтение, модификация, удаление в архив); обеспечение логической непротиворечивости базы данных; обеспечение защиты данных от несанкционированного или случайного доступа (определение прав доступа).
Также пользователи базы данных должны иметь возможность: получить список всех текущих проектов (книг, находящихся в печати и в продаже); получить список редакторов, работающих над книгами; получить полную информацию о книге (проекте); получить сведения о конкретном авторе (с перечнем всех книг); получить информацию о продажах (по одному или по всем проектам); определить общую прибыль от продаж по текущим проектам; определить размер гонорара автора по конкретному проекту.
Пример 2. Пусть требуется разработать информационную систему для автоматизации учета получения и выдачи книг в библиотеке. Система должна предусматривать режимы ведения системного каталога, отражающего перечень областей знаний, по которым имеются книги в библиотеке. Внутри библиотеки области знаний в систематическом каталоге могут иметь уникальный внутренний номер и полное наименование. Каждая книга может содержать сведения из нескольких областей знаний. Каждая книга в библиотеке может присутствовать в нескольких экземплярах.
Каждая книга, хранящаяся в библиотеке, характеризуется следующими параметрами: уникальный шифр; название; фамилии авторов (могут отсутствовать); место издания (город); издательство; год издания; количество страниц; стоимость книги; количество экземпляров книги в библиотеке. Книги могут иметь одинаковые названия, но они различаются по своему уникальному шифру (ISBN).
В библиотеке ведется картотека читателей. На каждого читателя в картотеку заносятся следующие сведения: фамилия, имя, отчество; домашний адрес; телефон (будем считать, что у нас два телефона — рабочий и домашний); дата рождения. Каждому читателю присваивается уникальный номер читательского билета. Каждый читатель может одновременно держать на руках не более 5 книг. Читатель не должен одновременно держать более одного экземпляра книги одного названия.
Каждая книга в библиотеке может присутствовать в нескольких экземплярах. Каждый экземпляр имеет следующие характеристики: уникальный инвентарный номер; шифр книги, который совпадает с уникальным шифром из описания книг; место размещения в библиотеке.
В случае выдачи экземпляра книги читателю в библиотеке хранится специальный вкладыш, в котором должны быть записаны следующие сведения: номер билета читателя, который взял книгу; дата выдачи книги; дата возврата.
Предусматриваются следующие ограничения на информацию в системе: Книга может не иметь ни одного автора; в библиотеке должны быть записаны читатели не моложе 17 лет; в библиотеке присутствуют книги, изданные начиная с 1960 по текущий год; каждый читатель может держать на руках не более 5 книг; каждый читатель при регистрации в библиотеке должен дать телефон для связи; каждая область знаний может содержать ссылки на множество книг, и каждая книга может относиться к различным областям знаний.
С данной информационной системой должны работать следующие группы пользователей: библиотекари; читатели; администрация библиотеки.
При работе с системой библиотекарь должен иметь возможность решать следующие задачи: принимать новые книги и регистрировать их в библиотеке; проводить каталогизацию книг; проводить списание старых и не пользующихся спросом книг; вести учет выданных книг читателям; проводить списание утерянных читателем книг; проводить закрытие абонемента читателя,
Читатель должен иметь возможность решать следующие задачи: просматривать системный каталог; по выбранной области знаний получить полный перечень книг, находящихся библиотеке; для выбранного автора получить список книг, которые числятся в библиотеке.
Администрация библиотеки должна иметь возможность получать сведения о должниках—читателях библиотеки; сведения о книгах, которые не являются популярными, т. е. ни один экземпляр которых не находится на руках у читателей; сведения о стоимости конкретной книги, для того чтобы установить возможность возмещения стоимости утерянной книги или возможность замены ее другой книгой; сведения о наиболее популярных книгах, то есть таких, все экземпляры которых находятся на руках у читателей.
Эти примеры показывают, что перед началом разработки необходимо иметь точное представление о том, что же должно выполняться в нашей системе, какие пользователи в ней будут работать, какие задачи будет решать каждый пользователь. К сожалению, часто по отношению к базам данных считается, что все можно определить потом, когда проект системы уже создан. Отсутствие четких целей создания базы данных может свести на нет все усилия разработчиков, и проект получится плохим, неудобным, не соответствующим ни реально моделируемому объекту, ни задачам, которые должны решаться с использованием данной базы данных.
5 Лекция. Принципы проектирования баз данных
Содержание лекции: принципы проектирования баз данных
Цель лекции: изучить основные принципы проектирования баз данных
5.1 Архитектура базы данных. Физическая и логическая независимость
Важным аспектом развития методов доступа к данным стала идея отделения логической структуры и манипуляции данными, как они понимаются пользователями, от физического представления, требуемого компьютерным оборудованием. В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации базы данных то есть стандартная структура систем баз данных, состоящая из внешнего, концептуального и внутреннего уровней.
Уровень внешних моделей — самый верхний уровень, где каждая модель имеет свое «видение» данных. Этот уровень определяет точку зрения на базу данных отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров.
Внешний уровень - структурный уровень базы данных, определяющий пользовательские представления базы данных. Этот уровень наиболее близок к пользователям и связан с тем, как отдельные пользователи представляют себе данные базы данных. Совокупность всех таких пользовательских представлений и есть внешний уровень.
Концептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира.
Концептуальный уровень – структурный уровень базы данных, определяющий логическую схему базы данных. Концептуальное проектирование базы данных, выполняемой на концептуальном уровне, включает анализ информационных потребностей пользователей и определение нужных им элементов данных. Результатом этого проектирования является концептуальная схема или единое логическое описание всех элементов данных и отношений между ними.
Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации.
Внутренний уровень – структурный уровень базы данных, определяющий физический вид базы данных. Он связан со способом физического хранения данных: дисководы, физические адреса, индексы, указатели и т.д. Ни один пользователь (как пользователь) не касается этого уровня.
Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Это именно то, чего не хватало при использовании файловых систем.
Выделение концептуального уровня позволило разработать аппарат централизованного управления базой данных.
Если внешний уровень связан с «частными» представлениями пользователей, то концептуальный уровень можно представить себе определяющим обобщенное представление пользователей. Это представление ближе к данным «как они есть», чем какими их видят пользователи. То есть может быть много «внешних представлений», каждая из которых состоит из представления части базы данных, и может быть единственное «концептуальное представление», состоящее из абстрактного представления базы данных в целом. Также есть единственное «внутреннее» представление, отражающее всю базу данных как действительно хранимую.
5.2 Концептуальные модели данных
Одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных». Понятие «данные» в концепции баз данных — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели. Не существует однозначного определения этого термина, у разных авторов эта абстракция определяется с некоторыми различиями, но, тем не менее, можно выделить общее в этих определениях.
Напомним, что база данных – совокупность данных, структурированных определенным образом.
Структура базы данных воплощает структуру предметной области.
Модель – представление реальности, отражающее только избранные детали. В контексте баз данных модель данных – методы структурирования данных.
В соответствии с рассмотренной ранее трехуровневой архитектурой мы сталкиваемся с понятием модели данных по отношению к каждому уровню.
Ядром любой системы баз данных является концептуальная модель. На концептуальном уровне выполняется концептуальное проектирование, то есть создание концептуальной схемы базы данных. На этом этапе создаются подробные модели пользовательских представлений данных, затем они интегрируются в концептуальную модель, фиксирующую все элементы данных, которые будет содержать база данных.
Концептуальная модель разрабатывается после словесного описания предметной области. Эта модель должна включать такое формализованное описание предметной области, которое легко будет «читаться» не только специалистами по базам данных и оно не должно быть привязано к конкретной СУБД.
Выбор системы управления базой данных — это отдельная задача, для корректного ее решения необходимо иметь проект, который не привязан ни к какой конкретной СУБД.
Инфологическое проектирование, прежде всего, связано с попыткой представления семантики (смысла) предметной области в модели базы данных. Реляционная модель данных в силу своей простоты и лаконичности не позволяет отобразить семантику, то есть смысл предметной области.
Проблема представления семантики давно интересовала разработчиков, и в семидесятых годах было предложено несколько моделей данных, названных семантическими моделями. Семантическое моделирование представляет собой моделирование структуры данных, опираясь на смысл этих данных. К таким моделям можно отнести семантическую модель данных, предложенную Хаммером (Hammer) и Мак-Леоном (McLeon) в 1981 году, функциональную модель данных Шипмана (Shipman), также созданную в 1981 году, модель «сущность—связь», предложенную Питером Пин-Шэн Ченом (Chen) в 1976 году, и ряд других моделей. У всех моделей были свои положительные и отрицательные стороны, но испытание временем выдержала только последняя. В дальнейшем многими авторами были разработаны свои варианты подобных моделей (нотация Мартина, нотация IDEF1X, нотация Баркера и др.). Здесь в качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь (ER - Entity-Relationship). В настоящий момент модель Чена стала фактическим стандартом при концептуальном моделировании баз данных. Общепринятым стало сокращенное название «ER-модель». Диаграммы «сущность-связь» исходят из одной идеи - рисунок всегда нагляднее текстового описания. Все такие диаграммы используют графическое изображение сущностей предметной области, их свойств (атрибутов), и взаимосвязей между сущностями.
6 Лекция. Концептуальное моделирование данных
Содержание лекции: основные определения концепуального моделирования данных.
Цель лекции: изучить основные принципы концептуального моделирования данных.
6.1 Основные определения концептуальных моделей данных
Как любая модель, концептуальная модель имеет несколько базовых понятий, которые образуют исходные кирпичики, из которых строятся уже более сложные объекты по заранее определенным правилам. Эта модель в наибольшей степени согласуется с концепцией объектно-ориентированного проектирования, которая в настоящий момент, несомненно, является базовой для разработки сложных программных систем.
Главными элементами концептуальной модели являются объекты и отношения. Объекты – вещи, которые пользователи считают важными в моделируемой части реальности. Все множество предметной области разбивается на группы объектов, однородных по структуре и поведению, называемых типами объектов. Объектное множество – множество вещей одного типа. Объект-элемент – конкретный элемент объектного множества. Объекты часто представляют в виде существительных, а отношения – в виде глаголов. Также для обозначения объекта может использоваться термин сущность. Имя объектного множества пишется заглавными буквами в единственном числе. Так: ЧЕЛОВЕК - имя объектного множества, представляющего людей, строчными буквами «человек» обозначается элемент из объектного множества.
Объектные множества бывают лексическими и абстрактными Лексическое объектное множество – объектное множество, состоящее из элементов, которые можно напечатать. Абстрактное объектное множество - объектное множество, состоящее из элементов, которые нельзя напечатать.
В компьютерной реализации концептуальной модели элементы лексических объектов будут представлены в виде строк символов. Элементы абстрактных множеств будут представлены внутренними номерами, не имеющими смысла вне системы. Внутренний номер называют «идентификатором объекта» или суррогатным ключом, так как он представляет и однозначно определяет абстрактный объект-элемент реального мира. Суррогатный ключ - «идентификатор» абстрактного объекта-элемента в компьютерной системе, вне системы не имеет смысла.
Объекты могут быть базовыми (основными) и подчиненными (дочерними). Например, читатель библиотеки – базовая сущность, а абонемент этого читателя – подчиненная, которая зависит от наличия соответствующего читателя.
Некоторые объектные множества содержатся внутри объектных множеств. Конкретизация – объектное множество, являющееся подмножеством другого объектного множества. Обобщение – объектное множество, являющееся надмножеством другого объектного множества (содержащее его).
Между объектами могут быть установлены связи — бинарные ассоциации, показывающие, каким образом объекты соотносятся или взаимодействуют между собой. Связь может существовать между двумя разными объектами или между объектом и им же самим (рекурсивная связь). Она показывает, как связаны экземпляры объектных множеств между собой. Связь между элементами двух объектных множеств называется отношением. Отношение само по себе является объектным множеством, состоящим из пар объектов-элементов, взятых из двух множеств, которые соединяет отношение. Отношение, рассматриваемое как объектное множество, называется составным объектным множеством. Составным объектным множествам можно давать имена и включать их в отношения, как и обычные объектные множества.
