Некоммерческое акционерное общество
АЛМАТИНСКИЙ ИНСТИТУТ ЭНЕРГЕТИКИ И СВЯЗИ
Кафедра инженерной кибернетики
ОСНОВЫ СБОРА И ПЕРЕДАЧИ ИНФОРМАЦИИ
Конспект лекций
Для студентов всех форм обучения специальности 050702 –
Автоматизация и управление
Алматы 2008
СОСТАВИТЕЛЬ: Ю.В. Шевяков. Основы сбора и передачи информации. Конспект лекций для студентов всех форм обучения специальности 050702-Автоматизация управления.- Алматы: АИЭС, 2008.-61 с.
В конспекте лекций изложены основы организации, принципы построения, методы и алгоритмы систем сбора и передачи информации. Указанные объекты рассмотрения входят в состав как подсистемы АСУТП, так и могут носить автономный характер и выполнять основное функциональное назначение в SCADA – системах. Конспект лекций предназначен для студентов, обучающихся по специальности 050702 – Автоматизация управления.
Содержание
Введение 5
1 Лекция 1 Организация систем сбора и обработки цифровой информации
ТОУ 5
1.1 Назначение и общие принципы организации АСУТП 5
1.2 Критерии управления 6
1.3 Виды подсистем. 6
1.3.1 Сбор и первичная обработка информации 6
1.3.2 Контроль состояния объекта 6
1.3.3 Автоматическое регулирование и оптимальное управление 6
1.3.4 Расчет технико-экономических показателей 6
1.3.5 Связь с MES – системой (АСУ предприятия) 6
1.4 Состав АСУ ТП 6
1.5 Структурная организация АСУ ТП. 7
1.5.1 Централизованные АСУ ТП. 7
1.5.2 Распределенные АСУ ТП 8
2 Лекция 2 SCADA-системы. Функциональная организация сбора
информации в системах реального времени 9
2.1. Функциональная организация сбора информации в SCADA –
системах 10
2.2 Системы реального времени 10
2.2.1 Режим реального времени [real time processing] 11
3 Лекция 3 SCADA-системы. Алгоритмы первичной обработки информа-
ции 13
3.1 Алгоритмы сбора и первичной обработка информации 13
3.2 Первичная обработка информации 14
3.2.1 Контроль достоверности информации 15
3.2.2 Интерполяция и экстраполяция 15
3.2.3 Фильтрация сигналов измерительной информации 16
4 Лекция 4 SCADA-системы. Пути интеграции АСУП (MES –системы) и
АСУТП (SCADA и DCS) 17
4.1 Уровни информационного взаимодействия систем управления 17
4.2 Реляционные БД и БД реального времени 18
5 Лекция 5 Основы теории кодирования и коды. Помехоустойчивое
кодирование 21
5.1 Помехоустойчивое кодирование 21
5.1.1 Классификация помехоустойчивых кодов 21
5.1.2 Блоковый код. Общие принципы использования избыточности 22
6 Лекция 6 Помехоустойчивое кодирование. Блоковый код 24
6.1 Связь корректирующей способности кода с кодовым расстоянием 25
6.2 Показатели качества корректирующего кода 27
7 Лекция 7 Линейные коды. Математическое введение к линейным кодам 29
7.1 Линейные коды 29
7.2 Математическое введение к линейным кодам 30
8 Лекция 8 Коды с исправлением искажений. Групповые коды 34
8.1 Линейный код как подпространство линейного векторного
пространства 34
8.2 Построение двоичного группового кода 35
9 Лекция 9 Групповые коды. Определение проверочных равенств 38
9.1 Случай исправления одиночных и двойных независимых ошибок 38
9.2 Определение проверочных равенств 40
10 Лекция 10 Матричное представление линейных кодов 43
10.1 Матричное представление линейных кодов 43
10.2 Образующая матрица линейного кода 44
11 Лекция 11 Циклические коды. Математические основы для построения
циклических кодов 47
11.1 Построение циклических кодов 48
11.2 Математическое введение к циклическим кодам 50
12 Лекция 12 Циклические коды. Определение образующего многочлена 51
12.1 Требования, предъявляемые к образующему многочлену 51
12.2 Выбор образующего многочлена по заданному объёму кода и заданной корректирующей способности 52
12.2.1 Обнаружение одиночных ошибок 53
12.2.2 Исправление одиночных или обнаружение двойных ошибок 53
13 Лекция 13 Циклические коды. Математические основы для построения
циклических кодов 55
13.1 Выбор неприводимого многочлена g(x) 55
13.2 Обнаружение и исправление независимых ошибок произвольной
кратности 56
13.2.1 Обнаружение и исправление пачек ошибок 57
13.3 Методы образования циклического кода 57
13.4 Матричная запись циклического кода 58
13.5 Укороченные циклические коды 59
Список литературы 61
Введение
SCADA-системы ответственны лишь за уровень промышленной автоматизации, связанный с получением данных от различных датчиков и устройств ввода/вывода, с визуализацией собранной информации и её архивацией. Доступ же к этой информации со стороны руководителя предприятия, а также руководителей экономических подразделений до недавнего времени был лишь опосредованным. Для анализа производства в целом, для моделирования его отдельных этапов, для выявления критических участков и слабых звеньев важна организация доступа к данным, отражающим весь процесс производства, с возможностью воздействия на него, в том числе и в реальном времени.
Для реализации подобных задач автоматизации промышленных предприятий в целом попытки создания интегрированных систем автоматизации, реализующих функции SCADA-систем, ERP-систем и, в целом, MES-систем, основным направлением определяется создание единого информационного пространства базирующегося на технологической информации в цифровой форме собранной и обработанной в реальном времени.
В распределённых микропроцессорных системах управления алгоритмы первичной обработки информации реализуются в виде стандартных модулей базового программного обеспечения микропроцессорных контроллеров.
Наряду с традиционной формой рассмотрения методов и алгоритмов построения коммутируемых линий связи подсистем сбора, первичной обработки и передачи информации, рассматриваются способы передачи информации во времени с использованием баз данных реального времени.
1 Лекция 1 Организация систем сбора и обработки цифровой информации ТОУ
Цель лекции: определение основных функций информационных подсистем в системах управления разного уровня.
Содержание лекции: классификация систем управления технологическими объектами управления. Подсистемы АСУТП. Основные функции SCADA – систем.
1.1 Назначение и общие принципы организации АСУТП
АСУТП - человеко-машинная система, в которой человек принимает содержательное участие в выработке решения.
АСУТП осуществляет воздействие на объект в том же, что и протекающие в нем процессы, т.е. АСУТП работает в режиме реального времени. В АСУТП в качестве объекта выступает ТОУ (технологический объект управления).
ТОУ представляет собой совокупность технологического оборудования и реализуемого на нем по соответствующим инструкциям и регламентам технологического процесса производства целевого продукта.В качестве ТОУ в АСУТП рассматриваются технологические установки, отдельные производства и технологические процессы всего предприятия.
При создании АСУТП необходимо определить цель этой системы.
Степень достижения поставленной цели принято характеризовать с помощью
критериев управления.
1.2 Критерии управления
Критерий управления должен быть обязательно выражен количественно и зависеть от выбранных управляющих воздействий.
1.3 Виды подсистем
АСУТП реализует свои функции с помощью следующих подсистем.
1.3.1 Сбор и первичная обработка информации:
- сбор информации с ТОУ;
- проверка достоверности информации ;
- фильтрация сигналов измерительной информации ;
- расчет действительных значений параметров;
- усреднение и интегрирование значений параметров.
1.3.2 Контроль состояния объекта:
- отображение информации ;
- контроль и регистрация отклонения параметров от заданных значений;
- анализ срабатывания блокировок и защит.
1.3.3 Автоматическое регулирование и оптимальное управление:
- стабилизация технологических параметров;
- каскадное и связанное регулирование;
- логическое управление;
- дискретное, программное управление задвижками;
- статическая оптимизация.
1.3.4 Расчет технико-экономических показателей:
- расчет себестоимости продукции;
- расчет материального баланса.
1.3.5 Связь с MES – системой (АСУ предприятия):
- передача сообщений на верхний уровень;
- прием сообщений с верхнего уровня.
1.4 Состав АСУ ТП


Рисунок 1.1- Составные части АСУ
Оперативный персонал состоит из операторов технологов, осуществляющих контроль и управление объектом, и эксплуатационного персонала, обеспечивающего функционирование технических средств систем.
Организационное обеспечение представляет собой совокупность документов, устанавливающих порядок и правила функционирования оперативного персонала.
Сюда входят:
1) технологические инструкции и регламенты, определяющие ведение процесса в нормальной, предаварийной и аварийной ситуации;
2) инструкции по эксплуатации системы.
В состав программного обеспечения входят:
1) операционная система;
2) система управления базовых данных (СУБД);
3) специализированное программное обеспечение.
1.5 Структурная организация АСУ ТП
1.5.1 Централизованные АСУ ТП
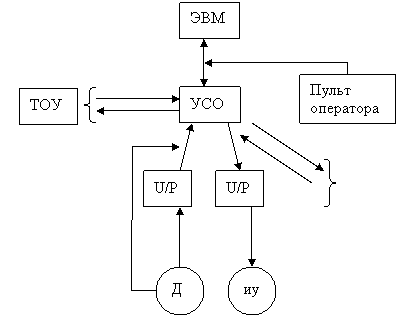

Рисунок 1.2 - Централизованная система управления ТОУ
УСО - устройство связи с объектом.
В состав УСО входят :
- АЦП ( аналого-цифровой преобразователь);
- ЦАП (цифро - аналоговый преобразователь);
- коммутатор.
Минусы:
- многочисленные кабели,связывающие датчики с объектом;
- поломка ЭВМ (много резервов).
1.5.2 Распределенные АСУ ТП
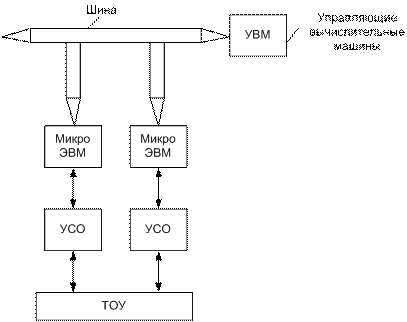
Рисунок 1.3 - Распределённая система управления ТОУ
С появлением цифровых датчиков появилась возможность не только обрабатывать информацию в цифровой форме, но и передавать эту информацию в цифровой форме. Цифровая передача данных между отдельными устройствами сделала основой построения АСУ вычислительную сеть. Такая вычислительная сеть используется для создания резервов для пользователей, расположенных на небольшой территории, поэтому такая сеть называется локальной.
В настоящее время различают 2 типа распределения систем управления:
1- SCADA – системы;
2- DCS – системы.
SCADA – Supervisory Control and Data Acquisition – система сбора данных и управления.
DCS – Distributed Control System – децентрализованные системы управле-ния.
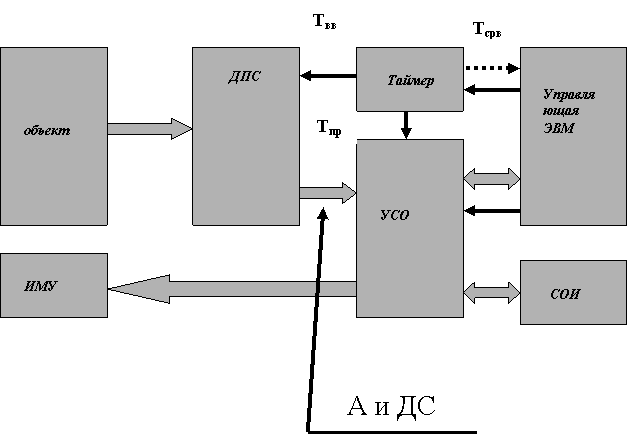
Рисунок 1.4 -Функционально - структурная схема SCADA - системы
2 Лекция 2 SCADA-системы. Функциональная организация сбора информации в системах реального времени
Цель лекции: определения и основные функции информационных подсистем в системах управления реального времени.
Содержание лекции: определение систем реального времени. Временная организация SCADA – систем.
2.1 Функциональная организация сбора информации в SCADA – системах
SCADA-системы это уровень промышленной автоматизации, связанный с получением данных от различных датчиков и устройств ввода/вывода, с визуализацией собранной информации и её архивацией. Для анализа производства в целом, для моделирования его отдельных этапов, для выявления критических участков и слабых звеньев важна организация доступа к данным, отражающим весь процесс производства, с возможностью воздействия на него, в том числе и в реальном времени. Для реализации подобных задач автоматизации промышленных предприятий в целом попытки создания интегрированных систем автоматизации, реализующих функции SCADA-систем, ERP-систем и, в целом, MES-систем, основным направлением определяется создание единого информационного пространства базирующегося на технологической информации в цифровой форме собранной и обработанной в реальном времени.

Рисунок 2.1 - Обобщенная структура систем типа SCADA
2.2 Системы реального времени
Real-time system система реального времени (СРВ) это любая система, в которой существенную роль играет время генерации выходного сигнала. Это обычно связано с тем, что входной сигнал соответствует каким-то изменениям в физическом процессе, и выходной сигнал должен быть связан с этими же изменениями. Временная задержка от получения входного сигнала до выдачи выходного сигнала должна быть небольшой, чтобы обеспечить приемлемое время реакции. Время реакции является системной характеристикой: при управлении ракетой требуется реакция в течении нескольких миллисекунд, тогда как для диспетчерского управления движением пароходов требуется время реакции, измеряемое днями.
Системы обычно считаются системами реального времени, если время их реакции имеет порядок миллисекунд; диалоговыми считаются системы с временем реакции порядка нескольких секунд, а в системах пакетной обработки время реакции измеряется часами или днями. Примерами систем реального времени являются системы управления физическими процессами с применением вычислительных машин, системы торговых автоматов, автоматизированные системы контроля и автоматизированные испытательные комплексы.
