Некоммерческое акционерное общество
АЛМАТИНСКИЙ УНИВЕРСИТЕТ ЭНЕРГЕТИКИ И СВЯЗИ
Кафедра инженерной кибернетики
АЛГОРИТМИЗАЦИЯ И ПРОГРАММИРОВАНИЕ
Конспект лекций
для студентов специальности 5В074600 – Космическая техника и технологии
Алматы 2013
СОСТАВИТЕЛИ: Г.А.Омарова «Алгоритмизация и программирование». Конспект лекций для студентов специальности 5В074600 – Космическая техника и технологии. - Алматы: АУЭС, 2013.-74 с.
Конспект лекций содержит классический подход при изучении алгоритмов в среде программирования С/С++.
Ил.-28, табл.-8, библиогр.-9
Рецензент: ст.преподаватель Шахматова Г.А.
Печатается по плану издания некоммерческого акционерного общества “Алматинский университета энергетики и связи” на 2013г.
© НАО “Алматинский университет энергетики и связи”, 2013 г.
Содержание
|
Введение |
4 |
|
Лекция №1. Понятие алгоритма. Свойства и классы алгоритмов. Формы представления алгоритмов. Лексические основы языка |
5 |
|
Лекция №2. Структура программы. Операторы ввода-вывода |
15 |
|
Лекция №3. Операторы ветвления. Операторы перехода |
20 |
|
Лекция №4. Операторы цикла |
25 |
|
Лекция №5. Одномерные массивы |
29 |
|
Лекция №6. Строки |
30 |
|
Лекция №7. Многомерные массивы |
33 |
|
Лекция №8. Функции |
35 |
|
Лекция №9. Указатели |
39 |
|
Лекция №10. Массивы и указатели |
42 |
|
Лекция №11. Структуры |
47 |
|
Лекция №12. Объединения |
50 |
|
Лекция №13. Файлы |
53 |
|
Лекция №14. Динамическое использование памяти |
56 |
|
Лекция №15. Динамические структуры |
59 |
|
Список литературы |
67 |
|
Приложение А |
68 |
|
Приложение Б |
69 |
|
Приложение В |
70 |
|
Приложение Г |
71 |
|
Приложение Д |
72 |
|
Приложение Е |
74 |
Введение
В разработанном курсе лекций по дисциплине «Алгоритмизация и программирования» рассматриваются основные понятия и свойства алгоритма. Изучение программирования базируется на наиболее распространенном языке программирования С/С++ для персональных компьютеров и описаны применение средств языка на примерах.
Данный курс лекций имеет классический методологический подход, когда изучение основывается на базовых понятиях и концепциях, а движение происходит от элементарных понятий к составным, от элементарных методов к сложным. Освещаются основные понятия и приемы программирования, а также рассмотрены типы данных и способы и определения. Описываются организация ввода-вывода, операторов перехода и циклов. Рассматриваются вопросы работы со сложными структурами данных таких как массивы, структуры, объединения, разновидности списков и куч.
Курс предназначен для студентов специальностей 5B074600 – «Космическая техника и технологии» и способствует приобретению студентами фундаментальных знаний по программированию.
Лекция №1. Понятие алгоритма. Свойства и классы алгоритмов. Формы представления алгоритмов. Лексические основы языка
Цель лекции: изучение свойств и классов алгоритмов, формы представления алгоритмов, лексических основ языка С/С++.
Алгоритм — точное и понятное предписание исполнителю совершить последовательность действий, направленных на решение поставленной задачи.
Основные свойства алгоритмов следующие:
- понятность для исполнителя, т.е. исполнитель алгоритма должен знать, как его выполнять;
- дискретность (прерывность, раздельность), т.е. алгоритм должен представлять процесс решения задачи как последовательное выполнение простых (или ранее определенных) шагов (этапов);
- определенность, т.е. каждое правило алгоритма должно быть четким, однозначным;
- результативность (или конечность), т.е. алгоритм должен приводить к решению задачи за конечное число шагов;
- массовость, т.е. алгоритм решения задачи pазpабатывается в общем виде (он должен быть применим для некоторого класса задач, различающихся лишь исходными данными), при этом исходные данные могут выбираться из некоторой области, которая называется областью применимости алгоритма.
Алгоритм может быть определен не для любой задачи и для некоторых задач могут быть несколько алгоритмов.
Классы алгоритмов можно подразделить на:
- вычислительные;
- информационные;
- управляющие;
- реального времени.
Формы представления алгоритмов:
- словесная (записи на естественном языке);
- графическая (изображения из графических символов (блок-схема));
- псевдокоды (полуформализованные описания алгоритмов на условном алгоритмическом языке, включающие в себя как элементы языка программирования, так и фразы естественного языка, общепринятые математические обозначения и др.);
- программная (тексты на языках программирования).
Команды алгоритма можно разделить на простые (определяют 1 шаг алгоритма, переработки (отображения информации) – ввод/вывод, присваивание) и составные (формируются из простых команд). Логическая структура любого алгоритма может быть представлена комбинацией трех базовых структур: следование, ветвление, цикл. Базовая структура «следование» образуется из последовательности действий, следующих одно за другим:
{
Оператор 1
Оператор 2
…
Оператор N
}
Базовая структура «ветвление» обеспечивает, в зависимости от результата проверки условия (да или нет), выбор одного из альтернативных путей работы алгоритма. Каждый из путей ведет к общему выходу, так что работа алгоритма будет продолжаться независимо от того, какой путь будет выбран. Структура «ветвление» существует в четырех основных вариантах:
- если-то (см. рисунок 1.1);
- если-то-иначе (см. рисунок 1.2);
- выбор (см. рисунок 1.3);
- выбор-иначе (см. рисунок 1.4).
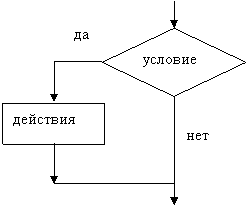 |
Рисунок 1.1 – Базовая алгоритмическая структура ветвления («если-то»)
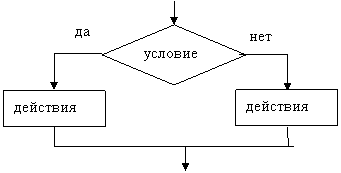 |
Рисунок 1.2– Базовая алгоритмическая структура ветвления («если-то-иначе»)
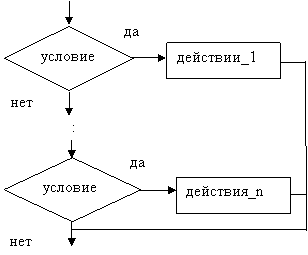 |
Рисунок 1.3– Базовая алгоритмическая структура ветвления («выбор»)
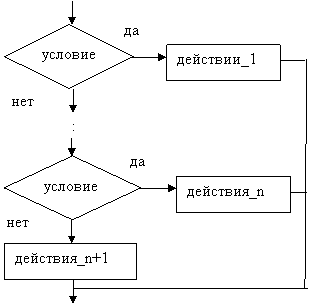 |
Рисунок 1.4 – Базовая алгоритмическая структура ветвления («выбор-иначе»)
Базовая алгоритмическая структура «цикл» обеспечивает многократное выполнение некоторой совокупности действий, которая называется телом цикла.
Цикл с предусловием.
Предписывает выполнять тело цикла до тех пор, пока выполняется условие, записанное после слова «пока» (см. рисунок 1.5).
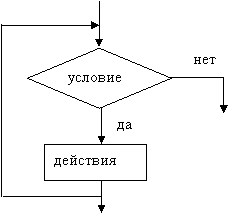
Рисунок 1.5 – Базовая алгоритмическая структура с предусловием.
Основная программная единица на языке Си – это текстовый файл с названием <имя>.срр, где срр – принятое расширение для программ на языке Си, а имя выбирается произвольно.
Исходный модуль (source code) вначале обрабатывается препроцессором, в задачи которого входит подключение при необходимости к данной программе внешних файлов, указываемых при помощи директивы (команды) #include
Например:
#include <имя__файла_1>
/* здесь поиск файла производится в специальном разделе подстановочных файлов*/
#include “имя _файла _2”
/* здесь поиск файла производится вначале в текущем разделе */
Далее измененный препроцессором исходный тест программы поступает на компиляцию. Компилятор выделяет из текста программы лексические элементы (лексемы), а затем распознает смысловые конструкции языка (выражения, определения, описания, операторы и т.д.), построенные из этих лексем. В результате работы компилятора формируется объектный модуль программы (object code). Объектный модуль не может быть выполнен. Это незавершенный вариант машинной программы. К объектному модулю в общем случае должны быть подсоединены модули стандартной библиотеки, и он должен быть настроен по месту выполнения. Исполняемый (абсолютный) модуль создает компоновщик (linker), объединяя в один общий модуль объектные модули, реализующие отдельные части алгоритма. На этом этапе к машинной программе подсоединяются необходимые функции стандартной библиотеки. Стандартная библиотека (library) — набор программных модулей, выполняющих наиболее часто встречающиеся в программировании задачи: ввод, вывод данных, вычисление математических функций, сортировки, работа с памятью и т.д. Модули библиотеки хранятся в откомпилированном виде. Ошибки, возникающие на этапе компиляции (ошибки компиляции), разделяют на синтаксические и семантические. В период выполнения программы могут быть ошибки выполнения. Они появляются либо из-за некорректной постановки задачи, либо из-за недопустимых данных и др.
Алфавит языка. Множество символов языка Си можно разделить на четыре группы. В первую группу входят буквы латинского алфавита и символ подчеркивания. Вторую группу используемых символов составляют цифры: 0, 1, ... , 9. В третью группу входят специальные символы. Четвертую группу символов составляют управляющие последовательности (ESC-последовательности — escape), используемые при вводе/выводе информации (см. приложение А). Управляющая последовательность начинается со знака обратной черты. Из символов и специальных символов (см. приложение Б) алфавита формируются лексемы языка:
- идентификаторы;
- ключевые слова;
- константы;
- знаки операций;
- разделители.
Идентификаторы. Идентификатор – это последовательность из букв латинского алфавита, цифр и символов подчеркивания. Идентификатор должен начинаться не с цифры, не совпадать с зарезервированными словами и именами функций из библиотеки языка. Компилятор различает идентификаторы 32 первых символа, а остальные игнорируются (буквы нижнего и верхнего регистров различаются). Данные в оперативной памяти размещаются по некоторым адресам, имена которым дает программист. Компилятор заменит условные имена адресами данных в оперативной памяти.
Следует обратить особое внимание на использование символа «_», подчеркивание в качестве первого символа идентификатора, поскольку идентификаторы, построенные таким образом, что, с одной стороны, могут совпадать с именами системных функций и (или) переменных, а с другой стороны, при использовании таких идентификаторов программы могут оказаться непереносимыми, т.е. их нельзя использовать на компьютерах других типов. На идентификаторы, используемые для определения внешних переменных, должны быть наложены ограничения, формируемые используемым редактором связей (отметим, что использование различных версий редактора связей, или различных редакторов, накладывает различные требования на имена внешних переменных).
Примеры: sum, result, n, m, clO, Beta, beta, letter, array и т.д.
Ошибочные идентификаторы:i+b, -omega, 9c, if, int, long, &b, %f.
Ключевые (служебные) слова. Ключевые (служебные) слова - это идентификаторы, зарезервированные в языке для специального использования. Ключевые слова сообщают компилятору о типе данных, способе их организации, о последовательности выполнения операторов.
К ключевым словам языка Си относятся: auto break case char const continue default do double els enum extern float for if int long register return shoi signed sizeof struct switch typedef union unsigned void volatile while catch class delete friend inline new template operator private protected public try virtual throw this_asm, fortran, near, far, cdecl, huge, paskal, interrupt. К ключевым словам языка С++ относятся: catch cin class cout delete friend inline new operator private protected. Ключевые слова: far, huge, near - позволяют определить размеры указателей на области памяти. Ключевые слова: _asm, cdelc, fortran, pascal - служат для организации связи с функциями, написанными на других языках, а также для использования команд языка ассемблера непосредственно в теле разрабатываемой программы на языке Си.
Ключевые слова не могут быть использованы в качестве идентификаторов.
Комментарии. Комментарии представляют собой текстовые части, формированные как последовательность знаков (символов), начиная знаками:
/* текст многострочного комментария */
// - однострочный комментарий
Комментарии исключаются из исходного текста программы транслятором.
Пример: /* функция вычисляет сумму */
В стандартном языке Си комментарии запрещено вкладывать друг в друга, их нельзя помещать внутрь строк или текстовых литералов.
Неправильное определение комментариев:
/* комментарии к алгоритму /* решение краевой задачи */ */
или
/* комментарии к алгоритму решения */ краевой задачи */
Константы. Константа – это лексема, представляющая изображение фиксированного строкового или символьного значения, которая в процессе выполнения программы не изменяется. Они делятся на целые, вещественные, перечислимые, символьные и строковые. Для константы выделяется место в оперативной памяти, но адрес размещения константы неизвестен, и его нельзя получить программным путем. В языке С/C++ для задания имен констант и макроопределений обычно употребляются заглавные буквы.
Синтаксис:
сonst тип имя_константы значение_константы;
Возможность вводить именованные константы обеспечивает препроцессорная директива:
#define имя_константы значение_константы
Здесь точка с запятой в конце директивы не ставится.
Например: #define pi 3.14
Константы целого типа. Константы целого типа могут задаваться в виде десятичных, восьмеричных и шестнадцатеричных системах счислениях:
- десятичные: образуют из цифр, где первый не должен быть нуль;
- восьмеричные: начинаются с цифры 0, а далее цифры 0-7, например:
037
- шестнадцатеричные: используется алфавит шестнадцатеричной системы счисления 0-f, начинающиеся с цифры 0 и символа Х (х), например:
0хD96.
К любой целой константе можно приписать справа символ L(l) для обозначения длинной целой, а символ U(u) для обозначения целой константы без знака. Например:
64L 0x55u
Вещественные константы. Константы с плавающей точкой имеют другую форму внутреннего представления в ЭВМ. В записях вещественные константы могут опускаться либо целая, либо дробная части; суффикс; десятичная точка или признак экспоненты с показателем степени (но не одновременно).
Например:
2F+6L
Суффикс f,F - придают тип данных float; l,L - тип long double.
Перечислимые константы. Перечислимые константы вводятся с помощью служебного слова enum. По существу, это обычные целочисленные константы, которым приписаны уникальные обозначения. В качестве обозначений выбираются произвольные идентификаторы, не совпадающие со служебными словами и именами других объектов программы.
Синтаксис:
еnum имя_ типа{список_именованных_ констант};
Перечислимые константы могут иметь и отрицательные значения, а также может быть введено имя типа. Имя типа- это произвольно выбираемый идентификатор, который может в дальнейшем использоваться в определениях и описаниях других объектов.
Пример 1:
enum week{sunday, monday, tuesday, wedneday, thurday, friday, saturday}; /*где sunday присвоено значение нуля, а monday единице и т.д.*/
Пример 2:
enum {one=1, two =2, three=3}; /* здесь enum – служебное слово, определяющее тип; one-three – условные имена, для обозначение констант: 1-3.*/
Если в определении констант опускать значение «=» и не указывать числовых значений, то они будут приписываться идентификаторам (именам), по умолчанию. Первый получит значение 0, потом 1 и т.д.