Мощность отношения обозначает максимальное количество элементов одного объектного множества, связанных с одним элементом другого объектного множества. Максимальная мощность в одном из направлений, равная одному, соответствует математическому понятию функции, которая устанавливает соответствие один-к-одному или много-к-одному между множествами. Поэтому, отношение, имеющее максимальную мощность в одном из направлений, равную одному, называется функциональным в этом направлении.
Если максимальная мощность отношения в обоих направлениях равна одному, отношение называется отношением один-к-одному (обозначается 1:1 или 1-1). Если максимальная мощность отношения в одном направлении равна одному, а в другом – многим отношение называется отношением один-ко-многим (обозначается 1:* или *1:М). Если максимальная мощность отношения в обоих направлениях равна многим, отношение называется отношением много-ко-многим (обозначается *:* или М:М).
Связь между объектами является обязательной, если в данной связи должен участвовать каждый экземпляр сущности, необязательной — если не каждый экземпляр сущности должен участвовать в данной связи. При этом связь может быть обязательной с одной стороны и необязательной с другой стороны.
Большинство проблем в бизнесе требуют использования отношений высокого порядка, в которых участвуют три или более объектных множества. Отношение высокого порядка – отношение между тремя или более объектными множествами. Отношения между двумя объектными множествами называются бинарными отношениями. Отношение между n объектными множествами (отношения высокого порядка) называются n-арными отношениями.
Элементы объектных множеств представляются обладающими некоторыми атрибутами, позволяющими их различать. Атрибут объекта – функциональное отношение объектного множества с другим объектным множеством. Мы будем понимать под атрибутами некоторые характеристики объектов, если не будем использовать атрибуты в других отношениях. При нормальном использовании атрибуты являются функциональными отношениями в направлении от объекта к атрибуту. Это означает, что значение атрибута однозначно определено для каждого элемента объекта. Например, у каждого человека ровно одна дата рождения. Если для некоторого элемента объектного множества значение некоторого атрибута не определено, то говорят, что этот атрибут имеет пустое значение для элемента объектного множества. Пустое значение атрибута – Значение атрибута не определено для элемента объектного множества.
Атрибуты нужно отделять от объектов, так как значения атрибутов могут меняться, в то время как описываемый ими объект остается тем же самым. Это не означает, что значения всех атрибутов меняются. Часто требуется найти атрибуты, значения которых не меняются, поскольку их можно использовать в качестве ключей. Ключ или идентификатор – это атрибуты, значения которых однозначно определяют элемент объектного множества. Не для каждого объекта нужен ключ. Например, в базе данных, записывающей продажи, пользователя может интересовать только объем продажи и продаваемый товар. Многие продажи могут иметь одни и те же значения товара и объема. Если пользователя не интересует различие двух продаж, не нужно создавать ключ для каждой продажи. Отсутствие ключа не имеет последствий.
Конкретизированные объекты наследуют все атрибуты и отношения обобщенного объекта. Наследование – свойство объектного подмножества обладать всеми атрибутами и отношениями объемлющего множества.
Модели, созданные при помощи базовых приемов моделирования, относительно просты, но нетрудно убедиться в их возможностях и приносимой ими пользе.
6.2 Графическое представление концептуальной модели
После словесного описания предметной области, на втором этапе проектирования, необходимо разработать концептуальную модель базы данных. Концептуальная модель должна включать такое формализованное описание предметной области, которое легко будет «читаться» не только специалистами по базам данных. Это описание должно быть настолько емким, чтобы можно было оценить глубину и корректность проработки проекта базы данных, и конечно, оно не должно быть привязано к конкретной СУБД. Выбор СУБД — это отдельная задача, для корректного ее решения необходимо иметь проект, который не привязан ни к какой конкретной СУБД.
При концептуальном моделировании баз данных используется ER-модель, которая представляет базу данных в виде сущностей и связей между ними. В настоящий момент не существует единой общепринятой системы обозначений для ER-модели, используются разные графические нотации, но разобравшись в одной, можно легко понять и другие.
Одно из общепринятых графических обозначений объектного множества — прямоугольник, тогда объекты-элементы обозначаются в виде точек Конкретизация графически обозначается U-образным символом. Атрибуты представляются в овалах.
Другое обозначение объекта — прямоугольник, в верхней части которого записано имя сущности, а ниже перечисляются атрибуты, причем ключевые атрибуты помечаются, например, подчеркиванием или специальным шрифтом.
Связи между объектными множествами обозначаются линиями, посередине которых пишут название связи. Иногда для наглядности название связи размещают в ромбе посередине этой линии.
В разных нотациях мощность связи изображается по-разному. Можно обозначить множественность связи путем разделения линии связи на 3 или же символами * и М. Обязательность связи тоже обозначается по-разному. Например, необязательность связи можно обозначить пустым кружочком на конце связи, а обязательность перпендикулярной линией, перечеркивающей связь. Графическая интерпретация связи позволяет сразу прочитать смысл взаимосвязи между объектами, она наглядна и легко интерпретируема.
В качестве примера приведем ER-диаграмму, отражающую связи между объектами СТУДЕНТ и ПРЕПОДАВАТЕЛЬ, где связь — руководство дипломными проектами: каждый студент имеет только одного руководителя, но один и тот же преподаватель может руководить множеством студентов-дипломников - связь «один-ко-многим» (см. рисунок 6.1).
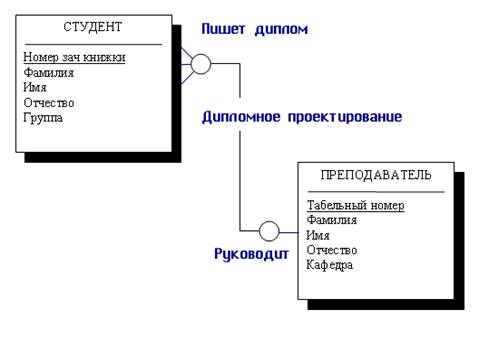
Рисунок. 6.1 - Пример отношения «один-ко-многим» при связывании объектов СТУДЕНТ и ПРЕПОДАВАТЕЛЬ
В результате построения модели предметной области в виде набора объектов и связей получаем связный граф. В полученном графе необходимо избегать циклических связей — они выявляют некорректность модели.
7 Лекция Разработка ER-диаграммы для анализируемой предметной области
Содержание лекции: методы разработки ER-диаграмм.
Цель лекции: разработать ER-диаграммы для анализируемой предметной области.
Основными задачами концептуального проектирования являются определение предметной области системы и формирование взгляда на программное обеспечение с позиций будущих пользователей базы данных. В качестве примера спроектируем концептуальную модель системы, предназначенной для хранения информации о книгах и областях знаний, представленных в библиотеке. Описание предметной области было приведено ранее (лекция 4).
Выделим основные объектные множества. Прежде всего, существует объектное множество КНИГИ, каждая книга имеет уникальный шифр, который является ее ключом, и ряд атрибутов, которые взяты из описания предметной области. Множество экземпляров множества определяет множество книг, которые хранятся в библиотеке. Каждый экземпляр множества КНИГИ соответствует не конкретной книге, стоящей на полке, а описанию некоторой книги, которое дается обычно в предметном каталоге библиотеке. Каждая книга может присутствовать в нескольких экземплярах, и это как раз те конкретные книги, которые стоят на полках библиотеки. Для того чтобы отразить это, мы должны ввести объектное множество ЭКЗЕМПЛЯРЫ, которая будет содержать описания всех экземпляров книг, которые хранятся в библиотеке. Каждый экземпляр сущности ЭКЗЕМПЛЯРЫ соответствует конкретной книге на полке. Каждый экземпляр имеет уникальный инвентарный номер, однозначно определяющий конкретную книгу. Кроме того, каждый экземпляр книги может находиться либо в библиотеке, либо на руках у некоторого читателя, и в последнем случае для данного экземпляра указываются дополнительно дата взятия книги читателем и дата предполагаемого возврата книги. Напомним, что связи бывают обязательные и факультативные. Если объект одного типа оказывается по необходимости связанным с объектом другого типа, то между этими типами объектов существует обязательная связь. Иначе связь является факультативной.
Между сущностями КНИГИ и ЭКЗЕМПЛЯРЫ существует связь «один-ко-многим» (1:М), обязательная с двух сторон. Чем определяется данный тип связи? Мы можем предположить, что каждая книга может присутствовать в библиотеке в нескольких экземплярах, поэтому связь «один-ко-многим». При этом если в библиотеке нет ни одного экземпляра данной книги, то мы не будем хранить ее описание, поэтому если книга описана в сущности КНИГИ, то по крайней мере один экземпляр этой книги присутствует в библиотеке. Это означает, что со стороны книги связь обязательная. Что касается сущности ЭКЗЕМПЛЯРЫ, то не может существовать в библиотеке ни одного экземпляра, который бы не относился к конкретной книге, поэтому и со стороны ЭКЗЕМПЛЯРЫ связь тоже обязательная.
Теперь нам необходимо определить, как в нашей системе будет представлен читатель. Естественно предложить ввести для этого объектное множество ЧИТАТЕЛИ, каждый экземпляр которой будет соответствовать конкретному читателю. В библиотеке каждому читателю присваивается уникальный номер читательского билета, который будет однозначно идентифицировать нашего читателя. Номер читательского билета будет ключевым атрибутом сущности ЧИТАТЕЛИ. Кроме того, в сущности ЧИТАТЕЛИ должны присутствовать дополнительные атрибуты, которые требуются для решения поставленных задач, этими атрибутами будут: «Фамилия Имя Отчество», «Адрес читателя», «Телефон домашний» и «Телефон рабочий». Почему мы ввели два отдельных атрибута под телефоны? Потому что надо в разное время звонить по этим телефонам, чтобы застать читателя, поэтому администрации библиотеки будет важно знать, к какому типу относится данный телефон. В описании нашей предметной области существует ограничение на возраст наших читателей, поэтому в сущности «Читатели» надо ввести обязательный атрибут «Дата рождения», который позволит нам контролировать возраст наших читателей.
Из описания предметной области мы знаем, что каждый читатель может держать на руках несколько экземпляров книг. Для отражения этой ситуации нам надо провести связь между сущностями ЧИТАТЕЛИ и ЭКЗЕМПЛЯРЫ. А почему не между сущностями ЧИТАТЕЛИ и КНИГИ? Потому что читатель берет из библиотеки конкретный экземпляр конкретной книги, а не просто книгу. А как же узнать, какая книга у данного читателя? А это можно будет узнать по дополнительной связи между сущностями ЭКЗЕМПЛЯРЫ и КНИГИ, и эта связь каждому экземпляру ставит в соответствие одну книгу, поэтому мы в любой момент можем однозначно определить, какие книги находятся на руках у читателя, хотя связываем с читателем только инвентарные номера взятых книг. Между сущностями ЧИТАТЕЛИ и ЭКЗЕМПЛЯРЫ установлена связь «один-ко-многим», и при этом она не обязательная с двух сторон. Читатель в данный момент может не держать ни одной книги на руках, а с другой стороны, данный экземпляр книги может не находиться ни у одного читателя, а просто стоять на полке в библиотеке.
Теперь надо отразить последний объект, который связан с системным каталогом. Системный каталог содержит перечень всех областей знаний, сведения по которым содержатся в библиотечных книгах. Обычно с системного каталога в библиотеке начинается поиск нужных книг, если неизвтны ихесаем их авторы и названия. Название области знаний может быть длинным и состоять из нескольких слов, поэтому для моделирования системного каталога мы введем объектное множество СИСТЕМНЫЙ_КАТАЛОГ с двумя атрибутами: «Код области знаний» и «Название области знаний». Атрибут «Код области знаний» будет ключевым атрибутом сущности.