2.2.1 Режим реального времени [real time processing].
Режим обработки данных, при котором обеспечивается взаимодействие вычислительной системы с внешними по отношению к ней процессами в темпе, соизмеримом со скоростью протекания этих процессов.
Пример – цикл управления самолетом, летящим на автопилоте. Датчики самолета должны постоянно передавать измеренные данные в управляющий компьютер. Если данные измерений теряются, то качество управления самолетом падает, возможно вместе с самолетом.
Пример – выделение самостоятельных программно-технических комплексов с функциями сбора, первичной обработки и передачи информации (PI System ). PI System предоставляет информацию о технологических процессах в реальном масштабе времени на уровень управления производством и бизнес-систем для специалистов среднего и верхнего звеньев предприятия.
PI
System - это инструмент построения информационной системы производства
реального времени для промышленного предприятия. PI System наилучшим образом
обеспечивает сбор, хранение и представление в едином формате данных от
различных SCADA-систем, DCS, ПЛК, устройств ручного ввода, заводских
лабораторий и т. п.
Рисунок 2.2- Функциональный состав системы реального времени
На рисунке 2.3 представлена циклограмма функционирования системы реального времени. Из циклограммы видно, что организация реального времени обеспечивается функционированием подсистемы сбор и первичной обработки информации
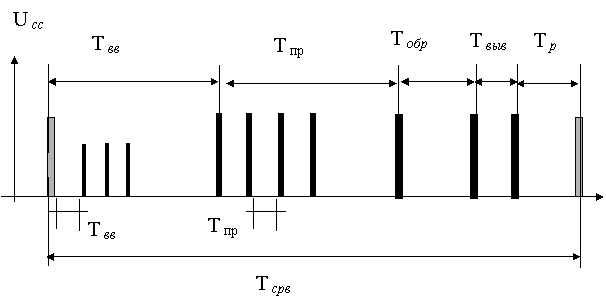

![]() Рисунок 2.3 - Циклограмма функционирования системы реального времени.
Рисунок 2.3 - Циклограмма функционирования системы реального времени.
3 Лекция 3 SCADA-системы. Алгоритмы первичной обработки
информации
Цель лекции: определение и изучение алгоритмов первичной обработки информации информационных подсистем реального времени.
Содержание лекции: алгоритмы сбора и первичной обработки информации. Алгоритмы контроля достоверности информации. Интерполяция и экстраполяция. Фильтрация сигналов измерительной информации.
3.1 Алгоритмы сбора и первичной обработки информации
Организация сбора информации в автоматизированных системах управления (SCADA-системах) определяет получение информации от датчиков технологических переменных ТОУ в цифровой форме в соответствии с алгоритмом общего функционирования (циклограмма СРВ, лекция 2)
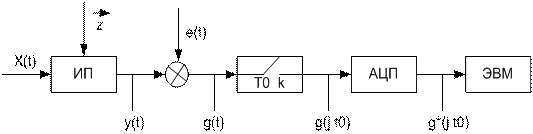
Рисунок 3.1- Информации от датчиков технологических переменных ТОУ в цифровой форме

Рисунок 3.2- Схема организации сбора информации
x(t) – сигнал измерительной информации
g(t) – выходная величина преобразователя (полезный сигнал)
z – влияющие факторы
g(t) – смесь полезного сигнала и помехи
к – коммутатор
Пример реализации переменной Х при измерении температуры термопарой:

где:
![]()
t – температура горячего спая – x
t0 – температура холодного спая z0
Если z0 ![]() - номинальная статическая
характеристика
- номинальная статическая
характеристика
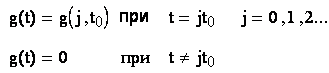
Далее идет квантование по уровню, в результате чего получаем y*(j t0).
3.2 Первичная обработка информации
Группа алгоритмов, хранящейся в ЭВМ в числовом значении параметра, называется алгоритмами первичной обработки информации. Основные алгоритмы первичной обработки информации:
1. Контроль достоверности информации
2. Интерполяция и экстраполяция
3. Фильтрация сигналов измерительной информации
4. Аналитическая градуировка датчиков
5. Коррекция восстановленных значений.
3.2.1 Контроль достоверности информации
Наиболее часто встречающимися причинами недостоверности информации являются:
1) неисправности датчиков и преобразователей;
2) влияние помех в линиях связи;
3) ухудшение метрологических характеристик ИП.
Контроль достоверности информации осуществляется путем сравнения:
- контроль по верхним и нижним пределам

- контроль по скорости изменения значений.
Если скорость изменяется по температуре => сбой
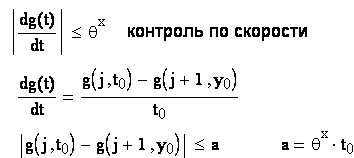
3.2.2 Интерполяция и экстраполяция
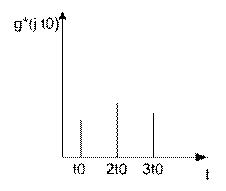
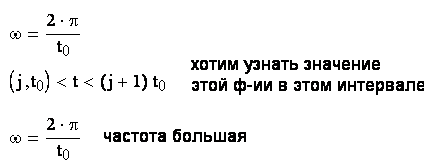
применяют ступенчатую интерполяцию (интерполяцию нулевого порядка). Поскольку интервалы очень малы, то
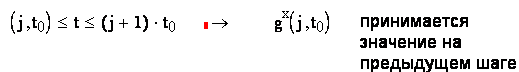 .
.
3.2.3 Фильтрация сигналов измерительной информации
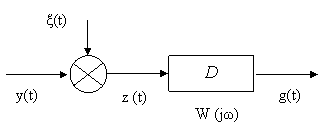 |
Рисунок 3.3- Фильтрация сигналов измерительной информации
Входной сигнал представляет собой случайный процесс z
(t) при
-∞ < t <
∞ и пусть z (t) представляет собой смесь ( не обязательно аддитивную
) полезного сигнала y(t) и помехи ξ(t). Требуется построить систему (фильтр Ф) такой обработки
входного сигнала, которая позволила бы получить на выходе желаемый сигнал g(t), являющийся результатом определённой операции D над одним лишь
полезным сигналом: ![]()
На практике применяют следующие частные случаи, когда:
а) g(t) = y(t) (-α) – задача фильтрации и сглаживания;
б) g(t) = y(t) - задача фильтрации;
в) g(t) = y(t) (+α) - задача фильтрации и упреждения;
где α >0.
С точки зрения требований к объёму вычислений выгодно использовать для (α) фильтр экспоненциального сглаживания:
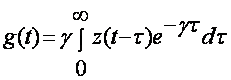 ,
(3.1)
,
(3.1)
где
![]() - параметр фильтра.
- параметр фильтра.
Дискретный вариант фильтра (3.1) применяется в подсистемах сбора и передачи информации, а также в системах SCADA :
![]() , (3.2)
, (3.2)
где z[n] – значение входного сигнала в момент времени nΔt
(Δt – интервал дискретизации);
![]() - параметр
фильтра (0 <
- параметр
фильтра (0 < ![]() <1).
<1).
Кроме этого, в системах часто применяются фильтры - статистический фильтр и фильтр скользящего среднего.
4 Лекция 4 SCADA-системы. Пути интеграции АСУП (MES –системы) и АСУТП (SCADA и DCS)
Цель лекции: определение и основные проблемы создания единого информационного пространства в системах управления реального времени и АСУП (MES –системы).
Содержание лекции: уровни информационного взаимодействия систем управления. Реляционные БД и БД реального времени
4.1 Уровни информационного взаимодействия систем управления
Две подсистемы автоматизации промышленных предприятий АСУП, включающая системы автоматизации управленческой и финансово-хозяйственной деятельности и системы планирования ресурсов предприятия, и АСУТП (системы автоматизации технологических и производственных процессов) развивались обособленно и независимо друг от друга (см. рисунок 4.1). Это сложившееся разделение и отражено на рисунке 4.1, где уровень управления процессом производства целиком отнесён к подсистеме АСУП. Однако в реальности чёткой границы между уровнем управления производством и АСУТП нет, а напротив, есть их некое перекрывание, в силу взаимной неразрывности выполняемых функций.

Рисунок 4.1- Уровни информационного взаимодействия систем управления
В подсистемах АСУТП принципиально важной является работа в реальном времени. Негарантированное время реакции на событие в технологическом процессе недопустимо. Различные каналы обмена (а соответственно, и протоколы) характеризуются соответствующими приоритетами, которые зависят от степени ответственности выполняемых задач (алармы, архивы, работа с таблицами РБД).
Наличие общих свойств программного обеспечения обеих подсистем позволяет говорить о том, что объективные возможности для интеграции созрели. Благодаря уже существующим единым сетевым протоколам и современным информационным технологиям есть все необходимые предпосылки для успешного решения этих задач. Рассмотрим следующие способы интеграции подсистем уровней АСУП и АСУТП:
Ø использование баз данных, в том числе в качестве буфера между различными подсистемами, позволяет обеспечивать оперативный обмен данными между подсистемами. Причем БД являются как основой функционирования самих подсистем, так и средством, используемым для хранения функциональных данных. Именно БД, скорее всего, могут стать основным средством интеграции двух подсистем;
Ø применение класса продуктов, главным назначением которых является импортирование объектов из одной подсистемы и экспортирование их в другую подсистему.
4.2 Реляционные БД и БД реального времени
С помощью СУБД решаются проблемы, связанные с огромными объемами дублированной и иногда противоречивой информации в системах управления технологическими процессами, предоставляемой различными и, зачастую, несовместимыми друг с другом способами. Использование традиционных реляционных баз данных, ориентированных на MES - системы , не всегда возможно в системах управления технологическими процессами. Этому препятствуют несколько основных ограничений:
Ø производственные процессы генерируют данные очень быстро. Чтобы хранить производственный архив системы, например, с 7500 рабочими переменными, в БД каждую секунду необходимо вставлять 7500 строк. Обычные БД не могут выдержать подобную нагрузку;
Ø объёмы производственной информации настолько велики, что она просто не вмещается в традиционную БД. Например, многомесячный архив завода с 7500 рабочими переменными требует под БД около 1 Терабайта дисковой памяти. Сегодняшние технологии такими объемами манипулировать не могут;
Ø SQL как язык не подходит для обработки временных или периодических данных, типичных для производственных систем. В частности, чрезвычайно трудно указать в запросе периодичность выборки возвращаемых данных.
Результатом преодоления этих ограничений стало появление класса продуктов, называемых базами данных реального времени (БДРВ). Отмечаются две концепции создания БДРВ: новая независимая разработка БД или разработка БДРВ на основе известных реляционных БД, например, MS SQL Server. Более перспективным представляется второй способ, поскольку, во-первых, он дешевле, а во-вторых, технологичнее . В качестве примера реализации БДРВ отметим, например, IndustrialSQL Server (компания Wonderware) и Plant2SQL (Ci Technologies). Основные функции БДРВ, построенные на основе MS SQL Server заключаются в следующем:
Ø сохранение некритичной во времени информации в БД Microsoft SQL Server, в то время как вся технологическая информация сохраняется в специальном формате;
Ø поддержание высокой пропускной способности, что обеспечивает сохранение огромных потоков информации с высокой разрешающей способностью;
Ø поддержание целостности данных, что обеспечивает запись больших объемов информации без потерь;
Ø добавление в Microsoft SQL Server свойств сервера реального времени.
В настоящее время БДРВ являются продуктами, ориентированными на хранение технологической информации, на обеспечение связи с управленческими данными, на использование уже ставших стандартными в подсистемах АСУП интерфейсов OLE DB, Internet. На рисунке 4.2 показаны информационные потоки. С одной стороны это данные, поступающие из различных технологических источников для сохранения в БД, с другой данные, запрашиваемые потребителями через интерфейс SQL-сервера.
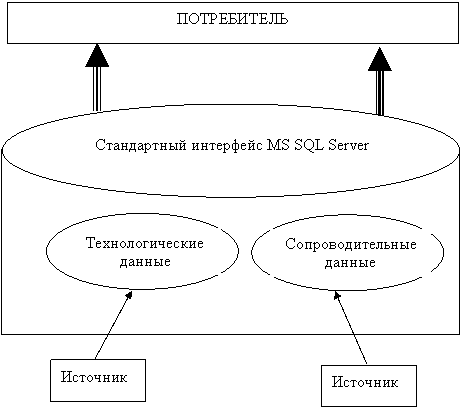 |
Рисунок 4.2 - БДРВ на основе MS SQL Server
Используемая в БДРВ архитектура клиент-сервер позволяет заполнить промежуток между промышленными системами контроля и управления реального времени, для которых характерны большие объемы информации, и открытыми гибкими управленческими информационными системами.
Следует подчеркнуть, что в зависимости от требований создаваемой системы возможны следующие варианты решений:
a) использование только РБД, в таблицы которой подсистема АСУТП по SQL-запросам записывает технологические данные; в дальнейшем последние могут быть использованы обеими подсистемами;
b) использование БДРВ, которые обеспечивают более высокие характеристики регистрации данных и упрощают (без использования SQL) процесс внесения данных в таблицы;
c) построение комбинированного решения, предполагающего использование БДРВ для технологических первичных данных и таблиц РБД для вторичной информации.
5 Лекция 5 Основы теории кодирования и коды. Помехоустойчивое
кодирование
Цель лекции: определение и изучение методов теории кодирования, применяемых в информационных подсистемах АСУ.
Содержание лекции: принципы помехоустойчивого кодирования. Определение и классификация корректирующих кодов. Блоковый код.
5.1 Помехоустойчивое кодирование
Бурный рост теории и практики помехоустойчивого кодирования в последнее десятилетие связан, в первую очередь, с созданием средств телеобработки данных, вычислительных систем и сетей, региональных автоматизированных систем управления, систем автоматизации научных исследований. Высокие требования к достоверности передачи, обработки и хранения информации в указанных системах диктовали необходимость такого кодирования информации, которое обеспечивало бы возможность обнаружения и исправления ошибки.