Пример1:
enum {zero,one,two,three}; /*здесь константы примут значения: zero=0; one=1 и т.д.*/
Пример 2:
enum {ten=10,three=3, four, five, six}; /*здесь значение four будет равно 4, five =5 и т.д.*/
Значения у перечислимых констант могут быть и в виде выражений, например:
enum {two=2, four=two*2};
Символьные константы. Символьные константы – это один или два символа, заключенные в апострофы (одиночные кавычки). Односимвольные константы имеют стандартные тип char, например:
‘с’ ‘n’
В языке C++ разрешается использовать двусимвольные константы, например:
‘ db’ ‘\r \a’ ‘\n\ t’
Константы такого вида в памяти занимают 2 байта памяти. В первом (младшем) байте храниться код первого символа, во втором (старшем) – код второго символа (‘b’ ‘a’ ‘t’).
Символьная константа не может содержать в себе одиночную кавычку «'» или символ новой строки; чтобы изобразить их и некоторые другие символы, могут быть использованы эскейп-последовательности (см. приложение Б).
Строковая константа. Строковая константа – это последовательность символов заключенные в двойные кавычки. Формально строковые константы не относятся к константам языка Си, а представляют собой отдельный тип его лексем.
Например:
“строковая константа”
Типы данных. В любом алгоритмическом языке каждая константа, переменная, результат вычисления выражения или функции должны иметь определенный тип. Существуют следующие базовые типы: char (символьный), int (целый), float вещественный), double (вещественный с двойной точностью), void (пустой). Иерархию типов данных смотри в приложении В. К модификаторам относятся: unsigned (без знаковый), signed (знаковый), short (короткий), long (длинный). Тип данных и модификатор типа определяют:
- формат хранения данных в оперативной памяти (внутреннее представление данных);
- диапазон значений, в пределах которого может изменяться переменная;
- операции, которые могут выполняться над данными соответствующего типа.
В зависимости от типа данных и модификатора типа, для обработки данных будут использоваться те или иные машинные команды микропроцессора.
Данные целого типа. Для того чтобы обеспечить возможность работы с числами любой величины, в большинстве компиляторов Си определено несколько типов целочисленных данных. Границы для разных типов могут различаться, в зависимости от конкретного компилятора. Характеристики данных приведены в таблице 1.
Таблица 1 - Характеристики чисел целого типа
|
Тип |
Размер, байт |
Диапазон значений |
|
signed int |
2 |
-32768…32767 |
|
unsigned int |
2 |
0…65535 |
|
signed long int |
4 |
2147783648…2147483647 |
|
unsigned long int |
4 |
0…4294967295 |
Ключевые слова signed и unsigned необязательны. Они указывают, как интерпретируется старший бит переменной. Если указано ключевое слово unsigned, то левый бит данного рассматривается как часть числа. Если же указано ключевое слово signed, то левый бит интерпретируется как знак. Старший бит знаковых типов int, short int и long int хранит знак числа. Если в этом бите записан нуль, то число положительное, если он равен 1 — отрицательное. Положительные числа хранятся в памяти и вступают в операции в прямом коде, т.е. в обычном двоичном представлении числа. Отрицательные числа хранятся в памяти компьютера в дополнительном коде. По умолчанию, все переменные целого типа считаются signed. Ключевые слова signed и unsigned могут предшествовать любому целому типу. По умолчанию, все целочисленные типы считаются знаковыми, то есть спецификатор signed можно опускать.
Вещественные типы данных.
Характеристики данных приведены в таблице 2.
Таблица 2 - Характеристики чисел вещественного типа
|
Тип |
Размер, байт |
Диапазон значений |
точность |
|
float |
4 |
1.17 в порядке возрастания E-38…3.37 38 |
7 |
|
double |
8 |
2.23E-308…1.67E 308 |
15 |
|
long double |
10 |
3.37E-4932…1.2E 4932 |
19 |
Все числа с плавающей запятой представляются в виде двух частей: мантиссы и порядка числа в двоичной системе счисления. Величины типа float занимают 4 байта. Из них 1 бит отводится для знака. 8 битов для избыточной экспоненты и 23 бита для мантиссы.
Символьные данные. Под величину символьного типа отводится в памяти 1 байт. Коды цифр и латинских букв идут в порядке возрастания. Тип char, как и другие целые типы, может быть со знаком или без знака. В величинах со знаком можно хранить значения в диапазоне от -128 до 127. При использовании спецификатора unsigned значения могут находиться в пределах от 0 до 255. Этого достаточно для хранения любого символа из 256-символьного набора ASCII. Величины типа char применяются также для хранения целых чисел, не превышающих границы указанных диапазонов. Однако есть различия между символом «1» и числом 1. Как символ единица не может использоваться в математических операциях, поскольку она не рассматривается в этом случае как математическая величина, так и для хранения символа «1» отводится объем памяти вполовину меньший, чем для хранения числа 1.
Переменные. Данные, значения которых во время выполнения программы можно изменять, называются переменными. В программе все данные перед их использованием должны быть объявлены или определены. В операторах определения данных указывается тип данных и перечисляются через запятую имена переменных, имеющих данный тип. В модуле, где записано определение переменных, для каждой переменной в соответствии с типом выделяется необходимое количество байтов памяти. Выделенному полю байтов присваивается имя переменной, которое в дальнейшем используется в программе. Отличие объявления от определения заключается в том, что при объявлении переменной место ей в памяти соответствующей функции не выделяется, объявление лишь сообщает компилятору тип переменной. Место же для значения переменой запрашивается в другой функции.
Определение переменных имеет следующий формат:
<спецификатор_класса_памяти > <спецификатор_типа>
идентификатор_1 [=начальное значение] , …
идентификатор_n [=начальное значение];
Идентификатор (имя переменной) может быть записан с квадратными скобками, круглыми скобками или перед ним может быть один или несколько знаков * (звездочка). Спецификатор типа — одно или несколько ключевых слов, определяющих тип переменной. Язык Си определяет стандартный набор основных типов данных (int, char, double), применяя которые пользователь может объявлять свои производные (структурированные) типы (массив, структура, объединение и др.). При определении переменных им можно присвоить начальное значение.
Четыре ключевых слова: auto, extern, register и static - определяют класс памяти, или каким образом для объявляемой переменной распределяется память и в каких фрагментах программы можно использовать ее значение. Если ключевое слово, определяющее класс памяти, опущено, то класс памяти определяется по контексту.
Определения и объявления переменных рекомендуется размещать в начале программного модуля.
Спецификатор типа — одно или несколько ключевых слов, определяющее тип переменной. Язык Си определяет стандартный набор основных типов данных (int, char, float), применяя которые пользователь может объявлять свои производные (структурированные) типы (массив, структура, объединение и др.). При определении переменных им можно присвоить начальное значение. Операцию можно использовать и для определения длины переменной типа, объявленного пользователем. Ключевое слово void (пусто), записанное вместо типа, обычно применяется для работы с данными через указатель и позволяет отложить определение типа до извлечения значения по этому указателю.
Лекция №2. Структура программы. Операторы ввода-вывода
Цель лекции: изучение структуры программы на языке С/ С++: определения объявлений, определений и операций, операторы ввода-вывода.
Любая Си-программа, каков бы ни был ее размер, состоит из одной или более функций (подпрограмм), указывающих фактические операции компьютера, которые должны быть выполнены. Mожно давать функциям любые имена, но среди них есть одно главное - main; выполнение программы начинается сначала с функции main. Это означает, что каждая программа должна в каком-то месте содержать функцию с именем main. Для выполнения определенных действий функция main обычно обращается к другим функциям, часть из которых находится в той же самой программе, а часть - в библиотеках, содержащих ранее написанные функции.
Одним из способов обмена данными между функциями является передача посредством аргументов. Круглые скобки, следующие за именем функции, заключают в себе список аргументов; здесь main — функция без аргументов, что указывается как (). Операторы, составляющие тело функции, заключаются в фигурные скобки { и }. Обращение к функции осуществляется указанием ее имени, за которым следует заключенный в круглые скобки список аргументов. Круглые скобки должны присутствовать и в том случае, когда функция не имеет аргументов.
Исходная программа состоит из следующих объектов: директив (перечисление и подключение директив происходит в начале программы), указаний компилятору, объявлений и определений.
Директивы задают действия препроцессора по преобразованию текста программы перед компиляцией.
Указания компилятору — это команды, выполняемые компилятором во время процесса компиляции.
Объявления задают имена и атрибуты переменных, функций и типов, используемых в программе.
Определения — это объявления, определяющие переменные и функции. Определение переменной в дополнение к ее имени и типу задает начальное значение объявленной переменной. Кроме того, определение предполагает распределение памяти для переменной.
Языки С/C++ являются языками свободного формата. Это означает, что для них не имеет значения, где будут помещены ограничители и начало строки. Ниже приводится текст простой программы на языке Си.
#include <stdio.h>
int x=i; int y=2; // Определение глобальных переменных х и у
void main ()
{ int z,w; // Объявление локальных переменных z и w
z=y+x; w=y-x; // Операторы вычисления
printf ("z=%d\nw=%d",z,w); /* Обращение к функции printf, которая
выводит на экран результаты вычисления */
}
В первой строке указана команда препроцессора #include, по которой к программе будет подсоединен раздел системной библиотеки, содержащий функции ввода/вывода на стандартные устройства (клавиатуру — stdin и экран - stdout). stdio.h — имя этого раздела (standard input / output header). Переменные х и у задаются своими определениями. Переменные z и w только объявляются. Далее переменным z и w присваиваются сумма и разность переменных у и х. Функция printf позволяет вывести на экран строки "z= 3" и "w = 1".
Каждый оператор, а также каждая строка с вызовом функции оканчиваются точкой с запятой (;). Исключение составляют команды препроцессора и имена функций, стоящие в начале программной единицы.
Операции. Операции – это специальные комбинации символов, предназначенные для преобразования некоторых величин. Лексема(token) – это неразделимая комбинация величин, которую интерпретирует компилятор. Операции, имеющие одинаковый приоритет выполнения, вычисляются последовательно. Порядок выполнения операции (см. приложение Д) происходит слева направо и приоритет операций уменьшается сверху вниз.
Функции ввода-вывода.
Функции форматированного вывода. Для этого используются следующие функции: printf(), sprint(), cprintf() и определяется в библиотеке stdio.h. Функция printf() выводит форматированные данные в стандартный поток; sprintf() выводит форматированные данные в строку; cprintf () выводит форматированные данные в текстовое окно.
Синтаксис функции printf():
printf(<управляющая строка>, <список переменных>);
где <список переменных> - перечень идентификаторов переменных, значения которых необходимо вывести на экран; <управляющая строка> содержит: простые сообщения, выводимые на экран без изменения, эти сообщения могут содержать произвольные символы; спецификации формата вывода переменных; специальные символы или символы, управляющие последовательности.
Спецификации формата начинаются с символа %, за которым следует код формата (см. приложение Г).
В функции printf() существует возможность задания вывода переменных определенного формата, а именно: можно задавать ширину поля переменных, определять точность вывода вещественных переменных, определять тип выравнивания данных и т.д. В этом случае спецификации формата записывается в такой форме:
%[флаг][ширина].[точность]спецификация
где флаг – тип выравнивания (пусто – выравнивания по правому краю («–» – выравнивания по левому краю, «+» – всегда печатать знак числа);
ширина – общая длина поля вывода, т.е. общее количество символов при выводе, включая знак и десятичную точку;
точность – количество цифр числа после запятой.
Пример спецификации формата:
%8.4f – вывод вещественной переменной с выравниванием по правому краю, общее количество символов при выводе –8 позиций( включая точку), количество знаков после десятичной точки – 4;
Функция putchar()– записывает в стандартный поток вывода. Синтаксис:
int putchar(int character);
Функция puts()-записывает символьную строку в стандартный поток данных. Нуль терминатор заменяется символом новой строки (/n).
Например:
puts ("Привет");
Пример:
/*строковая константа: */
#define MESSAGE " Привет"
main()
{
puts(MESSAGE);
}
/*строковая переменная: */
char greeting[]=" Привет";
main()
{
puts(geering);
}
Функция форматированного ввода scanf(). Функция позволяет ввести информация с клавиатуры и является многоцелевой функцией, дающей возможность вводить в компьютер данные любых типов. Название функции отражает ее назначение — функция сканирует (просматривает) клавиатуру, определяет, какие клавиши нажаты, и затем интерпретирует ввод, основываясь на указателях формата (SCAN Formatted characters). Также функция scanf() может иметь несколько аргументов, позволяя тем самым вводить значения числовых, символьных и строковых переменных в одно и то же время. Функция определяется в библиотеке <stdio.h>.
Синтаксис:
scanf(<управляющая строка>, <список адресов переменных>);
где <управляющая строка> - строка, которая может содержать только спецификации формата; перечень допустимых значений спецификаций тот же самый, что и для функции printf();
<список адресов переменных> - это список, который содержит перечисленные через запятую адреса переменных, вводимых функцией (адрес переменной указывается символом & и далее идет идентификатор переменной).
Для массивов и строк указывать символ & не обязательно. В управляющей строке нежелательно использовать никаких лишних символов (даже пробелов), кроме спецификаций, а также нельзя использовать и специальные символы, например:
scanf(“%f%d”,&x1,&x2);
Функция ввода строки gets(). Считывает символьную строку из стандартного входного потока и помещает ее по адресу, заданному указателем. Прием строки заканчивается, если функция заканчивается символом «/n»( Данный символ удаляется и заменяется на нуль-терминатор «/0») либо читает все, что набирается до тех пор, пока не нажат «Ввод»(«enter»).
Синтаксис:
сhar *gets (char *f);
/*Возвращает указатель на считанную строку.*/
Пример:
…main()
{
char name[15];
gets(name);
puts(name);
}
Функция getchar(). Считывает символ из стандартного входного потока.
Синтаксис:
int getchar (void);
/*Возвращает считанный символ.*/
Пример:
/* функция getchar() рассматривается как значение переменной */
…int letter; // или char letter;
letter = getchar();…// или letter = getchar();
Функцию getchar() можно использовать для приостановки выполнения программы, например:
printf("Для продолжения нажмите Enter");
getchar();
Функции консольного ввода-вывода. Консольная библиотека <conio.h> имеет очень похожие функции ввода-вывода. Отличие состоит в том, что с помощью консольных функций можно задать атрибуты вводимых/выводимых символов: задать положение курсора, изменить цвета фона и символов. Поэтому, например, не имеет смысла использовать некоторые специальные символы при выводе данных на экран (перевод строки, горизонтальная табуляция и т.п.). Синтаксис функций cscanf() и cprintf() идентичен аналогичным функциям библиотеки <stdio.h>.
Функция потокового ввода cin(). Cтандартный поток ввода cin в сочетании с двумя символами «больше» (>>), которые называются оператором извлечения, служит для считывания данных с клавиатуры. При использовании cin нет необходимости определять формат с помощью указателей формата. Поток ввода cin имеет возможность определять тип данных самостоятельно на основании вводимой информации. Это свойство называется перегрузкой.
Синтаксис:
cin >> переменная;
Например:
float A; int B; char C;
cin >> A; // Ввести вещественную А
cin >> B; // Ввести целую В
cin >> C; // Ввести символьную С
Аналогично можно ввести переменные одним оператором ввода:
cin >> A >> B >> C;
Функция потокового вывода cout(). В С++ существует стандартный поток вывода cout, позволяющий в сочетании с двумя символами «меньше» (<<), которые называются оператором вставки, отображать литералы или значения констант и переменных без использования указателей формата. Используя один стандартный поток вывода cout, можно отобразить несколько аргументов. Между собой аргументы разделяются операторами вставки.