Из описания предметной области нам известно, что каждая книга может содержать сведения из нескольких областей знаний, а также в библиотеке может присутствовать множество книг, относящихся к одной и той же области знаний, поэтому нам необходимо установить между СИСТЕМНЫЙ_КАТАЛОГ и КНИГИ связь «многие-ко-многим», обязательную с двух сторон. Действительно, в системном каталоге не должно присутствовать такой области знаний, сведения по которой не представлены ни в одной книге нашей библиотеки, противное было бы бессмысленно. И обратно, каждая книга должна быть отнесена к одной или нескольким областям знаний для того, чтобы читатель мог ее быстрее найти. Это отношение формирует составное объектное множество, для удобства таким отношениям иногда дают объектные имена – существительные (дополнительно к имени отношения). Назовем это множество СВЕДЕНИЯ. Графически составное множество обозначается прямоугольником, нарисованным вокруг отношения и участвующих в нем объектных множеств (рисунок 7.1).
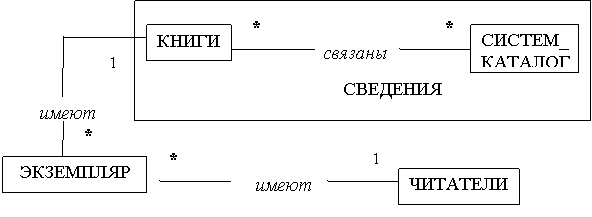 Рисунок 7.1
- Концептуальная модель предметной области «Библиотека»
Рисунок 7.1
- Концептуальная модель предметной области «Библиотека»
Спроектируем концептуальную модель системы, предназначенной для хранения информации издательской компании (предметная область описана в лекции 4). Разработку модели начнем с выделения основных сущностей.
Прежде всего, существует объектное множество КНИГИ, каждая книга имеет ряд атрибутов, которые взяты из описания предметной области. Для представления в разрабатываемой системе авторов вводим для этого объектное множество АВТОРЫ, каждый экземпляр которой будет соответствовать конкретному автору (атрибуты тоже приведены в описании предметной области). Надо отметить, что здесь идет речь об уже написанных, готовых к изданию книгах. Каждая книга имеет вполне определенный список авторов (или автора). Можно принять, что между объектами КНИГИ и АВТОРЫ будет связь «один-ко-многим»: у каждой книги определенный список авторов, каждая группа авторов (каждый автор) может написать не одну книгу. Но, в общем случае эта связь мощности «много-ко-многим». В этом случае это отношение может составлять составное объектное множество КНИГИ_ ГОТОВЫЕ_ К_ ИЗДАНИЮ. У этого множества могут быть свои атрибуты, например, такие: тираж, цена, дата выхода.
В работе по изданию определенной книги участвуют сотрудники компании, которые представляются объектным множеством СОТРУДНИКИ с соответствующими атрибутами. Сотрудниками могут быть редакторы книг или менеджеры, оформляющие контракты на издание книги. Функции у этих групп сотрудников разные. Поэтому, введем конкретизацию множества СОТРУДНИКИ - МЕНЕДЖЕРЫ и РЕДАКТОРЫ. Каждую книгу редактирует определенная группа редакторов (несколько редакторов), и эта группа может работать с несколькими книгами: отношение множеств «много-ко-многим». Это отношение можно назвать РЕДАКТИРОВАНИЕ - новое объектное множество например, с такими атрибутами: дата начала, дата окончания. Каждая группа авторов (или отдельный автор) могут подписывать контракты на издание нескольких книг. Менеджеры тоже работают со множеством авторов. Поэтому отношение между множествами АВТОРЫ и МЕНЕДЖЕРЫ будет иметь мощность «много-ко-многим», это отношение составляет новое объектное множество КОНТРАКТЫ (атрибуты контракта – номер, дата подписания, авторский гонорар).
Основной деятельностью компании является выполнение заказов на издание тех или иных книг: в объекте «Заказчики» хранится информация о заказчиках (название заказчика, адрес заказчика, телефоны). Заказчики могут заказать не одну книгу, и каждая книга может быть куплена многими заказчиками: отношение между ЗАКАЗЧИКИ и КНИГИ – «много-ко-многим», оно определяет объектное множество ЗАКАЗЫ (атрибуты - дата поступления заказа, дата его выполнения, стоимость заказа). Вариант ER–диаграммы модели издательской компании приведен на рисунке. 7.1. Чтобы не загромождать диаграмму, составные объектные множества и атрибуты не приведены.
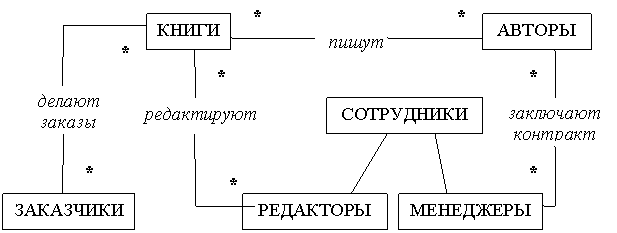
Рисунок 7.2 - ER–диаграмма модели издательской компании
Итак, диаграммы сущность-связь позволяют использовать наглядные графические обозначения для моделирования сущностей и их взаимосвязей. Основное достоинство метода состоит в том, модель строится методом последовательных уточнений первоначальных диаграмм. Концептуальные диаграммы не учитывают особенностей конкретных систем управления базами данных.
8 Лекция. Примеры концептуального моделирования
Содержание лекции: примеры концептуального проектирования баз данных.
Цель лекции: изучить на примерах методы разработки концептуальных схем баз данных.
Как уже отмечалось, отношения можно рассматривать как объекты, в этом случае они называются составными объектными множествами. Большинство проблем бизнеса требуют использования составных объектов. Ранее в примерах во всех отношениях участвовали два объектных множества (бинарные отношения). Однако отношение может связывать три и более объектных множеств (n-арные отношения). Проиллюстрируем это понятие примером.
Рассмотрим опыт компании, занимающейся международной торговлей товарами. Концепция компании такова: найти в разных странах производителей, чьи товары всегда удовлетворяют высоким стандартам качества; найти фирмы, реализующие товары; установить деловые связи между изготовителями и продавцами, снабжая последних товарами, закупленными у выбранных производителей. У компании есть офисы в различных странах; штат каждого офиса состоит из торговых агентов и закупщиков.
Создадим концептуальную модель данных компании. У компании есть клиенты, торговые агенты, товары, производители этих товаров. Выделим следующие объекты: ТОВАР, КЛИЕНТ, ТОРГОВЫЙ_АГЕНТ, ПРОИЗВОДИТЕЛЬ. Установим подходящие отношения между ними, как показано на рисунке 8.1:

![]()

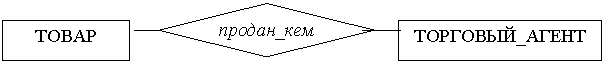
Предположим, что нужно отслеживать количество каждого товара, проданного каждому клиенту. Мы должны приписать атрибут КОЛИЧЕСТВО одному из объектов. Если это будет атрибут объекта ТОВАР, то мы не сможем различать количество товара, проданного различным клиентам, если же атрибут присвоить объекту КЛИЕНТ, то не сможем различать товары, проданные клиенту. Поэтому, КОЛИЧЕСТВО – атрибут отношения между товаром и клиентом, а не товара или клиента в отдельности. Итак, отношение «продан_кому» само является объектным множеством или составным объектом, которому и приписывается атрибут КОЛИЧЕСТВО (рисунок 8.2).
 |
Рисунок 8.2 - Правильная модель отображения количества продаж
Предположим, что необходимо записывать количество продаж каждого товара, проданного каждому клиенту в конкретный день. Тогда связываем отношение «продан_кому» с объектом ДАТА и приписываем атрибут КОЛИЧЕСТВО этому новому отношению. Модель более удобно представить в виде одного трехстороннего отношения (рисунок 8.3). Необходимо учесть, что среди объектов нашей модели есть производители товаров. Отобразим этот объект на схеме. На схеме также обозначены мощности отношений.
![]()
![]()
![]()

![]()
![]()
![]()
![]()

|
||||
|
||||
Рисунок 8.3 - Полная модель отслеживания продаж
Для иллюстрации еще одного понятия в концептуальном моделировании, рассмотрим следующий пример. Строительная компания возводит различные здания. Для всех зданий требуются разнообразные материалы в различных количествах. На разных этапах проекта работают разные бригады (арматурщиков, каменщиков, штукатуров и т.д.). При составлении графика работы фирма варьирует состав бригад. Рабочие назначаются в различные бригады в соответствии с квалификацией. Бригады составляются таким образом, как требуется для конкретного здания. Для каждой бригады назначается бригадир. Рабочий может возглавлять одну бригаду и работать в другой простым рабочим. Создадим концептуальную модель данных, которая может обеспечить нужной информацией владельца компании. На рисунке 8.4 представлено отношение между зданиями и материалами.
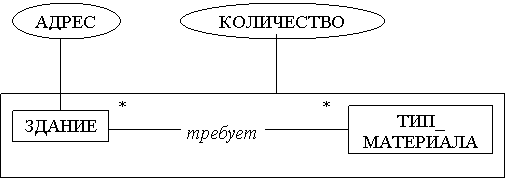
![]()
Мощность отношения между объектными множествами ЗДАНИЯ и ТИП_МАТЕРИАЛА много-ко-многим. Атрибут АДРЕС относится только к множеству ЗДАНИЕ, может быть использован в качестве ключа, для идентификации конкретного здания. Прямоугольник вокруг отношения «требует» показывает, что мы используем это отношение как составное объектное множество. Этому объектному множеству придаем атрибут КОЛИЧЕСТВО, элементами этого множества будут пары: здание и тип материала.
Важно отметить, что в этом примере объектное множество ТИП_МАТЕРИАЛА представляет собой концептуальный, а не физический объект. Концептуальный объект – объект, обозначающий тип вещей, то есть элементами этого множества являются абстрактные понятия. То есть каждый элемент этого множества обозначает тип материала, а не физический «кусок» материала. Физическое объектное множество – объектное множество, элементами которого являются физические предметы. Такое понятие концептуального объекта, противопоставляемого физическому объекту, часто применяется в концептуальном моделировании данных. В ранее рассмотренном примере о библиотечной проблеме в объектном множестве «Книги» хранятся сведения о концептуальных книгах, физические книги же это копии, тома или, как принято в нашей модели, экземпляры книг. Хотя читатель может не различать эти понятия, для того, чтобы решить, как моделировать данные, нужно выяснить, какая информация нужна пользователю базы данных.
Теперь покажем формирование бригад и назначение рабочих и бригадиров. Еще один пример концептуального объектного множества – ТИП_БРИГАДЫ – это не конкретные бригады, а типы бригад (бригада арматурщиков, каменщиков и т.д.). Отношение между зданием и типом бригады представляет конкретную бригаду, назначенную выполнять на данном здании данный тип работ. Это отношение будем рассматривать как объект, назовем его БРИГАДА.
Для каждой бригады как элемента объектного множества БРИГАДА выбираются дни работы. То есть между БРИГАДА и ДАТА есть отношение много-ко-многим.
Далее представлено распределение рабочих и бригадиров по бригадам. Отношение «является_бригадиром» имеет мощность «один-ко-многим» т.к. у бригады один бригадир, но один человек может возглавлять несколько бригад.
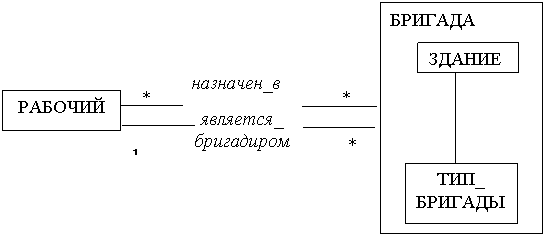
Рисунок 8.5 – Модель формирования бригад и бригадиров
На рисунке 8.6 представлена объединенная диаграмма, представляющая полную модель данных для строительной компании.

Рисунок 8.6 –Модель данных для строительной компании
Модели, рассмотренные выше, основывались на информации, заложенной в типах вопросов, которые задают менеджеры или управляющие. Поэтому эти модели являются фундаментом информационно-управляющих систем. Надо отметить, что концептуальную модель можно вывести из форм отчетов, используемых в деловых операциях.
9 Лекция 9 Методы моделирования данных
Содержание лекции: историческое развитие методов моделирования данных.