В этом случае кодирование должно осуществляться так, чтобы сигнал, соответствующий принятой последовательности символов, после воздействия на него предполагаемой в канале помехи оставался ближе к сигналу, соответствующему конкретной переданной последовательности символов, чем к сигналам, соответствующим другим возможным последовательностям. Степень близости обычно определяется по числу разрядов, в которых последовательности отличаются друг от друга.
Это достигается ценой введения при кодировании избыточности, которая позволяет так выбрать передаваемые последовательности символов, чтобы они удовлетворяли дополнительным условиям, проверка которых на приемной стороне дает возможность обнаружить и исправить ошибки.
Коды, обладающие таким свойством, называют помехоустойчивыми. Они используются как для исправления ошибок (корректирующие коды), так и для их обнаружения.
5.1.1 Классификация помехоустойчивых кодов
У подавляющего большинства существующих в настоящее время помехоустойчивых кодов указанные условия являются следствием их алгебраической структуры. В связи с этим их называют алгебраическими кодами. (В отличие, например, от кодов Вагнера, корректирующее действие которых базируется на оценке вероятности искажения каждого символа).
Алгебраические коды можно подразделить на два больших класса: блоковые и непрерывные.
В случае блоковых кодов процедура кодирования заключается в сопоставлении каждой букве сообщения (или последовательности из k символов, соответствующей этой букве) блока из п символов. В операциях по преобразованию принимают участие только указанные k символов, и выходная последовательность не зависит от других символов в передаваемом сообщении.
Блоковый код называют равномерным, если п остается постоянным для всех букв сообщения.
Различают разделимые и неразделимые блоковые коды. При кодировании разделимыми кодами выходные последовательности состоят из символов, роль которых может быть отчетливо разграничена. Это информационные символы, совпадающие с символами последовательности, поступающей на вход кодера канала, и избыточные (проверочные) символы, вводимые в исходную последовательность кодером канала и служащие для обнаружения и исправления ошибок.
При кодировании неразделимыми кодами разделить символы выходной последовательности на информационные и проверочные невозможно.
Непрерывными (древовидными) называют такие коды, в которых введение избыточных символов в кодируемую последовательность информационных символов осуществляется непрерывно, без разделения ее на независимые блоки. Непрерывные коды также могут быть разделимыми и неразделимыми.
Наиболее простыми в отношении технической реализации кодами этого класса являются сверточные (рекуррентные) коды.
5.1.2 Блоковый код. Общие принципы использования избыточности
Способность кода обнаруживать и исправлять ошибки обусловлена наличием избыточных символов. На вход кодирующего устройства поступает последовательность из k информационных двоичных символов. На выходе ей соответствует последовательность из п двоичных символов, причем n>k.
Всего может быть 2k различных входных и 2n различных
выходных последовательностей. Из общего числа 2 n выходных последовательностей только 2k последовательностей соответствуют входным. Назовем их разрешенными кодовыми комбинациями.
|
|
Остальные 2n — 2k возможных выходных последовательностей для передачи не используются. Назовем их запрещенными комбинациями.
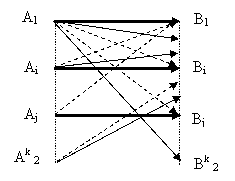 |
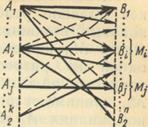
Рисунок 5.1- Варианты передачи информации с помехами
Искажение информации в процессе передачи сводится к тому, что некоторые из переданных символов заменяются другими - неверными. Так как каждая из 2k разрешенных комбинаций в результате действия помех может трансформироваться в любую другую, то всего имеется 2k• 2n возможных случаев передачи (см. рисунок 5.1). В это число входят:
2k случаев безошибочной передачи (на рисунке 5.1 обозначены жирными линиями);
2 k (2 k -1) случаев перехода в другие разрешенные комбинации, что соответствует не обнаруживаемым ошибкам (на рисунке 5.1 обозначены пунктирными линиями);
2k(2n - 2k) случаев перехода в неразрешенные комбинации, которые могут быть обнаружены (на рисунке 5.1 обозначены тонкими сплошными линиями).
Следовательно, часть обнаруживаемых ошибочных кодовых комбинаций от общего числа возможных случаев передачи составляет:
2k(2n - 2k) / 2k • 2n = 1 — 2k / 2n . (5.1)
Пример
Определим обнаруживающую способность кода, каждая комбинация которого содержит всего один избыточный символ ( n = k+1 ). Общее число выходных последовательностей составляет 2k+1, т. е. вдвое больше общего числа кодируемых входных последовательностей. За подмножество разрешенных кодовых комбинаций можно принять, например, подмножество 2k комбинаций, содержащих четное число единиц (или нулей).
При кодировании к каждой последовательности из k информационных символов добавляется один символ (0 или 1) такой, чтобы число единиц в кодовой комбинации было четным. Искажение любого нечетного числа символов переводит разрешенную кодовую комбинацию в подмножество запрещенных комбинаций, что обнаруживается на приемной стороне по нечетности числа единиц. Часть опознанных ошибок составляет
1 - 2k / 2k+1 = 1/2. (5.2)
Рассмотрим случай исправления ошибок.
Любой метод декодирования можно рассматривать как правило разбиения всего множества запрещенных кодовых комбинаций на 2k непересекающихся подмножеств Mi, каждое из которых ставится в соответствие одной из разрешенных комбинаций. При получении запрещенной комбинации, принадлежащей подмножеству Mi, принимают решение, что передавалась разрешенная комбинация Ai. Ошибка будет исправлена в тех случаях, когда полученная комбинация действительно образовалась из Ait, т.е. 2n —2k случаях.
Всего случаев перехода в неразрешенные комбинации 2k(2n - 2k). Таким образом, при наличии избыточности любой код способен исправлять ошибки. Отношение числа исправляемых кодом ошибочных кодовых комбинаций к числу обнаруживаемых ошибочных комбинаций равно
(2n -2k )/ [2k(2n -2k)] = 1 / 2k . (5.3)
Способ разбиения на подмножества зависит от того, какие ошибки должны исправляться данным конкретным кодом.
Большинство разработанных до настоящего времени кодов предназначено для корректирования взаимно независимых ошибок определенной кратности и пачек (пакетов) ошибок.
Взаимно независимыми ошибками будем называть такие искажения в передаваемой последовательности символов, при которых вероятность появления любой комбинации искаженных символов зависит только от числа искаженных символов r и вероятности искажения одного символа р.
Кратностью ошибки называют количество искаженных символов в кодовой комбинации.
При взаимно независимых ошибках вероятность искажения любых r символов в n-разрядной кодовой комбинации
Pr= C r n P r(1 – P) n -r (5.4)
Если учесть, что p<<1, то в этом случае наиболее вероятны ошибки низшей кратности. Их и следует обнаруживать и исправлять в первую очередь.
6 Лекция 6 Помехоустойчивое кодирование. Блоковый код
Цель лекции: определение и изучение методов теории кодирования, применяемых в информационных подсистемах АСУ.
Содержание лекции: принципы помехоустойчивого кодирования. Характеристики корректирующего кода.
6.1 Связь корректирующей способности кода с кодовым расстоянием
Как было рассмотрено ранее, при взаимно независимых ошибках наиболее вероятен переход в кодовую комбинацию, отличающуюся от данной в наименьшем числе символов.
Степень отличия любых двух кодовых комбинаций характеризуется расстоянием между ними в смысле Хэмминга или просто кодовым расстоянием. Оно выражается числом символов, в которых комбинации отличаются одна от другой, и обозначается через d.
Чтобы получить кодовое расстояние между двумя комбинациями двоичного кода, достаточно подсчитать число единиц в сумме этих комбинаций по модулю 2. Например:
1001111101
![]() 1100001010
1100001010
0101110111, d = 7.
Минимальное расстояние, взятое по всем парам кодовых разрешенных комбинаций кода, называют минимальным кодовым расстоянием.
Декодирование после приема может производиться таким образом, что принятая кодовая комбинация отождествляется с той разрешенной, которая находится от нее на наименьшем кодовом расстоянии.
Такое декодирование называется декодированием по методу максимального правдоподобия.
Очевидно, что при d = 1 все кодовые комбинации являются разрешенными.
Например, при п = 3 разрешенные комбинации образуют следующее множество: 000, 001, 010, 011, 100, 101, 110, 111.
Любая одиночная ошибка трансформирует данную комбинацию в другую разрешенную комбинацию. Это случай безызбыточного кода, не обладающего корректирующей способностью.
Если d = 2, то ни одна из разрешенных кодовых комбинаций при одиночной ошибке не переходит в другую разрешенную комбинацию. Например, подмножество разрешенных кодовых комбинаций может быть образовано по принципу четности в них числа единиц, как это приведено ниже для п = 3:
000, 011, 101, 110 - разрешенные комбинации
001, 010, 100, 111 - запрещенные комбинации
Код обнаруживает одиночные ошибки, а также другие ошибки нечетной кратности (при п = 3 тройные). В общем случае при необходимости обнаруживать ошибки кратности до r включительно минимальное хэммингово расстояние между разрешенными кодовыми комбинациями должно быть по крайней мере на единицу больше r, т. е.
d0 min ≥ r +l. (6.1)
Действительно, в этом случае ошибка, кратность которой не превышает r, не в состоянии перевести одну разрешенную кодовую комбинацию в другую.
Для исправления одиночной ошибки каждой разрешенной кодовой комбинации необходимо сопоставить подмножество запрещенных кодовых комбинаций. Чтобы эти подмножества не пересекались, хэммингово расстояние между разрешенными кодовыми комбинациями должно быть не менее трех. При п = 3 за разрешенные комбинации можно, например, принять 000 или 111. Тогда разрешенной комбинации 000 необходимо приписать подмножество запрещенных кодовых комбинаций 001, 010, 100, образующихся в результате возникновения единичной ошибки в комбинации 000.
Подобным же образом разрешенной комбинации 111 необходимо приписать подмножество запрещенных кодовых комбинаций: 110, 011, 101, образующихся в результате возникновения единичной ошибки в комбинации 111:
001
010
Разрешённые 000 100 Запрещённые
комбинации 111 011 комбинации
101
110
В общем случае для обеспечения возможности исправления всех ошибок кратности до s включительно при декодировании по методу максимального правдоподобия каждая из ошибок должна приводить к запрещенной комбинации, относящейся к подмножеству исходной разрешенной кодовой комбинации.
Подмножество каждой из разрешенных n - разрядных комбинаций Bi (см. рисунок 6.1) складывается из запрещенных комбинаций, являющихся следствием воздействия:
единичных
ошибок (они располагаются на сфере радиусом d=1, и
их число равно ![]() ,
,
Рисунок 6.1- Разрешающая способность кодов
двойных ошибок (они располагаются на
сфере радиусом d = 2, и их число равно![]() ) и т. д.
) и т. д.
Внешняя
сфера подмножества имеет радиус d = s и содержит![]() запрещенных кодовых комбинаций.
запрещенных кодовых комбинаций.
Поскольку указанные подмножества не должны пересекаться, минимальное хэммингово расстояние между разрешенными комбинациями должно удовлетворять соотношению
dn min ≥ 2s + l. (6.1)
Нетрудно убедиться в том , что для исправления всех ошибок кратности s и одновременного обнаружения всех ошибок кратности r(r≥s) минимальное хэммингово расстояние нужно выбирать из условия
d n 0 min ≥ r +s+l. (6.2)
Формулы, выведенные для случая взаимно независимых ошибок, дают завышенные значения минимального кодового расстояния при помехе, коррелированной с сигналом.
В реальных каналах связи длительность импульсов помехи часто превышает длительность символа. При этом одновременно искажаются несколько расположенных рядом символов комбинации. Ошибки такого рода получили название пачек ошибок или пакетов ошибок. Длиной пачки ошибок называют число следующих друг за другом символов, начиная с первого искаженного символа и кончая искаженным символом, за которым следует не менее ρ неискаженных символов. Основой для выбора ρ служат статистические данные об ошибках. Если, например, кодовая комбинация 00000000000000000 трансформировалась в комбинацию 01001000010101000 и ρ принято равным трем, то в комбинации имеется два пакета длиной 4 и 5 символов.
Применение корректирующего кода не может гарантировать безошибочного приема, но дает возможность повысить вероятность получения на выходе правильного результата.
6.2 Показатели качества корректирующего кода
Одной из основных характеристик корректирующего кода является избыточность кода, указывающая степень удлинения кодовой комбинации для достижения определенной корректирующей способности. Если на каждые п символов выходной последовательности кодера канала приходится k информационных и п — k проверочных, то относительная избыточность кода может быть выражена одним из соотношений
Rn= (n – k ) / n (6.3)
или
Rn= (n – k ) / k (6.4)
Величина Rk, изменяющаяся от 0 до ∞, предпочтительнее, так как лучше отвечает смыслу понятия избыточности. Коды, обеспечивающие заданную корректирующую способность при минимально возможной избыточности, называют оптимальными.
В связи с нахождением оптимальных кодов оценим, например, наибольшее возможное число Q разрешенных комбинаций n-значного двоичного кода, обладающего способностью исправлять взаимно независимые ошибки кратности до s включительно. Это равносильно отысканию числа комбинаций, кодовое расстояние между которыми не менее d = 2s +1.
Общее число различных исправляемых ошибок для каждой разрешенной
комбинации составляет ![]() .
.
Каждая из
таких ошибок должна приводить к запрещенной комбинации, относящейся к
подмножеству данной разрешенной комбинации. Совместно с этой комбинацией
подмножество включает 1 + ![]() комбинаций.
комбинаций.