Синтаксис: cout << переменная;
Например: cout << " Учимся программировать на языке C++" << endl;
Функция ввода символа getch().
Функция используется при посимвольном вводе данных, определяемую в библиотеке <conio.h>. Эта функция имеет два варианта применения:
а) для остановки программы до нажатия произвольной клавиши, например, перед ее завершением;
б) получение кода ASCII нажатой клавиши. Для получения кода клавиши необходимо объявить целую переменную и присвоить результат исполнения функции getch() этой переменной.
Некоторые компиляторы С/С++ используют функцию getch(), которая вводит символ без последующего нажатия Enter.
Операторы. Для того чтобы выполнить вычисления, превращающие данные в информацию, необходимы операторы. Операнд - это константа, литерал, идентификатор, вызов функции, индексное выражение, выражение выбора элемента или более сложное выражение, сформированное комбинацией операндов, знаков операций и круглых скобок.
Любой операнд, который имеет константное значение, называется константным выражением. Каждый операнд имеет тип.
Комбинация знаков операций и операндов, результатом которой является определенное значение, называется выражением. Знаки операций определяют действия, которые должны быть выполнены над операндами. Каждый операнд в выражении может быть выражением. Значение выражения зависит от расположения знаков операций и круглых скобок в выражении, а также от приоритета выполнения операций.
Лекция №3. Операторы ветвления. Операторы перехода
Цель лекции: изучение операторов ветвления и операторов перехода.
Операторы ветвления выбирают в программе среди нескольких единственный вариант вычислительного процесса.
Оператор if (оператор условия).
Существуют 2 формы записи:
1. if (условие) оператор;
2.if (условие) оператор-1; [else оператор-2;]
Выполнение оператора if начинается с вычисления условия, далее выполнение осуществляется по следующей схеме:
- если выражение истинно (т.е. отлично от 0), то выполняется оператор_1;
- если выражение ложно (т.е. равно 0),то выполняется оператор-2;
- если выражение ложно и отсутствует оператор-2 (в квадратные скобки заключена необязательная конструкция), то выполняется следующий за if оператор.
Пример:
… if (i < j) i++;
else { j = i-3; i++; }…
Допускается использование вложенных операторов if. Оператор if может быть включен в конструкцию if или в конструкцию else другого оператора if. Чтобы сделать программу более читабельной, рекомендуется группировать операторы и конструкции во вложенных операторах if, используя фигурные скобки. Если же фигурные скобки опущены, то компилятор связывает каждое ключевое слово else с наиболее близким if, для которого нет else.
Пример:
void main ( )
{ int t=2, b=7, r=3;
if (t>b)
{ if (b < r) r=b;
}
else r=t;
}
Пример: //Следующий фрагмент иллюстрирует вложенные операторы if:
… char ZNAC; int x,y,z;
…. if (ZNAC == '-') x = y - z;
else if (ZNAC == '+') x = y + z;
else if (ZNAC == '*') x = y * z;
else if (ZNAC == '/') x = y / z; …
Оператор switch. Оператор switch предназначен для организации выбора из множества различных вариантов. Формат оператора следующий:
switch ( выражение )
{ [ case константное-выражение1]: [ список-операторов1]; break;
[ case константное-выражение2]: [ список-операторов2]; break;
…
[ case константное-выражениеn]: [ список-операторовn]; break;
[ default: [ список операторов ] break;]
}
Выражение, следующее за ключевым словом switch в круглых скобках, может быть любым выражением, допустимыми в языке СИ, значение которого должно быть целым. Значение этого выражения является ключевым для выбора из нескольких вариантов. Тело оператора switch состоит из нескольких операторов, помеченных ключевым словом case с последующим константным выражением. Использование целого константного выражения является недостатком. Так как константное выражение вычисляется во время трансляции, оно не может содержать переменные или вызовы функций. Обычно в качестве константного выражения используются целые или символьные константы. Список операторов может быть пустым, либо содержать один или более операторов. Причем в операторе switch не требуется заключать последовательность операторов в фигурные скобки.
Схема выполнения оператора switch следующая:
- вычисляется выражение в круглых скобках;
- вычисленные значения последовательно сравниваются с константными выражениями, следующими за ключевыми словами case;
- если одно из константных выражений совпадает со значением выражения, то управление передается на оператор, помеченный соответствующим ключевым словом case;
- если ни одно из константных выражений не равно выражению, то управление передается на оператор, помеченный ключевым словом default, а в случае его отсутствия управление передается на следующий после switch оператор.
Конструкция со словом default может быть не последней в теле оператора switch. Ключевые слова case и default в теле оператора switch существенны только при начальной проверке, когда определяется начальная точка выполнения тела оператора switch. Все операторы, между начальным оператором и концом тела, выполняются вне зависимости от ключевых слов, если только какой-то из операторов не передаст управления из тела оператора switch. Выход из case используется оператор break. Для того чтобы выполнить одни и те же действия для различных значений выражения, можно пометить один и тот же оператор несколькими ключевыми словами case.
Пример:
… int i=2;
switch (i)
{ case 1: i += 2;
case 2: i *= 3;
case 0: i /= 2;
case 4: i -= 5;
default: ;
}
Пример:
… char ZNAC;
int x,y,z;
… switch (ZNAC)
{ case '+': x = y + z; break;
case '-': x = y - z; break;
case '*': x = y * z; break;
case '/': x = u / z; break;
default : ;
}
Использование оператора break позволяет в необходимый момент прервать последовательность выполняемых операторов в теле оператора switch, путем передачи управления оператору, следующему за switch. В теле оператора switch можно использовать вложенные операторы switch, при этом в ключевых словах case можно использовать одинаковые константные выражения.
Пример:
… switch (a)
{ case 1: b=c; break;
case 2: switch (d)
{ case 0: f=s; break;
case 1: f=9; break;
case 2: f-=9; break;
}
case 3: b-=c; break;…
}
В одном операторе switch не может быть двух констант, имеющие одинаковое значение, хотя оператор switch, включающий в себя другой оператор switch, может содержать аналогичные константы.
Отличие оператора switch от оператора if заключается в том, что он может выполнять только операции строгого равенства, в то время как if может вычислять логические операции.
Операторы перехода. В ряде случаев возникают ситуации, когда необходимо прервать выполнение блока операторов вне зависимости от каких-либо условий.В языке C определены четыре оператора перехода: break, continue, return и goto. Операторы break и continue можно использовать в любом из операторов цикла. Заметим, что вход в тело цикла из оператора, расположенного вне этого цикла, невозможен. Возможны выход из цикла до его нормального завершения и обход части цикла при некоторых условиях. Оператор break можно также использовать в операторе switch. Операторы return и goto можно использовать в любом месте внутри функции.
Оператор break. Оператор break применяется в двух случаях. Во-первых, в операторе switch с его помощью прерывается выполнение последовательности case. Во-вторых, оператор break используется для немедленного прекращения выполнения цикла без проверки его условия и передачи управления оператору, следующему после оператора цикла.
Пример:
/* Последовательно вводятся целые числа, и подсчитывается число введенных до первого отрицательного числа. После этого ввод чисел прекращается*/
#include <stdio.h>
int main(void)
{
int num, count=0;
for(;;count ++)
{
printf("\n num→");
scanf("%d",&num);
if (num<0)
break;// break использован в условии оператора if для выхода из цикла.
}
printf("\n count=%d",count);
return 0;
}
Оператор continue. Можно сказать, что оператор continue немного похож на оператор break. Оператор break вызывает прерывание цикла, а continue – прерывание текущей итерации цикла и переход к следующей итерации.
Пример
/* производится генерация случайных чисел с помощью функции rand() до тех пор, пока не будет найдено 10 нечетных чисел*/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
InitRoutin() /*создаем функцию инициализации генератора случайных чисел*/
{
printf("Инициализация генератора случайных чисел \n");
srand(time(NULL)); /*объявлена в time.h*/
return 0;
}
main(void)
{
int count=0;
for (InitRoutin(); count<10;)
{
int val=rand(); /*rand()–генератор случайных чисел, объявлена в stdlib.h*/
if (val %2==0) /*проверка на четность*/
{
putchar ('.');
continue;// передается управление на начало цикла:
}
count ++;
printf ("Найдено нечетное число: %d\n",val);
}
return 0;
}
Оператор goto. Оператор goto осуществляет безусловную передачу управления на метку в пределах текущей функции. Метка – это идентификатор с двоеточием, ставится перед оператором, которому надо передать управление.
Синтаксис:
M: …
…
goto M; /* М – метка*/
Данный оператор затрудняет понимание программы и нарушает ее структуру. В большинстве случаев его можно заменить оператором break или continue. Использование goto считается допустимым при организации выхода из глубоко вложенного цикла, хотя уже одно это (чрезмерная вложенность и неожиданный выход сразу из нескольких циклов) может свидетельствовать о плохой структуре программы.
Лекция №4. Операторы цикла
Цель лекции: изучение операторов цикла: с предусловием, с постусловием и с параметрами.
Циклом называют многократно повторяющийся участок (оператор или группа операторов) вычислительного процесса. Каждый проход по телу цикла называется итерацией. Цикл, не содержащий внутри себя других циклов, называют простым; если он содержит внутри себя другие циклы или разветвления, то цикл называют сложным. Обычно при каждом повторении цикла вычисления осуществляются с новыми значениями переменных. В любом циклическом процессе в ходе вычислений необходимо решать вопрос анализа некоторого условия. Анализируемую переменную называют параметром. Языки Си/Си++ имеют три оператора для организации цикла.
Оператор цикла с предусловием.
Первая форма записи оператора такова:
while(<условие>) <оператор>;
Вторая форма записи оператора такова:
while(<условие>) { <оператор_1>; <оператор_2>;... <оператор_n>;}
Блок –схема оператора показана на рисунке 4.1:
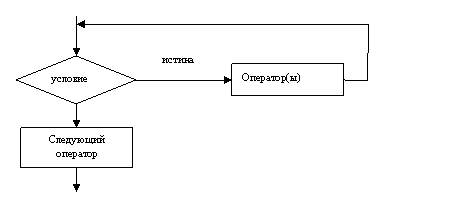
Рисунок 4.1- Блок-схема циклического алгоритма с предусловием
Оператор while организует повторное выполнение одного оператора или нескольких операторов, заключенных в операторные (фигурные) скобки, до тех пор, пока логическое выражение <условие> не примет значение ЛОЖЬ (0). Оператор while называют оператором цикла с предусловием, так как истинность <условие> проверяется перед входом в цикл. Возможна ситуация, когда тело цикла не выполнится ни разу, например:
… int a=0,b=l,n;
scanf("%d",&n);
while( a != n )
{ if (!( b & l ) ) {printf( " %d ", b) ; a++; }
/* Можно и так : if( b% 2== 0 ) {print* ( “ %d “, b); a++;}*/
b++; }
printf("\n");
}
Оператор цикла с постусловием. Если необходимо обеспечить выполнение цикла хотя бы один раз, то удобно использовать оператор цикла с постусловием.
Первая форма записи оператора такова:
do <oператop> while (<условие>);
Вторая форма записи оператора такова:
do {<оператор_1>;
<оператор_2>: ...
<оператор_n>; }
while (<условие>);
Блок –схема оператора показана на рисунке 4.2:
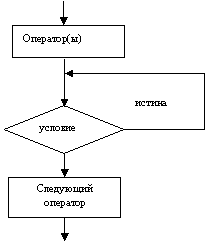 |
Рисунок 4.2 - Блок-схема циклического алгоритма с постусловием
Здесь сначала выполнится <оператор> (или группа операторов), а затем проверяется значение выражения <условие>. Повторение тела цикла (<onepатор>) происходит до тех пор, пока <условие> не примет значение ЛОЖЬ.
Пример:
… int a=0,b=l,n;
puts("Сколько найдем чисел, делящихся на 2?>"); scanf("%d",&n);
do{if (!( b & l ) ) {printf( " %d ", b) ; a++; }
b++; }
while( a != n ) ;
Оператор цикла c параметрами. При организации цикла, когда его тело должно быть выполнено фиксированное число раз, осуществляются три операции: инициализация счетчика, сравнение его величины с некоторым граничным значением и изменение значения счетчика при каждом прохождении тела цикла. Условное выражение, записанное в операторе while, используется для проверки окончания цикла, а приращение значения счетчика осуществляется с помощью опции увеличения.
Синтаксис оператора:
Первая форма записи оператора такова:
for (<иниииализация>;<условие>;<изменение параметров>)
<оператор>;
Вторая форма записи оператора такова:
for(<инициалязация>;<условие>; < изменение параметров>)
{<оператор__1>;
<оператор_2>; . . .
<оператор_n>;};
Блок-схема оператора показана на рисунке 4.3:
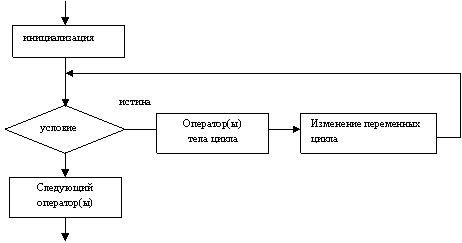
Рисунок 4.3 - Блок-схема циклического алгоритма с параметрами
Оператор использует три выражения, управляющие работой цикла. Они разделены символами "точка с запятой". Инициализирующее выражение вычисляется только один раз до начала выполнения какого-нибудь операторов цикла (поле <инициализация>) и служит для присваивания начальных значений переменным, используемым в цикле. Проверка значения <условие>, если оно не выполняется, т.е. ЛОЖЬ, то цикл завершается. Поле < изменение параметров > служит для изменения значений переменных, используемых в цикле, и значений переменных, управляющих циклом. Как <инициализация>, так и <инкремент> (изменение значения) могут быть любой последовательностью простых операторов, разделенных запятыми. Любое поле может отсутствовать, но знак «;» ставится независимо от присутствия определенного поля. Отсутствовать могут даже все поля, в этом случае получится бесконечный цикл, если внутри цикла не будет какого-нибудь условия выхода:
for(;;) printf(" бесконечно повторяющаяся строка \n");
Операция "запятая" позволяет включить в оператор for несколько инициализирующих или корректирующих выражений. Операторы, записанные через запятую, рассматриваются как один составной оператор.
…{ int k; double res, x;
for(res=0.0, x=1.0, k=1; k<5; res+=l. / x, k+ + , x*=2.0)
printf ("res= %f при k= %d \n", res);
}
Вложенным называется цикл, находящийся внутри другого цикла. Допускаются вложенные циклы с практически не ограниченным количеством уровней. Причем на каждом уровне может быть сколько угодно последовательно идущих циклов. Переменные, выполняющие роль счетчиков, для каждого уровня не должны совпадать.
Оператор break, стоящий в теле цикла, немедленно прекращает выполнение цикла и передает управление на уровень выше, а точнее, на следующий оператор, стоящий после данного цикла, содержащего break. Поэтому для прекращения выполнения многоуровневого цикла приходится выполнять не один, а несколько оператором break.