Цель лекции: изучить концептуальные методы структурирования данных.
9.1 Три базовые модели данных
Итак, система баз данных должна иметь возможность представлять два типа объектов: объекты и связи. причем между ними не существует принципиального различия: связь – специальный вид объектов. Три подхода к моделированию данных (иерархический, сетевой и реляционный) отличаются способом, которым они позволяют пользователю представлять и обрабатывать связи.
9.1.1 Иерархическая модель данных
Первая информационная система, использующая базы данных, появившаяся в середине 60-х 20 века, была основана на иерархической модели. Иерархическая модель – модель данных, в которой связи между данными имеют вид иерархий. Исторически эти модели появились раньше, и в настоящий момент они используются реже, чем современные реляционные модели данных. Однако до сих пор существуют системы, работающие на основе этих моделей, а одна из концепций развития объектно-ориентированных баз данных предполагает объединение принципов сетевой модели с концепцией реляционной. Появление иерархической модели связано с тем, что в реальном мире очень многие связи соответствуют иерархии, когда один объект выступает как родительский, а с ним может быть связано множество подчиненных объектов. Иерархия проста и естественна в отображении взаимосвязи между классами объектов.
Основными информационными единицами в иерархической модели являются: база данных (БД), сегмент и поле. Поле данных определяется как минимальная, неделимая единица данных, доступная пользователю с помощью СУБД. Сегмент в терминологии Американской Ассоциации по базам данных DBTG (Data Base Task Group) называется записью, при этом в рамках иерархической модели определяются два понятия: тип сегмента или тип записи и экземпляр сегмента или экземпляр записи.
Тип сегмента — это поименованная совокупность типов элементов данных, в него входящих. Экземпляр сегмента образуется из конкретных значений полей или элементов данных, в него входящих. Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Для возможности различия отдельных записей в данном наборе каждый тип сегмента должен иметь ключ или набор ключевых атрибутов (полей, элементов данных). Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента. В иерархической модели сегменты объединяются в ориентированный древовидный граф. При этом полагают, что направленные ребра графа отражают иерархические связи между сегментами: каждому экземпляру сегмента, стоящему выше по иерархии и соединенному с данным типом сегмента, соответствует несколько (множество) экземпляров данного (подчиненного) типа сегмента. Тип сегмента, находящийся на более высоком уровне иерархии, называется логически исходным по отношению к типам сегментов, соединенным с данным направленными иерархическими ребрами, которые в свою очередь называются логически подчиненными по отношению к этому типу сегмента. Иногда исходные сегменты называют сегментами-предками, а подчиненные сегменты называют сегментами-потомками.
На концептуальном уровне определяется понятие схемы базы данных в терминологии иерархической модели. Схема иерархической базы данных представляет собой совокупность отдельных деревьев, каждое дерево в рамках модели называется физической базой данных. Каждая физическая база данных удовлетворяет следующим иерархическим ограничениям:
- в каждой физической базе данных существует один корневой сегмент, то есть сегмент, у которого нет логически исходного (родительского) типа сегмента;
- каждый логически исходный сегмент может быть связан с произвольным числом логически подчиненных сегментов;
- каждый логически подчиненный сегмент может быть связан только с одним логически исходным (родительским) сегментом.
Между экземплярами сегментов также существуют иерархические связи. Экземпляры-потомки одного типа, связанные с одним экземпляром сегмента-предка, называют «близнецами».
В иерархической базе данных файлы связываются между собой физическими указателями. Указатель – физический адрес, обозначающий место хранения записи на диске.
9.1.2 Сетевая модель данных
У иерархической модели есть недостаток, так как не все отношения можно представить в виде иерархии. Сеть – отношения между данными, когда каждая запись может быть подчинена записям более чем из одного файла. В связи с очевидной необходимостью обрабатывать такие отношения, в конце 60- годов (20 века) появились сетевые системы управления базами данных. Как и в иерархических системах, в сетевых системах баз данных для связывания данных использовались предопределенные физические указатели. В иерархии у каждого потомка (подчиненной записи в файле) может быть только один предок (подчиняющая запись в иерархии). Сетевые модели поддерживали более сложные отношения между записями из разных файлов.
Базовыми объектами модели являются: элемент данных; агрегат данных; запись; набор данных,
Элемент данных — то же, что и в иерархической модели, то есть минимальная информационная единица, доступная пользователю с использованием системы управления базами данных.
Агрегат данных соответствует следующему уровню обобщения в модели. В модели определены агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа. Агрегат данных имеет имя, и в системе допустимо обращение к агрегату по имени.
Записью называется совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов реального мира. Понятие записи соответствует понятию «сегмент» в иерархической модели. Для записи, так же как и для сегмента, вводятся понятия типа записи и экземпляра записи. Следующим базовым понятием в сетевой модели является понятие «Набор». Набором называется двухуровневый граф, связывающий отношением «один-ко-многим» два типа записи.
Набор фактически отражает иерархическую связь между двумя типами записей. Родительский тип записи в данном наборе называется владельцем набора, а дочерний тип записи — членом того же набора. Для любых двух типов записей может быть задано любое количество наборов, которые их связывают. Фактически наличие подобных возможностей позволяет промоделировать отношение «многие-ко-многим» между двумя объектами реального мира, что выгодно отличает сетевую модель от иерархической. В рамках набора возможен последовательный просмотр экземпляров членов набора, связанных с одним экземпляром владельца набора. Между двумя типами записей может быть определено любое количество наборов: например, можно построить два взаимосвязанных набора. Существенным ограничением набора является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора.
Таким образом, использование физических указателей позволяет извлекать данные, связанные определенными отношениями. Однако, эти отношения должны быть определены до запуска системы. Извлечь данные на основе других отношений было сложно или даже невозможно.
9.1.3 Переход к реляционной модели
Реляционная модель основывается на математических принципах, вытекающих непосредственно из теории множеств и логики предикатов. Эти принципы впервые были применены в области моделирования данных доктором Е.Ф.Коддом (в то время работавшим в IBM). В 1970 г. доктор опубликовал революционную по содержанию статью, которая всерьез поколебала устоявшиеся представления о базах данных. Он выдвинул идею, что данные нужно связывать в соответствии с их внутренними логическими взаимоотношениями, а не физическими указателями. Таким образом, пользователи смогут комбинировать данные из разных источников, если логическая информация, необходимая для такого комбинирования, присутствует в исходных данных. Это открыло новые возможности для информационно-управляющих систем, поскольку запросы к базам данных теперь не были ограничены физическими указателями. Информационные системы, использующие базы данных, которые поддерживают извлечение данных на основе логических связей, позволяют легко получить ответы на множество вопросов. В своей статье Кодд предложил простую модель данных, согласно которой все данные сведены в таблицы, состоящие из строк и столбцов. Эти таблицы получили название реляций, а модель стала называться реляционной.
Реляционная модель определяет способ представления данных (структуру данных), методы защиты данных (целостность данных), а также операции, выполняемые с данными (манипулирование данными). Распространено заблуждение, что реляционная модель названа так потому, что она определяет отношения между таблицами. На самом деле название этой модели происходит от отношений (реляций), лежащих в ее основе. В рамках реляционной модели данные представлены в виде отношений на концептуальном уровне, однако при этом не дается никаких указаний, каким образом данные будут реализованы на физическом уровне.
Рассматривая данные с концептуальной, а не физической точки зрения, Кодд предложил еще одну революционную идею. В реляционных системах баз данных целые файлы данных могут обрабатываться одной командой, тогда как в традиционных системах за один раз обрабатывается только одна запись. Метод разделения концептуального и логического уровней произвел переворот в области программирования баз данных. Подход Кодда чрезвычайно повысил эффективность программирования в базах данных. Ранее программирование баз данных сводилось в основном к написанию программного кода для физического управления устройствами, предназначенными для хранения данных. Логический подход к данным сделал также возможным создание языков запросов, более доступных для пользователей, не являющихся специалистами по компьютерным технологиям. Конечно, очень трудно создать язык, которым могли бы пользоваться все, независимо от опыта работы с компьютером, однако реляционные языки запросов сделали базы данных доступными для более широкого круга пользователей, чем раньше.
Публикация работ Кодда в начале семидесятых годов прошлого века вызвала взрыв активности, как среди ученых, так и среди разработчиков коммерческих систем по созданию реляционной системы управления базами данных. Результатом этой деятельности явилось создание во второй половине семидесятых реляционных систем, которые поддерживали такие языки как (Structured Query Language - SQL, язык структурированных запросов), Query Language (Quel, язык запросов), и Query-by-Example (QBE, запросы по образцу). Сегодня реляционные базы данных рассматриваются как стандарт для современных коммерческих систем работы с данными.
10 Лекция 10 Реляционная модель данных
Содержание лекции: основные определения реляционных моделей данных.
Цель лекции: изучить основные понятия реляционных моделей данных.
10.1 Реляционные таблицы и ключи
Реляционная модель основана на понятии "отношения" (Relationship), она наиболее распространена в настоящее время, хотя наряду с общепризнанными достоинствами обладает и рядом недостатков. Эти преимущества привели к тому, что уже в середине 80-х годов реляционные СУБД практически вытеснили с мирового рынка ранние СУБД.
К числу достоинств реляционной модели относят следующие:
- простота, наличие небольшого набора абстракций, которые позволяют сравнительно просто моделировать большую часть распространенных предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными;
- наличие хорошо разработанного и мощного математического аппарата;
- возможность операций над данными без знания их физической организации.
Недостатками реляционной модели считают:
- низкую эффективность хранения данных по сравнению с другими моделями;
- недостаточное быстродействие при реализации некоторых операций;
- ограниченность представления сложных структур данных;
- невозможность адекватного отражения семантики предметной области.
Реляционная модель данных – модель данных, представляющая данные в виде таблиц или реляций. Реляция – двумерная таблица, содержащая строки и столбцы данных. В модели Кодда для работы с данными в таблице предлагается пользоваться двумя языками: реляционной алгеброй и реляционным исчислением. Математическое название таблицы – relation (отношение). Оба этих языка обеспечивают работу с данными на основе логических характеристик, а не физических указателей.
Понятие таблицы - это основа реляционной модели. База данных - это набор таблиц. Но обратите внимание: данное понятие таблица имеет отношение только к представлению данных. Никакой связи с физической реализации записей на диске или в памяти она не имеет.
В реляционной СУБД выполняются как минимум два условия:
1) данные воспринимаются пользователем как таблицы;
2) в распоряжении пользователя имеются операторы, которые генерируют новые таблицы из старых.
Здесь важно, что результат операции над таблицей является тоже таблицей (реляционное свойство замкнутости), то есть результатом операции является объект того же рода, что и объект, над которым проводится операция.
В основе реляционной модели лежат следующие понятия: тип данных, атрибут, домен, кортеж, первичный ключ и отношение.
Понятие тип данных в реляционной модели данных полностью совпадает с этим понятием в языках программирования. Обычно выделяют символьный, числовой, денежный, битовый и календарный типы.
Для хранения информации используется атрибут. Атрибут в реляционной модели имеет тот же смысл, что и свойство объекта в ER- модели. Атрибут имеет имя и тип. Структура отношения состоит из набора атрибутов и их типов. Название атрибута – имя атрибута. Количество атрибутов реляции называется степенью (рангом) реляции.
Порядок атрибутов считается несущественным. Отсюда следует, что никакие два атрибута реляции не могут иметь одинаковых имен.
Набор всевозможных значений, которые может принимать атрибут, называется доменом (областью) атрибута. Домен играет огромную роль в реляционной модели. Он реализует функцию справочника в обыденном понятии. Применение домена позволяет избежать многих ошибок сравнивания. Например, при разном вводе одного и того же понятия (например, в случае ошибки ввода). Так же домен выполняет функцию контроля и классификации ввода, позволяя выбрать из имеющихся позиций. Все элементы домена относятся к одному типу данных и отвечают какому-либо логическому условию. Элементом домена может быть число, символьная строка, дата, но не сложная структура типа массива, списка и т.п. Две области атрибутов совпадают только в том случае, если они имеют один и тот же смысл. Два атрибута одной и той же области не обязательно имеют одно и то же имя. Значения каждого атрибута относятся к одному из доменов, то есть атрибут может принимать значения из заданного множества. Атрибут имеет имя и значение, часто имя атрибута совпадает с именем домена.