Как отмечалось, однозначное декодирование возможно только в том случае, когда названные подмножества не пересекаются. Так как общее число различных комбинаций n-значного двоичного кода составляет 2n , число разрешённых комбинаций не может превышать
![]()
или
Q
≤ 2n / ![]() .
.
Эта верхняя оценка найдена Хэммингом. Для некоторых конкретных значений кодового расстояния d соответствующие Q указаны в таблице 6.1
Т а б л и ц а 6.1
|
d |
Q |
d |
Q |
|
1 |
2n |
5 |
|
|
2 |
≤2 n -1 |
… |
|
|
3 |
|
… |
|
|
4 |
|
2k + 1 |
|
Коды, для которых в приведенном соотношении достигается равенство, называют также плотноупакованными.
Однако не всегда целесообразно стремиться к использованию кодов, близких к оптимальным. Необходимо учитывать другой, не менее важный показатель качества корректирующего кода - сложность технической реализации процессов кодирования и декодирования.
Если информация должна передаваться по медленно действующей, ненадежной и дорогостоящей линии связи, а кодирующее и декодирующее устройства предполагается выполнить на высоконадежных и быстродействующих элементах, то сложность этих устройств не играет существенной роли. Решающим фактором в таком случае является повышение эффективности использования линии связи и поэтому желательно применение корректирующих кодов с минимальной избыточностью.
Если же корректирующий код должен быть применен в системе, выполненной на элементах, надежность и быстродействие которых равны или близки надежности и быстродействию элементов кодирующей и декодирующей аппаратуры (например, для повышения достоверности воспроизведения информации с запоминающего устройства цифровой вычислительной машины), то критерием качества корректирующего кода является надежность системы в целом, т. е. с учетом возможных искажений и отказов в устройствах кодирования и декодирования. В этом случае часто более целесообразны коды с большей избыточностью, но обладающие преимуществом простоты технической реализации.
7 Лекция 7 Линейные коды. Математическое введение к
линейным кодам
Цель лекции: определение и изучение методов теории кодирования, применяемых в информационных подсистемах АСУ.
Содержание лекции: принципы помехоустойчивого кодирования. Линейные коды. Описание линейных кодов с использованием представлений линейной алгебры.
7.1 Линейные коды
Самый большой класс разделимых кодов составляют линейные коды, у которых значения проверочных символов определяются в результате
проведения линейных операций над определенными информационными символами. Для случая двоичных кодов каждый проверочный символ выбирают таким, чтобы его сумма с определенными информационными символами была равна нулю. Символ проверочной позиции имеет значение 1, если число единиц информационных разрядов, входящих в данное проверочное равенство, нечетно, и 0, если оно четно. Число проверочных равенств (а следовательно, и число проверочных символов) и номера конкретных информационных разрядов, входящих в каждое из равенств, определяется тем, какие и сколько ошибок должен исправлять или обнаруживать данный код. Проверочные символы могут располагаться на любом месте кодовой комбинации.
При декодировании определяется справедливость проверочных равенств. В случае двоичных кодов такое определение сводится к проверкам на четность числа единиц среди символов, входящих в каждое из равенств (включая проверочный). Совокупность проверок дает информацию о том, имеется ли ошибка, а в случае необходимости и о том, на каких позициях символы искажены.
Любой двоичный линейный код является групповым, так как совокупность входящих в него кодовых комбинаций образует группу. Уточнение понятий линейного и группового кода требует ознакомления с основами линейной алгебры.
7.2 Математическое введение к линейным кодам
Основой математического описания линейных кодов является линейная алгебра (теория векторных пространств, теория матриц, теория групп). Кодовые комбинации рассматривают как элементы множества, например, кодовые комбинации двоичного кода принадлежат множеству положительных двоичных чисел.
Множества, для которых определены некоторые алгебраические операции, называют алгебраическими системами. Под алгебраической операцией понимают однозначное сопоставление двум элементам некоторого третьего элемента по определенным правилам. Обычно основную операцию называют сложением (обозначают а+b = с) или умножением (обозначают а∙b = с), а обратную ей - вычитанием или делением, даже если эти операции проводятся не над числами и неидентичны соответствующим арифметическим операциям.
Рассмотрим кратко основные алгебраические системы, широко используемые в теории корректирующих кодов. Группой называют множество элементов, в котором определена одна основная операция и выполняются следующие аксиомы:
1. В результате применения операции к любым двум элементам группы образуется элемент этой же группы (требование замкнутости).
2. Для любых трех элементов группы a, b и с удовлетворяется равенство (а+b)+c = а+(b+c) (если основная операция - сложение) и равенство a∙(bc) = (ab)∙c (если основная операция - умножение).
3. В любой группе Gn существует однозначно определенный элемент, удовлетворяющий при всех значениях а из Gn условию a+0=0 + a = a (если основная операция - сложение) или условно a • 1 = 1 • а = а (если основная операция - умножение).
В первом случае, этот элемент называют нулем и обозначают символом 0, а во втором - единицей и обозначают символом 1.
4. Всякий элемент а группы обладает элементом, однозначно определенным уравнением а + (— а) = — а+ а = 0 (если основная операция сложение) или уравнением
a • a-1 = a-1• a= 1 (если основная операция - умножение).
В первом случае, этот элемент называют противоположным и обозначают (-а), а во втором - обратным и обозначают a-1.
Если операция, определенная в группе, коммутативна, т. е. справедливо равенство a + 6 = b + a (для группы по сложению) или равенство a • b = b • a (для группы по умножению), то группу называют коммутативной или абелевой.
Группу, состоящую из конечного числа элементов, называют конечной. Число элементов в группе называют порядком группы.
Чтобы рассматриваемое нами множество n-разрядных кодовых комбинаций было конечной группой, при выполнении основной операции число разрядов в результирующей кодовой комбинации не должно увеличиваться. Этому условию удовлетворяет операция символического поразрядного сложения по заданному модулю q (q -простое число), при которой цифры одинаковых разрядов элементов группы складываются обычным порядком, а результатом сложения считается остаток от деления полученного числа на модуль q.
При рассмотрении двоичных кодов используется операция сложения по модулю 2. Результатом сложения цифр данного разряда является 0, если сумма единиц в нем четна, и 1, если сумма единиц в нем нечетна, например:
1 0 1 1 1 0 1
![]() 0 1 1 1 1 0 1
0 1 1 1 1 0 1
0 0 0 1 1 1 0
1 1 0 1 1 1 0
Выбранная нами операция коммутативна, поэтому рассматриваемые группы будут абелевыми.
Нулевым элементом является комбинация, состоящая из одних нулей. Противоположным элементом при сложении по модулю 2 будет сам заданный элемент. Следовательно, операция вычитания по модулю 2 тождественна операции сложения.
Пример 6.1
Определить, являются ли группами следующие множества кодовых комбинаций:
1)0001, 0110, 0111, 0011;
2)0000, 1101, 1110, 0111;
3) 000, 001, 010, 011, 100, 101, 110, 111.
Первое множество не является группой, так как не содержит нулевого элемента.
Второе множество не является группой, так как не выполняется условие замкнутости, например сумма по модулю 2 комбинаций 1101 и 1110 дает комбинацию 0011, не принадлежащему исходному множеству.
Третье множество удовлетворяет всем перечисленным условиям и является группой.
Подмножества группы, являющиеся сами по себе группами относительно операции, определенной в группе, называют подгруппами. Например, подмножество трехразрядных кодовых комбинаций: 000, 001, 010, 011 образуют подгруппу указанной в примере группы трехразрядных кодовых комбинаций.
Пусть в абелевой группе Gn задана определенная подгруппа А. Если В - любой не входящий в А элемент из Gn, то суммы (по модулю 2) элементов В с каждым из элементов подгруппы А образуют смежный класс группы Gn по подгруппе А, порождаемый элементом В.
Элемент В, естественно, содержится в этом смежном классе, так как любая подгруппа содержит нулевой элемент. Взяв последовательно некоторые элементы Вj, группы, не вошедшие в уже образованные смежные классы, можно разложить всю группу на смежные классы по подгруппе А.
Элементы Вj называют образующими элементами смежных классов подгруппы.
В таблице разложения, иногда называемой групповой таблицей, образующие элементы обычно располагают в крайнем левом столбце, причем крайним левым элементом подгруппы является нулевой элемент.
Пример 6.2. Разложим группу трехразрядных двоичных кодовых комбинаций по подгруппе двухразрядных кодовых комбинаций. Разложение выполняем в соответствии с табицей 6.2.
![]() Т а б л и ц а 6.2
Т а б л и ц а 6.2
|
А1 = 0 |
А2 |
А3 |
A4 |
|
|
001 |
010 |
011 |
|
В1 |
А2 + В1 |
Aз + В1 |
А4 + В1 |
|
100 |
101 |
110 |
111
|
![]()
Пример 6.3. Разложим группу четырехразрядных двоичных кодовых комбинаций по подгруппе двухразрядных кодовых комбинаций.
Существуют много вариантов разложения в зависимости от того, какие элементы выбраны в качестве образующих смежных классов. Один из вариантов представлен в таблице 6.3.
Т а б л и ц а 6.3
|
|
А2 0001 |
А3 0010 |
0011 |
|
B1 0100 |
А2 0101 |
Аз 0110 |
А4 0111 |
|
В2 1010 |
А2 1011 |
Аз |
А4 1001 |
|
В3 110 |
А2
|
Аз 1110 |
А4 1111 |
|
|
|
|
|
Кольцом называют множество элементов R, на котором определены две операции (сложения и умножения), такие, что:
1) множество R является коммутативной группой по сложению;
2) произведение элементов a![]() R и b
R и b![]() R есть элемент R (замкнутость по отношению к умножению);
R есть элемент R (замкнутость по отношению к умножению);
3) для любых трех элементов a, b и с из R справедливо равенство a∙(bc) = (ab) ∙c (ассоциативный закон для умножения);
4) для любых трех элементов а, b и с из R выполняются соотношения
a(b + c) = ab + ac и ( b+c)a = ba+ca (дистрибутивные законы).
Если для любых двух элементов кольца справедливо соотношение ab = bа, кольцо называют коммутативным. Кольцо может не иметь единичного элемента по умножению и обратных элементов.
Примером кольца может служить множество действительных четных целых чисел относительно обычных операций сложения и умножения.
Полем F называют множество по крайней мере двух элементов, в котором определены две операции - сложение и умножение, и выполняются следующие аксиомы:
1) множество элементов образует коммутативную группу по сложению;
2) множество ненулевых элементов образует коммутативную группу по умножению;
3) для любых трех элементов множества а, b, с выполняется соотношение (дистрибутивный закон)
a(b+c) = ab+ac.
Поле F является, следовательно, коммутативным кольцом с единичным элементом по умножению, в котором каждый ненулевой элемент обладает обратным элементом. Примером поля может служить множество всех действительных чисел.
Поле GF(P), состоящее из конечного числа элементов Р, называют конечным полем или полем Галуа. Для любого числа Р, являющегося степенью простого числа q существует поле, насчитывающее Р элементов. Например, совокупность чисел по модулю q, если q-простое число, является полем.
Поле не может содержать менее двух элементов, поскольку в нем должны быть по крайней мере единичный элемент относительно операции сложения (0) и единичный элемент относительно операции умножения (1). Поле, включающее только 0 и 1, обозначим GF (2). Правила сложения и умножения в поле с двумя элементами следующие:
|
+ |
0 |
1 |
|
|
0 |
1 |
|
0 |
0 |
1 |
0 |
0 |
0 |
|
|
1 |
1 |
0 |
1 |
0 |
1 |
Двоичные кодовые комбинации, являющиеся упорядоченными последовательностями из п элементов поля GF (2), рассматриваются в теории кодирования как частный случай последовательностей из п элементов поля GF(P). Такой подход позволяет строить и анализировать коды с основанием, равным степени простого числа.
В общем случае суммой кодовых комбинаций Aj и Ai называют комбинацию Af = Aj + Ai . в которой любой символ Ak (k=1, 2, ..., п) представляет собой сумму k-x символов исходных комбинаций, причем суммирование производится по правилам поля GF(P). При этом вся совокупность n-разрядных кодовых комбинаций оказывается абелевой группой.
В частном случае, когда основанием кода является простое число q, правило сложения в поле GF(q) совпадает с правилом сложения по заданному модулю q.
8 Лекция 8 Коды с исправлением искажений. Групповые коды
Цель лекции: определение и изучение методов помехоустойчивого кодирования , применяемых в информационных подсистемах АСУ.
Содержание лекции: принципы помехоустойчивого кодирования. Групповые коды. Построение двоичного группового кода.
8.1 Линейный код как подпространство линейного векторного
пространства
В рассмотренных алгебраических системах (группа, кольцо, поле) операции относились к одному классу математических объектов (элементов). Такие операции называют внутренними законами композиции элементов.
В теории
кодирования широко используются модели, охватывающие два класса математических
объектов (например, L и
Ω). Помимо внутренних законов композации в них задаются внешние законы
композиции элементов, по которым любым элементам ![]() и a
и a![]() L ставится в соответствие элемент c
L ставится в соответствие элемент c![]() L.
L.
Линейным векторным пространством над полем элементов F (скаляров) называют множество элементов V (векторов), если для него выполняются следующие аксиомы:
1) множество V является коммутативной группой относительно операции сложения;
2) для любого вектора v из V и любого скаляра сиз F определено произведение cv которое содержится в V (замкнутость по отношению умножения на скаляр);
если u и v из V векторы, а с и d из F скаляры, то справедливо c(c + v) = cu + cv, (с + d) = cv + dv (дистрибутивные законы);
3) если v- вектор, а с и d - скаляры, то (cd)v = = c(dv) и 1 • v = v (ассоциативный закон для умножения на скаляр).
Выше было определено правило поразрядного сложения кодовых комбинаций, при котором вся их совокупность образует абелеву группу. Определим теперь операцию умножения последовательности из п элементов поля GF(P) (кодовой комбинации) на элемент поля а, из GF(P] аналогично правилу умножения вектора на скаляр:
ai (a1,a2, …, an) =(ai a1,ai a2, …, ai an)
[умножение элементов производится по правилам поля GF(P)].