При написании программ необходимо при каком-то условии немедленно завершить данную итерацию и перейти на новую. Для этого служит оператор continue. Оператор continue вызывает пропуск той части цикла, которая находится после записи этого оператора.
Цель лекции: изучение одномерных массивов.
Массив представляет собой именованную переменную, способную хранить одно или несколько значений одного типа.
Синтаксис описания массива:
тип имя_массива [размерность];
Например:
float array[10]; / *резервируется память для 10 чисел вещественного типа с именем array и порядковыми номерами от 0 до 9. */
int mas[10*5]; //массив из 50 элементов целого типа
Отдельный элемент массива определяется именем массива и индексом элемента в квадратных скобках. Для обращения к элементам массива используется индексная переменная. Индекс – это порядковый номер элемента в массиве; индекс первого элемента всегда равен 0, далее идут положительные целые числа до последнего элемента на единицу меньше размера массива.
Пример:
#include <iostream.h>
void main(void)
{
int values[3]; // Объявление массива
values[0] = 100;
values[1] = 200;
values[2] = 300;
cout << "Массив содержит следующие значения"
<< endl;
cout << values [0] << ' '<< values [1]
<< ' '<< values [2] << ' ' << endl;
}
Инициализировать переменные при объявлении можно и массивы, например:
int values[5] = {100, 200, 300, 400, 500};
Если не указывать первоначальное значение для какого-либо элемента массива, большинство компиляторов С/C++ будут инициализировать такой элемент нулем, например:
int values[5] = {100, 200, 300}; // остальные элементы равны 0
Инициализируя при объявлении массив можно не указывать его размерность, например:
int numbers[] = { 1, 2, 3, 4 };
Чтобы выполнить операции над массивами, необходимо использовать операторы цикла и используется индексная переменная i внутри цикла for для ввода/вывода элементов массива, например:
//ввод массива
for (i=0; i<N; i++)
scanf (“%d”, &A[i]); // или cin >> A[i];
// вывод на экран значений элементов массива
for (i=0; i<N; i++)
printf (“%d ”, A[i]); // или cout<< A[i];
Использование констант при объявлении массивов.
При работе с массивами необходимо указать размер массива. Если изменить программу, увеличив размер массива до 10 значений; в этом случае придется изменить не только объявление массива, но и границу цикла for. Альтернативой этому является объявление массива с использованием макроопределения, например:
#include <stdio.h>
#define ARRAY_SIZE 5
void main(void)
{ int values[ARRAY_SIZE] = (80, 70, 90, 85, 80}; int i;
for (i = 0; i < ARRAY_SIZE; i++)
printf("values[%d] %d\n", i, values[i]);
}
Изменить размер массива, можно просто изменить значение константы ARRA Y_SIZE; в этом случае автоматически изменится как верхняя граница цикла обработки массива, так и размер самого массива.
Лекция №6. Строки
Цель лекции: изучение строк.
В С/С++, в отличие от многих других языков программирования, отсутствует специальный строковый тип. Вместо этого строки представляются как массив элементов типа char, в конце которого помешен символ *\0' (нуль-терминатор). Такой массив называется строкой в формате ASCII. При объявлении массива под строку необходимо предусмотреть место для нуль-терминатора. Объявления символьной строки внутри программы происходит как объявление массива типа char с количеством элементов, достаточным для хранения требуемых символов, например:
char mas[64];
Поскольку строка - это массив, то его можно проинициализировать, например:
char string[5] = { 'Б', 'К', 'Т’, 'T', '\0'}; //пять символов
char string[5] ="БКТТ"; // четыре символа + один для '\0'
char strin[]="БКТТ"; // четыре символа + один для '\0'
В последних двух объявлениях нуль-терминатора нет, потому что если текст помещается в двойные кавычки, то С/С++ рассматривает его как строку, а значит, компилятор автоматически добавляет в конец строки нуль-терминатор.
Инициализация двухмерного массива строками инициализируются символами. В конце каждой строки помещается символ '\0':
char string[3] [50] = {"Список",
"студентов",
"группы"};
Пример:
#include <studio.h>
#include <string.h>
void main(void)
{ char str [10], buf ; int i;
printf (“ введите строку”); gets(str);
for (i=0;i<=(strlen(str)-1)/2;i++)
{buf=str[i]; str[i] =str[(strlen(str)-i-1)]; str[(strlen(str)-i-1)] =buf;}
puts(str);
}
При рассмотрении программ на С/С++ можно встретить символы, заключенные в одинарные кавычки (например, 'А'), и символы, заключенные в двойные кавычки ("А"). Символ внутри одинарных кавычек представляет собой символьную константу. Компилятор выделяет только один байт памяти для хранения символьной константы. Однако символ в двойных кавычках представляет собой строковую константу — указанный символ и символ NULL (добавляемый компилятором). Таким образом, компилятор будет выделять два байта для символьной строки. Программы на С/С++ представляют конец символьной строки с помощью символа NULL, который изображается как специальный символ ' '. Когда вы присваиваете символы символьной строке, вы должны поместить символ NULL (' ') после последнего символа в строке.
Пример:
#include <iostream.h>
void main(void)
{
char alphabet [34]; // 33 буквы плюс NULL
char letter; int index;
for (letter = 'A', index = 0; letter <= 'Я'; letter++,
index++)
alphabet[index] = letter;
alphabet[index] = NULL;
cout << "Буквы " << alphabet;
}
Для работы со строками при использования функций библиотеки существуют следующие правила:
- при переносе символов строки с одного места в другое в функции, то для строки назначения требуется предварительно зарезервировать место в памяти;
- при копировании строк не используют неинициализированный указатель;
- работая со строками, нельзя использовать указатель до инициализации;
- при выделении места для строки-назначения следует предусмотреть место для нуль-терминатора ('\0').
Функции, как fgets ()и cgets(), присваивают символ признака конца строки NULL автоматически.
Пример:
/*функция gets() используется для чтения строки символов с клавиатуры, затем с помощью цикла for выполняется посимвольный вывод содержимого строки до тех пор, пока не будет обнаружен символ NULL*/
#include <stdio.h>
void main (void)
{
char string[256]; // Строка для ввода пользователя
int i; // Индекс в строке
printf("Введите строку символов и нажмите Enter:\n");
gets(string);
for (i = 0; string[i] != NULL; i++) putchar(string[i]);
printf("\nЧисло символов в строке равно %d\n", i);
Для определения в программе количества символов строки большинство Си-компиляторов предоставляет функцию strlen(), которая возвращает число символов в заданной строке.
Пример:
#include <stdio.h>
#include <string.h>
void main(void)
{ char book_title[] = " Учимся программировать на языке C++";
printf("%s содержит %d символов\n", book_title, strlen (book_title));
}
В качестве результата функция strcpy() возвращает указатель на начало целевой строки, например:
#include <stdio.h>
#include <string.h>
void main
(void)
{char title[] = "учебник по C/C++"; char book[128];
strcpy(book, title);
printf("Название книги %s\n", book);
}
Прототипы нижеприведенных функций располагаются в головном файле <string.h> (cм. приложение Ж).
Лекция №7. Многомерные массивы
Цель лекции: изучение многомерных массивов.
Многомерный массив – это массив массивов, т.е. массив, элементами которого являются массивы. Размерность массива – это количество индексов, используемых для ссылки на конкретный элемент массива. Многомерные массивы объявляются точно так же, как и одномерные, только после имени массива ставится более одной пары квадратных скобок, например:
int array[10][20]; /*описание двумерного массива с 10 строками и 20
столбцами*/
Общий объем выделяемой под массив памяти определяется как произведение всех размерностей массива (общее число элементов), умноженное на длину типа данных массива.
Можно инициализировать и многомерные массивы. Инициализация происходит построчно, т.е. в порядке возрастания самого правого индекса. В таком порядке элементы многомерных массивов располагаются в памяти компьютера, например:
int array[2][2][2] ={1,2,3,4,5,6,7,8};
проинициализированный массив будет выглядеть так:
[0][0][0] ==1;
[0][0][1] ==2;
[0][1][0] ==3;
…
[1][1][0] ==7;
[1][1][1] ==8;
Для наглядности при инициализации двумерного массива список начальных значений следует записывать следующим образом:
int array[3][3] ={ 1,2,3,
4,5,6,
7,8,9};
Многомерные массивы могут инициализироваться и без указания одной (самой левой) из размерностей массива. Компилятор определяет по количеству членов в списке инициализации, например:
int array[][3] ={ 1,2,3,
4,5,6,
7,8,9};
Не все элементы строки при объявлении могут быть инициализированы, а только несколько первых. В этом случае в списке инициализации можно использовать фигурные скобки, охватывающие значения этой строки, например:
int array[3][3] ={ {1},
{4,5},
{7,8,9}};
Для доступа к элементу массива необходимо использовать индексы n указатели на элемент массива. В зависимости от n-мерности используют n индексов, например:
int array[10][20]; int i,j;
где индекс i определяет элементы строки, а j определяет элементы столбца.
Для ввода (вывода) многомерных массивов следует использовать вложенные циклы, применяя различные операторы ввода (вывода):
//ввод массива
for (i=0; i<N; i++)
{ for (j=0;j<N; j++)
scanf (“%d”, &A[i]); // или cin >> A[i]
}
// вывод на экран значений элементов массива
for (i=0; i<N; i++)
{ for (j=0;j<N; j++)
printf (“%d ”, A[i]); // или cout<< A[i];
}
Пример:
…puts(‘Сортировка столбцов по убыванию:’);
for j:=1 to n do
{
for i:=1 to m-1 do
for g:=i to m do
if (b[i, j]< b[g, j])
{ z:= b[i, j];
b[i, j]:= b[g, j];
b[g, j]:= z;
}
}…
Лекция №8. Функции
Цель лекции: изучение функций.
Принцип программирования на языке С/ C++, основан на понятии функции. Функции ввода/вывода, обработки строк, преобразования данных и др. являются библиотечными, и они подключаются к программе на этапе ее компоновки. Функция — это программный блок, включающий совокупность объявлений определений данных и операторов, предназначенный для реализации конкретной задачи. В программе функции можно располагать в любой последовательности. Программу разрешается подразделять на произвольное число файлов, которые либо препроцессором, либо компоновщиком объединяются в общий модуль. Однако одна функция (ее определение) не может быть включена в другую функцию.
Спецификация записи функции имеет вид:
<спецификатор_класса_памяти> <спецификатор_типа> имя_функции (<список_формальных_параметров>)
{ тело функции
}
Отдельные части спецификации могут отсутствовать. Необязательный спецификатор класса памяти задает класс памяти и может принимать значения static или extern. Спецификатор типа определяет тип возвращаемого результата. Результат может быть любого стандартного типа, а также типа, определенного пользователем (структура, объединение, класс и др.). Функция возвращает явно только одно значение указанных выше типов. Допускается реализация функций, не имеющих параметров и/или не возвращающих никаких значений. Возвращаемое значение указывается в операторе return и используется в точке вызова функции. Спецификатор типа результата должен быть указан перед именем функции в операторе ее прототипа и в определении функции. Эта информация необходима компилятору для того, чтобы в код функции в необходимых случаях поместить команды преобразования возвращаемого результата к объявленному типу. В случае невозможности таких преобразований выводится сообщение об ошибке. Если тип результата опущен, то предполагается, что возвращается результат целого типа (int).
Оператор return. Оператор return завершает выполнение функции, в которой он встретился, и передает управление в вызывающую программу, в точку вызова. Такой точкой может быть как оператор, следующий за вызовом функции, так и некоторое выражение.
Оператор имеет следующий формат:
return [(выражение)];
Выражение обычно заключается в круглые скобки, хотя это необязательно. Выражение может быть как некоторой константой, так и вычисляемым выражением любого допустимого типа. Например:
return; return 0; return -l; return obj; return (i*j+S); return 5.2*x;
Оператор return в теле функции может быть записан несколько раз. Значение выражения, вычисленное в операторе return, возвращается в вызывающую функцию в качестве результата выполнения функции. Если функция возвращает результат, то ее вызов можно использовать в качестве операнда в выражении.
Например:
у = a*func(r,t); // func, sum - имена функций, вызываемых
z = d - b + sum(x,n); // для выполнения
t = func(a,b) + sum(mas,k);
Функция может возвращать результат, который разрешается не использовать (игнорируется). Если в операторе return отсутствует выражение (т.е. записано return;), то вызывающей функции никакое значение явно не возвращается. При отсутствии оператора return управление в точку вызова будет передано после выполнения последнего оператора функции. В этом случае функция также явно не возвращает результат. Перед именем функции в ее прототипе и определении должно быть записано void (англ. "пусто").
Функция не может в качестве результата возвращать массив любого типа, но может передать указатель на такой массив. Однако массив можно включить в структуру в качестве ее составной части и вернуть переменную типа структуры. Функция также не может вернуть функцию, но может передать результат- указатель на функцию. Если функция определена как возвращающая результат, а в операторе return выражение отсутствует, то выдается сообщение об ошибке.
Любая функция, в том числе и main(),может завершаться выполнением системной функции abort( ) или exit(n) , где п — целое число, являющееся кодом завершения.
Прототип функции. Прототип функции — это ее имя с указанием типа возвращаемого результата и перечислением в круглых скобках (через запятую) типов поступающих параметров. Прототип функции завершается точкой с запятой. Например:
double sum (double, double);
int max(int a, int b);
double prod (double*, int n, double z) ;
Прототип является предварительным объявлением данных функции: имени функции, количества и типов параметров, типа результата. Прототип необходим компилятору для того, чтобы проконтролировать корректность вызова функции и в необходимых случаях выполнить приведение аргументов к типу принимаемых параметров, а также сгенерировать корректный возвращаемый результат. Имена параметров можно опустить. Тело функции, заключенное в скобки {}, в прототипе отсутствует. В том случае, когда в функцию не передаются аргументы, в прототипе в круглых скобках вместо списка параметров записывается слово void либо ничего не указывается.
Например:
#include<stdio.h>
void print(void); // Прототип функции
void main{)
{print(); // Вызов функции
}
void print(void) // Определение (реализация) функции, можно void print()
{ puts("выполнялась функция print");
}
После имени функции при ее вызове круглые скобки обязательны. Если функция имеет класс памяти static, то этот класс должен быть указан в прототипе перед типом результата, иначе подразумевается класс extern. Прототип функции может иметь глобальную область видимости (видим для любой функции данной программы), если объявлен вне тела функции в начале программы, и локальную — объявлен в теле некоторой функции и известен (можно вызвать) только в ней и ниже точки определения функции. Прототипы всех используемых функций помещают в начале программы, а само тело функций — после функции main.
Определение функции. Определение функции — это ее полная реализация. Определение функции имеет формат:
<спецификатор_класса_памяти> <тип_результата> имя_функции (тип_параметра1 параметр1, тип параметра2 параметр2, тип параметраЗ параметрЗ и т.д.])
{ // Тело функции:
// Объявление, определение данных;
// Операторы, реализующие решение задачи, возложенной на функцию; }
Определение функции может располагаться в любом месте программы. Определение одной функции не может вмешать в себя определение другой, но может содержать ее прототип, если она вызывает эту функцию. Если определение некоторой функции располагается ниже точки ее вызова или в другом файле, то для такой функции выше точки ее вызова обязательно должен быть помещен прототип.