Схемой отношения называют именованное множество пар
(Ai, Di), i=1,k,
где Ai - имя атрибута, Di - имя домена, k - ранг отношения.
Если имя атрибута совпадает с именем домена, то схему отношения можно представить в виде списка
R (A1, A2, ... Ak),
где Аi - имена доменов.
Схема реляционной базы данных представляет собой совокупность схем отношений и содержит следующие компоненты:
S(rel) = < A, D, R, Rel, F>,
где A - множество атрибутов, D - множество доменов, R - множество имен отношений, Rel - множество схем отношений, F - множество ограничений, в том числе функциональных зависимостей.
Кортеж отношения - это множество пар "имя атрибута, значение атрибута", причем каждый атрибут отношения один и только один раз входит в кортеж. Кортеж - это тело отношения (строки реляции). Он состоит из набора заполненных атрибутов. Именно кортеж несет информацию об объекте, описываемом отношением. Если атрибуты и домены говорят о структуре, то кортеж - это наполнение информацией.
Отношение - это множество кортежей, соответствующих одной схеме отношения.
На практике отношение удобно представить в виде таблицы, заголовком которой является схема отношения, а строками - кортежи отношения; в этом случае имена атрибутов становятся именами столбцов этой таблицы.
Предопределенного порядка строк не существует, следовательно, никакие два кортежа не имеют одинаковый набор значений.
Пустое значение атрибута – значение, приписываемое атрибуту в кортеже, если атрибут неприменим или его значение неизвестно.
Любой набор атрибутов, однозначно определяющий каждый кортеж реляционной таблицы, называется суперключом. Ключ реляции – это минимальный набор атрибутов, то есть минимальный суперключ.
Ключ, содержащий два или более атрибутов, называется составным ключом.
В любой данной реляционной таблице может оказаться более одного набора атрибутов, которые можно выбрать в качестве ключа. Они называются потенциальными ключами. Когда один из потенциальных ключей выбран в качестве ключа реляции, его называют первичным ключом. Обычно в качестве первичного ключа выбирают потенциальный ключ, которым проще всего пользоваться при повседневной работе по вводу данных. Первичный ключ обычно называют ключом. Ключевой атрибут в обозначениях реляционной таблицы подчеркивают.
Для связи между разными отношениями используется понятие внешнего ключа. Внешним ключом называется атрибут (совокупность атрибутов), который является ключом Ak в другом отношении и его значения принадлежат к домену Dk. Говорят, что отношение, в котором определен внешний ключ, ссылается на другое отношение, в котором такой же атрибут является первичным ключом. То есть внешний ключ – набор атрибутов одной таблицы, являющийся ключом другой (или той же самой) таблицы. Внешние ключи обеспечивают важные связи между таблицами. Атрибуты внешних ключей не обязательно должны иметь те же имена, что и атрибуты ключа, которым они соответствуют.
Внешний ключ, ссылающийся на свою собственную реляционную таблицу, называется рекурсивным внешним ключом.
Поскольку информация о внешних ключах является жизненно важной, при определении реляционных таблиц обязательно отражаются определения внешних ключей. Общее обозначение реляционной таблицы: после имени реляции в круглых скобках перечисляются ее атрибуты. Подробный список, в котором даются имена реляционных таблиц с перечислением их атрибутов (ключи подчеркнуты) и определений внешних ключей, называется реляционной схемой базы данных.
10.2 Ограничительные условия, поддерживающие целостность данных
Под целостностью данных базы данных понимают согласованность данных в базе данных. В реляционной модели Кодда есть несколько ограничительных условий, используемых для проверки данных в базе данных, а также для придания данным осмысленной структуры. Они поддерживают целостность данных.
Ограничительное условие – правило, ограничивающее возможные значения данных в базе данных. Ограничительные условия обеспечивают логическую основу для поддержания правильных значений данных в базе данных, предупреждая ошибки при обновлении и обработке данных. Такие возможности обладают очевидной ценностью, поскольку основная цель базы данных – обеспечивать точную информацию для менеджмента и принятия решений. Обычно рассматриваются следующие ограничения: категорная целостность; целостность на уровне ссылок; функциональные зависимости.
Строки реляционной таблицы представляют в базе данных элементы конкретных объектов реального мира или, в соответствии с реляционной терминологией, категорий. Ключ реляционной таблицы однозначно определяет каждую строку и, следовательно, каждый элемент категории. Таким образом, если пользователи хотят извлекать данные конкретной строки, они должны знать значение ключа этой строки. То есть элемент не должен записываться в базу данных до тех пор, пока значения его ключевых атрибутов не будут полностью определены. Таким образом, ключу или любой части ключа не позволяется иметь пустое значение.
Правило категорной целостности: никакой ключевой атрибут любой строки реляционной таблицы не может иметь пустого значения.
При построении реляционных таблиц для связывания строк одной таблицы со строками другой таблицы используются внешние ключи. База данных, в которой все непустые внешние ключи ссылаются на текущие значения ключей другой реляционной таблицы, обладает целостностью на уровне ссылок.
Правило целостности на уровне ссылок: значение непустого внешнего ключа должно быть равно одному из текущих значений ключа другой таблицы.
Прежде чем перейти к третьему виду ограничений, необходимо рассмотреть правила нормализции базы данных.
11. Лекция. Преобразование концептуальной модели в реляционную
Содержание лекции: принципы преобразованиz концептуальной модели в реляционную модель данных.
Цель лекции: изучить методы преобразования элементов концептуальной модели в реляционные таблицы.
Огромное большинство СУБД основано на реляционной модели. Объектно-ориентированные СУБД, которые могли бы напрямую реализовать концептуальную схему, еще не лостигли «промышленной мощности», необходимой для больших приложений, и, следовательно, не могут использоваться. Необходим некоторый метод перевода концептуальных моделей в те модели, которые могут быть реализованы. Рассмотрим методы преобразования концептуальной модели в реляционную.
Концептуальная модель состоит из объектов, отношений, атрибутов, конкретизация, составных объектв и т.д. Рассмотрим методы преобразования каждой из этих конструкций в реляционные таблицы.
11.1 Преобразование объектных множеств и атрибутов
1. Для каждого объектного множества модели создается реляционная таблица. Чаще всего имена объектных множеств и таблиц совпадают. Но они могут быть и различными, потому что на имена объектных множеств могут не накладываться дополнительные синтаксические ограничения, кроме уникальности имени в рамках модели. Имена же таблиц могут быть ограничены требованиями конкретной СУБД. Чаще всего эти имена являются идентификаторами в некотором базовом языке, они ограничены по длине и не должны содержать пробелов и некоторых специальных символов. Например, объектное множество может быть названо СОТРУДНИКИ (рисунок 11.1), а соответствующую ей таблицу желательно назвать, например, EMPLOYEE (без пробелов и латинскими буквами).
Рисунок 11.1 - Преобразование объектного множества СОТРУДНИКИ в таблицу EMPLOYEE
Атрибуты объектного множества становятся атрибутами реляционной таблицы. Переименование атрибутов должно происходить в соответствии с теми же правилами, что и переименование объектных множеств. Для каждого атрибута задается конкретный допустимый в СУБД тип данных (рисунок 11.2) и обязательность или необязательность данного атрибута (то есть допустимость или недопустимость NULL значений для него).
Рисунок 11.2 - Свойства атрибутов отношения EMPLOYEE
2. Если в концептуальной модели существует ключевой атрибут, то он может использоваться в качестве ключа реляционной таблицы (PRIMARY KEY). В противном случае ключевой атрибут таблицы может быть создан проектировщиком базы данных. Все-таки лучше, если такой атрибут естественным образом возникает из модели. На практике, конечно, проектировщики должны советоваться с пользователями по поводу выбора ключа. Атрибуты, входящие в первичный ключ отношения, автоматически получают свойство обязательности (NOT NULL).
3. Если в концептуальной модели есть конкретизации объектного множества, то есть подобъекты и обобщающие объекты, то возможны несколько вариантов представления. Возможно создать только одно отношение для всех подобъектов одного обобщающего объекта. В него включают все атрибуты всех подобъектов. Однако тогда для ряда экземпляров ряд атрибутов не будет иметь смысла. И даже если они будут иметь неопределенные значения, то потребуются дополнительные правила различения одних подобъектов от других. Достоинством такого представления является то, что создается всего одно отношение. При втором способе для каждого подобъекта и для обобщающего объекта создаются свои отдельные отношения. Недостатком такого способа представления является то, что создается много отношений, однако достоинств у такого способа больше, так как можно работать только со значимыми атрибутами подобъекта.
Обычно конкретизация объектного множества будет иметь все атрибуты объектного множества, которое оно конкретизирует. Тогда конкретизация и обобщающее множество содержат повторяющуюся информацию. Чтобы избежать такой избыточности данных, из реляционной таблицы конкретизации удаляются все повторяющиеся не ключевые атрибуты; ключи же совпадают с ключами обобщающих объектных множеств.
11.2 Преобразование отношений
Отношения преобразуются одним из способов в зависимости от мощности:
а) отношение «один-к-одному» преобразуется путем помещения одного из объектных множеств в качестве атрибутов в таблицу второго объектного множества. Его выбор определяется потребностями конкретного приложения;
б) отношение «один-ко-многим»; в любом отношении «один-ко-многим» в таблицу, описывающую объект, мощность со стороны которого равна «многим», включается столбец, являющийся внешним ключом, указывающим на другой объект.
Для моделирования необязательного типа связи на физическом уровне у атрибутов, соответствующих внешнему ключу, устанавливается свойство допустимости неопределенных значений (признак NULL). При обязательном типе связи атрибуты получают свойство отсутствия неопределенных значений (признак NOT NULL);
в) отношение «много-ко-многим». Так как в реляционной модели данных поддерживаются между отношениями только связи типа «один-ко-многим», а в ER-модели допустимы связи «многие-ко-многим», то необходим специальный механизм преобразования, который позволит отразить множественные связи, неспецифические для реляционной модели, с помощью допустимых для нее категорий. Это делается введением специального дополнительного связующего отношения, которое связано с каждым исходным связью «один-ко-многим». Атрибутами этого отношения являются первичные ключи связываемых отношений.
Итак, чтобы преобразовать отношение «много-ко-многим», создается таблица пересечений. Таблица пересечений – таблица, представляющая элементы двух других таблиц, находящихся в отношении «много-ко-многим». Отношения «много-ко-многим» соответствуют многозначным атрибутам и преобразуются путем создания ключа из столбцов, соответствующих ключам двух объектных множеств, участвующих в отношении. То есть каждый из атрибутов новой таблицы (взятых из исходных таблиц) является внешним ключом (FOREIGN KEY), а вместе они образуют первичный ключ (PRIMARY KEY). Таблица пересечений может иметь дополнительные неключевые атрибуты, присущие только ей.
г) рекурсивное отношение; при преобразовании рекурсивных отношений для атрибута, обозначающего отношение, создается новое смысловое имя.
После того, как преобразование всех конкретных конструкций закончено, полученную реляционную схему необходимо пересмотреть на предмет избавления от избыточности. Любые избыточные таблицы (то есть таблицы, информация которых полностью содержится в других таблицах схемы) необходимо удалить из схемы.
12 Лекция. Нормализация базы данных
Содержание лекции: основные понятия теории нормализации баз данных.
Цель лекции: изучить понятие нормализации базы данных и первую нормальную форму.
Проектирование схемы базы данных может быть выполнено двумя путями:
- путем декомпозиции (разбиения), когда исходное множество отношений, входящих в схему базы данных заменяется другим множеством отношений (число их при этом возрастает), являющихся проекциями исходных отношений;
- путем синтеза, то есть путем компоновки из заданных исходных элементарных зависимостей между объектами предметной области схемы базы данных.