Поскольку при выбранных операциях дистрибутивные законы и ассоциативный закон (п. 3, 4) выполняются, все множество n-азрядных кодовых комбинаций можно рассматривать как векторное линейное пространство над полем GF(P), а кодовые комбинации - как его векторы.
В частности, при двоичном кодировании векторы состоят из элементов поля GF (2), (т. е. 0 и 1). Сложение проводят поразрядно по модулю 2. При умножении вектора на один элемент поля (1) он не изменяется, а умножение на другой (0) превращает его в единичный элемент векторного пространства, обозначаемый символом 0= (0 0...0).
Если в линейном пространстве последовательностей из п элементов поля GF(P) дополнительно задать операцию умножения векторов, удовлетворяющую определенным условиям (ассоциативности, замкнутости, билинейности по отношению к умножению на скаляры), то вся совокупность n-разрядных кодовых комбинаций превращается в линейную коммутативную алгебру над полем коэффициентов GF(P].
Подмножество элементов векторного пространства, которое удовлетворяет аксиомам векторного пространства, называют подпространством.
Линейным кодом называют множество векторов, образующих подпространство векторного пространства всех n-разрядных кодовых комбинаций над полем GF(P).
В случае двоичного кодирования такого подпространство комбинаций над полем GF (2) образует любая совокупность двоичных кодовых комбинаций, являющаяся подгруппой группы всех n-разрядных двоичных кодовых комбинаций. Поэтому любой двоичный линейный код является групповым.
8.2 Построение двоичного группового кода
Построение конкретного корректирующего кода производят, исходя из требуемого объема кода Q, т. е. необходимого числа передаваемых команд или дискретных значений измеряемой величины и статистических данных о наиболее вероятных векторах ошибок в используемом канале связи. Вектором ошибки называют n-разрядную двоичную последовательность, имеющую единицы в разрядах, подвергшихся искажению, и нули во всех остальных разрядах. Любую искаженную кодовую комбинацию можно рассматривать теперь как сумму (или разность) по модулю 2 исходной разрешенной кодовой комбинации и вектора ошибки.
Исходя из неравенства 2k-1≥ Q (нулевая комбинация часто не используется, так как не меняет состояния канала связи), определяем число информационных разрядов q, необходимое для передачи заданного числа команд обычным двоичным кодом.
Каждой из 2k-1 ненулевых комбинаций q-разрядного безызбыточного кода нам необходимо поставить в соответствие комбинацию из п символов. Значения символов в п - k проверочных разрядах такой комбинации устанавливаются в результате суммирования по модулю 2 значений символов в определенных информационных разрядах.
Поскольку множество 2k комбинаций информационных символов (включая нулевую) образует подгруппу группы всех n-разрядных комбинаций, то и множество 2q n-разрядных комбинаций, полученных по указанному правилу, тоже является подгруппой группы «-разрядных кодовых комбинаций. Это множество разрешенных кодовых комбинаций и будет групповым кодом.
Нам надлежит определить число проверочных разрядов и номера информационных разрядов, входящих в каждое из равенств для определения символов в проверочных разрядах.
Разложим группу 2n всех n-разрядных комбинаций на смежные классы по подгруппе 2k разрешенных n-разрядных кодовых комбинаций, проверочные разряды в которых еще не заполнены. Помимо самой подгруппы кода в разложении насчитывается 2п-k - 1 смежных классов. Элементы каждого класса представляют собой суммы по модулю 2 комбинаций кода и образующих элементов данного класса. Если за образующие элементы каждого класса принять те наиболее вероятные для заданного канала связи вектора ошибок, которые должны быть исправлены, то в каждом смежном классе сгруппируются кодовые комбинации, получающиеся в результате воздействия на все разрешенные комбинации определенного вектора ошибки. Для исправления любой полученной на выходе канала связи кодовой комбинации теперь достаточно определить, к какому классу смежности она относится. Складывая ее затем (по модулю 2) с образующим элементом этого смежного класса, получаем истинную комбинацию кода.
Ясно, что из общего числа 2n—1 возможных ошибок групповой код может исправить всего 2n-k -1 разновидностей ошибок по числу смежных классов.
Чтобы иметь возможность получить информацию о том, к какому смежному классу относится полученная комбинация, каждому смежному классу должна быть поставлена в соответствие некоторая контрольная последовательность символов, называемая опознавателем (синдромом).
Каждый символ опознавателя определяют в результате проверки на приемной стороне справедливости одного из равенств, которые мы составим для определения значений проверочных символов при кодировании.
Ранее указывалось, что в двоичном линейном коде значения проверочных символов подбирают так, чтобы сумма по модулю 2 всех символов (включая проверочный), входящих в каждое из равенств, равнялась нулю. В таком случае число единиц среди этих символов четное. Поэтому операции определения символов опознавателя называют проверками на четность. При отсутствии ошибок в результате всех проверок на четность образуется опознаватель, состоящий из одних нулей. Если проверочное равенство не удовлетворяется, то в соответствующем разряде опознавателя появляется единица. Исправление ошибок возможно лишь при наличии взаимно однозначного соответствия между множеством опознавателей и множеством смежных классов, а следовательно, и множеством подлежащих исправлению векторов ошибок.
Таким образом, количество подлежащих исправлению ошибок является определяющим для выбора числа избыточных символов п - k. Их должно быть достаточно для того, чтобы обеспечить необходимое число опознавателей.
Если, например, необходимо исправить все одиночные независимые ошибки, то исправлению подлежат п ошибок:
000...01
000...10
………
010...00
100...00
Различных ненулевых опознавателей должно быть не менее п. Необходимое число проверочных разрядов, следовательно, должно определяться из соотношения
2n-k – 1 ≥ n (8.1)
или
2n-k – 1 ≥ ![]() (8.2)
(8.2)
Если необходимо исправить не только все единичные, но и все двойные независимые ошибки, соответствующее неравенство принимает вид
2n-k – 1
≥ +![]() +
+![]() (8.3)
(8.3)
В общем случае, для исправления всех независимых ошибок кратности до 5 включительно получаем
2n-k – 1 ≥ +![]() +
+![]() + … +
+ … +![]() (8.4)
(8.4)
Стоит подчеркнуть, что в приведенных соотношениях указывается теоретический предел минимально возможного числа проверочных символов, который далеко не во всех случаях можно реализовать практически. Часто проверочных символов требуется больше, чем следует из соответствующего равенства.
Одна из причин этого выяснится при рассмотрении процесса сопоставления каждой подлежащей исправлению ошибки с ее опознавателем.
Составление таблицы опознавателей
Начнем для простоты с установления опознавателей для случая исправления одиночных ошибок. Допустим, что необходимо закодировать 15 команд. Тогда требуемое число информационных разрядов равно четырем. Пользуясь соотношением 2n-k – 1 = п, определяем общее число раз рядов кода, а следовательно, и число ошибок, подлежащих исправлению (n =7). Три избыточных разряда позволяют использовать в качестве опознавателей трехразрядные двоичные последовательности.
В данном случае ненулевые последовательности в принципе могут быть сопоставлены с подлежащими исправлению ошибками в любом порядке. Однако более целесообразно сопоставлять их с ошибками в разрядах, начиная с младшего, в порядке возрастания двоичных чисел (таблица 8.1).
Т а б л и ц а 8.1
|
|
Опознаватели |
Векторы ошибок |
|
|
0000001 0000010 0000100 0001000 |
001 010 011 100 |
0010000 0100000 1000000 |
101110 111
|
![]() При таком сопоставлении каждый опознаватель представляет собой
двоичное число, указывающее номер разряда, в котором произошла ошибка.
При таком сопоставлении каждый опознаватель представляет собой
двоичное число, указывающее номер разряда, в котором произошла ошибка.
Коды, в которых опознаватели устанавливаются по указанному принципу, известны как коды Хэмминга.
9 Лекция 9 Групповые коды. Определение проверочных равенств
Цель лекции: определение и изучение методов помехоустойчивого кодирования , применяемых в информационных подсистемах АСУ.
Содержание лекции: принципы помехоустойчивого кодирования. Построение двоичного группового кода. Составление таблицы опознавателей и проверочных равенств.
9.1 Случай исправления одиночных и двойных независимых ошибок
В качестве опознавателей одиночных ошибок в первом и втором разрядах можно принять, как и ранее, комбинации 0...001 и 0...010.
Однако, в качестве опознавателя одиночной ошибки в третьем разряде комбинацию 0...011 взять нельзя. Такая комбинация соответствует ошибке одновременно в первом и во втором разрядах, а она также подлежит исправлению и, следовательно, ей должен соответствовать свой опознаватель 0...011.
В качестве опознавателя одиночной ошибки в третьем разряде можно взять только трехразрядную комбинацию 0...0100, так как множество двухразрядных комбинаций уже исчерпано. Подлежащий исправлению вектор ошибки 0...0101 также можно рассматривать как результат суммарного воздействия двух векторов ошибок 0...0100 и 0...001 и, следовательно, ему должен быть поставлен в соответствие опознаватель, представляющий собой сумму по модулю 2 опознавателей этих ошибок, т. е. 0...0101.
Аналогично находим, что опознавателем вектора ошибки 0...0110 является комбинация 0...0110.
Определяя опознаватель для одиночной ошибки в четвертом разряде, замечаем, что еще не использована одна из трехразрядных комбинаций, а именно 0...0111. Однако, выбирая в качестве опознавателя единичной ошибки в i-м разряде комбинацию с числом разрядов, меньшим i, необходимо убедиться в том, что для всех остальных подлежащих исправлению векторов ошибок, имеющих единицы в i-м и более младших разрядах, получатся опознаватели, отличные от уже использованных. В нашем случае, подлежащими исправлению векторами ошибок с единицами в четвертом и более младших разрядах являются:
0...01001, 0...01010, 0...01100.
Если одиночной ошибке в четвертом разряде поставить в соответствие опознаватель 0...0111, то для указанных векторов опознавателями должны были бы быть соответственно
0...0111 0...0111 0...0111
![]() 0...0001
0...0001
![]() 0...0001
0...0001
![]() 0...0100
0...0100
0...0110 0...0110 0…0011 .
Однако эти комбинации уже использованы в качестве опознавателей других векторов ошибок, а именно:
0...0110, 0...0101, 0...0011.
Следовательно, во избежание неоднозначности при декодировании в качестве опознавателя одиночной ошибки в четвертом разряде следует взять четырехразрядную комбинацию 1000. Тогда для векторов ошибок
0...01001, 0...01010, 0...01100
опознавателями соответственно будут:
0...01001, 0...01010, 0...01100.
Аналогично можно установить, что в качестве опознавателя одиночной ошибки в пятом разряде может быть выбрана не использованная ранее четырехразрядная комбинация 01111.
Действительно, для всех остальных подлежащих исправлению векторов ошибок с единицей в пятом и более младших разрядах получаем опознаватели, отличающиеся от ранее установленных:
Векторы ошибок Опознаватели
0...010001 0…01110
0...010010 0…01101
0...010100 0…01011
0...011000 0…00111.
Продолжая сопоставление, можно получить таблицу опознавателей для векторов ошибок данного типа с любым числом разрядов. Так как опознаватели векторов ошибок с единицами в нескольких разрядах устанавливаются как суммы по модулю 2 опознавателей одиночных ошибок в этих разрядах, то для определения правил построения кода и составления проверочных равенств достаточно знать только опознаватели одиночных ошибок в каждом из разрядов. Для построения кодов, исправляющих двойные независимые ошибки, "таблица таких опознавателей определена с помощью вычислительной машины вплоть до 29-го разряда. Опознаватели одиночных ошибок в первых пятнадцати разрядах приведены в таблице 9.1
По тому же принципу аналогичные таблицы определены и для ошибок других типов, например для тройных независимых ошибок, пачек ошибок в два и три символа.
9.2 Определение проверочных равенств
Итак, для любого кода, имеющего целью исправлять наиболее вероятные векторы ошибок заданного канала связи (взаимно независимые ошибки или пачки ошибок), можно составить таблицу опознавателей одиночных ошибок в каждом из разрядов. Пользуясь этой таблицей, нетрудно определить, символы каких разрядов должны входить в каждую из проверок на четность.
Т а б л и ц а 9.1
|
|
Опознава- |
Номер |
Опознава- |
Номер |
|
|
разряда |
тель |
разряда |
тель |
разряда |
тель |
|
1 |
00000001 |
6 |
00010000 |
11 |
01101010 |
|
2 |
00000010 |
7 |
00100000 |
12 |
10000000 |
|
3 |
00000100 |
8 |
00110011 |
13 |
10010110 |
|
4 |
00001000 |
9 |
01000000 |
14 |
10110101 |
|
|
00001111 |
10 |
01010101 |
15 |
11011011 |
Рассмотрим в качестве примера опознаватели для кодов, предназначенных исправлять единичные ошибки (таблица 9.2).
Т а б л и ц а 9.2
|
Номер разрядов |
Опознава-тель |
Номер разрядов |
Опознава-тель |
Номер разрядов |
Опознава-тель |
|
1 2 3 4 5 6 |
0001 0010 0011 0100 0101 0110 |
7 8 9 10 11 |
0111 1000 1001 1010 1011 |
12 13 14 15 16 |
1100 1101 1110 1111 10000 |
В принципе можно построить код, усекая эту таблицу на любом уровне. Однако из таблицы видно, что оптимальными будут коды (7, 4), (15, 11), где первое число равно n, а второе k, и другие, которые среди кодов, имеющих одно и то же число проверочных символов, допускают наибольшее число информационных символов.
Усечем эту таблицу на седьмом разряде и найдем номера разрядов, символы которых должны войти в каждое из проверочных равенств.