Пример:
#include <iostream.h>
int add|(int a, int b); // Прототип функции add
void main ()
{ int a,b,res;a=l;b=3;
res=add(a, b); // Вызов функции add
cout«"\n res =”'« res;}
int add(int a, int b) // Определение функции add
{ return a+b; }
Активизация функции. Функция активизируется (вызывается), если в тексте программы встречается имя функции с последующими круглыми скобками. В круглых скобках могут быть записаны выражения, разделенные запятыми. Выражения являются аргументами, передаваемыми в функцию.
Например:
res=func(a+2*b, lc-dl/j, r+t); // Вызов функции с тремя аргументами
print(); // Вызов функции без аргументов
у=2*рrос ()+1. 5/funl (i + j , j *k, 1, m) ; /* Вызывается функция рrос без аргументов и функция funl с четырьмя аргументами */
Имя функции без круглых скобок не является ее вызовом, а определяет только точку входа в функцию (адрес первой выполняемой команды) и используется при работе с указателями на функции. При вызове функции вычисляются выражения, являющиеся аргументами.
Связь данными между функциями. Функции могут обмениваться информацией тремя способами:
- используя глобальные переменные;
- передавая копии данных;
- передавая адреса, по которым записаны значения переменных (аргументов).
Выражения, которые используются при вызове функции (записываются в круглых скобках после имени функции), называются фактическими параметрами или аргументами. Имена переменных, которые вместе со своими типами записываются в определении функции в круглых скобках после ее имени, называются фиктивными (формальными) параметрами. Формальные параметры — переменные, имена которых используются в операторах функции в качестве ссылок на поступившие аргументы. Эти имена не могут быть переопределены в основном блоке, образующем тело функции, но они могут быть переопределены в блоках ({...}), являющихся частями функции. Параметры получают значения при вызове функции путем копирования значений соответствующих аргументов. В качестве аргумента (параметра) разрешается использовать любой стандартный тип, перечисление, указатель, массив, структуру или объединение. Количество аргументов в обращении к функции должно соответствовать количеству параметров в ее определении. Последовательность записи аргументов должна соответствовать последовательности параметров. Типы аргументов должны быть совместимы с типами соответствующих им параметров. Переменные, определенные в функции, называются локальными переменными т.е. по умолчанию имеют класс памяти auto. Эти переменные видимы (их можно использовать) только в данной функции. Передача значения некоторого аргумента бывает двух типов:
- передача аргументов по значению (изменение параметра в функции модифицирует лишь копию, находящуюся в стеке);
- передача по ссылке (указателю) (изменение значения, находящегося по этому адресу, т.е. изменять значения аргументов, определенных в другой функции).
Обработка в функции массивов данных. Если в качестве передаваемого аргумента используется массив данных, то в функцию передается только указатель на массив, т.е. адрес первого элемента. При вызове функции в списке аргументов записывается имя массива. Имя массива без индекса является адресом элемента с нулевым индексом.
Существует три варианта описания массива, поступающего в функцию в качестве параметра:
- параметр в функции может быть объявлен как массив соответствующего типа с указанием его размера. В этом случае язык Си автоматически преобразует массив к указателю на целый тип, и в функцию передается адрес первого элемента каждой строки матрицы, т.е. адрес первого элемента массива;
- массив в качестве параметра в функции может быть объявлен без указания его размера. Так как сам массив в стек не копируется, то размер массива в общем случае компилятору не требуется. В этом случае также используется указатель на первый элемент массива;
- объявление параметра-массива указателем на соответствующий тип данных.
В языке С/C++ функции распознаются по имени, т.е. разные вызовы функции с одним и тем же именем должны иметь одно и то же количество аргументов и одинаковую их последовательность. Функции можно переопределять, т.е. одно и то же имя можно использовать для вызова различных функций. В этом случае вызов функции определяется либо по количеству параметров, либо по их типу, или и тем, и другим.
Лекция №9. Указатели
Цель лекции: изучение указателей.
Указатель - особый вид переменной, которая хранит адрес элемента памяти, где может быть записано значение другой переменной.
Определение указателя:
type *variable_name;
где type - тип данных указателя; * - звездочка, определяющая тип 'указатель’; variable_name - имя переменной.
Например:
int variable, *point; /* Переменная целого типа и указатель на целый тип (*point) */
Существует операция, неразрывно связанная с указателями. Это унарная операция взятие адреса: &.
Например:
point=&variable;
где point — указатель, variable — переменная некоторого типа. В данном примере в point записывается адрес переменной variable. Результатом применения операции & является адрес переменной в памяти. Результат имеет тип "указатель" на тип переменной. Операция & может использоваться практически со всеми типами данных, кроме констант и битовых полей. Указатели часто используются для обмена данными с функциями. В то время как в функцию можно передавать столько аргументов, сколько требуется, с помощью оператора return возвращается только одно значение.
Операция доступа по указателю:
*Е
где Е - переменная типа "указатель", * - операция разадресации. Результат - содержимое ячейки памяти, на которую указывает Е. C переменной (выражением) *Е можно работать как с обычной переменной.
Пример:
{…
int *p; /* Объявление переменной типа указатель на int*/
int a; /* Объявление переменной а */
а=18;
p=&a; /* Присвоение адреса переменной а переменной р */
*р+=8; /* Значение переменной а после выполнения
этого,
оператора равно 26 */
}
Операция присваивания для указателей аналогична соответствующей операции для других типов данных. Необходимо применять операцию приведения типа, если используются указатели на разные типы данных.
Операция увеличения (уменьшения) указателя (инкремент/декремент):
E+i; E-i;
где Е - переменная типа "указатель", a i — значение целочисленного типа.
Результат операции (E+i) — "указатель", определяющий адрес i-ro элемента после данного, a (E-i) — на i-й элемент перед данным.
Операция сложного присваивания:
E+=i; E-=i;
где Е — переменная типа "указатель", a i — значение целочисленного типа. Эти операции аналогичны выражениям (соответственно):
E=E+i; E=E-i;
Операции инкремента (декремента):
Е++; Е--; ++Е; --Е;
Выполнение данных операций аналогично соответствующим операциям над целочисленными типами, т.е. указатель, будет смещаться (увеличиваться или уменьшаться в зависимости от операции) на один элемент, фактически указатель (адрес) изменится на количество байтов, занимаемых этим элементом в памяти.
Пример изменение адреса вышеперечисленных операций:
…
int a, *pi=&a;
float f,*pf=&f;
pi++;
pf++;
…
В результате pi++ указатель изменится на два байта, а при операции pf++ - на четыре байта.
Операция индексирования:
E[i]
где Е — переменная типа "указатель", a i — значение целочисленного типа. Эта операция полностью аналогична выражению *(E+i), т.е. из памяти извлекается и используется в выражении значение i-ro элемента массива, адрес которого присвоен указателю Е.
Операция вычитания указателей:
Е1-Е2;
где El, E2 — переменные типа "указатель", причем указатели на один и тот же набор данных и, естественно, одного типа. Результат имеет тип int и равен количеству элементов, которые можно расположить в ячейках памяти с Е2 по Е1.
Для указателей определяются операции отношения:
Е1= =Е2; El>=E2; Е1>Е2; E1<=E2; ЕК<=Е2; E1!=E2.
Результат всех операций имеет тип int. Результат операции отношения будет равен единице {true), если Е1 и Е2 указывают на один и тот же элемент в оперативной памяти. В противном случае результат будет равен нулю (false). Результат операции ">=" - единица (true), если объект *Е1 расположен в памяти по более старшим адресам, чем объект *Е2. Результатом операции "<" будет единица (true), если объект *Е1 расположен по более младшим адресам, чем объект *Е2. При реализации операций отношения необходимо учитывать используемую модель памяти и тип указателей. Для указателей типа near и huge операции отношения будут выполняться корректно.
Кроме того, любой указатель (адрес) может быть проверен на равенство
(= =) или неравенство (!=) со специальным значением NULL (NULL = 0).
Функции выделения памяти возвращают NULL при появлении ошибок. Например:
… int * p;
p = new int[10];//выделение памяти под массив из 10 элементов;
if (p = = NULL) printf(“ошибка выделения памяти”);
…
Имя массива - это указатель, равный адресу первого байта первого элемента массива.
Тип указателя void. Указатель типа void* определяет место в оперативной памяти (адрес некоторого байта), но не содержит информации о типе объекта. До использования значения, находящегося по этому адресу, обязательно должна быть выполнена операция приведения указателя к некоторому типу, ибо в противном случае компилятору будет неизвестна длина поля памяти, используемого в операции.
Так как язык С/С++ не поддерживает элементы типа строка, то для работы со строками обычно используются указатели типа char*.
Если строковая константа используется для инициализации указателя типа char*, то адрес первого символа переменной будет начальным значением указателя.
Например:
char *str="cat";
Если строковая константа используется в тех местах выражения, где разрешается применять указатель, компилятор подставляет в выражение вместо константы адрес ее первого символа. Т.к функция выдает только один результат, то для получения результатов из функции используют указатели.
Использование указателей для получения результатов из функции. Пусть функция должна возвратить два значения типа int. Такую функцию реализовать невозможно, но можно вернуть не значение, а записать его в определенную ячейку памяти. Для этого необходимо передать в функцию информацию о том, в какую ячейку памяти поместить результат. Передавать адрес этой ячейки будем с помощью указателя.
Пример: / *вычисление в функции значения квадрата и куба числа. Значение квадрата числа возвращается с помощью указателя.*/
… int fun (int n, int *n2)
{
return n*( *n2- n*n) ;
}
void main ( )
{ int n3; /* В n3 получим куб числа */
int n, n2; /* В 'п2' получим квадрат числа */
cout«"\n Введите N: " ; cin»n;
n3=fun(n, &n2); /* через &n2 передаем указатель на 'n2', т.е. адрес той
ячейки, куда необходимо поместить второе значение */
cout«" n*n= "«n2 «" n*n*n= "«nЗ;
getch();
}
Лекция №10. Массивы и указатели
Цель лекции: изучение взаимосвязи между массивами и указателями.
Между указателями и массивами существует тесная связь. Любую операцию, которую можно выполнить с помощью индексов массива, можно сделать и с помощью указателей. Вариант с указателями обычно оказывается более быстрым, но и несколько более трудным для непосредственного понимания.
Описание int a[10] определяет массив размера 10, т.е. набор из 10 последовательных объектов, называемых a[0], a[1], ..., a[9]. Запись a[i] соответствует элементу массива через i позиций от начала. Если pa - указатель целого, описанный как int *pa ; то присваивание pa = &a[0] ; приводит к тому, что pa указывает на нулевой элемент массива a; это означает, что pa содержит адрес элемента a[0]. Теперь присваивание x = *pa ; будет копировать содержимое a[0] в x.
Если pa указывает на некоторый определенный элемент массива a, то по определению pa+1 указывает на следующий элемент, и вообще pa-i указывает на элемент, стоящий на i позиций до элемента, указываемого pa, а pa+i на элемент, стоящий на i позиций после. Таким образом, если pa указывает на a[0], то
*(pa+1)
ссылается на содержимое a[1], pa+i - адрес a[i], а *(pa+i) - содержимое a[i].
Эти замечания справедливы независимо от типа переменных в массиве a. Суть определения "добавления 1 к указателю", а также его распространения на всю арифметику указателей, состоит в том, что приращение масштабируется размером памяти, занимаемой объектом, на который указывает указатель. Таким образом, i в pa+i перед прибавлением умножается на размер объектов, на которые указывает pa.
Очевидно существует очень тесное соответствие между индексацией и арифметикой указателей. в действительности компилятор преобразует ссылку на массив в указатель на начало массива. В результате этого имя массива является указательным выражением. Отсюда вытекает несколько весьма полезных следствий. Так как имя массива является синонимом местоположения его нулевого элемента, то присваивание pa=&a[0] можно записать как pa = a;
Указателем на массив является имя данного массива, а также указатель на его первый элемент. Например:
int array[10], *аР;
aP=array; // или aP=&array[10]
Для доступа к элементам массива существуют два различных способа:
- по указателю на массив и индексу элемента, задаваемого в квадратных скобках: первый элемент массива имеет индекс 0;
- по указателю на элемент массива.
Для получения адреса элемента массива применяется оператор &.
Имя массива является адресом массива и эквивалентно следующему выражению: &имя_массива[0].
Первый способ связан с использованием обычных индексных выражений в квадратных скобках, например, аrrау[3]=1 или array[i+2] = 7. При таком способе доступа записываются два выражения (array и i+2), причем второе заключается в квадратные скобки. Одно из них должно быть указателем, а второе — выражением целого типа. Последовательность записи этих выражений может быть любой, но в квадратных скобках записывается выражение, следующее вторым. Поэтому записи array [3] и 3[array] эквивалентны и обозначают элемент массива array под номером три.
Указатель, используемый в индексном выражении, не обязательно должен быть константой, указывающей на какой-либо массив, это может быть и переменная.
В частности, после выполнения присваивания аР=аrrау доступ к десятому элементу массива можно получить с помощью указателя аР в форме aP[10] или 10[aP].
Второй способ доступа к элементам массива связан с использованием адресных выражений и операции разадресации в форме (аrrау+10)=3 или
*(array+i+2) =7.
При таком способе доступа адресное выражение, равное адресу десятого элемента массива, тоже может быть записано разными способами:
*(аrrау+10) или *(10+array).
При реализации на компьютере первый способ приводится ко второму, т, е. индексное выражение преобразуется к адресному. Для приведенных примеров array[10] и 10[array] преобразуются в *(аrrау+10).
Для доступа к начальному элементу массива (к элементу с нулевым индексом) можно использовать просто значение указателя array или аР. Любая из операций
*аrrау=2;
array[0]=2;
*(аrrау+0)=2;
*аР=2 ;
аР[0]=2;
*(аР+0)=2;
присваивает начальному элементу массива значение 2, но быстрее всего выполнятся операции *аггау=2 и *ар=2, т. к. в них отсутствует сложение.
Операции над указателями. Над указателями можно выполнять унарные операции — инкремент и декремент. При выполнении операций ++ и -- значение указателя увеличивается или уменьшается на длину типа, на который ссылается используемый указатель. Например:
…int *aP, array[10];
аР=&а[5];
аР++; // Становится равным адресу элемента аrrау[6]
--аР; // Становится равным адресу элемента аrrау[5]
…
В бинарных операциях сложения и вычитания могут участвовать указатель и величина типа int. При этом результатом операции будет указатель на исходный тип, а его значение будет на заданное число элементов больше или меньше исходного. Например:
int *aPl, *aP2, array[10];
int i=2;
aPl=array+(i+4); // Становится равным адресу элемента array[6]
aP2=aPl-i; // Становится равным адресу элемента аrrау [4]
В операции вычитания могут участвовать два указателя на один и тот же тип. Результат такой операции имеет тип int и равен числу элементов исходного типа между уменьшаемым и вычитаемым, причем если первый адрес младше, то результат имеет отрицательное значение. Например:
… int *аР1, *аР2, array[10]; int i;
aPl=array+4;
aP2=array+9;
i=aPl-aP2; // Возвращено значение 5
i=aP2-aPl; // Возвращено значение -5 …
Значения двух указателей на одинаковые типы можно сравнивать в операциях ==, ! =, <, <=, >, >=, при этом значения указателей рассматриваются просто как целые числа, а результат сравнения равен 0 (ложь) или 1 (истина). Например:
…int *aPl, *аР2, аrrау[10];
аР1=аrrау+5;
аР2=аrrау+7;
if (aPl>aP2) аrrау[3]=4;
…
В данном примере значение аР1 меньше значения аР2, и поэтому оператор array [3] =4 не будет выполнен.