При проектировании реляционной базы данных необходимо решить вопрос о наиболее эффективной структуре данных. Основные цели, которые при этом преследуются: обеспечить быстрый доступ к данным в таблицах; исключить ненужное повторение данных (избыточность), которая может явиться причиной ошибок при вводе и нерационального использования дискового пространства компьютера; обеспечить целостность данных таким образом, чтобы при изменении одних объектов автоматически происходили соответствующие изменения связанных с ними объектов. Корректной является схема базы данных, в которой отсутствуют нежелательные зависимости между атрибутами отношении.
Реляционная база данных - это набор отношений. Но не просто набор, а нормализованный набор отношений. Классическая технология проектирования реляционных баз данных связана с теорией нормализации, основанной на анализе функциональных зависимостей между атрибутами отношений. Понятие функциональной зависимости является фундаментальным в теории нормализации реляционных баз данных. Мы определим его далее, а пока коснемся смысла этого понятия. Функциональные зависимости определяют устойчивые отношения между объектами и их свойствами в рассматриваемой предметной области. Именно поэтому процесс поддержки функциональных зависимостей, характерных для данной предметной области, является базовым для процесса проектирования.
Нормализация – метод создания набора отношений с заданными свойствами на основе требований к данным, установленных в некоторой организации. Процесс приведения реляционных таблиц к стандартному виду называется нормализацией.
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм:
- первая нормальная форма (1NF);
- вторая нормальная форма (2NF);
- третья нормальная форма (3NF);
- нормальная форма Бойса— Кодда (BCNF);
- четвертая нормальная форма (4NF);
- пятая нормальная форма, или форма проекции-соединения.
При практическом проектировании баз данных используются первые три нормальные формы.
Процесс проектирования с использованием декомпозиции представляет собой процесс последовательной нормализации схем отношений, при этом каждая последующая итерация соответствует нормальной форме более высокого уровня и обладает лучшими свойствами по сравнению с предыдущей.
Каждой нормальной форме соответствует некоторый определенный набор ограничений, и отношение находится в некоторой нормальной форме, если удовлетворяет свойственному ей набору ограничений.
Основные свойства нормальных форм:
- каждая следующая нормальная форма в некотором смысле улучшает свойства предыдущей;
- при переходе к следующей нормальной форме свойства предыдущих нормальных форм сохраняются.
В основе классического процесса проектирования лежит последовательность переходов от предыдущей нормальной формы к последующей. Однако в процессе декомпозиции мы сталкиваемся с проблемой обратимости, то есть возможности восстановления исходной схемы. Таким образом, декомпозиция должна сохранять эквивалентность схем базы данных при замене одной схемы па другую. Схемы базы данных называются эквивалентными, если содержание исходной базы данных может быть получено путем естественного соединения отношений, входящих в результирующую схему, и при этом не появляется новых кортежей в исходной базе данных. При выполнении эквивалентных преобразований сохраняется множество исходных фундаментальных функциональных зависимостей между атрибутами отношений.
Функциональные зависимости определяют не текущее состояние базы данных, а все возможные ее состояния, то есть они отражают те связи между атрибутами, которые присущи реальному объекту, который моделируется с помощью базы данных. Поэтому определить функциональные зависимости но текущему состоянию базы данных можно только в том случае, если экземпляр базы данных содержит абсолютно полную информацию (то есть никаких добавлений и модификации базы данных не предполагается). В реальной жизни это требование невыполнимо, поэтому набор функциональных зависимостей задает разработчик, системный аналитик, исходя из глубокого системного анализа предметной области.
Из-за небрежного проектирования базы данных появляется избыточность данных (повторение), которая приводит не только к потере лишнего места; она может вызвать нарушение целостности, то есть привести к пртиворечивости данных в базе данных. Несоотвествия между данными (противоречивость) называются аномалиями. Существут три вида аномалий:
- аномалия обновления – противоречивость данных, вызванная их избыточностью и их частичным обновлением;
- аномалия удаления – непреднамеренная потеря данных, вызванная удалением других данных;
- аномалия ввода – невозможность ввести данные в таблицу, вызванная отсутствием других данных.
Очевидно, что аномалии обновления, удаления и ввода нежелательны. Чтобы свести к минимуму проблемы, возникающие из-за аномалий, используется формальный метод, называемый разбиением. Разбиение – процесс разделения таблиц на несколько таблиц в целях избавления от аномалий и поддержания целостности данных. Для этого используются нормальные формы или правила структурирования таблиц.
Реляционная таблица находится в первой нормальной форме (1НФ), если никакое значение атрибута не является множеством значений или повторяющейся группой. Иногда говорят, что атрибуты таблицы, которая находится в 1НФ, являются скалярными величинами. То есть отношение находится в первой нормальной форме тогда и только тогда, когда на пересечении каждого столбца и каждой строки находятся только элементарные значения атрибутов. В некотором смысле это определение избыточно, потому что собственно оно определяет само отношение в теории реляционных баз данных. Однако, в силу исторически сложившихся обстоятельств и для преемственности такое определение первой нормальной формы существует. Определение Кодда реляционной таблицы содержит условие, согласно которому реляционная таблица должна удовлетворять первой нормальной форме. То есть в дальнейшем полагаем, что все рассматриваемые реляционные схемы находятся в 1НФ.
Не всегда легко определить, является ли атрибут скалярным. Например, дата состоит из трех различных компонентов: дня, месяца и года. Дату можно хранить как три различных атрибута или как единое целое. Выбор зависит от особенностей моделируемой предметной области. Если дата используется как отдельная величина, то она скалярная. Но если система работает с отдельными составляющими даты, лучше хранить ее в качестве набора из трех различных атрибутов. Аналогично можно по-разному моделировать имена: атрибут «Имя» может содержать полное имя (ФИО) элемента, а можно каждую составляющую часть отнести к разным атрибутам; также и с адресом: полный адрес или нет.
Таблица находится в первой нормальной форме, если удовлетворяет следующими требованиям:
1) таблица не имеет повторяющихся записей;
2) в таблице должны отсутствовать повторяющиеся группы полей;
3) строки должны быть не упорядочены;
4) столбцы должны быть не упорядочены.
13 Лекция. Функциональные зависимости и связанные с ними нормальные формы
Содержание лекции: основные нормальные формы.
Цель лекции: изучить понятие функциональной зависимости и связанные с нею нормальные формы.
13.1 Функциональные зависимости и нормальные формы
Ранее обсужденные правила категорной целостности и целостности на уровне ссылок накладывают ограничения на реляционную схему. Функциональные зависимости (ФЗ) позволяют накладывать дополнительные ограничения.
Функциональная зависимость – значение атрибута в кортеже однозначно определяет значение другого атрибута в кортеже. Формально функциональная зависимость определяется следующим образом: если А и В – атрибуты в таблице R, то запись
![]()
обозначает, что если два кортежа в таблице R имеют одно и то же значение атрибута А, то они имеют одно и то же значение атрибута В. Это определение также применимо, если А и В – множества столбцов, а не просто отдельные столбцы. Обозначение читается следующим образом: А функционально определяет В.
Атрибут в левой части ФЗ называется детерминантом. Детерминант – атрибут (атрибуты), значение которого определяет значения других атрибутов кортежей.
Реляционная таблица находится во второй нормальной форме (2НФ), если никакие неключевые атрибуты не являются функционально зависимыми лишь от части ключа. Таким образом, вторая нормальная форма может быть нарушена только в том случае, когда ключ составной.
Если таблица не удовлетворяет 2НФ, то возникают всевозможные аномалии (ввода, обновления, удаления). Для того, чтобы избавится от аномалий, таблицу необходимо разбить на две реляционные таблицы, каждая из которых удовлетворяет 2НФ. Эти две меньшие таблицы называются проекциями исходной таблицы. Проекция – таблица, состоящая из нескольких выбранных атрибутов другой таблицы. Процесс разбиения на две 2НФ-таблицы состоит из следующих шагов:
1) создается новая таблица, атрибутами которой будут атрибуты исходной таблицы, входящие в противоречащую правилу ФЗ. Детерминант ФЗ становится ключом новой таблицы;
2) атрибут, стоящий в правой части ФЗ, исключается из исходной таблицы;
3) если более одной ФЗ нарушают 2НФ, то шаги 1 и 2 повторяются для каждой такой ФЗ;
4) если один и тот же детерминант входит в несколько ФЗ, то все функционально зависящие от него атрибуты помещаются в качестве неключевых атрибутов в таблицу, ключом которой будет детерминант.
Реляционная таблица имеет третью нормальную форму
(3НФ), если для любой функциональной зависимости ![]() , Х является ключом (то есть детеминант
является ключом). Отсюда следует, что любая таблица, удовлетворяющая 3НФ, таже
удовлетворяет и 2НФ. Если таблица не соответсвует 3НФ, то возникает
избыточность данных, которая также приводит ко всевозможным аномалиям. Решение этих проблем – тоже разбиение.
, Х является ключом (то есть детеминант
является ключом). Отсюда следует, что любая таблица, удовлетворяющая 3НФ, таже
удовлетворяет и 2НФ. Если таблица не соответсвует 3НФ, то возникает
избыточность данных, которая также приводит ко всевозможным аномалиям. Решение этих проблем – тоже разбиение.
Поскольку 3НФ-таблицы всегда удовлетворяют 2НФ, достаточно пользоваться критерием третьей нормальной формы. Если каждый детерминант в таблице является ключом этой таблицы, то таблицы удовлетворяет первой, второй и третьей нормальным формам. Это упрощает процесс нормализации, так как нужно проверить только один критерий.
Надо отметить, что данное определение третьей нормальной формы соответствует в некоторых источниках нормальной форме Бойса—Кодда.
В большинстве случаев достижение третьей нормальной формы а считается достаточным для реальных проектов баз данных, однако в теории нормализации существуют нормальные формы высших порядков, которые уже связаны не с функциональными зависимостями между атрибутами отношений, а отражают более тонкие вопросы семантики предметной области и связаны с другими видами зависимостей.
Первая нормальная форма запрещает иметь многозначные атрибуты. Однако существует много ситуаций, когда требуется многозначность.
Условие, обеспечивающее независимость атрибутов путем обязательного повтора значений, называется многозначной зависимостью (МЗЗ). МЗЗ является таким же ограничительным условием, как и ФЗ, так как они требуют огромного числа повторений значений данных. Важный этап нормализации состоит в избавлении от многозначных зависимостей. Таблица находится в четвертой нормальной форме, если она находится в третьей нормальной форме и не имеет многозначных зависимостей. Так как проблема многозначных зависимостей возникает в связи с многозначными атрибутами, то проблема многозначных зависимостей решается размещением каждого многозначного атрибута в свою собственную таблицу вместе с ключом, от которого атрибут зависит.
Рассмотрим конкретную ситуацию, понятную всем студентам. Пусть дано отношение, которое моделирует предстоящую сдачу экзаменов на сессии. Допустим, оно имеет вид:
(Номер зач.кн,. Группа, Дисциплина).
Перечень дисциплин, которые должен сдавать студент, однозначно определяется не его фамилией, а номером группы (то есть специальностью).
В данном отношении существуют следующие две многозначные зависимости:
Группа -» Дисциплина и Группа -» Номер зач.кн.
Это означает, что каждой группе однозначно соответствует перечень дисциплин по учебному плану и номер группы определяет список студентов, которые в этой группе учатся.
Если мы будем работать с исходным отношением, то мы не сможем хранить информацию о новой группе и ее учебном плане — перечне дисциплин, которые должна пройти группа до тех пор, пока в нее не будут зачислены студенты. При изменении перечня дисциплин по учебному плану, например, при добавлении новой дисциплины, внести эти изменения в отношение для всех студентов, занимающихся в данной группе, весьма затруднительно. С другой стороны, если мы добавляем студента в уже существующую группу, то мы должны добавить множество кортежей, соответствующих перечню дисциплин для данной группы. Эти аномалии модификации отношения как раз и связаны с наличием двух многозначных зависимостей.
В этом примере можно произвести декомпозицию исходного отношения в два отношения:
(Номер зач.кн.. Группа),
(Группа, Дисциплина).