Предположим, что в результате первой проверки на четность для младшего разряда опознавателя будет получена единица. Очевидно, это может быть следствием ошибки в одном из разрядов, опознаватели которых в младшем разряде имеют единицу. Следовательно, первое проверочное равенство должно включать символы 1, 3, 5 и 7-го разрядов:
a1 ![]() a3
a3 ![]() a5
a5![]() a7 = 0.
a7 = 0.
Единица во втором разряде опознавателя может быть следствием ошибки в разрядах, опознаватели которых имеют единицу во втором разряде. Отсюда второе проверочное равенство должно иметь вид
a2 ![]() a3
a3 ![]() a6
a6 ![]() a7 = 0.
a7 = 0.
Аналогично находим и третье равенство:
a4![]() a5
a5 ![]() a6
a6 ![]() a7 = 0.
a7 = 0.
Чтобы эти равенства при отсутствии ошибок удовлетворялись для любых значений информационных символов в кодовой комбинации, в нашем распоряжении имеется три проверочных разряда. Мы должны так выбрать номера этих разрядов, чтобы каждый из них входил только в одно из равенств. Это обеспечит однозначное определение значений символов в проверочных разрядах при кодировании. Указанному условию удовлетворяют разряды, опознаватели которых имеют по одной единице. В нашем случае это будут первый, второй и четвертый разряды.
Таким образом, для кода (7, 4), исправляющего одиночные ошибки, искомые правила построения кода, т. е. соотношения, реализуемые в процессе кодирования, принимают вид:
a1 = a3
![]() a5
a5![]() a7
a7
a2 = a3 ![]() a6
a6 ![]() a7 (9.1)
a7 (9.1)
a4= a5
![]() a6
a6 ![]() a7
a7
Поскольку построенный код имеет минимальное хэммингово расстояние
d min = 3, он в соответствии с (6.1) может использоваться с целью обнаружения единичных и двойных ошибок. Обращаясь к таблице 9.2, легко убедиться, что сумма любых двух опознавателей единичных ошибок дает ненулевой опознаватель, что и является признаком наличия ошибки.
Пример 9.1. Построим групповой код объемом 15 слов, способный исправлять единичные и обнаруживать двойные ошибки.
В соответствии с (6.17) код должен обладать минимальным хэмминговым расстоянием, равным 4. Такой код можно построить в два этапа. Сначала строим код заданного объема, способный исправлять единичные ошибки. Это код Хэмминга (7, 4). Затем добавляем еще один проверочный разряд, который обеспечивает четность числа единиц в разрешенных комбинациях.
Таким образом, получаем код (8, 4). В процессе кодирования реализуются соотношения:
a1 = a3
![]() a5
a5![]() a7
a7
a2 = a3
![]() a6
a6 ![]() a7
a7
a4= a5
![]() a6
a6 ![]() a7
a7
a8= a1![]() a2
a2![]() a3
a3
![]() a4
a4![]() a5
a5 ![]() a6
a6![]() a7
a7
Обозначив синдром кода (7, 4) через S1, результат общей проверки на четность — через S2(![]() )
и пренебрегая возможностью возникновения
ошибок кратности 3 и выше, запишем алгоритм декодирования:
)
и пренебрегая возможностью возникновения
ошибок кратности 3 и выше, запишем алгоритм декодирования:
при S1 = 0 и S2 = 0 ошибок нет;
при S1 = 0 и S2 = 1 ошибка в восьмом разряде;
при S1 ≠ 0 и S2 = 0 двойная ошибка ( коррекция блокируется,
посылается запрос повторной передачи);
при S1 ≠ 0 и S2 = 1 одиночная ошибка (осуществляется её исправление).
Пример 9.2. Используя табл. 9.2, составим правила построения кода (8,2), исправляющего все одиночные и двойные ошибки.
Усекая табл. 9.1 на восьмом разряде, найдем следующие проверочные равенства:
a1 ![]() a5
a5 ![]() a8 =
0 a34
a8 =
0 a34![]() a5 = 0
a5 = 0
a2 ![]() a5
a5 ![]() a8 =
0 a6
a8 =
0 a6 ![]() a8 = 0
a8 = 0
a3 ![]() a5 =
0 a7
a5 =
0 a7
![]() a8 = 0
a8 = 0
Соответственно правила построения кода выразим соотношениями
a1
= a5 ![]() a8
a4= a5
a8
a4= a5
a2 = a5 ![]() a8
a6 = a8
a8
a6 = a8
a3 = a5 a7 = a8
Отметим, что для построенного кода dmin = 5, и, следовательно, он может использоваться для обнаружения ошибок кратности от 1 до 4.
Соотношения, отражающие процессы кодирования и декодирования двоичных линейных кодов, могут быть реализованы непосредственно с использованием сумматоров по модулю два. Однако декодирующие устройства, построенные таким путем для кодов, предназначенных исправлять многократные ошибки, чрезвычайно громоздки. В этом случае более эффективны другие принципы декодирования.
10 Лекция 10 Матричное представление линейных кодов
Цель лекции: определение и изучение методов помехоустойчивого кодирования, с использованием матричного представления.
Содержание лекции: принципы помехоустойчивого кодирования. Использование матричного представления для построения двоичного группового кода.
10.1 Матричное представление линейных кодов
В теории кодирования элементами матрицы являются элементы некоторого поля GF(P), а строки и столбцы матрицы рассматриваются как векторы. Сложение и умножение элементов матриц осуществляется по правилам поля GF(P).
Пример10.1 Вычислим произведение матриц с элементами из поля
GF (2):

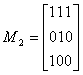
Элементы cik матрицы произведения М = М1 М2 будут равны:
с11 = (011) (101) = 0+0+1 = 1
с12 = (011) (110) = 0+1+0 = 1
с13 = (011) (100) = 0+0+0 = 0
с21 = (100) (110) = 1+0+0 = 1
с22 = (100) (110) = 1+0+0 = 1
с23 = (100) (100) = 1+0+0 = 1
с31 = (001) (101) = 0+0+1 = 1
с32 = (001) (110) = 0+0+0 = 0
с33 = (001) (100) = 0+0+0 = 0
Следовательно,

10.2 Образующая матрица линейного кода
Зная закон построения кода, определим все множество разрешенных кодовых комбинаций. Расположив их друг под другом, получим матрицу, совокупность строк которой является подпространством векторного пространства n-разрядных кодовых комбинаций (векторов) из элементов поля GF(P). В случае двоичного (п, k)-кода матрица насчитывает п столбцов и 2k — 1 строк (исключая нулевую). Например, для рассмотренного ранее кода (8,2), исправляющего все одиночные и двойные ошибки, матрица имеет вид
a5 a8 a1 a2 a3 a4 a6 a7
0 1 1 1 0 0 1 1
1 0 1 1 1 1 0 0
1 1
0 0 1 1 1 1![]()
При больших п и k матрица, включающая все векторы кода, слишком громоздка. Однако совокупность векторов, составляющих линейное пространство разрешенных кодовых комбинаций, является линейно зависимой, так как часть векторов может быть представлена в виде линейной комбинации некоторой ограниченной совокупности векторов, называемой базисом пространства.
Совокупность векторов Vj, Vo, Va, ..., Vn называют линейно зависимой, когда существуют скаляры с1...сп (не все равные нулю), при которых
c1 V1 + c1 V1 + … + c1 V1 = 0.
В приведенной матрице, например, третья строка представляет собой суммы по модулю два первых двух строк.
Для полного определения пространства разрешенных кодовых комбинаций линейного кода достаточно записать в виде матрицы только совокупность линейно независимых векторов. Их число называют размерностью векторного пространства.
Среди 2k-1 ненулевых двоичных кодовых комбинаций — векторов их только k. Например, для кода (8,2)
а1 а2 а3 а4 а5 а6 а7 а8
М 8,2 = 1 1 0 0 0 1 1 1
1 1 1 1 1 0 0 0.
Матрицу, составленную из любой совокупности векторов линейного кода, образующей базис пространства, называют порождающей (образующей) матрицей кода.
Если порождающая матрица содержит k строк по п элементов поля GF(q), то код называют (n,k)-кодом. В каждой комбинации (n,k)-кода k информационных символов и п — k проверочных. Общее число разрешенных кодовых комбинаций (исключая нулевую)
Q = qk.-1.
Зная порождающую матрицу кода, легко найти разрешенную кодовую комбинацию, соответствующую любой последовательности Aki из k информационных символов. Она получается в результате умножения вектора Aki на порождающую матрицу Mn,k:
Ani = Aki ∙ Mn,k .
Найдем, например, разрешенную комбинацию кода (8,2), соответствующую информационным символам а5=1, а8=1.
|
|
[11] M8,2 = [11]![]() = 00111111
= 00111111
Пространство строк матрицы остается неизменным при выполнении следующих элементарных операций над строками: 1) перестановка любых двух строк; 2) умножение любой строки на ненулевой элемент поля; 3) сложение какой-либо строки с произведением другой строки на ненулевой элемент поля, а также при перестановке столбцов.
Если образующая матрица кода М2 получена из образующей матрицы кода М1с помощью элементарных операций над строками, то обе матрицы порождают один и тот же код. Перестановка столбцов образующей матрицы кода приводит к образующей матрице эквивалентного кода. Эквивалентные коды весьма близки по своим свойствам. Корректирующая способность таких кодов одинакова.
Для анализа возможностей линейного (n,k)-кода, а также для упрощения процесса кодирования удобно, чтобы порождающая матрица (Mn,k) состояла из двух матриц: единичной матрицы размерности k×k и дописываемой справа матрицы-дополнения (контрольной подматрицы) размерности k • (п — k), которая соответствует п — k проверочным разрядам:
Mn,k = [ Ik Pk,n-k ] =  (10.1)
(10.1)
Разрешенные кодовые комбинации кода с такой порождающей матрицей отличаются тем, что первые k символов в них совпадают с исходными информационными, а проверочными оказываются (n — k) последних символов.
Действительно, если умножим
вектор-строку Aki = ![]() матрицу
матрицу
Mn,k = [ Ik Pk,n-k ], получим вектор An,i =![]() ,
,
где проверочные символы ![]() являются линейными комбинациями информационных
являются линейными комбинациями информационных
![]() (10.2)
(10.2)
Коды, удовлетворяющие этому условию, называют систематическими. Для каждого линейного кода существует эквивалентный систематический код.
B свою очередь, по заданной матрице-дополнению P k,n-k можно определить равенства, задающие правила построения кода. Единица в первой строке каждого столбца указывает на то, что в образовании соответствующего столбцу проверочного разряда участвовал первый информационный разряд. Единица в следующей строке любого столбца говорит об участии в образовании проверочного разряда второго информационного разряда и т. д.
Так как матрица-дополнение содержит всю информацию о правилах построения кода, то систематический код с заданными свойствами можно синтезировать путем построения соответствующей матрицы-дополнения.
Так как минимальное кодовое расстояние d для линейного кода равно минимальному весу его ненулевых векторов, то в матрицу-дополнение должны быть включены такие k строк, которые удовлетворяли бы следующему общему условию: вектор-строка образующей матрицы, получающаяся при суммировании любых l(1≤l≤k) строк, должна содержать не менее d — l отличных от нуля символов.
Действительно, при выполнении указанного условия любая разрешенная кодовая комбинация, полученная суммированием l строк образующей матрицы, имеет не менее d ненулевых символов, так как l ненулевых символов она всегда содержит в результате суммирования строк единичной матрицы.
Синтезируем таким путем образующую матрицу двоичного систематического кода (7,4) с минимальным кодовым расстоянием d = 3.
В каждой вектор-строке матрицы-дополнения согласно сформулированному условию (при l = 1) должно быть не менее двух единиц. Среди трехразрядных векторов таких имеется четыре: 011, 110, 101, 111.
Эти векторы могут быть сопоставлены со строками единичной матрицы в любом порядке. В результате получим матрицы систематических кодов, эквивалентных коду Хэмминга, например:
M7,4 =
Нетрудно убедиться, что при суммировании нескольких строк такой матрицы (l>1) получим вектор-строку, содержащую не менее d = 3 ненулевых символов.
Имея образующую матрицу систематического кода Mn,k = [ Ik Pk,n-k ], можно построить так называемую проверочную (контрольную) матрицу Н размерности (n-k) × n:
H = ![]() =
= 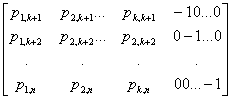 (6.29)
(6.29)
При умножении неискаженного кодового вектора Ani на матрицу, транспонированную к матрице Н, получим вектор, все компоненты которого равны нулю:
Ani НT=│![]() ,
,![]() ,…,
,…,![]() ,...,
,...,![]() │∙
│∙ =│Sk+1, Sk+2,…,Sj,… Sn│=│0,0,…0,…0│.
=│Sk+1, Sk+2,…,Sj,… Sn│=│0,0,…0,…0│.
Каждая компонента Sj является результатом проверки справедливости соответствующего уравнения декодирования:
![]()
11 Лекция 11 Циклические коды. Математические основы для построения циклических кодов
Цель лекции: определение и изучение методов помехоустойчивого кодирования.
Понятие об образующем многочлене.
Содержание лекции: циклические коды. Общие понятия и определения. Идеал и порождающий многочлен. Требования к образующему многочлену.
11.1 Построение циклических кодов
Общие понятия и определения. Любой групповой код (п, k) может быть записан в виде матрицы, включающей k линейно независимых строк по п символов и, наоборот, любая совокупность k линейно независимых п-разрядных кодовых комбинаций может рассматриваться как образующая матрица некоторого группового кода. Среди всего многообразия таких кодов можно выделить коды, у которых строки образующих матриц связаны дополнительным условием цикличности. Все строки образующей матрицы такого кода могут быть получены циклическим сдвигом одной комбинации, называемой образующей для данного кода. Коды, удовлетворяющие этому условию, получили название циклических кодов.