Указатели на строку. При обработке строк указатели используются достаточно часто. Строка это массив символов, оканчивающийся null-символом. В нижеприведенной программе определяется функция show_string() для вывода символов строки с помощью указателя на строку:
#include <stdio.h>
#include <conio.h>
void show_string(char *String) // Описание функции
{ while (*String) // Пока строка не пуста
putchar(*String++); // Выбирает первый символ из строки и выводит на экран
}
main()
{ show_string( "Example") ; // Передает в функцию некоторую строку
getch(); // Задерживает экран
return 0; // Завершает программу
}
Переменная string объявлена в функции как указатель. Указатель увеличивается в простом цикле до тех пор, пока не встретится конец строки. Перед тем как вывести очередной символ, он определяется в функции посредством операции *. Затем указатель увеличивается, тем самым ссылаясь на следующий символ.
Указатели на многомерные массивы. Указатели на многомерные массивы создают несколько различных объектов. Например, при выполнении объявления двумерного массива int arr2[4][3] в памяти выделяется участок для хранения значения переменной arr, которая является указателем на массив из четырех указателей. Для этого массива из четырех указателей тоже выделяется память. Каждый из этих четырех указателей содержит адрес массива из трех элементов типа int и в памяти компьютера выделяется четыре участка для хранения четырех массивов чисел типа int, каждый из которых состоит из трех элементов. Такое выделение памяти показано на схеме на рисунке 10.1:
|
arr→ |
|
|
|
|
|
|
|
arr[0]→ |
arr[0][0] |
arr[0][1] |
arr[0][2] | |
|
|
arr[1]→ |
arr[1][0] |
arr[1][1] |
arr[1][2] | |
|
|
arr[2]→ |
arr[2][0] |
arr[2][1] |
arr[2][2] | |
|
|
arr[3]→ |
arr[3][0] |
arr[3][1] |
arr[3][2] | |
Рисунок 10.1 – Выделение памяти двумерного массива
Объявление arr[4][3] порождает в программе три разных объекта: указатель с идентификатором arr, безымянный массив из четырех указателей и безымянный массив из двенадцати чисел типа int. Для доступа к безымянным массивам используются адресные выражения с указателем arr. Доступ к элементам массива указателей осуществляется с указанием одного индексного выражения в форме arr2[2] или *(arr2+2). Для доступа к элементам двумерного массива чисел типа int должны быть использованы два индексных выражения в форме arr2[1][2] или эквивалентных ей *(*(arr2+1)+2) и (*(arr2+1))[2]. Следует учитывать, что с точки зрения синтаксиса указатель arr и указатели arr[0], arr[1], arr[2], arr[3] являются константами, и их значения нельзя изменять во время выполнения программы. Размещение трехмерного массива происходит аналогично, и объявление float arr3[3][4][5] порождает в программе, кроме самого трехмерного массива из шестидесяти чисел типа float, массив из четырех указателей на тип float, массив из трех указателей на массив указателей на float и указатель на массив массивов указателей на float. При размещении элементов многомерных массивов они располагаются в памяти подряд по строкам, т.е. быстрее всего изменяется последний индекс, а медленнее - первый. Такой порядок дает возможность обращаться к любому элементу многомерного массива, используя адрес его начального элемента и только одно индексное выражение. Например, обращение к элементу arr2[1][2] можно осуществить с помощью указателя ptr2, объявленного в форме
int *ptr2=arr2[0]
как обращение
ptr2[1*4+2]
/* здесь 1 и 2 это индексы используемого элемента, а 4 это число элементов в строке) или как ptr2[6]; для обращения к элементу arr3[2][3][4] из трехмерного массива тоже можно использовать указатель, описанный как float *ptr3=arr3[0][0] с одним индексным выражением в форме ptr3[3*2+4*3+4] или ptr3[22]. */
Массивы указателей. Элементы массивов могут иметь любой тип и, в частности, могут быть указателями на любой тип. При объявлении массива имя массива а будет константа-указатель на первый элемент массива.
int a[]={10,11,12,13,14,};
int *p[]={a, a+1, a+2, a+2, a+3, a+4};
int **pp=p;
Лекция №11. Структуры
Цель лекции: изучение структур.
Структуры - это совокупность одного или более объектов, сгруппированных под одним именем. Определение структуры состоит из двух шагов:
- объявление шаблона структуры (задание нового типа данных);
- определение переменных типа объявленного шаблона.
Объявление шаблонов структур. Задание шаблона осуществляется с помощью ключевого слова struct , за которым следует имя шаблона структуры и список элементов, заключенных в фигурные скобки.
Синтаксис шаблона структуры:
struct имя _шаблона
{тип_переменной_1 имя_ переменной_1;
…
тип_переменной_n имя_ переменной_n;
};
Например:
struct student
{char fam[20];
char name[15];
char gruppa[8];
int kurs;
};
Имена элементов в одном шаблоне должны быть уникальными, однако в разных шаблонах можно использовать одинаковые. Задание шаблона не резервируется память компилятором, а дает необходимую информацию об элементах структурной переменной для резервирования места в оперативной памяти и организации доступа к ней при определении.
Полями структуры может быть и сама структура, например:
struct date
{int den, mes,god;};
struct person
{char fam[20];
char name[15];
struct date birthday;
char gruppa[8];
int kurs;
};
Определение структур переменных. Переменная типа структура объявляется как и обычные переменные.
Синтаксис:
struct имя_шаблона имя_переменной;
например:
struct student bktt_12[19];
Компилятор выделит под каждую переменную количество байтов памяти, необходимую для хранения всех ее элементов.
Для совмещения описания шаблона и определения структурной переменной можно использовать псевдонимы, например:
struct date
{
int den, mes,god;
};
struct student
{char fam[20];
char name[15];
char gruppa[8];
int kurs;
struct date birthday;
} lefarov, bktt_12[19], *ptr_ktt;
Доступ к компонентам структуры. Доступ к компонентам структуры осуществляется с помощью:
- оператора «.» -прямой доступ к элементу;
- оператора «->» -доступ по указателю.
Эти операторы называются селекторами членов класса.
Общий синтаксис для доступа к компонентам структуры:
имя_переменной_структуры.имя_поля;
имя_указателя->имя_поля;
(*имя_указателя).имя_поля;
Например:
bktt_12[5].fam= “Ергешев”;
(bktt_12 + 5).fam= “Ергешев”;
ptr_bktt +5 ->kurs = 1;
(*(ptr_bktt +5 )).kurs = 1;
(bktt_12 + 5) -> birthday.god= 1994;
Инициализация структур.
При определении структурных переменных можно инициализировать их поля по тем же правилам, как и инициализация массива:
- присваиваемые значения должны совпадать по типу с соответствующими полями;
- можно объявлять количество присваемых значений меньше, чем количество полей (компилятор присвоит остальным полям структуры нули);
- список инициализации последовательно присваивает значениям структуры, вложенных структур и массивов.
Синтаксис:
имя_шаблона имя_переменной_структуры =
{ значение1;
…
значение n;
};
Например:
struct date
{int den, mes, god;} d[4] = { {26,4,1980 },
{15,7,1994},
{1,1,1990}
};
struct student bktt_12[19] ={
{“Eргешев”, “Абдуазим”, “БКТТ-12”,1, 23,11,1995},
{“Маликов”, “Алишер”, “БКТТ-12”,1, 11,3,1994},
{“Сантбаева”, “Ардак”, “БКТТ-12”,1, 15,7,1994},
};
Операция присваивания значения одной структуре переменной другой при условии, если обе структуры относятся к одному и тому же типу.
Структуры как параметры функций. Компилятор передает в функцию (в стек) данные всей структуры также как и стандартные типы данных.
Например:
… struct person
{ char * str;
int number;
int
};
Лекция №12. Объединения
Цель лекции: изучение объединений.
Объединение - это составной тип данных, который позволяет в разные моменты времени хранить значения различных типов. Объединение может содержать и структурные переменные. Его особенностью является то, что все данные, включенные в объединение, располагаются в памяти с одной и той же границы (адреса), т.е. в отдельный момент времени объединение может хранить только одно значение (они перекрывают друг друга). Данные, входящие в объединение, называются полями.
Объявление объединения. Определение состоит из двух шагов:
- задание шаблона объединения;
- описание переменной .
Каждый шаблон имеет собственное уникальное имя. Но если он используется один раз, то имя может опускаться.
Синтаксис шаблона:
union <имя>
{ тип_1 поле_1;
тип_2 поле_2;
….
тип_n поле_n;
};
где union – ключевое слово объединения; имя – имя шаблона; тип- тип переменной данного поля; поле- имя поля; «;» в конце шаблона определяет конец данного оператора.
Например: union DROB
{ int chisl;
int znam;
};
Имена полей в одном шаблоне должны быть уникальными, однако в различных шаблонах допускается совпадение имен полей и имя шаблона может совпадать с именем поля.
Для задания шаблона можно определять саму переменную:
union <имя_шаблона> < имя_переменной>;
Например: union DROB x1,x2,x3;
Описание шаблона возможно с определением переменной, например:
union DROB
{ int chisl;
int znam;
} x1, x2, x3;
Поле, являющееся объединением называют вложенным. Шаблон вложенного объединения должен быть уже известен компилятору, например:
union DROB
{ int chisl;
int znam;
} ;
union DROB
{ int chislо;
union DROB х;
} x1, x2, x3;
Исключением может являться то ,что вложенное объединение не может вкладываться само в себя, но разрешается использовать шаблон, если одно или несколько полей являются указателями на объединение данного типа.
union DROB
{ int chislо;
union DROB *х;
} ;
Общая форма описания объединения, используя оператор собственного типа typedef:
typedef < опиание_типа><имя_нового_типа> union <имя>
{ тип_1 поле_1;
тип_2 поле_2;
….
тип_n поле_n;
};
Например: typedef union DROB
{ int chisl;пол
int znam;
} complex;
/* без имени объединения */
typedef union
{ int chisl;
int znam;
}complex;
Далее используемый тип можно применить в описании переменных, например:
complex x1,x2, *x3;
union DROB x1,x2, *x3;
Особенностью инициализации объединения является то, что можно инициализировать только первое описанное поле, например:
union DROB
{ int chisl;
int znam;
} ;
union DROB х1 =2;
union DROB
{ int chisl;
int znam;
} complex=2;
Обращение к полям объединения происходит аналогично, как и обращение к полям структуры:
1) используя операцию «.»(точка)
- <имя_объединения> .<имя_поля>
- (*<имя_указателя>).<имя_поля>
2) используя операцию «->»(указатель): <имя_указателя>-> <имя_поля>
Для вложенных объединений используется следующая форма записи:
<имя_указателя><имя_переменной_вложенного_объединения>.<имя_поля>
Т.к. все элементы объединения размещаются в одной и той же области памяти (с одного адреса памяти), то память, которая выделяется под объединение, определяется размером наиболее длинного из элементов данного объединения, например:
union DROB
{
int chisl;
double znam;
} complex;
где компилятор выделит под объединение complex 8 байтов
union PERSON
{
int vozrast;
char fam[20];
} student;
где компилятор выделит под объединение student 20 байтов
/*Все переменные, кроме массивов компилятор размещает в памяти с четного адреса. Пример программы вывода значения полей.*/
#include <iostream.h>
void main ()
{
union person
{
int number;
float zar_pl;
char fam [20];
} azim;
cout <<sizeof (azim);
azim.number =6802;
cout <<endl<< azim.number;
azim. zar_pl =200000.00;
cout <<endl<< azim. zar_pl;
cout <<”введите фамилию”;
cin>> azim.fam;
cout <<endl<< azim.fam;
}
Лекция №12. Файлы
Цель лекции: изучение файлов
Файл – это участок памяти однородной информации, имеющий собственное уникальное имя. Файлы предназначены только для хранения информации, а обработка этой информации осуществляется программами. Файл отличается от массива тем, что файл располагается не в оперативной памяти, а на жестком (или внешнем) носителе. Файл, не содержащий ни одного элемента, называется пустым. Длина файла, т.е. количество элементов, не задается при определении файла. При вводе и выводе данные рассматриваются как поток байтов. Физически поток – это файл или устройство (клавиатура или дисплей). В Си поток можно открыть для чтения и/или записи в текстовом или бинарном (двоичном) режиме. В текстовых файлах не употребляются первые 31 символ кодовой таблицы ASCII (управляющие), а символы конца строки 0x13 (возврат каретки, CR) и 0x10 (перевод строки LF) преобразуются при вводе в одиночный символ перевода строки \n (при выводе выполняется обратное преобразование). Эти символы добавляются в конце каждой строки, записываемой в текстовый файл. При обнаружении в текстовом файле символа с кодом 26 (0x26), т.е. признака конца файла, чтение файла в текстовом режиме заканчивается, хотя файл может иметь продолжение. В двоичном режиме эти преобразования не выполняются, чтение продолжается, пока не встретится физический конец файла. При чтении символы не преобразуются и не анализируются. Объявляется файловая переменная следующим образом:
FILE указатель на поток;
Например: FILE *f;
Открытие и закрытие файла. Перед работой с файлом его необходимо открыть с помощью функции fopen, которая описывается следующим образом:
FILE *fopen(char *filename,char * mode);
где char *filename –строковый литерал, который задает физическое нахождение файла (или путь, если имеет другое местонахождение); и char * mode- строковый литерал, который задает режим доступа к файлу.
Функция открытия потока fopen возвращает указатель на предопределенную структуру типа FILE (содержащую всю необходимую для работы с потоком информацию) при успешном открытии потока, или NULL в противном случае.
В заголовочном файле stdio.h содержится описание файлового типа FILE, с которым связывается файловая переменная (указатель на файл). При открытии файла указатель на файл связывается с конкретным файлом на диске и определяется режим открытия файла (см. таблицу 13.1).
Режим открытия может также содержать символы t (текстовый файл) и b (двоичный файл), указывающий на вид открываемого файла: rb, wb, ab, rt, at, rb+, w+b, ab+ и т.д.
Если не указан режим, то файл указывается в текстовом режиме. Например: if ((file = fopen("1.txt","w")) == NULL) …
Для проверки признака конца файла используется функция feof, возвращаемое ненулевое значение, если текущая позиция является концом (т.е. установлен флаг eof).
После установки флаг не разрешены операции чтения. Флаг опускается при операциях rewind, fseek, и при закрытии потока. Возвращает 0, если флаг не установлен.
Таблица 13.1 – Описание режимов
|
значение |
описание |
|
r |
файл открывается для чтения |
|
r+ |
файл открывается для чтения и записи; файл должен уже существовать |
|
w |
открывается пустой файл для записи . Если файл с таким именем существует, он стирается; |
|
w+ |
открывается файл для чтения и записи. Если файл с таким именем существует, он стирается; |
|
a |
файл открывается для записи в конец |
|
а+ |
файл открывается для чтения и записи в конец файла; если файл не существует, то он создается |
Описание данной функции: int feof (FILE *fp);
Например:
#include <stdio.h>
#define BUFSIZE 128
char buffer [BUFSIZE];
main()
{ FILE *fp;
fp = fopen("file.dat", "r");
{ while(!feof(fp))
fgets(buffer, BUFSIZE, fp);
}
printf("Файл прочитан, встретился EOF \n", buffer);
}
Закрытие файла (текстового или бинарного) выполняется функцией fclose().Для этого необходимо в указанную функцию передавать указатель на FILE, который был получен при открытии. Не закрытые файлы в процессе завершения программы автоматически закрываются системой.