Оба эти отношения находятся в четвертой нормальной форме и свободны от отмеченных аномалий. Действительно, обе операции модификации теперь упрощаются: добавление нового студента связано с добавлением всего одного кортежа в первое отношение, а добавление новой дисциплины выливается в добавление одного кортежа во второе отношение. Кроме того, во втором отношении мы можем хранить любое количество групп с определенным перечнем дисциплин, в которые пока еще не зачислены студенты.
Последней нормальной формой является пятая нормальная форма 5NF, которая
редко используется на практике. В большей степени она является теоретическим исследованием.
13.2 Сравнение концептуального и реляционного моделирования данных
Главное назначение базы данных состоит в обеспечении пользователя точной информацией. Поэтому важно, чтобы структура базы данных была логичной и не имела изъянов. Чем сложнее модель базы данных, тем труднее правильно ее спроектировать. Эта сложность растет с добавлением объектных множеств, конкретизаций, составных объектов и отношений. Поэтому графический подход (схема концептуальной модели) сильно повышает вероятность получения точных моделей по сравнению с текстовым подходом реляционной схемы.
Концептуальные модели данных значительно легче понимать, чем реляционные модели, поскольку они лучше соответствуют нашему естественному взгляду на вещи, отраженному в языке в виде употребления глаголов и существительных (объектных множеств). Информация представляется в графическом виде, визуальное представление упрощает понимание структуры.
В реляционной же модели единственными средствами являются реляционные таблицы и внешние ключи, все объектные множества и отношения моделируются одинаковым образом. С одного взгляда на реляционную схему не просто понять, какие таблицы представляют объекты, а какие – отношения. Анализируя реляционную модель, вы мысленно рисуете картинку, которая связывает таблицы. То есть, для понимания реляционной модели мысленно проделывается та же работа, которая выполняется при концептуальном моделировании. Поэтому создание концептуальной модели и последующее преобразование ее в нормализованную реляционную модель стоит затраченных усилий, иначе в сложных ситуациях моделирования с большей вероятностью можно допускать серьезные ошибки. Конечно, для простой базы данных создать реляционную модель, возможно, не сложнее, чем создавать концептуальную модель.
Теория нормализации, которая была рассмотрена ранее применительно к реляционной модели, применима и к модели «объект—связь». Алгоритм приведения семантической модели к 5-й нормальной форме может быть следующим:
- проанализировать схему на присутствие объектов, которые моделируют несколько взаимосвязанных объектов реального мира (именно это соответствует ненормализованным отношениям) и разделить каждое из этих объектов на несколько новых, установить между ними соответствующие связи, полученная схема будет находиться в первой нормальной форме;
- проанализировать все сущности, имеющие составные первичные ключи, на наличие неполных функциональных зависимостей непервичных атрибутов от атрибутов возможного ключа. Если такие зависимости обнаружены, то разделить данные сущности на два, определить для каждой сущности первичные ключи и установить между ними соответствующие связи. Полученная схема будет находиться во второй нормальной форме;
- проанализировать все сущности на наличие детерминантов, которые не являются возможными ключами. При обнаружении подобных расщепить сущность на две, установив между ними соответствующие связи. Полученная схема соответствует третьей нормальной форме;
- проанализировать все сущности на наличие многозначных зависимостей. Если обнаружатся сущности, у которых имеется более одной многозначной зависимости, то расщепить такие сущности на две, установив между ними соответствующие связи.
Полученная таким образом схема будет находиться в четвертой нормальной форме.
14 Лекция 14 Реализация разработанной реляционной схемы
Содержание лекции: рассматриваются вопросы реализации разработанного проекта базы данных в среде конкретной СУБД..
Цель лекции: ознакомиться с современными языками манипулирования данными.
14.1 Структурированный язык запросов SQL
Все языки манипулирования данными, созданные до появления реляционных баз данных и разработанные для многих систем управления базами данных персональных компьютеров, были ориентированы на операции с данными, представленными в виде логических записей файлов. Это требовало от пользователей детального знания организации хранения данных и достаточных усилий для указания не только того, какие данные нужны, но и того, где они размещены и как шаг за шагом получить их. Рассматриваемый непроцедурный язык SQL (Structured Query Language - структуризованный язык запросов) ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц. Особенность предложений этого языка состоит в том, что они ориентированы в большей степени на конечный результат обработки данных, чем на процедуру этой обработки. SQL сам определяет, где находятся данные, какие индексы и даже наиболее эффективные последовательности операций следует использовать для их получения: не надо указывать эти детали в запросе к базе данных.
Непроцедурность языка означает, что на нем можно указать, что нужно сделать с базой данных, но нельзя описать алгоритм этого процесса. Все алгоритмы обработки SQL-запросов генерируются самой СУБД и не зависят от пользователя. Язык SQL состоит из набора операторов, которые можно разделить на несколько категорий:
- Data Definition Language (DDL) — язык определения данных, позволяющий создавать, удалять и изменять объекты в базах данных;
- Data Manipulation Language (DML) — язык управления данными, позволяющий модифицировать, добавлять и удалять данные в имеющихся объектах базы данных;
- Data Control Languages (DCL) — язык, используемый для управления пользовательскими привилегиями;
- Transaction Control Language (TCL) — язык для управления изменениями, сделанными группами операторов;
- Cursor Control Language (CCL) — операторы для определения курсора, подготовки операторов SQL к выполнению и некоторых других операций.
В начале 80-х годов SQL и стал фактическим стандартом таких языков для профессиональных реляционных СУБД. В 1987 году он стал международным стандартом языка баз данных и начал внедряться во все распространенные СУБД персональных компьютеров.
14.2 Объекты базы данных
14.2.1 Таблицы SQL
Понятие "таблица", как правило, связывается с реальной таблицей (создается с помощью предложения CREATE TABLE), т.е. c таблицей, для каждой строки которой в действительности имеется некоторый двойник, хранящийся в физической памяти машины. Таблицы поддерживаются всеми реляционными СУБД, и в их полях могут храниться данные разных типов. Однако SQL использует и создает ряд виртуальных (как будто существующих) таблиц: представлений, курсоров и неименованных рабочих таблиц, в которых формируются результаты запросов на получение данных из базовых таблиц и, возможно, представлений. Это таблицы, которые не существуют в базе данных, но как бы существуют с точки зрения пользователя.
Представление представляет собой виртуальную таблицу, предоставляющую данные из одной или нескольких реальных таблиц. Реально оно не содержит никаких данных, а только описывает их источник. Нередко такие объекты создаются для хранения в базах данных сложных запросов. Фактически представление - это хранимый запрос. Создание представлений в большинстве современных СУБД осуществляется специальными визуальными средствами. Они позволяют отображать на экране необходимые таблицы, устанавливать связи между ними, выбирать отображаемые поля, вводить ограничения на записи и др. Нередко эти объекты используются для обеспечения безопасности данных, например, путем разрешения просмотра данных с их помощью без предоставления доступа непосредственно к таблицам. Помимо этого некоторые представления объектов могут возвращать разные данные в зависимости, например, от имени пользователя, что позволяет ему получать только интересующие его данные.
При создании таблиц важным является определение первичных ключей. Очень часто первичные ключи генерируются самой СУБД. Это более удобно, чем их генерация в клиентском приложении, так как при многопользовательской работе генерация ключей с помощью СУБД — это единственный способ избежать дублирования ключей и получать их последовательные значения. В разных СУБД для генерации ключей используются разные объекты. Некоторые из таких объектов хранят целое число и правила, по которым генерируется следующее за ним значение, —обычно это выполняется с помощью триггеров. Некоторые СУБД поддерживают специальные типы полей для первичных ключей. При добавлении записей такие поля заполняются автоматически последовательными значениями (обычно целыми). В случае Microsoft Access и Microsoft SQL Server такие поля называются Identity fields.
В большинстве реляционных СУБД ключи реализуются с помощью объектов, называемых индексами, которые можно определить как список номеров записей, указывающий, в каком порядке их предоставлять..
14.2.2 Ограничения
Большинство современных серверных СУБД содержат специальные объекты, называемые ограничениями. Эти объекты содержат сведения об ограничениях, накладываемых на возможные значения полей. Например, с помощью такого объекта можно установить максимальное или минимальное значение для данного поля, и после этого СУБД не позволит сохранить в базе данных запись, не удовлетворяющую данному условию. Помимо ограничений, связанных с установкой диапазона изменения данных, существуют также ссылочные ограничения. Не все СУБД поддерживают ограничения. В этом случае для реализации аналогичной функциональности правил можно либо использовать другие объекты (например, триггеры), либо хранить эти правила в клиентских приложениях, работающих с этой базой данных.
14.2.3 Запросы к базам данных
Модификация и выбор данных, изменение метаданных и некоторые другие операции осуществляются с помощью запросов.
Большинство современных СУБД (и некоторые средства разработки приложений) содержат средства для генерации таких запросов. Один из способов манипуляции данными называется «queries by example» (QBE) — запрос по образцу. QBE представляет собой средство для визуального связывания таблиц и выбора полей, которые следует отобразить в результате запроса. Можно также написать запрос непосредственно на языке SQL.
В отличие от реляционной таблицы в результатах запроса строки упорядочены, и их порядок определяется исходным запросом (и иногда — наличием индексов). Поэтому можно определить текущую строку в таком наборе и указатель на нее, который называется курсором.
14.2.4 Транзакции
Транзакция — это группа операций над данными, которые либо выполняются все вместе, либо все вместе отменяются. Завершение транзакции означает, что все операции, входящие в состав транзакции, успешно завершены, и результат их работы сохранен в базе данных. Откат транзакции означает, что все уже выполненные операции, входящие в состав транзакции, отменяются и все объекты базы данных, затронутые этими операциями, возвращены в исходное состояние. Для реализации возможности отката транзакций многие СУБД поддерживают запись в log-файлы, позволяющие восстановить исходные данные при откате. Транзакция может состоять из нескольких вложенных транзакций.
14.2.5 Пользователи и роли
Предотвращение несанкционированного доступа к данным является серьезной проблемой, которая решается разными способами. Самый простой — это парольная защита либо всей таблицы, либо некоторых ее полей. В настоящее время более популярен другой способ защиты данных — создание списка пользователей с именами (user names) и паролями (passwords). Некоторые СУБД, в основном серверные, поддерживают не только список пользователей, но и роли. Роль — это набор привилегий. Если конкретный пользователь получает одну или несколько ролей, то вместе с ними — и все привилегии, определенные для данной роли.
14.2.6 Системный каталог
Любая реляционная СУБД, поддерживающая списки пользователей и ролей, должна их где-то хранить. В дополнение к этим спискам многие СУБД хранят списки таблиц, индексов, триггеров, процедур и др., а также сведения о том, кто ими владеет. Эти списки называются системными таблицами, а соответствующая часть базы данных называется системным каталогом. Отметим, что не все СУБД поддерживают системные каталоги. Вся информация об используемых структурах данных, логической организации данных, правах доступа пользователей и, наконец, физическом расположении данных является базой метаданных (БМД). Для управления БМД существует специальное программное обеспечение администрирования баз данных, которое предназначено для корректного использования единого информационного пространства многими пользователями.
14.2.7 Триггеры и хранимые процедуры
Триггеры и хранимые процедуры, поддерживаемые в большинстве современных серверных СУБД, используются для хранения исполняемого кода.
Хранимая процедура — это специальный вид процедуры, который выполняется сервером баз данных. Хранимые процедуры пишутся на процедурном языке, который зависит от конкретной СУБД. Они могут вызывать друг друга, читать и изменять данные в таблицах, и их можно вызвать из клиентского приложения, работающего с базой данных. Хранимые процедуры обычно используются при выполнении часто встречающихся задач.
Триггерами называется специальный класс хранимых процедур, автоматически запускаемых при добавлении, изменении и удалении данных из таблицы. Триггер срабатывает при модификации данных и запускает хранимую процедуру, выполняющую определенные действия. Триггеры также содержат исполняемый код, но их, в отличие от процедур, нельзя вызвать из клиентского приложения или хранимой процедуры. Триггер всегда связан с конкретной таблицей и выполняется тогда, когда при редактировании этой таблицы наступает событие, с которым он связан (например, вставка, удаление или обновление записи).