Сдвиг осуществляется справа налево, причем крайний левый символ каждый раз переносится в конец комбинации. Запишем, например, совокупность кодовых комбинаций, получающихся циклическим сдвигом комбинации 001011:
G = 
Число возможных циклических ( п ,k )-кодов значительно меньше числа различных групповых (п, k)-кодов.
При описании циклических кодов n-разрядные кодовые комбинации представляются в виде многочленов фиктивной переменной х. Показатели степени у х соответствуют номерам разрядов (начиная с нулевого), а коэффициентами при х в общем случае являются элементы поля GF(q). При этом наименьшему разряду числа соответствует фиктивная переменная
х°= 1. Многочлен с коэффициентами из поля GF(q] называют многочленом над полем GF(q). Так как мы ограничиваемся рассмотрением только двоичных кодов, то коэффициентами при х будут только цифры 0 и 1. Иначе говоря, будем оперировать с многочленами над полем GF(2).
Запишем, например, в виде многочлена образующую кодовую комбинацию 01011:
G(x) = 0 • х4 + 1 • х3 + 0 • х2 + 1 . х + 1 .
Поскольку члены с нулевыми коэффициентами при записи многочлена опускаются, образующий многочлен:
G(x) = x3 + x+1. (11.1)
Наибольшую степень х в слагаемом с ненулевым коэффициентом называют степенью многочлена. Теперь действия над кодовыми комбинациями сводятся к действиям над многочленами. Суммирование многочленов осуществляется с приведением коэффициентов по модулю два.
Указанный циклический сдвиг некоторого образующего многочлена степени п — k без переноса единицы в конец кодовой комбинации соответствует простому умножению на х. Умножив, например, первую строку матрицы (001011), соответствующую многочлену go(x) =x3+х+1, на х, получим вторую строку матрицы (010110), соответствующую многочлену x∙go(x).
Нетрудно убедиться, что кодовая комбинация, получающаяся при сложении этих двух комбинаций, также будет соответствовать результату умножения многочлена х3 + х+1 на многочлен х+1. Действительно,
0 0 1 0 1 1 х3 + 0 + х +1
![]() 0 1 0 1 1 0 x +1
0 1 0 1 1 0 x +1
0 1 1 1 0 1 х3 + 0 + х + 1
![]() х4 + 0 + х2
+ x
х4 + 0 + х2
+ x
х4 + х3 + х2 + 0 +1
Циклический сдвиг строки матрицы с единицей в старшем (n-м) разряде (слева) равносилен умножению соответствующего строке многочлена на х с одновременным вычитанием из результата многочлена хп +1 = хп— 1, т. е. с приведением по модулю хп + 1.
Отсюда ясно, что любая разрешенная кодовая комбинация циклического кода может быть получена в результате умножения образующего многочлена на некоторый другой многочлен с приведением результата по модулю хп + 1. Иными словами, при соответствующем выборе образующего многочлена любой многочлен циклического кода будет делиться на него без остатка.
Ни один многочлен, соответствующий запрещенной кодовой комбинации, на образующий многочлен без остатка не делится. Это свойство позволяет обнаружить ошибку. По виду остатка можно определить и вектор ошибки.
Умножение и деление многочленов весьма просто осуществляется на регистрах сдвига с обратными связями, что и явилось причиной широкого применения циклических кодов.
11.2 Математическое введение к циклическим кодам
Так как каждая разрешенная комбинация n-разрядного циклического кода есть произведение двух многочленов, один из которых является образующим, то эти комбинации можно рассматривать как подмножества всех произведений многочленов степени не выше n—1. Это наталкивает на мысль использовать для построения этих кодов еще одну ветвь теории алгебраических систем, а именно — теорию колец.
Как следует из приведенного ранее определения (Л. 7), для образования кольца на множестве n-разрядных кодовых комбинаций необходимо задать две операции: сложение и умножение.
Операция сложения многочленов уже выбрана нами с приведением коэффициентов по модулю два.
Определим теперь операцию умножения. Нетрудно видеть, что операция умножения многочленов по обычным правилам с приведением подобных членов по модулю два может привести к нарушению условия замкнутости. Действительно, в результате умножения могут быть получены многочлены более высокой степени, чем п—1, вплоть до 2(п— 1), а соответствующие им кодовые комбинации будут иметь число разрядов, превышающее п и, следовательно, не относятся к рассматриваемому множеству. Поэтому операция символического умножения задается так:
1) многочлены перемножаются по обычным правилам, но с приведением подобных членов по модулю два;
2) если старшая степень произведения не превышает n—1, то оно и явля-ется результатом символического умножения;
3) если старшая степень произведения больше или равна п, то многочлен произведения делится на заранее определенный многочлен степени п и результатом символического умножения считается остаток от деления.
Степень остатка не превышает n—1, и следовательно, этот многочлен принадлежит к рассматриваемому множеству n - разрядных кодовых комбинаций. При анализе циклического сдвига с перенесением единицы в конец кодовой комбинации установлено, что таким многочленом n-й степени является многочлен хп+1.
Действительно, в результате умножения многочлена степени п — 1 на х получим
G(x) = (xn- 1+ xn- 2+…+ x+1)∙x = xn+ xn- 1+…+ x (11.2)
Следовательно, чтобы результат умножения и теперь соответствовал кодовой комбинации, образующейся путем циклического сдвига исходной кодовой комбинации, в нем необходимо заменить хп на 1. Такая замена эквивалентна делению полученного при умножении многочлена на хn+1с записью в качестве результата остатка от деления, что обычно называют взятием остатка или приведением по модулю хп+1 (сам остаток при этом называют вычетом).
Выделим теперь в нашем кольце подмножество всех многочленов, кратных некоторому многочлену g(x). Такое подмножество называют идеалом, а многочлен g(x) — порождающим многочленом идеала.
Количество различных элементов в идеале определяется видом его порождающего многочлена. Если на порождающий многочлен взять 0, то весь идеал будет составлять только этот многочлен, так как умножение его на любой другой многочлен дает 0.
Если за порождающий многочлен принять 1[g(x) =1], то в идеал войдут все многочлены кольца. В общем случае число элементов идеала, порожденного простым многочленом степени n—k, составляет 2k.
Теперь становится понятным, что циклический двоичный код в построенном нами кольце n-разрядных двоичных кодовых комбинаций является идеалом.
Остается выяснить, как выбрать многочлен g(x), способный породить циклический код с заданными свойствами.
12 Лекция 12 Циклические коды. Определение образующего многочлена
Цель лекции: определение и изучение методов помехоустойчивого кодирования. Определение образующего многочлена.
Содержание лекции: циклические коды. Общие понятия и определения. Идеал и порождающий многочлен. Выбор образующего многочлена по заданному объёму кода и заданной корректирующей способности.
12.1 Требования, предъявляемые к образующему многочлену
Согласно определению циклического кода все многочлены, соответствующие его кодовым комбинациям, должны делиться на g(x) без остатка. Для этого достаточно, чтобы на g(x] делились без остатка многочлены, составляющие образующую матрицу кода. Последние получаются циклическим сдвигом, что соответствует последовательному умножению g(x] на х с приведением по модулю хп+1.
Следовательно, в общем случае многочлен gi(x) является остатком от деления произведения g(x) • хi на многочлен хп+ 1 и может быть записан так:
gi(x} = g(x}xi + c(xn+1), (12.1)
где с = 1, если степень g(x)xi превышает п - 1; с = О, если степень g(x)xi не превышает п—1.
Отсюда следует, что все многочлены матрицы, а поэтому и все многочлены кода будут делиться на g(x) без остатка только в том случае, если на g(x) будет делиться без остатка многочлен хп+1.
Таким образом, чтобы g(x) мог породить идеал, а следовательно, и циклический код, он должен быть делителем многочлена хп+1.
Поскольку для кольца справедливы все свойства группы, а для идеала - все свойства подгруппы, кольцо можно разложить на смежные классы, называемые в этом случае классами вычетов по идеалу.
Первую строку разложения образует идеал, причем нулевой элемент располагается крайним слева. В качестве образующего первого класса вычетов можно выбрать любой многочлен, не принадлежащий идеалу. Остальные элементы данного класса вычетов образуются путем суммирования образующего многочлена с каждым многочленом идеала.
Если многочлен g(x) степени m = п — k является делителем хп+1, то любой элемент кольца либо делится на g(x) без остатка (тогда он является элементом идеала), либо в результате деления появляется остаток r(х), представляющий собой многочлен степени не выше m-1.
Элементы кольца, дающие в остатке один и тот же многочлен ri(x), относятся к одному классу вычетов. Приняв многочлены r(х) за образующие элементы классов вычетов, разложение кольца по идеалу с образующим многочленом g(x) степени m можно представить таблице 12.1, где f(x) — произвольный многочлен степени не выше п - m -1.
Т а б л и ц а 12.1
|
0 |
g(x) |
xg(x) |
(x+1)g(x) |
… |
f(x)g(x) |
|
r1(x) |
g(x)+ r1(x) |
xg(x)+ r1(x) |
(x+1)g(x) + r1(x) |
… |
f(x)g(x) + r1(x) |
|
r2(x) |
g(x)+ r2(x) |
xg(x)+ r2(x) |
(x+1)g(x) + r2(x) |
… |
f(x)g(x) + r2(x) |
|
… |
… |
… |
… |
… |
… |
|
… |
… |
… |
… |
… |
… |
|
rz(x) |
g(x)+ rz(x) |
xg(x) + rz(x) |
(x+1)g(x) + rz(x) |
… |
f(x)g(x) + rz(x) |
Как отмечалось, групповой код способен исправить столько разновидностей ошибок, сколько различных классов насчитывается в приведенном разложении. Следовательно, корректирующая способность циклического кода будет тем выше, чем больше остатков может быть образовано при делении многочлена, соответствующего искаженной кодовой комбинации, на образующий многочлен кода.
Наибольшее число остатков, равное 2m-1 (исключая нулевой), может обеспечить только неприводимый (простой) многочлен, который делится сам на себя и не делится ни на какой другой многочлен (кроме 1).
12.2 Выбор образующего многочлена по заданному объёму кода и заданной корректирующей способности
По заданному объему кода однозначно определяется число информационных разрядов k. Далее необходимо найти наименьшее п, обеспечивающее обнаружение или исправление ошибок заданной кратности. В случае циклического кода эта проблема сводится к нахождению нужного многочлена g(x).
Начнем рассмотрение с простейшего циклического кода, обнаруживающего все одиночные ошибки.
12.2.1 Обнаружение одиночных ошибок
Любая принятая по каналу связи кодовая комбинация h(x), возможно содержащая ошибку, может быть представлена в виде суммы по модулю два неискаженной комбинации кода f(x) и вектора ошибки ξ(x):
h(x) = f(x)![]() ξ(x)
( 12.1)
ξ(x)
( 12.1)
При делении h(x) на образующий многочлен g(x) остаток, указывающий на наличие ошибки, обнаруживается только в том случае, если многочлен, соответствующий вектору ошибки, не делится на g(x): f(x) — неискаженная комбинация кода и, следовательно, на g(x) делится без остатка.
Вектор одиночной ошибки имеет единицу в искаженном разряде и нули во всех остальных разрядах. Ему соответствует многочлен ξ(x) = xi. Последний не должен делиться на g(x). Среди неприводимых многочленов, входящих в разложении хп+1, многочленом наименьшей степени, удовлетворяющим указанному условию, является х+1. Остаток от деления любого многочлена на x+1 представляет собой многочлен нулевой степени и может принимать только два значения: 0 или 1. Все кольцо в данном случае состоит из идеала, содержащего многочлены с четным числом членов, и одного класса вычетов, соответствующего единственному остатку, равному 1. Таким образом, при любом числе информационных разрядов необходим только один проверочный разряд. Значение символа этого разряда как раз и обеспечивает четность числа единиц в любой разрешенной кодовой комбинации, а следовательно, и делимость ее на x+ 1.
Полученный циклический код с проверкой на четность способен обнаруживать не только одиночные ошибки в отдельных разрядах, но и ошибки в любом нечетном числе разрядов.
12.2.2 Исправление одиночных или обнаружение двойных ошибок
Прежде чем исправить одиночную ошибку в принятой комбинации из п разрядов, необходимо определить, какой из разрядов был искажен. Это можно сделать только в том случае, если каждой одиночной ошибке в определенном разряде соответствуют свой класс вычетов и свой опознаватель. Так как в циклическом коде опознавателями ошибок являются остатки от деления многочленов ошибок на образующий многочлен кода g(x), то g(x) должно обеспечить требуемое число различных остатков при делении векторов ошибок с единицей в искаженном разряде. Как отмечалось, наибольшее число остатков дает неприводимый многочлен. При степени многочлена т = п - k он может дать 2n- k- 1 ненулевых остатков (нулевой остаток является опознавателем безошибочной передачи).
Следовательно, необходимым условием исправления любой одиночной ошибки является выполнение неравенства
![]() (12.2)
(12.2)
где Сп — общее число разновидностей одиночных ошибок в кодовой комбинации из п символов; отсюда находим степень образующего многочлена кода
т = п — k ≥ log2(n+l) (12.3)
и общее число символов в кодовой комбинации. Наибольшие значения k и п для различных т можно найти, пользуясь таблицей 12.1.
Как указывалось, образующий многочлен g(x) должен быть делителем двучлена хп+1. Доказано [20], что любой двучлен типа x2m-1+1 = хп+1 может быть представлен произведением всех неприводимых многочленов, степени которых являются делителями числа т (от 1 до m включительно).
Т а б л и ц а 12.1
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
п |
1 |
3 |
7 |
15 |
31 |
63 |
127 |
255 |
511 |
1023 |
|
k |
0 |
1 |
4 |
11 |
26 |
57 |
120 |
247 |
502 |
1013 |
![]() Следовательно, для любого т существует по крайней мере
один неприводимый многочлен степени т, входящий сомножителем в разложение двучлена
хп+ 1.