Пример:
#include <iostream.h>
void main()
{ FILE *f;
if(!(f = fopen(“primer.txt”, “r+t”;)))
{ puts(“невозможно отрыть файл”); return;}
… fclose(f); …
Чтение и запись в файл. Если при попытке чтения данных из файла встречается символ конца файла, то возвращается специальное значение EOF. Функции feof(),ferror() сообщают о причинах, по которым операция ввода/вывода не выполнилась. Запись данных в файл и чтение данных из файла можно выполнять разными способами:
- функциями форматного ввода-вывода fscanf(), fprintf();
- функциями неформатного ввода-вывода fread(), fwrite().
Если требуется сохранять и восстанавливать числовые данные без потери точности, то лучше использовать fread(), fwrite().
Например: fread (&bal, sizeof(int),1, file);
fwrite (&bal, sizeof(int),1, file );
Если обрабатывается текстовая информация, которая будет просматриваться обычными текстовыми редакторами, то используется fgetс()- посимвольное чтение файла, посимвольная запись в файл - fputc() или функции fscanf(), fprintf().
Например: fscanf(file,"%d %s", &bal, name);
fprintf(file,"%d %s\n", bal, name);
Для чтения из файла и записи в файл строки используются функции fgets() и fputs().
Пример:
#include
<conio.h>
#include <stdio.h>
main()
{
int
bal;
FILE *file;
if ((file = fopen("3.txt","w")) == NULL)
printf("Файл невозможно открыть или создать\n");
else {
for(int i=0; i<5;i++)
{ scanf("%d", &bal);
fwrite
(&bal, sizeof(int),1, file );
}
}
fclose(file);
getch();
return 0;
}
Позиционирование в файле. При каждом выполнении функции чтения (записи) указатель смещается на определенное количество байтов (устанавливается сразу за прочитанным (записанным) блоком данных), т.е. осуществляется последовательный доступ к данным. Но для того чтобы считывать (записывать) данные в произвольном порядке, необходимо устанавливать указатель на заданную позицию. Для этого используется функция fseek().
Описание данной функции имеет вид:
int fseek (FILE *stream, long offset, int n);
где первый параметр это указатель на файл; offset- количество байтов, на которое необходимо сместить указатель соответственно n.
Параметр n может принимать следующие значения (см. таблицу 13.2):
Таблица 13.2 – Описание параметров смещения n
|
SEEK_SET |
0 |
Смещение выполняется от начала файла |
|
SEEK_CUR |
1 |
Смещение выполняется от текущей позиции указателя |
|
SEEK_END |
2 |
Смещение выполняется от конца файла |
Установка указателя на начало файла осуществляется с помощью функции rewind().
Синтаксис:
void rewind ( FILE *stream);
Не маловажным отличием данных функций является то,
что, в отличие от функции fseek,
rewind
обнуляет индикатор ошибок.
Для потоков, открытых в режиме обновления (чтения + записи), вызов функции rewind позволяет
переключаться между режимами чтения и записи.
/*пример использования rewind*/
#include <stdio.h>
#include <iostream.h>
main()
{
FILE * ptr= fopen("file.txt","w+");
char buffer [27];
for(int counter = 'A'; counter <= 'Z' ; counter++)
fputc( counter, ptr); // записать символ в файл
rewind(ptr); // установить внутренний указатель файла в начало
fread(buffer, 1, 26, ptr); /*считать из файла 26 символов и сохранить в буфер*/
fclose (ptr); //закрыть файл
buffer[26]='\0'; //зaвершить строку
puts(buffer); //вывод на экран
}
Лекция №14. Динамическое использование памяти
Цель лекции: изучение динамического использования памяти.
Динамическое распределение памяти используется тогда, когда заранее неизвестно, сколько объектов понадобится в программе. Память выделяется и освобождается по мере надобности. Область свободной памяти, доступной для выделения, находится между областью памяти, где размещается программа и стеком. Эта область называется кучей или хипом (от англ. heap – куча). Динамическое выделение памяти дает возможность создания динамических структур данных, списков, деревьев, очередей. Ядром динамического выделения памяти в языке Си являются функции, объявленные в стандартной библиотеке в заголовочном файле stdlib.h: malloc(), calloc(), realoc(), free().
Функция malloc(): void *malloc(unsigned size);
Функция malloc() осуществляет запрос на выделение области памяти из хипа размером size байтов. В случае успеха данная функция возвращает указатель на начало выделенного блока памяти. Если для выделения блока в хипе не хватает памяти, возвращается NULL.
Пример:
void main()
{
int *ptr;
…..
if (!(ptr=(int *) malloc(5*sizeof(int))))
/*указатель указывает на массив из 5 элементов*/
{
puts (“проверка на выделение памяти”);
…
}
Функция calloc(). void *malloc(unsigned num, unsigned size);
Функция calloc() выделяет блок памяти и возвращает указатель на первый байт блока. Размер выделяемой памяти равен num*size, т.е функция выделяет память, необходимую для хранения массива из num элементов по size байтов каждый. В случае нехватки памяти для удовлетворения запроса calloc возвращает NULL. Выделяемая память инициализируется нулями.
void main()
{
int *ptr;
…..
if (!(ptr=(int *) calloc(5,sizeof(int)))) /*указатель указывает на массив из 5 элементов*/
//заполненный нулями
{
puts (“проверка на выделение памяти”);
…
}
Функция realloc.
void *realloc(void *ptr, unsigned size);
Эта функция изменяет размер динамически выделяемой области памяти, на которую указывает *ptr на size(новый размер). Если новый размер size больше, чем размер ранее существовавшего блока, то новое неинициализированное пространство памяти будет выделено в конце блока и предыдущее содержимое пространства сохраняется. В противном случае возвращаемое значение равно NULL и с содержимое пространства, на которое указывает ptr, остается нетронутым. Если ptr- не NULL, то значение size равно нулю, то функция realloc действует как free. Отличительной особенностью данной функции является то, что новое пространство может начинаться с адреса, отличного от исходного, поэтому возникает необходимость следить за указателями на измененное пространство, например:
if (p2==realloc(p1,new_size))
p1=p2;
пример:
… if (tmp = realloc(ptr,10* sizeof(int)))
ptr =tmp; /* ptr указывает на массив из 10 чисел*/
else
puts(“не достаточно памяти”); …
Функция free: void free (void *ptr);
Служит для освобождения области памяти, ранее выделенную при помощи функций сalloc, malloc или realloc, на которую указывает ptr, например: … free(ptr);
Если указатель ptr никуда на указывает, т.е. значение равно NULL, то функция free ничего не выполняет.
Пример:
void main()
{
int *ptr;
…
if (!(ptr=(int *) calloc(5*sizeof(int))))
puts(“not enough memory”);
getch();…
free(ptr);…
}
В языке С++ для выделения и освобождения динамической памяти используются два оператора new и delete.
Синтаксис:
указатель_на_тип =new тип; //выделение памяти
delete указатель_на_тип; // освобождение памяти
Оператор new автоматически выделяет требуемое количество памяти для хранения объекта заданного типа и автоматически возвращает указатель на заданный тип. Если оператор new по каким–то причинам не может выделить указанную память, то оператор возвратит указатель на ноль. При выделении памяти под переменные можно производить их инициализацию.
Синтаксис операций выделения и освобождения памяти под одномерный массив:
указатель_на_тип =new тип [размерность];
delete [] указатель_на_тип;
Пример:
/* выделение памяти под многомерные массивы Си++*/
#include <iostream.h>
void main()
{
int *uk =new int (10);
cout << *uk<< “\” ;
int *ptr=new int [5,5];
for (int i=0;i<5;i++)
{ for (int j=0;j<5;j++)
{if (i = =j) ptr[i,j] =i;
else
ptr[i,j] =0;
cout << ptr[i,j];
}
delete uk;
delete[] ptr;
}
}
В программах не рекомендуется использовать смешанные функции по управлению динамической памятью. Если память была выделена функцией new , то освобождать необходимо ее с помощью delete, а не функцией free.
Лекция №15. Динамические структуры
Цель лекции: изучение динамических структур.
Структуры одного типа можно связывать между собой, создавая так называемые динамические структуры данных. Связь между отдельными структурами может быть организована по-разному, и именно поэтому среди динамических данных выделяют списки, стеки, очереди, деревья, графы и т.д. Для динамических типов данных используются структуры. В программе определяется структурный тип данных, где полем такой структуры будет указатель на него. При поступлении команды на создание следующей структуры, снова с помощью функции выделяется память, а указателю присваивается адрес этой новой структуры. В это поле-указатель записывается адрес на структуру, которая была создана перед данной структурой.
Линейные однонаправленные списки Список - это совокупность объектов, называемых элементами списка, в которой каждый объект содержит информацию о местоположении связанного с ним объекта. Если список располагается в оперативной памяти, то, как правило, информация для поиска следующего объекта - это адрес (указатель) в памяти. Если список хранится в файле на диске, то информация о следующем элементе может включать смещение элемента от начала файла, положение указателя записи/считывания файла, ключ записи и любую другую информацию, позволяющую однозначно отыскать следующий элемент списка. Каждый элемент списка представим структурой с двумя полями:
- информационное поле, которое в общем случае может содержать произвольное количество полей разных типов. Ясно, что если значением переменной p является ссылка на элемент списка, то присоединяя к обозначению (*p) с помощью точки имя соответствующего поля, можно манипулировать со значением любого поля информационной части;
- ссылка на следующий элемент списка.
Каждую пару будем называть звеном, а ссылки, содержащиеся в каждом из звеньев, будем использовать для соединения звеньев в список. Такой способ представления упорядоченной последовательности звеньев называется сцеплением.
Описание звена списка выглядит так:
struct node
{
int elem; //Информационный элемент звена списка
node *sled; // Указатель на следующее звено списка
};
Чтобы иметь возможность оперировать со списком как с единым объектом, введем в употребление статическую ссылочную переменную phead, которая указывает на первое звено списка и описывается следующим образом:
struct node *phead;
пустой однонаправленный список с заглавным звеном можно схематически представить как на рисунке 15.1:
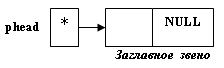
Рисунок 15.1 - Пустой однонаправленный
список с заглавным звеном
Ортогональные списки. Добавление к динамической переменной двух и более полей указателей создает возможность построения нелинейных структур . Ортогональными списками называется списочная структура данных, в которой узлы могут принадлежать более чем одному списку и содержать более одного указателя. На рисунке 15.2 изображено графическое представление ортогональных списков.
Описание типов данных:
// Описание типа звена гирлянды.
struct nodeGir
{int elem; // Информационное поле звена гирлянды.
nodeVis *vniz; // Указатель на звено висюльки.
nodeGir *sled; // Указатель на звено гирлянды.
};
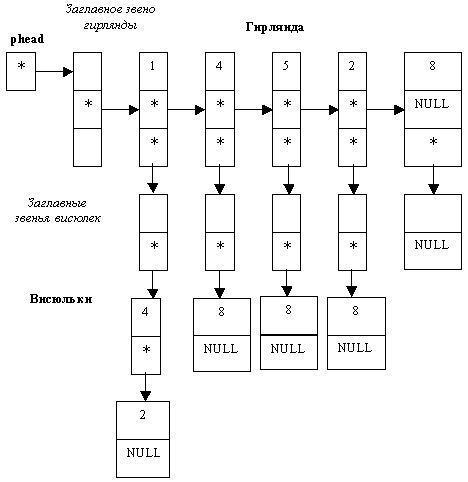
Рисунок 15.2 - "Гирлянды" и "висюльки"
// Описание типа звена висюльки.
struct nodeVis
{int elem; // Информационное поле звена висюльки.
nodeVis *vniz; // Указатель на звено висюльки.
};
Выделим типовые операции над списками:
- добавление звена в начало списка;
- удаление звена из начала списка;
- добавление звена в произвольное место списка, отличное от начала (например, после звена, указатель на которое задан);
- удаление звена из произвольного места списка, отличного от начала (например, после звена, указатель на которое задан);
- проверка, пуст ли список;
- очистка списка;
- печать списка.
Кольцевые списки. Один из недостатков линейных списков заключается в том, что, зная указатель p на звено списка, мы не имеем доступа к предшествующим ему звеньям. Если производится просмотр списка, то для повторного обращения к нему исходный указатель на начало списка должен быть сохранен. Если в структуре линейного списка необходимо сделать изменение, при котором поле sled последнего элемента содержит указатель на заглавное звено, в таком случае необходимы кольцевые списки. Кольцевым списком (кольцом) на базе линейного однонаправленного списка называется линейный список, в котором указатель из некоторого звена направлен на такое звено в списке, из которого данное звено может быть достигнуто вновь (см. рисунок 15.3) Кольцевыми могут быть и однонаправленные, и двунаправленные списки.
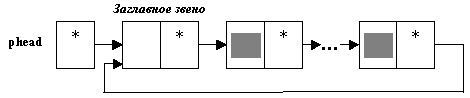
Рисунок 15.3 - Кольцо с включенным заглавным звеном
Очередь - это динамическая структура данных, так как с течением времени длина очереди (количество входящих в нее звеньев) изменяется. Очередь иногда называют циклической памятью или списком типа FIFO ("First In - First Out" - "первым включается - первым исключается").
Изобразим это схематически, как показано на рисунке 15.4:
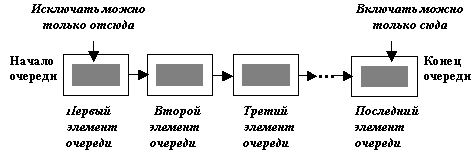
Рисунок 15.4 – Очередь
Стек - это динамическая структура данных, в котором все включения и исключения звеньев делаются в одном конце списка (cм. рисунок 15.5). Существуют и другие названия стека – это список типа LIFO ("Last In - First Out" - "последним включается - первым исключается").
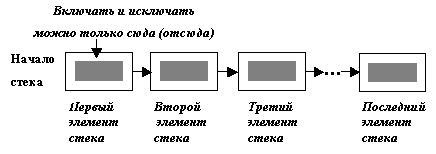
Рисунок 15.5 - Стек
Алгоритм помещения в стек информации.