15 Лекция. Распределенная обработка данных
Содержание лекции: рассматриваются вопросы распределенной обработки данных
Цель лекции: ознакомиться с моделями «клиент—сервер» в технологии баз данных.
15.1 Общие сведения
Параллельный доступ к одной базе данных нескольких пользователей, в том случае если база данных расположена на одной машине, соответствует режиму распределенного доступа к централизованной базе данных. Такие системы называются системами распределенной обработки данных. Если же база данных распределена по нескольким компьютерам, расположенным в сети, и к ней возможен параллельный доступ нескольких пользователей, то мы имеем дело с параллельным доступом к распределенной базе данных. Подобные системы называются системами распределенных баз данных. Схема распределения физической базы данных по сети называется топологией базы данных или структурой распределенной базы данных.
Обработка одной транзакции, состоящей из множества SQL-запросов на одном удаленном узле возможностью реализации удаленной транзакции. Поддержка распределенной транзакции допускает обработку транзакции, состоящей из нескольких запросов SQL, которые выполняются на нескольких узлах сети (удаленных или локальных), но каждый запрос в этом случае обрабатывается только на одном узле, то есть запросы не являются распределенными. При обработке одной распределенной транзакции разные локальные запросы могут обрабатываться в разных узлах сети. Запрос, при обработке которого используются данные из базы данных, расположенные в разных узлах сети называется распределенным запросом.
Системы распределенной обработки данных в основном связаны с первым поколением БД, которые строились на мультипрограммных операционных системах и использовали централизованное хранение БД на устройствах внешней памяти центральной ЭВМ и терминальный многопользовательский режим доступа к ней. При этом пользовательские терминалы не имели собственных ресурсов — то есть процессоров и памяти, которые могли бы использоваться для хранения и обработки данных.
15.2 Модели «клиент—сервер» в технологии баз данных
Вычислительная модель «клиент—сервер» исходно связана с парадигмой открытых систем, которая появилась в 90-х годах и быстро эволюционировала. Сам термин «клиент-сервер» исходно применялся к архитектуре программного обеспечения, которое описывало распределение процесса выполнения по принципу взаимодействия двух программных процессов, один из которых в этой модели назывался «клиентом», а другой — «сервером». Клиентский процесс запрашивал некоторые услуги, а серверный процесс обеспечивал их выполнение. При этом предполагалось, что один серверный процесс может обслужить множество клиентских процессов.
Ранее приложение (пользовательская программа) не разделялось на части, оно выполнялось некоторым монолитным блоком. Но возникла идея более рационального использования ресурсов сети. Действительно, при монолитном исполнении используются ресурсы только одного компьютера, а остальные компьютеры в сети рассматриваются как терминалы. Но теперь, в отличие от эпохи main-фреймов, все компьютеры в сети обладают собственными ресурсами, и разумно так распределить нагрузку на них, чтобы максимальным образом использовать их ресурсы.
Основной принцип технологии «клиент—сервер» применительно к технологии баз данных заключается в разделении функций стандартного интерактивного приложения на 5 групп, имеющих различную природу: функции ввода и отображения данных (Presentation Logic); прикладные функции, определяющие основные алгоритмы решения задач приложения (Business Logic); функции обработки данных внутри приложения (Database Logic); функции управления информационными ресурсами (Database Manager System); служебные функции, играющие роль связок между функциями первых четырех групп.
Структура типового приложения, работающего с базой данных приведена на рисунке 15.1.
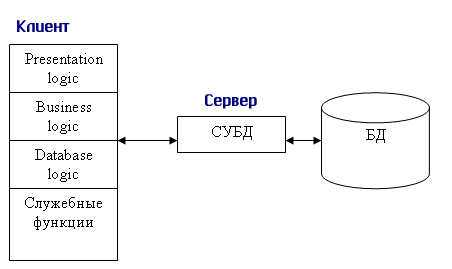
Рисунок 15.1 - Структура типового интерактивного приложения, работающего с базой данных
Презентационная логика (Presentation Logic) как часть приложения определяется тем, что пользователь видит на своем экране, когда работает приложение. Сюда относятся все интерфейсные экранные формы, которые пользователь видит или заполняет в ходе работы приложения, к этой же части относится все то, что выводится пользователю на экран как результаты решения некоторых промежуточных задач либо как справочная информация. Поэтому основными задачами презентационной логики являются: формирование экранных изображений; чтение и запись в экранные формы информации; управление экраном; обработка движений мыши и нажатие клавиш клавиатуры.
Бизнес-логика, или логика собственно приложений (Business processing Logic), — это часть кода приложения, которая определяет собственно алгоритмы решения конкретных задач приложения. Обычно этот код пишется с использованием различных языков программирования, таких как С, C++, Cobol, SmallTalk, Visual-Basic.
Логика обработки данных (Data manipulation Logic) — это часть кода приложения, которая связана с обработкой данных внутри приложения. Данными управляет собственно СУБД (DBMS). Для обеспечения доступа к данным используются язык запросов и средства манипулирования данными стандартного языка SQL
Обычно операторы языка SQL встраиваются в языки 3-го или 4-го поколения (3GL, 4GL), которые используются для написания кода приложения.
Процессор управления данными (Database Manager System Processing) — это собственно СУБД, которая обеспечивает хранение и управление базами данных. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако для рассмотрения архитектуры приложения нам надо их выделить в отдельную часть приложения.
15.3 Двухуровневые модели
Двухуровневая модель фактически является результатом распределения пяти указанных функций между двумя процессами, которые выполняются на двух платформах: на клиенте и на сервере. В чистом виде почти никакая модель не существует, приведем наиболее характерные особенности каждой двухуровневой модели:
1) Модель удаленного управления данными или модель файлового сервера (File Server, FS). В этой модели СУБД, а также функции управления всеми информационными ресурсами находится на клиенте. На сервере располагаются файлы с данными, и поддерживается доступ к файлам. Запрос клиента формулируется в командах DML. СУБД переводит этот запрос в последовательность файловых команд. Каждая файловая команда вызывает перекачку блока информации на клиента.
2) В модели удаленного доступа к данным (Remote Data Access, RDA) база данных хранится на сервере. На сервере же находится ядро СУБД. На клиенте располагается презентационная логика и бизнес-логика приложения. Клиент обращается к серверу с запросами на языке SQL.
3) Модель сервера баз данных. Данную модель поддерживают большинство современных СУБД.. Основу данной модели составляет механизм хранимых процедур как средство программирования SQL-сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры.
В этой модели бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика реализована в виде хранимых процедур — специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, релевантные его запросу, которые требуются клиенту либо для вывода на экран, либо для выполнения части бизнес-логики, которая расположена на клиенте. Трафик обмена информацией между клиентом и сервером резко уменьшается.
Централизованный контроль в модели сервера баз данных выполняется с использованием механизма триггеров. Механизм использования триггеров предполагает, что при срабатывании одного триггера могут возникнуть события, которые вызовут срабатывание других триггеров. Этот мощный инструмент требует тонкого и согласованного применения, чтобы не получился бесконечный цикл срабатывания триггеров.
В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД. И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что. существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях. Для написания хранимых процедур и триггеров используется расширение стандартного языка SQL, так называемый встроенный SQL.
Недостатком данной модели является очень большая загрузка сервера. Действительно, сервер обслуживает множество клиентов и выполняет следующие функции: осуществляет мониторинг событий, связанных с описанными триггерами; обеспечивает автоматическое срабатывание триггеров при возникновении связанных с ними событий; обеспечивает исполнение внутренней программы каждого триггера; запускает хранимые процедуры по запросам пользователей; запускает хранимые процедуры из триггеров; возвращает требуемые данные клиенту; обеспечивает все функции СУБД: доступ к данным, контроль и поддержку целостности данных в БД, контроль доступа, обеспечение корректной параллельной работы всех пользователей с единой БД.
Если мы переложили на сервер большую часть бизнес-логики приложений, то требования к клиентам в этой модели резко уменьшаются. Иногда такую модель называют моделью с «тонким клиентом», в отличие от предыдущих моделей, где на клиента возлагались гораздо более серьезные задачи. Эти модели называются моделями с «толстым клиентом».
Для разгрузки сервера используется трехуровневая модель.
Список литературы
1. Хансен Г., Хансен Д. Базы данных: разработка и управление. – М.: ЗАО «Издательство БИНОМ», 1999 г.
2. Тихомиров Ю. Microsoft SQL Server 7.0 – СПб. Издательство «Питер», 1999 г.
3. Плю Р., Стефенс Р., Райан К. Освой самостоятельно SQL за 24 часа. – М.: Издательский дом «Вильямс», 2000 г.
4. Кандзюба С.П., Громов В.Н. Delphi 6/7. Базы данных и приложения. – СПб: ООО «ДиаСофтЮП», 2002 г.
5. Бобровский С. Delphi 5: учебный курс. – СПб: Издательство «Питер», 2000 г.
6 Базы данных, учебник для высших учебных заведений под редакцией Хомоненко А. СПб.: Издательство «Корона», 2000 г.
7 Карнова Т.Базы данных. - СПб.: Издательство «Питер», 2000 г.
8 Ю. А. Григорьев, Г. И. Ревунrов. Банки данных. - Изд. МГТУ им. Н. Э. Баумана, 2002 г.
9 С.В. Глушаков, Д. В. Ломотько. Базы данных. Учебный курс. М.: Издательский дом «Вильямс», 2000 г.
10 Джек Л. Харрингтон Проектирование реляционных баз данных просто и доступно. – М.:Издательство «Лори», 2000 г.
11 Т.А. Гаврилова, В. Ф. Хорошевский Базы знаний интеллектуальных систем - СПб,: Излательство «Питер», 2000 г.
12 В. В. Корнеев, А. Ф. Гареев и др. Базы данных интеллектуальная обработка информации - М: «Нолидж», 2000 г.
|
Содержание |
с |
|
1 Лекция. Развитие технологии баз данных 1.1 Информационные системы 1.2 Файлы и файловые системы |
|
|
2 Лекция. Информационные системы, использующие базы данных 2 .1 Недостатки файловых систем 2.2 Информационные системы, использующие базы данных |
|
|
3 Лекция. История развития систем управления базами данных 3.1 Базы данных на больших ЭВМ 3.2 Эпоха персональных компьютеров 3.3 Распределенные базы данных 3.4 Перспективы развития систем управления базами данных |
|
|
4 Лекция. Системный анализ предметной области 4.1 Предметная область информационной системы 4.2 Примеры описания предметной области |
|
|
5 Лекция. Принципы проектирования баз данных 5.1 Архитектура базы данных 5.2 Концептуальные модели данных |
|
|
6 Лекция. Концептуальное моделирование данных 6.1 Основные определения концептуальных моделей данных 6.2 Графическое представление концептуальной модели |
|
|
7 Лекция. Разработка ER-диаграммы для предметной области |
|
|
8 Лекция. Примеры концептуального моделирования |
|
|
9 Лекция. Методы моделирования данных |
|
|
10 Лекция. Реляционная модель данных 10.1 Реляционные таблицы и ключи 10.2 Ограничительные условия, поддерживающие целостность данных |
|
|
11 Лекция. Преобразование концептуальной модели в реляционную 11.1 Преобразование объектных множеств и атрибутов 11.2 Преобразование отношений |
|
|
12 Лекция. Нормализация базы данных |
|
|
13 Лекция. Функциональные зависимости и связанные с ними нормальные формы 13.1 Функциональные зависимости и нормальные формы 13.2 Сравнение концептуального и реляционного моделирования |
|
|
14 Лекция. Реализация разработанной реляционной схемы 14.1 Структурированный язык запросов SQL 14.2 Объекты базы данных |
|
|
15 Лекция. Распределенная обработка данных 15.1 Общие сведения 15.2 Модели «клиент—сервер» в технологии баз данных 15.3 Двухуровневые модели Список литературы |
|