Следовательно, для любого т существует по крайней мере
один неприводимый многочлен степени т, входящий сомножителем в разложение двучлена
хп+ 1.
Пользуясь этим свойством, а также имеющимися [20] таблицами многочленов, неприводимых при двоичных коэффициентах, выбрать образующий многочлен при известных п и т несложно. Определив образующий многочлен, необходимо убедиться в том, что он обеспечивает заданное число остатков.
Пример 12.1 Выберем образующий многочлен для случая п = 15 и m = 4.
Двучлен x15+l можно записать в виде произведения всех неприводимых многочленов, степени которых являются делителями числа 4. Последнее делится на 1, 2, 4. В таблице неприводимых многочленов находим один многочлен первой степени, а именно х+1, один многочлен второй степени х2 + х+1 и три многочлена четвертой степени: х4+ х+1, х4 + х3+1, х4 + х3+ х2 + х+ 1. Перемножив все многочлены, убедимся в справедливости соотношения (х+ 1)(х2 + х + 1)( х4+ х+1)( х4 + х3+ х2 + х+ 1) = x15+l.
Один из сомножителей четвертой степени может быть принят за образующий многочлен кода. Возьмем, например х4 + х3+1, многочлен, или в виде двоичной последовательности 11001.
Степени соответствующих им многочленов меньше степени образующего многочлена g(x). Поэтому они сами являются остатками при нулевой целой части. Остаток, соответствующий вектору ошибки в следующем старшем разряде, получаем при делении 00.. .10000 на 11001, т.е.
1 0000 | 11001
![]() 1 1001
1 1001
1001
Аналогично могут быть найдены и остальные остатки. Однако их можно получить проще, деля на g(x) комбинацию в виде единицы с рядом нулей и выписывая все промежуточные остатки:
1 000000000… | 11001 Остатки
![]() 1 1001
1 1001
10010 1001 1101
![]() 11001
1011 0011
11001
1011 0011
1011 1111 0110
… 0111 1100
… 1110 0001
… 0101 0010
… 1010 0100
… 1000
При последующем делении остатки повторяются.
С тем же успехом за образующий многочлен кода мог быть принят и многочлен х4 + х+1. При этом был бы получен код, эквивалентный выбранному. Однако использовать для тех же целей многочлен х4 + х3 + х2 + x+1 нельзя. При проверке числа различных остатков обнаруживается, что их у него не 15, а только 5. Это объясняется тем, что многочлен х4 + х3 + х2 + х + 1 входит в разложение не только двучлена x15+ 1, но и двучлена х5+ 1.
13 Лекция 13 Циклические коды. Математические основы для построения циклических кодов
Цель лекции: определение и изучение методов помехоустойчивого кодирования. Определение образующего многочлена.
Содержание лекции: циклические коды. Общие понятия и определения. Идеал и порождающий многочлен. Выбор образующего многочлена по заданному объёму кода и заданной корректирующей способности.
13.1 Выбор неприводимого многочлена g(x)
В качестве образующего следует выбирать такой неприводимый многочлен g(x) (или произведение таких многочленов), который, являясь делителем двучлена хп+ 1, не входит в разложение ни одного двучлена типа xλ+1, степень которого К меньше п. В этом случае говорят, что многочлен g(x) принадлежит показателю степени п. В таблице 13.1 приведены основные характеристики некоторых кодов, способных исправлять одиночные ошибки или обнаруживать все одиночные и двойные ошибки.
Т а б л и ц а 13.1
|
|
|
|
|
|
непроводи мого мно- |
Образующий многочлен |
Число остатков |
Длина кода |
|
гочлена |
|
|
|
|
2 |
х2 + х + 1 |
3 |
3 |
|
3 |
х3 + х + 1 |
7 |
7 |
|
3 |
х 3 + х2 + 1 |
7 |
7 |
|
4 |
х4 + х3 + 1 |
15 |
15 |
|
4 |
х4 + х+1 |
15 |
15 |
|
5 |
х5 + х2 + 1 |
31 |
31 |
|
5 |
х5 + х3 + 1 |
31 |
31 |
![]()
Эти коды могут быть
использованы для обнаружения любых двойных ошибок. Многочлен, соответствующий вектору
двойной ошибки, имеет вид ![]() (x) = xi+xj, или
(x) = xi+xj, или ![]() (x) =
xi(xj-i+1) при j>i. Так как j-i<n, a g(x) не кратен х и принадлежит
показателю степени п, то
(x) =
xi(xj-i+1) при j>i. Так как j-i<n, a g(x) не кратен х и принадлежит
показателю степени п, то![]() (x)
не делится на g(x), что
и позволяет обнаружить двойные ошибки.
(x)
не делится на g(x), что
и позволяет обнаружить двойные ошибки.
Обнаружение ошибок кратности три и ниже. Образующие многочлены кодов, способных обнаруживать одиночные, двойные и тройные ошибки можно определить, базируясь на следующем указании Хэмминга. Если известен образующий многочлен р(хт} кода длины п, позволяющего обнаруживать ошибки некоторой кратности 2, то образующий многочлен g(x) кода, способного обнаруживать ошибки следующей кратности (z+1), может быть получен умножением многочлена р(хт) на многочлен х+1, что соответствует введению дополнительной проверки на четность. При этом число символов в комбинациях кода за счет добавления еще одного проверочного символа увеличивается до n+1.
В таблице 13.2 приведены основные характеристики некоторых кодов, способных обнаруживать ошибки кратности три и менее.
Т а б л и ц а 13.2
|
|
|
Число |
|
|
неприводимого много- |
Образующий многочлен |
информационных |
Длина кода |
|
члена |
|
символов |
|
|
3 |
(x + 1)(х3 + x + 1) |
4 |
8 |
|
4 |
(х+ 1)(х4+ х+ 1) |
11 |
16 |
|
5 |
(x +1)( х 5 + х + 1) |
26 |
32 |
|
|
|
|
|
13.2 Обнаружение и исправление независимых ошибок произвольной кратности
Важнейшим классом кодов, используемых в каналах, где ошибки в последовательностях символов возникают независимо, являются коды Боуза — Чоудхури — Хоквингема. Доказано, что для любых целых положительных чисел т и s<n/2 существует двоичный код этого класса длины п = 2т—1 с числом проверочных символов не более ms, который способен обнаруживать ошибки кратности 2s или исправлять ошибки кратности s. Для понимания теоретических аспектов этих кодов необходимо ознакомиться с рядом новых понятий высшей алгебры.
13.2.1 Обнаружение и исправление пачек ошибок. Для произвольного линейного блокового (п, k)-кода, рассчитанного на исправление пакетов ошибок длины b или менее, основным соотношением, устанавливающим связь корректирующей способности с числом избыточных символов, является граница Рейджера:
n - k ≥ 2b. (13.1)
При исправлении линейным кодом пакетов длины b или менее с одновременным обнаружением пакетов длины l≥b или менее требуется по крайней мере b+l проверочных символов.
Из циклических кодов, предназначенных для исправления пакетов ошибок, широко известны коды Бартона, Файра и Рида — Соломона.
Первые две разновидности кодов служат для исправления одного пакета ошибок в блоке. Коды Рида — Соломона способны исправлять несколько пачек ошибок.
13.3 Методы образования циклического кода
Существует несколько различных способов кодирования. Принципиально наиболее просто комбинации циклического кода можно получить, умножая многочлены а(х), соответствующие комбинациям безызбыточного кода (информационным символам), на образующий многочлен кода g(x). Такой способ легко реализуется. Однако он имеет тот существенный недостаток, что получающиеся в результате умножения комбинации кода не содержат информационные символы в явном виде. После исправления ошибок такие комбинации для выделения информационных символов приходится делить на образующий многочлен кода.
Применительно к циклическим кодам принято (хотя это и не обязательно) отводить под информационные k символов, соответствующих старшим степеням многочлена кода, а под проверочные n — k символов низших разрядов.
Чтобы получить такой систематический код, применяется следующая процедура кодирования.
Многочлен а(х), соответствующий k-разрядной комбинации безизбыточного кода, умножаем на хт, где т = п — k. Степень каждого одночлена, входящего в а(х), увеличивается, что по отношению к комбинации кода означает необходимость приписать со стороны младших разрядов m нулей. Произведение а(х)хт делим на образующий многочлен g(x). В общем случае при этом получаем некоторое частное q(x) той же степени, что и а(х) и остаток r(х). Последний прибавляем к а(х)хт. В результате получаем многочлен
f(x) = a(x)xm + r(x). (13.2)
Поскольку степень g(x) выбираем равной т, степень остатка r(х) не превышает m—1. В комбинации, соответствующей многочлену а(х)хт, т младших разрядов нулевые, и, следовательно, указанная операция сложения равносильна приписыванию r(х) к а(х) со стороны младших разрядов.
Покажем, что f(x) делится на g(x) без остатка, т. е. является многочленом, соответствующим комбинации кода. Действительно, запишем многочлен а(х)хт в виде
a(x)xm=q(x)g(x) + r(x). (13.3)
Так как операции сложения и вычитания по модулю два идентичны, r(х) можно перенести влево, тогда
а(х)хт + r(x) = f(x) = q(x)g(x) (13.4)
что и требовалась доказать.
Таким образом, циклический код можно строить, приписывая к каждой комбинации безизбыточного кода остаток от деления соответствующего этой комбинации многочлена на образующий многочлен кода. Для кодов, число информационных символов в которых больше числа проверочных, рассмотренный способ реализуется наиболее просто.
Следует указать еще на один способ кодирования. Так как циклический код является разновидностью группового кода, то его проверочные символы должны выражаться через суммы по модулю два определенных информационных символов.
Равенства для определения проверочных символов могут быть получены путем решения рекуррентных соотношений
![]() (13.5)
(13.5)
где h— двоичные коэффициенты так называемого генераторного многочлена h(х), определяемого так
h(x) = (xn + 1)/g(x) = h0 + h1 x +... + hk x. (13.6)
Соотношение (13.6) позволяет по заданной последовательности информационных сигналов a0, a1 ..., ak-1 вычислить п — k проверочных символов ak,, ak+1, …, an-1 роверочные символы, как и ранее, размещаются на местах младших разрядов.
13.4 Матричная запись циклического кода
Полная образующая матрица циклического кода Mn,k составляется из двух матриц: единичной Ik (соответствующей k информационным разрядам) и дополнительной Ck,n-k (соответствующей проверочным разрядам):
Mn,k= ||IkС.k,n-k ||. (13.7)
Построение матрицы Ik трудностей не представляет.
Если образование циклического кода производится на основе решения рекуррентных соотношений, то его дополнительную матрицу можно определить, воспользовавшись правилами, указанными ранее. Однако, обычно строки дополнительной матрицы циклического кода Ck,n-k определяются путем вычисления многочленов r(х). Для каждой строки матрицы Ik соответствующий r(х) находят делением информационного многочлена а(х)хт этой строки на образующий многочлен кода g(x).
Пример 13.1 Запишем образующую матрицу для циклического кода (15,11) с порождающим многочленом g(x) = х4 + х3 + 1.
Воспользовавшись результатами ранее проведенного деления, получим
M15,11 = 
Существует другой способ построения образующей матрицы, базирующийся на основной особенности циклического (п, k)-кода (Л.№11). Он проще описанного, но получающаяся матрица менее удобна.
Матричная запись кодов достаточно широко распространена.
13.5 Укороченные циклические коды
Корректирующие возможности циклических кодов определяются степенью т образующего многочлена. В то время как необходимое число информационных символов может быть любым целым числом, возможности в выборе разрядности кода весьма ограничены. Однако можно построить код минимальной разрядности, заменив в (п, k) -коде j первых информационных символов нулями и исключив их из кодовых комбинаций. Код уже не будет циклическим, поскольку циклический сдвиг одной разрешенной кодовой комбинации не всегда приводит к другой разрешенной комбинации того же кода. Получаемый таким путем линейный (п-j, k -j)-код называют укороченным циклическим кодом. Минимальное расстояние этого кода не менее, чем минимальное кодовое расстояние (п, k)-кода, из которого он получен. Матрица укороченного кода получается из образующей матрицы (п, k)-кода исключением j строк и столбцов, соответствующих старшим разрядам. Например, образующая матрица кода (9,5), полученная из матрицы кода (15,11), имеет вид
M9,5 = 
Список литературы
1. Сергиенко А.Б. Цифровая обработка сигналов. – СПб.: Питер, 2002.
2. Гультяев А.К. MATLAB 5.2. Имитационное моделирование в среде Windows: Практическое пособие. – СПб.: КОРОНА принт, 1999.
3. Гоноровский И.С. Радиотехнические цепи и сигналы. – М.: Радио и связь, 1994.
4. Дмитриев В.И. Прикладная теория информации. – М.: Высшая школа, 1989.
5. Зюко А.Г. Теория передачи сигналов. – М.: Радио и связь, 1986.
6. Баскаков С.И. Радиотехнические цепи и сигналы. – М.: Высшая школа, 2000.
7. Баранов А.А. Квантование по уровню и временная дискретизация в цифровых системах управления. – М., 1990.
8. Баричев С.Г. Основы современной криптографии: Учебный курс. – М.: 2001.
9. Куприянов М.С. Техническое обеспечение цифровой обработки сигналов: Справочник. – СПб.: Наука и техника, 2000.
10. Разевиг В.Д., Лаврентьев Г.В., Златин И.Л. SystemView средство системного проектирования радиоэлектронных устройств - М.:Горячая линия-Телеком, 2002.
11. Скляр Б. Цифровая связь: Теоретические основы и практическое применениею - М.: Вильямс, 2003.
12. Гаранин М.В., Журавлев В.И., Кунегин С.В. Системы и сети передачи
Информацию - М.: Радио и связь, 2000.
13. Передача дискретных сообщений: Учебник/Под ред. В.П. Шувалова. -
М.: Радио и связь, 1990.