1. Вначале стек пуст (cм. рисунок 15.6): stk = NULL;
![]()
Рисунок 15.6 - Стек пуст
2. Содержимое стека будем вводить с клавиатуры, ввод заканчивается нулем(cм. рисунок 15.7): cin>>Элем;
t = new (node);
(*t).elem = Элем; (*t).sled = stk;
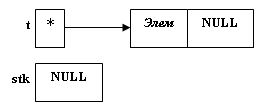
Рисунок 15. 7 - Новый элемент
3. "Настраиваем" указатель стека на созданный элемент (cм. рисунок 15.8).:
stk = t;
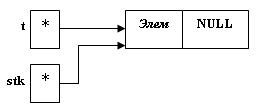
Рисунок 15.8 - "Настройка"
указателя стека
4. В результате в стек будет помещено первое звено(cм. рисунок 15.9):
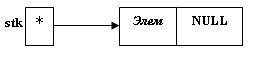
Рисунок 15.9 - Первый элемент в
стеке
5. Продолжим заполнение стека (cм. рисунок 15.10):
cin>>Элем1;
t = new (node);
(*t).elem = Элем1;
(*t).sled = stk;
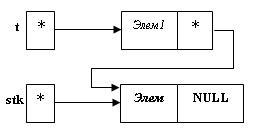
Рисунок 15.10- Размещение в стеке второго
элемента
6. "Настраиваем" указатель стека на созданный элемент (cм. рисунок 15.11): stk = t;
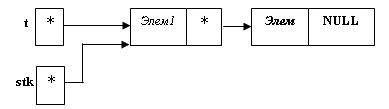
Рисунок 15.11 - "Настройка"
указателя стека
7. Теперь стек содержит уже два звена:

Рисунок 15.12 - В стеке
два элемента
Алгоритм в виде функции языка C++:
void POSTROENIE (node **stk)
//Построение стека, заданного указателем *stk с клавиатуры.
{
node *t;
int el;
*stk = NULL;
cin>>el;
while (el!=0)
{
t = new (node);
(*t).elem = el; (*t).sled = *stk; *stk = t;
cin>>el;
}
}
Алгоритм включения элемента в стек.
1. Создаем новый элемент (cм. рисунок 15.13).:
q = new (node);
(*q).elem = Элем;
![]()
Рисунок 15.13 - Новый
элемент
2. Включаем элемент в начало стека (cм. рисунок 15.14):
(*q).sled = stk;
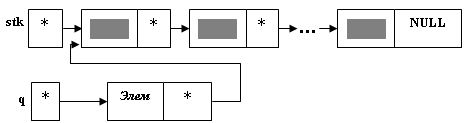
Рисунок 15.14 -. Включение элемента в стек
3."Настроим" указатель вершины стека (cм. рисунок 15.15):
stk = q;
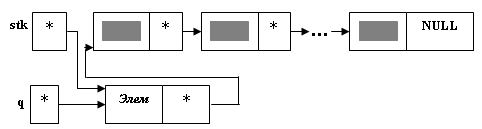
Рисунок 15.15-"Настройка" указателя вершины стека
Функция имеет вид:
void W_S (node **stk, int el)
//Включение звена с элементом el в стек,
// заданный указателем *stk.
{
node *q;
q = new (node);
(*q).elem = el; (*q).sled = *stk; *stk = q;
}
Дек ("Double-Ended Queue" - "двухсторонняя очередь") - это динамическая структура данных, в которой все включения и исключения звеньев делаются на обоих концах списка (см. рисунок 15.16).
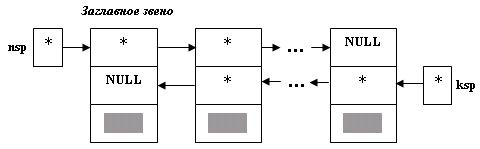
Рисунок 15.16 - Общий вид двунаправленного списка
Тип каждого звена списка можно описать так:
struct node
{ int elem;//Информационное поле.
node *sled; // Указатель на следующее звено.
node *pred; // Указатель на предыдущее звено.
};
Графическое изображение звена показано на рисунке 15.17:
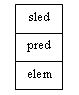
Рисунок 15.17 – Звено списка
Линейные двунаправленные списки.
Структура двунаправленного списка с заглавным звеном показана на рисунке15.18.
Рисунок 15.18 - Общий вид
двунаправленного списка с заглавным звеном
где nsp - указатель на заглавное звено двунаправленного списка, ksp - указатель на последнее звено двунаправленного списка.
Тип каждого звена списка можно описать так:
struct node
{
int elem;//Информационное поле.
node *sled; // Указатель на следующее звено.
node *pred; // Указатель на предыдущее звено.
};
Бинарные деревья. Дерево - это совокупность элементов, называемых узлами (при этом один из них определен как корень), и отношений (родительский–дочерний), образующих иерархическую структуру узлов. Узлы могут являться величинами любого простого или структурированного типа, за исключением файлового. Узлы, которые не имеют ни одного последующего узла, называются листьями. В двоичном (бинарном) дереве каждый узел может быть связан не более чем двумя другими узлами. Рекурсивно двоичное дерево определяется так: двоичное дерево бывает либо пустым (не содержит ни одного узла), либо содержит узел, называемый корнем, а также два независимых поддерева — левое поддерево и правое поддерево.
Каждая вершина бинарного дерева является структурой, состоящей из четырех полей. Содержимым этих полей будут, соответственно:
- информационное поле (ключ вершины);
- служебное поле (их может быть несколько );
- указатель на левое поддерево;
- указатель на правое поддерево.
Таким образом, каждая вершина бинарного дерева описываются на языке C++ следующим образом:
struct node
{ int Key; // Ключ вершины.
int Count; // Счетчик количества вершин с одинаковыми ключами.
node *Left; // Указатель на "левого" сына.
node *Right; // Указатель на "правого" сына.
}
Список литературы
- Керниган Б., Ритчи Д. Язык программирования Си . Пер. с англ., 3-е изд., испр. - СПб.: "Невский Диалект", 2001. - 352 с.
- Борисенко В.В. Основы программирования. http://www.intuit.ru/department/se/pbmsu/
- Поляков К. Программирование на языке Си, 2009. http://kpolyakov.narod.ru
- Бусько В.Л, Корбит А.Г., Коренская И.Н., Убийконь В.И.. Лабораторный практикум по программированию. Ч.2: Основы программирования на алгоритмическом языке. - Мн.: БГУИР, 2001.-62 с.
- Жоголев Е. А. Лекции по технологии программирования. – МГУ.:, 2000 http://sp.cmc.msu.ru/info/3/techprog.htm.
- Ерёмин Е.А., Шестаков А.П. Примерные ответы на профильные билеты. 2007 http://comp-science.narod.ru/Bilet/bil6.htm
- Павловская Т.А. C/C++. Программирование на языке высокого уровня: учебник для студентов вузов, обучающихся по направлению "Информатика и вычислительная техника" / Т.А. Павловская - СПб.: Питер, 2005.- 461 с.
- Культин Н. Б. C/C++ в задачах и примерах. - СПб.: БХВ-Петербург, 2005. - 430 с.
- Подбельский В.В. Язык СИ++: учебное пособие. - М.: Финансы и статистика, 2003. - 560 с.
Приложение А
Таблица А1- Эскейп-последовательности
|
новая строка (newline, linefeed) |
NL (LF) |
\n |
|
горизонтальная табуляция (horizontal tab) |
HT |
\t |
|
вертикальная табуляция (vertical tab) |
VT |
\v |
|
возврат на шаг (backspace) |
BS |
\b |
|
возврат каретки (carriage return) |
CR |
\r |
|
перевод страницы (formfeed) |
FF |
\f |
|
сигнал звонок (audible alert, bell) |
BEL |
\a |
|
обратная наклонная черта (backslash) |
\ |
\\ |
|
знак вопроса (question mark) |
? |
\? |
|
одиночная кавычка (single quote) |
' |
\' |
|
двойная кавычка (double quote) |
" |
\" |
|
восьмеричный код (octal number) |
ooo |
\ooo |
|
шестнадцатеричный код (hex number) |
hh |
\xhh |
Приложение Б
Таблица Б1- Специальные символы
|
знак |
обозначение |
|
Точка |
. |
|
Запятая |
, |
|
Точка с запятой |
; |
|
Двоеточие |
: |
|
Вопросительный знак |
? |
|
Восклицательный знак |
! |
|
Круглая скобка левая |
( |
|
Круглая скобка правая |
) |
|
Апостроф |
‘ |
|
Квадратная открывающая |
[ |
|
Квадратная закрывающая |
] |
|
Фигурная открывающая |
{ |
|
Фигурная закрывающая |
} |
|
Вертикальная черта |
| |
|
Знак "меньше" |
< |
|
Знак "больше" |
> |
|
Знак "равно" |
= |
|
Дробная черта |
/ |
|
Обратная черта |
\ |
|
тильда |
~ |
|
плюс |
+ |
|
минус |
- |
|
звездочка |
* |
|
Исключающее «или» |
^ |
|
амперсанд |
& |
|
Знак процента |
% |
|
номер |
# |
|
кавычки |
“ ” |
Приложение В

Рисунок В1- Иерархия типов
Приложение Г
Таблица Г1- Перечень основных спецификаций формата
|
Формат спецификации |
Назначение |
|
ЦЕЛЫЕ ЧИСЛА | |
|
%d |
целое десятичное число |
|
%x |
целое шестнадцатеричное число |
|
%o |
целое восьмеричное число |
|
%u |
целое беззнаковое десятичное число |
|
%ld |
число типа длинное целое |
|
ВЕЩЕСТВЕННЫЕ ЧИСЛА | |
|
%f |
вещественное число в формате xx.xxxxxx |
|
%e |
вещественное число в научном формате xx.xxxxx e+xx |
|
%g |
вещественное число в форматах %f или %e (в какой форме запись будет короче) |
|
%lf |
вещественное число двойной точности |
|
ОСТАЛЬНЫЕ | |
|
%c |
символ |
|
%s |
строка |
|
%p |
указатель |
Приложение Д
Таблица Д1- Перечень основных операций
|
Операции |
Предназначение операции |
пример |
|
Арифметические операции | ||
|
+ |
Сложение |
z=x+y; если x=7,y=3, то z=10 |
|
- |
Вычитание |
z=x-y; если x=7,y=3, то z=4 |
|
* |
Умножение |
z=x*y; если x=7,y=3, то z=21 |
|
/ |
Деление |
z=x/y; если x=7.0,y=2.0, то z=3.5 |
|
% |
остаток от деления |
z=x%y; если x=7,y=3, то z=1 |
|
Логические операции | ||
|
&& |
логическое И (конъюнкция) |
z=x&&y; если x не равен 0, то z=1, иначе z=0 |
|
|| |
логическое ИЛИ (дизъюнкция) |
z=x||y; если x и y равны 0, то z=0, иначе z=1 |
|
! |
Логическое отрицание (инверсия) |
z=!x; если x = 0, то z=1, иначе z=0 |
|
Побитовые операции | ||
|
& |
Поразрядная конъюнкция |
z=x&y; если оба сравниваемых бита единицы, то бит результата равен 1, иначе 0:если x=1010,y= 0110 то z=0010 |
|
| |
Поразрядная дизъюнкция |
z=x|y; если (любой) оба сравниваемых бита единицы, то бит результата равен 1, иначе 0:если x=1010,y= 0110 то z=0010 |
|
^ |
Поразрядное исключающее ИЛИ |
z=x^y; если один из сравниваемых битов равен 0, а другой бит равен 1, иначе 0:если x=1010,y= 0110 то z=1100 |
|
~ |
Побитовое отрицание (инверсия) |
z=~x; если x=1010, то z=0101 |
|
<< |
Сдвиг влево |
z=x<<y; осуществляет сдвиг значения x влево на y рядов; в освободившиеся разряды заносятся нули; если x=1011,y= 2 то z=101100 |
|
>> |
Сдвиг вправо |
z=x>>y; осуществляет сдвиг значения x влево на y рядов; в освободившиеся разряды заносятся нули; тип x=1011,y= 2 то z=0010 |
Окончание таблицы Д1
|
Операции отношения | ||
|
== |
Равно(сравнение на равенство) |
а==b |
|
< |
Меньше |
a<b |
|
> |
Больше |
a>b |
|
<= |
меньше равно |
a<=b |
|
>= |
больше равно |
a>=b |
|
!= |
не равно |
a!=b |
|
Операции присваивания | ||
|
= |
Присваивание |
x=y; x присваивает значение y |
|
++ |
Унарный инкремент |
x++ (++x) увеличение на единицу |
|
-- |
Унарный декремент |
x--(--x) уменьшение на единицу |
|
op= |
Составная (бинарная) операция присваивания: op принимает операции:* / % + - << >> & | ^ |
x op= y ; применяется как x = x op y; пример: x += y ; применяется как x = x + y;
|
|
Операции адресации (разадресации) | ||
|
& |
взятие адреса |
x=&a;x присваивает адрес а |
|
* |
обращение по адресу |
x=*a; x присваивается значение по адресу а |
|
& |
взятие адреса |
x=&a;x присваивает адрес а |
|
Остальные операции | ||
|
, |
Операции последовательного вычисления запятая |
|
|
? : |
Условная (тернарная) операция |
<операнд1> ? <операнд2>:<операнд3> x= a >b ? a: b; |
|
sizeof |
Операция определения размера (размер в байтах) |
x=sizeof(int); |
|
. |
обращение к полям и методам через сам объект |
|
|
( ) |
вызов функции |
|
|
-> |
обращение к полям и методам через ссылку на объект |
|
|
(тип) |
преобразование типа |
|
Приложение Е
Таблица Е1 – Прототипы функций
|
№ |
синтаксис |
описание |
|
1 |
size_t strlen (const char *s) |
возвращает длину в байтах строки s, не включая '\0' |
|
2 |
char * strcat (char *st, const char *src) |
присоединяет строку src в конец строки st |
|
3 |
char * strcpy (char *st, const char *src) |
копирует строку src в место памяти, на которое указывает st |
|
4 |
char * strncat (char *st, const char *src, size_t maxlen) |
присоединяет maxlen символов строки src в конец строки st |
|
5 |
char * strncpy (char *st, const char *src, size_t maxlen) |
копирует maxlen первых символов строки src в место памяти, на которое указывает st |
|
6 |
char * strstr (char *st, const char *s2) |
отыскивает первое вхождение строки s2 в строку st |
|
7 |
int strcmp (const char *st, const char *s2) |
сравнивает две строки в лексикографическом порядке с учетом различия прописных и строчных букв; возвращает значение меньше нуля, если st располагается в упорядоченном по алфавиту порядке раньше, чем s2, и больше нуля, если наоборот. Функция возвращает нуль, если строки идентичны |
|
8 |
char * stricmp (const char *st, const char *s2) |
аналогична strcmp(), только не различает прописные и строчные буквы |
|
9 |
char *strchr (char * S1, char ch) |
поиск в строке S1 первого вхождения символа ch |
|
10 |
int strncmp (char * S1, char * S2, int maxlen) |
возвращает 0, если S1==S2, возвращает < 0, если S1 < S2 и возвращает > 0, если S1 > S2 сравнивается только первые maxlen символов двух строк |
|
11 |
char *strlwr (char * S) |
переводит всю строку S в нижний регистр (в строчые. буквы) |
|
12 |
char *strupr (char * S) |
переводит всю строку S в верхний регистр (прописные. буквы) |
|
13 |
char *strset (char * S, char ch) |
заполняет всю строку S символами ch |
|
14 |
char *strrev (char * S) |
инвертирует все буквы в строке S (зеркально переворачивает) |
|
15 |
char *strpbrk (char * S1, char * S2) |
просматривает строку S1 до тех пор, пока в ней не встретится символ, содержащийся в строке S2 |
|
16 |
int strspn (char * S1, char * S2) |
возвращает длину начального сегмента строки S1, который состоит исключительно из символов строки S2 |
|
17 |
int strnicmp (char * S1, char * S2, int maxlen) |
возвращает 0, если S1==S2, возвращает < 0, если S1 < S2и возвращает > 0, если S1 > S2сравниваются только первые maxlen символов двух строк, не проверяющих регистр букв |
Сводный план 2013г., поз 253